Improving Transferability of Adversarial Samples via Critical Region-Oriented Feature-Level Attack
- 摘要-Abstract
- 引言-Introduction
- 相關工作-Related Work
- 提出的方法-Proposed Method
- 問題分析-Problem Analysis
- 擾動注意力感知加權-Perturbation Attention-Aware Weighting
- 區域 ViT 關鍵檢索-Region ViT-Critical Retrieval
- 損失函數-Loss Functions
- 實驗-Experiments
- 討論-Discussion
- 結論-Conclusion

論文鏈接
本文 “Improving Transferability of Adversarial Samples via Critical Region-Oriented Feature-Level Attack” 提出基于關鍵區域的特征級攻擊(CRFA)方法提升對抗樣本遷移性,包括擾動注意力感知加權(PAW)和區域 ViT 關鍵檢索(RVR)。PAW 通過生成近似注意力圖加權對抗擾動,減少對模型注意力的改變,提升跨模型遷移性,尤其是在攻擊多目標圖像時效果顯著;RVR 搜索對 ViT 輸出有重要影響的關鍵 patch,引入 ViT 先驗知識,提高對抗樣本在 ViT 上的跨架構遷移性。實驗表明,CRFA 生成的對抗樣本在 CNN 和 ViT 模型上,相比現有特征級攻擊方法,愚弄率分別提高了 19.9% 和 25.0% ,視覺質量更優,驗證了該方法的有效性。
摘要-Abstract
Deep neural networks (DNNs) have received a lot of attention because of their impressive progress in computer vision. However, it has been recently shown that DNNs are vulnerable to being spoofed by carefully crafted adversarial samples. These samples are generated by specific attack algorithms that can obfuscate the target model without being detected by humans. Recently, feature-level attacks have been the focus of research due to their high transferability. Existing state-of-the-art feature-level attacks all improve the transferability by greedily changing the attention of the model. However, for images that contain multiple target class objects, the attention of different models may differ significantly. Thus greedily changing attention may cause the adversarial samples corresponding to these images to fall into the local optimum of the surrogate model. Furthermore, due to the great structural differences between vision transformers (ViTs) and convolutional neural networks (CNNs), adversarial samples generated on CNNs with feature-level attacks are more difficult to successfully attack ViTs. To overcome these drawbacks, we perform the Critical Region-oriented Feature-level Attack (CRFA) in this paper. Specifically, we first propose the Perturbation Attention-aware Weighting (PAW), which destroys critical regions of the image by performing feature-level attention weighting on the adversarial perturbations without changing the model attention as much as possible. Then we propose the Region ViT-critical Retrieval (RVR), which enables the generator to accommodate the transferability of adversarial samples on ViTs by adding extra prior knowledge of ViTs to the decoder. Extensive experiments demonstrate significant performance improvements achieved by our approach, i.e., improving the fooling rate by 19.9% against CNNs and 25.0% against ViTs as compared to state-of-the-art feature-level attack method.
深度神經網絡(DNNs)因其在計算機視覺領域取得的顯著進展而備受關注。然而,最近研究表明,DNNs容易受到精心制作的對抗樣本的欺騙。這些樣本由特定的攻擊算法生成,能夠迷惑目標模型且不易被人類察覺。近年來,特征級攻擊因其較高的遷移性成為研究熱點。現有的前沿特征級攻擊方法均通過貪婪地改變模型的注意力來提高遷移性。然而,對于包含多個目標類對象的圖像,不同模型的注意力可能存在顯著差異。因此,貪婪地改變注意力可能會導致對應這些圖像的對抗樣本陷入代理模型的局部最優解。此外,由于視覺 Transformer(ViTs)和卷積神經網絡(CNNs)在結構上存在巨大差異,通過特征級攻擊在 CNNs 上生成的對抗樣本更難成功攻擊 ViTs。為克服這些缺點,本文提出了基于關鍵區域的特征級攻擊(CRFA)。具體而言,我們首先提出了擾動注意力感知加權(PAW)方法,該方法通過對對抗擾動進行特征級注意力加權來破壞圖像的關鍵區域,同時盡可能不改變模型的注意力。然后,我們提出了區域 ViT 關鍵檢索(RVR)方法,通過向解碼器添加 ViTs 的額外先驗知識,使生成器能夠適應對抗樣本在 ViTs 上的遷移性。大量實驗表明,我們的方法在性能上有顯著提升,與最先進的特征級攻擊方法相比,對 CNNs 的愚弄率提高了19.9%,對 ViTs 的愚弄率提高了25.0%.
引言-Introduction
這部分內容主要介紹了研究背景和動機,具體如下:
- DNNs的廣泛應用與安全問題:近年來,DNNs 在圖像分類、分割、檢索等眾多視覺任務中得到廣泛應用且表現出色。隨著物聯網、軟件開發等領域對安全問題的深入探索,DNNs 的魯棒性備受關注。研究發現,DNNs 易受對抗樣本欺騙,這些樣本由惡意添加的精心設計的擾動產生,難以被察覺卻能使模型輸出錯誤結果。因此,對抗攻擊在人臉識別、工業系統、自動駕駛等領域受到高度關注,同時也為神經網絡的可解釋性和魯棒性研究提供了思路。
- 對抗攻擊的分類:根據攻擊者對模型信息的獲取程度,對抗攻擊可分為白盒攻擊和黑盒攻擊。白盒攻擊中攻擊者能獲取目標模型的結構和參數;而在現實應用中,DNNs 多部署在黑盒環境下,目標模型未知,所以黑盒攻擊更具實際意義。黑盒攻擊又可大致分為基于查詢的攻擊和基于遷移的攻擊。基于查詢的攻擊通過向目標模型發送查詢獲取概率向量或硬標簽來生成對抗樣本,但在現實中大量查詢往往受限。基于遷移的攻擊則利用對抗樣本的跨模型遷移性,在代理模型上生成對抗樣本并直接攻擊目標模型,受到越來越多的關注 。
- 現有攻擊方法的局限性與特征級攻擊的發展:傳統攻擊方法(如 FGSM、PGD、BIM 等)生成的對抗樣本在代理模型上常出現過擬合問題,導致跨模型遷移性受限。以往方法通過在對抗樣本優化過程中添加額外操作來緩解過擬合,也有一些方法在特征空間設計對抗擾動,即特征級攻擊。特征級攻擊利用模型內部特征信息,由于影響圖像類別的關鍵特征在不同模型間有較高重疊,該方法在提高對抗樣本跨模型遷移性方面展現出潛力。早期特征級攻擊(如 NRDM、TAP)不加區分地扭曲目標模型內部特征,過度強調非關鍵特征,使生成的對抗樣本易陷入代理模型的局部最優,阻礙了遷移性。近期的一些方法(如 FIA、NAA)雖提出了衡量特征重要性的方法,但對于包含多個目標對象的圖像,不同模型的注意力差異較大,修改后的注意力區域可能與目標模型不匹配,導致對抗樣本攻擊失敗。
- 本文的研究內容與貢獻:為緩解當前特征級攻擊的不足,本文提出了 PAW 方法,通過用生成的近似注意力圖對對抗擾動進行加權,顯著提高對抗樣本的跨模型遷移性,尤其是在攻擊多目標圖像時效果明顯。同時,提出 RVR 方法,通過搜索對 ViTs 輸出有重要影響的圖像關鍵 patch 并將其作為加權項,提高對抗樣本在 ViTs 上的跨架構遷移性。綜合實驗證實,本文提出的 CRFA 方法能兼顧對抗樣本在 CNNs 和 ViTs 上的遷移性,與現有最先進的特征級攻擊方法相比,對 CNNs 和 ViTs 的愚弄率分別提高了19.9%和25.0%.
