我們學習過順序表時,一旦對頭部或中間的數據進行處理,由于物理結構的連續性,為了不覆蓋,都得移,就導致時間復雜度為O(n),還有一個潛在的問題就是擴容,假如我們擴容前是100個大小的元素空間,一旦擴容以后(我們就說二倍的擴),那就是200,但我們實際上就只存105個元素,那不就有95個元素所對應的空間被浪費了嗎?怎樣才能解決這樣的問題呢?
帶著疑問,來學習線性表的其中之一,鏈表。
一、鏈表
鏈表是物理存儲結構上非連續的線性表,數據元素的邏輯順序是通過鏈表中的指針來實現的。
按照指針方向鏈表分為單向鏈表,雙向列表和循環鏈表。
按內存管理的話還是靜態鏈表和動態鏈表
二、單鏈表
本次就進行單鏈表的學習。
1.單鏈表概述
單鏈表一般作Single List
單鏈表是什么東西呢?
單鏈表就好像是火車一樣,火車的每個單位是車廂,車頭是動力,車廂與車廂之間存在有結構連接。
為什么要這么對比呢?
單鏈表的基本單位就是結點,結點與結點之間由指針連接起來,這是靜態的看;火車在淡旺季可以選擇加車廂和減車廂,而我們的單鏈表對應的操作就是增加或者刪除結點。
單鏈表屬于鏈表,根據指針的方向取名單鏈表,單鏈表結點間的指針方向是只有一個的。

我們在申請順序表的大小的時候用的是realloc,第一個參數是需要修改的內存的地址,第二個參數是改為的內存空間的大小,這個內存空間我們申請的時候直接是一整塊全部申請下來,但是對于單鏈表則不同,如上面畫的圖,我們每次申請都僅僅申請一個結點,任意取出來邏輯上相鄰的兩個結點:
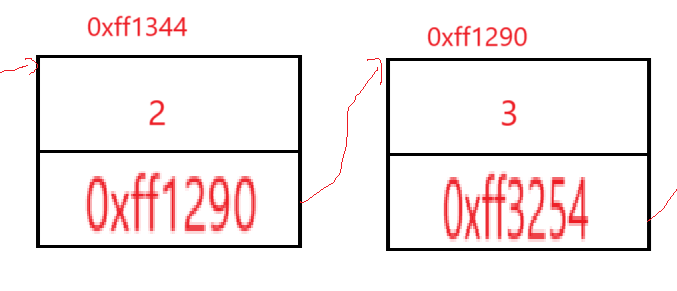
現在視角落在存儲了整型2的這個結點上,這個結點存儲了兩個東西,一個是數據,一個是下一個結點的地址,由此我們的單鏈表的結點就是一個結構體變量,一個是存儲的數據,一個是結點結構體類型的指針(因為通過這個指針訪問下一個結點時,還是一個結點結構體,所以必須是結點結構體類型的指針變量)。
2.鏈表的性質
由這個簡略圖給出鏈表的通用特性:
①鏈表在邏輯上是連續的,物理空間上不一定連續
②結點一般是在堆上申請的
③從堆上申請的空間不一定連續
了解即可。
3.單鏈表結點結構的創建
非常清晰了,直接給出來:
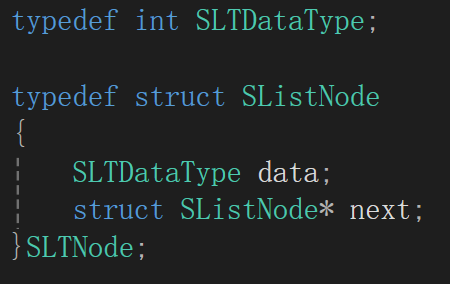
為了單鏈表存儲數據類型的可修改性,一個typedef,為了后續與結點這個結構體操作的簡便性,再來一個typedef,這點在順序表中已經見過了,不多解釋。
不管是先前的圖片還是后續的創建,都展示出了結點的兩個屬性,一般存放數據的被稱作數據域,存放下一個結點地址的叫做指針域。
4.單鏈表的打印
有了單鏈表的結點,如果要實現我們所畫的圖片的效果應該是這樣的:
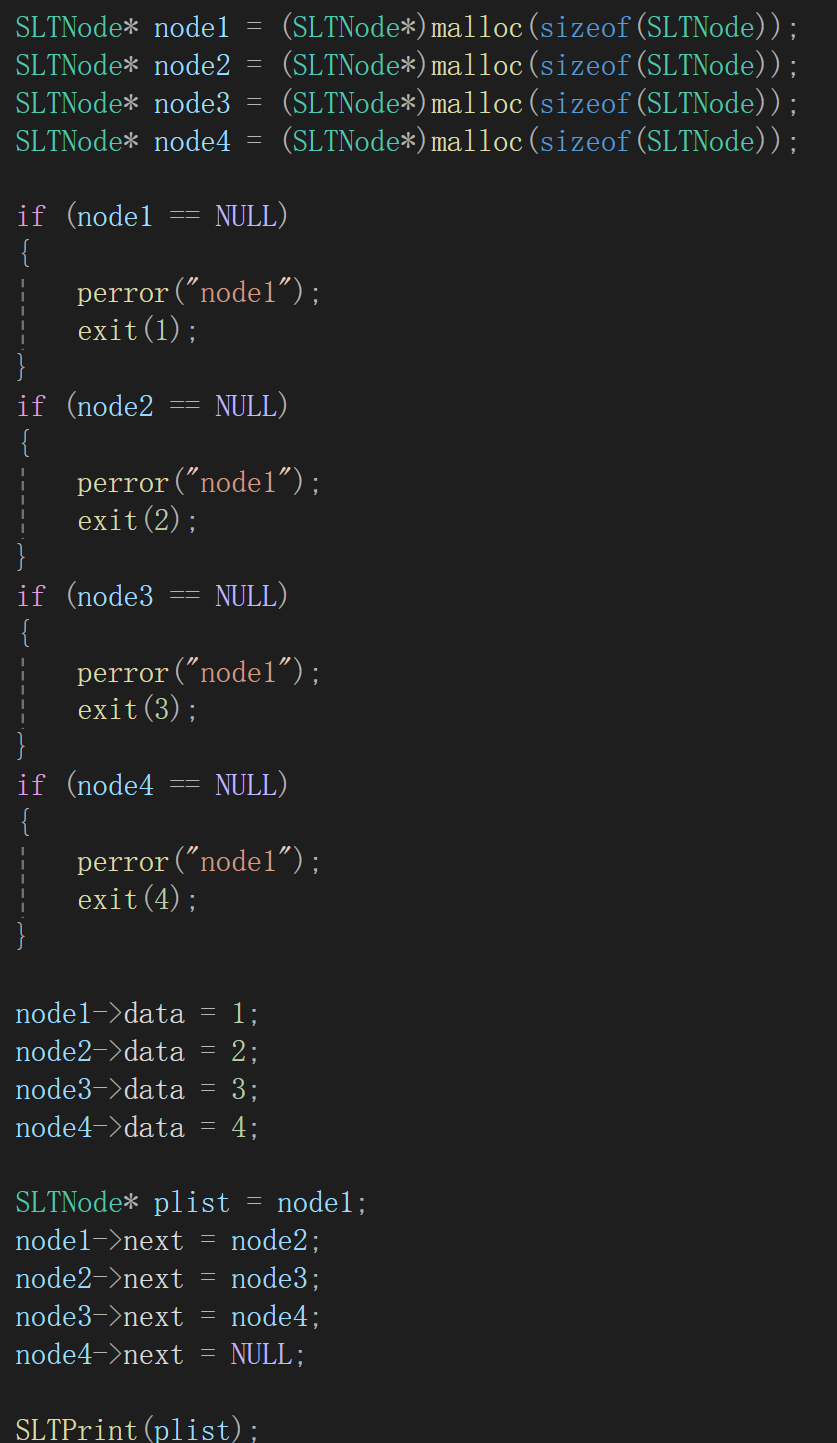
為每一個結點創建內存空間,并且賦值,實際上發現,我們邏輯上的1,2,3,4是通過指針來實現的。
如果對于這樣的一個鏈表,我們該如何實現遍歷打印呢?
通過plist開始訪問鏈表的數據,進去打印該結點的數據,并且將指針該為下一個結點的地址,最終下一個結點的next指針為空則遍歷完成。

進去就打印,并且跳到下一個鏈表結點里,如果不為空則繼續打印,為空說明已經遍歷到尾,可以停止。
當然,其實可以把assert換一下,因為如果鏈表為空,直接打印個NULL,也可以:

5.單鏈表的插入結點操作
①單鏈表的尾插
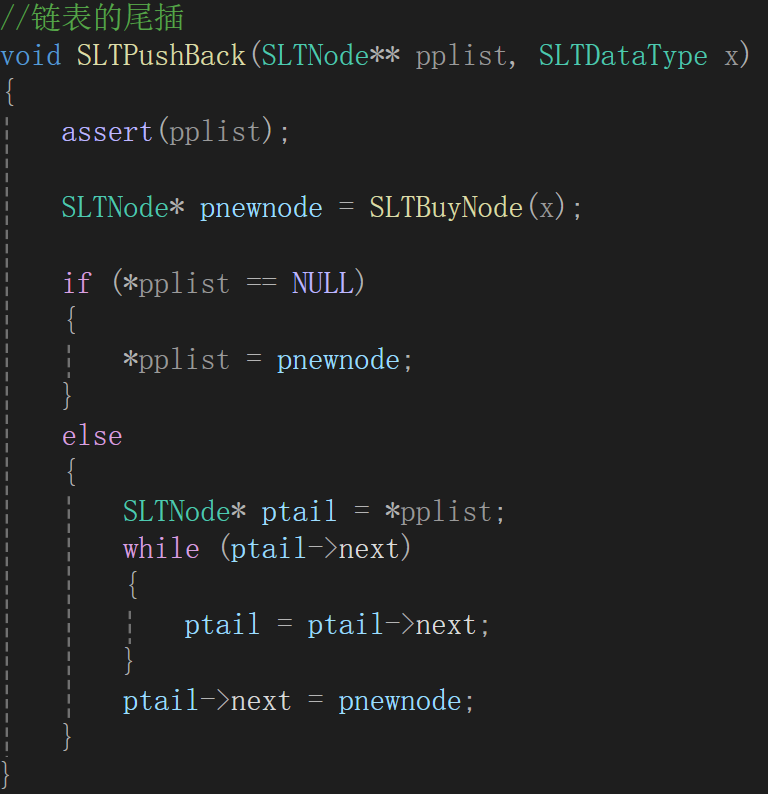
先想尾插的參數,肯定得把單鏈表的地址傳過去吧,然后你插什么總得告訴我吧。
所以就倆參數,一個是單鏈表的地址(如上面的plist),還有想要插入的元素是什么。
進去第一件事可不是去插入,就像順序表插入一樣,你總得看看有沒有地方讓你插入吧,類比過來,就得先生成個結點,這個結點專門用來存放本次插入的值,指針的話由于尾插,所以肯定是NULL。
有了這個結點以后就得把它像連接火車車廂一樣接上去,很顯然,需要先找到鏈表尾,其實我們打印的時候用的while循環結束后,指針已經到了單鏈表的尾了,所以拿過來即可,找到尾以后把原來的尾的指針從NULL變成新創建的結點的地址即可。
思路有了,代碼表達:

逢開辟必檢查。
而鏈表的插入分為空鏈表的尾插和非空鏈表的尾插,至于為什么,先往下看:
非空:
拿著鏈表地址,遍歷到最后,把創建的新結點地址賦給尾結點即可。
但是如果是空鏈表呢:
你非空確實傳過來地址,我順著地址修改值就行,但是如果是空的鏈表呢?你傳過來的是什么,是NULL,那你再修改,對實際的鏈表根本就是無濟于事啊。所以為了對真正的鏈表的里面的值進行修改,我們不能傳值了,只能傳過來這個空鏈表的指針的地址(為了通過這個地址去修改這個指針)
地址的地址,或者說一級指針的地址應該用二級指針來承接,所以形參寫的時候應該是二級指針,修改為:
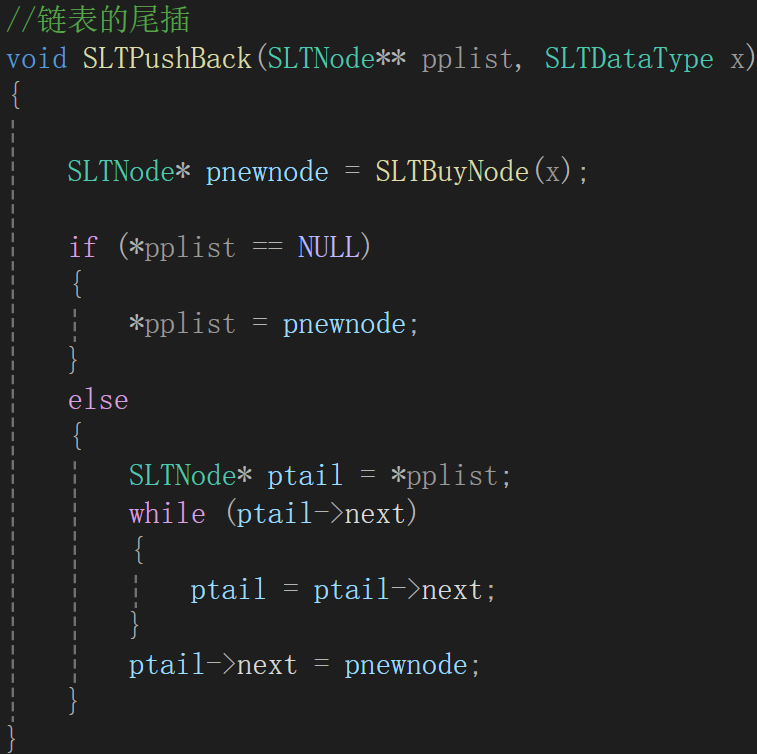
其中,鏈表不為空需要遍歷到鏈表尾部的地址,因為后續需要用這個地址去修改NULL,這樣的話到尾結點就該停,而尾結點與其他結點的不同就是下一個結點的地址為空。
測試代碼如下:
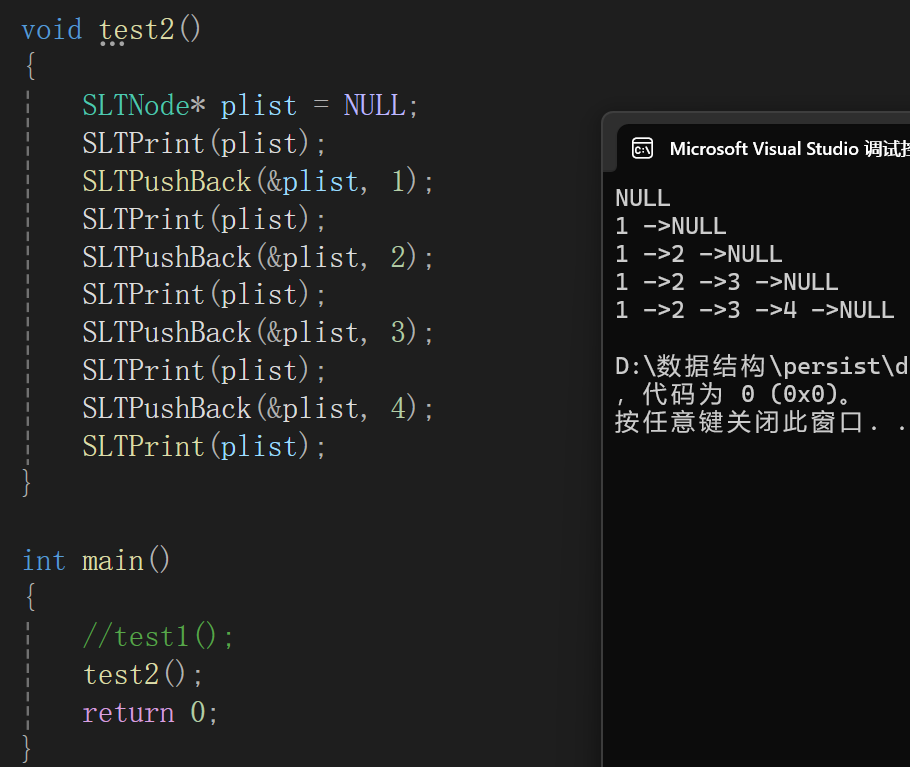
說明確實插入了。
當然,還得防范一下傳過來的指針,畢竟plist可以為空(即鏈表為空),但是pplist存的可是鏈表的地址的啊,這玩意為空算哪門子事:
加個assert防范一下。
②單鏈表的頭插
還是有了經驗以后,參數還是pplist,并且分開鏈表為空和鏈表不為空的情況:
首先還是不為空:
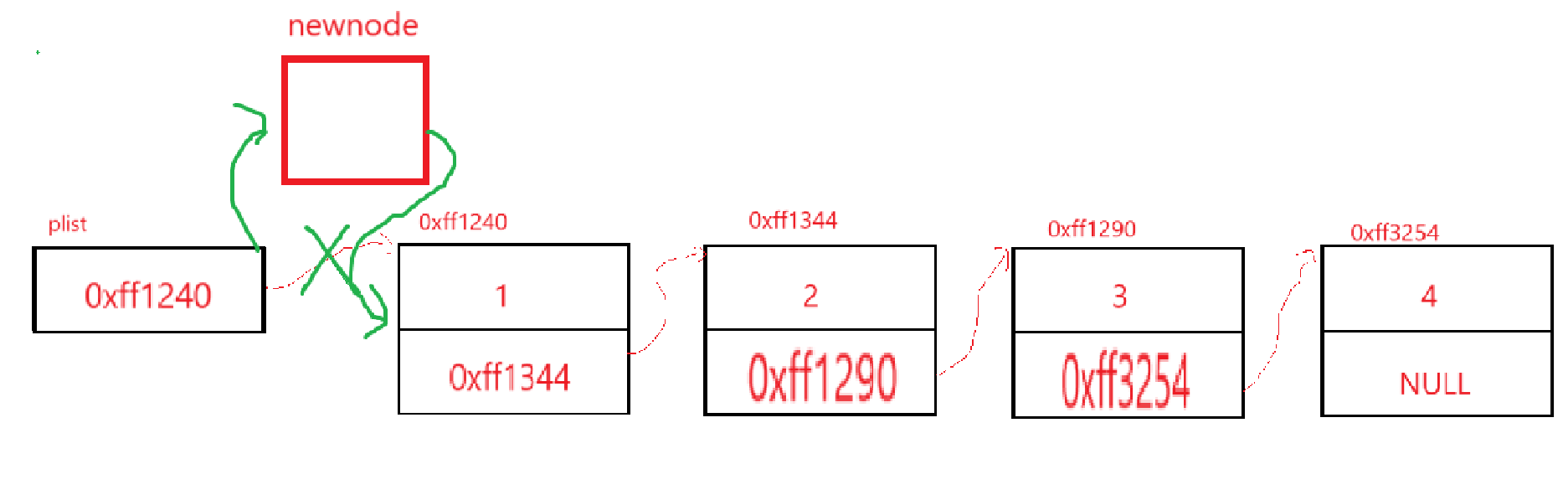
讓plist指向我們的newnode,newnode指向我們的第一個結點,這樣的話賦值就得先把plist的值賦給newnod->next了,然后再把plist的值修改了:

而且發現,如果鏈表為空,plist為NULL,賦過去,newnode地址給plist,也沒毛病。
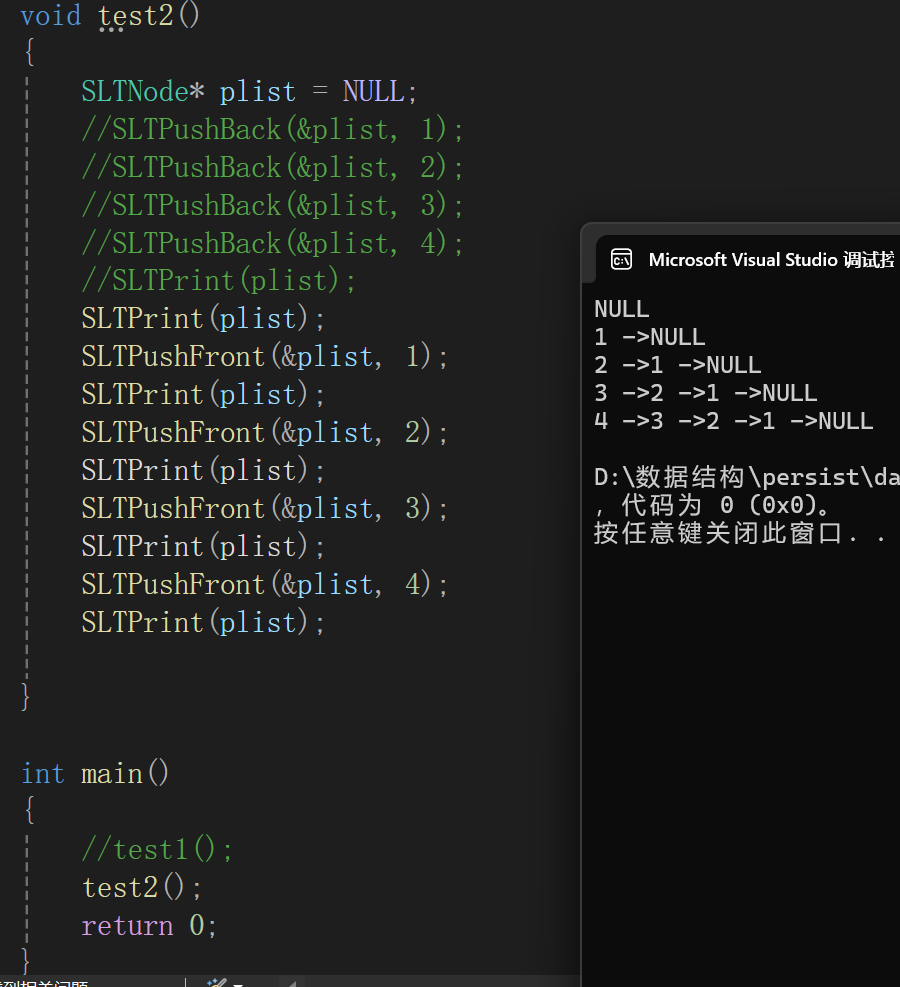
調試完畢,沒啥問題
6.單鏈表的刪除結點操作
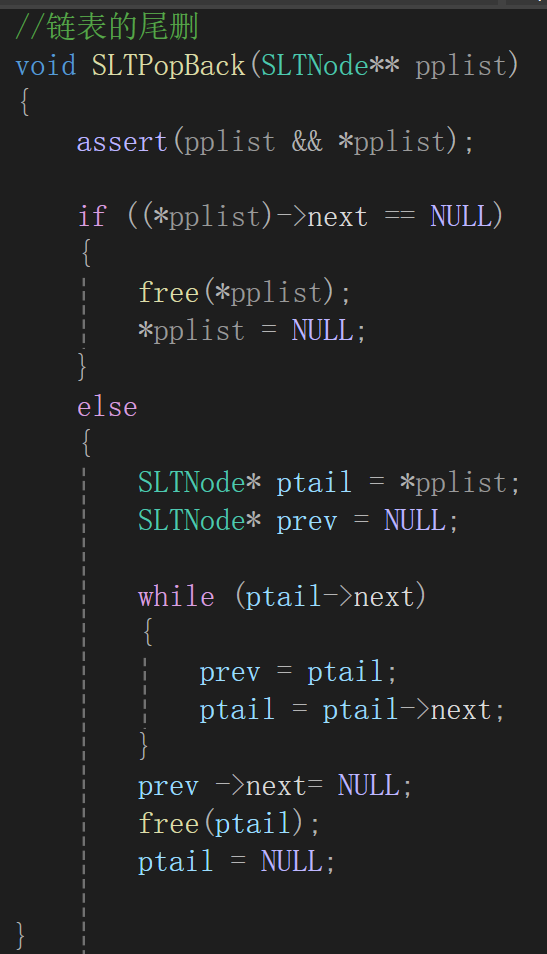
①單鏈表的尾刪
 釋放最后一塊空間,并將尾結點的前一個結點的next指針改成NULL。
釋放最后一塊空間,并將尾結點的前一個結點的next指針改成NULL。
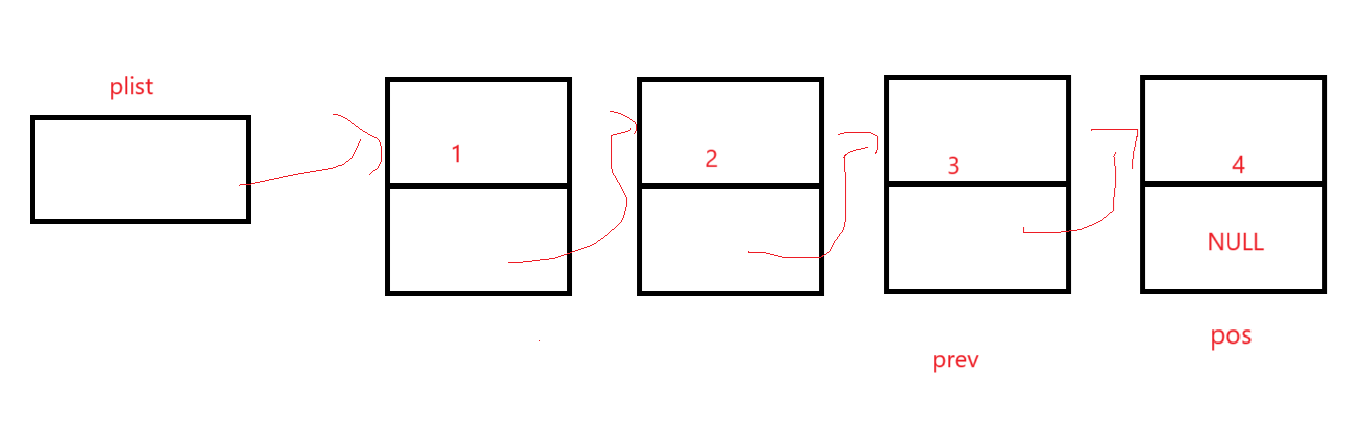
這就要求你必須找到兩個位置的指針,一個是ptail,一個是ptail前的prev,我們以這樣的思路來想辦法遍歷,示意圖:
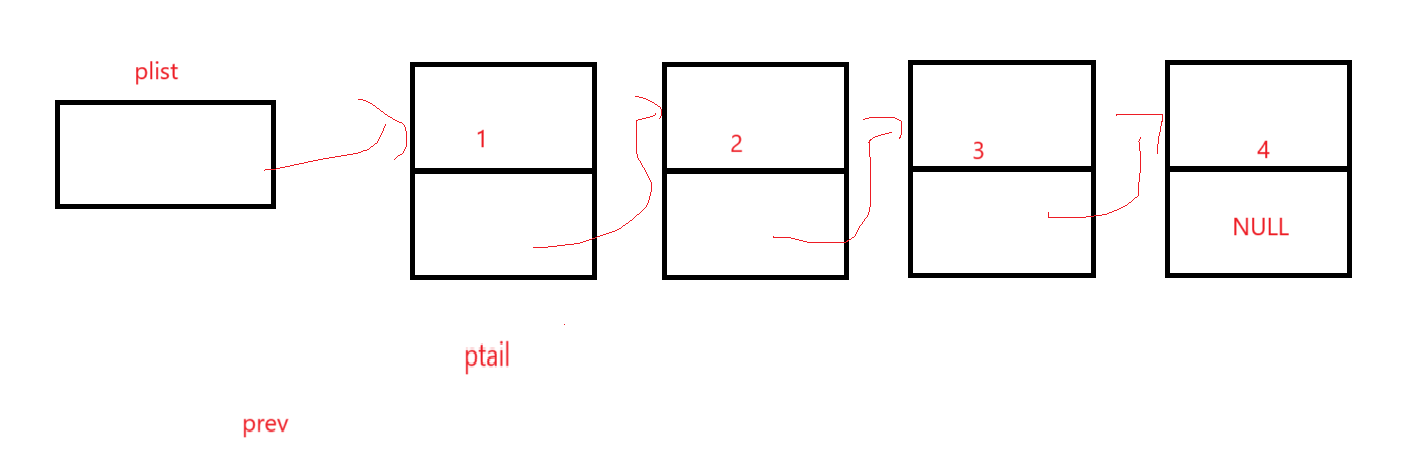
ptail開始指向第一個元素,prev由于必須在ptail前,此時應該為空;
進入檢測以后看看這個結點是不是尾結點,是的話就該停止遍歷了,即判斷條件為ptail->next != NULL。
問題就在于循環體如何實現ptail往后走的同時來讓prev在ptail前,很簡單,可以說是keep up with:

