分庫分表是分布式數據庫架構中常用的優化手段,用于解決單庫單表數據量過大、性能瓶頸等問題。其核心思想是將數據分散到多個數據庫(分庫)或多個表(分表)中,以提升系統的吞吐量、查詢性能和可擴展性。
一:為什么要分庫分表?
MySQL單庫數據量超過5000萬或單表數據量超過1000萬時,性能會顯著下降。隨著數據增長,單庫單表的查詢和寫入效率逐漸成為系統瓶頸。
二:拆分類型
拆分類型可分為兩類:水平拆分和垂直拆分。
1.水平拆分
水平拆分又分為水平分庫和水平分表。
1)水平分庫:將相同表結構的表復制到另一個庫中,減少單個數據庫的訪問壓力。
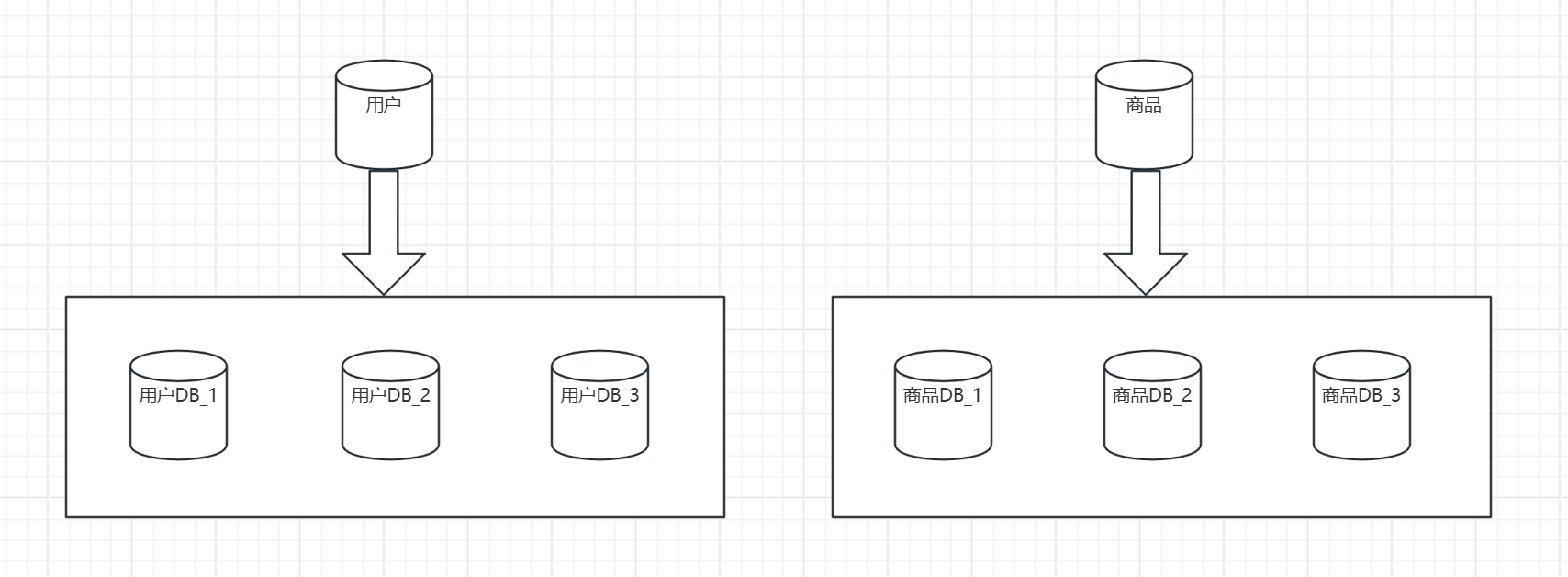
優點
- 提升系統吞吐量:大幅降低單庫數據量,提升查詢和寫入性能;
- 便于擴展:支持數據庫層面的水平擴展(增加數據庫節點)。
- 提高可用性:單個數據庫故障不會影響整體服務,其他庫仍可正常訪問。
缺點
- 跨庫查詢復雜:需要聚合多個庫的數據時,需借助中間件或手動處理,性能較低。
- 事務一致性難保證:分布式事務實現復雜,通常需引入額外機制。
2)水平分表:是將同一張表的數據分到多個表中,提高查詢效率。
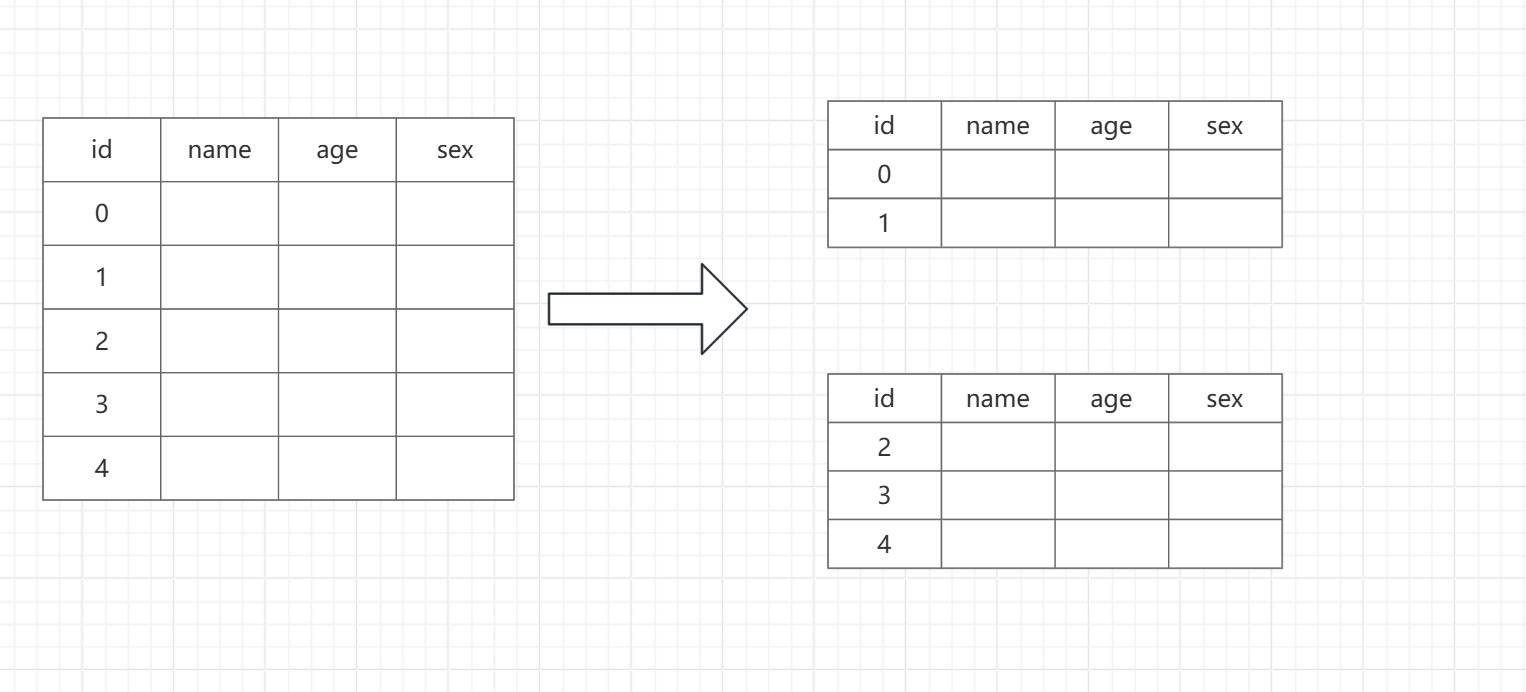
優點
- 單表數據量可控:將大表拆分為小表,避免單表數據量過大導致的索引效率下降、查詢變慢等問題。
- 提高并發性能:不同分表可分散到不同磁盤或物理機,降低I/O爭用。
缺點
- 跨表查詢麻煩:需合并多個分表結果,查詢復雜。
- 擴容復雜度高:后期調整分表數量時,需要進行數據遷移。
