我猜咱們每個人肯定都累壞了,天天追著 LLM 研究社區跑,感覺每天都冒出個新的最牛模型,把之前的基準都給打破了呢。要是你好奇為啥創新速度能這么快,那主要就是研究人員能夠在超大規模下訓練和驗證模型啦,這全靠并行計算的功勞呀。
要是你還沒聽說過呢,5D 并行這個術語最早是 Meta AI 的論文 — The Llama 3 Herd of Models 里火起來的哦。傳統上,它指的是結合數據、張量、上下文、流水線和專家并行這些技術呢。不過最近呀,又冒出了個新的玩意兒 — ZeRO (Zero Redundancy Optimizer),這可是個大殺器,通過減少分布式計算中的冗余來優化內存呢。每種技術都針對訓練挑戰的不同方面,它們組合起來就能搞定那些有幾十億甚至幾萬億參數的模型啦。
我之前已經講過一些比較底層的技巧啦,這些技巧能讓你用 PyTorch 訓練和部署模型的速度更快哦。雖然這些小貼士和小技巧能在訓練時給你加分,但它們也就是加分項而已呀。要是你沒有從根本上搞懂它們該在啥時候、啥地方用,那很可能就會用錯地方啦。
這篇文章的重點呢,就是要給大家講清楚模型操作的高層組織結構,還會用 PyTorch 來舉些例子哦。這些并行計算的基本原則,就是現在能讓模型在超大規模下(想想看,日活躍用戶有幾千萬呢)更快迭代和部署的關鍵因素哦。
1. 數據并行
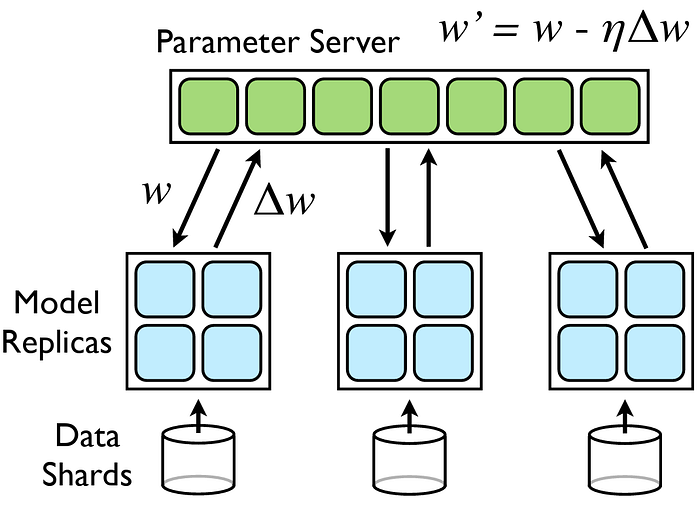
數據并行 [圖片來源]
數據并行是最簡單也是最常用的并行技術啦。它就是創建多個相同的模型副本,然后讓每個副本在數據的不同子集上進行訓練呢。在本地計算完梯度后,就會通過全歸約操作(all-reduce operation)把梯度聚合起來,用來更新所有模型副本的參數呢。
當模型本身能裝進單個 GPU 的內存里,但數據集太大沒法按順序處理的時候,這種方法特別管用哦。
PyTorch 通過 torch.nn.DataParallel 和 torch.nn.parallel.DistributedDataParallel(DDP) 模塊,為數據并行提供了現成的支持呢。這其中呀,DDP 更受大家青睞,因為它在多節點設置下有更好的可擴展性和效率呢。NVIDIA 的 NeMo 框架就很好地展示了它是怎么工作的哦 —

數據并行示意圖 [圖片來源]
一個實現示例可能長這樣:
import torch
import torch.nn as nn
import torch.optim as optim# 定義你的模型
model = nn.Linear(10, 1)# 用 DataParallel 包裹模型
model = nn.DataParallel(model)# 把模型移到 GPU
model = model.cuda()# 定義損失函數和優化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 假數據
inputs = torch.randn(64, 10).cuda()
targets = torch.randn(64, 1).cuda()# 前向傳播
outputs = model(inputs)
loss = criterion(outputs, targets)# 反向傳播和優化
loss.backward()
optimizer.step()
重點收獲
- 小模型 / 大數據集 — 只有當模型能裝進單個 GPU 的內存,但數據集太大時,這種方法才有效哦。
- 模型復制 — 每個 GPU 都會保存一份相同的模型參數副本呢。
- 小批量分割 — 輸入數據會在 GPU 之間分配,確保每個設備處理一個獨立的小批量數據哦。