如果不是尾結點的話,prev先站到現在ptail的位置,因為下一步就是后移,這樣出了循環就是一個在前一個在后的效果,如:
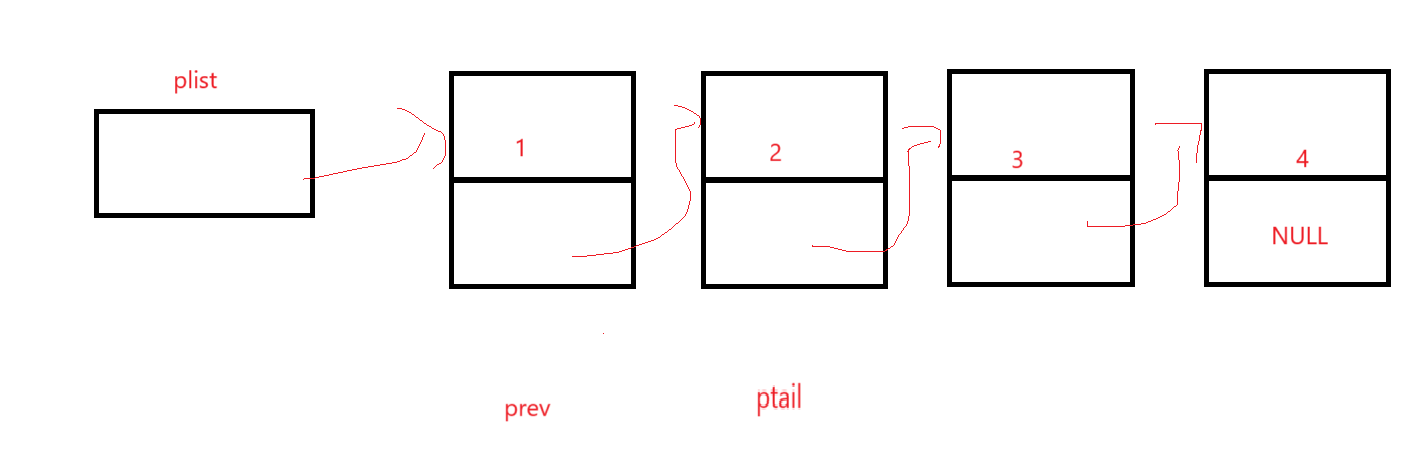
當然不能忘了釋放空間和防范野指針:
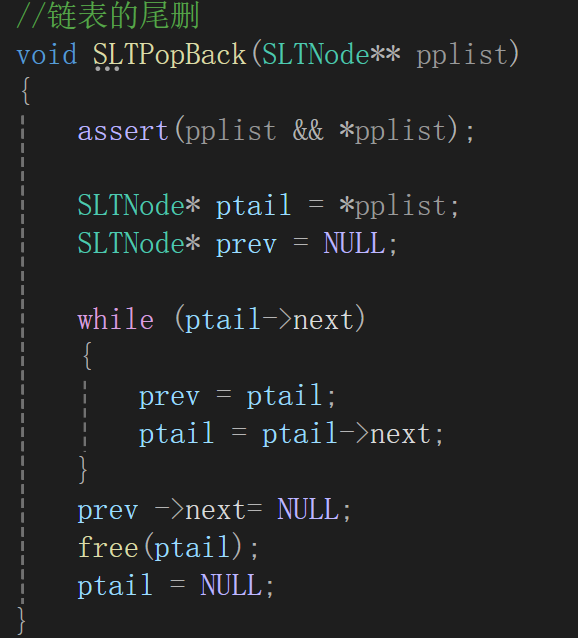
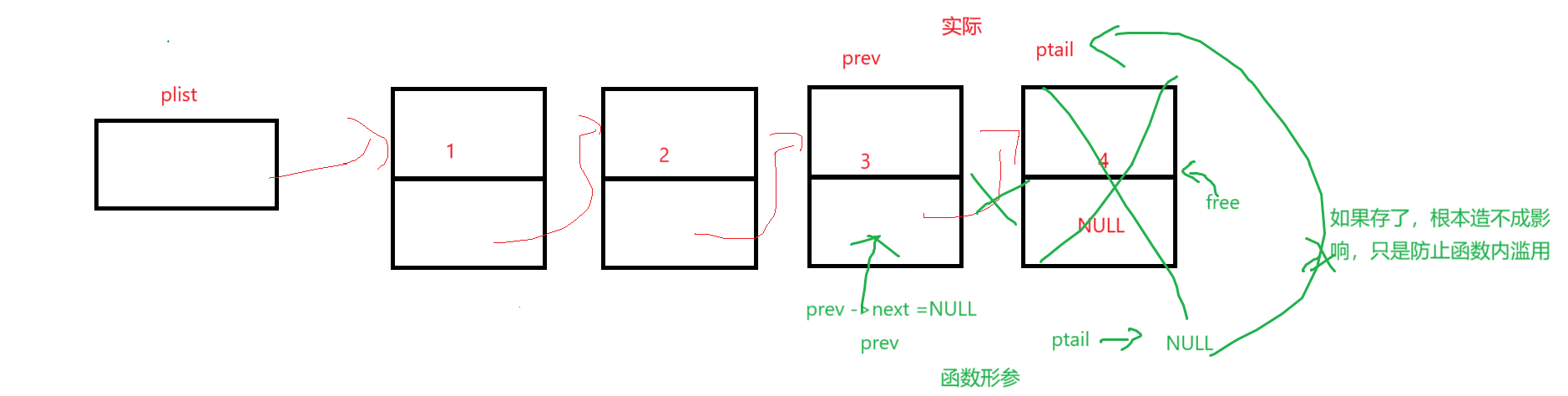
最后三條解釋一下,prev->next = NULL確實是修改了鏈表的實際結構,因為prev是尾結點前那個結點的地址,順著地址肯定能修改成功實際的鏈表;有了尾結點地址,free不用多解釋;重點在于ptail = NULL,它可不是真的把尾結點指針置空了,或者說它即使置空也不影響實際鏈表中的地址還存在(如果存了的話),只是free以后習慣置空,作用是防止在函數內部再被調用。
畫圖解釋:
正如我們插入操作的時候需要防范鏈表是不是空鏈表一樣,對應過來就是,我們刪除的恰好就是唯一的一個結點,即第一個結點,代碼思路還行不行得通: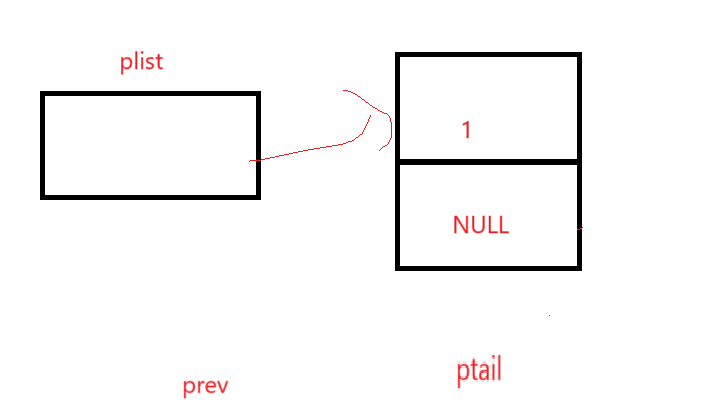
就盯著這個看,很明顯,上來就是NULL,這么一搞,prev直接就是隨機值。
所以如果只有一個結點的話,直接free并且賦plist為空即可(當然,在函數里是*pplist)。
完善:
測試:
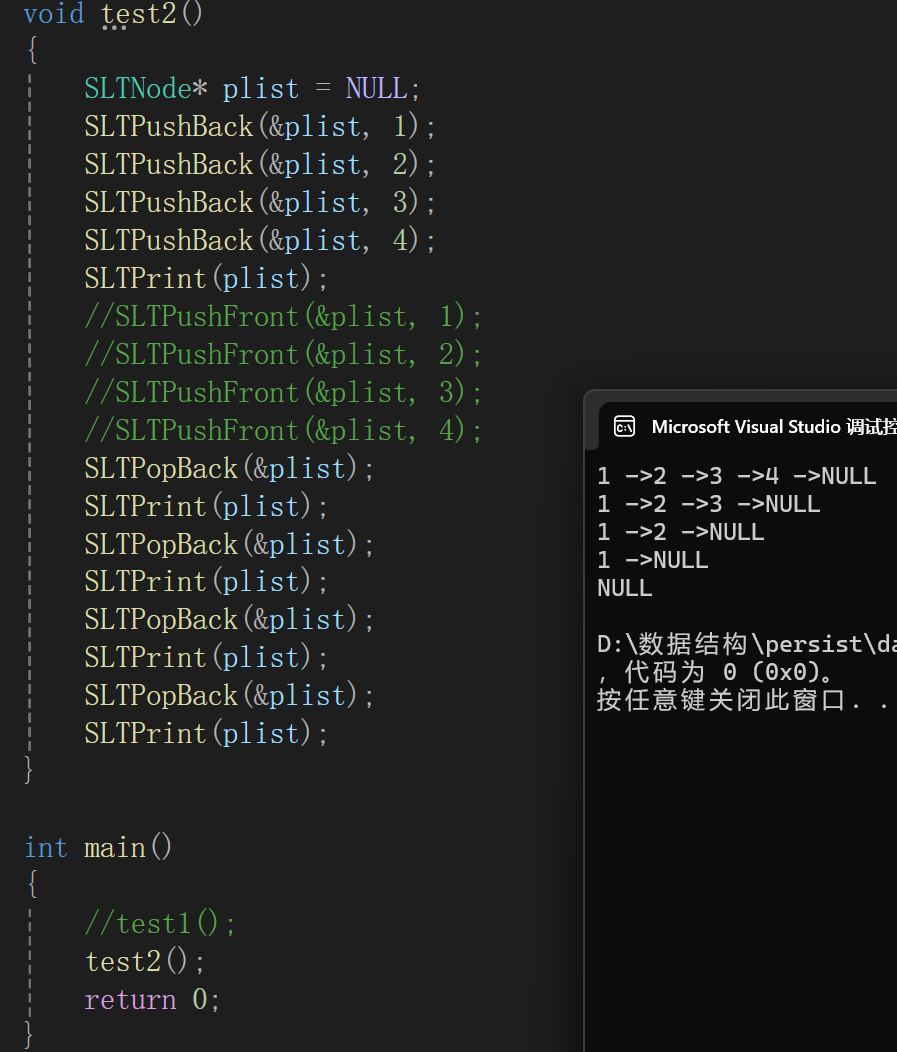
兩端代碼都成功。
②單鏈表的頭刪
頭刪其實沒什么可多說的,把plist修改為原plist->next,再對原plist的空間釋放即可:

測試代碼:
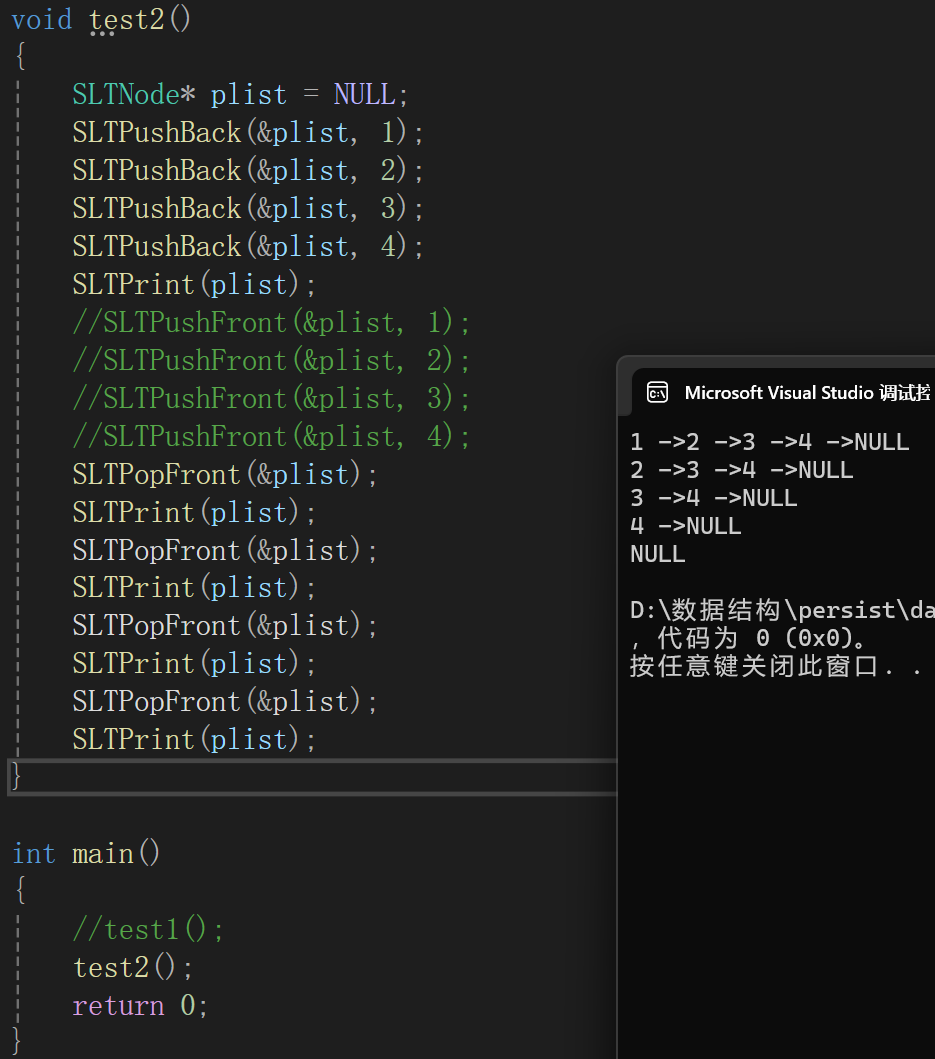
沒啥好講的,連圖都不用畫,空想一下就能想出來。
7.單鏈表的查找操作
參數:你想查哪個鏈表,地址給我,你想查鏈表里哪個元素,元素也給我,所以就倆參數,而且不會對鏈表的結構產生改變,傳值即;上面都沒說返回值的事,因為不管是打印還是對鏈表結構的改變,不需要返回什么,但是查找,你找到了給我個地址讓我知道啊,找不到你總得告訴我找不到吧。
查找我寫了兩個版本:
第一個版本是這樣的:
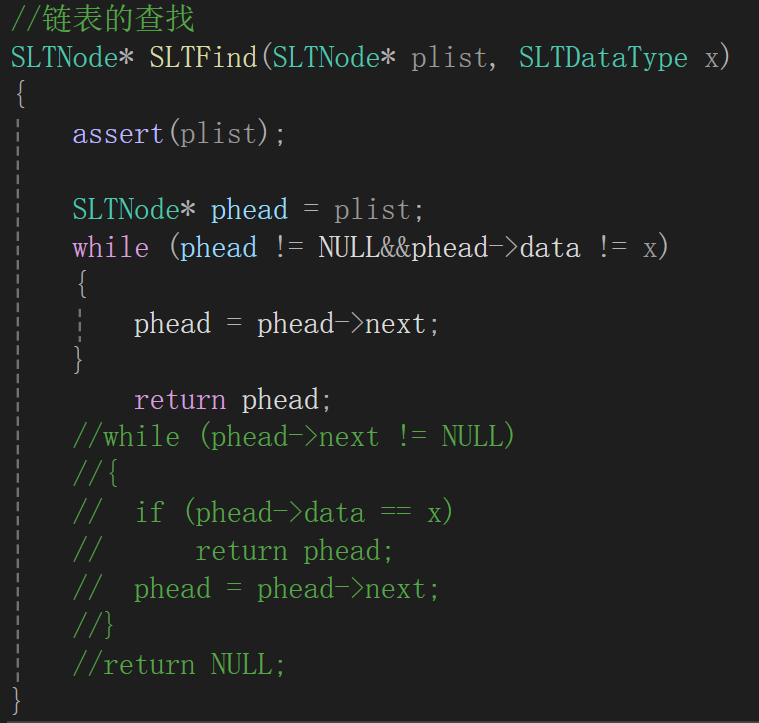
最開始實際上我寫的是:
while (phead->data != x)
{
?? ?phead = phead->next;
}if(phead == NULL)
? ? ? ? return NULL;
else
? ? ? ? return phead;
思路就是,要是這個結點的值不是我要的值,就往死里給我遍歷,跳出循環以后有倆情況,一個就是為空了都,那說明找完都沒找到,直接返回NULL就行;一個就是找到了,跳出循環即可。
問題有倆,一個是遍歷到尾了,phead就是NULL,再解引用去判斷data與x相等不相等就不禮貌了,再來就是其實我寫的if-else語句其實就是return phead的意思,(我剛開始就意識到了if-else的化簡,絲毫沒有發現第一個問題,最后代碼報錯檢查了檢查才發現)
第一次檢查修改為:
while (phead->data != x)
{
?? ?phead = phead->next;
}? ? ? ? return phead;
然后發現空指針解引用問題:
while (phead->data != x && phead != NULL)
{
?? ?phead = phead->next;
}? ? ? ? return phead;
加上了還給我整事,后來想了想,這就是當時學邏輯運算符的短路問題,如果遍歷完都找不到你先解引用才去檢驗是不是空,這樣代碼當然還是會報錯,所以還得:
while (phead != NULL && phead->data != x)
{
?? ?phead = phead->next;
}? ? ? ? return phead;
才沒毛病。
第二個版本是這樣的:
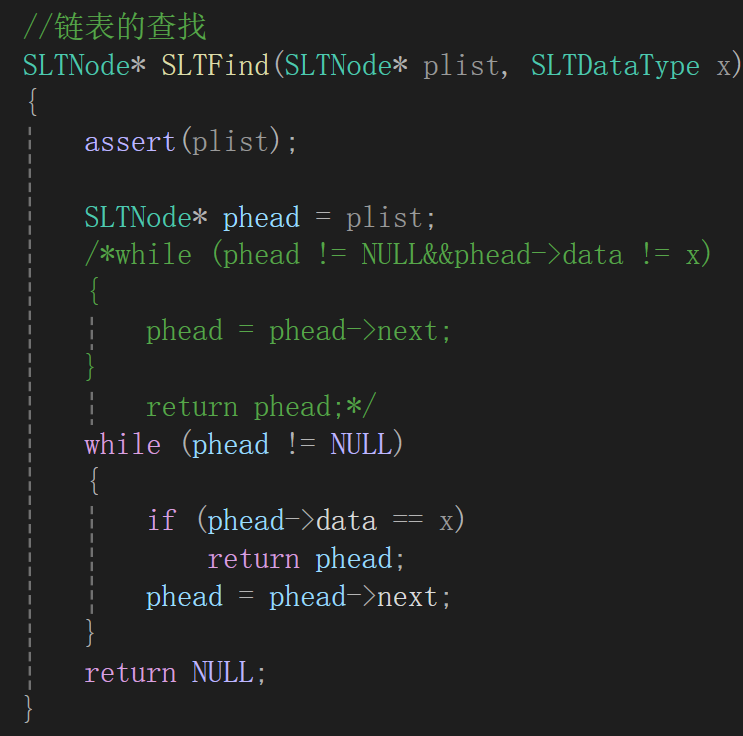
while循環瘋狂遍歷,每次遍歷到的結點去檢測一下data,如果遍歷完都沒找到,直接返回NULL。
這個版本寫出來其實是因為想放棄第一個版本了,但是又因為自己不服氣,就有了上面的修改過程。
8.單鏈表指定位置的插入和刪除操作
①指定位置之前插入數據
指定位置的插入和刪除,肯定是在某個特定的值前才進行,所以鏈表在這種情況下不會為空
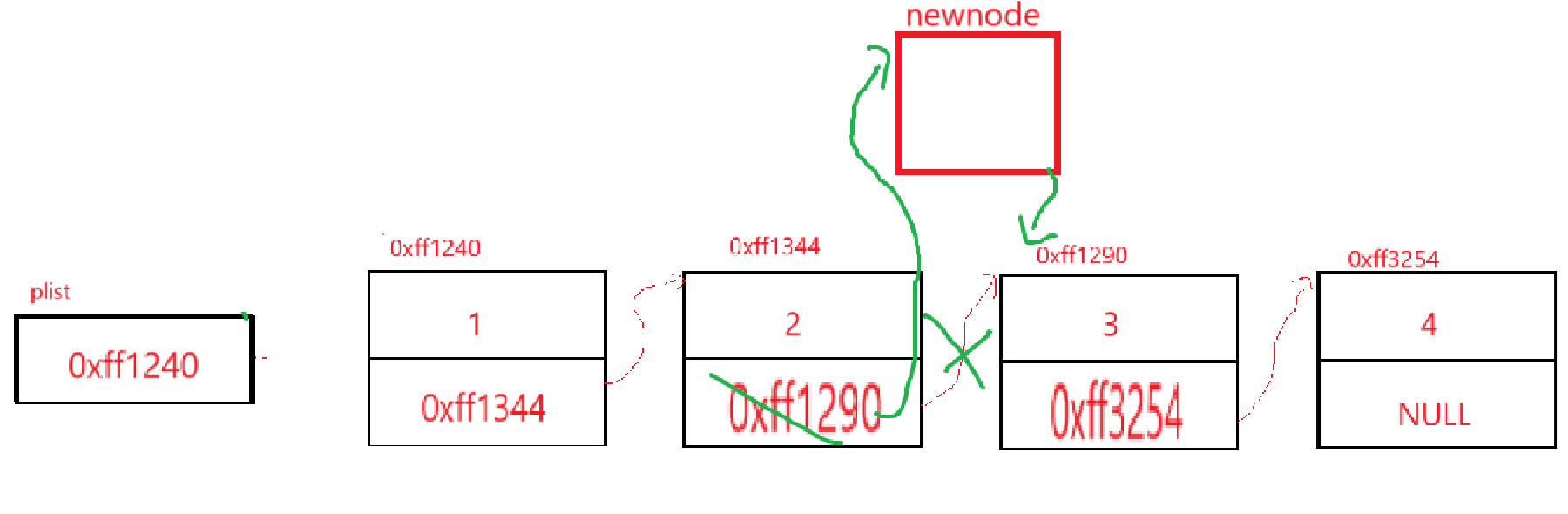
這點意味著要在3這個結點前插結點,創建新結點就不說了,來看指針怎么變,這種情況下傳的肯定是鏈表中某個節點的地址,這樣看來的話newnode->next不成問題,但是前面一個結點的next指針可就炸缸了啊,因為你給我的是3的指針,給了這個我往后遍歷順著走就行,往前遍歷可就得想想辦法了,還是得寫一循環遍歷,當該指針next為3這個結點就停手,給目標節點起名pos,給目標節點前一個結點起名prev(取自previous)。
準備工作:

準備好結點,準備好要改變的值以后,就是賦值

最后:
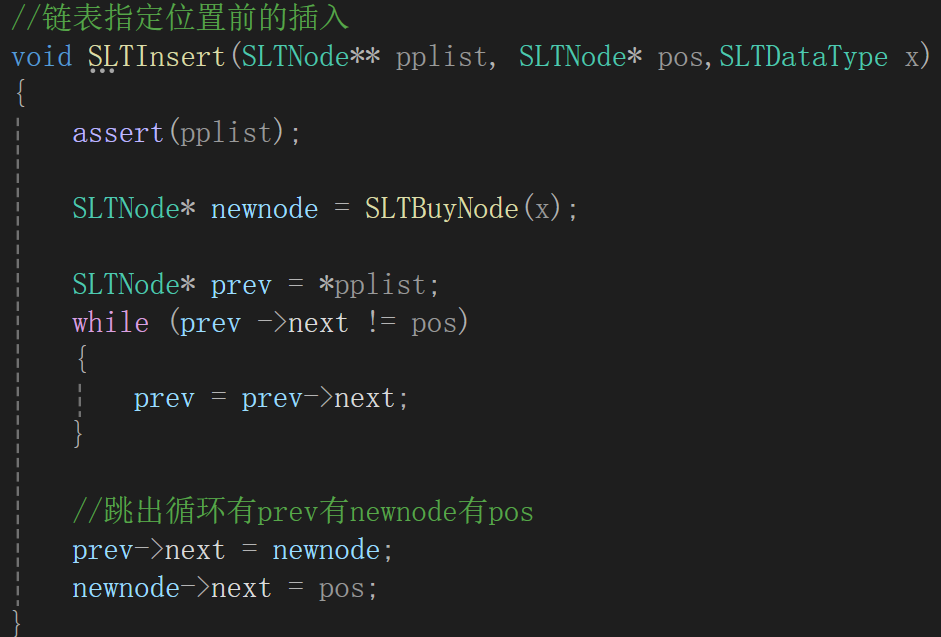
但有一特例,如果指定位置前是鏈表的頭呢:

這個時候的prev->next永遠不會是pos,就會無休止的找下去,這樣的話會導致出錯,干脆如果plist==pos,直接調頭插去,懶得再寫邏輯了,反正也跟寫頭插一樣:
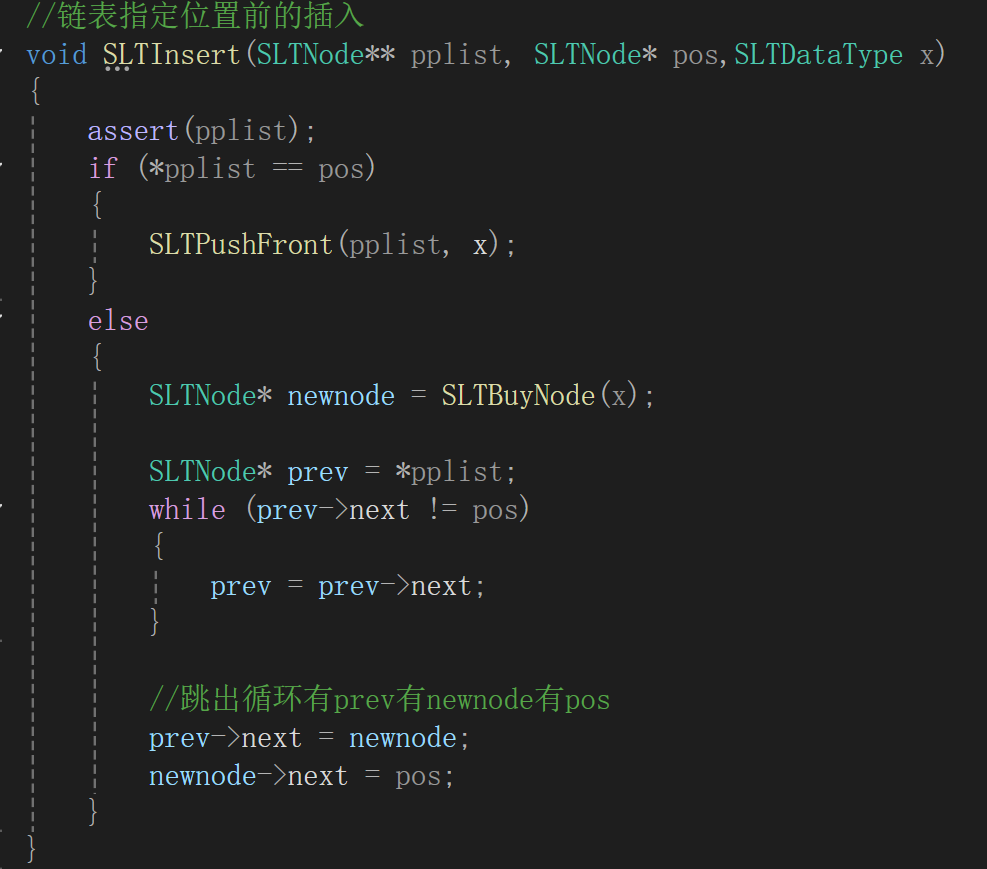
測試代碼:
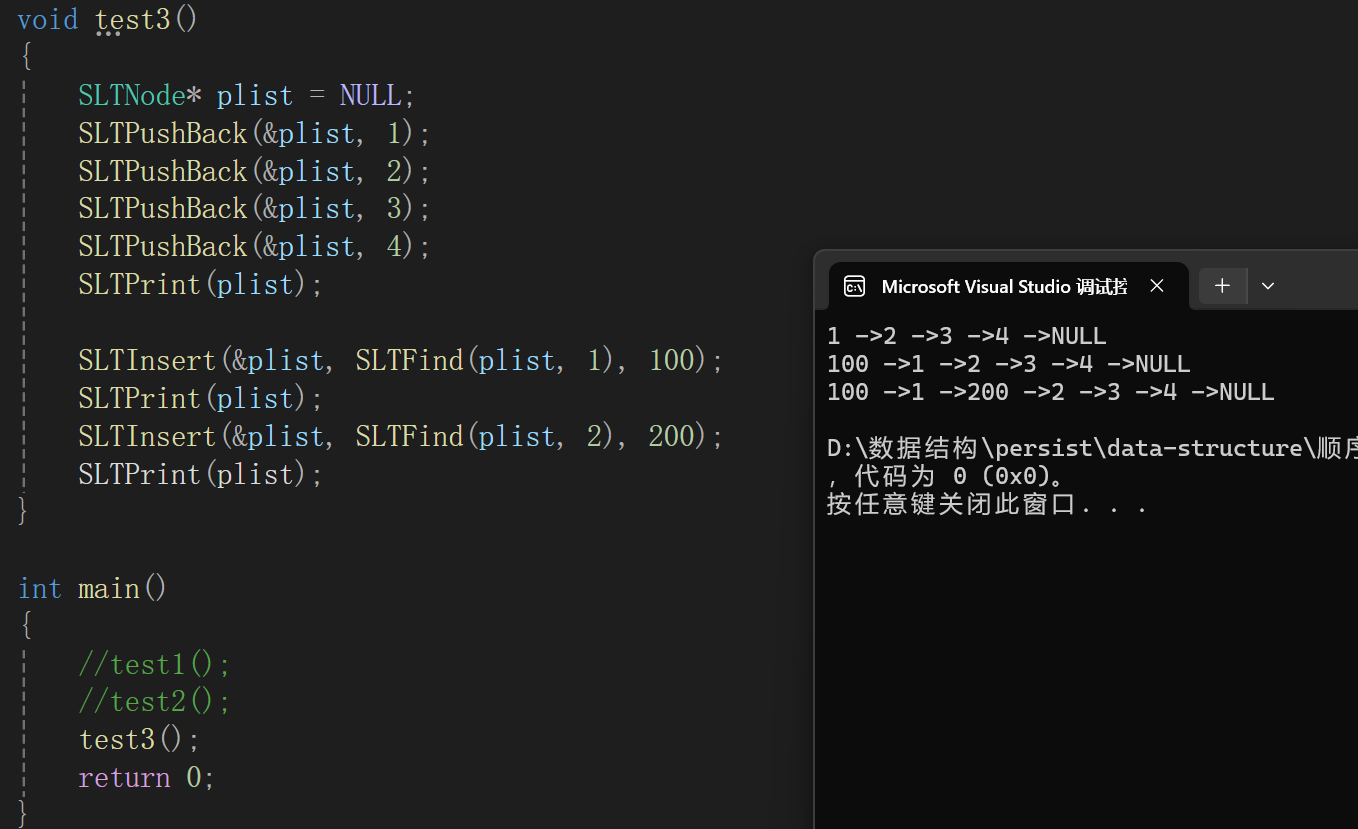
不管頭插還是中間的插入都沒啥大毛病。
②指定位置之后插入數據

