1、創建知識庫步驟
創建一個知識庫并上傳相關文檔主要涉及以下五個關鍵步驟:
-
創建知識庫:首先,需要創建一個新的知識庫。這可以通過上傳本地文件、從在線資源導入數據或者直接創建一個空的知識庫來實現。
-
指定分段模式:接下來是內容預處理與數據結構化的階段,其中長文本將被劃分為多個內容分段。在此過程中,可以預覽文本分段的效果。
-
設定索引方法和檢索設置:一旦文檔被正確分段,下一步就是配置索引方法以及檢索參數。這些設置決定了當用戶提出查詢時,系統如何在已有文檔中查找相關內容,并提取出最相關的片段以供語言模型生成答案。
-
等待分段嵌入:此步驟涉及到將每個分段的內容轉化為向量表示(即 Embedding),以便于后續的高效檢索。
-
完成上傳并在應用內關聯使用:最后,完成文檔的上傳,并在應用程序中關聯該知識庫。這樣,就可以基于這個知識庫搭建問答式的LLM應用了。對于知識庫的管理和維護,請參閱相關指南。
參考閱讀
-
ETL:為了增強非結構化或半結構化數據的預處理能力,Dify 提供了兩種ETL方案:Dify ETL 和 Unstructured ETL。不同的ETL方案支持不同的文件格式解析,選擇合適的ETL方案可以優化數據提取效果。
-
Embedding:這是一種技術,通過將文本轉換為連續的向量表示,從而有效地捕捉文本間的語義相似性和關系。這對于提升信息檢索效率至關重要。
-
元數據:利用元數據功能可以更高效地管理您的知識庫內容,包括但不限于對數據進行分類、標注等操作。
2、示例
2.1、導入文本
2.2 指定分段模式
將內容上傳至知識庫后,接下來需要對內容進行分段與數據清洗。該階段是內容的預處理與數據結構化過程,長文本將會被劃分為多個內容分段。
什么是分段與清洗策略?
分段
由于大語言模型的上下文窗口有限,無法一次性處理和傳輸整個知識庫的內容,因此需要對文檔中的長文本分段為內容塊。即便部分大模型已支持上傳完整的文檔文件,但實驗表明,檢索效率依然弱于檢索單個內容分段。
LLM 能否精準地回答出知識庫中的內容,關鍵在于知識庫對內容塊的檢索與召回效果。類似于在手冊中查找關鍵章節即可快速得到答案,而無需逐字逐句分析整個文檔。經過分段后,知識庫能夠基于用戶問題,采用分段 TopK 召回模式,召回與問題高度相關的內容塊,補全關鍵信息從而提高回答的精準性。