- 梯度同步 — 在前向和反向傳播之后,梯度會在 GPU 之間同步,以保持一致性呢。
優點和注意事項
- 簡單高效 — 實現起來很簡單,能很輕松地和現有的代碼庫集成,而且在處理大數據集時擴展性特別好哦。
- 通信開銷 — 在梯度同步時的通信開銷可能會成為大規模系統的一個瓶頸呢。
2. 張量并行
張量并行 [圖片來源]
數據并行關注的是分割數據,而 張量并行(或者叫 模型并行)則是把模型本身分散到多個設備上呢。這種方法會把大型權重矩陣和中間張量分割開來,讓每個設備只負責一部分計算呢。和數據并行不同(數據并行會在每個 GPU 上復制整個模型),張量并行會把模型的層或者張量分散到不同的設備上呢。每個設備負責計算模型前向和反向傳播的一部分哦。
當模型太大,沒辦法裝進單個 GPU 的內存時,這種方法就特別有用啦,尤其是對于那些基于 Transformer 的超大模型呢。
雖然 PyTorch 沒有直接提供現成的張量并行支持,但用 PyTorch 靈活的張量操作和分布式通信原語,很容易就能實現自定義的張量并行呢。不過呢,要是想要更強大的解決方案,像 DeepSpeed 和 Megatron-LM 這樣的框架就能擴展 PyTorch 來實現這個功能哦。一個簡單的張量并行實現示例如下:
import torch
import torch.distributed as distdef tensor_parallel_matmul(a, b, devices):# a 按行分割,b 在設備間共享a_shard = a.chunk(len(devices), dim=0)results = []for i, dev in enumerate(devices):a_device = a_shard[i].to(dev)b_device = b.to(dev)results.append(torch.matmul(a_device, b_device))# 把各個設備的結果拼接起來return torch.cat(results, dim=0)# 示例用法:
a = torch.randn(1000, 512) # 假設這個張量太大,一個 GPU 裝不下
b = torch.randn(512, 256)
devices = ['cuda:0', 'cuda:1']result = tensor_parallel_matmul(a, b, devices)
重點收獲
- 大模型 — 當模型太大,裝不下單個 GPU 的內存時,這種方法特別有效哦。
- 分割權重 — 不是在每個設備上復制整個模型,張量并行會把模型的參數切片呢。
- 集體計算 — 前向和反向傳播是在 GPU 之間集體完成的,需要精心協調,以確保張量的所有部分都被正確計算呢。
- 自定義操作 — 往往要用到專門的 CUDA 內核或者第三方庫,才能高效地實現張量并行哦。
優點和注意事項
- 內存效率 — 通過分割大型張量,你就能訓練那些超出單個設備內存的模型啦。它還能顯著減少矩陣操作的延遲呢。
- 復雜性 — 設備之間的協調增加了額外的復雜性哦。當擴展到超過兩個 GPU 時,開發者必須仔細管理同步呢。由于手動分割可能導致的負載不平衡,以及為了避免 GPU 空閑太久而需要進行的設備間通信,是這些實現中常見的問題呢。
- 框架增強 — 像 Megatron-LM 這樣的工具已經為張量并行樹立了標桿,而且很多這樣的框架都能和 PyTorch 無縫集成呢。不過,集成并不總是那么順利哦。
3. 上下文并行