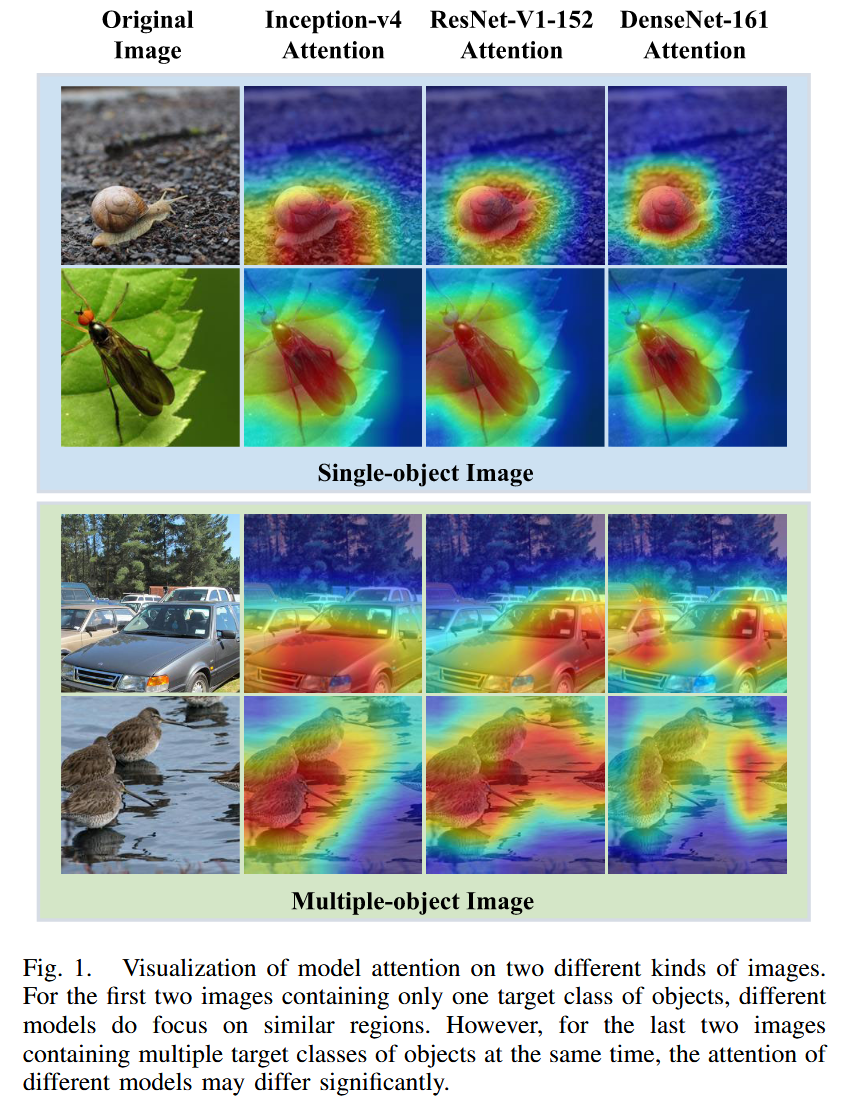
圖1. 兩種不同類型圖像上模型注意力的可視化。前兩張圖像僅包含一個目標類別的對象,不同模型確實聚焦于相似區域。然而,對于最后兩張同時包含多個目標類別的圖像,不同模型的注意力可能存在顯著差異。
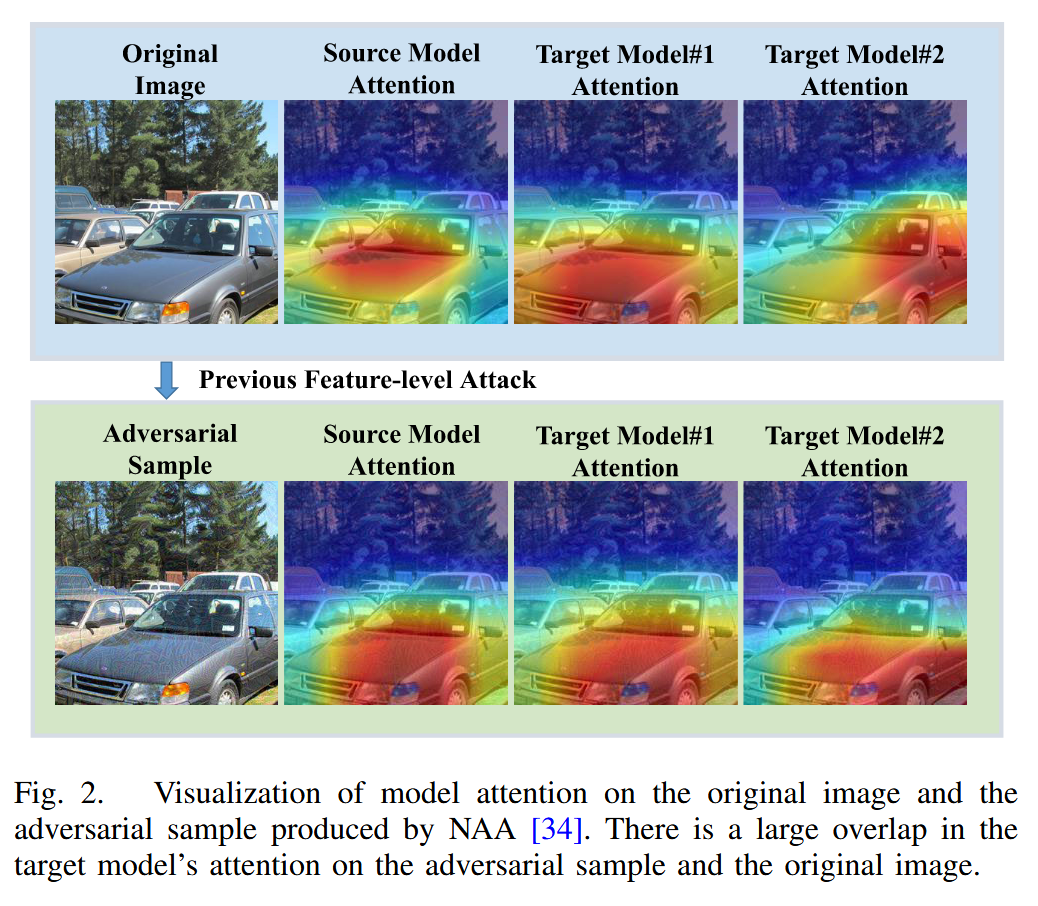
圖2. 原圖像以及由神經元歸因攻擊(NAA)方法生成的對抗樣本上的模型注意力可視化。目標模型對對抗樣本和原圖像的注意力存在很大重疊。
相關工作-Related Work
該部分主要回顧了與深度神經網絡對抗攻擊相關的研究工作,包括白盒攻擊、黑盒攻擊和特征級攻擊,具體內容如下:
- 對抗攻擊場景分類:根據攻擊者獲取目標模型信息的程度,攻擊場景分為白盒攻擊和黑盒攻擊。白盒攻擊中攻擊者可獲取模型結構、訓練參數和防御方法等所有信息;黑盒攻擊則需要攻擊者通過間接方式實施攻擊。
- 白盒攻擊:在白盒攻擊設置下,基于梯度的攻擊是最常見的方法。例如,快速梯度符號法(FGSM)通過用損失函數的梯度符號正向更新良性圖像,并使用步長控制擾動的 L ∞ L_{\infty} L∞? 范數來生成對抗樣本;迭代快速梯度符號法(I - FGSM)是 FGSM 的迭代版本;投影梯度下降法(PGD)通過固定次數的 FGSM 迭代或直到出現誤分類來生成對抗樣本;Carlini 和 Wagner 攻擊(C&W)通過優化降低損失函數并引入超參數 κ κ κ 控制攻擊強度來生成對抗樣本。
- 黑盒攻擊:在實際任務中,目標模型通常是未知的,白盒攻擊因高度依賴梯度信息難以在現實中部署,因此黑盒攻擊近年來受到越來越多的關注。黑盒攻擊大致可分為基于查詢的攻擊和基于遷移的攻擊。基于查詢的攻擊通過不斷向目標模型發出查詢以獲取硬標簽或輸出概率向量來生成對抗樣本,但在現實中大量查詢不被允許,查詢成本與對抗樣本數量大致呈線性關系,存在實際限制。基于遷移的攻擊利用對抗樣本的跨模型遷移性,使用在已知的代理模型上精心制作的對抗樣本來攻擊未知結構和參數的目標模型。許多工作通過設計梯度更新方法(如動量迭代法(MIM)、Nesterov迭代法(NIM))避免對抗樣本因貪婪迭代陷入局部最優,還有一些工作通過變換輸入圖像(如多樣輸入法(DIM)、平移不變法(TIM))來減輕過擬合程度,基于對象的多樣輸入(ODI)通過將輸入圖像投影到 3D 表面進行攻擊,Zhang 等人利用額外的增強路徑來擴展輸入圖像的多樣性,這些基于變換的攻擊可以靈活地與其他攻擊方法結合。
- 特征級攻擊:考慮到白盒攻擊在現實中的不適用性,本文旨在增強黑盒設置下對抗樣本的遷移性。特征級攻擊通過關注模型的內部特征層來進一步提高對抗樣本的遷移性。例如,TAP 通過最大化對抗樣本與原始圖像在代理模型特定特征層上的距離來生成對抗樣本;NRDM 借鑒此思想生成在不同視覺任務中具有高遷移性的對抗樣本。然而,這些早期特征級攻擊方法簡單地貪婪破壞代理模型的內部特征,容易使對抗樣本陷入局部最優。后續的 FDA 使用通道的平均激活值來衡量不同特征的重要性,但僅根據是否大于平均激活值將特征分為正負兩類;FIA 通過計算反向傳播梯度和激活值的乘積獲得特征重要性圖,通過破壞在模型決策中起關鍵作用的特征來生成對抗樣本;NAA 使用集成梯度來進一步提高對抗樣本的遷移性,以應對 FIA 可能出現的梯度飽和問題。特征級攻擊生成的對抗樣本的高遷移性是基于不同模型之間關鍵特征的共享,但對于包含多個目標類對象的圖像,不同模型的關注區域往往不同,改變后的關注區域可能與目標模型重疊,從而降低對抗樣本的跨模型遷移性。此外,視覺 Transformer(ViTs)在視覺任務中表現出色且比傳統 CNNs 更具魯棒性,由于 CNNs 和 ViTs 之間的結構差異,在 CNNs 上生成的對抗樣本往往難以遷移到 ViTs 上。現有基于遷移的黑盒對抗攻擊分別考慮 CNNs 和 ViTs,沒有致力于減少兩種不同架構之間攻擊有效性的差異。本文提出的 RVR 方法通過讓生成器更關注對 ViTs 輸出類別有顯著影響的 patch,在不影響對 CNNs 攻擊成功率的情況下,盡可能提高對抗樣本在 ViTs 上的遷移性。
