研究背景與意義
研究背景與意義
隨著城市化進程的加快,路邊廣告牌作為重要的商業宣傳媒介,越來越多地出現在城市的各個角落。它們不僅承擔著信息傳播的功能,還對城市的視覺環境產生了深遠的影響。然而,隨著廣告牌數量的激增,如何有效地管理和分析這些廣告牌,成為了城市管理者和廣告商面臨的一大挑戰。傳統的人工監測和管理方式效率低下,難以滿足日益增長的需求。因此,開發一種基于計算機視覺的自動化實例分割系統,能夠精準識別和分析路邊廣告牌,顯得尤為重要。
本研究旨在基于改進的YOLOv11模型,構建一個高效的路邊廣告牌實例分割系統。YOLO(You Only Look Once)系列模型因其實時性和高精度而廣泛應用于目標檢測領域。通過對YOLOv11進行改進,我們期望在提高檢測精度的同時,提升模型對復雜場景的適應能力。為此,我們將利用一個包含2100張圖像的多類別數據集,該數據集包含三類廣告牌(T1、T2、T3),并已進行YOLO格式的標注。這一數據集的構建為模型的訓練和驗證提供了堅實的基礎。
此外,實例分割技術的應用將使得廣告牌的邊界更加清晰,能夠有效區分不同類別的廣告牌,從而為后續的分析和決策提供更為準確的數據支持。通過對廣告牌的自動識別與分類,城市管理者可以實時掌握廣告牌的分布情況,優化廣告資源的配置,提升城市的整體形象。同時,廣告商也能借助這一系統,分析廣告牌的投放效果,制定更為精準的市場策略。
綜上所述,基于改進YOLOv11的路邊廣告牌實例分割系統,不僅具有重要的學術價值,還有著廣泛的應用前景,能夠為城市管理和商業決策提供有力支持。
圖片演示
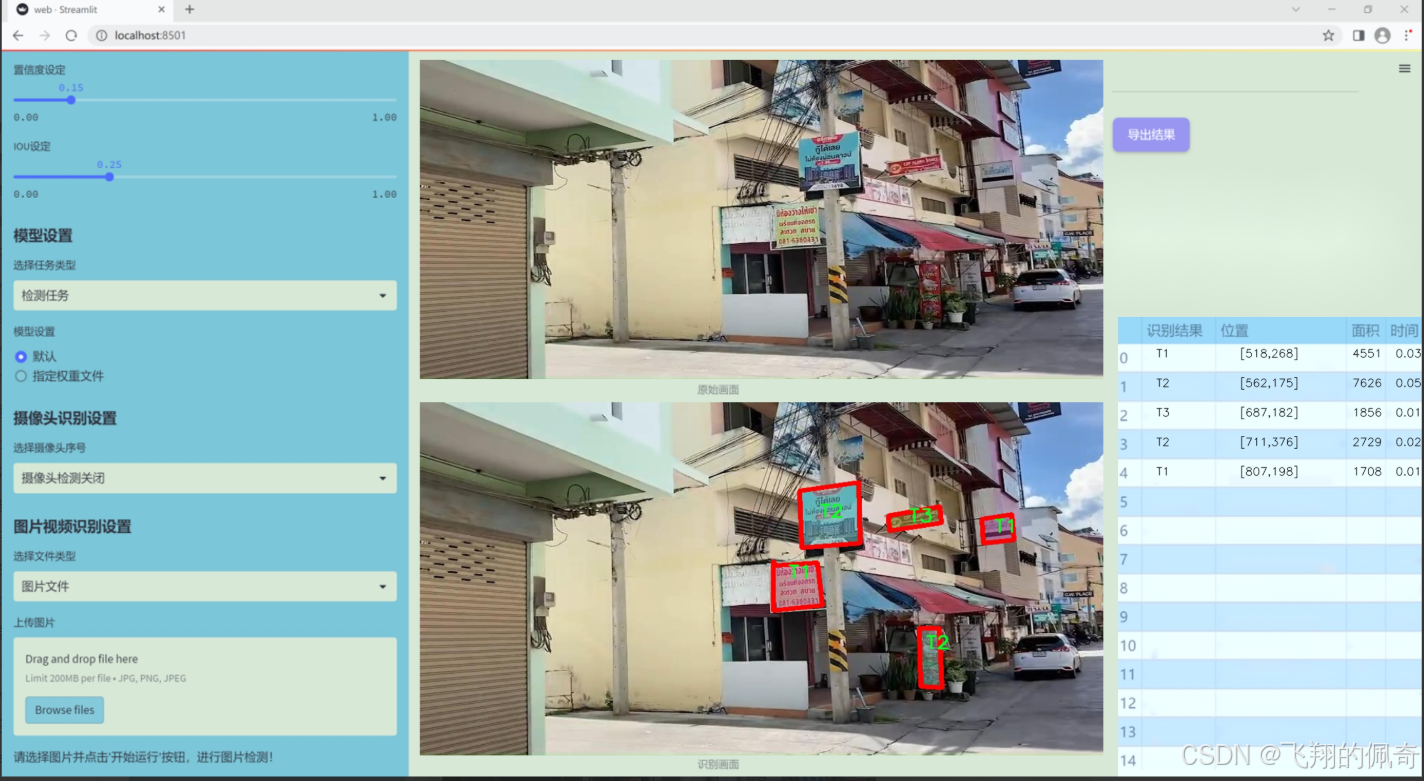
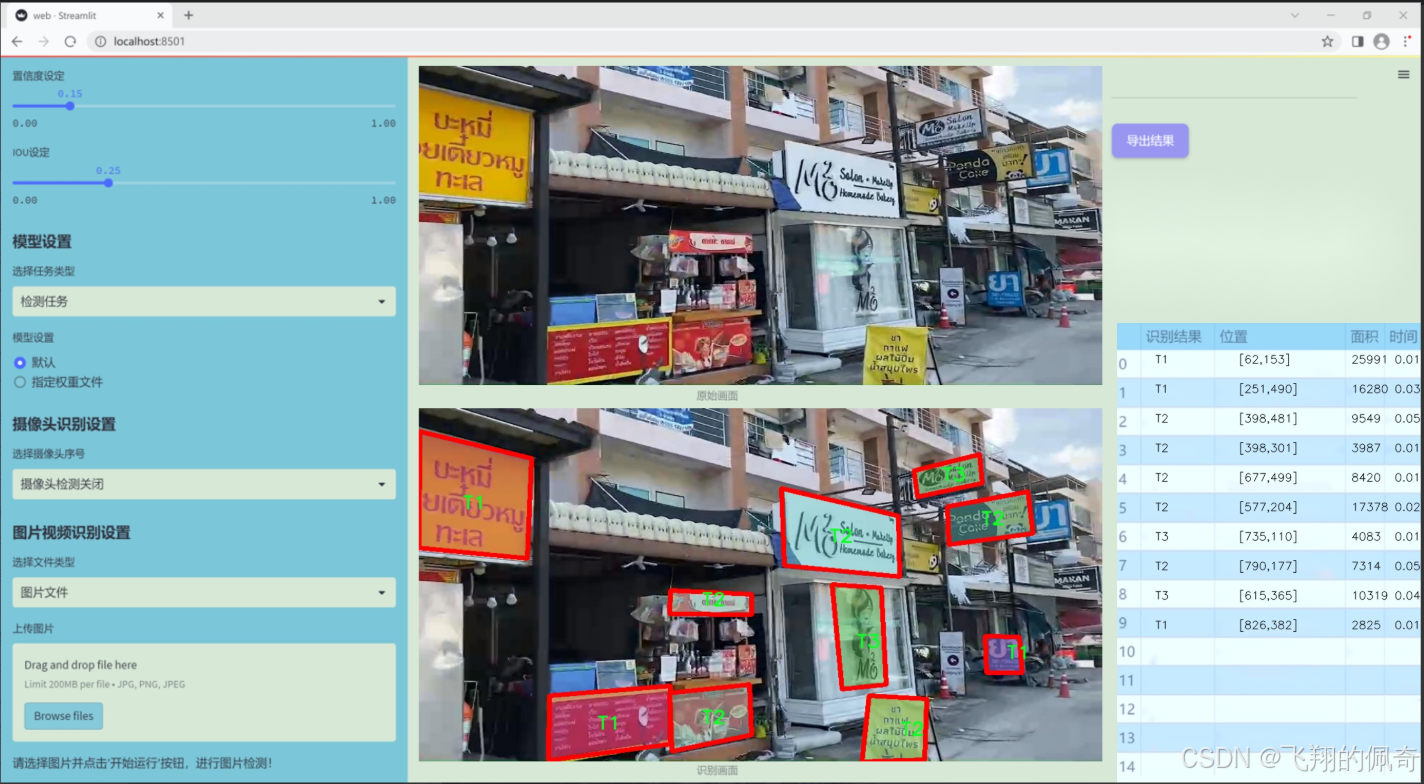
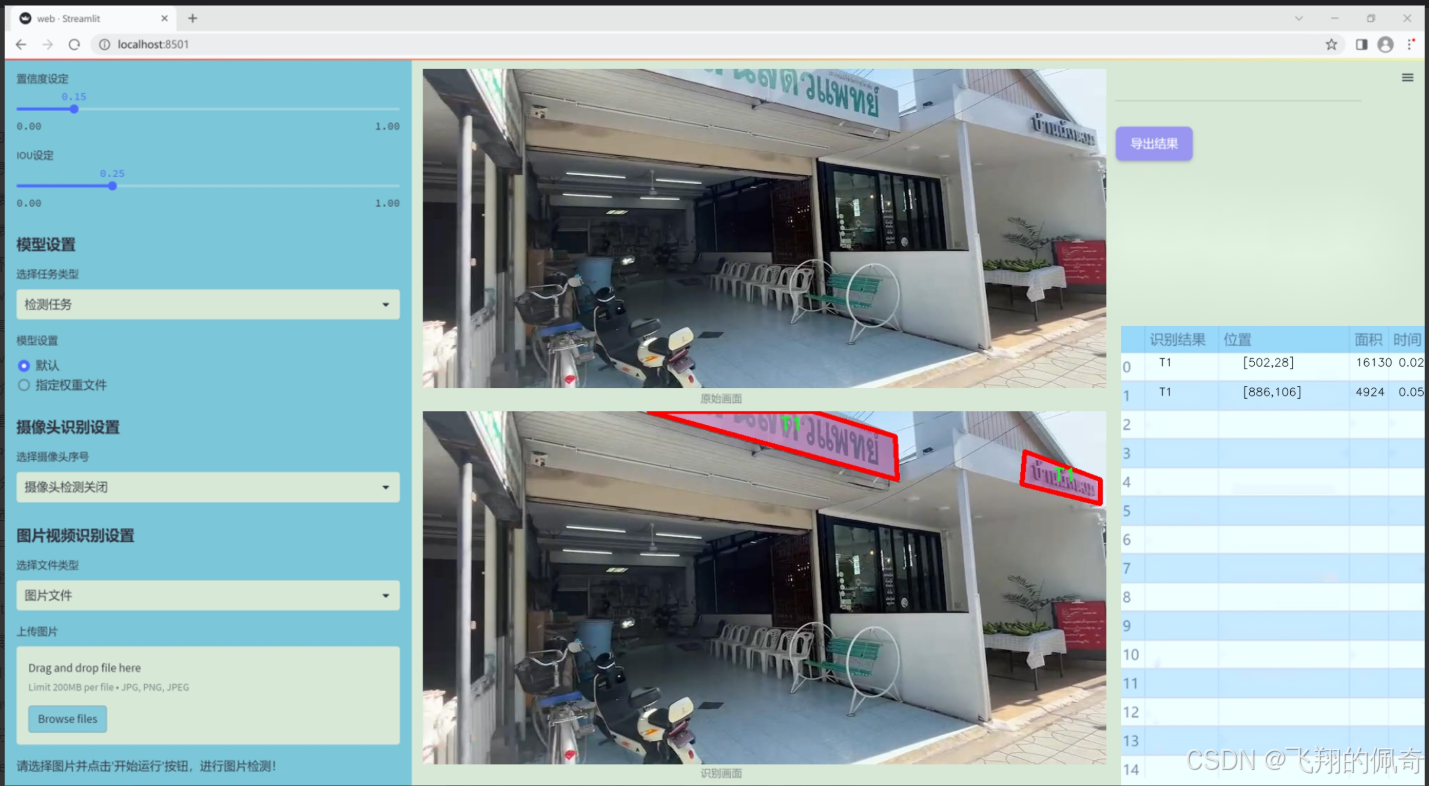
數據集信息展示
本項目數據集信息介紹
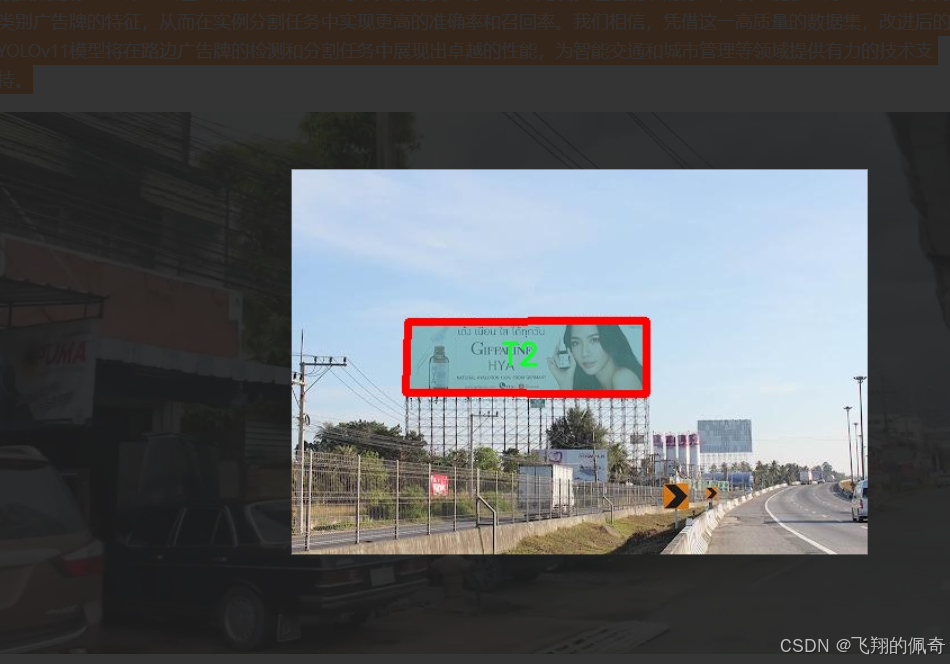
本項目旨在改進YOLOv11的路邊廣告牌實例分割系統,所使用的數據集專注于“Sign”主題,涵蓋了與路邊廣告牌相關的多種實例。該數據集包含三種主要類別,分別為T1、T2和T3,這些類別代表了不同類型的廣告牌和標識,能夠有效地為模型的訓練提供多樣化的樣本。這種多樣性不僅有助于提高模型的泛化能力,還能增強其在實際應用中的表現。
在數據集的構建過程中,我們注重了樣本的多樣性和代表性,確保涵蓋了各種不同的環境和光照條件下的廣告牌實例。這些實例包括城市街道、鄉村道路以及商業區等多種場景,力求在訓練過程中模擬真實世界中的各種情況。此外,為了提高數據集的實用性,我們還進行了數據增強處理,包括旋轉、縮放、裁剪等操作,以生成更多的訓練樣本,從而提升模型的魯棒性。