上下文并行采用了一種不同的方法,它針對的是輸入數據的上下文維度,尤其在基于序列的模型(比如 Transformer)中特別厲害呢。主要思想就是把長序列或者上下文信息分割開來,讓不同的部分同時進行處理呢。這樣能讓模型在不超出內存或者計算能力的情況下,處理更長的上下文哦。當需要一起訓練多個任務時,比如在多任務 NLP 模型中,這種方法就特別有用啦。
和張量并行類似,PyTorch 本身并沒有原生支持上下文并行呢。不過,通過巧妙地重構數據,我們就能有效地管理長序列啦。想象一下,有一個 Transformer 模型需要處理長文本 —— 可以把序列分解成更小的片段,然后并行處理,最后再合并起來呢。
下面就是一個自定義 Transformer 塊中上下文如何分割的示例哦。在這個示例中,這個塊可能會并行處理長序列的不同片段,然后把輸出合并起來進行最后的處理呢。
import torch
import torch.nn as nnclass ContextParallelTransformer(nn.Module):def __init__(self, d_model, nhead, context_size):super(ContextParallelTransformer, self).__init__()self.context_size = context_sizeself.transformer_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead)def forward(self, x):# x 的形狀:[batch, seq_len, d_model]batch, seq_len, d_model = x.size()assert seq_len % self.context_size == 0, \"序列長度必須能被 context_size 整除"# 把序列維度分割成片段segments = x.view(batch, seq_len // self.context_size,self.context_size, d_model)# 使用循環或者并行映射并行處理每個片段processed_segments = []for i in range(segments.size(1)):segment = segments[:, i, :, :]processed_segment = self.transformer_layer(segment.transpose(0, 1))processed_segments.append(processed_segment.transpose(0, 1))# 把處理過的片段拼接回完整的序列return torch.cat(processed_segments, dim=1)# 示例用法:
model = ContextParallelTransformer(d_model=512, nhead=8, context_size=16)
# [batch, sequence_length, embedding_dim]
input_seq = torch.randn(32, 128, 512)
output = model(input_seq)
重點收獲
- 序列分割 — 把序列或者上下文維度分割開來,就能在不同的數據片段上并行計算啦。
- 長序列的可擴展性 — 這對于處理特別長的序列的模型特別有用,要是把整個上下文一次性處理,那既不可能,也不高效哦。
- 注意力機制 — 在 Transformer 中,把注意力計算分割到不同的片段上,能讓每個 GPU 處理序列的一部分以及它相關的自注意力計算呢。
優點和注意事項
- 高效的長序列處理 — 把長上下文分割成并行的片段,模型就能在不過度占用內存資源的情況下處理超長的序列啦。
