目錄
一、知識圖譜背景介紹
(一)基本背景
(二)與NLP的關系
(三)常識性概念圖譜的引入對比
二、常識性概念圖譜介紹
(一)常識性概念圖譜關系圖示例
(二)圖譜三類節點
(三)圖譜四類關系
Is-a 關系|Part-of 關系|Instance-of 關系|Property-value 關系
同義/上下位關系
三、常識性概念圖譜構建
(一)圖譜構建整體框架
(二)概念挖掘
原子概念挖掘
復合概念挖掘
(三)概念上下位關系挖掘
概念-Taxonomy間上下位關系
概念-概念間上下位關系
(四)概念屬性關系挖掘
基于復合概念挖掘公共屬性關系
基于開放屬性詞挖掘特定屬性關系
(五)概念承接關系挖掘
基于共現特征挖掘種子數據
基于種子數據訓練深度模型
基于已有的圖譜結構進行關系補全
(六)POI/SPU-概念關系建設
四、應用分析
(一)在美團內部的具體應用舉例
到綜品類詞圖譜建設
點評搜索引導
到綜醫美內容打標
(二)業內領域的應用舉例
金融領域
醫療領域
零售領域
智能交通領域
阿里巴巴、騰訊
字節跳動
五、簡單模擬示例
(一)Neo4j知識圖譜數據庫查詢展示
(二)學習建議建議和思路
六、總結
參考文獻、書籍及鏈接
干貨分享,感謝您的閱讀!
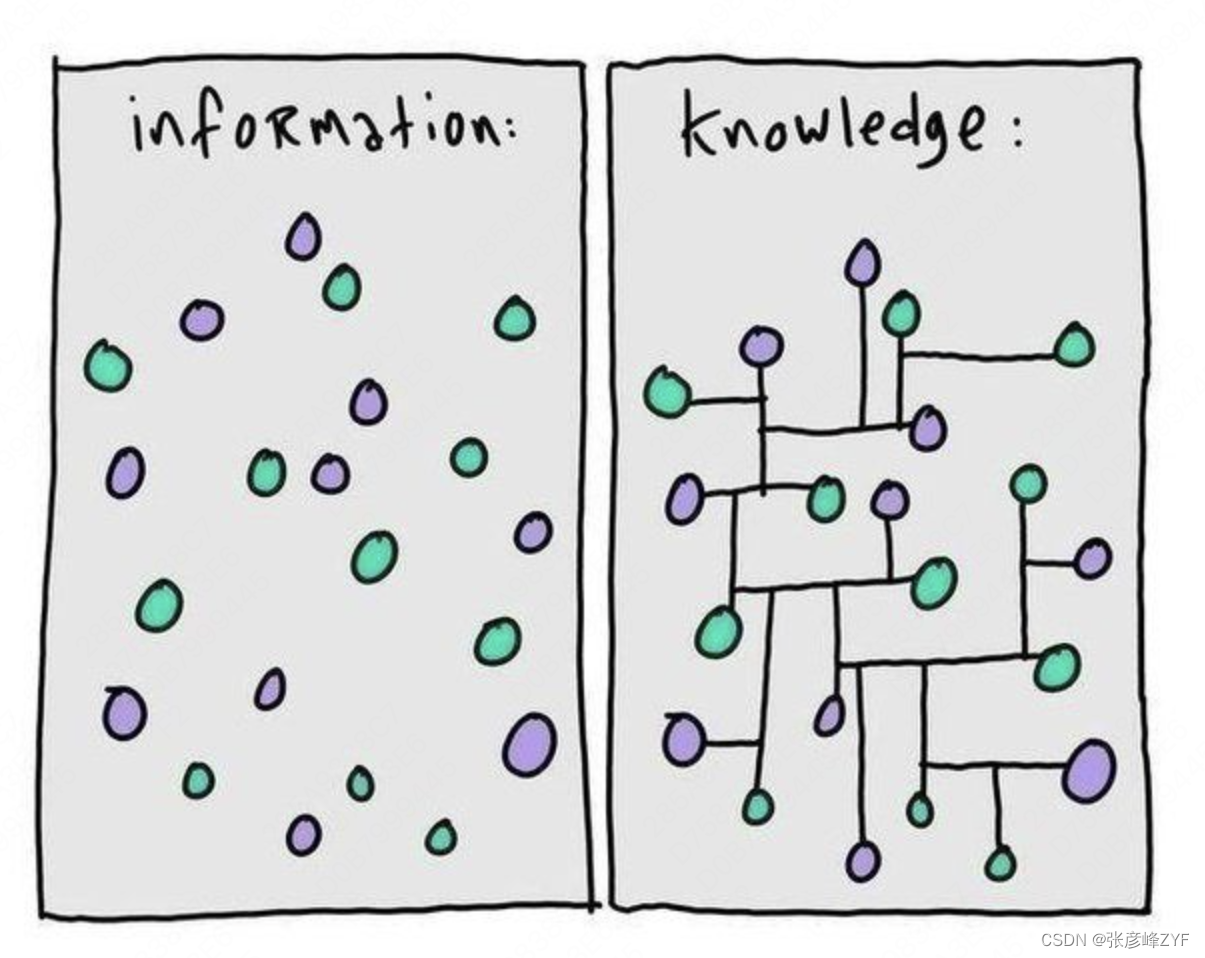
在當今信息爆炸的時代,知識的獲取與應用變得愈加復雜。如何讓機器更好地理解人類的常識,以實現更智能的問答系統和服務,已成為人工智能領域的重要挑戰。常識性概念圖譜的構建為這一問題提供了有效的解決方案。通過系統化地整理和連接人類的常識知識,我們不僅能夠提升機器的理解能力,更能為智能生活的各個方面打下堅實的基礎。本文將深入探討常識性概念圖譜的構建過程、應用場景及其在智能問答系統中的革命性影響,帶領讀者一同探索這一引領未來的知識架構。
一、知識圖譜背景介紹
(一)基本背景
知識圖譜是一種用于表示和管理知識的技術,它將知識組織成圖形結構,每個節點代表一個實體,每條邊代表實體之間的關系。知識圖譜的概念最早由Google在2012年提出,隨后得到了學術界和工業界的廣泛關注和研究。
知識圖譜的背景可以追溯到人工智能的發展歷程。早期的人工智能主要基于規則推理系統,人們通過編寫大量的規則來讓計算機模擬人類的智能。但是,這種方法存在規則復雜、難以維護、泛化能力不足等問題,無法應對復雜的現實場景。
隨著互聯網技術和數據挖掘技術的不斷發展,人們開始關注從大規模的數據中自動發現知識的方法。知識圖譜作為一種自動化知識發現和管理的技術,受到了廣泛關注。
在知識圖譜的發展過程中,谷歌公司的“知識圖譜”項目起到了重要的推動作用。該項目的目標是構建一個包含各種實體和關系的大規模知識庫,可以幫助人們更好地理解世界和實現更智能的搜索。

除了谷歌,許多知名企業和組織也在積極推進知識圖譜的應用和研究,如微軟、IBM、阿里巴巴、騰訊、百度等。知識圖譜已經被廣泛應用于各個領域,包括搜索引擎、智能問答、語義分析、智能推薦、自然語言處理等。
(二)與NLP的關系
知識圖譜和自然語言處理(NLP)之間存在密切的關系。自然語言處理是指利用計算機技術處理和理解人類自然語言的能力,包括自然語言的分析、生成、理解和應用等方面。而知識圖譜則是為了更好地實現自然語言處理任務而構建的知識庫。
具體來說,自然語言處理的任務之一就是語義理解,即讓計算機能夠理解人類的語言,并從中提取出有意義的信息。知識圖譜可以提供給自然語言處理算法必要的背景知識和上下文信息,以便更好地理解和解釋自然語言文本中的實體、關系和事件等內容。
例如,自然語言問答系統通常需要從輸入的自然語言問句中提取出問題所涉及的實體和關系,才能正確地回答問題。知識圖譜可以提供必要的實體和關系信息,幫助問答系統進行更準確和全面的理解。又比如,在智能推薦系統中,知識圖譜可以提供用戶和商品之間的關系和屬性信息,幫助推薦系統更準確地預測用戶的偏好和行為。
(三)常識性概念圖譜的引入對比
知識圖譜、常識性概念圖譜和概念圖譜都是用于表示和存儲知識的技術,它們之間存在某些相似和重疊之處,但又各有側重和差異。
知識圖譜是一個大規模、多模態的知識庫,以圖形結構的形式存儲實體、屬性和關系等知識,并通過語義關聯對這些知識進行組織和鏈接。知識圖譜主要用于知識的存儲、推理、查詢和應用等方面,在人工智能、自然語言處理、推薦系統等領域具有廣泛的應用。