數據集的標注工作也經過嚴格的審核,確保每個實例的類別標注準確無誤。通過精確的標注,模型能夠更好地學習到不同類別廣告牌的特征,從而在實例分割任務中實現更高的準確率和召回率。我們相信,憑借這一高質量的數據集,改進后的YOLOv11模型將在路邊廣告牌的檢測和分割任務中展現出卓越的性能,為智能交通和城市管理等領域提供有力的技術支持。




項目核心源碼講解(再也不用擔心看不懂代碼邏輯)
以下是保留的核心代碼部分,并附上詳細的中文注釋:
import torch
import torch.nn as nn
from einops import rearrange
class LayerNorm2d(nn.Module):
“”“自定義的二維層歸一化模塊”“”
def __init__(self, normalized_shape, eps=1e-6, elementwise_affine=True):super().__init__()# 使用 PyTorch 的 LayerNorm 進行歸一化self.norm = nn.LayerNorm(normalized_shape, eps, elementwise_affine)def forward(self, x):# 將輸入的形狀從 (B, C, H, W) 轉換為 (B, H, W, C)x = rearrange(x, 'b c h w -> b h w c').contiguous()# 進行歸一化x = self.norm(x)# 將形狀轉換回 (B, C, H, W)x = rearrange(x, 'b h w c -> b c h w').contiguous()return x
class CrossScan(torch.autograd.Function):
“”“交叉掃描操作的自定義函數”“”
@staticmethod
def forward(ctx, x: torch.Tensor):B, C, H, W = x.shapectx.shape = (B, C, H, W)# 創建一個新的張量,用于存儲交叉掃描的結果xs = x.new_empty((B, 4, C, H * W))# 第一部分:直接展平xs[:, 0] = x.flatten(2, 3)# 第二部分:轉置后展平xs[:, 1] = x.transpose(dim0=2, dim1=3).flatten(2, 3)# 第三和第四部分:翻轉前兩部分xs[:, 2:4] = torch.flip(xs[:, 0:2], dims=[-1])return xs@staticmethod
def backward(ctx, ys: torch.Tensor):B, C, H, W = ctx.shapeL = H * W# 反向傳播時,合并計算梯度ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L)y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, -1, L)return y.view(B, -1, H, W)