- 序列依賴性 — 必須特別注意跨越上下文片段邊界的依賴關系哦。可能需要采用重疊片段或者額外的聚合步驟等技術呢。
- 新興領域 — 隨著研究的不斷深入,我們期待會有更多專門促進 PyTorch 中上下文并行的標準工具和庫出現呢。
4. 流水線并行

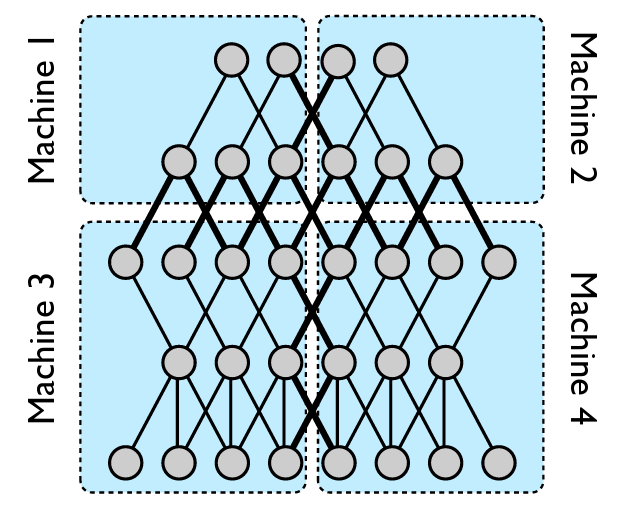
流水線并行示意圖 [圖片來源]
流水線并行引入了把神經網絡分割成一系列階段的概念,每個階段都在不同的 GPU 上進行處理呢。當數據流經網絡時,中間結果會從一個階段傳遞到下一個階段,就像流水線一樣呢。這種錯開的執行方式能讓計算和通信重疊起來,從而提高整體的吞吐量呢。
幸運的是,PyTorch 有一個現成的 API 支持這個功能,叫做 Pipe,用它就能非常輕松地創建分段的模型呢。這個 API 會自動把一個順序模型分割成微批次,這些微批次會在指定的 GPU 上流動呢。
一個簡單的使用示例如下:
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe# 定義模型的兩個順序片段
segment1 = nn.Sequential(nn.Linear(1024, 2048),nn.ReLU(),nn.Linear(2048, 2048)
)segment2 = nn.Sequential(nn.Linear(2048, 2048),nn.ReLU(),nn.Linear(2048, 1024)
)# 使用 Pipe 把片段組合起來
# 如果提供了設備分配,Pipe 會自動處理模塊在設備上的放置
# 這里是自動分配的
model = nn.Sequential(segment1, segment2)
model = Pipe(model, chunks=4)# 現在,當你把數據傳遞給模型時,微批次就會以流水線的方式進行處理啦。
inputs = torch.randn(16, 1024)
outputs = model(inputs)import torch
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe# 定義模型片段
segment1 = nn.Sequential(nn.Linear(1024, 2048),nn.ReLU(),nn.Linear(2048, 2048)
)
segment2 = nn.Sequential(nn.Linear(2048, 2048),nn.ReLU(),nn.Linear(2048, 1024)
)# 使用 Pipe 把片段組合成一個模型
model = nn.Sequential(segment1, segment2)
# 把模型分割成微批次,這些微批次會在 'cuda:0' 和 'cuda:1' 設備上流動
model = Pipe(model, devices=['cuda:0', 'cuda:1'], chunks=4)# 模擬輸入批次
inputs = torch.randn(16, 1024).to('cuda:0')
outputs = model(inputs)
重點收獲
- 分階段計算 — 把模型分割成一系列階段(或者叫“流水線”)。每個階段都分配給不同的 GPU 哦。
- 微批次 — 不是把一個大批次一次性傳給一個階段,而是把批次分割成微批次,這些微批次會持續不斷地流經流水線呢。
- 提高吞吐量 — 通過確保所有設備都在同時工作(即使是在處理不同的微批次),流水線并行可以顯著提高吞吐量哦。
優點和注意事項
- 資源利用 — 流水線并行可以通過重疊不同階段的計算,提高 GPU 的利用率哦。
