ElasticSearch
簡介:ElasticSearch簡稱ES是一個開源的分布式搜素和數據分析引擎。是使用Java開發并且是當前最流行的開源的企業級搜索引擎,能夠達到近實時搜索,它專門設計用于處理大規模的文本數據和實現高性能的全文搜索。它基于 Apache Lucene 構建,專為處理海量數據而設計。它支持全文搜索、結構化查詢、數據分析,并廣泛應用于日志管理(如 ELK Stack)、電商搜索、實時監控等場景。

基本概念
| 術語 | 說明 |
|---|---|
| 索引(Index) | 類似數據庫中的“表”,存儲相關文檔(如 user_index)。 |
| 文檔(Document) | 索引中的基本數據單元,格式為 JSON(如一條用戶信息)。 |
| 分片(Shard) | 索引被分割成的子部分,支持分布式存儲和并行計算。 |
| 節點(Node) | 一個運行中的 Elasticsearch 實例,多個節點組成集群(Cluster)。 |
ELK技術棧
Elasticsearch結合Kibana、Logstash、Beats,也就是elastic stack(ELK)。被廣泛應用在日志數據分析,實時監控等領域:

核心組件
| 組件 | 功能 | 配圖示意(文字描述) |
|---|---|---|
| Logstash、Beats | 數據采集與處理:從多種來源(如日志文件、數據庫)收集數據,過濾并格式化后傳輸到 Elasticsearch。 | [輸入] → Logstash(過濾/轉換) → [輸出] |
| Elasticsearch | 數據存儲與檢索:分布式存儲處理后的數據,支持快速搜索和分析。 | [數據存儲] → Elasticsearch(索引/分片) |
| Kibana | 數據可視化:通過圖表、儀表盤展示 Elasticsearch 中的數據。 | Kibana ← [查詢] → Elasticsearch |
總結:ELK 技術棧通過 Logstash/Beats(采集)→ Elasticsearch(存儲)→ Kibana(可視化) 實現數據全生命周期管理,適用于日志分析、運維監控等場景。學習時需掌握各組件配置和協同工作原理。
Elasticsearch和lucene之間的關系
說的專業一點:Elasticsearch 基于 Apache Lucene(高性能全文檢索引擎庫)構建,核心的索引和搜索功能由 Lucene 實現。
說的通俗一點:Lucene 是“發動機”,專注單機性能;Elasticsearch 是“整車”,集成發動機并添加了方向盤、底盤(分布式、易用性)