概念圖譜則是一種更為通用的知識表示方法,它可以表示任意領域的概念、實體和關系等,與知識圖譜和常識性概念圖譜相比更為靈活和自由。概念圖譜主要用于知識表示和推理的研究,也可以作為知識圖譜和常識性概念圖譜的底層技術之一。
常識性概念圖譜則是一種特定領域的知識圖譜,它主要用于表示人類的日常生活中所涉及的一些基礎概念、實體和關系等,如人物、地點、時間、物品、事件等。常識性概念圖譜旨在幫助計算機更好地理解和模擬人類的日常生活,為自然語言處理、智能對話、情感分析等應用提供基礎支持。
因此,知識圖譜、常識性概念圖譜和概念圖譜之間的關系可以被理解為層次關系。概念圖譜是最底層的知識表示方法,知識圖譜是在概念圖譜的基礎上構建的更大規模、更具實際應用價值的知識庫,而常識性概念圖譜則是知識圖譜的一個特定領域的應用,用于表示人類日常生活中的常識知識。
二、常識性概念圖譜介紹
常識性概念圖譜是一種基于人類常識的知識圖譜,它通過構建和維護實體、概念、屬性、關系、事件等多維度的知識元素,并將它們以圖譜的形式組織起來,以便于計算機理解和推理。
與傳統的知識圖譜相比,常識性概念圖譜更加注重人類常識的表達和應用,包含了更加豐富和細致的知識元素。例如,在一個旅游領域的常識性概念圖譜中,除了景點、酒店等實體,還包括了人們出游的目的、方式、注意事項等常識性概念,以及它們之間的屬性和關系。
常識性概念圖譜的構建需要借助大量的語料庫和常識庫,同時還需要進行自動化的知識抽取、實體鏈接、關系抽取等技術,以便快速構建和更新圖譜。常識性概念圖譜的應用也非常廣泛,例如在智能客服、智能搜索、智能推薦、智能問答等領域中,可以大大提高計算機理解和處理自然語言的能力,從而更好地為人類服務。看了很多文章,最后我們還是以MATLAB算法實戰應用-【應用案例篇】常識性概念圖譜建設以及在美團場景中的應用_matlab實戰案例_林聰木的博客-CSDN博客為主要分析來看
(一)常識性概念圖譜關系圖示例
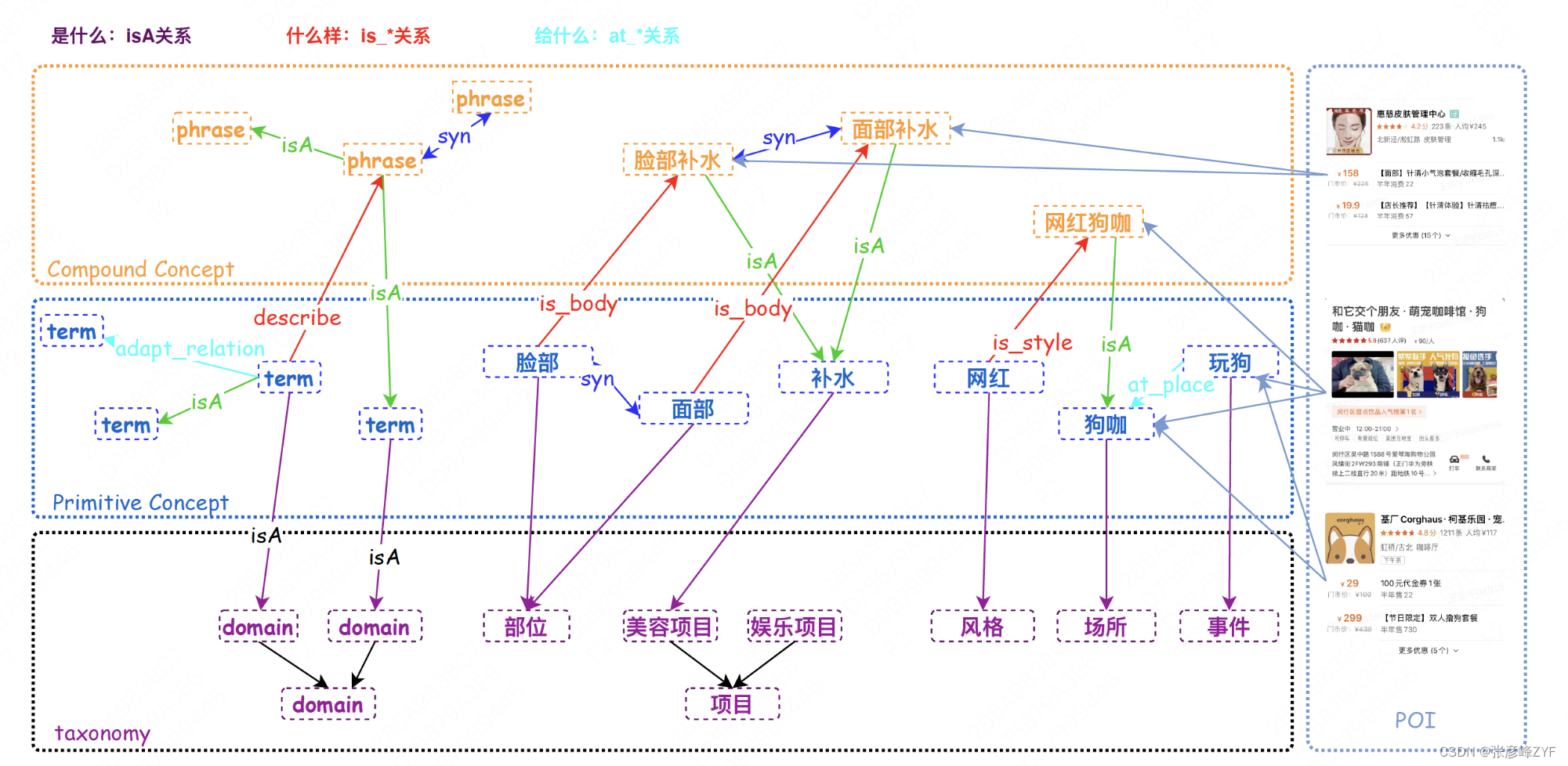
前面提到“通過構建和維護實體、概念、屬性、關系、事件等多維度的知識元素,并將它們以圖譜的形式組織起來,以便于計算機理解和推理”總結起來可以用下圖美團的知識圖譜進行展開分析,
涵蓋“是什么”的概念Taxonomy體系結構,“什么樣”的概念屬性關系,“給什么”的概念承接關系。同時POI(Point of Interesting)、SPU(Standard Product Unit)、團單作為美團場景中的實例,需要和圖譜中的概念建立連接。
(二)圖譜三類節點
知識圖譜中三類節點指的是實體節點、屬性節點和關系節點,基于概念分類的節點分類方法通常用于本體論(Ontology)或知識圖譜的語義表示,以幫助機器理解和推理。其中,常見的有以下三類節點:
- Taxonomy節點(分類樹節點):代表分類樹上的節點,每個節點代表一個類別。它是一種層次結構,上層節點代表較為抽象的類別,下層節點代表具體的實體。
- 原子概念節點:代表最基本的概念單元,不能被拆分為更小的概念。原子概念通常表示一種事物的本質屬性,是其他概念的基礎。例如,在一個動物分類的知識圖譜中,狗、貓、鳥等就是原子概念節點。
- 復合概念節點:由多個原子概念節點組合而成的復合概念。它可以表示更復雜的概念和實體,是知識圖譜中更高層次的節點。例如,在一個人類分類的知識圖譜中,復合概念節點可以是“青年人”、“老年人”、“男性”、“女性”等。
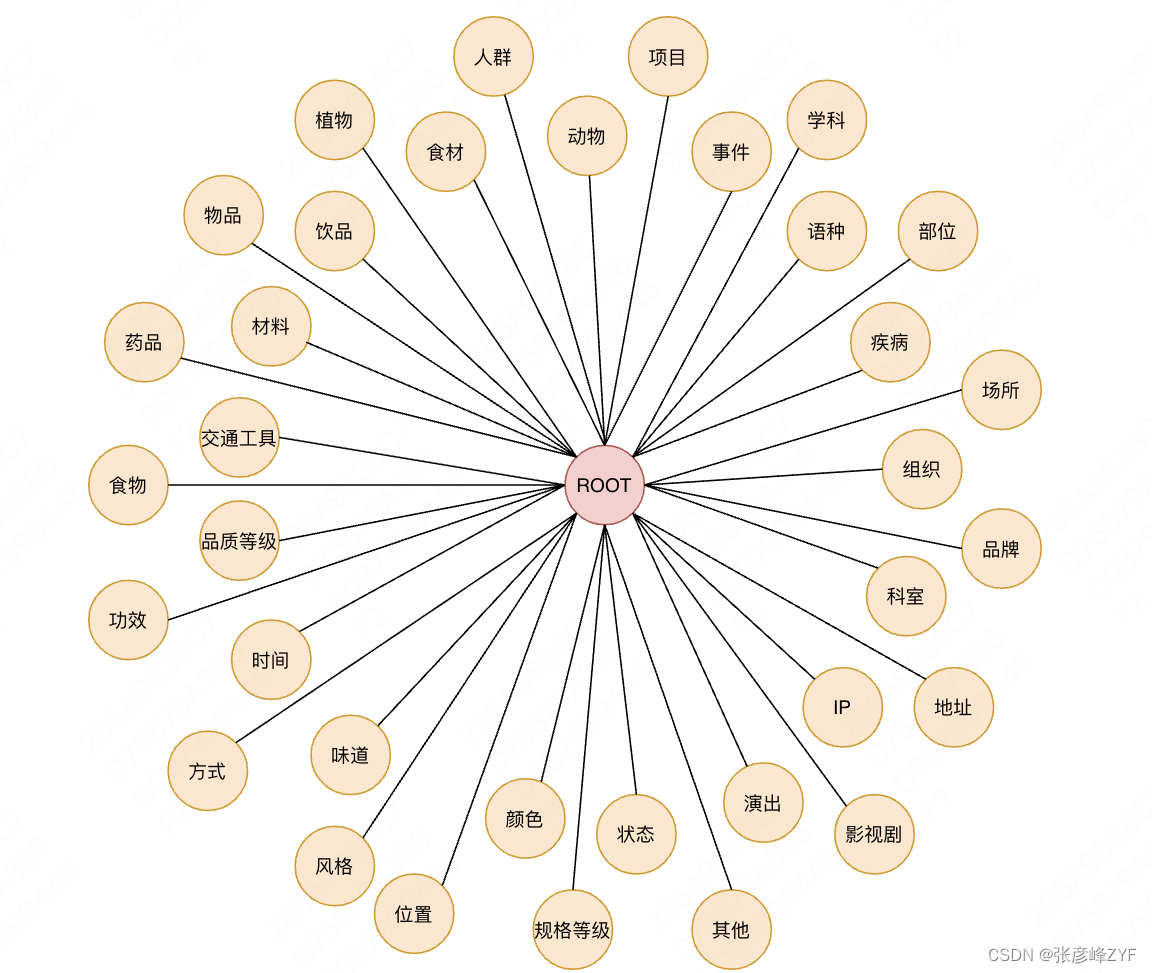
理解一個概念需要合理的知識體系,預定義好的Taxonomy知識體系作為理解的基礎,在預定義的體系中分為兩類節點:第一類在美團場景中可以作為核心品類出現的,例如,食材、項目、場所;另一類是作為對核心品類限定方式出現的,例如,顏色、方式、風格。這兩類的節點的定義都能幫助搜索、推薦等的理解。目前預定義的Taxonomy節點如下圖所示:
(三)圖譜四類關系
Is-a 關系|Part-of 關系|Instance-of 關系|Property-value 關系
基于概念分類的圖譜通常包含以下四類關系:
- Is-a 關系:表示概念之間的上下位關系,如“貓”是“動物”的一種,可以表示為Cat is a type of Animal。
- Part-of 關系:表示一個物體或概念是另一個物體或概念的一部分,如“車輪”是“汽車”的一部分,可以表示為Wheel is part of Car。
- Instance-of 關系:表示一個具體的事物是某個概念的一個實例,如“加菲貓”是“貓”的一個實例,可以表示為Garfield is an instance of Cat。