class SS2D(nn.Module):
“”“自定義的二維選擇性掃描模塊”“”
def __init__(self, d_model=96, d_state=16, ssm_ratio=2.0, dropout=0.0):super().__init__()self.in_proj = nn.Conv2d(d_model, d_model * ssm_ratio, kernel_size=1) # 輸入投影self.out_proj = nn.Conv2d(d_model * ssm_ratio, d_model, kernel_size=1) # 輸出投影self.dropout = nn.Dropout(dropout) # Dropout 層def forward(self, x: torch.Tensor):x = self.in_proj(x) # 進行輸入投影# 這里可以插入選擇性掃描的邏輯x = self.dropout(x) # 應用 Dropoutx = self.out_proj(x) # 進行輸出投影return x
class VSSBlock_YOLO(nn.Module):
“”“YOLO中的自定義塊”“”
def __init__(self, in_channels: int, hidden_dim: int, drop_path: float = 0):super().__init__()self.proj_conv = nn.Conv2d(in_channels, hidden_dim, kernel_size=1) # 投影卷積self.ss2d = SS2D(d_model=hidden_dim) # 選擇性掃描模塊self.drop_path = nn.Dropout(drop_path) # DropPath 層def forward(self, input: torch.Tensor):input = self.proj_conv(input) # 進行投影x = self.ss2d(input) # 進行選擇性掃描x = self.drop_path(x) # 應用 DropPathreturn x
代碼注釋說明:
LayerNorm2d: 自定義的二維層歸一化模塊,主要用于對輸入的特征圖進行歸一化處理,以提高模型的訓練穩定性。
CrossScan: 自定義的交叉掃描操作,包含前向和反向傳播的實現。前向傳播中對輸入進行展平和轉置操作,反向傳播中計算梯度。
SS2D: 自定義的二維選擇性掃描模塊,包含輸入和輸出的卷積投影,以及 Dropout 層,用于防止過擬合。
VSSBlock_YOLO: YOLO網絡中的自定義塊,包含輸入的投影卷積和選擇性掃描模塊的組合,最后應用 DropPath。