注意參數即可,因為鏈表的結點的成員是一個data,一個next指針,所以往后插根本不需要指定位置的前一結點的地址,也就不需要鏈表的頭結點地址。
先按照正常元素往中間插的思路寫:
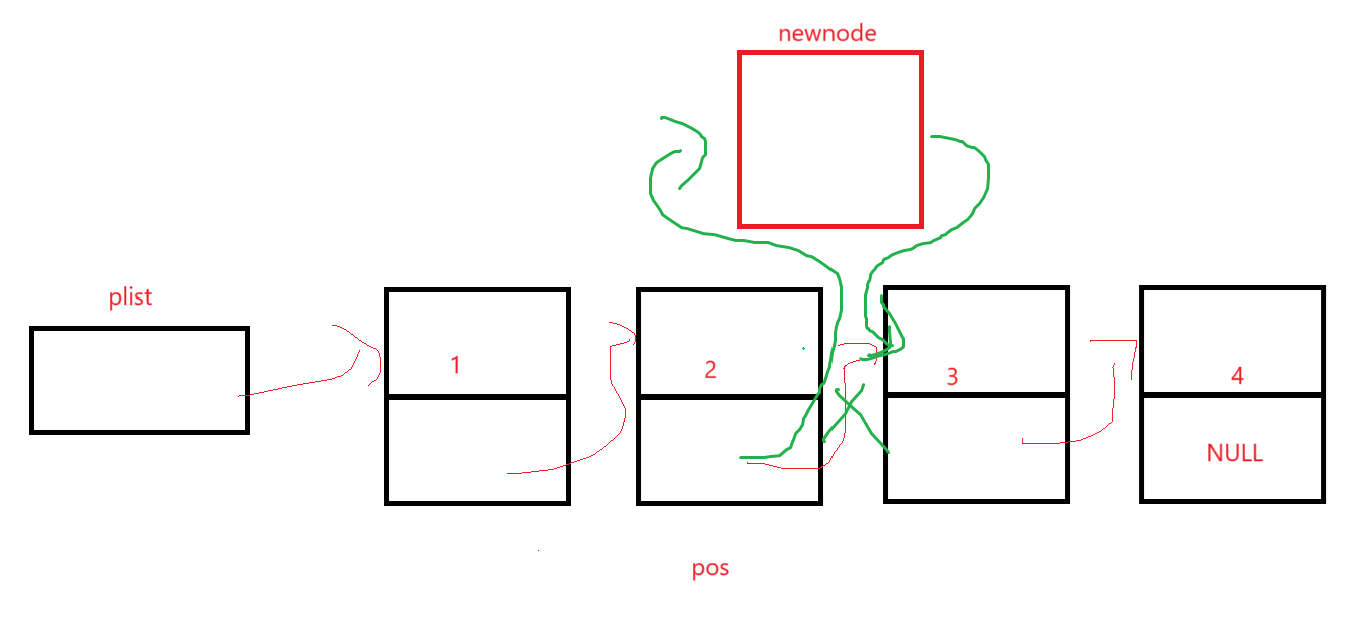
newnode->next指向pos->next,pos->next指向newnode即可,一定要注意順序。
newnode->next = pos ->next;
pos->next = newnode;
和
pos->next = newnode;
newnode ->next= pos ->next;
真按照下面的干了,直接炸了,因為pos->next直接被你用newnode覆蓋了,導致第二句代碼newnode->next指的還是newnode自己。

直接寫出來就行,但是插入還得小心點(空就不用考慮了,肯定是查找后的指針,不可能為空,即有pos就不用驗空),想想第一個結點插入,由于是之后,那跟找中間的插也沒啥區別;想想尾結點插入:
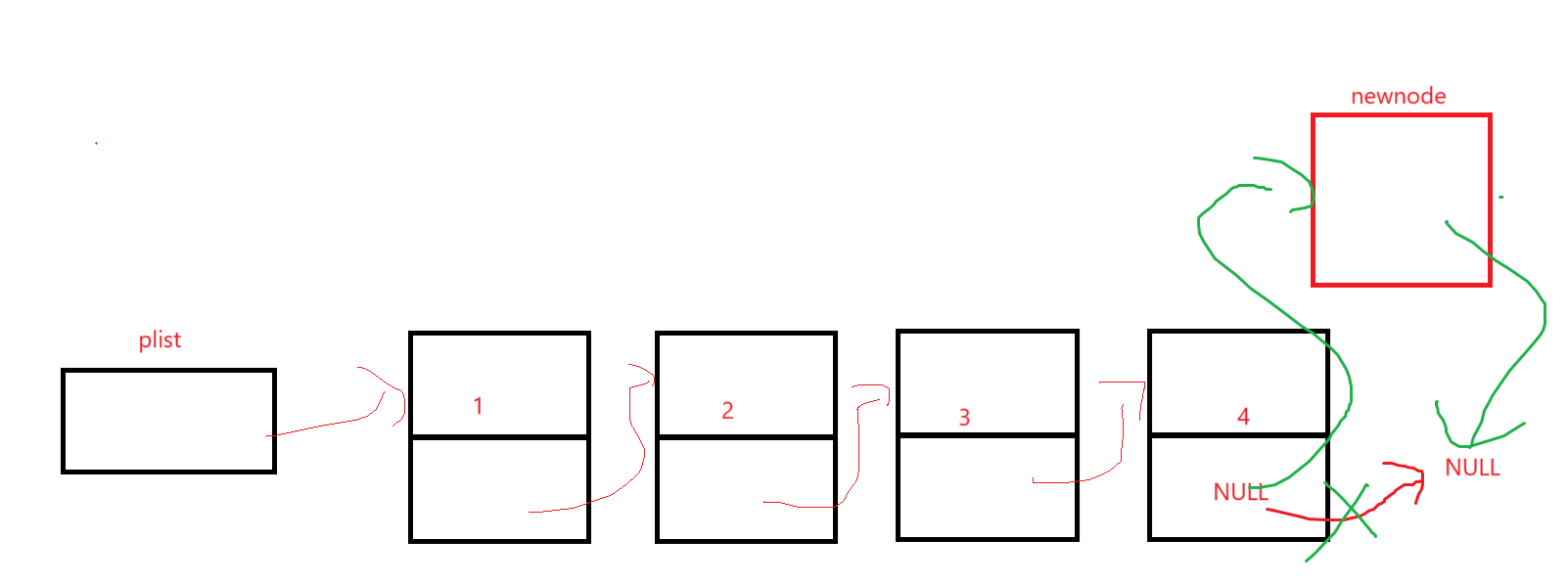
對著代碼看,也沒啥毛病。
測試一下:
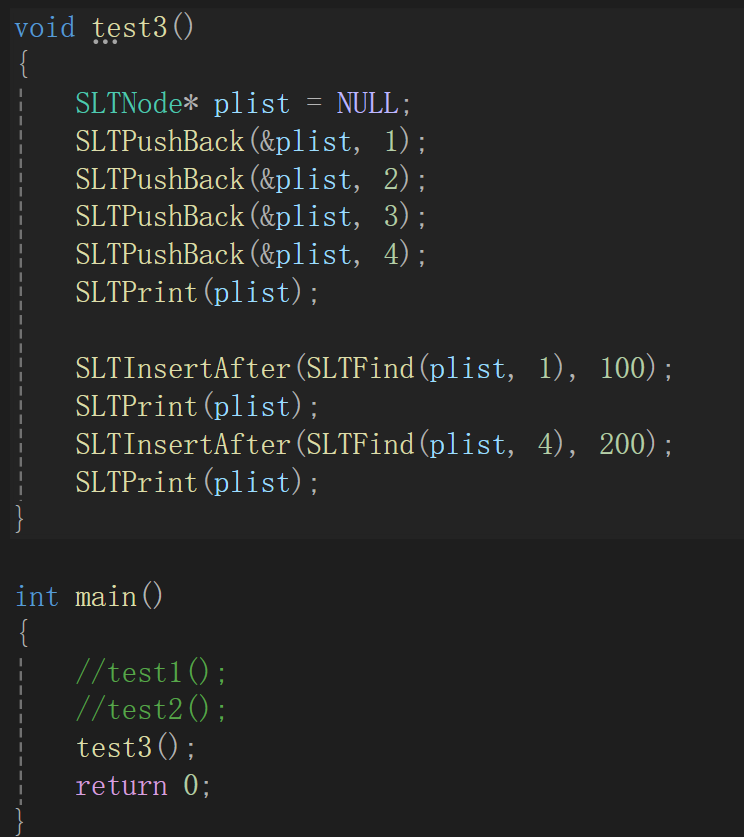
沒犯啥毛病,成功了。
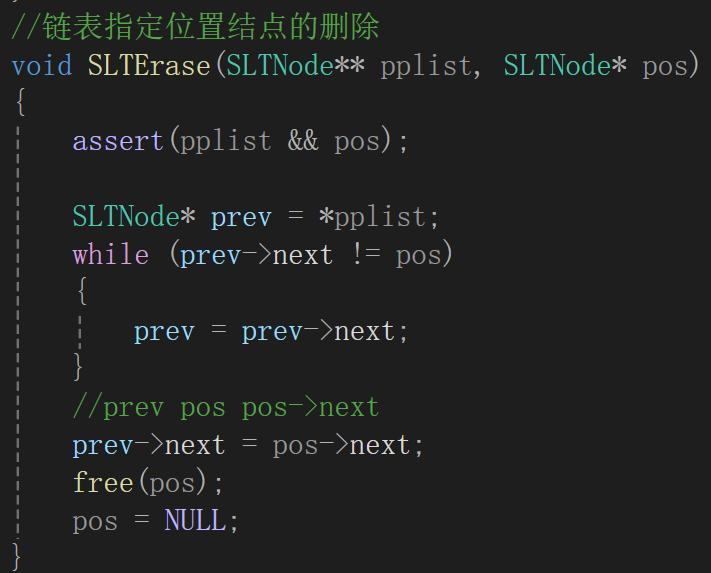
③刪除指定位置的結點
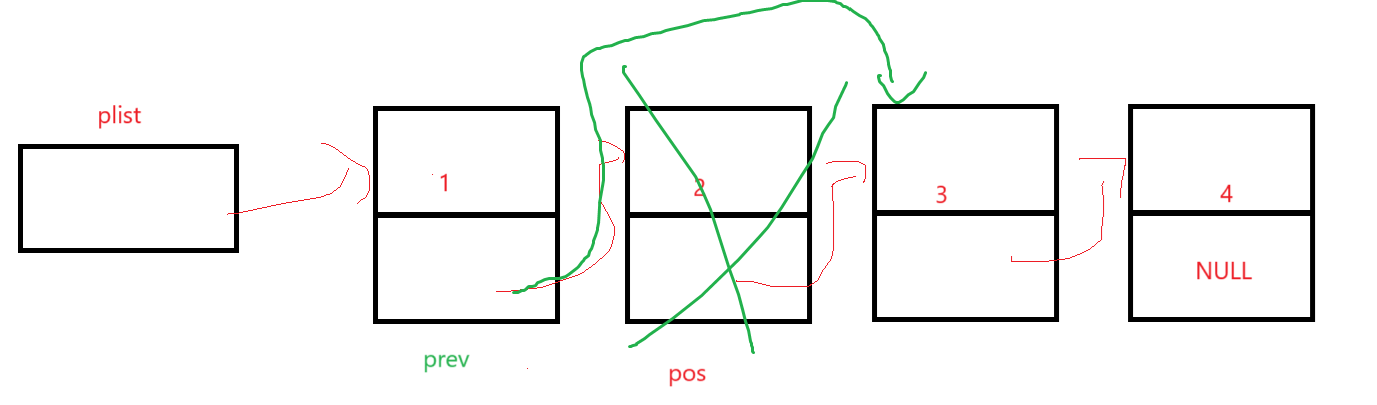
一個遍歷到pos前,一個賦值改指針指向,一個釋放:
然后就是看看首或者尾會不會出幺蛾子:
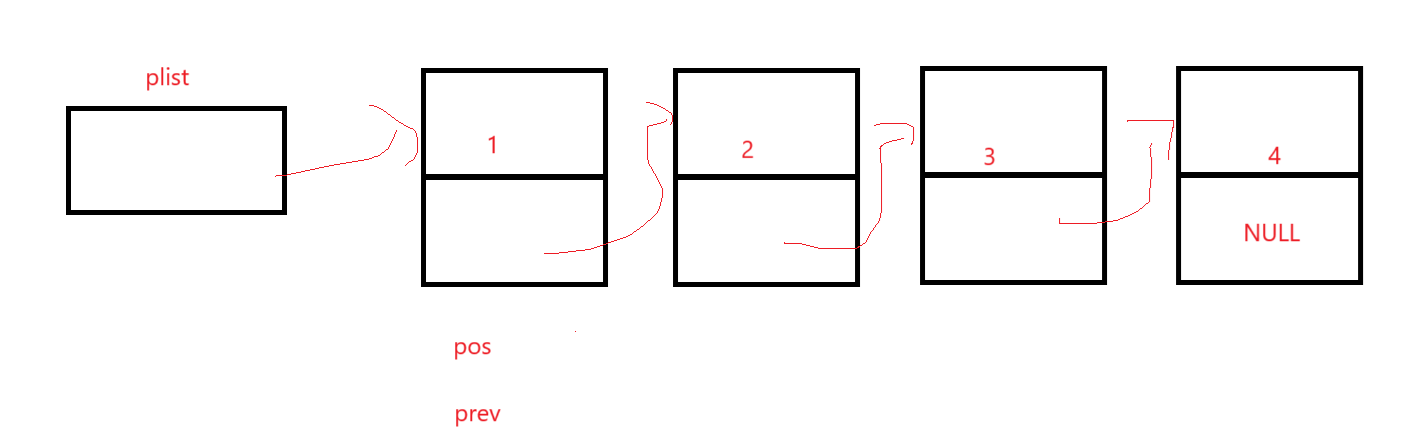
上來就發現了,我們的邏輯是prev->next是不是pos,根本無法檢測pos剛好為頭的情況,所以還是寫個if-else去頭刪:
尾結點沒炸。
測試:
④刪除指定位置后的結點