- Property-value 關系:表示概念與其屬性之間的關系,如“加菲貓”的顏色是“橙色”,可以表示為Garfield has the property of Color with value Orange。
這些關系可以用來描述概念之間的語義關聯,從而在自然語言處理、知識推理等領域得到廣泛應用。以美團的案例為例,可以細化展開為以下四個詳細介紹。
同義/上下位關系
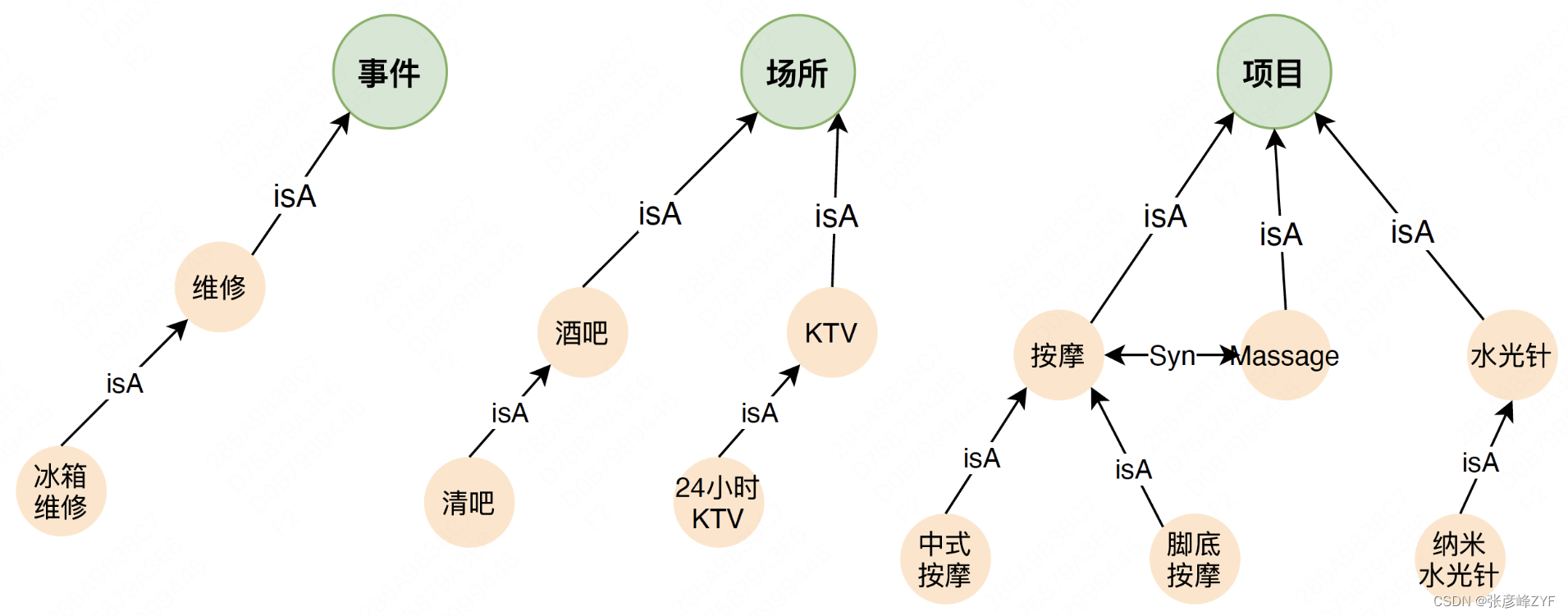
語義上的同義/上下位關系,例如臉部補水-syn-面部補水等。定義的Taxonomy體系也是一種上下位的關系,所以歸并到同義/上下位關系里。
概念屬性關系
典型的CPV(Concept-Property-Value)關系,從各個屬性維度來描述和定義概念,例如火鍋-口味-不辣,火鍋-規格-單人等,示例如下:
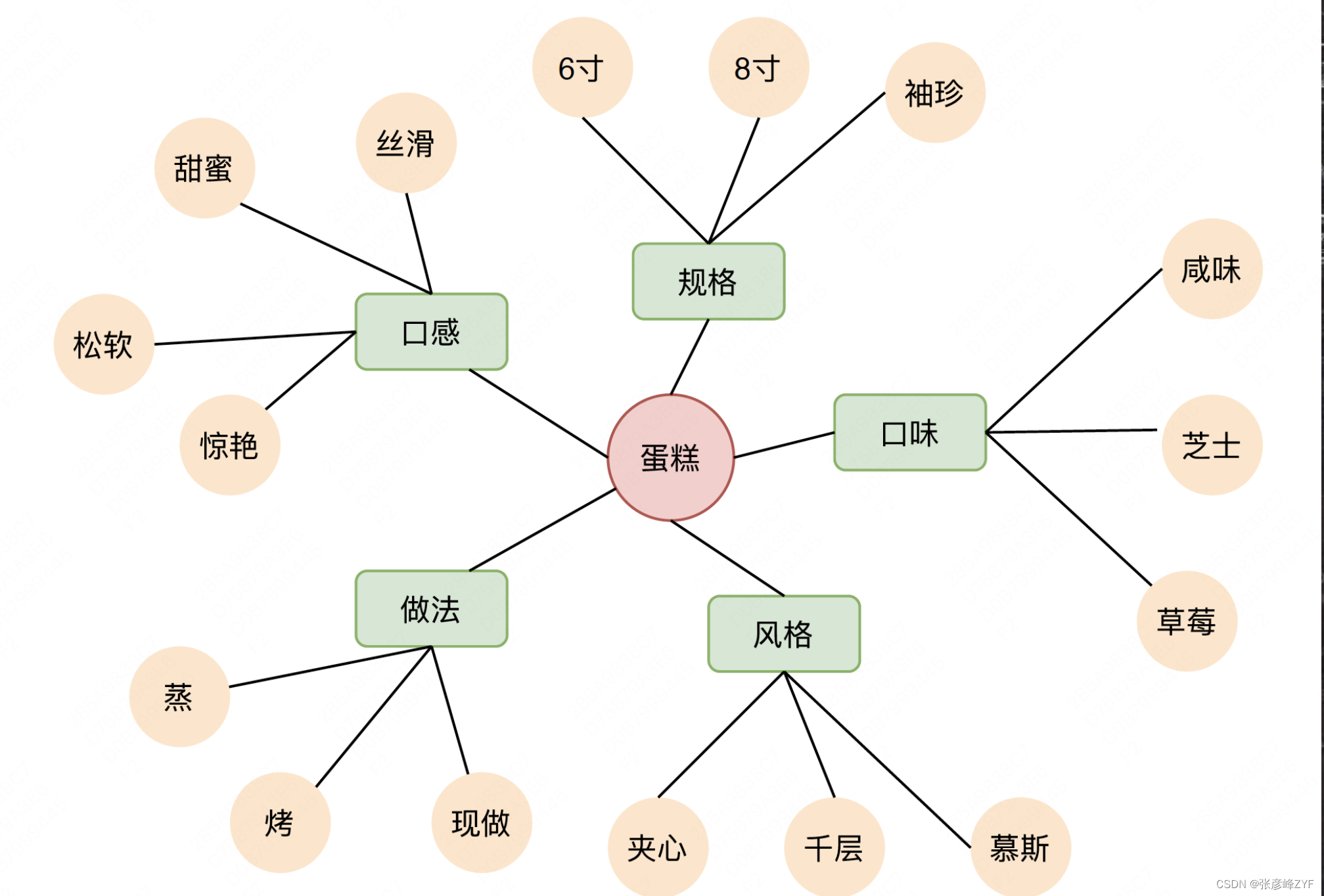
概念屬性關系包含兩類:
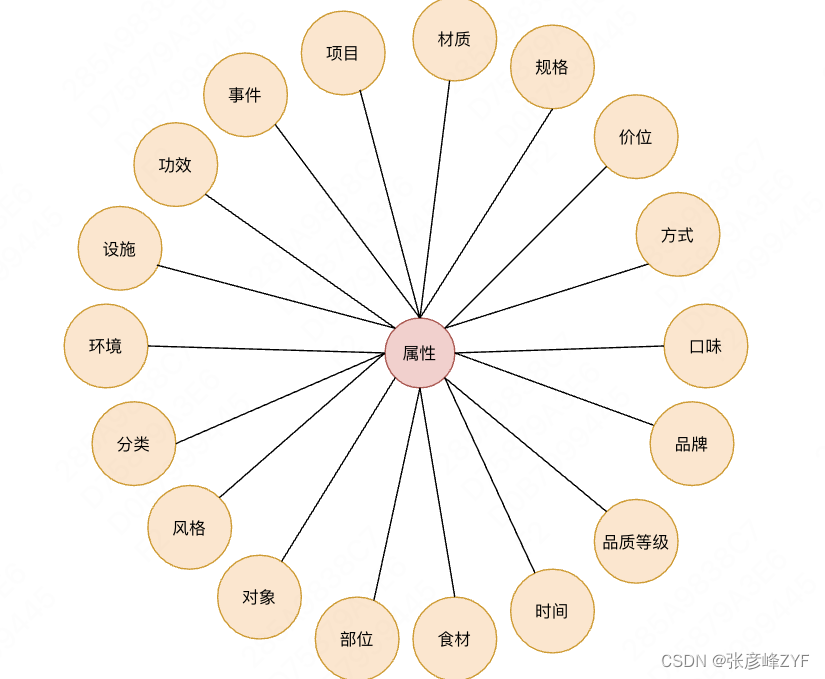
預定義概念屬性:目前我們預定義典型的概念屬性如下圖
開放型概念屬性:除了我們自己定義的公共的概念屬性外,我們還從文本中挖掘一些特定的屬性詞,補充一些特定的屬性詞。例如,姿勢、主題、舒適度、口碑等。
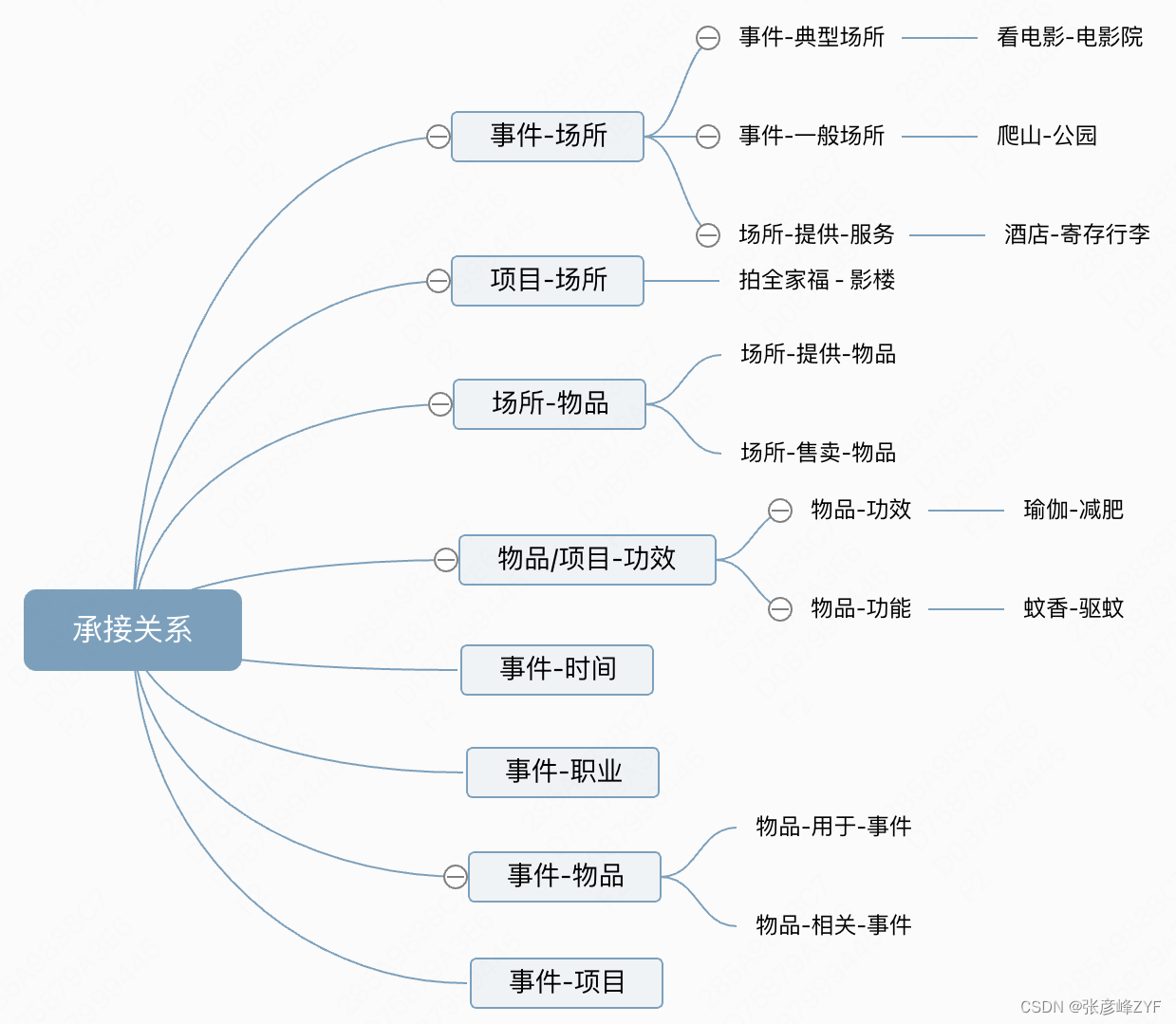
概念承接關系
這類關系主要建立用戶搜索概念和美團承接概念之間的鏈接,例如踏春-場所-植物園,減壓-項目-拳擊等。
概念承接關系以「事件」為核心,定義了「場所」、「物品」、「人群」、「時間」、「功效」等能夠滿足用戶需求的一類供給概念。以事件“美白”為例,“美白”作為用戶的需求,可以有不三 同的供給概念能夠滿足,例如美容院、水光針等。目前,定義的幾類承接關系如下圖所示:
POI/SPU-概念關系
POI作為美團場景中的實例,實例-概念的關系作為知識圖譜中最后的一站,常常是比較能發揮知識圖譜在業務上價值的地方。在搜索、推薦等業務場景,最終的目的是能夠展示出符合用戶需求的POI,所以建立POI/SPU-概念的關系是整個美團場景常識性概念圖譜重要的一環,也是比較有價值的數據。
三、常識性概念圖譜構建
還是以美團的文章為例繼續查看對應的流程
(一)圖譜構建整體框架
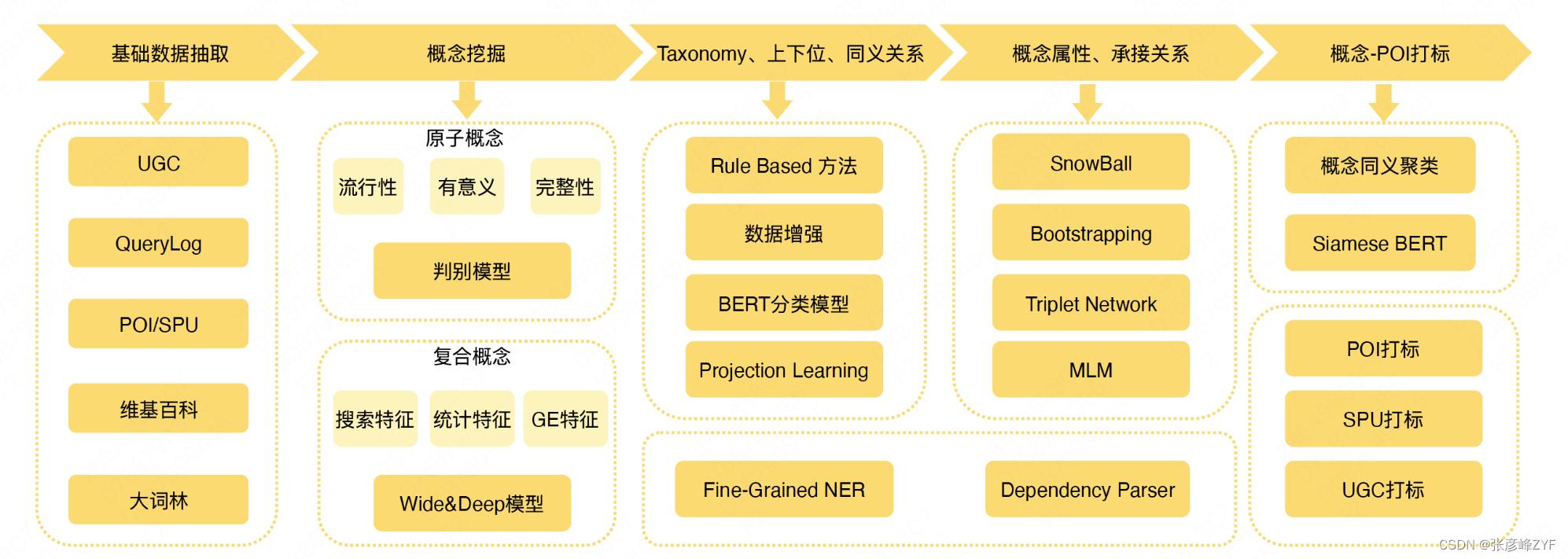
(二)概念挖掘
常識性概念圖譜的各種關系都是圍繞概念構建,這些概念的挖掘是常識性概念圖譜建設的第一環。按照原子概念和復合概念兩種類型,分別采取相應的方法進行挖掘。
原子概念挖掘
原子概念候選來自于Query、UGC(User Generated Content)、團單等文本分詞后的最小片段,原子概念的判斷標準是需要滿足流行性、有意義、完整性三個特性的要求。
- 流行性,一個概念應是某個或某些語料內流行度較高的詞,該特性主要通過頻率類特征度量,如“桌本殺”這個詞搜索量很低且UGC語料中頻率也很低,不滿足流行性要求。
- 有意義,一個概念應是一個有意義的詞,該特性主要通過語義特征度量,如“阿貓”、“阿狗”通常只表一個單純的名稱而無其他實際含義。
- 完整性,一個概念應是一個完整的詞,該特性主要通過獨立檢索占比(該詞作為Query的搜索量/包含該詞的Query的總搜索量)衡量,如“兒童設”是一個錯誤的分詞候選,在UGC中頻率較高,但獨立檢索占比低。
基于原子概念以上的特性,結合人工標注以及規則自動構造的訓練數據訓練XGBoost分類模型對原子概念是否合理進行判斷。
復合概念挖掘
復合概念候選來自于原子概念的組合,由于涉及組合,復合概念的判斷比原子概念判斷更為復雜。復合概念要求在保證完整語義的同時,在美團站內也要有一定的認知。根據問題的類型,采用Wide&Deep的模型結構,Deep側負責語義的判斷,Wide側引入站內的信息。
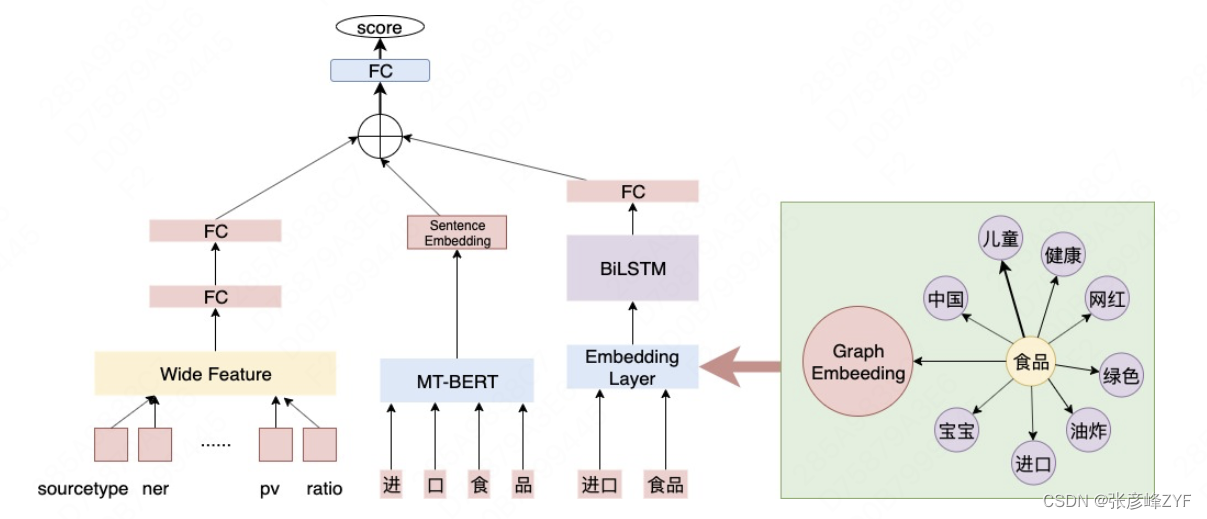
該模型結構有以下兩個特點,對復合概念的合理性進行更準確的判斷:
- Wide&Deep模型結構:將離散特征與深度模型結合起來判斷復合概念是否合理。
- Graph Embedding特征:引入詞組搭配間的關聯信息,如“食品”可以與“人群”、“烹飪方式”、“品質”等進行搭配。
(三)概念上下位關系挖掘
