文章目錄
- 前言
- 一、TCP流量控制
- 1.1、案例:三次流量控制
- 1.2、持續計時器
- 二、TCP擁塞控制
- 2.1、擁塞控制的指標
- 2.2、慢開始算法和擁塞避免算法
- 2.3、快重傳算法和快恢復算法
- 2.4、練習
- 三、TCP擁塞控制與網際層擁塞控制
- 總結
前言
??TCP協議中的流量和擁塞,是兩個關鍵的控制指標,兩者的側重點也是不一樣的:
- 流量控制:側重于控制點對點通信中發送方與接收方的流量,保證發送方的發送速率不高于接收方的接收速率,避免接收方的緩存溢出。
- 擁塞控制:側重于控制全局網絡中的主機,路由器,按照擁塞控制算法,自行控制發送速率。防止過多的數據注入到網絡中,使網絡可以承受現有的負荷。
一、TCP流量控制
??流量控制的目的,是為了避免發送方的發送速率高于接收方的接收速率,具體是接收方根據自己的接收能力,控制發送方的發送速率。
??控制手段則是通過發送方的發送窗口swnd(s:send)和接收方的接收窗口rwnd(r:receive)。
1.1、案例:三次流量控制
??TCP流量控制的過程,假設我有A和B兩臺主機,A是發送方,B是接收方。那么在建立連接時,B應該通知A,自己的接收窗口是多少,A相應地將自己的發送窗口也設置相同的大小:

??A發送出第一個報文段,對應的是1-100:

??A發送出第二個報文段,對應的是101-200:

??發送第三個報文段,丟失:

??主機B給主機A發送累計確認報文段,對seq為201之前的數據進行累計確認

??在累計確認的同時,接收方通知發送方,自己的rwnd大小發生了變更,則發送方在將自己發送數據的滑動窗口向前滑動時,也要將自己的swnd同步變更,當前的rwnd和滑動窗口如圖所示,這是第一次流量控制的體現

??隨后發送301~500的數據。

??201到300的重傳計時器超時了,主機A將其重新封裝成一個TCP報文段進行發送,主機B發送一個確認報文段,同時調整自身的接收窗口為100:

??這是第二次流量控制的體現

??最后發送501~600的數據,并且接收方進行確認,并進行最后一次流量控制,將rwnd設置為0,表示不再接受數據,有可能是因為接收方的緩存區已滿。

??上述的過程,就是一次完整的流量控制。
1.2、持續計時器
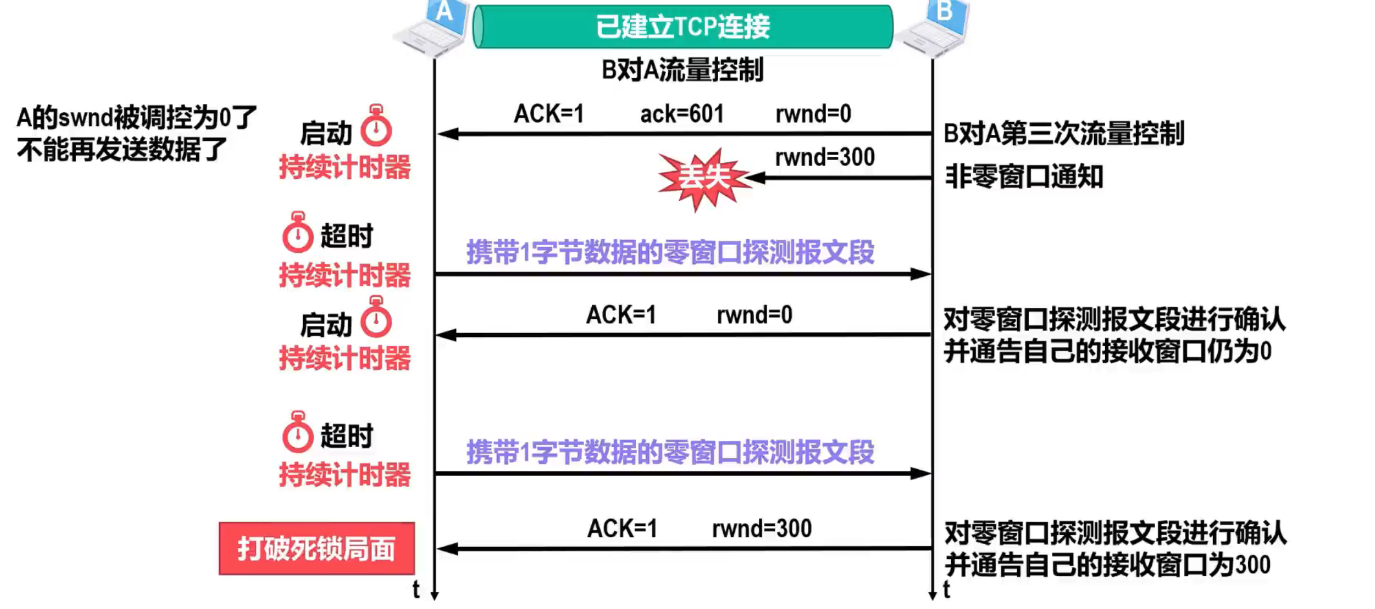
??接著上面的案例,假設最后一次流量控制之后,接收方B處理完成了數據,緩存區又有了空間,準備繼續接收發送方A的數據,這時B需要再次對A進行流量控制,將自身的rwnd調整至300:

??但是消息在發送的過程中丟失了,那么就會出現A一直等待B的非零窗口通知,B一直等待A發送消息,造成通信死鎖的情況。
??為了解決這樣的問題,TCP給每一個連接都設置了一個持續計時器,并且規定,即使接收窗口值為0,也必須接受零窗口探測報文段,確認報文段以及攜帶有緊急數據的報文段:

二、TCP擁塞控制
??網絡擁塞問題是指網絡中傳輸的數據過多,超過了網絡設備(如路由器、交換機)或鏈路的處理能力,導致網絡性能下降的現象。就像高峰期的馬路:
- 如果車(數據包)太多,馬路(網絡)就會堵;
- 堵車后,不僅原來開的慢,新車也進不來;
- 嚴重時還可能發生車輛回退(丟包)、繞路(重傳)甚至“交通癱瘓”(網絡崩潰)。
??如果不加以控制,導致的就是整個網絡的崩潰,類似于微服務的雪崩。

??擁塞控制的基本方法,分為開環控制和閉環控制:
- 開環控制側重于從設計的角度避免出現擁塞的問題,前提是要提前知道進行控制的網絡的參數和流量。
- 閉環控制側重于從運行時的角度避免擁塞的問題,即對于網絡進行監控,及時接受反饋并且調整。

??閉環控制,又可以分為顯式控制算法和隱式控制算法:
- 顯式控制算法指的是,路由器向源點反饋網絡的擁塞狀態,即路由器擁塞,丟棄IP數據報,并且通知源站,通知同樣需要利用網絡通信,通知的行為,可能會造成網絡更加擁堵。可以在路由器的轉發分組中,保留一個字段,該字段的值表示網絡的擁塞狀態。
- 隱式控制算法指的是,源站點自己對網絡的指標進行觀察,判斷網絡是否發生擁塞。TCP使用的就是隱式控制算法。

2.1、擁塞控制的指標
??對于發送方而言,指標有發送窗口swnd(s:send),擁塞窗口cwnd(c:crowded),對于接收方而言,指標有接收窗口rwnd(r:reveive)
??只有序號落入swnd的數據,發送方才可以進行發送,swnd的取值,是cwnd和rwnd的最小值。
??rwnd用于控制流量,cwnd用于控制擁塞


2.2、慢開始算法和擁塞避免算法
??慢開始算法和擁塞避免算法,通常配合使用,這里加入了一個ssthresh慢開始門限的指標:

??使用慢開始算法和擁塞避免算法組合時,首先運用的是慢開始算法,將cwnd進行逐次指數累加,直到到達ssthresh的值:

??然后改用擁塞避免算法,每個輪次cwnd的值只能 + 1,而不像慢開始算法,可以指數增長,當發生了重傳和報文段丟失的情況,說明網絡中出現了擁塞,就需要調整擁塞窗口cwnd和ssthresh的值,然后重新執行慢開始算法。
- ssthresh的值調整為發生擁塞時,擁塞窗口cwnd值的一半。
- cwnd的值重置為1。

??最終的曲線如下:

2.3、快重傳算法和快恢復算法
??快重傳算法和快恢復算法是對于慢開始算法和擁塞避免算法的改進。因為后者可能會存在一個問題,也就是如果路由器是因為請求出現了誤碼,才將其丟棄**(非網絡出現擁塞)**,源站是無法判斷這種情況的,會將cwnd的值重置為1重新開始,降低了效率。
??快重傳算法的目的是讓發送方盡快知道TCP報文段的丟失,從而盡快地進行重新傳輸,就要求接收方在收到消息后,立刻進行ack。

??如下圖,如果TCP沒有接收到3號報文段,就會在后續報文段到達時,**發送對未收到報文段的重復確認。**當發送方接收到3次重復確認后,就對丟失的報文進行立刻重傳(接收方在接收到M4后,發現M3并沒有接收到,于是重復確認M2,重復確認M2到達3次后,發送方立刻重傳M2)

??當發送方接收到3次重復確認后,同時也會執行快恢復算法 + 擁塞避免算法:
- ssthresh的值調整為cwnd值的一半。
- cwnd的值調整為cwnd值的一半。

??最終的曲線如下圖:


2.4、練習

??這道題的答案是C。擁塞窗口為16KB時發生了超時,那么此時的指標:
- ssthresh:16/2 = 8
- cwnd:1
??然后重新使用慢開始算法:
| RTT | cwnd |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 8(到達了ssthresh,轉換為擁塞避免算法) |
| 4 | 8 + 1 = 9 |