在進行問題與內容塊的語義匹配時,合理的分段大小非常關鍵,它能夠幫助模型準確地找到與問題最相關的內容,減少噪音信息。過大或過小的分段都可能影響召回的效果。
Dify 提供了 "通用分段" 和 "父子分段" 兩種分段模式,分別適應不同類型的文檔結構和應用場景,滿足不同的知識庫檢索和召回的效率與準確性要求。
清洗
為了保證文本召回的效果,通常需要在將數據錄入知識庫之前便對其進行清理。例如,文本內容中存在無意義的字符或者空行可能會影響問題回復的質量,需要對其清洗。Dify 已內置的自動清洗策略,詳細說明請參考 ETL。
LLM 收到用戶問題后,能否精準地回答出知識庫中的內容,取決于知識庫對內容塊的檢索和召回效果。匹配與問題相關度高的文本分段對 AI 應用生成準確且全面的回應至關重要。
好比在智能客服場景下,僅需幫助 LLM 定位至工具手冊的關鍵章節內容塊即可快速得到用戶問題的答案,而無需重復分析整個文檔。在節省分析過程中所耗費的 Tokens 的同時,提高 AI 應用的問答質量。
分段模式
知識庫支持兩種分段模式:通用模式與父子模式。如果你是首次創建知識庫,建議選擇父子模式。
注意:原 "自動分段與清洗"模式已自動更新為 "通用"模式。無需進行任何更改,原知識庫保持默認設置即可繼續使用。選定分段模式并完成知識庫的創建后,后續無法變更。知識庫內新增的文檔也將遵循同樣的分段模式。?
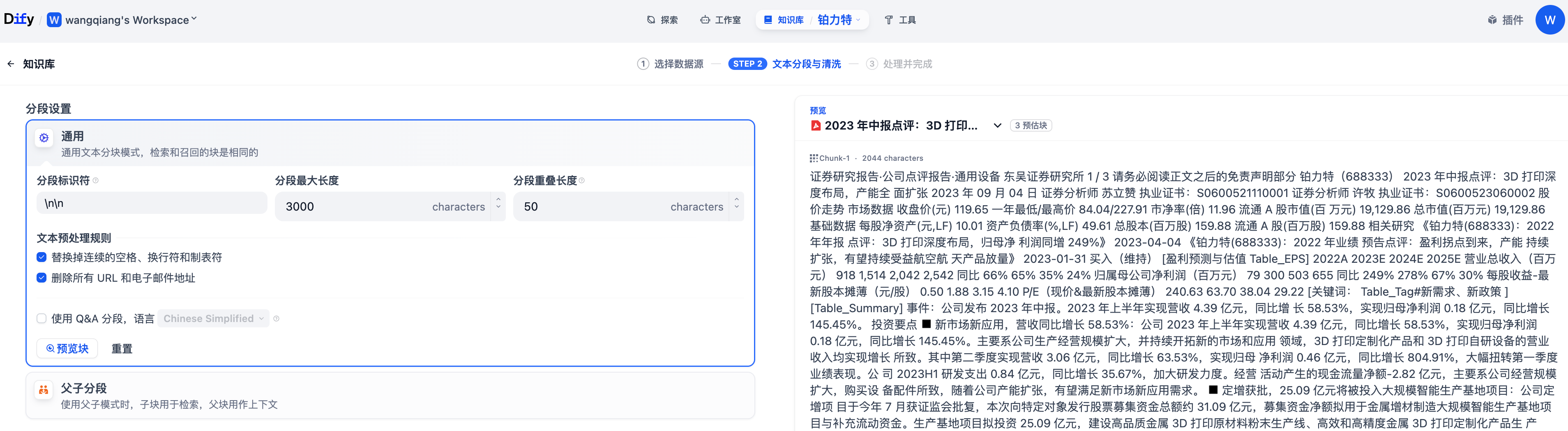
通用模式
系統按照用戶自定義的規則將內容拆分為獨立的分段。當用戶輸入問題后,系統自動分析問題中的關鍵詞,并計算關鍵詞與知識庫中各內容分段的相關度。根據相關度排序,選取最相關的內容分段并發送給 LLM,輔助其處理與更有效地回答。
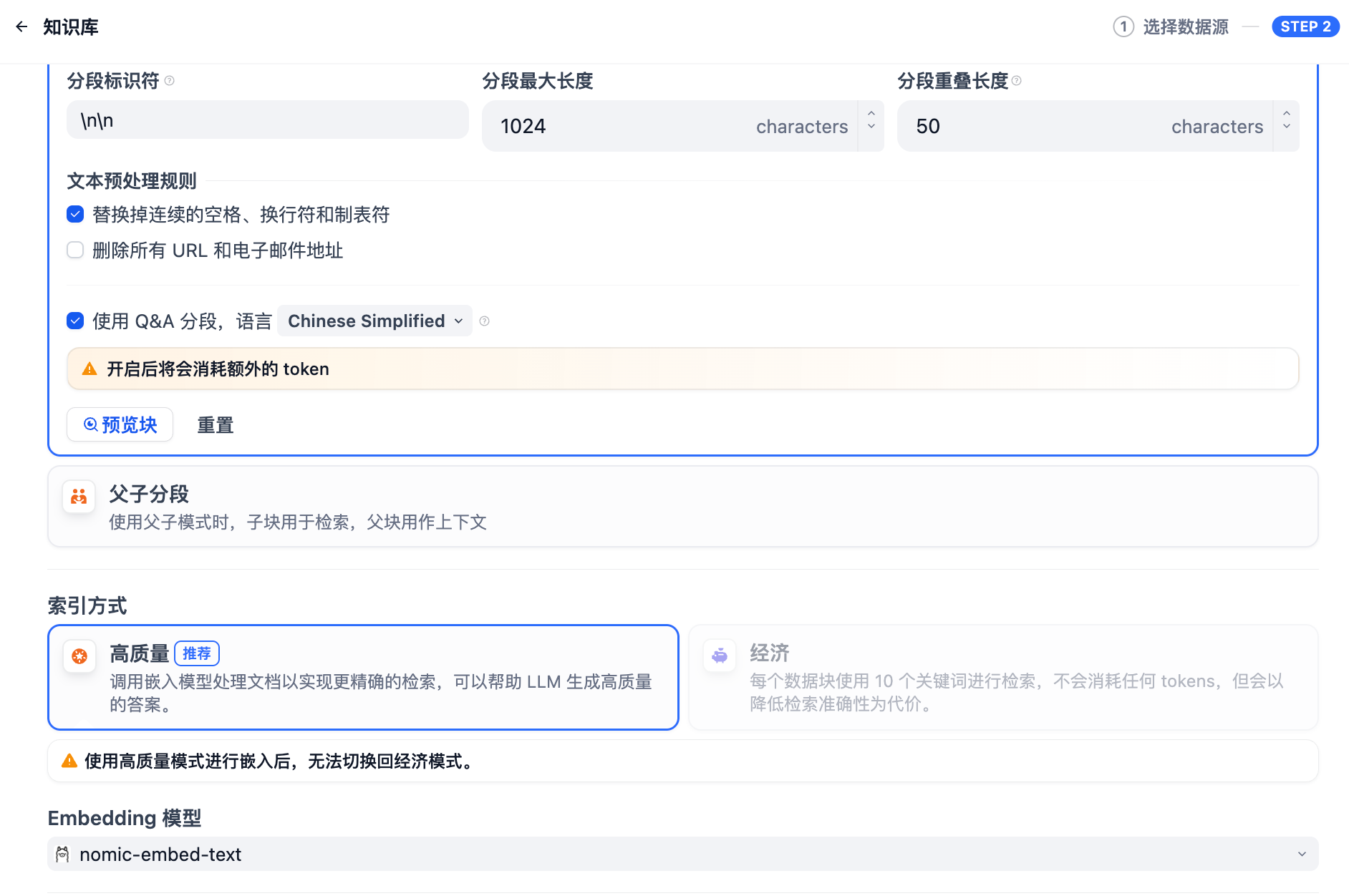
在該模式下,你需要根據不同的文檔格式或場景要求,參考以下設置項,手動設置文本的分段規則。
- 分段標識符,默認值為?
\n,即按照文章段落進行分塊。你可以遵循正則表達式語法自定義分塊規則,系統將在文本出現分段標識符時自動執行分段。例如 的含義是按照句子進行分段。下圖是不同語法的文本分段效果:
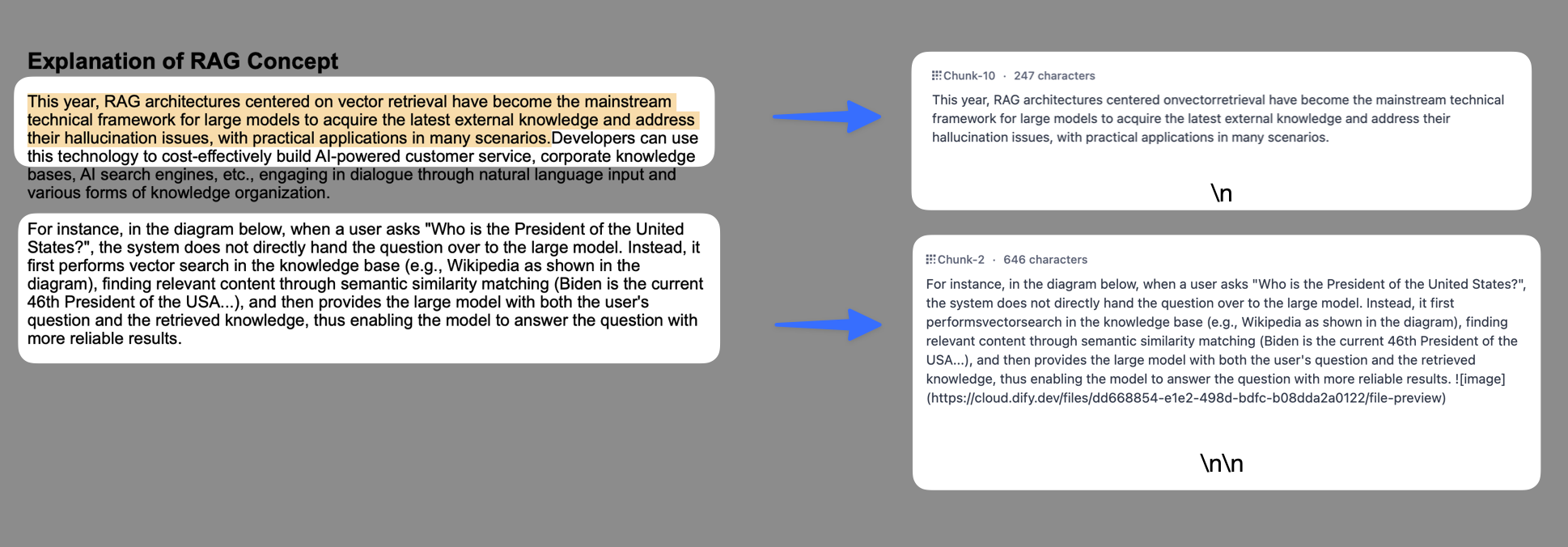