在獲取概念之后,還需要理解一個概念“是什么”,一方面通過人工定義的Taxonomy知識體系中的上下位關系進行理解,另一方面通過概念間的上下位關系進行理解。
概念-Taxonomy間上下位關系
概念-Taxonomy間上下位關系是通過人工定義的知識體系理解一個概念是什么,由于Taxonomy類型是人工定義好的類型,可以把這個問題轉化成一個分類問題。同時,一個概念在Taxonomy體系中可能會有多個類型,如“青檸魚”既是一種“動物”,也屬于“食材”的范疇,所以這里最終把這個問題作為一個Entity Typing的任務來處理,將概念及其對應上下文作為模型輸入,并將不同Taxonomy類別放在同一空間中進行判斷,具體的模型結構如下圖所示:
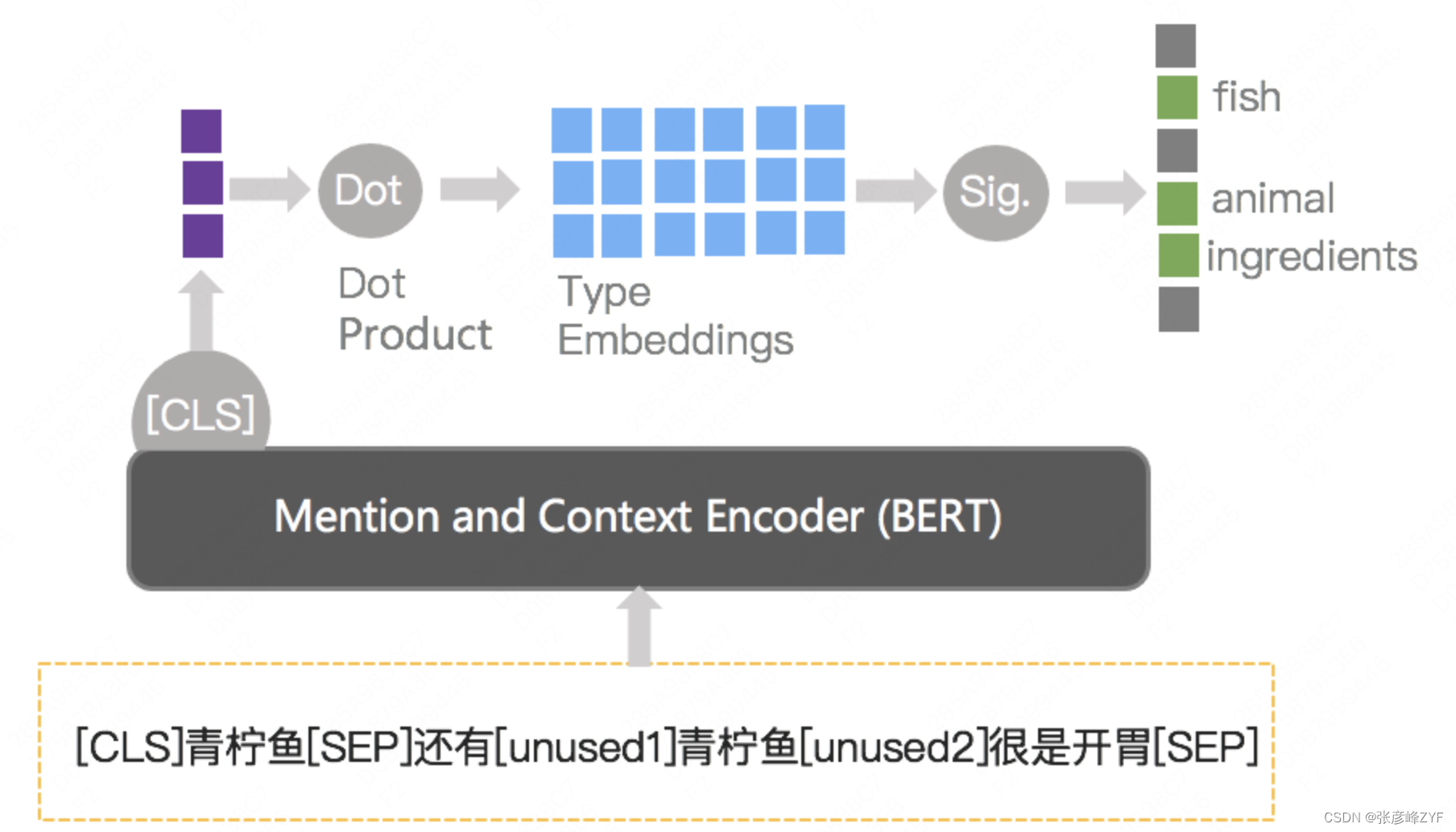
概念-概念間上下位關系
知識體系通過人工定義的類型來理解一個概念是什么,但人工定義的類型始終是有限的,如果上位詞不在人工定義的類型中,這樣的上下位關系則沒辦法理解。如可以通過概念-Taxonomy關系理解“西洋樂器”、“樂器”、“二胡”都是一種“物品”,但沒辦法獲取到“西洋樂器”和“樂器”、“二胡”和“樂器”之間的上下位關系。基于以上的問題,對于概念-概念間存在的上下位關系,目前采取如下兩種方法進行挖掘。
基于詞法規則的方法
主要解決原子概念和復合概念間的上下位關系,利用候選關系對在詞法上的包含關系(如西洋樂器-樂器)挖掘上下位關系。
基于上下文判斷的方法
詞法規則可以解決在詞法上存在包含關系的上下位關系對的判斷。對于不存在詞法上的包含關系的上下位關系對,如“二胡-樂器”,首先需要進行上下位關系發現,抽取出“二胡-樂器”這樣的關系候選,再進行上下位關系判斷,判斷“二胡-樂器”是一個合理的上下位關系對。考慮到人在解釋一個對象時會對這個對象的類型進行相關介紹,如在對“二胡”這個概念進行解釋時會提到“二胡是一種傳統樂器”,從這樣的解釋性文本中,既可以將“二胡-樂器”這樣的關系候選對抽取出來,也能同時實現這個關系候選對是否合理的判斷。這里在上下位關系挖掘上分為候選關系描述抽取以及上下位關系分類兩部分:
- 候選關系描述抽取:兩個概念從屬于相同的Taxonomy類型是一個候選概念對是上下位關系對的必要條件,如“二胡”和“樂器”都屬于Taxonomy體系中定義的“物品”,根據概念-Taxonomy上下位關系的結果,對于待挖掘上下位關系的概念,找到跟它Taxonomy類型一致的候選概念組成候選關系對,然后在文本中根據候選關系對的共現篩選出用作上下位關系分類的候選關系描述句。
- 上下位關系分類:在獲取到候選關系描述句后,需要結合上下文對上下位關系是否合理進行判斷,這里將兩個概念在文中的起始位置和終止位置用特殊標記標記出來,并以兩個概念在文中起始位置標記處的向量拼接起來作為兩者關系的表示,根據這個表示對上下位關系進行分類,向量表示使用BERT輸出的結果,詳細的模型結構如下圖所示:
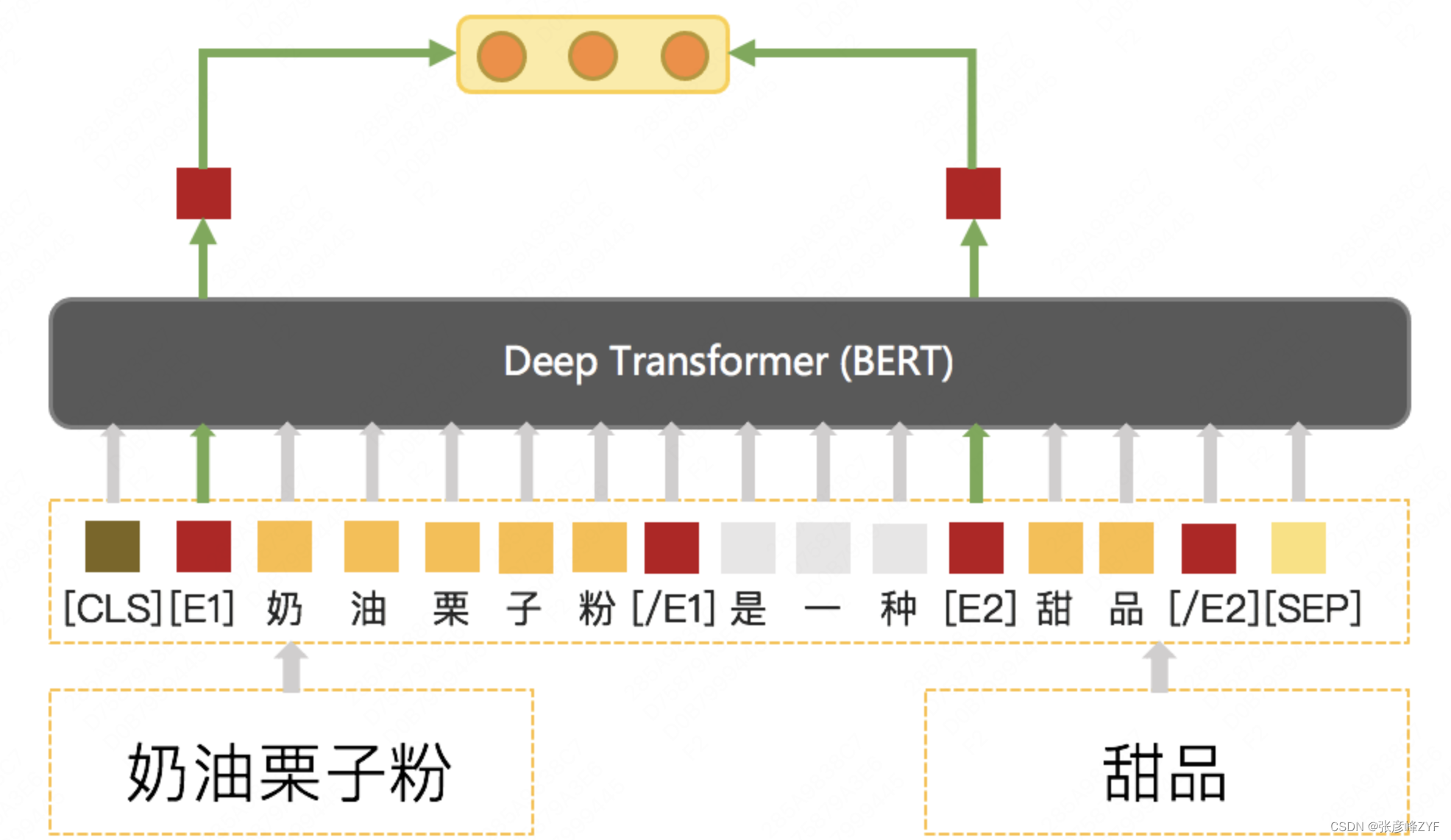
在訓練數據構造上,由于上下位關系表述的句子非常稀疏,大量共現的句子并沒有明確的表示出候選關系對是否具有上下位關系,利用已有上下位關系采取遠程監督方式進行訓練數據構建不可行,所以直接使用人工標注的訓練集對模型進行訓練。由于人工標注的數量比較有限,量級在千級別,這里結合Google的半監督學習算法UDA(Unsupervised Data Augmentation)對模型效果進行提升,最終Precision可以達到90%+,詳細指標如下:

(四)概念屬性關系挖掘
概念含有的屬性可以按照屬性是否通用劃分為公共屬性和開放屬性。公共屬性是由人工定義的、大多數概念都含有的屬性,例如價位、風格、品質等。開放屬性指某些特定的概念才含有的屬性,例如,“植發”、“美睫”和“劇本殺”分別含有開放屬性“密度”、“翹度”和“邏輯”。開放屬性的數量遠遠多于公共屬性。針對這兩種屬性關系,我們分別采用以下兩種方式進行挖掘。
基于復合概念挖掘公共屬性關系
由于公共屬性的通用性,公共屬性關系(CPV)中的Value通常和Concept以復合概念的形式組合出現,例如,平價商場、日式料理、紅色電影高清。我們將關系挖掘任務轉化為依存分析和細粒度NER任務(可參考《美團搜索中NER技術的探索與實踐》一文),依存分析識別出復合概念中的核心實體和修飾成分,細粒度NER判斷出具體屬性值。例如,給定復合概念「紅色電影高清」,依存分析識別出「電影」這個核心概念,「紅色」、「高清」是「電影」的屬性,細粒度NER預測出屬性值分別為「風格(Style)」、「品質評價(高清)」。
