文章目錄 流水線stage分屬前后端 PC pipeline IF ID DP DP 與 SW 中間沒有latch SW COM
IF -> ID -> DP -> SW -> EX -> COM
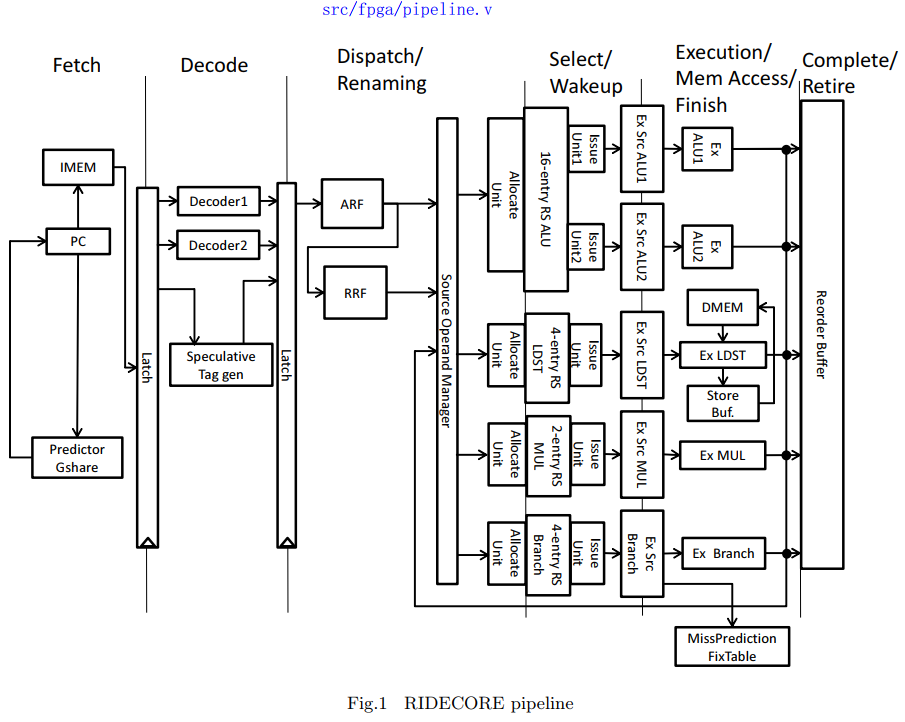
分類 階段 說明 前端 IF 指令獲取階段。PC 使用分支預測器,訪問指令存儲器。典型前端操作。 前端 ID 解碼并寄存器重命名,這仍然屬于前端操作,因為沒有開始實際執行。 中間(交界處) DP 分發階段是前端和后端的“橋梁”:它決定指令是否能夠進入執行系統(Reservation Station)。 后端 SW Issue 階段已經涉及硬件調度和等待執行資源。 后端 EX 執行階段。指令在對應的執行單元中運行。 后端 COM 提交/寫回階段,更新寄存器狀態和 ROB,徹底屬于后端。
Dispatch(DP)階段通常被認為是“前端的最后階段”或者“前后端的分界點”。它從解碼器/ 寄存器重命名器中取出指令,并將它們放入合適的 Reservation Station(RS)。你可以把它看成是:前端準備好的指令交給后端執行的關鍵一步,所以分析系統時,很多資料會將 DP 歸為前端,但也有資料將它作為交界點來單獨分析。結論:DP 更偏向前端,但有一定后端屬性。
PC的值根據優先級優先級1 ( top) : reset時 : ENTRY_POINT 優先級2 : prmiss : jmpaddr : stall_IF : pc : 其余情況 : npc
1.指令的獲取及invalid // 不考慮
2.npc的計算
npc的計算gshare 命中 : btb中計算出來的 地址第二條指令 invalid : pc+ 4 其他 : pc+ 8 gshare 的設計 模塊BHR PHT PCBTB 流程在每個時鐘的負邊沿,使用的讀取地址是 PC[ 12 : 3 ] 和 BHR 做異或(⊕)得到的結果, 從 PHT 中讀取預測信息. 如果( 讀出的值大于1 , 即2 或3 ) 跳轉(Taken):用 PC 查 BTB → 得到 跳轉目標地址將目標地址 更新到 npc否則(Not Taken):npc += 4 or 8 (順序執行)模塊讀寫BHR 的讀寫會基于當前預測結果進行更新;但如果最終證明預測是錯誤的,BHR 會回滾到更新前的狀態。因此,在每次更新之前,BHR 都會先被備份。PHT 的讀寫 讀一個用于 IF 階段;一個用于 COM 階段。寫一個寫端口用于 COM 階段的寫操作 BTB 的讀寫TODO1. 按地址 0x4 取指, 那么 inst2 會 invalid 嗎 ? 另外, 豈不是 會存在 一拍 沒有 inst2 發送到后端 會是的,確實會出現某一拍中只有一條有效指令(Inst1)被送入 IF/ ID latch。
1. 給 每一條處于投機路徑的指令 分配一個 Speculative Tag
2. 解碼
項目 內容 功能 為每條投機路徑上的指令分配 Speculative Tag,以支持分支恢復 核心輸出 sptagN 和 speculativeN使用者 Decoder、Dispatch、ROB、RS(Reservation Station)、Commit 等 解決問題 精確追蹤投機指令,支持分支預測失敗時快速恢復系統狀態