2.垂直拆分
垂直拆分又分為垂直分庫和垂直分表。
1)垂直分庫:將不同表分到不同庫中,降低單機的訪問瓶頸。
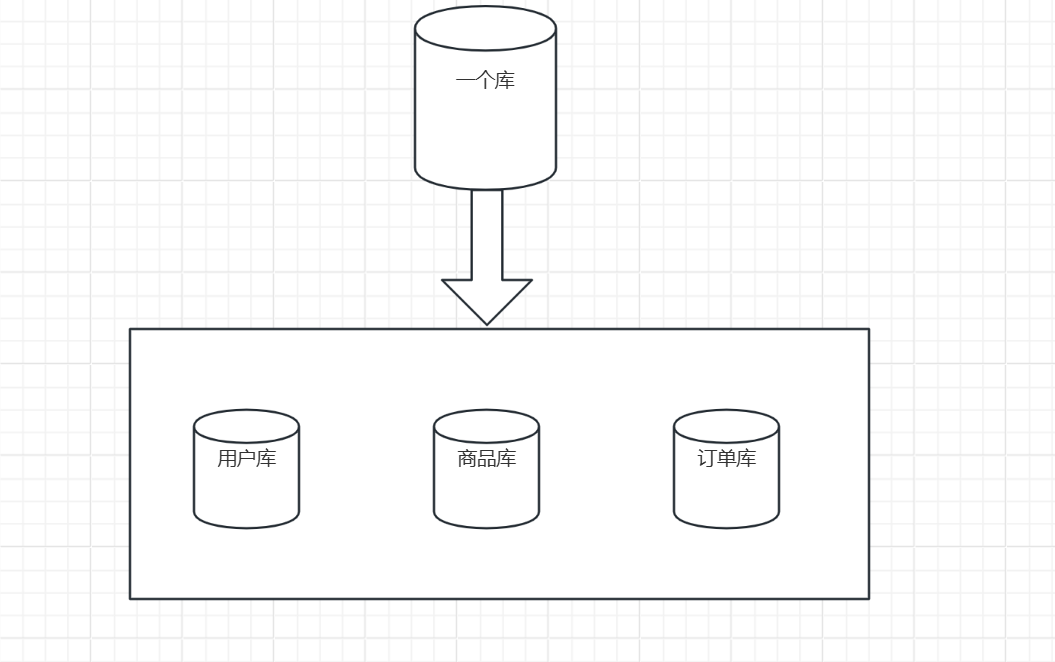
優點
- 業務解耦:按業務維度拆分庫,不同業務的數據獨立存儲,降低耦合度。
- 資源隔離:不同庫可部署在不同服務器,避免資源競爭(如CPU、內存、磁盤IO)。
- 擴展性強:業務增長時可單獨擴展特定庫的硬件資源。
缺點
- 跨庫查詢復雜:需通過接口或中間件(如ShardingSphere)實現跨庫關聯查詢,開發復雜度高。
- 事務一致性難保證:分布式事務(如Seata)引入的性能開銷。
2)垂直分表:將一張表的不同列拆分到多個表中,比如將熱點字段或者長度大的字段單獨分表。
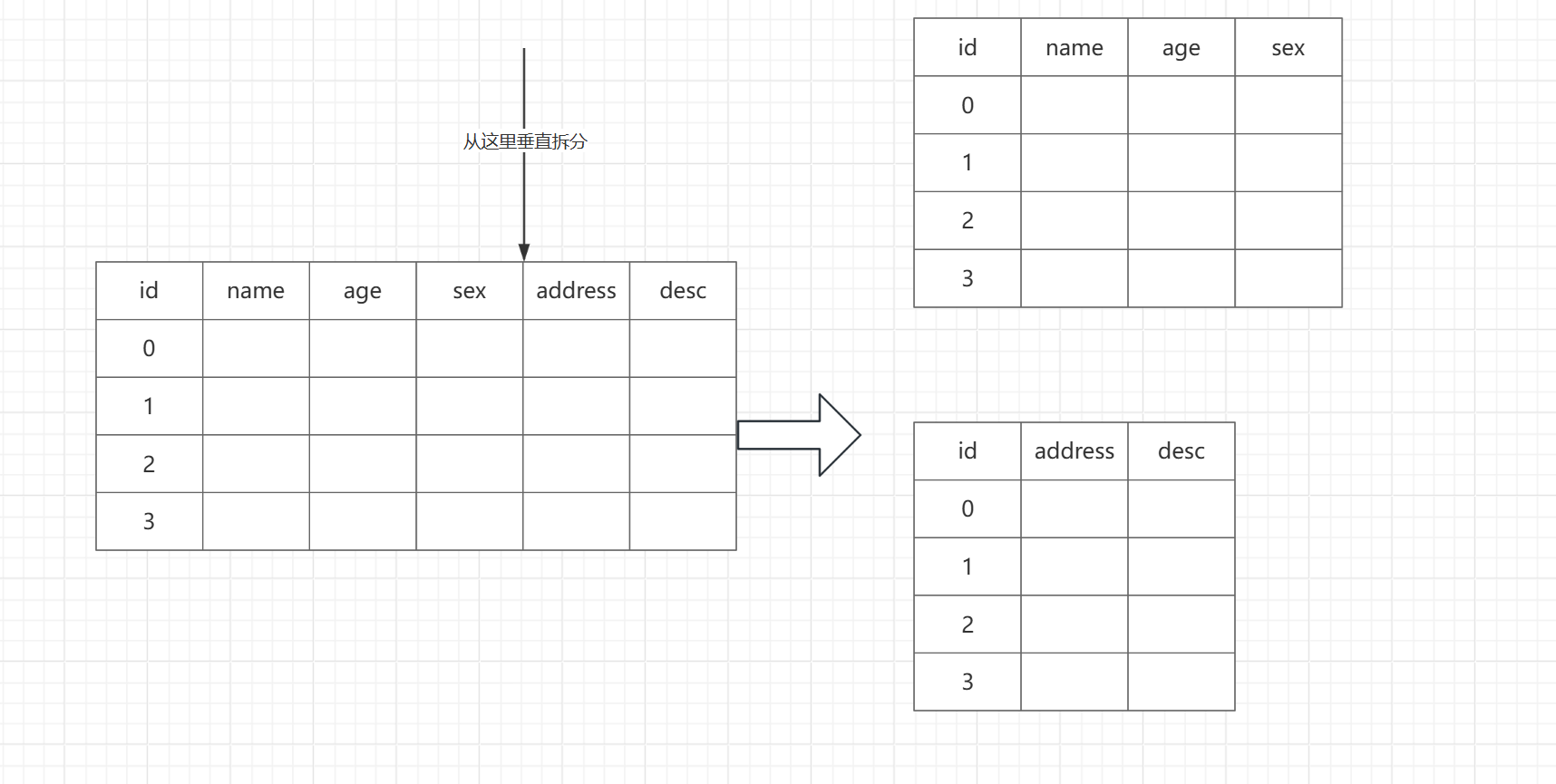
優點
- 冷熱數據分離:將高頻字段與低頻字段拆分,減少單表數據量,提升查詢效率。
- 減少鎖沖突:不同業務字段拆分后,更新操作鎖定更少數據。
缺點
- 查詢復雜:跨表查詢需關聯操作,增加開發復雜度;
- 數據量大:仍需解決單表數據量過大問題。
三:分庫分表策略
在選取分庫分表的策略前,首先要了解什么是分片鍵。
分片鍵(Sharding Key):決定數據分布的字段,需選擇高頻查詢條件(如用戶 ID、訂單 ID),避免跨分片查詢(盡量選取連續的分片放到同一個庫或表中)。
1.常見的分片策略
1)哈希取模:對分片字段進行哈希取模(shard_id = hash(key) % node_count)。
