導讀
隨著智能物流需求日益增長,特別是“最后一公里”配送場景的精細化,傳統地面機器人逐漸暴露出適應性差、精度不足等瓶頸。為此,本文提出了LogisticsVLN系統——一個基于多模態大語言模型的無人機視覺語言導航框架,專為窗戶級別的終端配送任務設計。
??【深藍AI】編譯
本文由paper一作——Xinyuan Zhang授權【深藍AI】編譯發布!
論文標題:LogisticsVLN: Vision-Language Navigation For Low-Altitude Terminal Delivery Based on Agentic UAVs
論文作者:Xinyuan Zhang, Yonglin Tian, Fei Lin, Yue Liu, Jing Ma, Kornelia Sara Szatmary, Fei-Yue Wang
論文地址:https://www.arxiv.org/abs/2505.03460
與現有研究多聚焦于長距離、粗粒度的目標定位不同,LogisticsVLN面向真實住宅場景中的窗戶級精細導航任務,無需環境先驗地圖或特定訓練。系統通過語言理解模塊解析用戶請求,利用輕量化的VLM完成樓層定位、目標窗口識別,并結合深度輔助機制進行視角選擇與導航控制,最終實現精準投遞。
論文還構建了VLD數據集,模擬復雜住宅環境下的300個任務,涵蓋不同樓層、難度與指令風格。實驗驗證了系統的可行性,并通過模塊級消融分析,評估了VLM在各子任務中的表現優劣。
這項研究不僅填補了空中VLN在終端配送中的空白,還為基礎模型在真實智能物流系統中的部署提供了可行路徑和有益啟示。
1.?引入
在電子商務與城市化迅速發展的推動下,物流系統已成為現代社會中愈發關鍵的組成部分。特別是在終端配送環節,即將商品直接送達用戶住所的最后一步,穩定、高效且以用戶為中心的配送服務需求日益增長。
該研究認為,一種有前景的解決方案是利用具備智能體能力的無人機(Agentic UAVs)執行視覺-語言導航(VLN)任務,來滿足終端配送的需求。