這些核心部分是實現選擇性掃描和特征處理的基礎,能夠有效地進行特征提取和信息融合。
這個程序文件 mamba_yolo.py 實現了一個基于深度學習的模型,主要用于計算機視覺任務,特別是目標檢測。文件中包含多個類和函數,主要功能是構建一個復雜的神經網絡架構。以下是對代碼的詳細說明。
首先,導入了一些必要的庫,包括 torch 和 torch.nn,這些是構建深度學習模型的基礎庫。還使用了 einops 庫來進行張量的重排和重復操作,以及 timm 庫中的 DropPath 層用于實現隨機深度的特性。
接下來,定義了一個 LayerNorm2d 類,這是一個二維層歸一化的實現,適用于圖像數據。它通過調整輸入的維度順序來應用 LayerNorm,確保在通道維度上進行歸一化。
autopad 函數用于自動計算卷積操作的填充,以確保輸出的形狀與輸入相同,方便后續的層連接。
接下來定義了幾個重要的自定義操作,包括 CrossScan 和 CrossMerge,它們實現了特定的張量操作,主要用于在網絡中進行信息的交叉掃描和合并。這些操作通過 PyTorch 的自定義 autograd 功能實現,能夠在前向和反向傳播中高效計算。
SelectiveScanCore 類實現了選擇性掃描的核心功能,允許在特定條件下對輸入進行選擇性處理。這個類的前向和反向方法都使用了 CUDA 加速,以提高計算效率。
cross_selective_scan 函數是一個高層次的接口,結合了前面定義的操作,處理輸入張量并應用選擇性掃描,返回處理后的輸出。
接下來是 SS2D 類,它實現了一個基于選擇性掃描的二維神經網絡模塊。這個模塊包括輸入投影、卷積層、選擇性掃描操作和輸出投影。它的設計允許在不同的配置下靈活使用,支持多種前向傳播方式。
RGBlock 和 LSBlock 類實現了特定的塊結構,分別用于處理輸入特征并進行非線性變換。它們通過卷積層和激活函數組合,形成深度學習中的基本構建塊。
XSSBlock 和 VSSBlock_YOLO 類是更復雜的模塊,結合了前面定義的所有組件,形成了一個完整的網絡層。它們支持多種配置選項,允許用戶根據需求調整模型的結構和參數。
SimpleStem 類是網絡的起始部分,負責將輸入圖像轉換為適合后續處理的特征表示。它通過一系列卷積和歸一化層來實現。
最后,VisionClueMerge 類用于合并特征圖,通常在多尺度特征融合的場景中使用。
整體來看,這個文件實現了一個復雜的深度學習模型,具有高度的模塊化和靈活性,適合用于計算機視覺任務,尤其是目標檢測。通過使用選擇性掃描和自定義的張量操作,模型能夠有效地處理輸入數據并提取有用的特征。
10.4 afpn.py
以下是經過簡化和注釋的核心代碼部分,主要保留了模型的結構和關鍵功能。
import torch
import torch.nn as nn
import torch.nn.functional as F
