目錄
探會——第三屆 OceanBase 開發者大會
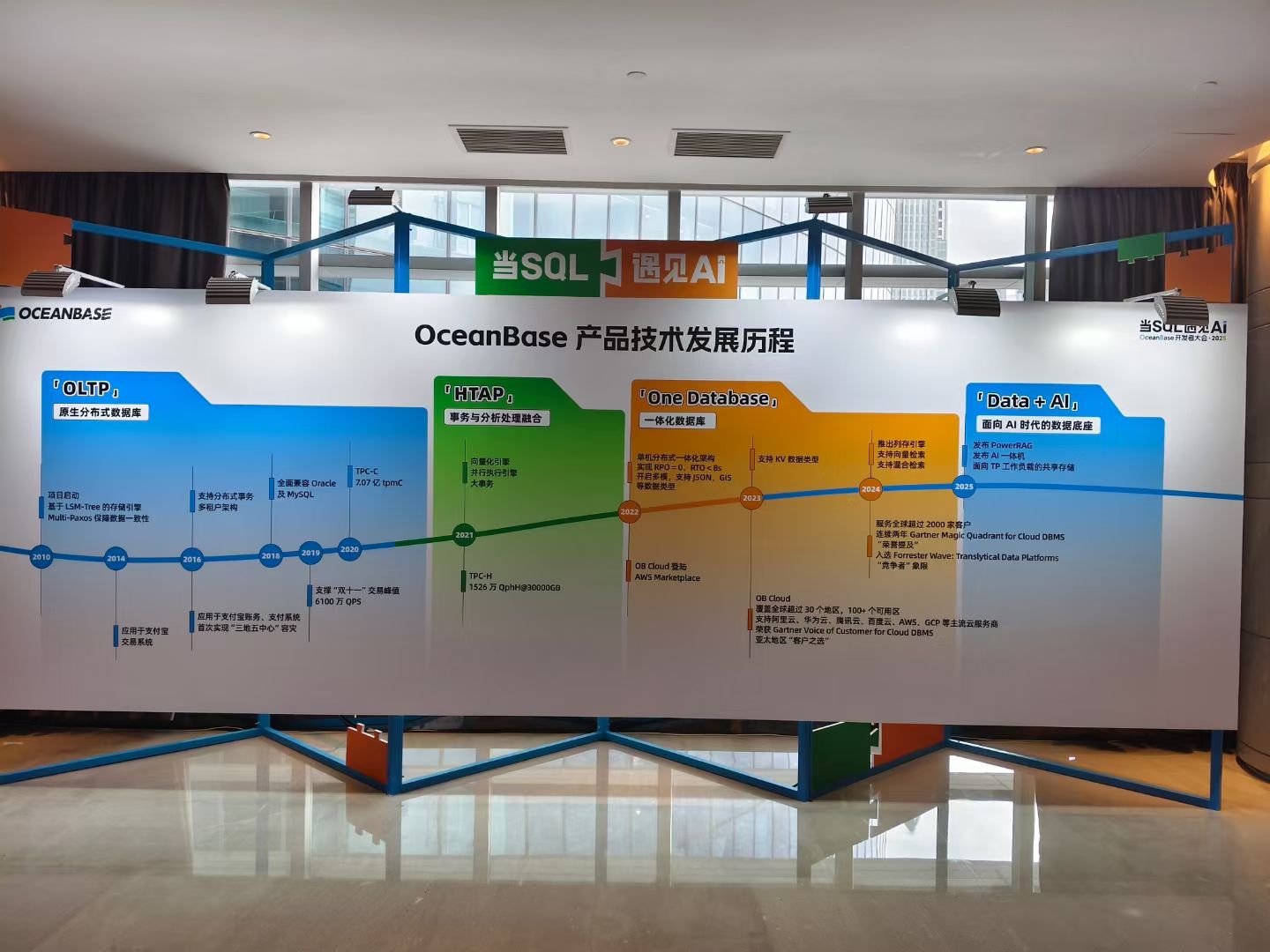
重磅發布:OceanBase 4.3
開發者生態全面升級
實戰演講:用戶案例與行業落地
OceanBase 共享存儲架構解析
什么是共享存儲架構?
云原生數據庫的架構
性能、彈性與多云的統一
為何OceanBase能征服OLTP生產級挑戰?