還是說,指定位置后可以直接通過pos找到,就不需要傳plist了。
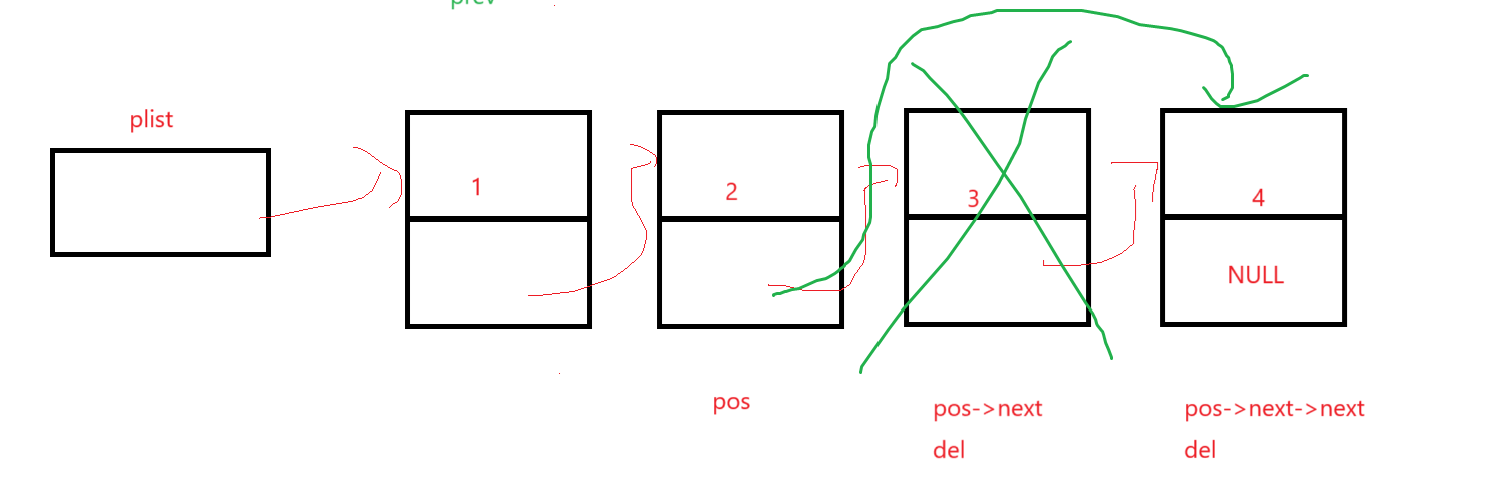
不想寫那么多next就將要刪去的結點的地址存到del里,方便自己看以及方便改指針和釋放:

這么寫增加代碼可讀性。
想想頭尾會不會出啥問題,頭的話頭后刪,跟我們從中間找一個結點刪效果一樣;尾結點后面沒結點,想了想指定位置后結點刪去不能有尾結點,所以加到assert里:

測試:
9.單鏈表的銷毀
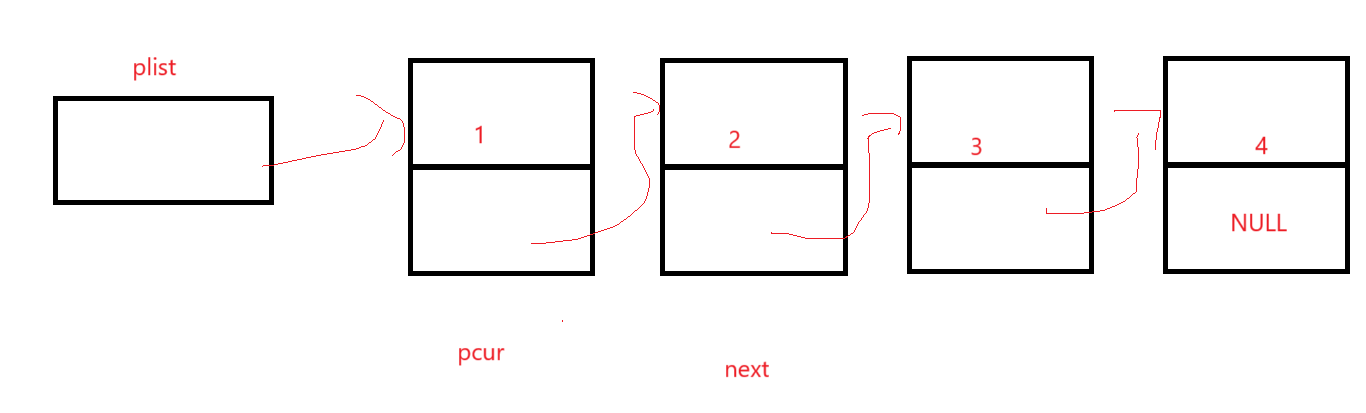
銷毀單鏈表就把頭結點的地址傳過來。
很明顯,如果直接free掉plist那么后面的結點全部都丟了,所以在free結點前記錄下一個結點,直到下一個結點為NULL再停止:

三、對比順序表和單鏈表
剛剛學完,可謂是手感火熱,順序表和單鏈表都有插入和刪除操作。
其中順序表的頭插頭刪由于其空間的連續性,所以必須先將已有元素后移,才能插入,后移就會用一個循環,時間復雜度是O(n);
順序表的尾插尾刪,不需要移動數據,所以也不需要循環,插就一句根據地址賦值的事,尾刪更簡單,直接size--即可。時間復雜度是O(1)
單鏈表的頭插頭刪,頭插由于不需要將其他元素后移,直接針對鏈表頭結點所給指針改變一下next指針;頭刪就先改頭結點指向地址,再free即可。
單鏈表的尾插尾刪,最影響時間復雜度的就是while循環去找尾結點的指針ptail,導致時間復雜度為O(n)。
我們現在就學了這兩種數據結構,已經可以看出來,沒有哪一種數據結構就能一招鮮吃遍天,各有各的優點,你尾部頻繁的增刪改,那就用順序表,頭部頻繁增刪改那就單鏈表。
解釋這個就是為了解釋我最開始所說的,學習各種各樣的數據結構,是為了算法里選擇最優的數據結構。
另外,單鏈表由于每個結點都是在堆區申請獨立的空間,所以不會存在內存浪費的情況,這種優勢是針對順序表來說的,因為在順序表里有一開辟內存的函數叫CheckCapacity,二倍擴容空間如果不用,那就會浪費。

)
)





流編輯器系統)

![[Java實戰]Spring Boot整合Kafka:高吞吐量消息系統實戰(二十七)](http://pic.xiahunao.cn/[Java實戰]Spring Boot整合Kafka:高吞吐量消息系統實戰(二十七))
)






線性代數)
![[特殊字符] Word2Vec:將詞映射到高維空間,它到底能解決什么問題?](http://pic.xiahunao.cn/[特殊字符] Word2Vec:將詞映射到高維空間,它到底能解決什么問題?)