在Redis中通常普遍認為,使用redis的能進行查詢,插入,刪除,修改操作都是O(1)是因為他是利用hash表實現的,但是,背后的實現不一定是一個標準的hash表,它內部的數據類型還會有變數,不過仍然能保證時間復雜度符合承諾。
在面對不同的場景,redis會進行特定的優化,不同的數據類型(value值)的實現會有不同的內部編碼格式,如下表所示。
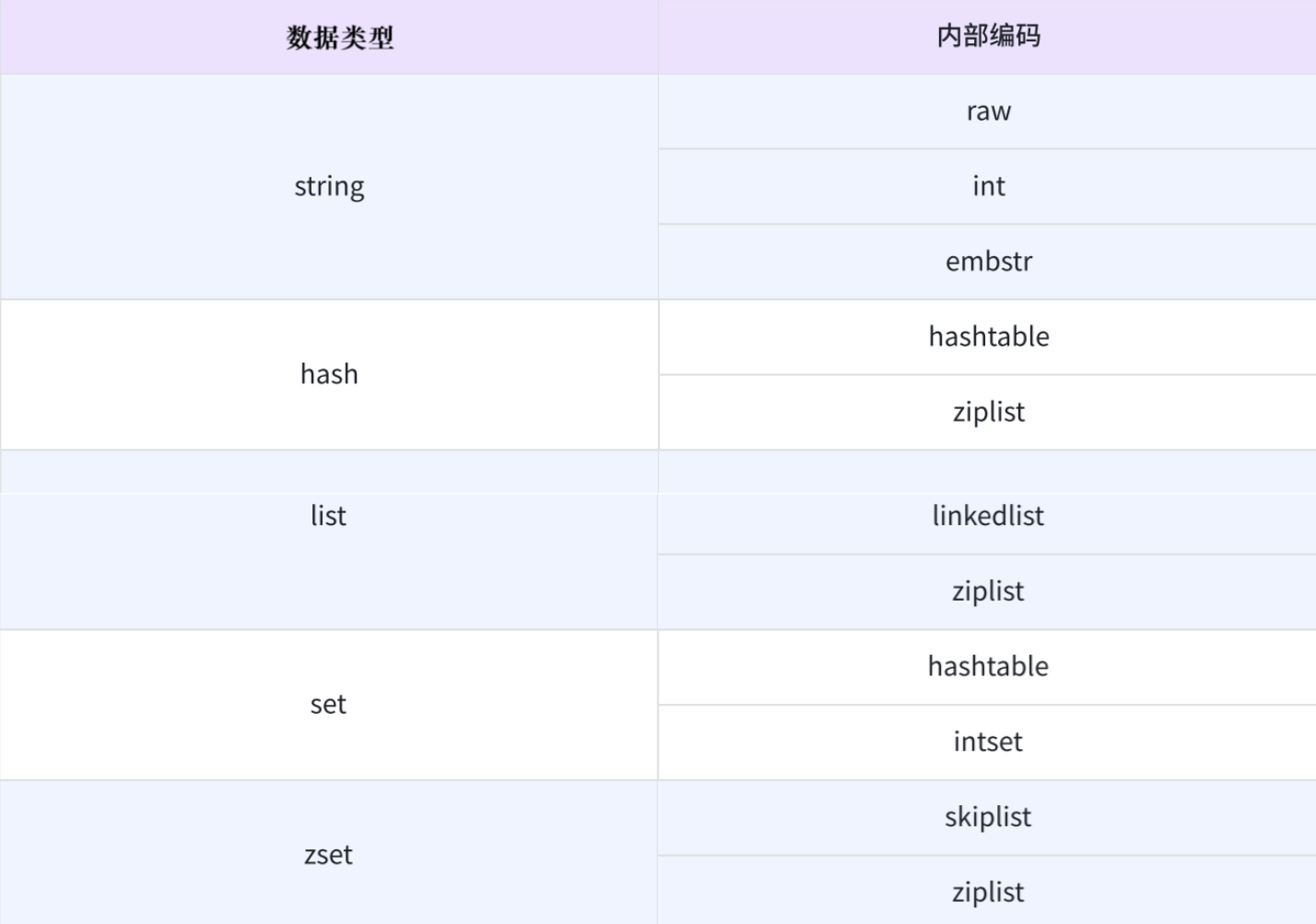
string
raw:最基本的字符串。(底層就是一個C++的char數組,或者Java的byte數組)
int:當value是整數的時候,此時redis可能會直接使用int來保存。
embstr:針對短字符串進行的特殊優化。
hash
hashtable:最基本的hash表。(不是Java標準庫中的HashTable)
ziplist:壓縮列表,能夠節省空間,在hash表元素比較少的時候,可能就會優化成ziplist。
list
linkedlist:最基本的鏈表。
ziplist:壓縮列表。
!!!注意:從redis3.2開始,引入了新的實現方式quicklist,結合兩者優點來替代上面兩種方式,但ziplist任然存在。
set
hashtable:最基本的hash表。
intset:集合中存的都是整數
zset
skiplist:跳表,跳表也是鏈表,不同于普通的鏈表,每個節點上有多個指針域。(類似于經典題目“隨機鏈表的復制”力扣138題)
ziplist:壓縮列表。
如果想要知道當前的key是什么編碼方式可以使用object encoding key來查詢。
對于上面的數據類型采用的哪種編碼方式,最重要的是能知道思想,而不用去記數字。


)


 進度對話框 QProgressDialog:屬性,公共成員函數,槽函數,信號函數,與源代碼帶注釋)
7.24)
機制)









)

