深度學習中的 Dropout 技術在代碼層面上的實現通常非常直接。其核心思想是在訓練過程中,對于網絡中的每個神經元(或者更精確地說,是每個神經元的輸出),以一定的概率 p 隨機將其輸出置為 0。在反向傳播時,這些被“drop out”的神經元也不會參與梯度更新。
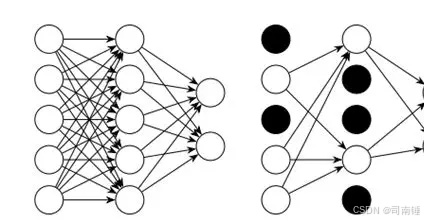
以下是 Dropout 在代碼層面上的一個基本實現邏輯,以 Python 和 NumPy 為例進行說明,然后再展示在常見的深度學習框架(如 TensorFlow 和 PyTorch)中的實現方式。
1. NumPy 實現(概念演示)
假設我們有一個神經網絡的某一層輸出 activation,它是一個形狀為 (batch_size, num_neurons) 的 NumPy 數組。我們可以通過以下步驟實現 Dropout:
Python
import numpy as npdef dropout_numpy(activation, keep_prob):"""使用 NumPy 實現 Dropout。Args:activation: 神經網絡層的激活輸出 (NumPy array).keep_prob: 保留神經元的概率 (float, 0 到 1 之間).Returns:經過 Dropout 處理的激活輸出 (NumPy array).mask: 用于記錄哪些神經元被 drop out 的掩碼 (NumPy array)."""if keep_prob < 0. or keep_prob > 1.:raise ValueError("keep_prob must be between 0 and 1")# 生成一個和 activation 形狀相同的隨機掩碼,元素值為 True 或 Falsemask = (np.random.rand(*activation.shape) < keep_prob)# 將掩碼應用于激活輸出,被 drop out 的神經元輸出置為 0output = activation * mask# 在訓練階段,為了保證下一層的期望輸入不變,需要對保留下來的神經元輸出進行縮放output /= keep_probreturn output, mask# 示例
batch_size = 64
num_neurons = 128
activation = np.random.randn(batch_size, num_neurons)
keep_prob = 0.8dropout_output, dropout_mask = dropout_numpy(activation, keep_prob)print("原始激活輸出的形狀:", activation.shape)
print("Dropout 后的激活輸出的形狀:", dropout_output.shape)
print("Dropout 掩碼的形狀:", dropout_mask.shape)
print("被 drop out 的神經元比例:", np.sum(dropout_mask == False) / dropout_mask.size)
代碼解釋:
keep_prob: 這是保留神經元的概率。Dropout 的概率通常設置為1 - keep_prob。- 生成掩碼 (
mask): 我們使用np.random.rand()生成一個和輸入activation形狀相同的隨機數數組,其元素值在 0 到 1 之間。然后,我們將這個數組與keep_prob進行比較,得到一個布爾類型的掩碼。True表示對應的神經元被保留,False表示被 drop out。 - 應用掩碼 (
output = activation * mask): 我們將掩碼和原始的激活輸出進行逐元素相乘。由于布爾類型的True和False在數值運算中會被轉換為 1 和 0,所以掩碼中為False的位置對應的激活輸出會被置為 0。 - 縮放 (
output /= keep_prob): 這是一個非常重要的步驟。在訓練階段,由于一部分神經元被隨機置為 0,為了保證下一層神經元接收到的期望輸入與沒有 Dropout 時大致相同,我們需要對保留下來的神經元的輸出進行放大。放大的倍數是1 / keep_prob。
需要注意的是,在模型的評估(或推理)階段,通常不會使用 Dropout。這意味著 keep_prob 會被設置為 1,或者 Dropout 層會被禁用。這是因為 Dropout 是一種在訓練時使用的正則化技術,用于減少過擬合。在評估時,我們希望模型的所有神經元都參與計算,以獲得最準確的預測。
2. TensorFlow 實現
在 TensorFlow 中,Dropout 是一個內置的層:
Python
import tensorflow as tf# 在 Sequential 模型中添加 Dropout 層
model = tf.keras.models.Sequential([tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),tf.keras.layers.Dropout(0.2), # Dropout 概率為 0.2 (即 keep_prob 為 0.8)tf.keras.layers.Dense(10, activation='softmax')
])# 或者在函數式 API 中使用
inputs = tf.keras.Input(shape=(784,))
x = tf.keras.layers.Dense(128, activation='relu')(inputs)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = tf.keras.layers.Dense(10, activation='softmax')(x)
model_functional = tf.keras.Model(inputs=inputs, outputs=outputs)# 訓練模型
# model.compile(...)
# model.fit(...)
在 TensorFlow 的 tf.keras.layers.Dropout(rate) 層中,rate 參數指定的是神經元被 drop out 的概率。在訓練時,這個層會隨機將一部分神經元的輸出置為 0,并對剩下的神經元進行縮放。在推理時,這個層不會有任何作用。TensorFlow 內部會自動處理訓練和推理階段的行為。
3. PyTorch 實現
在 PyTorch 中,Dropout 也是一個內置的模塊:
代碼段
import torch
import torch.nn as nnclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(784, 128)self.relu = nn.ReLU()self.dropout = nn.Dropout(p=0.2) # Dropout 概率為 0.2self.fc2 = nn.Linear(128, 10)self.softmax = nn.Softmax(dim=1)def forward(self, x):x = self.fc1(x)x = self.relu(x)x = self.dropout(x)x = self.fc2(x)x = self.softmax(x)return xmodel = Net()# 設置模型為訓練模式 (啟用 Dropout)
model.train()# 設置模型為評估模式 (禁用 Dropout)
model.eval()# 在前向傳播中使用 Dropout
# output = model(input_tensor)
在 PyTorch 的 nn.Dropout(p) 模塊中,p 參數指定的是神經元被 drop out 的概率。與 TensorFlow 類似,PyTorch 的 Dropout 在訓練模式 (model.train()) 下會啟用,隨機將神經元置零并縮放輸出。在評估模式 (model.eval()) 下,Dropout 層會失效,相當于一個恒等變換。
總結
在代碼層面上,Dropout 的實現主要涉及以下幾個步驟:
- 生成一個隨機的二值掩碼,其形狀與神經元的輸出相同,掩碼中每個元素以一定的概率(Dropout 概率)為 0,以另一概率(保留概率)為 1。
- 將這個掩碼與神經元的輸出逐元素相乘,從而將一部分神經元的輸出置為 0。
- 在訓練階段,對保留下來的神經元的輸出進行縮放,通常除以保留概率。
- 在評估階段,禁用 Dropout,即不進行掩碼操作和縮放。
現代深度學習框架已經將 Dropout 的實現封裝在專門的層或模塊中,用戶只需要指定 Dropout 的概率即可,框架會自動處理訓練和評估階段的不同行為。這大大簡化了在模型中應用 Dropout 的過程。
![AtCoder AT_abc406_c [ABC406C] ~](http://pic.xiahunao.cn/AtCoder AT_abc406_c [ABC406C] ~)






)








)