- 分段最大長度,指定分段內的文本字符數最大上限,超出該長度時將強制分段。默認值為 500 Tokens,分段長度的最大上限為 4000 Tokens;
- 分段重疊長度,指的是在對數據進行分段時,段與段之間存在一定的重疊部分。這種重疊可以幫助提高信息的保留和分析的準確性,提升召回效果。建議設置為分段長度 Tokens 數的 10-25%;
文本預處理規則, 過濾知識庫內部分無意義的內容。提供以下選項:
- 替換連續的空格、換行符和制表符
- 刪除所有 URL 和電子郵件地址
配置完成后,點擊"預覽區塊"即可查看分段后的效果。你可以直觀的看到每個區塊的字符數。如果重新修改了分段規則,需要重新點擊按鈕以查看新的內容分段。
若同時批量上傳了多個文檔,輕點頂部的文檔標題,快速切換并查看其它文檔的分段效果。
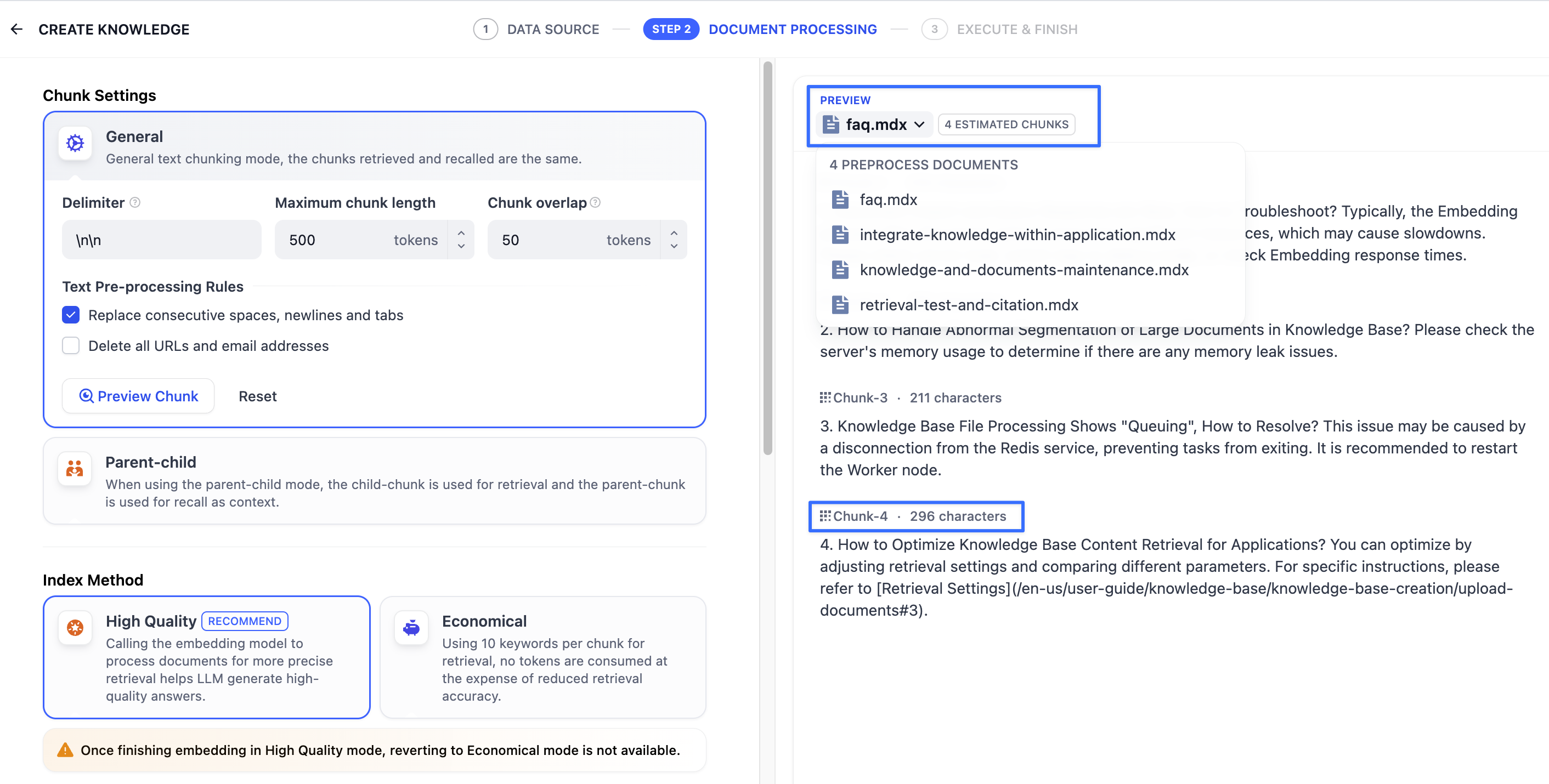
分段規則設置完成后,接下來需指定索引方式。支持"高質量索引"和"經濟索引",詳細說明請參考設定索引方法。
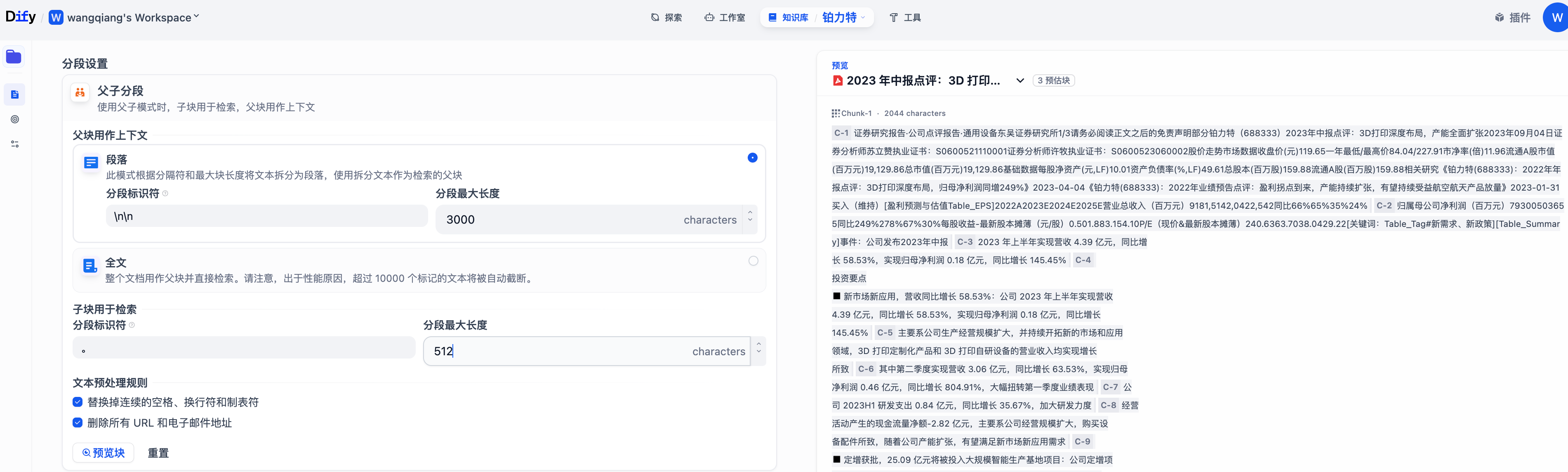
父子模式
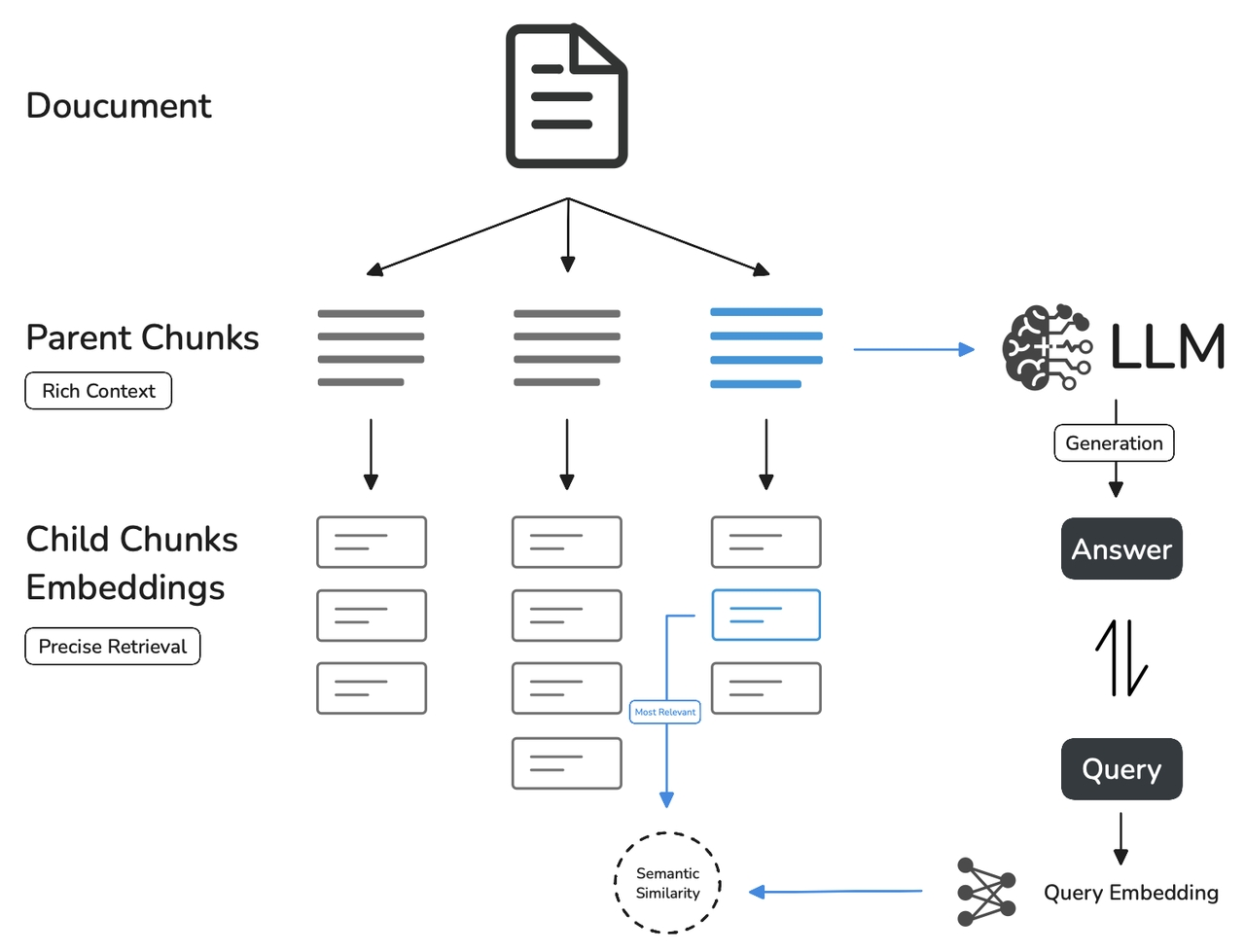
與通用模式相比,父子模式采用雙層分段結構來平衡檢索的精確度和上下文信息,讓精準匹配與全面的上下文信息二者兼得。
其中,父區塊(Parent-chunk)保持較大的文本單位(如段落),提供豐富的上下文信息;子區塊(Child-chunk)則是較小的文本單位(如句子),用于精確檢索。系統首先通過子區塊進行精確檢索以確保相關性,然后獲取對應的父區塊來補充上下文信息,從而在生成響應時既保證準確性又能提供完整的背景信息。你可以通過設置分隔符和最大長度來自定義父子區塊的分段方式。
例如在 AI 智能客服場景下,用戶輸入的問題將定位至解決方案文檔內某個具體的句子,隨后將該句子所在的段落或章節,聯同發送至 LLM,補全該問題的完整背景信息,給出更加精準的回答。
其基本機制包括:
- 子分段匹配查詢:
- 將文檔拆分為較小、集中的信息單元(例如一句話),更加精準的匹配用戶所輸入的問題。
- 子分段能快速提供與用戶需求最相關的初步結果。
- 父分段提供上下文:
- 將包含匹配子分段的更大部分(如段落、章節甚至整個文檔)視作父分段并提供給大語言模型(LLM)。