??優點:
- 數據分布均勻,不會容易出現冷熱數據分離導致性能瓶頸。
??缺點:
- 擴容時需遷移大量數據(如從 3 庫擴至 4 庫,需重新計算所有數據的分片)。
- 會出現跨分片查詢的情況(如要查詢訂單金額前10,需要查詢每段分片的前10然后比較)。
2)范圍劃分:按時間(如年 / 月)或數值范圍(如用戶 ID>1000 萬)分片,適合遞增數據(如訂單)。
優點:
- 便于水平擴展,如果要進行擴容,只需要添加節點即可,無需像哈希取模一樣要進行數據遷移。
- 連續分片能夠盡可能的避免跨分片查詢,提高查詢性能。
?缺點:
- 可能導致熱點分片(如最新月份的數據量過大),會被頻繁的讀和寫,從而導致單個分片的數據量訪問過大,出現性能瓶頸。
四.分布式問題
1.分布式主鍵:分庫分表后需保證不同庫 / 表的主鍵唯一。
- UUID:簡單易用,但作為主鍵性能較差(字符串類型,索引效率低)。
- 雪花算法(Snowflake):生成 64 位唯一整數,包含時間戳、機器 ID 等,性能高且有序,適用于高并發場景。
- 數據庫自增序列:每個分片設置不同的起始值和步長(如庫 1 起始 1、步長 3;庫 2 起始 2、步長 3),避免主鍵沖突。
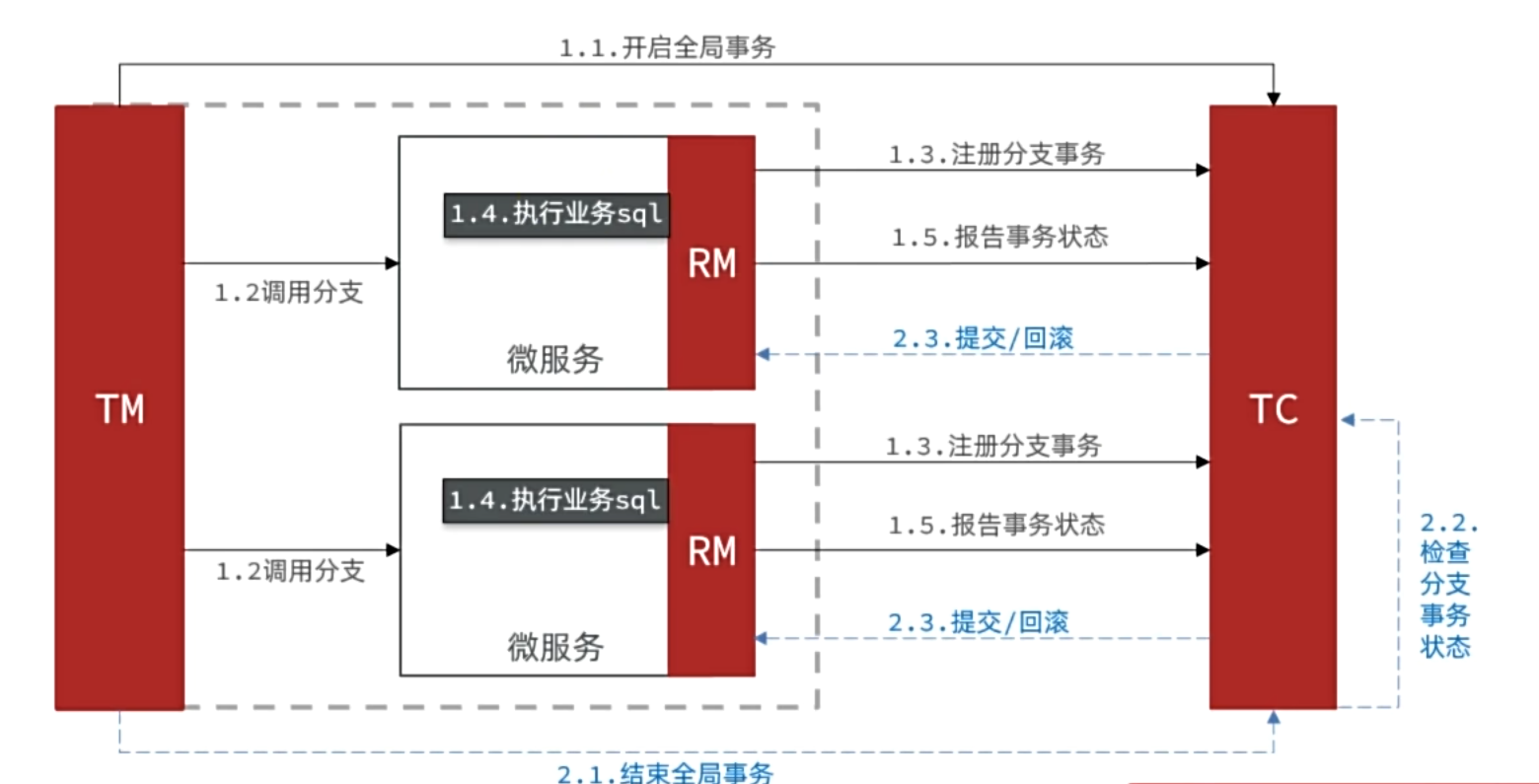
2.分布式事務:分布式事務需要解決跨節點(如跨數據庫、跨服務)操作的原子性問題,即確保多個節點的操作要么全部成功,要么全部回滾,下面主要講解seata中的兩種模式。
在講解兩種模式前需要了解三個概念。