然而,傳統的視覺-語言導航方法大多依賴于基于網絡的模型,這些方法通常需要大量訓練數據來實現泛化。現有基于無人機的VLN研究主要集中在長距離、粗粒度目標的導航任務上,因此難以滿足對終端配送任務中高精度、細粒度導航的需求。雖然近期有研究嘗試將基礎模型用于地面機器人進行樓宇級配送,并取得了無需訓練即可實現的零樣本導航能力,但這種方法無法實現更精細的窗戶級送達目標。
為了解決這些問題,該研究提出了LogisticsVLN系統,這是一個基于輕量級多模態大語言模型(MLLM)的無人機導航系統,具備良好的可擴展性,專為窗戶級終端配送任務而設計。
該系統首先通過大語言模型(LLM)解析用戶的自然語言請求,提取出目標窗戶的關鍵屬性;接著利用視覺-語言模型(VLM)實現樓層定位,引導無人機上升到合適的高度;在抵達目標樓層后,無人機再通過視角選擇算法、目標檢測VLM與決策VLM,在建筑周圍探索尋找目標窗戶。同時系統集成了一個深度感知輔助模塊,提升操作的安全性。
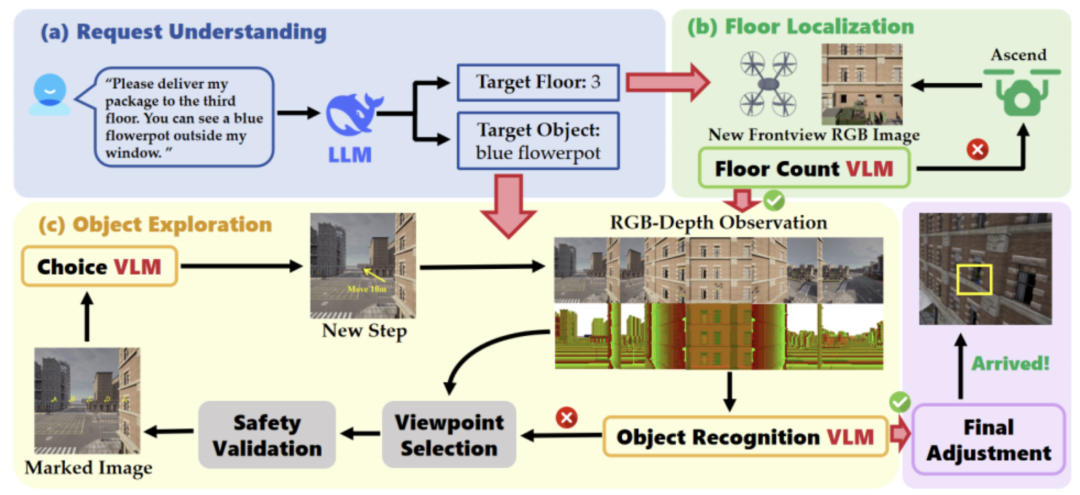
圖1|全文方法總覽??【深藍AI】編譯
2.?具體方法與實現
1.?任務定義
該研究聚焦于面向窗戶級終端配送的空中視覺語言導航任務。任務場景假設無人機從目標建筑附近出發,僅依據用戶提供的自然語言請求,自主導航至指定窗戶位置完成配送。整個過程中不依賴預先構建的環境地圖,更貼近現實中住宅區域缺乏詳盡室內結構信息的實際場景。
在執行任務過程中:
●?無人機以離散時間步推進,每一步都會從傳感器(包括多個方向的 RGB-D 攝像頭)獲取環境觀測;
●?系統融合當前觀測信息與語言描述,通過策略模型動態規劃下一步動作;
●?最終目標是在滿足空間安全約束的前提下,使無人機抵達目標窗戶附近的鄰域區域,實現高精度包裹投遞。
2. 系統總覽
該系統部署于具備智能體能力的無人機平臺上。無人機配備了五組朝向不同角度(前、左前、右前、左側、右側)的 RGB-D 攝像頭,實現對周圍環境的半環繞感知。
配送流程從自然語言請求開始,系統首先使用內嵌的大語言模型解析請求信息;隨后由視覺語言模型模塊完成樓層定位和目標窗戶識別。三個 VLM 被分別用于樓層估計、對象識別和動作決策,并通過一個深度輔助模塊增強空間理解能力。當目標窗戶被成功檢測到后,無人機根據這些模塊的引導精準調整位置,完成包裹的窗戶級配送。
2.1 請求理解