from …modules.conv import Conv
定義基本的卷積塊
class BasicBlock(nn.Module):
def init(self, filter_in, filter_out):
super(BasicBlock, self).init()
# 兩個卷積層
self.conv1 = Conv(filter_in, filter_out, 3)
self.conv2 = Conv(filter_out, filter_out, 3, act=False)
def forward(self, x):residual = x # 保存輸入用于殘差連接out = self.conv1(x) # 第一個卷積out = self.conv2(out) # 第二個卷積out += residual # 殘差連接return self.conv1.act(out) # 返回激活后的輸出
定義上采樣模塊
class Upsample(nn.Module):
def init(self, in_channels, out_channels, scale_factor=2):
super(Upsample, self).init()
# 使用1x1卷積和雙線性插值進行上采樣
self.upsample = nn.Sequential(
Conv(in_channels, out_channels, 1),
nn.Upsample(scale_factor=scale_factor, mode=‘bilinear’)
)
def forward(self, x):return self.upsample(x) # 執行上采樣
定義下采樣模塊
class Downsample_x2(nn.Module):
def init(self, in_channels, out_channels):
super(Downsample_x2, self).init()
# 使用2x2卷積進行下采樣
self.downsample = Conv(in_channels, out_channels, 2, 2, 0)
def forward(self, x):return self.downsample(x) # 執行下采樣
自適應特征融合模塊
class ASFF_2(nn.Module):
def init(self, inter_dim=512):
super(ASFF_2, self).init()
compress_c = 8 # 壓縮通道數
# 定義權重卷積層
self.weight_level_1 = Conv(inter_dim, compress_c, 1)
self.weight_level_2 = Conv(inter_dim, compress_c, 1)
self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1) # 計算融合權重