環境準備與基礎配置
核心功能配置與優化
典型場景應用指南
運維與監控
OceanBase 共享存儲使用步驟
ASCII字符示意圖
整體布局(分層結構)
探會——第三屆 OceanBase 開發者大會
2025年5月17日,第三屆 OceanBase 開發者大會在廣州州順利舉辦。作為國內領先的原生分布式數據庫解決方案提供者,OceanBase 本屆大會以“數聚生態,智算未來”為主題,吸引了來自全國各地的數據庫專家、開發者及生態合作伙伴齊聚一堂,共同探討分布式數據庫領域的最新技術演進與應用實踐。
重磅發布:OceanBase 4.3
本次大會最受矚目的焦點之一是 OceanBase 4.3 的正式發布。新版本在原有架構基礎上實現了關鍵性能提升,支持更加復雜的多活部署場景,并大幅優化了存儲引擎性能,進一步降低讀寫延遲。同時,在兼容性方面也向 Oracle、MySQL 更進一步,助力企業更加平滑地遷移和使用。
OceanBase 技術負責人表示,4.3 版本引入了更智能的資源調度機制與彈性算力架構,使得 OceanBase 在應對金融、政務等對一致性與高可用性有極高要求的場景中更為穩定與高效。
開發者生態全面升級
大會設置了多個技術專場,覆蓋 數據庫內核優化、SQL引擎調優、運維監控體系、多云部署實踐 等議題。在“內核與架構專場”中,OceanBase 團隊分享了有關 LSM Tree 引擎優化、寫放大控制、分布式事務一致性協議等前沿技術。
此外,OceanBase 官方宣布了 開源社區生態激勵計劃升級,鼓勵更多開發者參與到代碼貢獻、文檔完善、插件開發中來。目前 OceanBase GitHub Star 數已突破 2 萬,社區活躍度持續攀升,形成了更具凝聚力的開發者生態圈。
實戰演講:用戶案例與行業落地
除了官方演講等企業的技術專家也登臺分享了 OceanBase 在各自業務中的落地經驗。例如,在面對“雙十一”億級交易高并發場景時,OceanBase 通過彈性擴容和全局一致性保障,實現了毫秒級響應與零故障穩定運行,為電商業務保駕護航。
這些用戶故事不僅驗證了 OceanBase 的技術實力,也為其他企業提供了寶貴的參考范例。




第三屆 OceanBase 開發者大會是一場技術與生態的雙重盛會。從 4.3 版本的發布,到開源生態的深化,再到實踐案例的展示,OceanBase 向業界展示了它作為國產數據庫中堅力量的技術演進路徑與未來愿景。
在“智算未來”的浪潮下,OceanBase 將繼續深化分布式數據庫底層能力的打磨,推動更多企業實現自主可控的數據基礎設施建設,賦能數字中國的加速發展。
第三屆 OceanBase 開發者大會,既是一場技術深耕的展示,也是一場生態共建的盛會。從 4.3 版本的功能躍遷,到 開源生態的全方位升級,再到 實際行業用戶的成功落地案例,OceanBase 展現出其作為國產數據庫中堅力量的技術進化路徑與產業影響力。
站在“智算未來”的時代交匯點,OceanBase 將持續推進分布式數據庫底層能力的打磨,深化計算與存儲解耦、智能調度、跨云部署等核心能力,賦能企業實現 真正的云原生架構升級,并在自主可控的數字基礎設施建設進程中發揮更大作用。
OceanBase 共享存儲架構解析
什么是共享存儲架構?