- 延遲與吞吐量的權衡 — 雖然吞吐量提高了,但可能會因為引入的流水線延遲,稍微影響一下延遲呢。
- 復雜的調度 — 有效的微批次調度和負載平衡對于在各個階段實現最佳性能至關重要哦。
5. 專家并行
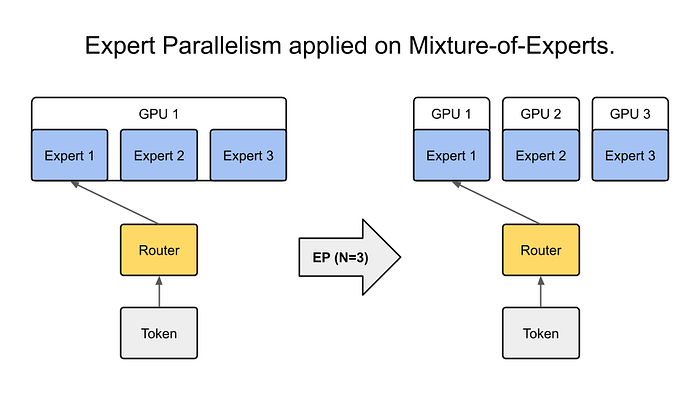
專家并行 [圖片來源]
專家并行是一種受 混合專家模型(MoE) 啟發的技術,旨在在保持計算成本可控的同時,擴展模型的容量呢。在這個范式中,模型由多個專門的“專家”組成 —— 這些子網絡通過一個門控機制,為每個輸入選擇性地激活呢。對于每個樣本,只有部分專家會參與處理,這樣就能在不大幅增加計算開銷的情況下,擁有巨大的模型容量啦。
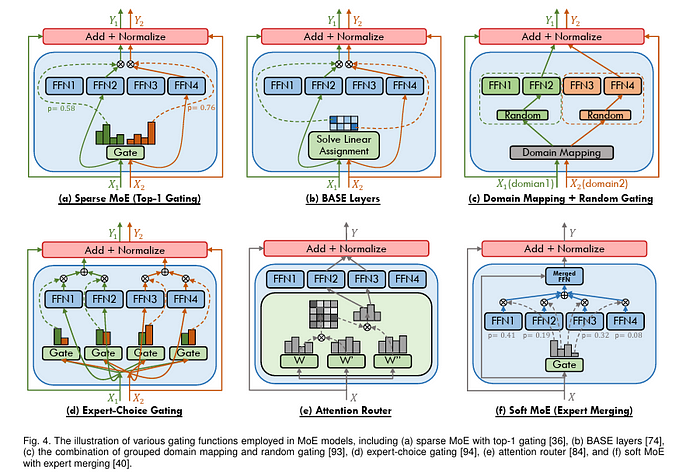
混合專家模型使用的門控函數 [圖片來源]
同樣呢,PyTorch 并沒有直接提供現成的專家并行解決方案哦,不過它模塊化的設計使得創建自定義實現成為可能呢。這種策略通常涉及定義一組專家層,以及一個決定激活哪些專家的門控器呢。
在生產環境中,專家并行通常會和其他并行策略結合起來使用哦。比如,你可以同時使用數據并行和專家并行,既能處理大型數據集,又能處理大量的模型參數 —— 同時,還能通過門控機制,把計算有選擇性地路由到合適的專家那里呢。下面就是一個簡化版的實現示例:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Expert(nn.Module):def __init__(self, input_dim, output_dim):super(Expert, self).__init__()self.fc = nn.Linear(input_dim, output_dim)def forward(self, x):return F.relu(self.fc(x))class MoE(nn.Module):def __init__(self, input_dim, output_dim, num_experts, k=2):super(MoE, self).__init__()self.num_experts = num_expertsself.k = k # 每個樣本使用的專家數量self.experts = nn.ModuleList([Expert(input_dim, output_dim)for _ in range(num_experts)])self.gate = nn.Linear(input_dim, num_experts)def forward(self, x):# x 的形狀:[batch, input_dim]gate_scores = self.gate(x) # [batch, num_experts]# 為每個輸入選擇 top-k 個專家topk = torch.topk(gate_scores, self.k, dim=1)[1]outputs = []for i in range(x.size(0)):expert_output = 0for idx in topk[i]:expert_output += self.experts[idx](x[i])outputs.append(expert_output / self.k)return torch.stack(outputs)# 示例用法:
batch_size = 32
input_dim = 512
output_dim = 512
num_experts = 4
model = MoE(input_dim, output_dim, num_experts)