總結:Elasticsearch = Lucene + 分布式 + 易用接口 + 高級功能(如聚合、近實時搜索)。
索引
兩個基本概念:
文檔(Document):文檔是 Elasticsearch 中 最小的數據存儲單元,類似于 Excel 表格中的一行數據,但更靈活。
詞條(Term):詞條是文檔內容經過 分詞處理 后的最小單位,是搜索引擎操作的基本元素。
文檔與詞條的關系:
| 維度 | 文檔(Document) | 詞條(Term) |
|---|---|---|
| 角色 | 數據存儲的基本單位(“完整信息包”) | 搜索的基本單位(“信息碎片”) |
| 存儲方式 | 原始 JSON 格式,保存在索引(Index)中 | 分詞后存儲在反向索引(Inverted Index)中 |
| 操作目標 | 用于增刪改查完整數據 | 用于快速檢索和匹配內容 |
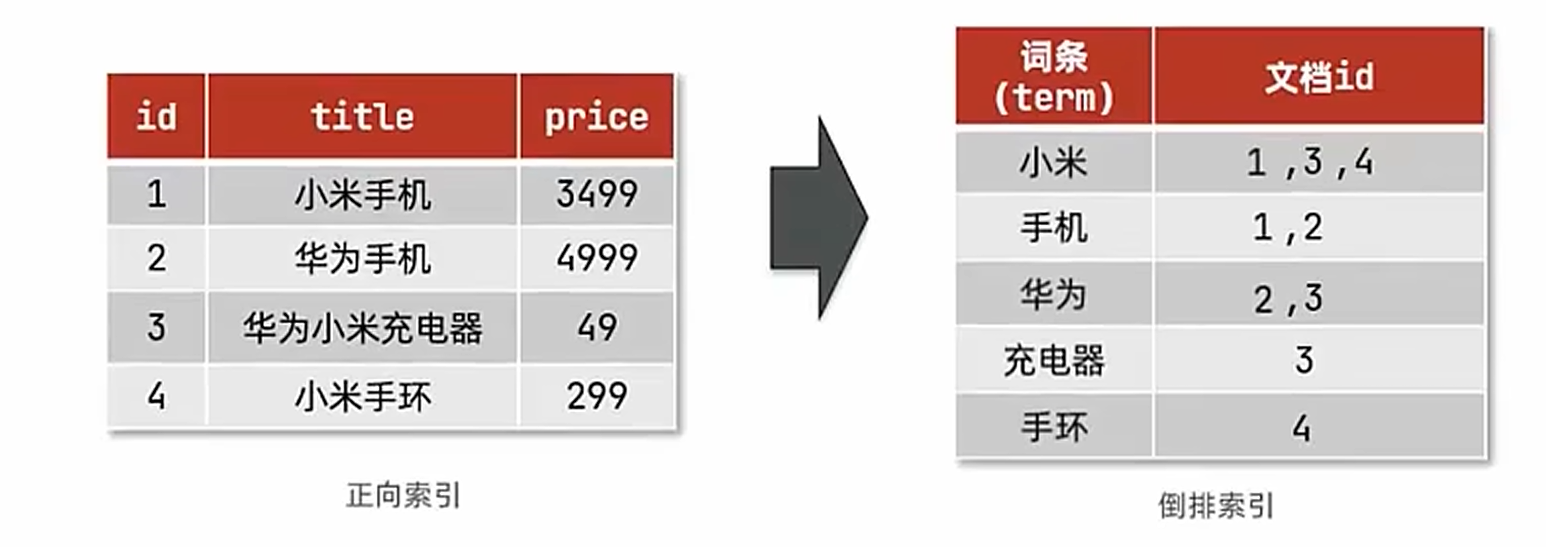
正向索引:正向索引是 以文檔為中心 的索引結構,記錄每個文檔包含哪些關鍵詞(類似書的目錄,告訴你每本書里有什么內容)。
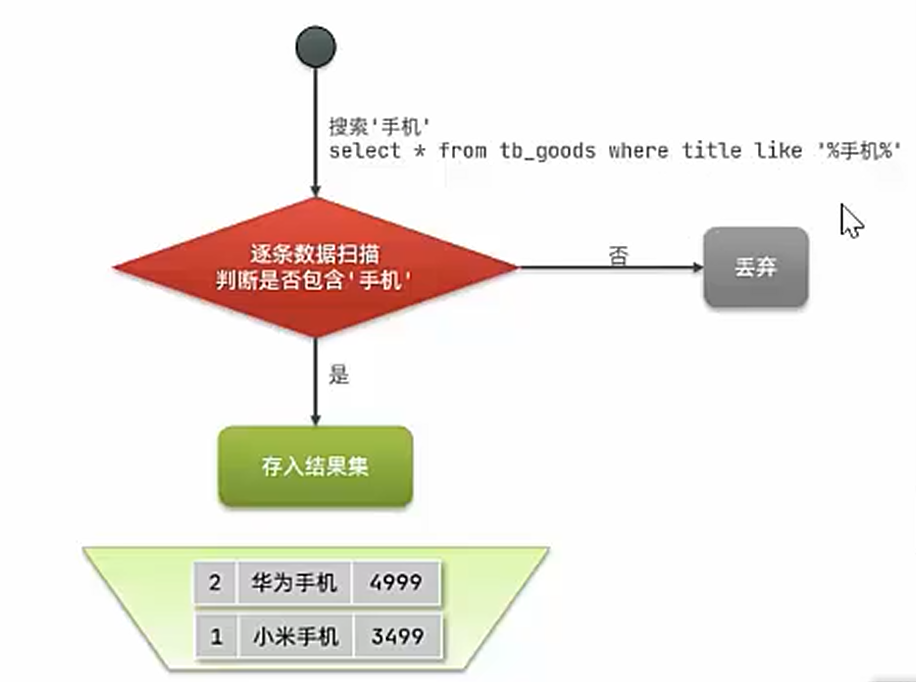
反向索引:反向索引是 以關鍵詞為核心 的索引結構,記錄每個關鍵詞出現在哪些文檔中(類似詞典的索引頁,告訴你哪個詞在哪本書出現)。