傳統 OceanBase 采用的是“本地盤 + 多副本”的 Share-Nothing 架構:每個副本節點持有自己獨立的存儲和計算資源。雖然具備強一致性和高可用性,但也存在 數據復制開銷大、寫放大嚴重、資源利用率偏低 等問題。
OceanBase 共享存儲架構引入了 計算與存儲分離 的理念,多個計算節點可以訪問同一個后端存儲。其關鍵特征包括:多租戶共享統一存儲池,持久化數據只保存一份,副本間元數據分離,數據共享,支持即開即用,秒級彈性擴容。
這一轉變實現了從 Share-Nothing 向 Share-Disk/Share-Storage 的跨越,尤其適用于資源緊張或高密度部署場景。
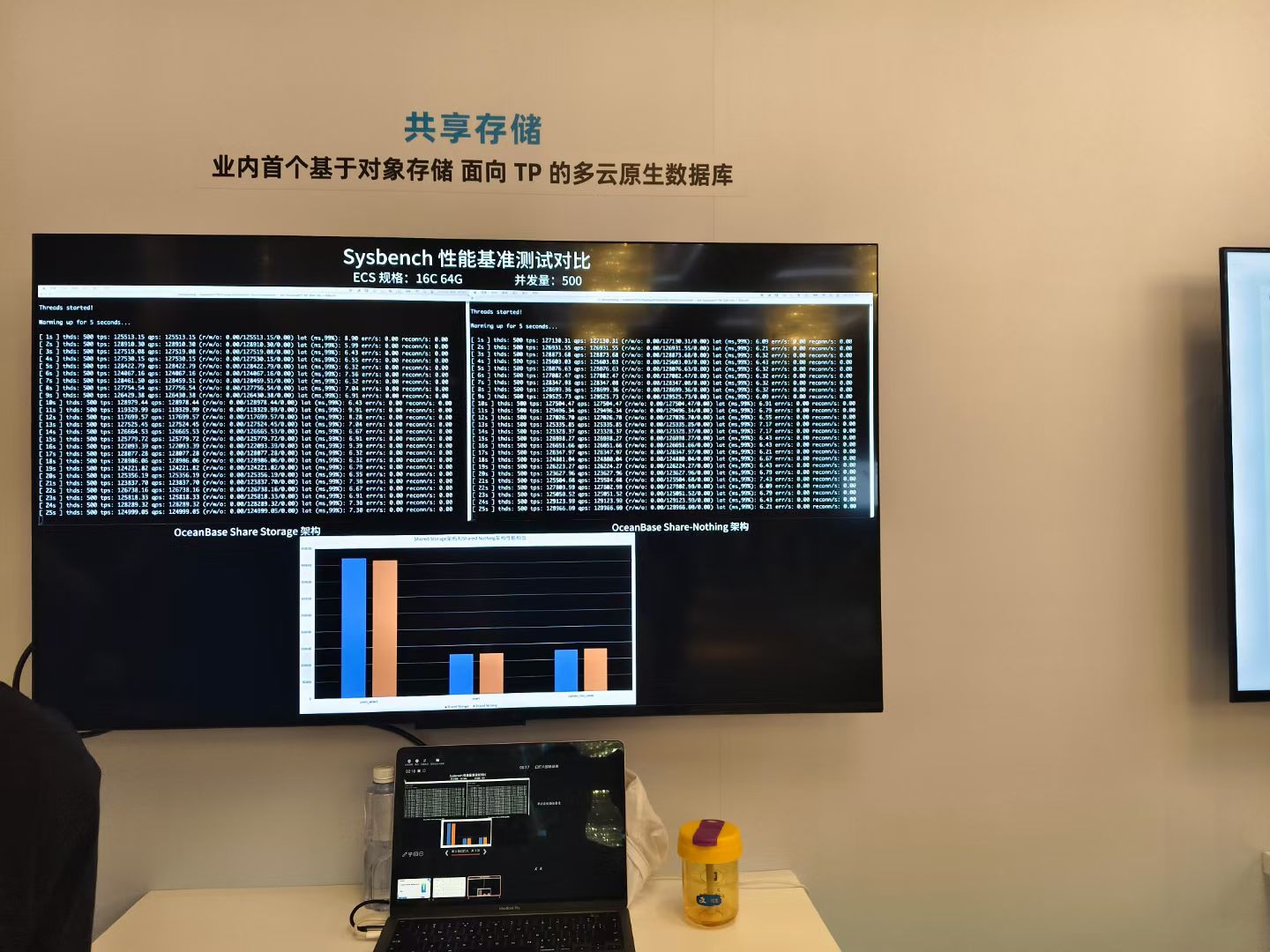
云原生數據庫的架構
在云計算時代,對象存儲憑借高可靠性、低成本、無限擴展的優勢,已成為海量數據存儲的核心方案,但其在事務型數據庫(TP)領域的應用長期受限。傳統TP數據庫普遍采用Shared-Nothing架構,依賴本地磁盤或云盤保障低延遲與高并發性能,卻也帶來擴縮容低效、存儲冗余度高、成本壓力大等問題。
OceanBase作為原生分布式數據庫的領軍者,以存算解耦為核心突破,推出業內首個面向OLTP場景的共享存儲產品。通過將計算層與存儲層分離,OceanBase首次實現事務型數據庫與對象存儲(如Amazon S3、阿里云OSS等)的深度融合,在保持強一致性、毫秒級響應的同時,將TP場景的存儲成本降低50%,AP場景成本甚至可降至原方案的1/10。
性能、彈性與多云的統一
極致性價比:性能無損,成本減半
通過“對象存儲+多級緩存”架構,OceanBase將全量數據落地于低成本對象存儲,僅需單副本即可保障跨可用區的高可用性;熱數據通過本地SSD緩存實現快速訪問,冷數據自動下沉至對象存儲,存儲成本直降50%。
Serverless彈性:計算與存儲獨立擴展
支持計算節點秒級擴縮容,存儲層容量無限擴展。結合Spot實例技術,計算資源成本最高可降低70%,實現“存儲不動、計算隨需”的云原生體驗。
多云原生:打破云廠商鎖定
全面兼容Amazon S3、阿里云OSS等主流對象存儲協議,覆蓋阿里云、華為云、AWS等六大公有云平臺,全球超100個可用區,為企業提供跨云、混合云的統一數據底座。
為何OceanBase能征服OLTP生產級挑戰?