x = torch.randn(batch_size, input_dim)
output = model(x)
重點收獲
- 混合專家 — 對于每個訓練樣本,只使用部分專家,這樣就能在不大幅增加每個樣本計算量的情況下,保持巨大的模型容量哦。
- 動態路由 — 門控函數會動態決定哪些專家應該處理每個輸入標記或者數據片段呢。
- 專家級別的并行 — 專家可以在多個設備上分布開來,這樣就能并行計算,進一步減少瓶頸啦。
優點和注意事項
- 可擴展的模型容量 — 專家并行讓你能夠構建出容量巨大的模型,而不會因為每個輸入都增加計算量哦。
- 高效的計算 — 通過只為每個輸入處理選定的專家子集,就能實現高效的計算啦。
- 路由復雜性 — 門控機制非常關鍵哦。要是設計得不好,可能會導致負載不平衡和訓練不穩定呢。
- 研究前沿 — 專家并行仍然是一個活躍的研究領域,目前正在進行的研究旨在改進門控方法以及專家之間的同步呢。
6. ZeRO:零冗余優化器
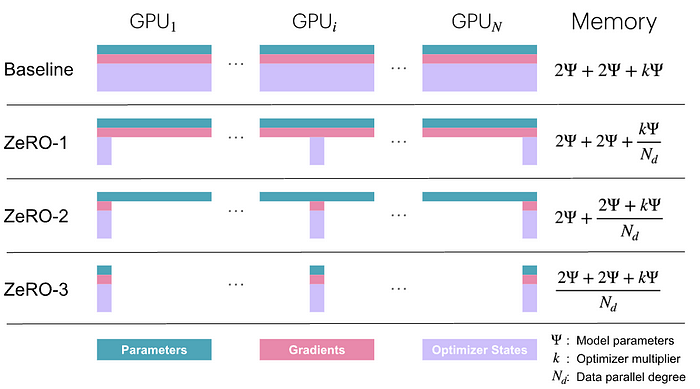
分區策略和 GPU 性能 [圖片來源]
ZeRO,也就是 零冗余優化器,在大規模訓練的內存優化方面可是個突破性的成果哦。作為 DeepSpeed 庫的一部分,ZeRO 通過分區優化器狀態、梯度和模型參數,解決了分布式訓練中的內存限制問題呢。說白了,ZeRO 就是消除了每個 GPU 都保存一份所有東西的冗余,從而節省了大量的內存呢。
它的運作方式是把優化器狀態和梯度的存儲分散到所有參與的設備上,而不是復制它們呢。這種策略不僅能減少內存使用量,還能讓那些原本會超出單個 GPU 內存容量的模型也能進行訓練呢。ZeRO 通常會分三個階段來實現,每個階段都針對不同的內存冗余問題:
ZeRO-1:優化器狀態分區
- 把優化器狀態(比如動量緩沖區)分區到各個 GPU 上呢
- 每個 GPU 只保存其參數部分的優化器狀態哦
- 模型參數和梯度仍然在所有 GPU 上復制呢
ZeRO-2:梯度分區
- 包含了 ZeRO-1 的所有內容呢
- 另外還會把梯度分區到各個 GPU 上哦
- 每個 GPU 只計算并保存其參數部分的梯度呢
- 模型參數仍然在所有 GPU 上復制呢
ZeRO-3:參數分區
- 包含了 ZeRO-1 和 ZeRO-2 的所有內容呢
- 另外還會把模型參數分區到各個 GPU 上哦
- 每個 GPU 只保存模型參數的一部分呢
- 在前向和反向傳播過程中需要收集參數呢
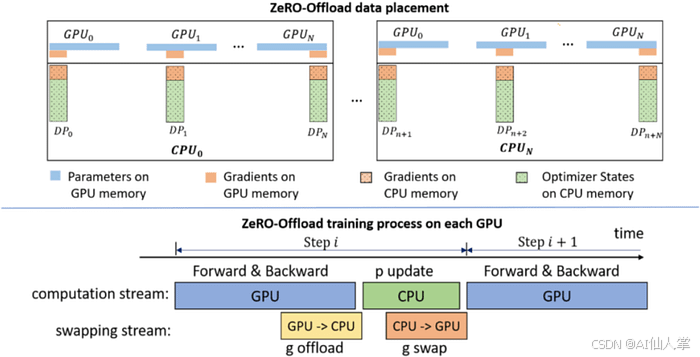
ZeRO Offload 的架構 [圖片來源]
ZeRO 提供了最大的靈活性,因為它結合了數據和模型并行的好處,如上圖所示呢。
雖然 ZeRO 是 DeepSpeed 的一個特性,但它和 PyTorch 的集成使得它成為了訓練優化工具箱中的一個重要工具,有助于高效地管理內存,并讓以前無法訓練的模型大小在現代硬件上成為可能呢。下面是一個示例實現:
import torch
import torch.nn as nn
import deepspeedclass LargeModel(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(LargeModel, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_dim, output_dim)def forward(self, x):x = self.relu(self.fc1(x))return self.fc2(x)model = LargeModel(1024, 4096, 10)# DeepSpeed 配置,帶有 ZeRO 優化器設置