self.conv = Conv(inter_dim, inter_dim, 3) # 最后的卷積層
def forward(self, input1, input2):# 計算每個輸入的權重level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1) # 拼接權重levels_weight = self.weight_levels(levels_weight_v) # 計算最終權重levels_weight = F.softmax(levels_weight, dim=1) # 歸一化權重# 根據權重融合輸入fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + input2 * levels_weight[:, 1:2, :, :]out = self.conv(fused_out_reduced) # 最后的卷積return out
定義特征金字塔網絡(FPN)模塊
class AFPN_P345(nn.Module):
def init(self, in_channels=[256, 512, 1024], out_channels=256, factor=4):
super(AFPN_P345, self).init()
# 輸入通道的卷積層
self.conv0 = Conv(in_channels[0], in_channels[0] // factor, 1)
self.conv1 = Conv(in_channels[1], in_channels[1] // factor, 1)
self.conv2 = Conv(in_channels[2], in_channels[2] // factor, 1)
# 定義特征融合的主體self.body = BlockBody_P345([in_channels[0] // factor, in_channels[1] // factor, in_channels[2] // factor])# 輸出通道的卷積層self.conv00 = Conv(in_channels[0] // factor, out_channels, 1)self.conv11 = Conv(in_channels[1] // factor, out_channels, 1)self.conv22 = Conv(in_channels[2] // factor, out_channels, 1)def forward(self, x):x0, x1, x2 = x # 輸入特征圖x0 = self.conv0(x0) # 卷積處理x1 = self.conv1(x1)x2 = self.conv2(x2)out0, out1, out2 = self.body([x0, x1, x2]) # 特征融合out0 = self.conv00(out0) # 輸出處理out1 = self.conv11(out1)out2 = self.conv22(out2)return [out0, out1, out2] # 返回輸出特征圖
代碼注釋說明