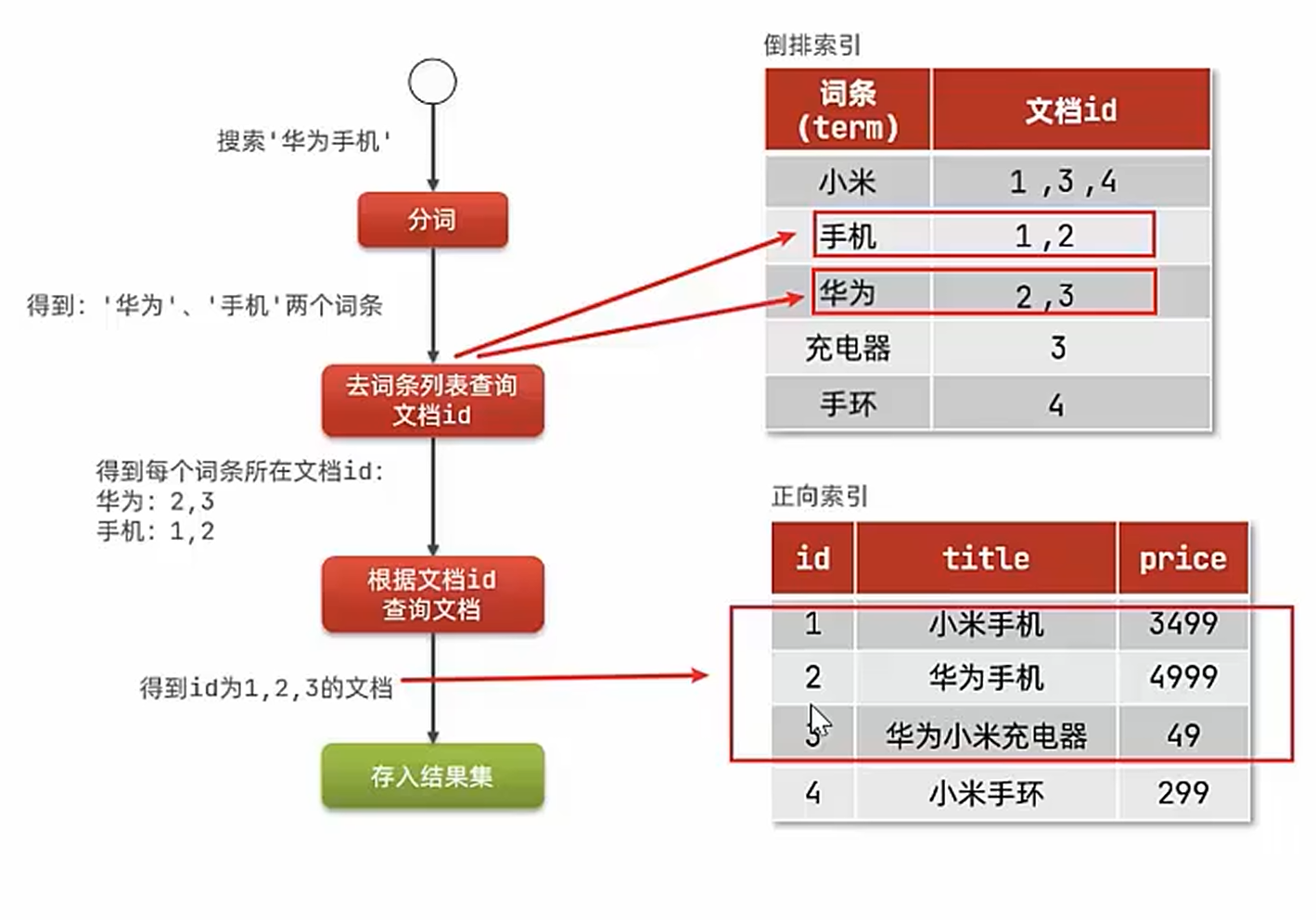
正向索引VS反向索引
| 正向索引 | 反向索引 | |
|---|---|---|
| 核心邏輯 | 文檔→關鍵詞(書→內容) | 關鍵詞→文檔(詞典→書頁) |
| 搜索效率 | 慢(需遍歷所有文檔) | 快(直接查關鍵詞對應的文檔) |
| 存儲空間 | 較小 | 較大(需存儲詞頻、位置等額外信息) |
| 典型應用 | 早期搜索引擎、小規模系統 | 現代搜索引擎(Google/Bing)、大數據系統 |
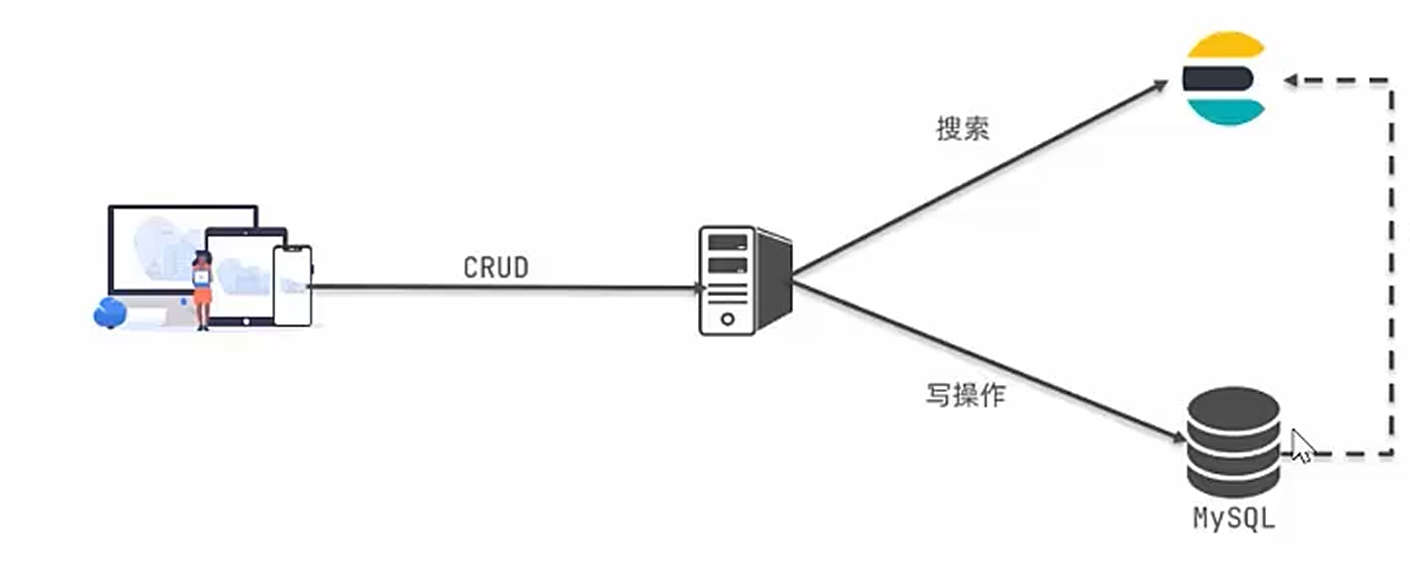
Mysql與ElasticSearch
-
ES 適合全文搜索和實時分析(如日志、商品搜索)。
-
MySQL 適合強事務和高一致性的業務(如支付、訂單)。
-
實際項目中常結合使用(如 MySQL 存儲業務數據,ES 提供搜索服務)。

)

------ROS2通信接口)
Ymodem協議實現OTA升級包括Bootloader、上位機、應用程序)
:配置“構建歷史的顯示名稱,加上包名等信息“)


Java學習-5.13(Redis,OSS))



Java/python/JavaScript/C++/C語言/GO六種最佳實現)


深度解析:原理、實戰與核心概念對比)