- 父分段能為 LLM 提供完整的背景信息,避免遺漏重要細節,幫助 LLM 輸出更貼合知識庫內容的回答。
在該模式下,你需要根據不同的文檔格式或場景要求,手動分別設置父子分段的分段規則。
父分段:
父分段設置提供以下分段選項:
- 段落
根據預設的分隔符規則和最大塊長度將文本拆分為段落。每個段落視為父分段,適用于文本量較大,內容清晰且段落相對獨立的文檔。支持以下設置項:
-
分段標識符,默認值為
\n,即按照文本段落分段。你可以遵循正則表達式語法自定義分塊規則,系統將在文本出現分段標識符時自動執行分段。 -
分段最大長度,指定分段內的文本字符數最大上限,超出該長度時將強制分段。默認值為 500 Tokens,分段長度的最大上限為 4000 Tokens;
-
全文
不進行段落分段,而是直接將全文視為單一父分段。出于性能原因,僅保留文本內的前 10000 Tokens 字符,適用于文本量較小,但段落間互有關聯,需要完整檢索全文的場景。

子分段:
子分段文本是在父文本分段基礎上,由分隔符規則切分而成,用于查找和匹配與問題關鍵詞最相關和直接的信息。如果使用默認的子分段規則,通常呈現以下分段效果:
- 當父分段為段落時,子分段對應各個段落中的單個句子。
- 父分段為全文時,子分段對應全文中各個單獨的句子。
在子分段內填寫以下分段設置:
- 分段標識符,默認值為 ,即按照句子進行分段。你可以遵循正則表達式語法自定義分塊規則,系統將在文本出現分段標識符時自動執行分段。
- 分段最大長度,指定分段內的文本字符數最大上限,超出該長度時將強制分段。默認值為 200 Tokens,分段長度的最大上限為 4000 Tokens;
你還可以使用文本預處理規則過濾知識庫內部分無意義的內容:
- 替換連續的空格、換行符和制表符
- 刪除所有 URL 和電子郵件地址
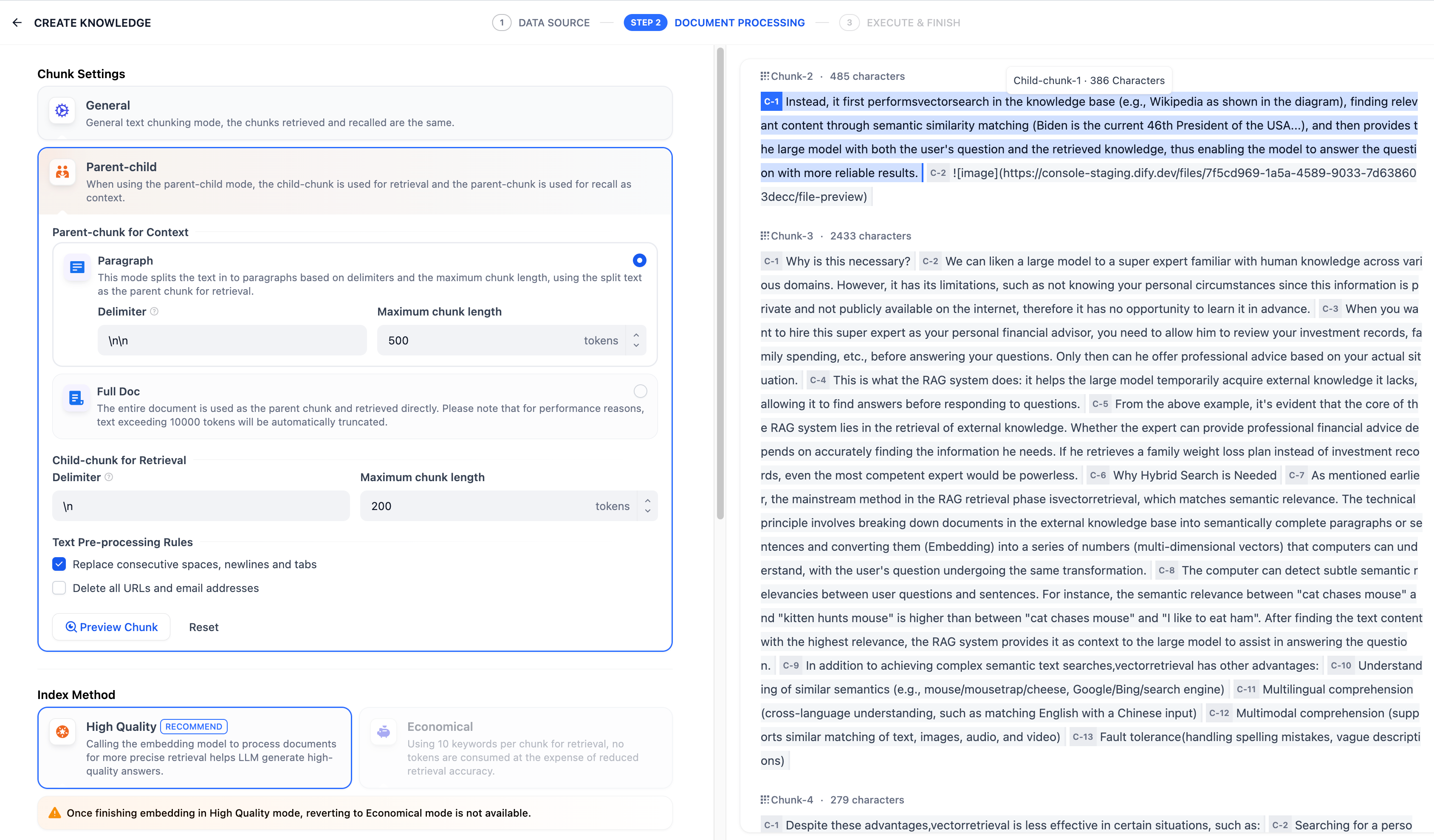
配置完成后,點擊"預覽區塊"即可查看分段后的效果。你可以查看父分段的整體字符數。背景標藍的字符為子分塊,同時顯示當前子段的字符數。
如果重新修改了分段規則,需要重新點擊"預覽區塊"按鈕以查看新的內容分段。若同時批量上傳了多個文檔,輕點頂部的文檔標題,快速切換至其它文檔并預覽內容的分段效果。
為了確保內容檢索的準確性,父子分段模式僅支持使用"高質量索引"。
兩種模式的區別是什么?