依存分析和細粒度NER有可以互相利用的信息,例如“畢業公仔”,「時間(Time)」和「產品(Product))」的實體類型,與「公仔」是核心詞的依存信息,可以相互促進訓練,因此將兩個任務聯合學習。但是由于兩個任務之間的關聯程度并不明確,存在較大噪聲,使用Meta-LSTM,將Feature-Level的聯合學習優化為Function-Level的聯合學習,將硬共享變為動態共享,降低兩個任務之間噪聲影響。
模型的整體架構如下所示,目前,概念修飾關系整體準確率在85%左右:
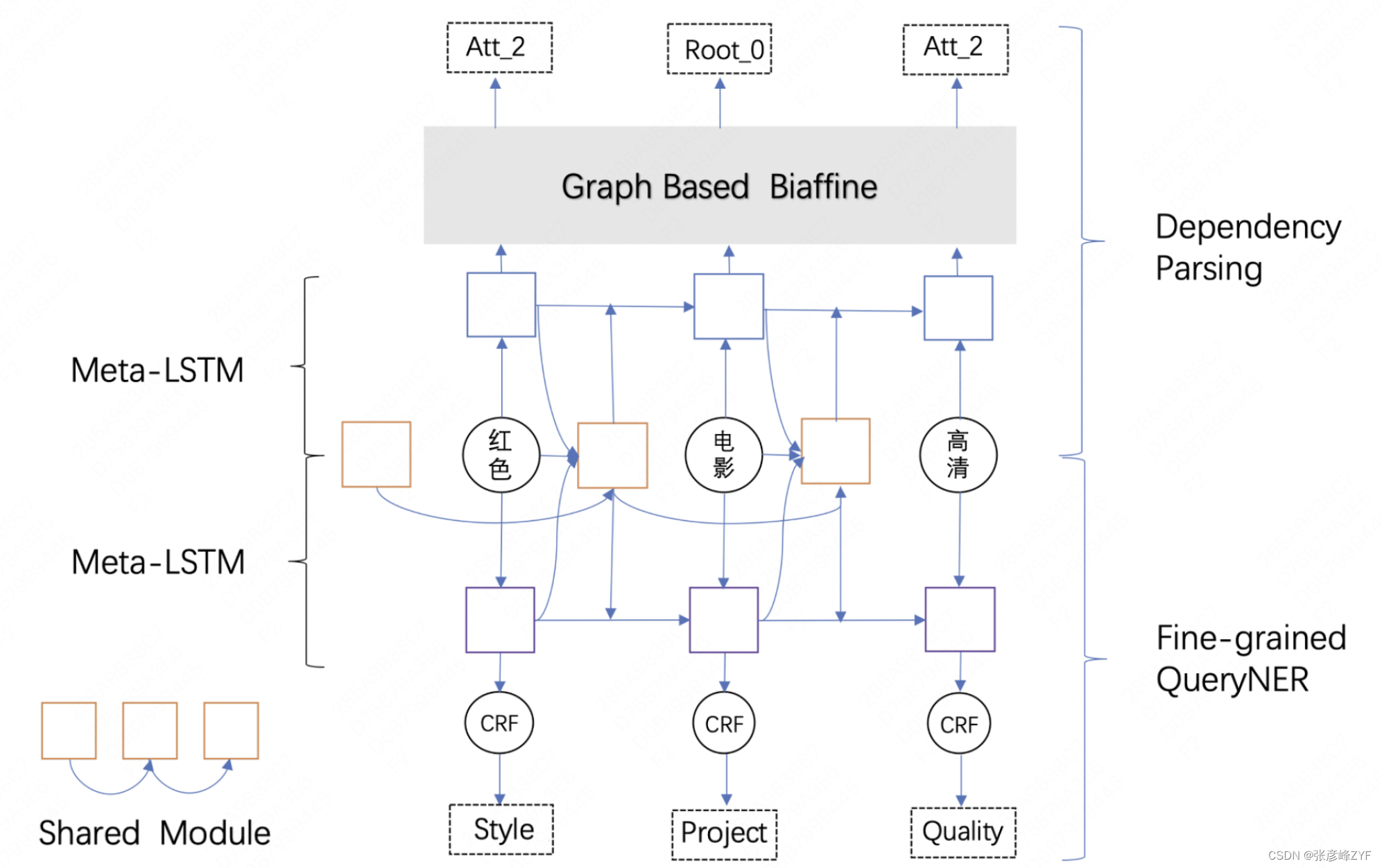
基于開放屬性詞挖掘特定屬性關系
開放屬性詞和屬性值的挖掘
開放屬性關系需要挖掘不同概念特有的屬性和屬性值,它的難點在于開放屬性和開放屬性值的識別。通過觀察數據發現,一些通用的屬性值(例如:好、壞、高、低、多、少),通常和屬性搭配出現(例如:環境好、溫度高、人流量大)。所以我們采取一種基于模板的Bootstrapping方法自動從用戶評論中挖掘屬性和屬性值,挖掘流程如下:
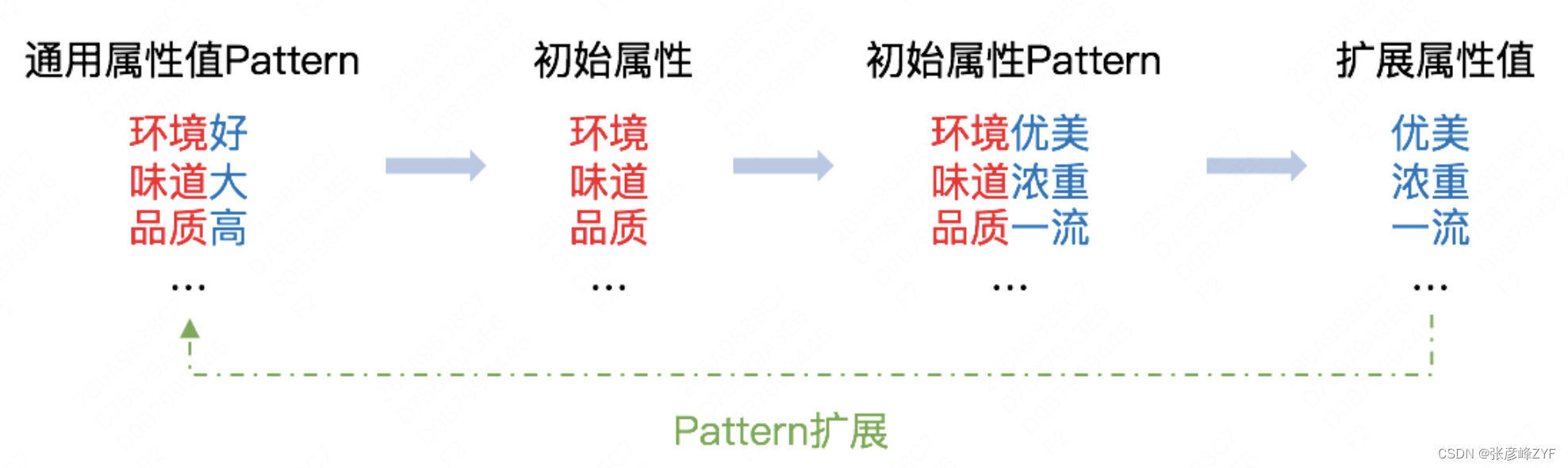
在挖掘了開放屬性詞和屬性值之后,開放屬性關系的挖掘拆分為「概念-屬性」二元組的挖掘和「概念-屬性-屬性值」三元組的挖掘。
概念-屬性的挖掘
「概念-屬性」二元組的挖掘,即判斷概念Concept是否含有屬性Property。挖掘步驟如下:
- 根據概念和屬性在UGC中的共現特征,利用TFIDF變種算法挖掘概念對應的典型屬性作為候選。
- 將候選概念屬性構造為簡單的自然表述句,利用通順度語言模型判斷句子的通順度,保留通順度高的概念屬性。
概念-屬性-屬性值的挖掘
在得到「概念-屬性」二元組后,挖掘對應屬性值的步驟如下:
- 種子挖掘。基于共現特征和語言模型從UGC中挖掘種子三元組。
- 模板挖掘。利用種子三元組從UGC中構建合適的模板(例如,“水溫是否合適,是選擇游泳館的重要標準。”)。
- 關系生成。利用種子三元組填充模板,訓練掩碼語言模型用于關系生成。
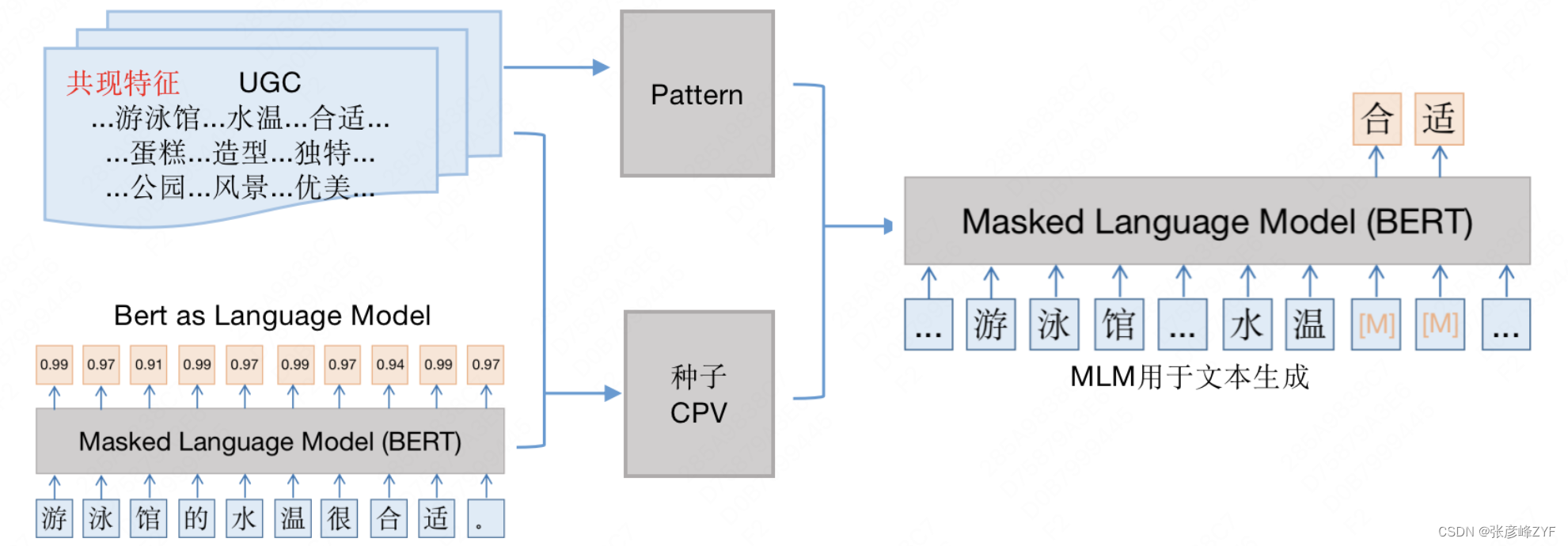
目前,開放領域的概念屬性關系準確率在80%左右。
(五)概念承接關系挖掘
概念承接關系是建立用戶搜索概念和美團承接概念之間的關聯。例如,當用戶搜索“踏青”時,真正的意圖是希望尋找“適合踏青的地方”,因此平臺通過“郊野公園”、“植物園”等概念進行承接。關系的挖掘需要從0到1進行,所以整個概念承接關系挖掘根據不同階段的挖掘重點設計了不同的挖掘算法,可以分為三個階段:①初期的種子挖掘;②中期的深度判別模型挖掘;③后期的關系補全。詳細介紹如下:
基于共現特征挖掘種子數據
為了解決關系抽取任務中的冷啟動問題,業界通常采用Bootstrapping的方法,通過人工設定的少量種子和模板,自動從語料中擴充數據。然而,Bootstrapping方法不僅受限于模板的質量,而且應用于美團的場景中有著天然缺陷。美團語料的主要來源是用戶評論,而用戶評論的表述十分口語化及多樣化,很難設計通用而且有效的模板。因此,我們拋棄基于模板的方法,而是根據實體間的共現特征以及類目特征,構建了一個三元對比學習網絡,自動從非結構化的文本中挖掘實體關系之間潛在的相關性信息。
具體來說,我們觀察到不同商戶類目下用戶評論中實體的分布差異較大。例如,美食類目下的UGC經常涉及到“聚餐”、“點菜”、“餐廳”;健身類目下的UGC經常涉及到“減肥”、“私教”、“健身房”;而“裝修”、“大廳”等通用實體在各個類目下都會出現。因此,我們構建了三元對比學習網絡,使得同類目下的用戶評論表示靠近,不同類目的用戶評論表示遠離。與Word2Vec等預訓練詞向量系統類似,通過該對比學習策略得到的詞向量層天然蘊含豐富的關系信息。在預測時,對于任意的用戶搜索概念,可以通過計算其與所有承接概念之間的語義相似度,輔以搜索業務上的統計特征,得到一批高質量的種子數據。
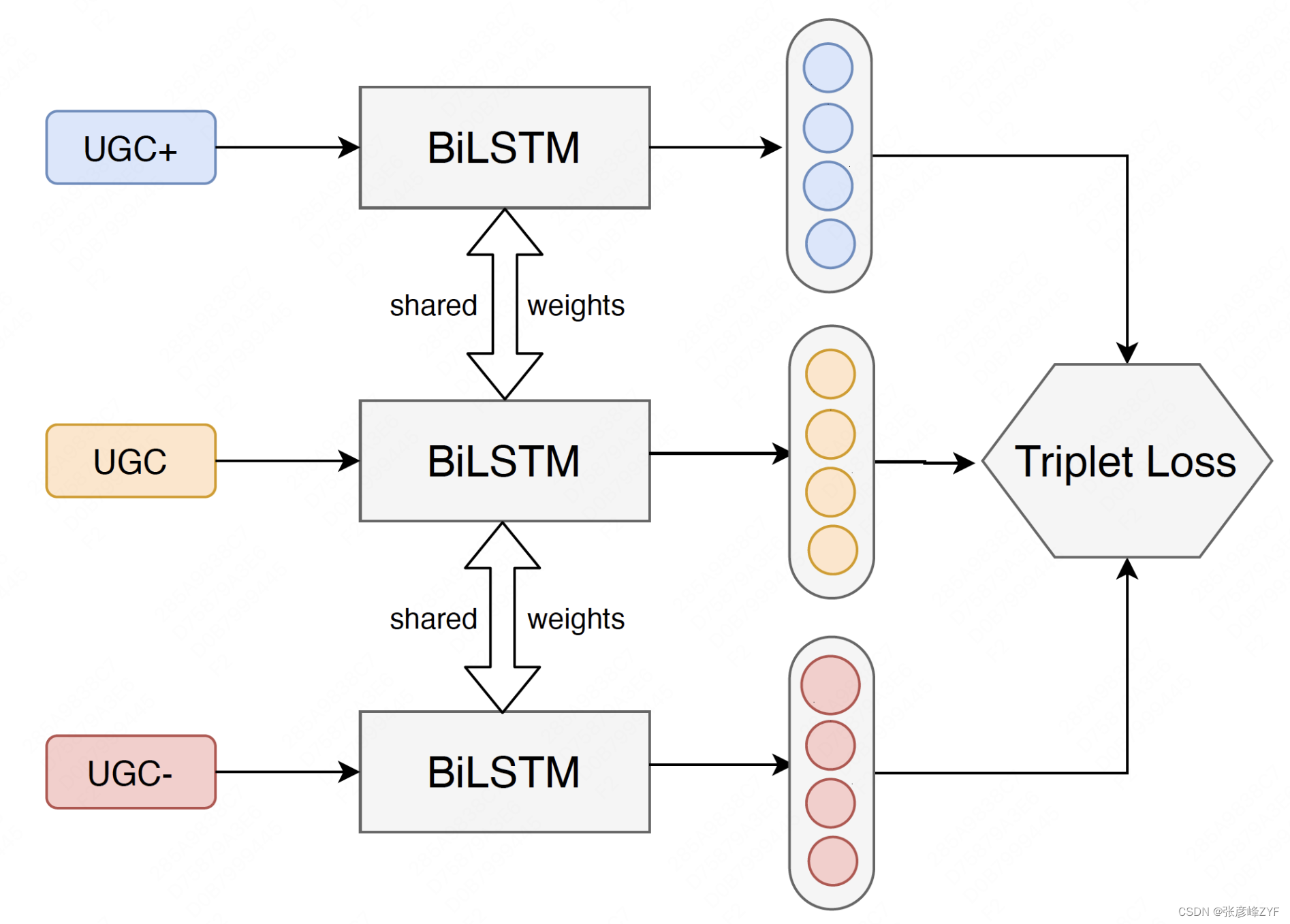
基于種子數據訓練深度模型
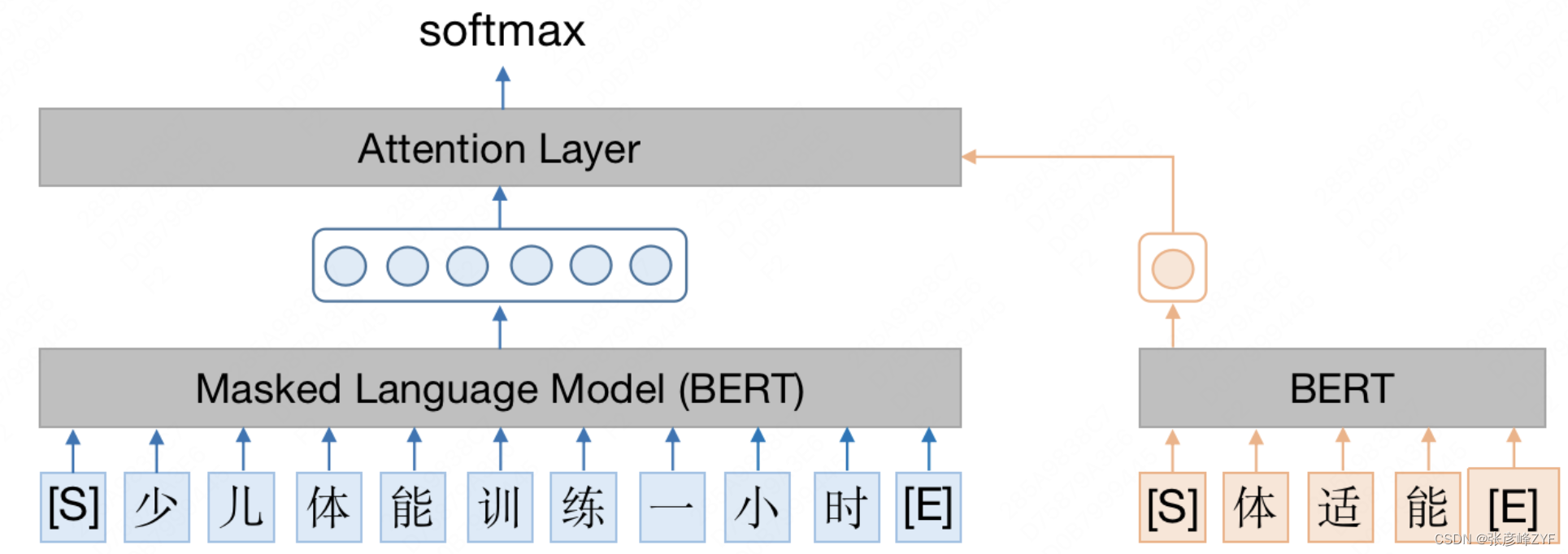