用戶的請求文本通常包含了目標窗戶的位置描述、所在樓層、附近的顯著物體(例如綠色花盆)以及一些無關或干擾性內容。
該系統采用 DeepSeek-R1-Distill-Qwen-14B 模型,結合三步鏈式推理(Chain-of-Thought)設計的提示詞模板,對請求進行解析。通過這一過程,系統提取出兩個關鍵信息:目標樓層編號和顯著參照物,為后續模塊的環境感知和決策提供支持。
2.2 樓層定位
該模塊旨在引導無人機到達目標所在樓層高度,具備以下特點:
●?使用一個基于視覺語言模型構建的樓層計數器(Floor Count VLM);
●?無人機從建筑底部依次飛行到預設的垂直高度點,并在每個高度拍攝正前方圖像;
●?模型分析圖像中可見樓層數,實時更新無人機當前位置的樓層估計;
●?基于當前估計結果與目標樓層的對比,系統決定:
○?繼續上升;
○?或進入樓層內微調階段;
一旦到達目標高度,無人機鎖定該樓層,維持固定飛行高度,進入環繞探索階段。
2.3 目標探索
由于該任務中沒有預構建地圖,無人機需依靠自身感知能力探索目標窗戶。為此,系統設計了一個探索模塊,結合了對象識別 VLM、動作選擇 VLM 和深度輔助模塊。
對象識別:?系統將五個方向的 RGB 圖像輸入對象識別 VLM,并結合顯著參照物的描述,判斷目標窗戶是否在視野內。如果識別成功,系統返回目標窗戶的邊界框,并利用深度信息計算一條安全的接近路徑,確保無人機能夠精準且安全地靠近目標。
視角選擇:?若當前圖像中未檢測到目標窗戶,系統會基于深度圖評估各個攝像頭視角的探索潛力,選出最有可能發現目標的視角繼續移動。該過程通過分析深度圖中的顯著深度變化區來推斷建筑轉角等潛在視野突破口。
動作選擇:?一旦選定新的視角,系統會在圖像上標記若干探索方向,結合深度信息估算每個方向的安全行進距離,并將這些信息連同任務描述送入動作選擇 VLM,選擇最佳的移動方向與距離,從而實現連續、高效且避障的探索行為。
3.實驗
為驗證系統性能,該研究在 CARLA 模擬器中構建了一個名為 VLD 的視覺語言配送數據集,覆蓋22類建筑,共300個窗戶級別配送任務。任務具有多樣的目標類別、樓層分布和不同難度等級,通過模擬不同用戶請求風格,進一步提升數據集的語言多樣性。
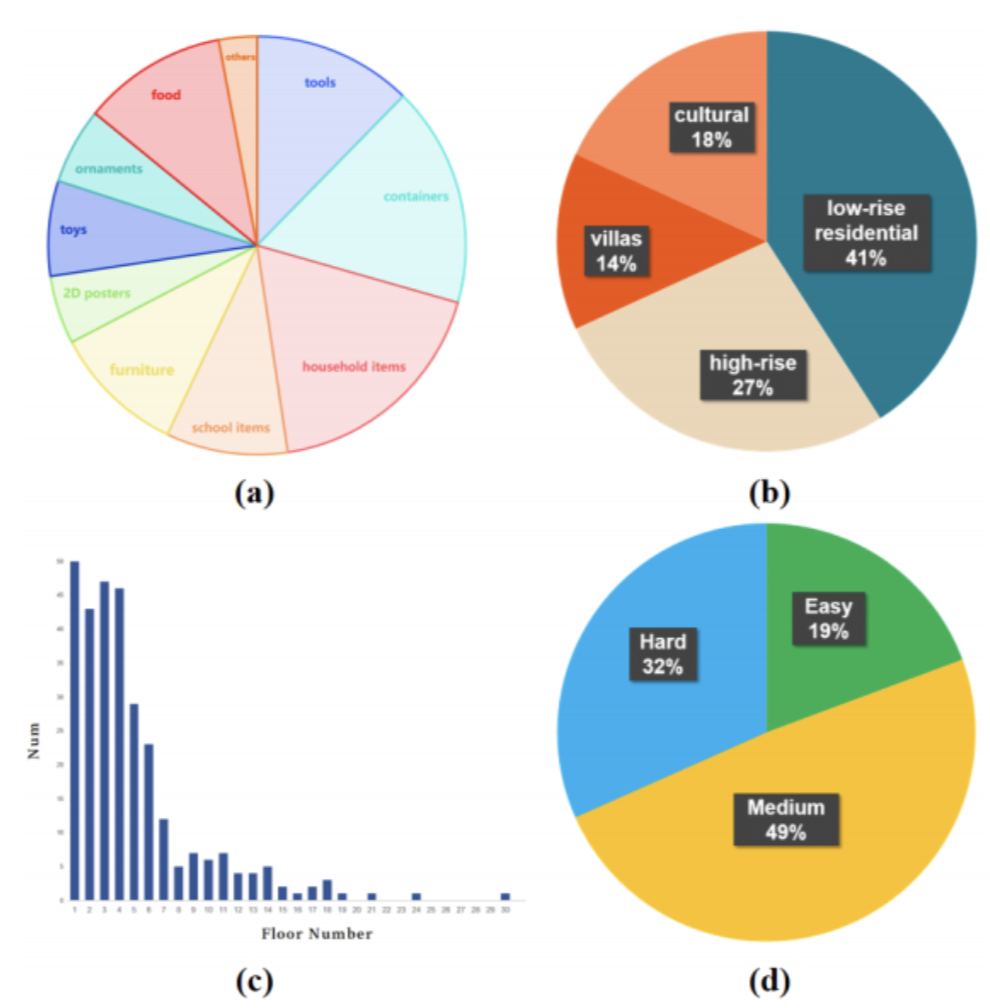