BasicBlock: 定義了一個基本的卷積塊,包含兩個卷積層和殘差連接。
Upsample/Downsample: 定義了上采樣和下采樣模塊,分別使用卷積和插值方法調整特征圖的尺寸。
ASFF_2: 自適應特征融合模塊,通過計算輸入特征的權重進行融合。
AFPN_P345: 特征金字塔網絡的核心模塊,處理輸入特征圖并輸出融合后的特征圖。
這些模塊可以組合成更復雜的網絡結構,適用于圖像處理和計算機視覺任務。
這個程序文件afpn.py實現了一種特征金字塔網絡(AFPN),用于計算機視覺任務中的特征提取和融合。該文件主要包含多個類,每個類實現了特定的功能,整體上構成了一個復雜的神經網絡結構。
首先,文件引入了一些必要的庫,包括torch和torch.nn,這些是PyTorch框架的核心模塊,用于構建和訓練神經網絡。OrderedDict用于有序字典的操作,可能在某些模塊中使用。
接下來,定義了多個類,其中BasicBlock類實現了一個基本的卷積塊,包含兩個卷積層和殘差連接。Upsample和Downsample_x2等類用于實現上采樣和下采樣操作,分別通過卷積和插值方法調整特征圖的尺寸。
ASFF_2、ASFF_3和ASFF_4類實現了自適應特征融合模塊,能夠根據輸入特征圖的權重進行加權融合。這些模塊的設計允許網絡在不同尺度上靈活地整合特征,從而提高特征表達能力。
BlockBody_P345和BlockBody_P2345類是網絡的主體部分,分別處理不同數量的輸入特征圖。它們通過多層卷積塊和自適應特征融合模塊構建了一個深度網絡結構。每個塊都包含多個卷積層和下采樣、上采樣操作,以便在不同尺度上提取和融合特征。
AFPN_P345和AFPN_P2345類是特征金字塔網絡的具體實現,分別接收3個和4個輸入通道的特征圖。它們通過初始化卷積層和主體塊,將輸入特征圖進行處理,最終輸出經過處理的特征圖。AFPN_P345_Custom和AFPN_P2345_Custom類則允許用戶自定義塊的類型,以便在特定任務中使用不同的網絡結構。
最后,文件中還包含了對卷積層和批歸一化層的權重初始化,以確保網絡在訓練初期的穩定性和收斂速度。
總體而言,這個文件實現了一個靈活且強大的特征金字塔網絡,適用于各種計算機視覺任務,如目標檢測和圖像分割等。通過不同的模塊組合和自適應特征融合,網絡能夠有效地提取和利用多尺度特征信息。
源碼文件

源碼獲取
歡迎大家點贊、收藏、關注、評論啦 、查看👇🏻獲取聯系方式👇🏻




)







)
)
(二十一)——unordered_set和unordered_map)