對象存儲的高延遲與低IOPS特性曾是其適配OLTP場景的“死穴”,OceanBase通過四項核心技術實現破局:
多級緩存架構:
內存緩存:承載最熱數據,保障毫秒級響應;
本地持久化緩存+分布式緩存:通過預讀預熱、節點間同步機制,彌補對象存儲訪問延遲;
對象存儲:作為無限容量的冷數據底座。
自研LSM-Tree引擎:
針對對象存儲“只追加、不修改”的特性,優化寫入路徑,聚合小I/O為順序大塊寫入,降低寫放大與存儲壓力,提升IOPS效率。
動態彈性緩存:
本地緩存空間隨負載自動擴縮,智能識別熱點數據,避免資源浪費,應對業務流量波動。
全鏈路優化:
從I/O調度、預取策略到跨可用區同步機制,全面壓低延遲波動,確保TP業務穩定性。
環境準備與基礎配置
云平臺接入
OceanBase 共享存儲已支持阿里云、華為云、騰訊云、百度云、AWS、Google Cloud 六大公有云平臺,覆蓋全球超 100 個可用區。用戶需在目標云平臺創建 OceanBase 實例,并綁定兼容 S3 協議的對象存儲服務(如 Amazon S3、阿里云 OSS)作為持久化存儲層。
存儲與計算資源規劃
存儲層:將全量數據落地至對象存儲,僅需單副本即可保障跨可用區高可用性。
計算層:按需分配計算節點,支持秒級彈性擴縮容,結合 Spot 實例可節省最高 70% 計算成本。
核心功能配置與優化
多級緩存架構設置
內存緩存:自動緩存最熱數據(如近 30 天訂單),保障毫秒級響應。
本地持久化緩存:將高頻訪問數據緩存在本地 SSD,通過預讀預熱機制減少對象存儲訪問延遲。
分布式緩存:支持節點間數據同步,確保容災恢復能力。
冷熱數據分層策略
自動識別冷熱數據(如淘寶訂單場景中,近 30 天為熱數據,歷史數據為冷數據),熱數據緩存在本地,冷數據自動下沉至對象存儲。
配置示例:通過 SQL 或管理控制臺設置數據生命周期策略,例如按時間閾值(如 30 天)自動遷移冷數據。
LSM-Tree 引擎優化
寫入優化:聚合小 I/O 為順序大塊寫入,適配對象存儲“只追加、不修改”特性,降低寫放大。
異步落盤:通過后臺任務處理 Compaction、備份等重 I/O 操作,減少對實時事務的影響。
典型場景應用指南
核心 TP 與歷史庫
場景示例:電商訂單系統將全量數據存入對象存儲,僅緩存近期熱數據,存儲成本降低 50%,歷史數據查詢仍保持秒級響應。
操作步驟:
創建歷史表并設置冷熱分離策略。
通過 OceanBase 控制臺配置自動緩存規則,指定熱數據保留周期。
時序數據(IoT/智能制造)
場景示例:智能設備監控數據寫入頻繁,短期查詢為主,長期存儲成本需優化。
配置方法:
啟用自動冷熱識別,將超過指定時間(如 7 天)的數據標記為冷數據。
結合分布式緩存提升寫入吞吐量。
HBase 兼容與流水型業務
遷移方案:將 HBase 冷數據遷移至 OceanBase 共享存儲,保留強一致性事務能力,存儲成本降至原方案的 1/10。
流水型數據管理:
配置流水表按時間分區,自動歸檔舊分區至對象存儲。
使用 Serverless 計算節點按需處理高頻寫入。
運維與監控
彈性伸縮管理
計算層:通過控制臺或 API 動態調整計算節點數量,支持業務高峰期的資源彈性。
緩存層:啟用持久化緩存彈性伸縮功能,本地緩存空間隨負載自動擴縮。
全鏈路監控
通過 OceanBase 內置監控工具,實時跟蹤對象存儲訪問延遲、緩存命中率及 I/O 壓力。
設置告警閾值(如延遲超過 10ms),及時
優化緩存策略或調整資源分配。
OceanBase 共享存儲使用步驟
1、環境準備
支持平臺:阿里云、AWS、華為云等(需開通對象存儲服務,如 OSS/S3)
操作:獲取對象存儲的 Access Key 和 Bucket 名稱
在 OceanBase 控制臺創建 共享存儲卷,綁定對象存儲地址
2、 創建數據庫與表
示例:電商訂單表(自動冷熱分離)
-- 創建數據庫
CREATE DATABASE orders_db STORAGE_POLICY = 'HOT_COLD'; -- 啟用冷熱分層策略-- 創建訂單表(按時間分區)