圖4|數據集示例??【深藍AI】編譯
在系統評估中,研究者選用了三種輕量級視覺語言模型(VLM)進行對比。結果顯示,Qwen2-VL 模型表現最佳,在任務完成率與導航效率上均優于 LLaMA-3.1 和 Yi-VL 模型。Yi-VL 模型在任務執行中頻繁拒絕提供明確的樓層判斷,導致定位失敗率較高,而 LLaMA-3.1 也在對象識別與樓層判斷上表現不穩定,尤其容易被顏色等視覺屬性干擾,誤識別目標。
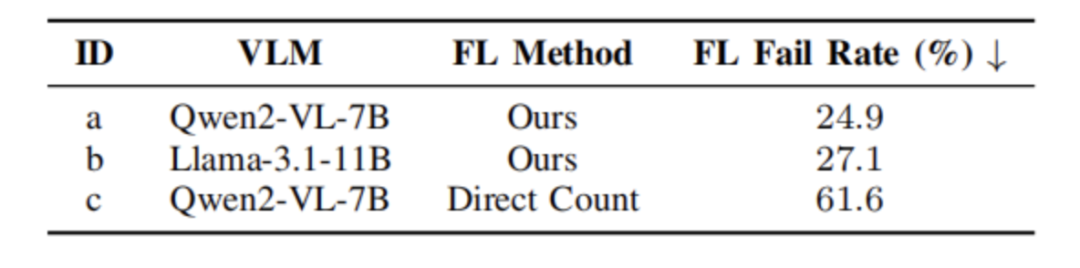
圖5|不同樓層定位結果??【深藍AI】編譯
為進一步驗證系統中各模塊的效果,該研究還設計了多項消融實驗。例如,與傳統樓層計數方式相比,自研的樓層定位方法顯著降低了定位失敗率,提高了系統的穩定性。在探索策略方面,深度驅動的視角選擇算法相比于隨機或默認策略,在成功率和路徑效率上也有明顯優勢,尤其在需要繞行建筑多面的“困難任務”中表現突出。
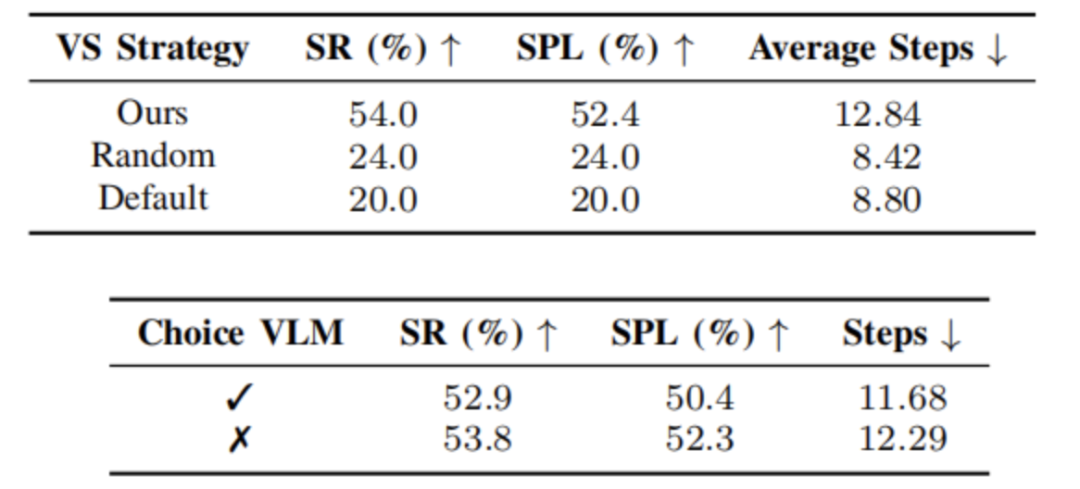
圖6|消融實驗結果??【深藍AI】編譯
盡管動作選擇模塊(Choice VLM)在整體指標上提升有限,但在視角選擇不理想的情況下,其策略性判斷能有效避免死鎖和碰撞,保障任務安全完成。
總結
這項研究提出了一個叫 LogisticsVLN 的系統,目標是讓無人機能夠自動把包裹送到用戶家窗戶前,整個過程不需要提前訓練、也不需要地圖。系統主要依靠“多模態大模型”來理解語言、識別圖像,并做出導航決策。
為了測試這個系統是否真的有效,研究團隊在一個逼真的虛擬城市環境里,設計了一個專門的數據集,模擬了各種建筑、不同風格的用戶請求和復雜的送貨場景。實驗結果表明,LogisticsVLN 不僅能完成任務,還能較好應對樓層定位、窗戶識別等挑戰。
更重要的是,研究者還對系統中的每個關鍵環節做了分析,比如:哪種模型更適合識別樓層?哪種算法能更聰明地選擇視角來探索?這些分析幫助大家更清楚地了解大模型在真實配送任務中的優點與不足。
未來,該團隊計劃繼續優化系統結構,讓它能更充分地發揮大模型的能力,并探索如何把這套方案真正用在現實中的空中配送服務中。







)










)