模塊 主要用途 寄存器重命名 tag(如RRF中分配的物理寄存器編號) 建立寫后讀/寫后寫依賴關系,支持亂序執行 投機 tag(Tag Generator 生成) 標記哪些指令是投機的,支持錯誤恢復
以一個預測成功的分支為例:
分支指令 B 發射 → branchvalid1=1, enable=1 Tag Generator: 分配一個新的 Tag(比如 00010) 設置 sptag1=00010, speculative1=1 tagreg 左移(進入下一輪準備)brdepth+1 后續投機指令 C、D、E 都被分配同樣的 sptag=00010 如果分支 B 后來預測成功(prsuccess=1): brdepth--,該 Tag 被釋放,其他無影響 如果分支 B 后來預測失敗(prmiss=1): tagreg ← tagregfix(恢復到分支預測前狀態)brdepth ← 0所有 sptag==00010 的指令都將被清除(flush) 階段 動作 模塊 說明 IF 預測(Prediction) Branch Predictor(BTB / GShare) 猜跳不跳、跳到哪,控制 PC ID 恢復環境(Prediction) Speculative Tag gen 跟蹤指令的投機狀態 EX 驗證(Resolution) exunit_branch分支指令實際執行,看預測對不對,發出 prsuccess / prmiss 信號
1.為每個指令中的"被寫入寄存器" 分配 rename register
2.
tag generator 與 寄存器重命名機制 原理 tag generator避免 寫后讀(RAW)( Read After Write) 、寫后寫(WAW)、讀后寫(WAR) 等寄存器沖突( 亂序執行導致的沖突) 問題,會使用寄存器重命名機制每條指令的目標寄存器在進入后端之前都會被重新命名為一個“Tag”,這個 tag 是由 Tag Generator 生成的。
模塊 功能 Tag Generator 為目標寄存器生成唯一的標識符(Tag),用于寄存器重命名與依賴跟蹤 所在階段 通常在 Decode 或 Dispatch 階段 在亂序中的地位 關鍵,維持指令依賴關系和正確性
模塊Architected Register File ( ARF) :程序員視角下的寄存器集合(邏輯寄存器)Rename Register File ( RRF) :物理寄存器集合(或者是寄存器標記表)Reorder Buffer ( ROB) :保持提交順序,支持恢復/ 回滾Tag Generator:為每條指令分配唯一標識符(tag),表示結果的位置
步驟 描述 分配 tag 為每個目標寄存器分配唯一 tag 更新 Rename Table 建立邏輯寄存器到物理 tag 的映射 消除冒險 使用 tag 跟蹤依賴,避免多個指令寫同一個寄存器 回寫/提交 使用 ROB 確保亂序執行但順序提交
如果只是順序執行,那么根本不需要引入 RRF
為了支持亂序執行,必須引入物理寄存器(RRF)來保存未提交的指令結果,并通過 tag 建立依賴關系,使得即使寫同一個邏輯寄存器也能正確調度。
亂序執行了之后,也需要計算依賴,然后重新執行吧,是不是浪費資源了只有發生 分支錯誤預測 時,才需要回滾和重新執行后續指令。這種情況雖然代價高,但在正確率高的預測器(如 Gshare)下,概率已經較低。




)










)


)