兩者的主要區別在于內容區塊的分段形式。通用模式的分段結果為多個獨立的內容分段,而父子模式采用雙層結構進行內容分段,即單個父分段的內容(文檔全文或段落)內包含多個子分段內容(句子)。
不同的分段方式將影響 LLM 對于知識庫內容的檢索效果。在相同文檔中,采用父子檢索所提供的上下文信息會更全面,且在精準度方面也能保持較高水平,大大優于傳統的單層通用檢索方式。
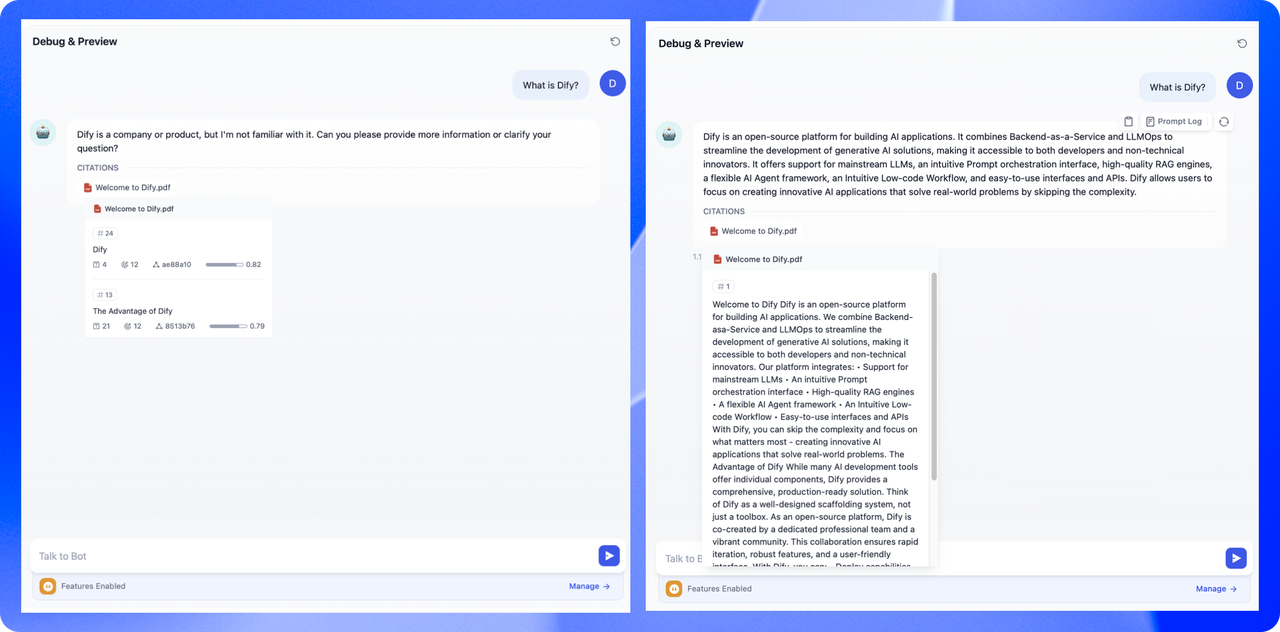
3. 設定索引方法與檢索設置
選定內容的分段模式后,接下來設定對于結構化內容的索引方法與檢索設置。
設定索引方法
正如搜索引擎通過高效的索引算法匹配與用戶問題最相關的網頁內容,索引方式是否合理將直接影響 LLM 對知識庫內容的檢索效率以及回答的準確性。
提供 高質量 與 經濟 兩種索引方法,其中分別提供不同的檢索設置選項:
原 Q&A 模式(僅適用于社區版)已成為高質量索引方法下的一個可選項。
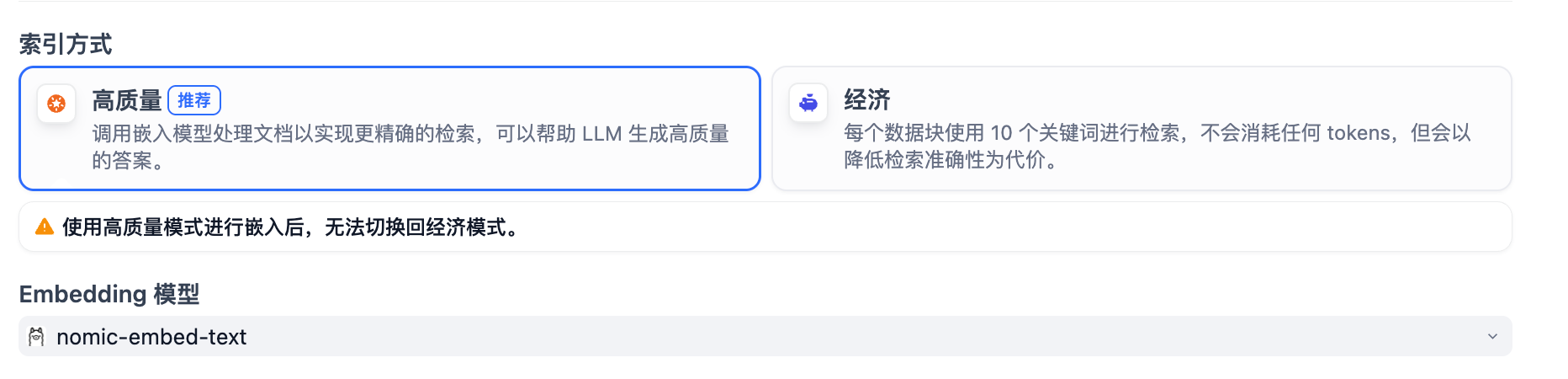
高質量
在高質量模式下,使用 Embedding 嵌入模型將已分段的文本塊轉換為數字向量,幫助更加有效地壓縮與存儲大量文本信息;使得用戶問題與文本之間的匹配能夠更加精準。
將內容塊向量化并錄入至數據庫后,需要通過有效的檢索方式調取與用戶問題相匹配的內容塊。高質量模式提供向量檢索、全文檢索和混合檢索三種檢索設置。關于各個設置的詳細說明,請繼續閱讀檢索設置。
選擇高質量模式后,當前知識庫的索引方式無法在后續降級為 “經濟”索引模式。如需切換,建議重新創建知識庫并重選索引方式。
如需了解更多關于嵌入技術與向量的說明,請參考《Embedding 技術與 Dify》。
 ?