預訓練語言模型近兩年來在NLP領域取得了很大的進展,基于大型的預訓練模型微調下游任務,是NLP領域非常流行的做法。因此,在關系挖掘中期,我們采用基于BERT的關系判別模型(參考《美團BERT的探索和實踐》一文),利用BERT預訓練時學到的大量語言本身的知識來幫助關系抽取任務。
模型結構如下圖所示。首先,根據實體間的共現特征得到候選實體對,召回包含候選實體對的用戶評論;然后,沿用MTB論文中的實體標記方法,在兩個實體的開始位置和結束位置分別插入特殊的標志符號,經過BERT建模之后,將兩個實體開始位置的特殊符號拼接起來作為關系表示;最后,將關系表示輸入Softmax層判斷實體間是否含有關系。
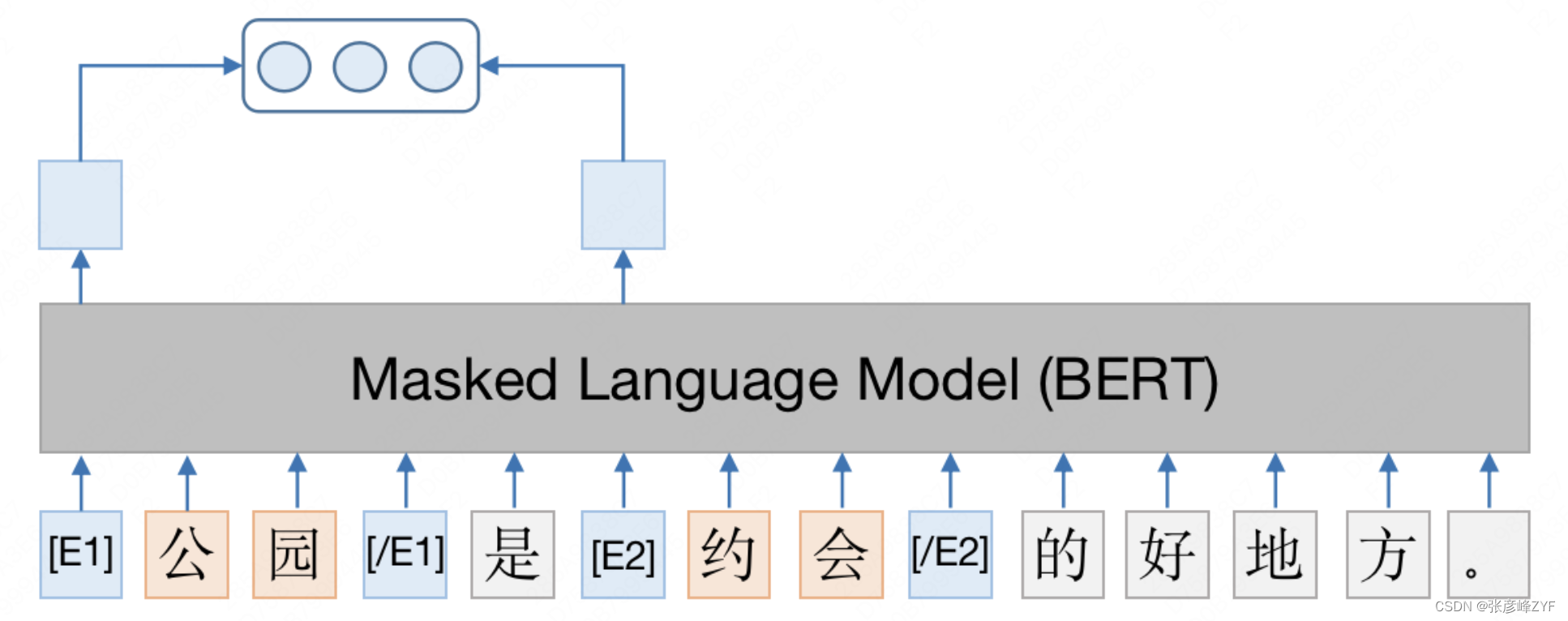
基于已有的圖譜結構進行關系補全
通過上述兩個階段,已經從非結構化的文本信息中構建出了一個初具規模的概念承接關系的圖譜。但是由于語義模型的局限性,當前圖譜中存在大量的三元組缺失。為了進一步豐富概念圖譜,補全缺失的關系信息,我們應用知識圖譜鏈接預測中的TransE算法以及圖神經網絡等技術,對已有的概念圖譜進行補全。
為了充分利用已知圖譜的結構信息,我們采用基于關系的圖注意力神經網絡(RGAT,Relational Graph Attention Network)來建模圖結構信息。RGAT利用關系注意力機制,克服了傳統GCN、GAT無法建模邊類型的缺陷,更適用于建模概念圖譜此類異構網絡。在利用RGAT得到實體稠密嵌入之后,我們使用TransE作為損失函數。TransE將三元組(h,r,t)中的r視為從h到t的翻譯向量,并約定h+r≈t。該方法被廣泛適用于知識圖譜補全任務當中,顯示出極強的魯棒性和可拓展性。
具體細節如下圖所示,RGAT中每層結點的特征由鄰居結點特征的均值以及鄰邊特征的均值加權拼接而成,通過關系注意力機制,不同的結點和邊具有不同的權重系數。在得到最后一層的結點和邊特征后,我們利用TransE作為訓練目標,對訓練集中的每對三元組(h,r,t),最小化||h+r=t||。在預測時,對于每個頭實體和每種關系,圖譜所有結點作為候選尾實體與其計算距離,得到最終的尾實體。目前概念承接關系整體準確率90%左右。
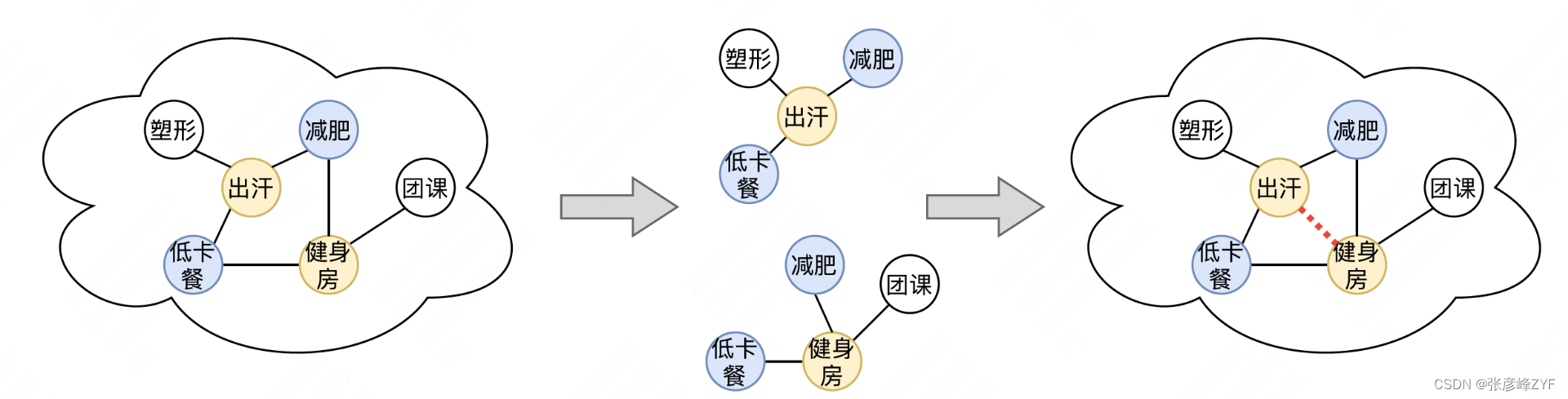
(六)POI/SPU-概念關系建設
建立圖譜概念和美團實例之間的關聯,會利用到POI/SPU名稱、類目、用戶評論等多個維度的信息。建立關聯的難點在于如何從多樣化的信息中獲取與圖譜概念相關的信息。因此,我們通過同義詞召回實例下所有與概念語義相關的子句,然后利用判別模型判斷概念與子句的關聯程度。具體流程如下:
- 同義詞聚類。對于待打標的概念,根據圖譜同義詞數據,獲取概念的多種表述。
- 候選子句生成。根據同義詞聚類的結果,從商戶名稱、團單名稱、用戶評論等多個來源中召回候選子句。
- 判別模型。利用概念-文本關聯判別模型(如下圖所示)判斷概念和子句是否匹配。
- 打標結果。調整閾值,得到最終的判別結果。
四、應用分析
(一)在美團內部的具體應用舉例
到綜品類詞圖譜建設
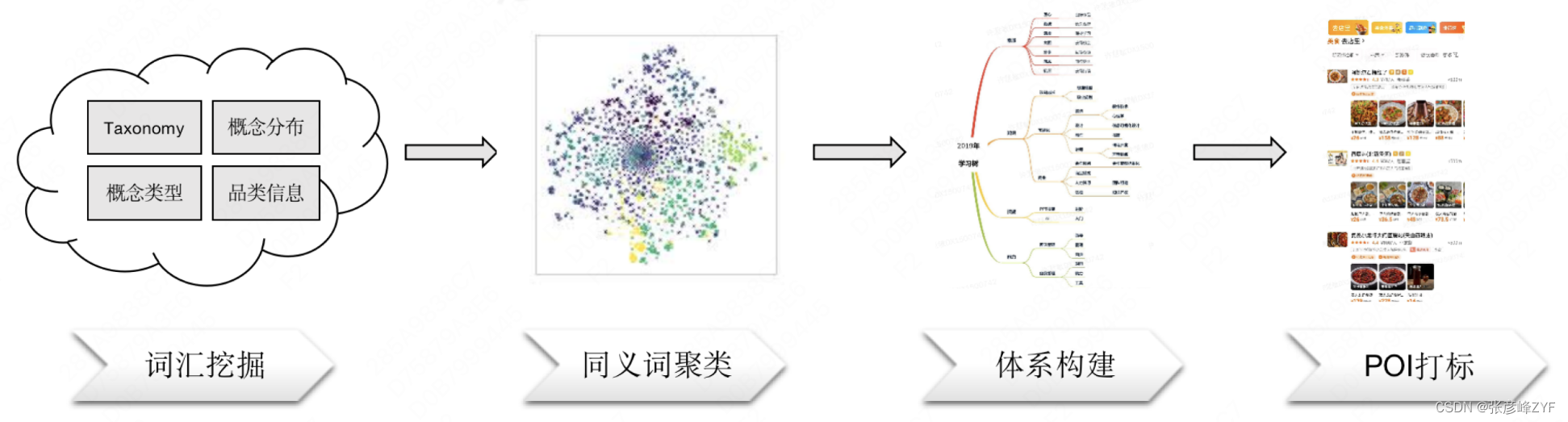
美團到綜業務涵蓋知識領域較廣,包含親子、教育、醫美、休閑娛樂等,同時每個領域都包含更多小的子領域,所以針對不同的領域建設領域內的知識圖譜,能夠輔助做好搜索召回、篩選、推薦等業務。
在常識性概念圖譜中除了常識性概念數據,同時也包含美團場景數據,以及基礎算法能力的沉淀,因此可以借助常識性圖譜能力,幫助建設到綜品類詞的圖譜數據。
借助常識性圖譜,補充欠缺的品類詞數據,構建合理的品類詞圖譜,幫助通過搜索改寫,POI打標等方式提升搜索召回。目前在教育領域,圖譜規模從起初的1000+節點擴展到2000+,同時同義詞從千級別擴展到2萬+,取得了不錯的效果。
品類詞圖譜建設流程如下圖所示:
點評搜索引導
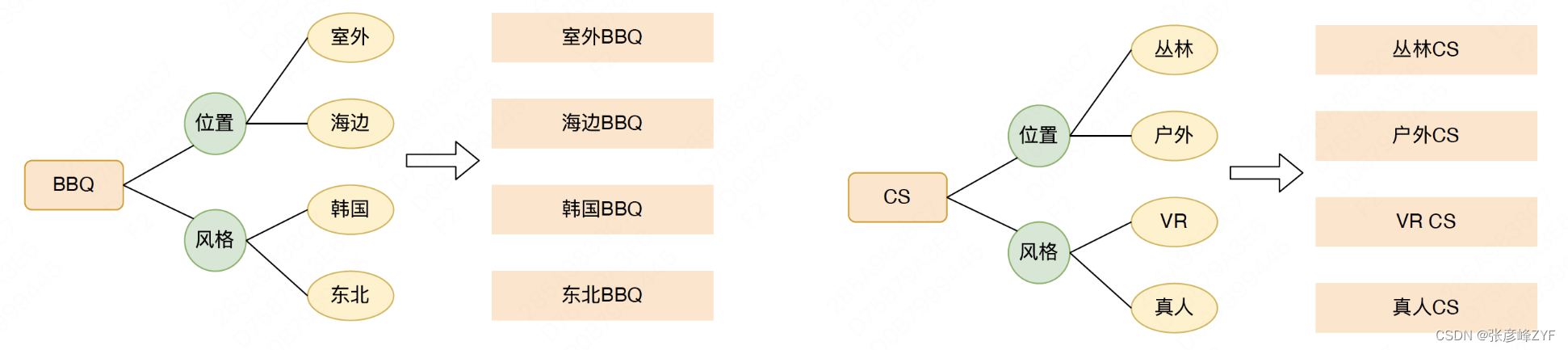
點評搜索SUG推薦,在引導用戶認知的同時幫助減少用戶完成搜索的時間,提升搜索效率。所以在SUG推薦上需要聚焦兩個方面的目標:①幫助豐富用戶的認知,從對點評的POI、類目搜索增加自然文本搜索的認知;②精細化用戶搜索需求,當用戶在搜索一些比較泛的品類詞時,幫助細化用戶的搜索需求。
在常識性概念圖譜中,建立了很豐富的概念以及對應屬性及其屬性值的關系,通過一個相對比較泛的Query,可以生成對應細化的Query。例如蛋糕,可以通過口味這個屬性,產出草莓蛋糕、芝士蛋糕,通過規格這個屬性,產出6寸蛋糕、袖珍蛋糕等等。