??這道題的答案是A。同樣地,擁塞窗口為8KB時發生了超時,那么此時的指標:
- ssthresh:8/2 = 4
- cwnd:1
??然后重新使用慢開始算法:
| RTT | cwnd |
|---|---|
| 1 | 2 |
| 2 | 4(到達了ssthresh,轉換為擁塞避免算法) |
| 3 | 5 |
| 4 | 6 |
| 5 | 7 |
| … | … |
| 10 | 12 |
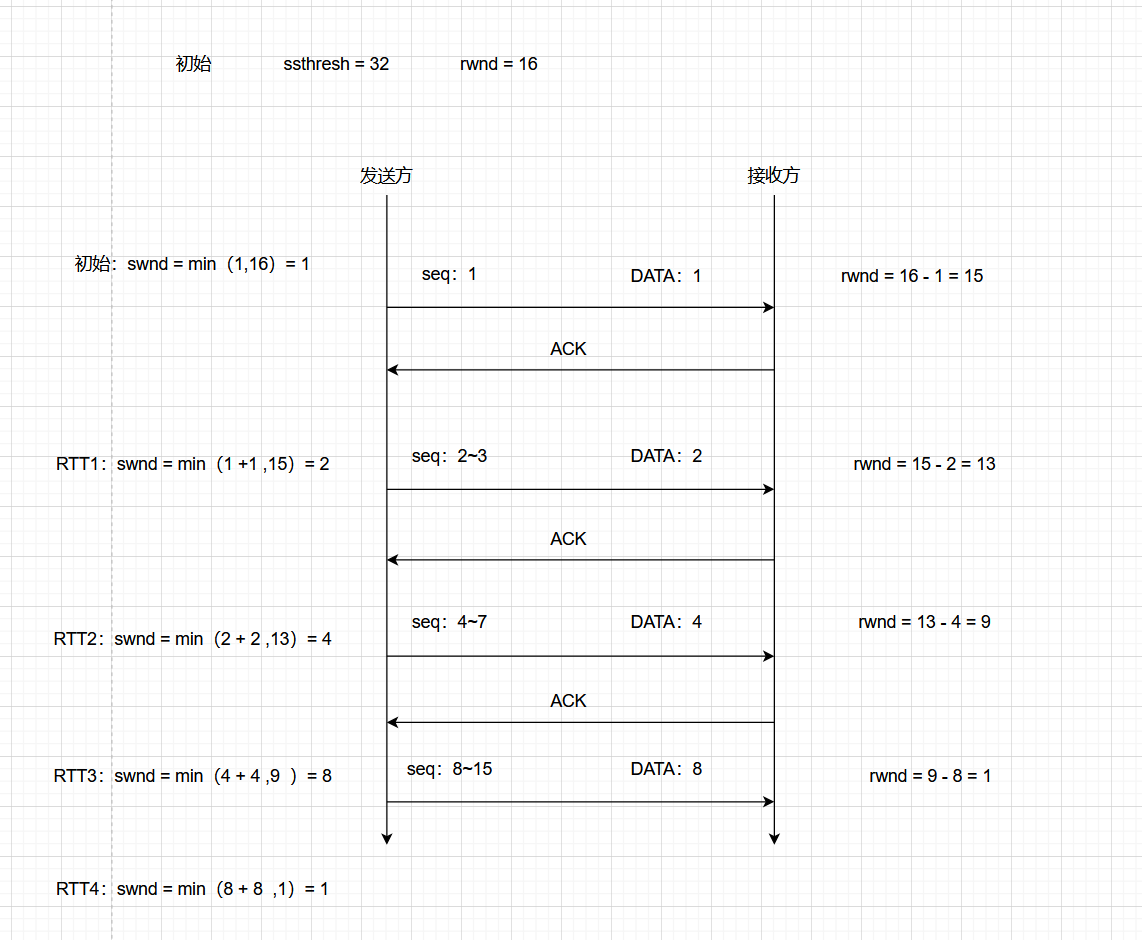
??這一題比上一題多了一個考察點,發送窗口swnd 是 rwnd 和 cwnd 的較小值。 min(12,10)= 10。

??這道題的答案選A:
三、TCP擁塞控制與網際層擁塞控制
??與運輸層TCP擁塞控制相關的,是網際層路由器對于IP數據報的丟棄策略。由于路由器的緩存隊列是標準的“先進先出”的結構,隊列已滿,則會丟棄最后的元素。
??當多個發送行為觸發尾部丟棄時,這些發送方都會進入慢開始狀態,稱為全局同步,會導致同一時刻網絡流量的驟降,以及之后的持續增高。
??為了避免這樣的問題,提出了主動隊列管理的概念,其核心思想在于避免出現路由器緩存隊列已滿的情況,當隊列長度達到某個閾值時,就觸發丟棄策略:


總結








)







-IDEA集成調試配置)



)