?
啟用 Q&A 模式(可選,僅適用于社區版)
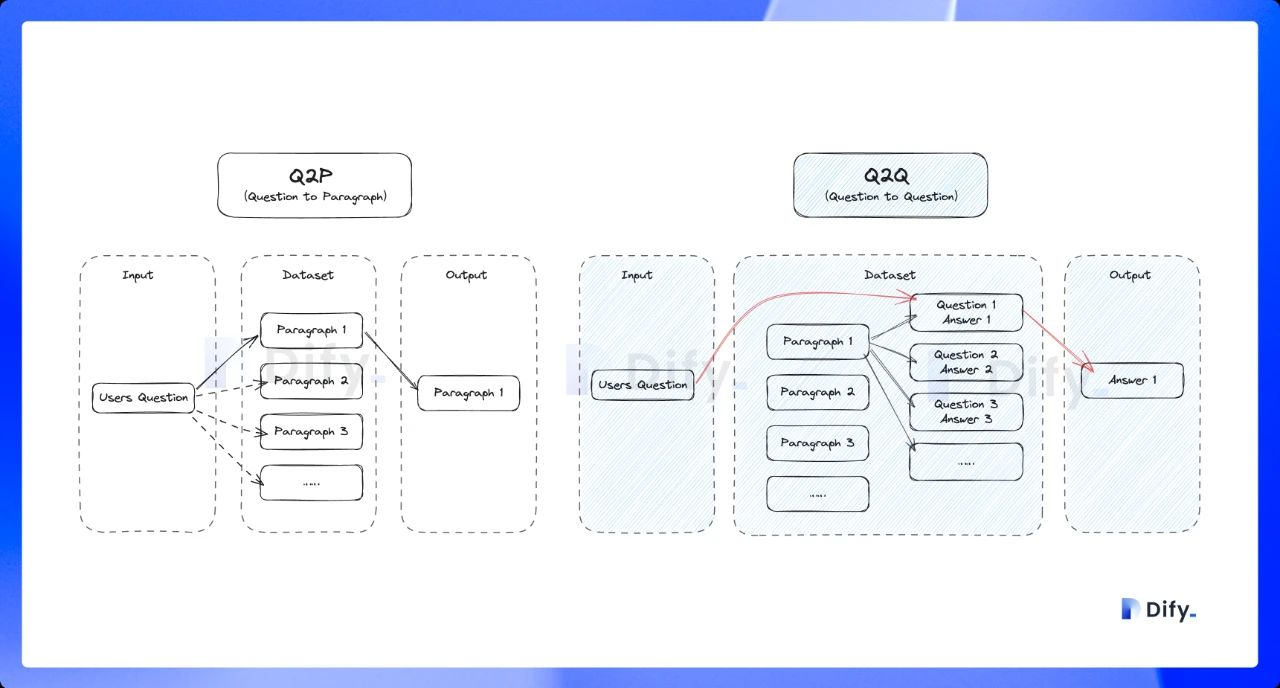
開啟該模式后,系統將對已上傳的文本進行分段。總結內容后為每個分段自動生成 Q&A 匹配對。與常見的 「Q to P」(用戶問題匹配文本段落)策略不同,QA 模式采用 「Q to Q」(問題匹配問題)策略。
這是因為 「常見問題」 文檔里的文本通常是具備完整語法結構的自然語言,Q to Q 模式會令問題和答案的匹配更加清晰,并同時滿足一些高頻和高相似度問題的提問場景。
Q&A 模式僅支持處理 「中英日」 三語。啟用該模式后可能會消耗更多的 LLM Tokens,并且無法使用經濟型索引方法。
 ?
?
當用戶提問時,系統會找出與之最相似的問題,然后返回對應的分段作為答案。這種方式更加精確,因為它直接針對用戶問題進行匹配,可以更準確地幫助用戶檢索真正需要的信息。
 ?
?
經濟
在經濟模式下,每個區塊內使用 10 個關鍵詞進行檢索,降低了準確度但無需產生費用。對于檢索到的區塊,僅提供倒排索引方式選擇最相關的區塊,詳細說明請閱讀下文。
選擇經濟型索引方式后,若感覺實際的效果不佳,可以在知識庫設置頁中升級為 “高質量”索引方式。
指定檢索方式
知識庫在接收到用戶查詢問題后,按照預設的檢索方式在已有的文檔內查找相關內容,提取出高度相關的信息片段供語言模型生成高質量答案。這將決定 LLM 所能獲取的背景信息,從而影響生成結果的準確性和可信度。
常見的檢索方式包括基于向量相似度的語義檢索,以及基于關鍵詞的精準匹配:前者將文本內容塊和問題查詢轉化為向量,通過計算向量相似度匹配更深層次的語義關聯;后者通過倒排索引,即搜索引擎常用的檢索方法,匹配問題與關鍵內容。
不同的索引方法對應差異化的檢索設置。
高質量索引
在高質量索引方式下,Dify 提供向量檢索、全文檢索與混合檢索設置:
向量檢索
定義: 向量化用戶輸入的問題并生成查詢文本的數學向量,比較查詢向量與知識庫內對應的文本向量間的距離,尋找相鄰的分段內容。
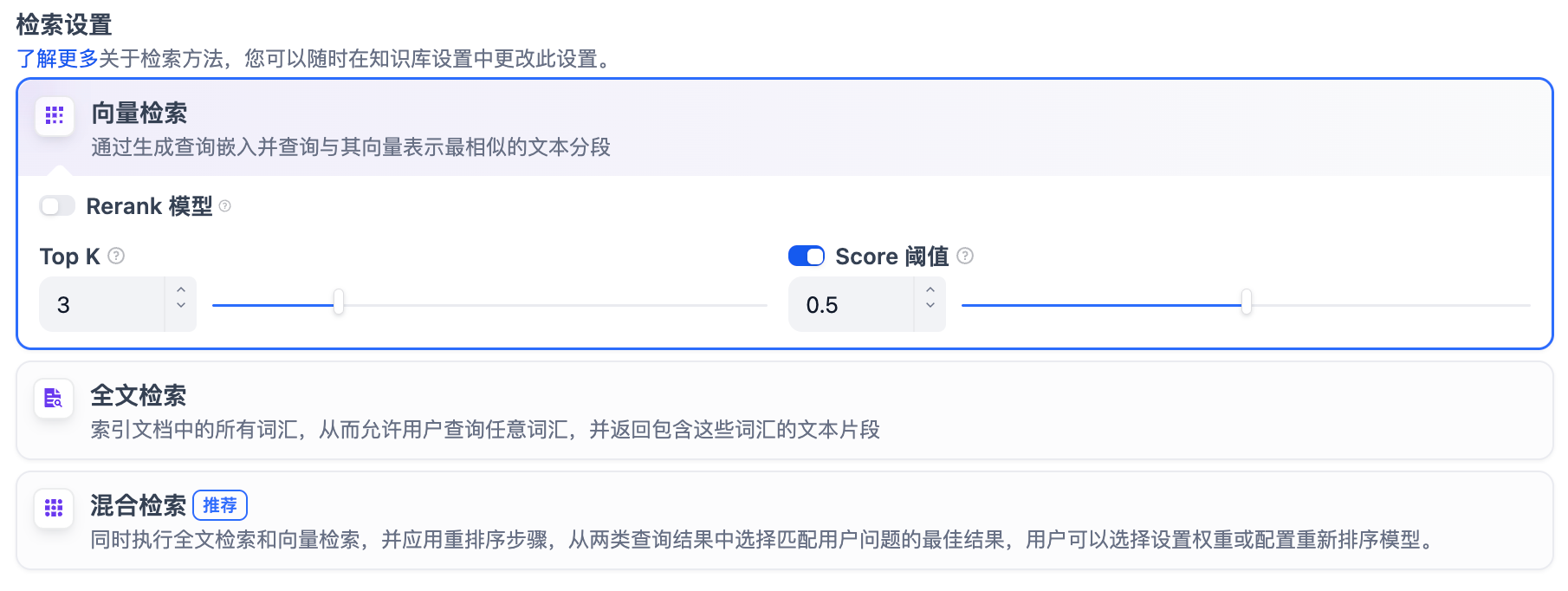
向量檢索設置:
-
Rerank 模型: 默認關閉。開啟后將使用第三方 Rerank 模型再一次重排序由向量檢索召回的內容分段,以優化排序結果。幫助 LLM 獲取更加精確的內容,輔助其提升輸出的質量。開啟該選項前,需前往“設置” → “模型供應商”,提前配置 Rerank 模型的 API 秘鑰。