ds_config = {"train_batch_size": 32,"optimizer": {"type": "Adam","params": {"lr": 0.001}},"zero_optimization": {"stage": 2, # 第 2 階段:梯度分區"allgather_partitions": True,"reduce_scatter": True,"allgather_bucket_size": 2e8,"overlap_comm": True}
}# 用 ZeRO 初始化 DeepSpeed 和模型
model_engine, optimizer, _, _ = deepspeed.initialize(model=model,config=ds_config)
inputs = torch.randn(32, 1024).to(model_engine.local_rank)
outputs = model_engine(inputs)
loss = outputs.mean() # 簡化的損失計算
model_engine.backward(loss)
model_engine.step()
重點收獲
- 階段選擇 — ZeRO 通常分多個階段實現,每個階段在內存節省和通信開銷之間提供了不同的平衡呢。根據模型大小、網絡能力以及可以接受的通信開銷水平,選擇合適的階段至關重要哦。
- 與其他技術的集成 — 它可以無縫地融入一個可能還包括上述并行策略的生態系統中呢。
優點和注意事項
- 通信開銷 — 這種策略的一個固有挑戰是,減少內存冗余通常會增加 GPU 之間的數據交換量哦。因此,高效利用高速互連(比如 NVLink 或 InfiniBand)就變得更加關鍵啦,因為這個原因。
- 配置復雜性 — ZeRO 比傳統優化器引入了更多的配置參數呢。這些設置需要仔細地進行實驗和分析,以匹配硬件的優勢,確保優化器能夠高效運行呢。設置內容包括但不限于 — 適當的梯度聚合桶大小,以及各種狀態(優化器狀態、梯度、參數)的分區策略。
- 強大的監控 — 在啟用 ZeRO 的訓練中調試問題可能會非常困難哦。因此,提供對 GPU 內存使用情況、網絡延遲以及整體吞吐量等信息的監控工具就變得至關重要啦,因為這個原因。
把它們全部結合起來
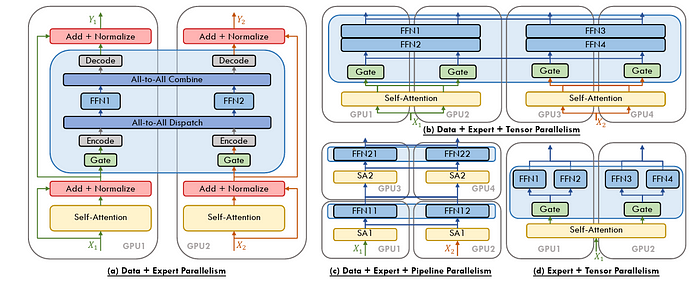
并行的各種混合方法 [圖片來源]
在超大規模下訓練深度學習模型,很多時候都需要采用混合方法 —— 通常會結合上述提到的這些技術呢。比如,一個最先進的 LLM 可能會使用數據并行來在節點之間分配批次,張量并行來分割巨大的權重矩陣,上下文并行來處理長序列,流水線并行來連接順序模型階段,專家并行來動態分配計算資源,最后再用 ZeRO 來優化內存使用呢。這種協同作用確保了即使是參數數量天文數字級別的模型,也仍然能夠進行訓練,并且保持高效的哦。
搞清楚在什么時候、在什么地方以及如何使用這些技術,對于突破可能的極限至關重要呢。再加上 PyTorch 的模塊化和即插即用的庫,構建能夠突破傳統硬件限制的健壯、可擴展的訓練管道,已經變得越來越容易被更多人掌握了呢。
應用技巧)
:[macOS 64bit App開發]: 如何獲取目錄大小?](http://pic.xiahunao.cn/[原創](現代Delphi 12指南):[macOS 64bit App開發]: 如何獲取目錄大小?)
3D數學(4)之四元數Quaternion)
