提出的方法-Proposed Method
問題分析-Problem Analysis
這部分主要分析了基于遷移的黑盒對抗攻擊中存在的問題,并提出了本文的解決思路,具體內容如下:
- 對抗樣本的定義與條件:將用于圖像分類任務的深度神經網絡表示為函數 f θ ( x ) f_{\theta}(x) fθ?(x),其中 θ \theta θ 代表模型參數, x x x 是原始輸入圖像,其真實標簽為 t t t,函數輸出是對應輸入圖像 x x x 的概率向量, f θ ( x ) [ c ] f_{\theta}(x)[c] fθ?(x)[c] 表示 x x x 屬于類別 c c c 的輸出 logit 值 。對抗樣本 x a d v = x + δ x^{adv}=x+\delta xadv=x+δ 通過在輸入圖像 x x x 上疊加精心設計的對抗擾動 δ \delta δ 得到,需滿足兩個條件:一是 a r g m a x c f θ ( x a d v ) [ c ] ≠ t \underset{c}{arg max } f_{\theta}\left(x^{adv}\right)[c] \neq t cargmax?fθ?(xadv)[c]=t,即讓分類器輸出錯誤標簽;二是 ∥ δ ∥ p ≤ ? \| \delta\| _{p} \leq \epsilon ∥δ∥p?≤?,使用 ? ∞ \ell_{\infty} ?∞? 范數約束擾動,使對抗樣本具有實際意義。
- 以往特征級攻擊的問題:基于遷移的黑盒對抗攻擊的核心是在代理模型上生成具有高遷移性的對抗樣本。然而,以往大多數特征級攻擊嚴重依賴代理模型對單個輸入圖像的梯度信息,這使得生成的對抗樣本容易過度擬合代理模型,在不同模型間的遷移性受限。
- 本文的解決思路:本文采用基于生成器的方法,學習從輸入圖像到對抗樣本的直接映射。這種映射是基于訓練數據分布進行學習的,而非針對單個圖像,從而有效緩解了過擬合問題。此外,在生成器的優化過程中,添加特定的先驗知識,幫助生成器更加關注對 CNNs 和 ViTs 輸出類別影響較大的敏感區域,進而提升對抗樣本的跨模型遷移性。
擾動注意力感知加權-Perturbation Attention-Aware Weighting
這部分主要介紹了擾動注意力感知加權(PAW)方法,旨在提升多目標圖像對抗樣本的跨模型遷移性,具體內容如下:
- 方法提出的背景:對于包含多個目標類對象的圖像,不同模型的注意力區域差異顯著。以往特征級攻擊通過貪婪地改變代理模型的注意力區域來生成對抗樣本,這會使對應這些圖像的對抗樣本陷入局部最優,影響其遷移性。因此,PAW 方法摒棄直接破壞代理模型內部特征的方式,采用基于近似注意力圖對擾動進行加權的策略,讓生成器聚焦關鍵區域的同時盡量不改變模型注意力。
- 計算特征重要性圖和注意力圖:
- 用空間池化梯度計算特征圖 A k c ( x ) A_{k}^{c}(x) Akc?(x) 的重要性圖 α k c ( x ) [ t ] \alpha_{k}^{c}(x)[t] αkc?(x)[t],公式為 α k c ( x ) [ t ] = 1 M ∑ i ∑ j ? f θ ( x ) [ t ] ? A k c ( x ) [ i , j ] \alpha_{k}^{c}(x)[t]=\frac{1}{M} \sum_{i} \sum_{j} \frac{\partial f_{\theta}(x)[t]}{\partial A_{k}^{c}(x)[i, j]} αkc?(x)[t]=M1?∑i?∑j??Akc?(x)[i,j]?fθ?(x)[t]?,其中 M M M 是限制重要性圖值范圍的放縮因子, α k c ( x ) [ t ] \alpha_{k}^{c}(x)[t] αkc?(x)[t] 表示第 k k k 層第 c c c 個特征圖對于真實標簽 t t t 的重要性圖。
