202502 arxiv
1 intro
- 多智能體辯論(Multi-Agent Debate, MAD):通過讓多個智能體在大模型推理時展開多輪辯論,可提升生成內容的事實準確性和推理質量
- 但論文認為,目前多智能體辯論在大多數情況下不敵簡單的單智能體方法 Chain-Of-Thought
- 在 36 種實驗配置(覆蓋 9 個常見數據集與 4 種大模型)中,MAD 的勝率不足 20%。
- 但論文認為,目前多智能體辯論在大多數情況下不敵簡單的單智能體方法 Chain-Of-Thought
- ——>論文提出Heter-MAD,通過簡單引入異構模型智能體,無需修改現有 MAD 框架即可穩定提升性能(最高達 30%)
2 主要結論
- 選取了?
- 5 種具有代表性的 MAD 框架
- SoM、MP、EoT、ChatEval 和 AgentVerse
- 9 個涵蓋通用知識、數學推理和編程能力的基準數據集
- ?4 個基礎模型
- GPT-4o-mini、Claude-3.5-haiku、Llama3.1-8b/70b
- 兩種baseline
- Chain-of-Thought;self-consistency
- 評估指標
- 性能、效率和魯棒性
- 5 種具有代表性的 MAD 框架
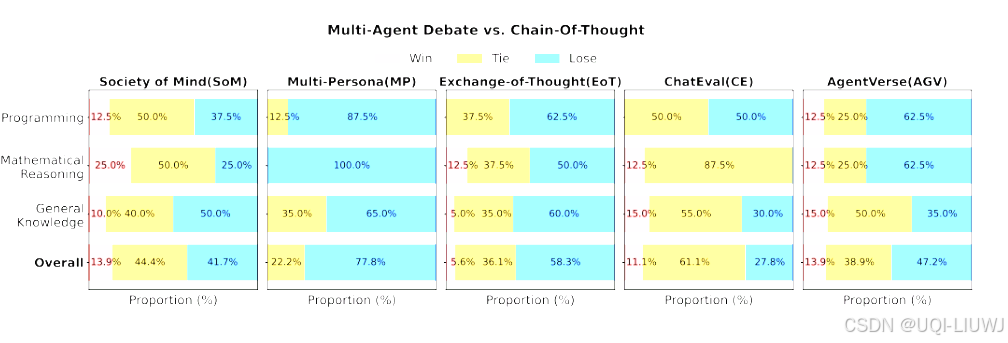
- 在 36 個測試場景中,MAD 方法僅在不到 20% 的情況下優于CoT,更別說SC了
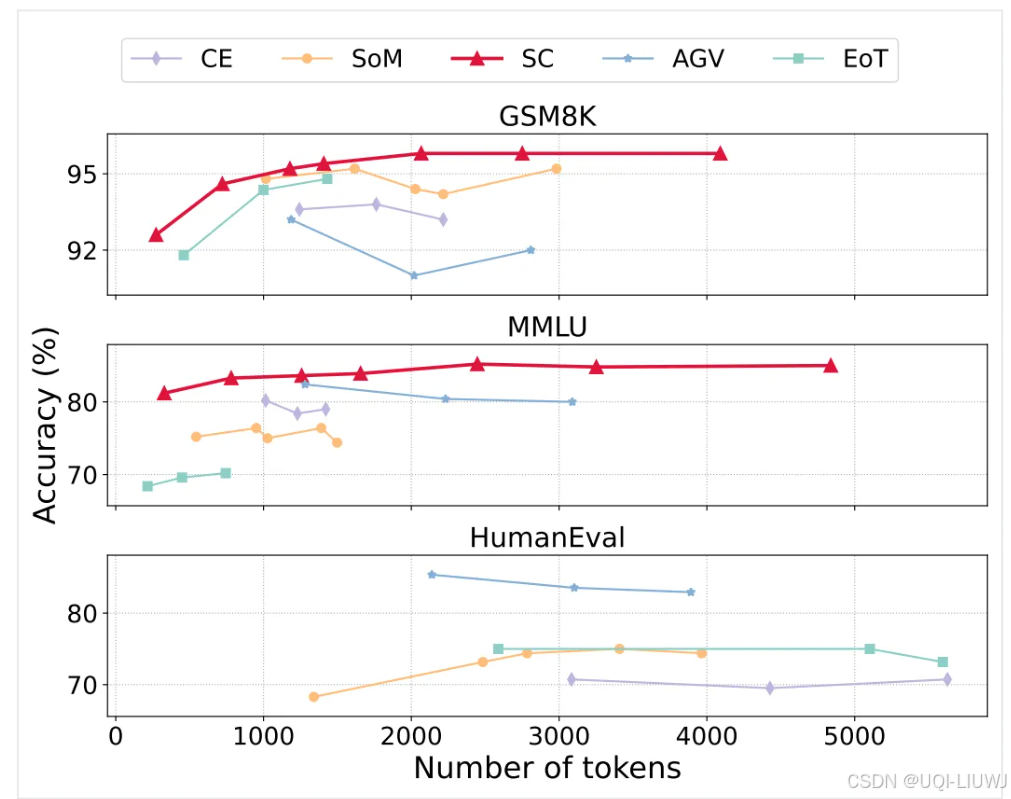
- MAD 方法消耗了更多的 token,但未能帶來穩定的性能提升????????
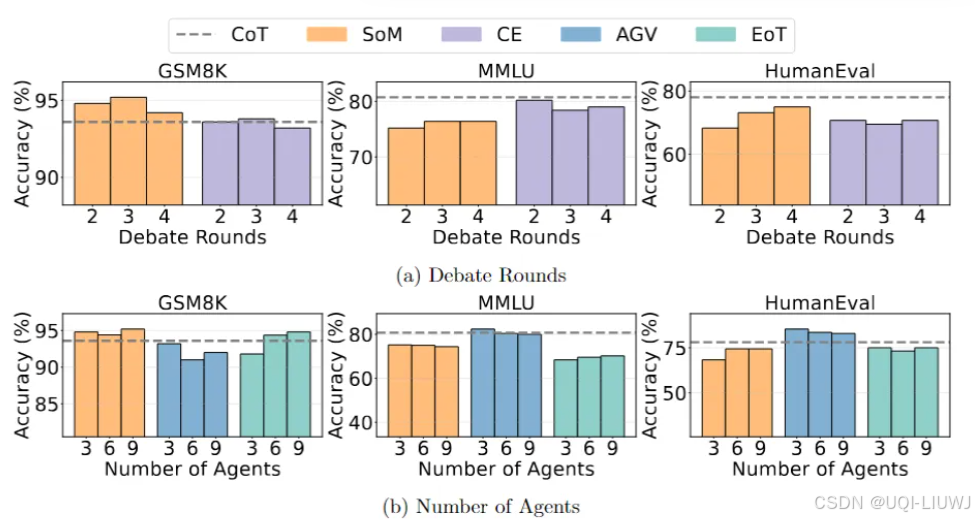
- 增加智能體數量或辯論輪次并未顯著改善 MAD 的表現
3 異構MAD效果
- 論文認為,人類協作成功的關鍵在于個體多樣性
- 但現有 MAD 方法大多使用同一模型的多個實例進行評測,忽視了模型多樣性可能帶來的性能提升
- ——>提出了 Heter-MAD 方法:在MAD 框架中,每個 LLM 智能體隨機從異構模型池中選擇模型生成答案
- 無需改變現有 MAD 框架結構,卻能顯著且穩定地提升性能
)
關于窗體的右鍵菜單的學習與使用,這關系到了信號與事件 event)
)








:互相引用)


注冊教程)