搜索引導詞Query產出示例如下圖所示:
到綜醫美內容打標
在醫美內容展示上,用戶通常會對某一特定的醫美服務內容感興趣,所以在產品形態上會提供一些不同的服務標簽,幫助用戶篩選精確的醫美內容,精準觸達用戶需求。但是在標簽和醫美內容進行關聯時,關聯錯誤較多,用戶篩選后經常看到不符合自己需求的內容。提升打標的準確率能夠幫助用戶更聚焦自己的需求。
借助圖譜的概念-POI打標能力和概念-UGC的打標關系,提升標簽-內容的準確率。通過圖譜能力打標,在準確率和召回率上均有明顯提升。
- 準確率:通過概念-內容打標算法,相比于關鍵詞匹配,準確率從51%提升到91%。
- 召回率:通過概念同義挖掘,召回率從77%提升到91%。
(二)業內領域的應用舉例
金融領域
在金融領域,常識性概念圖譜可以應用于風險控制、客戶服務、智能投顧等場景。例如,可以構建一個金融常識性概念圖譜,包含與金融領域相關的實體、屬性和關系,如銀行、金融產品、市場、投資等。然后,可以利用這個概念圖譜,提供風險控制模型的支持,進行風險評估和風險管理;通過智能投顧模型,根據客戶的風險偏好和投資目標,智能推薦最適合的投資方案。
醫療領域
在醫療領域,常識性概念圖譜可以應用于疾病診斷、藥物研發、醫療智能問答等場景。例如,可以構建一個醫療常識性概念圖譜,包含與疾病、藥物、癥狀、治療方法等相關的實體、屬性和關系。然后,可以利用這個概念圖譜,進行疾病診斷和藥物研發,幫助醫生更快、更準確地診斷疾病,同時也可以輔助藥物研發團隊進行藥物研發;通過醫療智能問答模型,回答患者關于癥狀、治療方法等方面的問題。
零售領域
在零售領域,常識性概念圖譜可以應用于商品推薦、用戶畫像、營銷策略等場景。例如,可以構建一個零售常識性概念圖譜,包含與商品、用戶、商店、品牌等相關的實體、屬性和關系。然后,可以利用這個概念圖譜,提供個性化商品推薦服務,幫助用戶更快、更準確地找到自己喜歡的商品;通過用戶畫像模型,了解用戶的購買行為和偏好,優化營銷策略和促銷活動。
智能交通領域
在智能交通領域,常識性概念圖譜可以應用于交通流量預測、路徑規劃、智能導航等方面。例如,可以構建一個常識性概念圖譜,包含各種交通實體、道路、交通標識、行駛規則等。然后,可以利用這個概念圖譜來進行交通流量預測,提供更準確的路徑規劃和智能導航服務,以及輔助交通管理部門制定更科學的交通管理策略。
阿里巴巴、騰訊
利用常識性概念圖譜來構建智能客服,提高客戶服務的效率和質量。常識性概念圖譜可以幫助機器理解自然語言中的指代、歧義等問題,更準確地回答用戶的問題,同時也可以幫助機器學習如何與人類進行自然交互。
字節跳動
字節跳動利用常識性概念圖譜來構建智能搜索和智能推薦系統。常識性概念圖譜可以幫助機器理解用戶搜索和瀏覽行為中的含義和目的,從而更好地推薦符合用戶興趣和需求的內容和產品。同時,常識性概念圖譜還可以輔助機器更好地處理多義詞和同義詞等問題,提高搜索和推薦的準確性和覆蓋率。
五、簡單模擬示例
(一)Neo4j知識圖譜數據庫查詢展示
使用Java語言連接Neo4j知識圖譜數據庫,并執行Cypher查詢語句的示例代碼
package org.zyf.javabasic.test;/*** @author yanfengzhang* @description* @date 2022/1/3 23:18*/
public class Neo4jExample {public static void main(String[] args) {// 連接到Neo4j數據庫String uri = "bolt://localhost:7687";String user = "neo4j";String password = "123456";Driver driver = GraphDatabase.driver(uri, AuthTokens.basic(user, password));Session session = driver.session();// 定義查詢語句,查找“蘋果”的描述String query = "MATCH (c:Concept{name:'蘋果'})-[:HasDescription]->(d:Description) RETURN d.content";// 執行查詢語句,返回結果StatementResult result = session.run(query);// 輸出查詢結果while (result.hasNext()) {Record record = result.next();String content = record.get("d.content").asString();System.out.println(content);}// 關閉數據庫連接session.close();driver.close();}