開啟該功能后,將消耗 Rerank 模型的 Tokens,詳情請參考對應模型的價格說明。
-
TopK: 用于篩選與用戶問題相似度最高的文本片段。系統同時會根據選用模型上下文窗口大小動態調整片段數量。默認值為 3,數值越高,預期被召回的文本分段數量越多。
-
Score 閾值: 用于設置文本片段篩選的相似度閾值,只召回超過設置分數的文本片段,默認值為 0.5。數值越高說明對于文本與問題要求的相似度越高,預期被召回的文本數量也越少。
TopK 和 Score 設置僅在 Rerank 步驟生效,因此需要添加并開啟 Rerank 模型才能應用兩者中的設置參數。
全文檢索
定義: 關鍵詞檢索,即索引文檔中的所有詞匯。用戶輸入問題后,通過明文關鍵詞匹配知識庫內對應的文本片段,返回符合關鍵詞的文本片段;類似搜索引擎中的明文檢索。
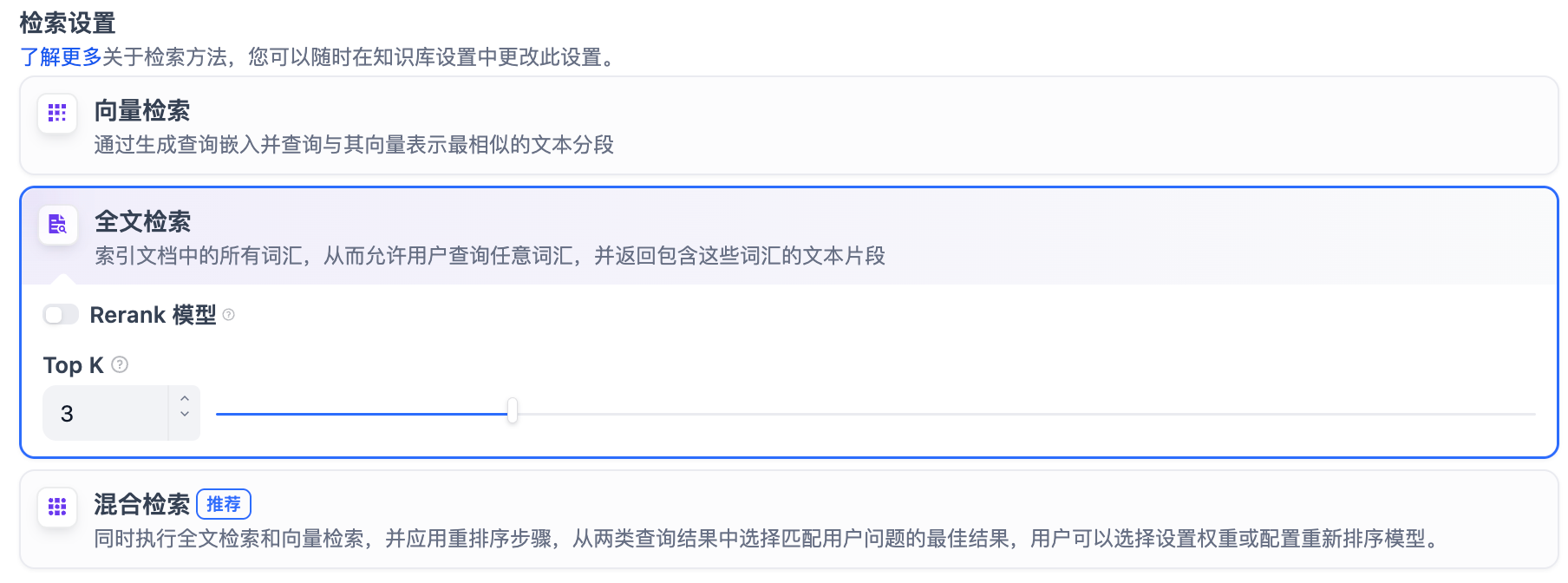
全文檢索設置:
-
Rerank 模型: 默認關閉。開啟后將使用第三方 Rerank 模型再一次重排序由全文檢索召回的內容分段,以優化排序結果。向 LLM 發送經過重排序的分段,輔助其提升輸出的內容質量。開啟該選項前,需前往“設置” → “模型供應商”,提前配置 Rerank 模型的 API 秘鑰。
開啟該功能后,將消耗 Rerank 模型的 Tokens,詳情請參考對應模型的價格說明。
-
TopK: 用于篩選與用戶問題相似度最高的文本片段。系統同時會根據選用模型上下文窗口大小動態調整片段數量。系統默認值為 3 。數值越高,預期被召回的文本分段數量越多。
-
Score 閾值: 用于設置文本片段篩選的相似度閾值,只召回超過設置分數的文本片段,默認值為 0.5。數值越高說明對于文本與問題要求的相似度越高,預期被召回的文本數量也越少。
TopK 和 Score 設置僅在 Rerank 步驟生效,因此需要添加并開啟 Rerank 模型才能應用兩者中的設置參數。
混合檢索
定義: 同時執行全文檢索和向量檢索,或 Rerank 模型,從查詢結果中選擇匹配用戶問題的最佳結果。
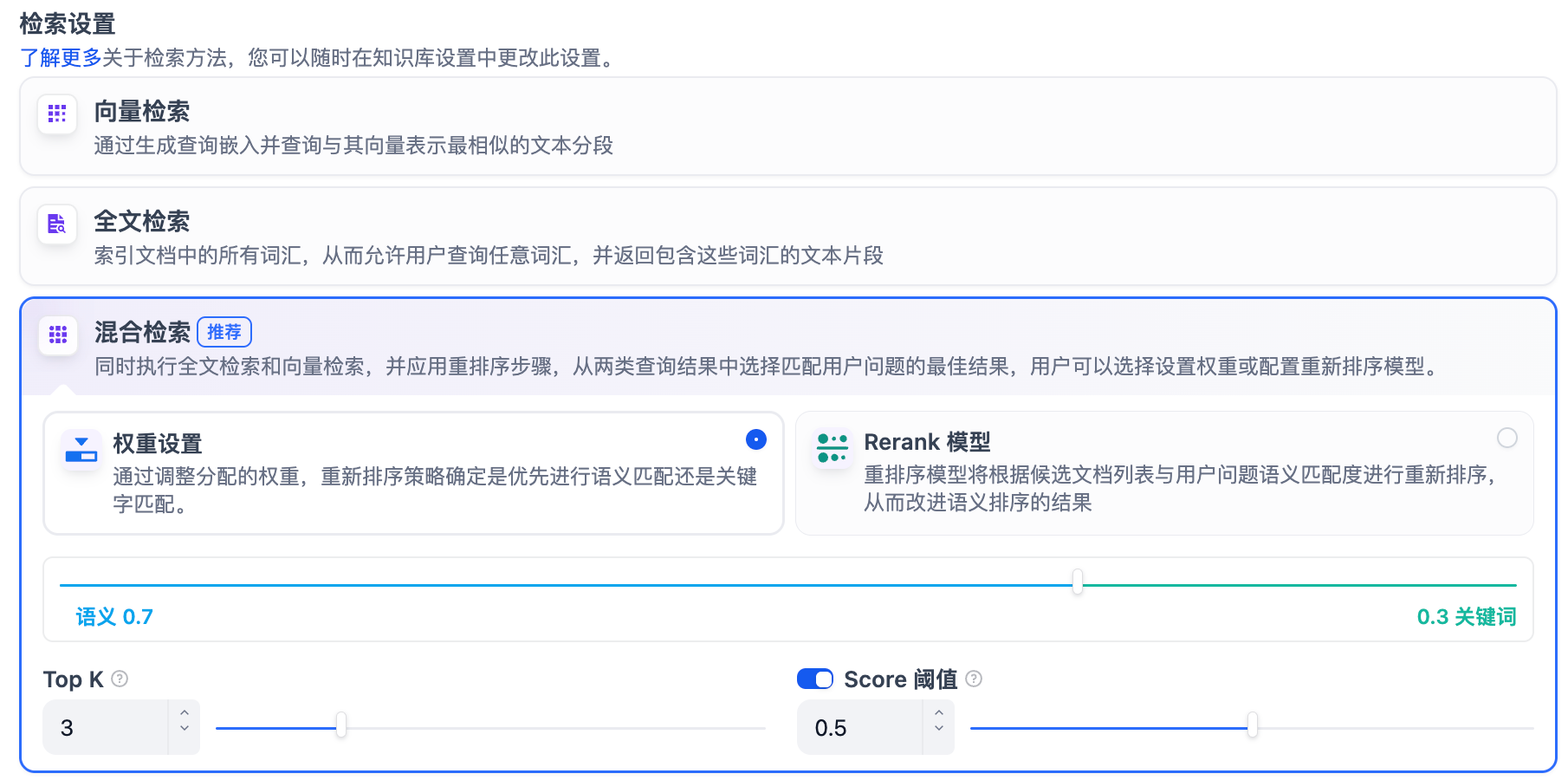
權重設置
允許用戶賦予語義優先和關鍵詞優先自定義的權重。關鍵詞檢索指的是在知識庫內進行全文檢索(Full Text Search),語義檢索指的是在知識庫內進行向量檢索(Vector Search)。