CREATE TABLE orders (order_id BIGINT PRIMARY KEY,order_time DATETIME,data JSON
) PARTITION BY RANGE(order_time) (PARTITION p_hot VALUES LESS THAN (CURRENT_DATE - INTERVAL 30 DAY), -- 熱數據分區PARTITION p_cold VALUES LESS THAN (MAXVALUE) -- 冷數據自動存對象存儲
);3、冷熱數據管理
自動策略:
數據寫入時自動按分區規則分離(如超過30天的訂單自動存對象存儲)
手動遷移:
-- 將歷史數據批量遷移至對象存儲
ALTER TABLE orders MOVE PARTITION p_old TO STORAGE 'S3';4、彈性與監控
計算節點擴容:
# 從2節點擴展到4節點(10秒完成)
obd cluster scale-out ob_shared --servers=2查看存儲狀態:
-- 查看冷熱數據分布
SELECT partition_name, storage_type, total_size
FROM information_schema.table_storage
WHERE table_name = 'orders';-- 監控緩存命中率
SHOW STATUS LIKE 'cache_hit_ratio%';5、注意
首次使用建議開啟 自動緩存伸縮(SET GLOBAL auto_cache_scaling=ON;)
高頻寫入場景可調整 I/O塊大小(SET GLOBAL s3_block_size='64MB';)
免費工具:OceanBase 冷熱遷移助手
ASCII字符示意圖
+-------------------+ +-------------------+
| 計算節點集群 | | 計算節點集群 |
| (無狀態,彈性伸縮) | <--> | (秒級擴容/釋放) |
+-------------------+ +-------------------+↓
+--------------------------------+
| 多級緩存層 |
| ---------------------------- |
| [內存緩存]🔥熱數據(毫秒級) |
| [本地SSD]?高頻訪問數據 |
| [分布式緩存]🌐節點間同步 |
+--------------------------------+↓
+--------------------------------+
| 共享對象存儲 |
| (S3/OSS,單副本跨AZ) |
| ▼ 存儲成本降低50% |
+--------------------------------+整體布局(分層結構)
+------------------------------+
| 計算層 |
| [無狀態節點集群] |
| - 支持秒級擴縮容 |
| - Spot實例節省70%成本 |
+--------------|---------------+↓
+------------------------------+
| 多級緩存層 |
| +---------+ +---------+ |
| | 內存緩存 | | 本地SSD | | ← 熱數據(自動緩存)
| +---------+ +---------+ |
| +---------------------+ |
| | 分布式緩存集群 | | ← 跨節點同步
| +---------------------+ |
+--------------|---------------+↓
+------------------------------+
| 共享存儲層 |
| [對象存儲 S3/OSS] |
| - 單副本跨AZ高可用 |
| - 存儲成本降低50% |
+------------------------------+

的崛起——品牌如何被大模型收錄)

)














)