- 為了對與原始輸入圖像大小相同的對抗擾動進行元素級加權,通過 Ω k t ( x ) = U p s a m p l e ( ∑ c ( A k c ( x ) ? α k c ( x ) [ t ] ) ) \Omega_{k}^{t}(x)=Upsample\left(\sum_{c}\left(A_{k}^{c}(x) \cdot \alpha_{k}^{c}(x)[t]\right)\right) Ωkt?(x)=Upsample(∑c?(Akc?(x)?αkc?(x)[t])) 計算注意力圖。具體操作是先將神經元激活值 A k c ( x ) A_{k}^{c}(x) Akc?(x) 與注意力權重 α k c ( x ) [ t ] \alpha_{k}^{c}(x)[t] αkc?(x)[t] 相乘,再對同一層的所有特征圖進行通道維度的求和,最后通過上采樣操作得到注意力圖。與傳統方法不同,這里去除了 ReLU 函數操作,保留負注意力權重,使生成器能更好地區分圖像中的非關鍵區域,生成更精細的對抗擾動。
- 生成近似注意力圖和加權對抗擾動:使用包含編碼器和兩個解碼器的生成器 G G G。編碼器 ? \epsilon ? 將輸入圖像 x x x 映射為潛在代碼 z = E ( x ) z = E(x) z=E(x), z z z 分別輸入到解碼器 D 1 D_{1} D1? 和 D 2 D_{2} D2?。 D 1 D_{1} D1? 在注意力圖 Ω k t ( x ) \Omega_{k}^{t}(x) Ωkt?(x) 的監督下生成近似注意力圖 Ω ~ k t ( x ) = D 1 ( z ) \tilde{\Omega}_{k}^{t}(x)=D_{1}(z) Ω~kt?(x)=D1?(z), D 2 D_{2} D2? 負責生成原始對抗擾動 δ = D 2 ( z ) \delta = D_{2}(z) δ=D2?(z)。通過公式 δ ′ = δ ? Ω ~ k t ( x ) ? α + δ = δ ( 1 + Ω ~ k t ( x ) ? α ) \delta'=\delta \cdot \tilde{\Omega}_{k}^{t}(x) * \alpha+\delta=\delta\left(1+\tilde{\Omega}_{k}^{t}(x) * \alpha\right) δ′=δ?Ω~kt?(x)?α+δ=δ(1+Ω~kt?(x)?α) 計算注意力加權后的對抗擾動 δ ′ \delta' δ′,其中 α \alpha α 是預定義的超參數,用于控制加權強度。這樣在反向傳播時,關鍵區域中被擾動像素的梯度會乘以較大權重,非關鍵區域的梯度乘以較小權重,使生成器在優化過程中更關注不同模型間共享的關鍵區域,有效破壞圖像中高注意力區域,顯著提升多目標圖像對抗樣本的跨模型遷移性。
區域 ViT 關鍵檢索-Region ViT-Critical Retrieval
這部分主要介紹了區域 ViT 關鍵檢索(RVR)方法,目的是提升對抗樣本在視覺 Transformer(ViTs)上的跨架構遷移性,具體內容如下:
- 方法提出的背景:ViTs 在圖像識別任務中表現出色,但相比傳統卷積神經網絡(CNNs)具有更強的魯棒性。由于兩者結構差異顯著,基于 CNNs 生成的對抗樣本難以成功攻擊 ViTs。對于特征級攻擊而言,貪婪地改變 CNNs 代理模型的注意力會導致對抗樣本在 ViTs 上的跨架構遷移性較差,因為 ViTs 和 CNNs 的關鍵區域并不共享。所以,需要在生成器優化過程中引入 ViTs 的先驗知識來解決這一問題。
- 搜索ViT關鍵區域:定義在 Imagenet1k 上預訓練的 ViT 分類器為函數 F ( x ) F(x) F(x),以 ViT-B/16 為例,它將圖像分割成 196 個 patch 作為輸入,這些 patch 包含圖像的所有信息,但不同 patch 對識別任務的貢獻不同。通過計算 patch 對真實標簽概率的邊際貢獻來衡量其重要性,定義二元掩碼 M M M 并初始化為全1,某 patch 集合 s s s 的邊際貢獻公式為 φ s = F ( x ) [ t ] ? F ( x ⊙ M s ) [ t ] \varphi_{s}=F(x)[t]-F\left(x \odot M_{s}\right)[t] φs?=F(x)[t]?F(x⊙Ms?)[t],其中 M s M_{s} Ms? 是將集合 s s s 中的 patch 全部設為 0 后的二元掩碼。
- 具體檢索過程:從原始輸入圖像 x i n i t x_{init} xinit? 開始,遍歷圖像中的196個 patch,分別計算每個 patch 的邊際貢獻。選擇邊際貢獻最大的 patch,更新掩碼 M M M(將該 patch 所在區域設為0),并用更新后的掩碼與當前圖像 x x x 相乘來更新圖像。若當前圖像 x x x 仍能使 F ( x ) F(x) F(x) 正確分類,則繼續遍歷未被選擇的 patch,重新計算邊際貢獻并更新圖像,直到模型誤分類或所有 patch 都被視為關鍵區域,最終得到二元掩碼 M M M,其中元素值為 0 的區域就是對 ViTs 輸出有顯著影響的關鍵區域。
- 計算最終對抗擾動和樣本:得到關鍵區域后,對對抗擾動進行加權計算。在 PAW 得到的對抗擾動 δ ′ \delta' δ′ 基礎上,通過 δ ′ ′ = δ ′ ⊙ ( 1 ? M ) ? β + δ ′ \delta''=\delta' \odot(1 - M) \cdot \beta+\delta' δ′′=δ′⊙(1?M)?β+δ′ 計算最終的對抗擾動 δ ′ ′ \delta'' δ′′ ,其中 β \beta β 是控制加權強度的放縮因子,可隨生成器訓練過程不斷優化。最后,通過 x a d v = x + ? ? t a n h ( δ ′ ′ ) x^{adv}=x+\epsilon \cdot tanh (\delta^{\prime \prime}) xadv=x+??tanh(δ′′) 得到最終的對抗樣本,其中 ? \epsilon ? 是超參數,與 t a n h ( ? ) tanh (\cdot) tanh(?) 函數一起將對抗擾動限制在 ? ∞ \ell_{\infty} ?∞? 范數約束內。

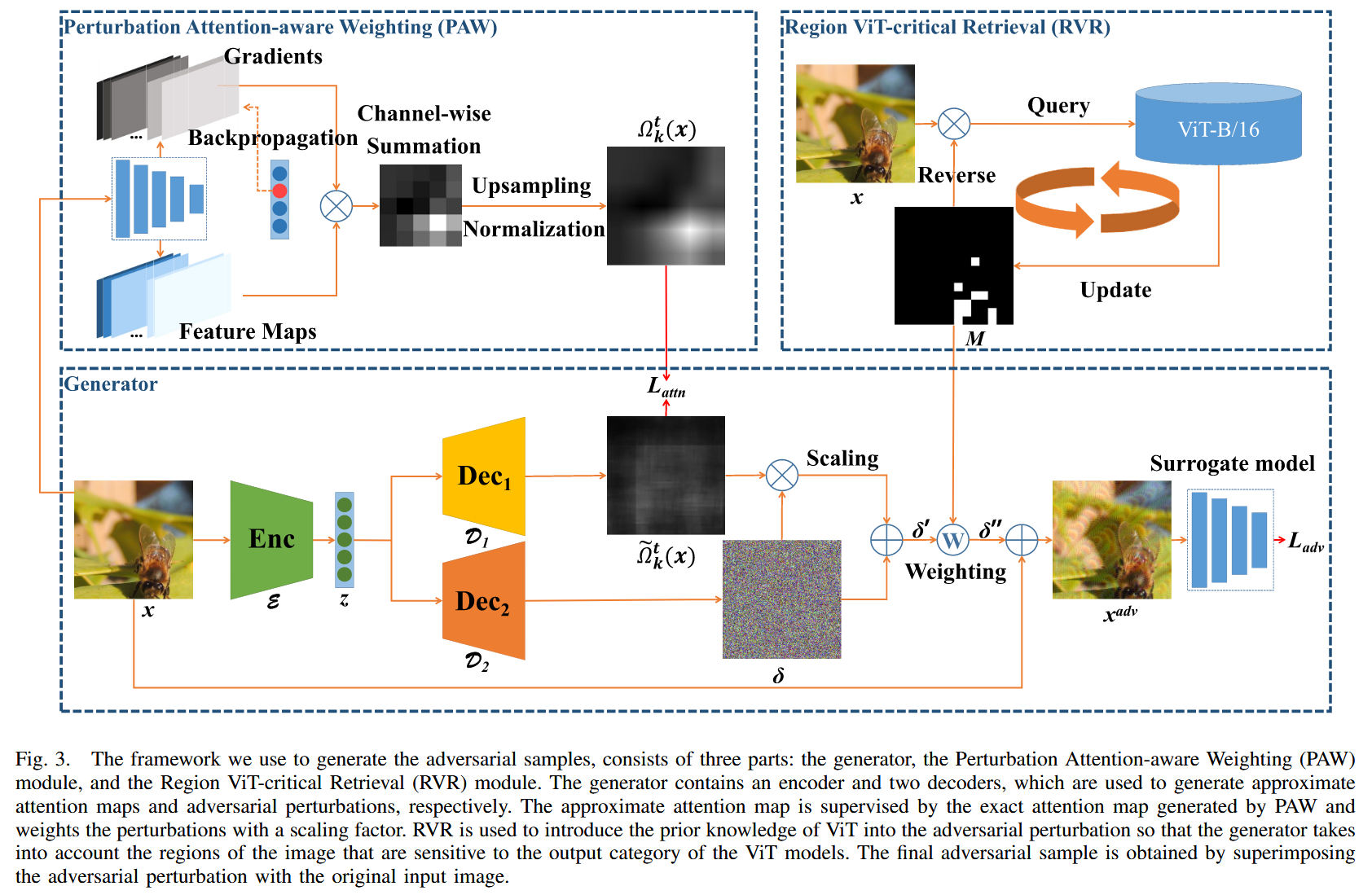
圖3. 我們用于生成對抗樣本的框架由三個部分組成:生成器、擾動注意力感知加權(PAW)模塊和區域 ViT 關鍵檢索(RVR)模塊。生成器包含一個編碼器和兩個解碼器,分別用于生成近似注意力圖和對抗擾動。近似注意力圖由 PAW 生成的精確注意力圖進行監督,并使用縮放因子對擾動進行加權。RVR 用于將 ViT 的先驗知識引入對抗擾動中,以便生成器考慮圖像中對 ViT 模型輸出類別敏感的區域。最終的對抗樣本是通過將對抗擾動與原始輸入圖像疊加得到的。
損失函數-Loss Functions
這部分內容介紹了在生成對抗樣本過程中使用的損失函數,包括對抗損失、注意力損失以及總體損失,具體如下:
- 對抗損失(Adversarial Loss):非目標對抗攻擊旨在生成能被目標模型誤分類的對抗樣本。在基于遷移的黑盒攻擊中,需要一個代理模型 f θ f_{\theta} fθ? 來監督生成器 S S S 的訓練過程。在每次迭代時,生成器嘗試最小化對抗樣本對應真實標簽 t t t 的輸出概率,因此對抗損失函數定義為 L a d v = f θ ( x a d v ) [ t ] \mathcal{L}_{adv}=f_{\theta}\left(x^{adv}\right)[t] Ladv?=fθ?(xadv)[t]. 通過最小化這個損失函數,促使生成器生成的對抗樣本更易被目標模型誤分類,從而實現對抗攻擊的目的。
- 注意力損失(Attention Loss):在提出的 PAW 方法中,使用解碼器 D 2 D_{2} D2? 生成的近似注意力圖來替代從公式計算得到的精確注意力圖 Ω k t ( x ) \Omega_{k}^{t}(x) Ωkt?(x),對對抗擾動進行加權。為了保證近似注意力圖能較好地逼近精確注意力圖,需要用精確注意力圖 Ω ( x ) t \Omega_{(x)}^{t} Ω(x)t? 來監督生成器的訓練過程。因此,注意力損失函數被定義為 L a t t n = ∥ D 1 ( z ) ? Ω k t ( x ) ∥ 2 \mathcal{L}_{attn }=\left\| \mathcal{D}_{1}(z)-\Omega_{k}^{t}(x)\right\| _{2} Lattn?=∥D1?(z)?Ωkt?(x)∥2?,該損失函數衡量了生成器生成的近似注意力圖 D 1 ( z ) \mathcal{D}_{1}(z) D1?(z) 與精確注意力圖 Ω k t ( x ) \Omega_{k}^{t}(x) Ωkt?(x) 之間的差異,通過最小化這個差異,使生成器生成更準確的近似注意力圖,進而提升對抗樣本的質量和遷移性。
- 總體損失(Overall Loss):將對抗損失和注意力損失結合起來,得到總體損失函數 L = L a d v + λ L a t t n \mathcal{L}=\mathcal{L}_{adv}+\lambda \mathcal{L}_{attn } L=Ladv?+λLattn?,其中 λ \lambda λ 是一個超參數,用于控制注意力損失與對抗損失的相對重要程度。在訓練過程中,通過調整 λ \lambda λ 的值,可以平衡對抗損失和注意力損失對生成器訓練的影響,使得生成器在生成對抗樣本時,既能有效地使目標模型誤分類(通過對抗損失),又能保證近似注意力圖的準確性(通過注意力損失),從而提高對抗樣本的性能。在推理階段,訓練好的生成器 G G G 可以將任何輸入圖像映射為相應的對抗樣本,并用于攻擊任何黑盒模型。
實驗-Experiments
這部分主要通過一系列實驗驗證了基于關鍵區域的特征級攻擊(CRFA)方法的有效性,具體內容如下:
-
實驗設置
- 生成器實現:采用包含編碼器和兩個解碼器的殘差網絡架構。編碼器將原始輸入圖像映射為潛在代碼,兩個解碼器分別用于生成顏色初始對抗擾動圖像和灰度近似注意力圖,最終結合二者得到最終對抗擾動。
- 數據集:生成器在 ImageNet 驗證集上訓練,使用 NIPS 2017 對抗競賽數據集進行測試,以保證與之前工作對比的公平性。
- 目標模型:選擇 9 個 CNN 模型、6 個 ViT 模型,還納入了新的卷積模型和自監督學習訓練的 ViT 模型,以及基于多層感知器的 Mixer-B 模型,全面評估方法的性能。
- 基線方法:選取 4 種特征級攻擊方法(FDA、NRDM、FIA、NAA)和 2 種常用方法(MIM、DIM)作為基線,用于對比驗證 CRFA 的有效性。
- 評估指標:使用愚弄率衡量攻擊效果,即被目標模型分類為與原始輸入圖像不同類別的對抗樣本占所有對抗樣本的比例。