-
將語義值拉至 1: 僅啟用語義檢索模式。借助 Embedding 模型,即便知識庫中沒有出現查詢中的確切詞匯,也能通過計算向量距離的方式提高搜索的深度,返回正確內容。此外,當需要處理多語言內容時,語義檢索能夠捕捉不同語言之間的意義轉換,提供更加準確的跨語言搜索結果。
-
將關鍵詞的值拉至 1: 僅啟用關鍵詞檢索模式。通過用戶輸入的信息文本在知識庫全文匹配,適用于用戶知道確切的信息或術語的場景。該方法所消耗的計算資源較低,適合在大量文檔的知識庫內快速檢索。
-
自定義關鍵詞和語義權重: 除了將不同的數值拉至 1,你還可以不斷調試二者的權重,找到符合業務場景的最佳權重比例。
語義檢索指的是比對用戶問題與知識庫內容中的向量距離。距離越近,匹配的概率越大。參考閱讀:《Dify:Embedding 技術與 Dify 知識庫設計/規劃》。
Rerank 模型
默認關閉。開啟后將使用第三方 Rerank 模型再一次重排序由混合檢索召回的內容分段,以優化排序結果。向 LLM 發送經過重排序的分段,輔助其提升輸出的內容質量。開啟該選項前,需前往“設置” → “模型供應商”,提前配置 Rerank 模型的 API 秘鑰。
開啟該功能后,將消耗 Rerank 模型的 Tokens,詳情請參考對應模型的價格說明。
“權重設置” 和 “Rerank 模型” 設置內支持啟用以下選項:
-
TopK: 用于篩選與用戶問題相似度最高的文本片段。系統同時會根據選用模型上下文窗口大小動態調整片段數量。系統默認值為 3 。數值越高,預期被召回的文本分段數量越多。
-
Score 閾值: 用于設置文本片段篩選的相似度閾值,即:只召回超過設置分數的文本片段。系統默認關閉該設置,即不會對召回的文本片段相似值過濾。打開后默認值為 0.5。數值越高,預期被召回的文本數量越少。
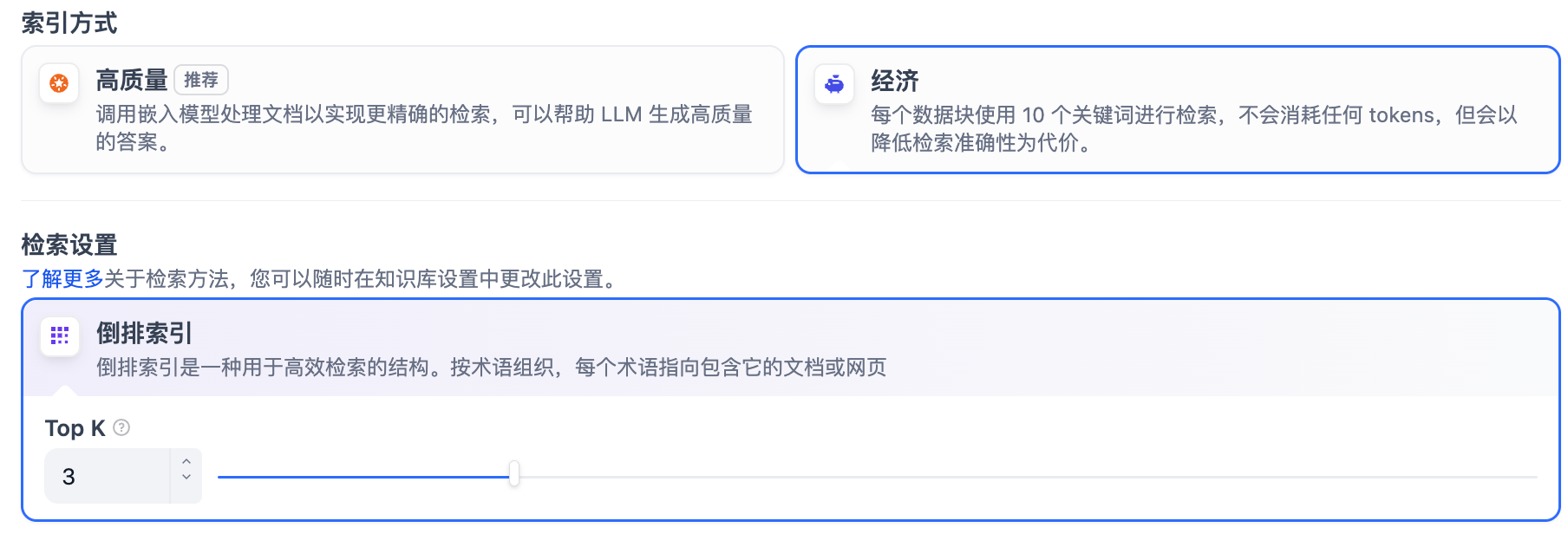
經濟索引
倒排索引
在經濟索引方式下,僅提供倒排索引方式。這是一種用于快速檢索文檔中關鍵詞的索引結構,常用于在線搜索引擎。倒排索引僅支持 TopK 設置項。
-
TopK: 用于篩選與用戶問題相似度最高的文本片段。系統同時會根據選用模型上下文窗口大小動態調整片段數量。系統默認值為 3 。數值越高,預期被召回的文本分段數量越多。









` 函數)




 指令本質、三個查找指令、打包壓縮、重要熱鍵、linux體系結構、命令行解釋器)


)