}
這段代碼使用了Neo4j官方提供的Java驅動程序,連接到一個Neo4j數據庫,然后執行了一個Cypher查詢語句,查找了知識圖譜中“蘋果”概念的描述,最后輸出查詢結果。
(二)學習建議建議和思路
- 學習常識性知識圖譜的構建方法和知識表示模型:了解常識性知識圖譜的構建方法和知識表示模型,可以幫助您理解常識性概念圖譜的內部結構和知識組織方式。相關的論文和研究報告可以幫助您深入了解這些知識。
- 探索常識性知識圖譜的應用場景:常識性知識圖譜可以應用于自然語言處理、智能問答、知識圖譜推理和智能對話等領域。您可以根據自己的興趣和專業背景,選擇相應的應用場景進行深入學習和研究。
- 學習常識性知識圖譜的應用技術和工具:常識性知識圖譜的應用技術和工具包括知識圖譜數據庫、知識圖譜查詢語言、知識圖譜可視化工具和自然語言處理工具等。掌握這些技術和工具,可以幫助您更加高效地進行常識性概念圖譜的應用開發和實踐。
- 參與相關的開源社區和項目:許多開源社區和項目已經開始使用常識性知識圖譜進行應用開發和實踐,您可以通過參與這些社區和項目,獲取更多的經驗和知識,并與同行進行交流和合作。
- 實踐和應用常識性知識圖譜:最后,通過實踐和應用常識性知識圖譜,您可以進一步深入了解常識性概念圖譜的應用價值和技術挑戰,并掌握更多的實際應用經驗。可以選擇一些開源的常識性知識圖譜項目進行實踐,或者參加一些相關的實戰培訓和競賽,提升自己的實踐能力和應用水平。
六、總結
常識性概念圖譜的構建不僅是人工智能研究中的一項技術創新,更是推動智能問答系統發展的關鍵因素。通過對人類常識的系統化整理和結構化表示,我們能夠使機器更好地理解并應用這些知識,從而實現更準確、更智能的問答和決策支持。本文探討了概念圖譜的構建過程、應用場景及其在智能問答系統中的實際效果,展示了常識性知識對提升機器智能的重要性。展望未來,隨著技術的不斷進步和數據資源的日益豐富,常識性概念圖譜將在更多領域發揮更大作用,推動智能化服務向更高水平發展。我們期待這一領域的進一步探索,期待智能問答系統在日常生活中的更廣泛應用,為人類社會帶來更多便利與可能。
參考文獻、書籍及鏈接
- 阿里巴巴:《阿里大數據科學家王斌:常識性概念圖譜與自然語言理解》鏈接:https://www.infoq.cn/article/2xcwnnybpjmml7zqxrlt
- MATLAB算法實戰應用-【應用案例篇】常識性概念圖譜建設以及在美團場景中的應用_matlab實戰案例_林聰木的博客-CSDN博客
- 知識圖譜構建全流程_知識圖譜構建過程_曾小健量化博士Dr的博客-CSDN博客
- 字節跳動:《字節跳動技術專家分享:基于圖譜的智能搜索和推薦系統》https://www.infoq.cn/article/Cfn6Y3bgqEPU6-krGMQh
- 《知識圖譜(Knowledge Graph)之美團應用實踐》:介紹了美團在知識圖譜方面的應用實踐,包括知識圖譜的構建、應用場景、技術架構等方面。
- 《知識圖譜(Knowledge Graph)在阿里的實踐》:介紹了阿里在知識圖譜方面的應用實踐,包括知識圖譜的構建、應用場景、技術架構等方面。
- 《騰訊知識圖譜的應用實踐》:介紹了騰訊在知識圖譜方面的應用實踐,包括知識圖譜的構建、應用場景、技術架構等方面。
- 知識圖譜在企業智能化中的應用:本文介紹了知識圖譜在企業智能化中的應用,并以企業知識管理、智能問答系統為例,詳細闡述了知識圖譜的應用流程、技術架構和實現方法。
- 如何用知識圖譜助力企業數字化轉型:本文介紹了知識圖譜在企業數字化轉型中的應用,包括企業數據整合、知識管理、智能問答系統等方面,并提出了如何選擇知識圖譜技術供應商和技術方案的建議。
- 智能客服如何用上知識圖譜,降低服務成本,提升用戶體驗:本文介紹了知識圖譜在智能客服領域的應用,包括知識庫構建、語義理解、智能問答等方面,并提出了如何應對實際場景中的挑戰和優化知識圖譜的方法。






![[docker]更新容器中鏡像版本](http://pic.xiahunao.cn/[docker]更新容器中鏡像版本)