- TM(Transaction Manager):事務管理器
- TC(Transaction Coordinator):事務協調者
- RM(Resource Manager):資源管理器
| 特性 | AT 模式(Auto Transaction) | XA 模式 |
|---|---|---|
| 一致性級別 | 最終一致(柔性事務) | 強一致(剛性事務) |
| 業務侵入性 | 無侵入(基于生成回滾日志) | 低侵入(需使用 Seata 提供的 XA 數據源) |
| 性能損耗 | 較低(僅在提交 / 回滾階段有少量額外開銷) | 較高(兩階段提交需等待所有分支事務響應) |
| 隔離性 | 基于全局鎖實現讀已提交(RC) | 支持可重復讀(RR)等強隔離級別 |
| 適用場景 | 高并發、允許短暫不一致的業務(如電商訂單、庫存) | 金融級強一致場景(如資金轉賬、賬戶余額) |
| 數據庫支持 | 關系型數據庫(MySQL、Oracle 等) | 支持 XA 協議的數據庫(MySQL 5.7+、PostgreSQL) |
1)AT模式
(1)一階段(Prepare)
- 注冊分支事務
- 生成回滾日志:將相關信息存入 UNDO_LOG 表。
- SQL 執行并提交
- 釋放本地鎖:本地事務提交,釋放數據庫行鎖。
(2)二階段(Commit/Rollback)分為提交和回滾兩種情況
- 提交(Commit):TM(事務管理器)通知 RM(資源管理器)直接刪除 UNDO_LOG,無需操作數據庫。
- 回滾(Rollback):RM 通過 UNDO_LOG 中的記錄恢復數據。