- 參數設置:對 PAW 中的放縮因子 α \alpha α、總體損失中的 λ \lambda λ 等參數進行設置,并對基線方法的相關參數也進行設定,確保實驗的一致性和可比性。
-
遷移性比較
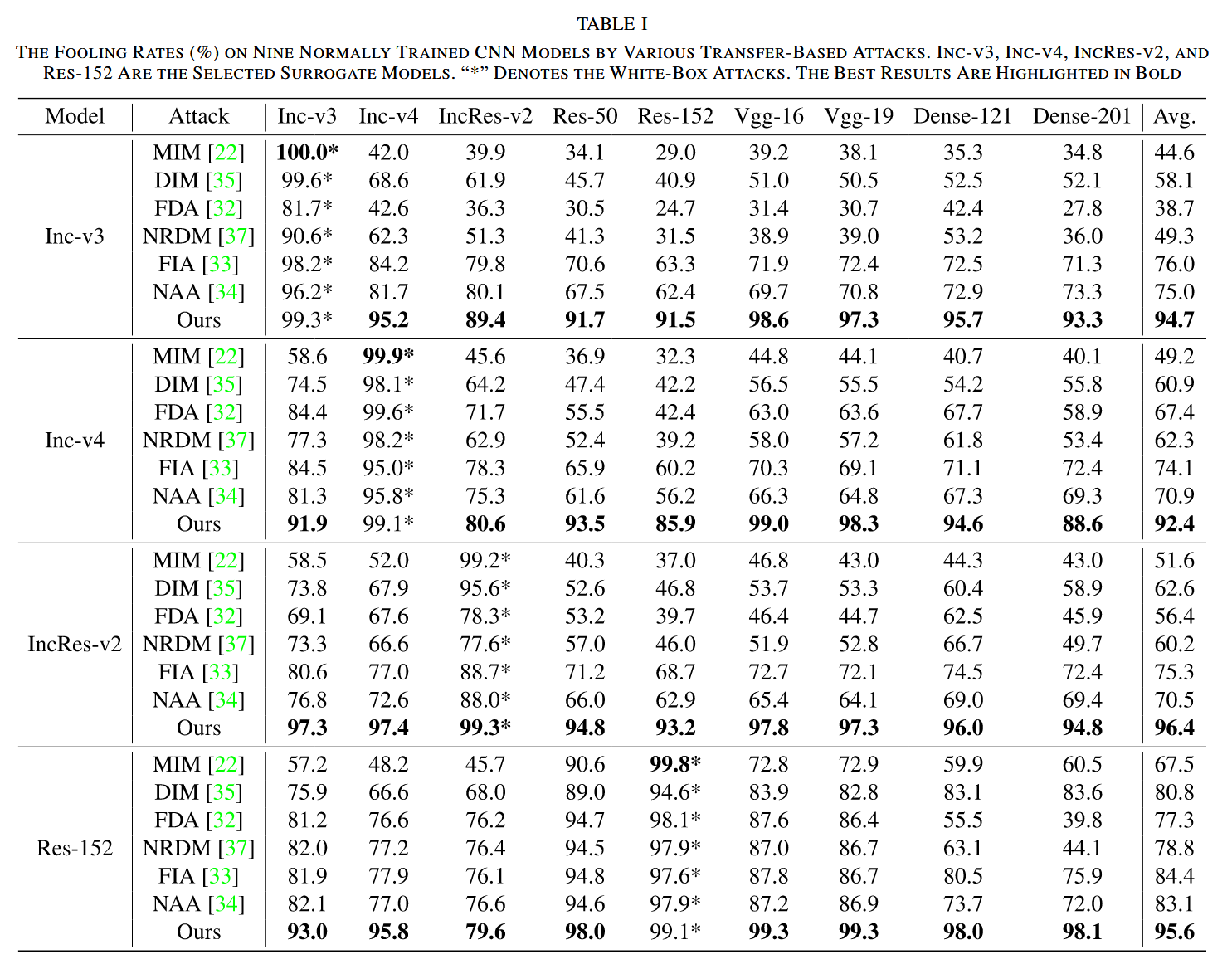
- 跨模型遷移性:以 Inc-v3、Inc-v4、IncRes-v2 和 Res-152 為代理模型攻擊其他 CNN 目標模型。結果顯示,早期的 MIM 在白盒設置下愚弄率高,但在目標模型上攻擊效果衰減嚴重;DIM 通過輸入變換提升了性能,但在簡單結構代理模型上生成的對抗樣本跨模型遷移性仍不佳;FDA 和 NRDM 表現優于 MIM,但未達預期;NAA 和 FIA 有較大改進,但攻擊多目標圖像時效果不佳。相比之下,CRFA 在所有目標模型上表現優異,愚弄率比 NAA 和 FIA 分別提高 19.9% 和 17.3%,且在更復雜代理模型上生成的對抗樣本遷移性更強。
表1. 展示了各種基于遷移的攻擊方法對九個正常訓練的 CNN 模型的愚弄率(%)。Inception-V3(Inc-v3)、Inception-V4(Inc-v4)、Inception-Resnet-V2(IncRes-v2)和ResNet-V1-152(Res-152)被選作代理模型。“*”表示白盒攻擊。最佳結果以粗體突出顯示。
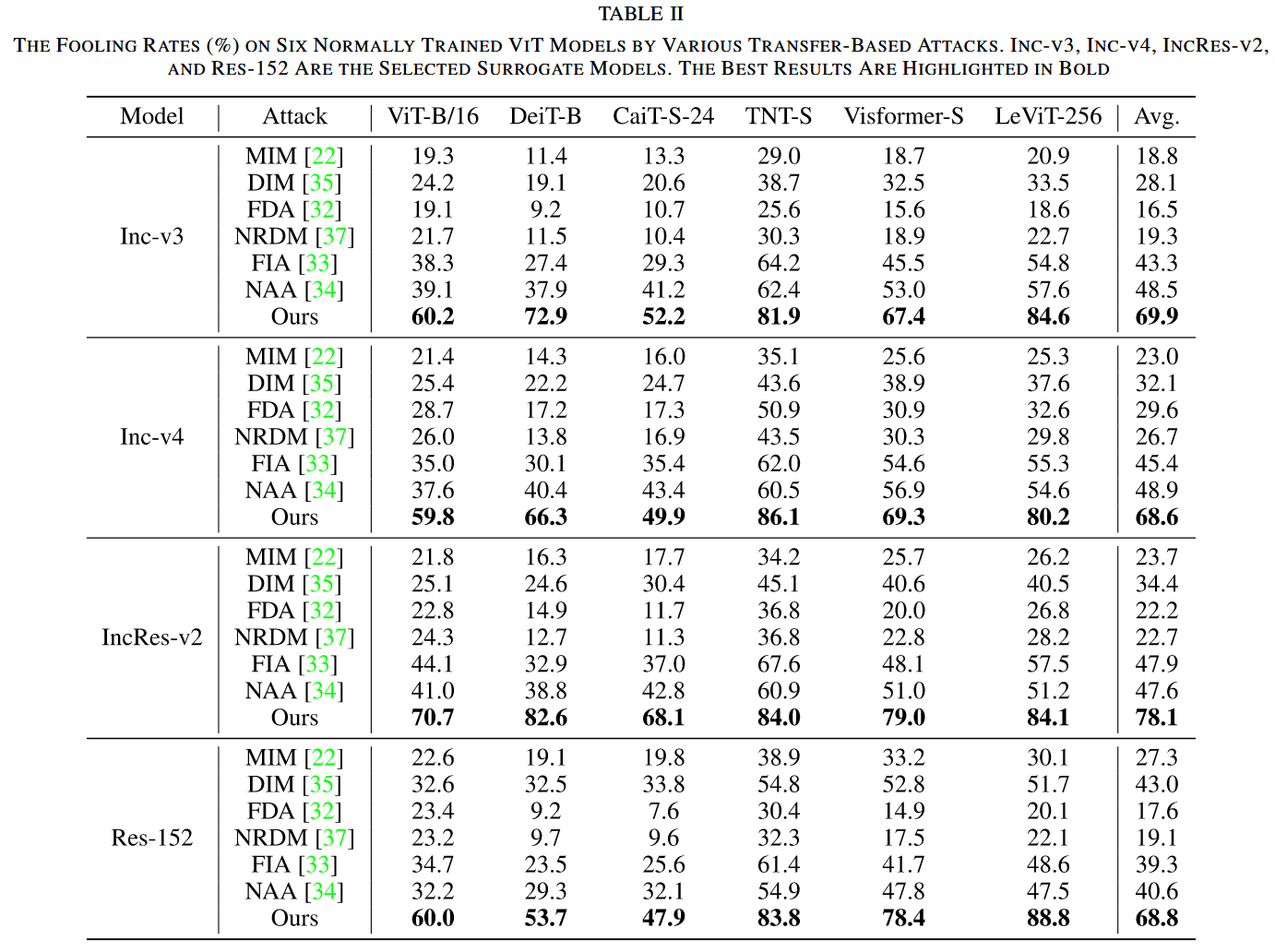
- 跨架構轉遷移性:用在 Inc-v3、Inc-v4、IncRes-v2 和 Res-152 上生成的對抗樣本攻擊 6 種常見 ViT 模型。MIM 對 ViTs 的平均愚弄率低于 30.0%,DIM 表現稍好但仍低于 43.0%,早期特征級攻擊如 FDA 在 ViTs 上遷移性差,NAA 在 ViTs 上的最大平均愚弄率僅 48.9%。而 CRFA 在所有 ViT 目標模型上表現最優,最大平均愚弄率超 78.1%,且對抗樣本跨架構遷移性與代理模型復雜度正相關。
表2. 展示了各種基于遷移的攻擊方法對六個正常訓練的 ViT 模型的愚弄率(%)。Inception-V3(Inc-v3)、Inception-V4(Inc-v4)、Inception-Resnet-V2(IncRes-v2)和ResNet-V1-152(Res-152)被選作代理模型。最佳結果以粗體突出顯示。
- 跨模型遷移性:以 Inc-v3、Inc-v4、IncRes-v2 和 Res-152 為代理模型攻擊其他 CNN 目標模型。結果顯示,早期的 MIM 在白盒設置下愚弄率高,但在目標模型上攻擊效果衰減嚴重;DIM 通過輸入變換提升了性能,但在簡單結構代理模型上生成的對抗樣本跨模型遷移性仍不佳;FDA 和 NRDM 表現優于 MIM,但未達預期;NAA 和 FIA 有較大改進,但攻擊多目標圖像時效果不佳。相比之下,CRFA 在所有目標模型上表現優異,愚弄率比 NAA 和 FIA 分別提高 19.9% 和 17.3%,且在更復雜代理模型上生成的對抗樣本遷移性更強。
-
注意力可視化:通過可視化分析發現,CRFA 能在不顯著改變模型注意力的情況下成功攻擊圖像,有效緩解了特征級攻擊中因代理模型和目標模型注意力差異導致的過擬合問題,使生成器更關注代理模型感興趣的圖像區域,提升對抗樣本跨模型遷移性。
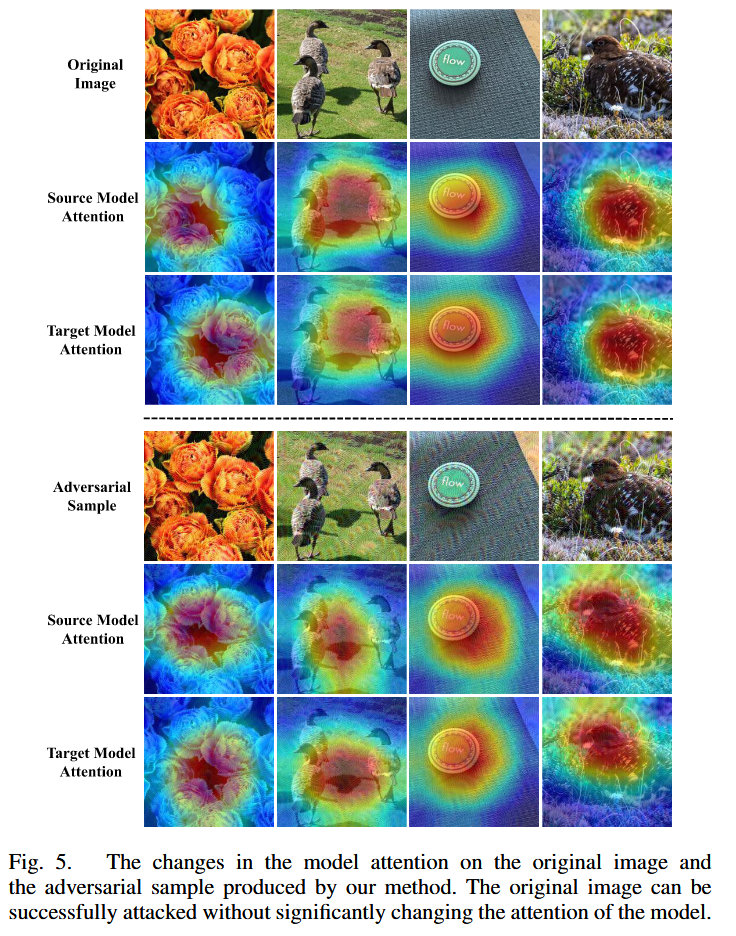
圖5. 模型對原始圖像的注意力以及由我們的方法生成的對抗樣本的注意力的變化情況。原始圖像能夠在不顯著改變模型注意力的情況下被成功攻擊。 -
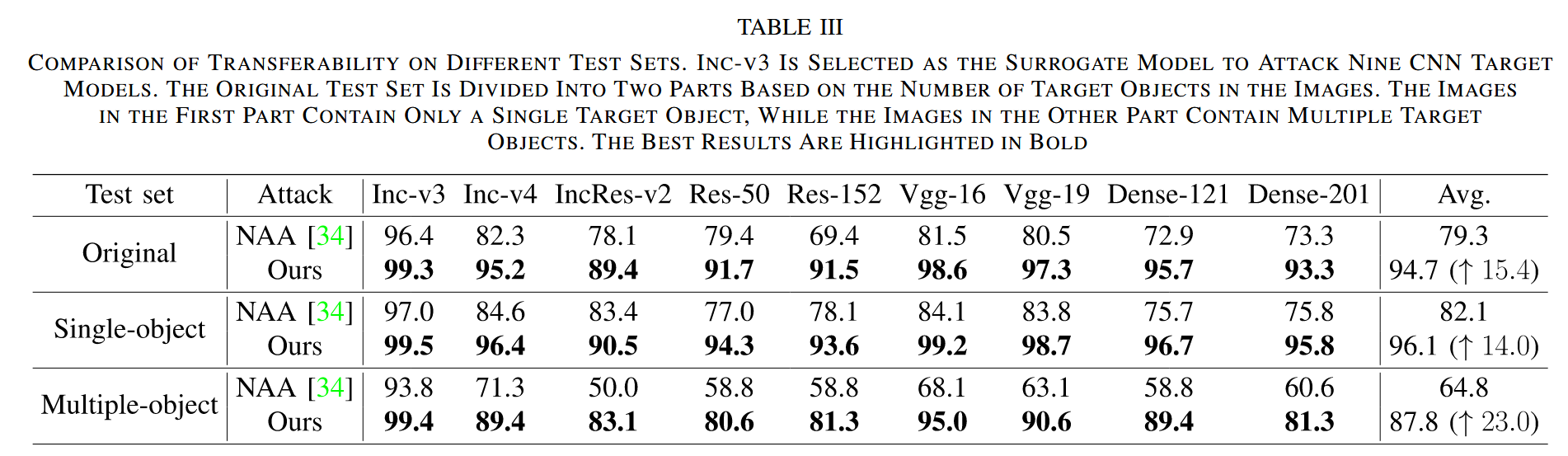