2)XA模式(兩階段提交模式)
XA 模式基于數據庫原生 XA 協議實現強一致事務,遵循“兩階段提交(2PC)”?協議:
(2)一階段(Prepare)
- TM 向所有 RM 發送
prepare請求。 - RM 執行本地事務,但不提交,將事務資源鎖定。
- RM 向 TM 返回
成功或失敗。
(2)二階段(Commit/Rollback)
- 若所有 RM 均返回成功,TM 發送
commit,RM 提交本地事務; - 若任一 RM 失敗,TM 發送
rollback,RM 回滾本地事務。
五.Seata 中如何配置?
(一)AT 模式配置示例(基于 Spring Boot)
seata:enabled: trueapplication-id: ${spring.application.name}tx-service-group: my_test_tx_groupconfig:type: nacos # 配置中心類型nacos:server-addr: 127.0.0.1:8848registry:type: nacos # 注冊中心類型nacos:server-addr: 127.0.0.1:8848data-source-proxy-mode: AT # 指定AT模式
關鍵步驟:
- 引入 Seata 客戶端依賴;
- 配置數據源代理(
DataSourceProxy); - 在需要分布式事務的方法上添加
@GlobalTransactional注解。
(二)XA 模式配置示例
seata:data-source-proxy-mode: XA # 指定XA模式xa-override-boundary: true # 允許XA事務跨越多個本地事務
關鍵步驟:
- 使用 Seata 提供的
SeataDataSourceProxyXA包裝數據源; - 確保數據庫開啟 XA 支持(如 MySQL 需設置
innodb_support_xa=ON); - 其余配置與 AT 模式類似。
六.總結
| 維度 | AT 模式 | XA 模式 |
|---|---|---|
| 事務協調機制 | 基于 UNDO_LOG 和全局鎖 | 基于數據庫 XA 協議 |
| 資源鎖定時間 | 僅在一階段執行期間鎖定(時間短) | 一階段到二階段提交期間一直鎖定(時間長) |
| 性能 | 高(接近本地事務) | 低(兩階段提交開銷大) |
| 回滾機制 | 自動根據 UNDO_LOG 回滾 | 依賴數據庫回滾能力 |
| 隔離級別 | 讀已提交(RC) | 可重復讀(RR)等數據庫原生級別 |
| 異常處理 | 需處理全局鎖沖突和補償失敗 | 需處理事務懸掛和協調者故障 |
- AT 模式是 Seata 的默認模式,適合大多數高并發、最終一致的業務場景,通過無侵入的方式實現柔性事務。
- XA 模式適合對一致性要求極高的金融級業務,依賴數據庫原生支持實現強一致,但性能較低。
- 實際應用中,建議根據業務特性混合使用不同模式(如核心鏈路用 XA,例如轉賬等功能,非核心用 AT),并結合監控系統及時發現和處理異常。
?













講解與實戰(9))