不同測試集遷移性:從原始測試集中選取多目標圖像構成多目標集,其余構成單目標集,以 Inc-v3 為代理模型攻擊 9 個 CNN 目標模型,并與 NAA 對比。結果表明,在單目標集上,兩種方法的愚弄率都有所提高,NAA 提升更明顯;在多目標集上,兩種方法愚弄率均下降,但 NAA 下降顯著,CRFA 在多目標集上的平均愚弄率比 NAA 高 23.0%,在原始測試集上高 15.4%,證明 CRFA 在攻擊多目標圖像時優勢明顯。
表3. 不同測試集上的遷移性比較。選擇 Inception-V3(Inc-v3)作為代理模型,對九個 CNN 目標模型進行攻擊。原始測試集根據圖像中目標對象的數量分為兩部分。第一部分的圖像僅包含一個目標對象,而另一部分的圖像包含多個目標對象。最佳結果以粗體突出顯示。
-
攻擊先進模型:對兩種新卷積模型、四種自監督學習的 ViT 模型和一種多層感知器模型進行攻擊實驗。結果顯示,早期特征級攻擊方法如 FDA 平均愚弄率約 25%,FIA 和 NAA 雖有改進但仍低于 50%,CRFA 在所有選定目標模型上表現更優,對 RepLKNet-B 的愚弄率比 FIA 和 NAA 提高超 25%,表明該方法對先進模型同樣有效。
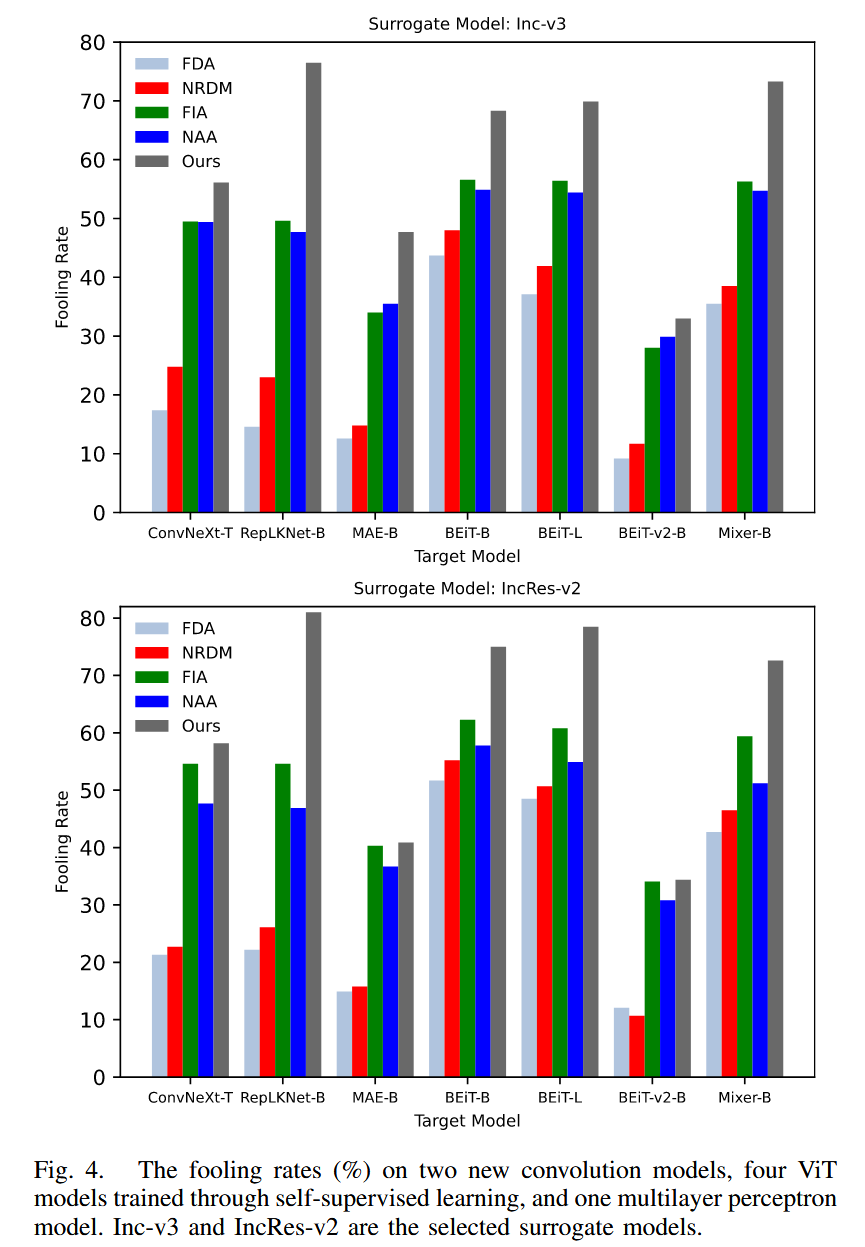
圖4. 針對兩種新型卷積模型、四種通過自監督學習訓練的視覺Transformer(ViT)模型以及一種多層感知器模型的愚弄率(%)。Inception-V3(Inc-v3)和 Inception-Resnet-V2(IncRes-v2)被選為代理模型。 -
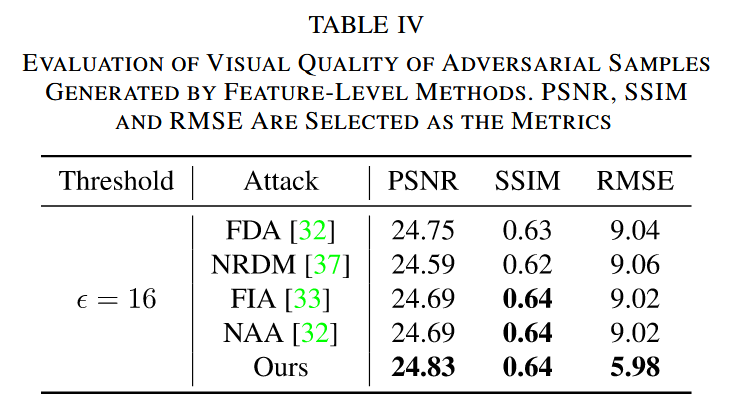
視覺質量評估:使用 PSNR、SSIM 和 RMSE 指標評估對抗樣本視覺質量。在相同 ? ∞ \ell_{\infty} ?∞? 范數約束下,CRFA 生成的對抗樣本在 PSNR 和 SSIM 性能相當的情況下,RMSE 更小,視覺質量更優。
表4. 特征級方法生成的對抗樣本視覺質量評估。選用峰值信噪比(PSNR)、結構相似性指數(SSIM)和均方根誤差(RMSE)作為評估指標。
-
消融研究
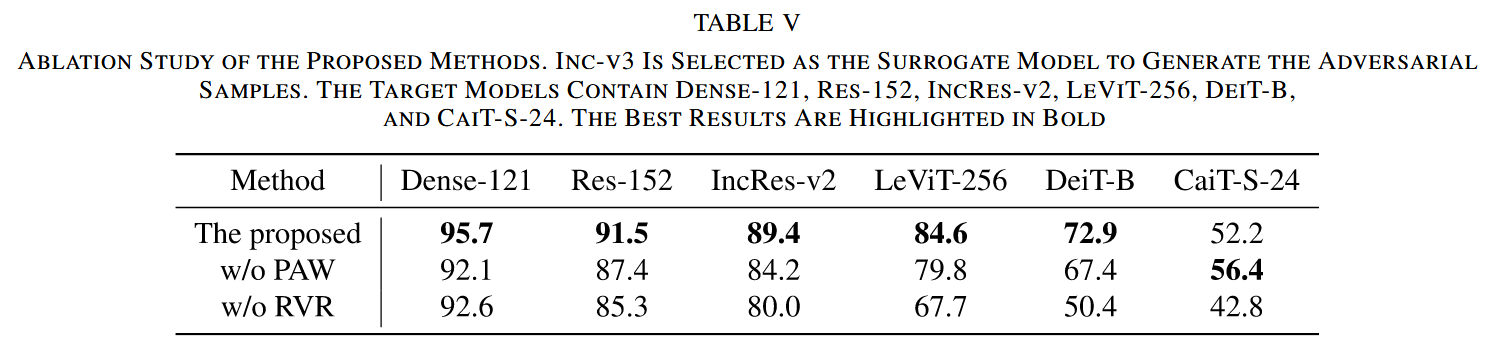
- PAW 的影響:去除 PAW 后,對抗樣本在CNN目標模型上的愚弄率從92.2%降至87.9%,在多數ViT目標模型上愚弄率也下降,表明PAW能有效提升跨模型遷移性,并有助于平衡RVR,減輕對抗樣本在ViTs上的過擬合。
- RVR 的影響:去除 RVR 后,對抗樣本在所有選定目標模型上的愚弄率均下降,在 ViTs 上下降更明顯,表明 RVR 通過添加 ViTs 先驗知識,顯著提升了跨架構遷移性,同時也能緩解對抗樣本在 CNNs 上的過擬合,提升跨模型遷移性。
表5. 所提出方法的消融研究。選擇Inception-V3(Inc-V3)作為代理模型來生成對抗樣本。目標模型包括DenseNet-121(Dense-121)、ResNet-152(Res-152)、Inception-ResNet-V2(IncRes-V2)、LeViT-256(LEVIT-256)、DeiT-B(DEIT-B)和CaiT-S-24(CAIT-S-24)。最佳結果以粗體突出顯示。
-
參數影響:研究 PAW 中 α \alpha α 和總體損失中 λ \lambda λ 對愚弄率的影響。發現 α \alpha α 在1-2.5之間時,對抗樣本愚弄率大致相同, α \alpha α 為 3 時愚弄率下降,因此將 α \alpha α 設為 2; λ \lambda λ 過小時,生成器過度關注基本對抗損失,導致近似注意力圖保真度差,對抗樣本遷移性不佳; λ \lambda λ 過大時,會使對抗樣本在代理模型注意力上過擬合,同樣降低遷移性,所以選擇 λ = 5 \lambda = 5 λ=5 平衡對抗損失和注意力損失。
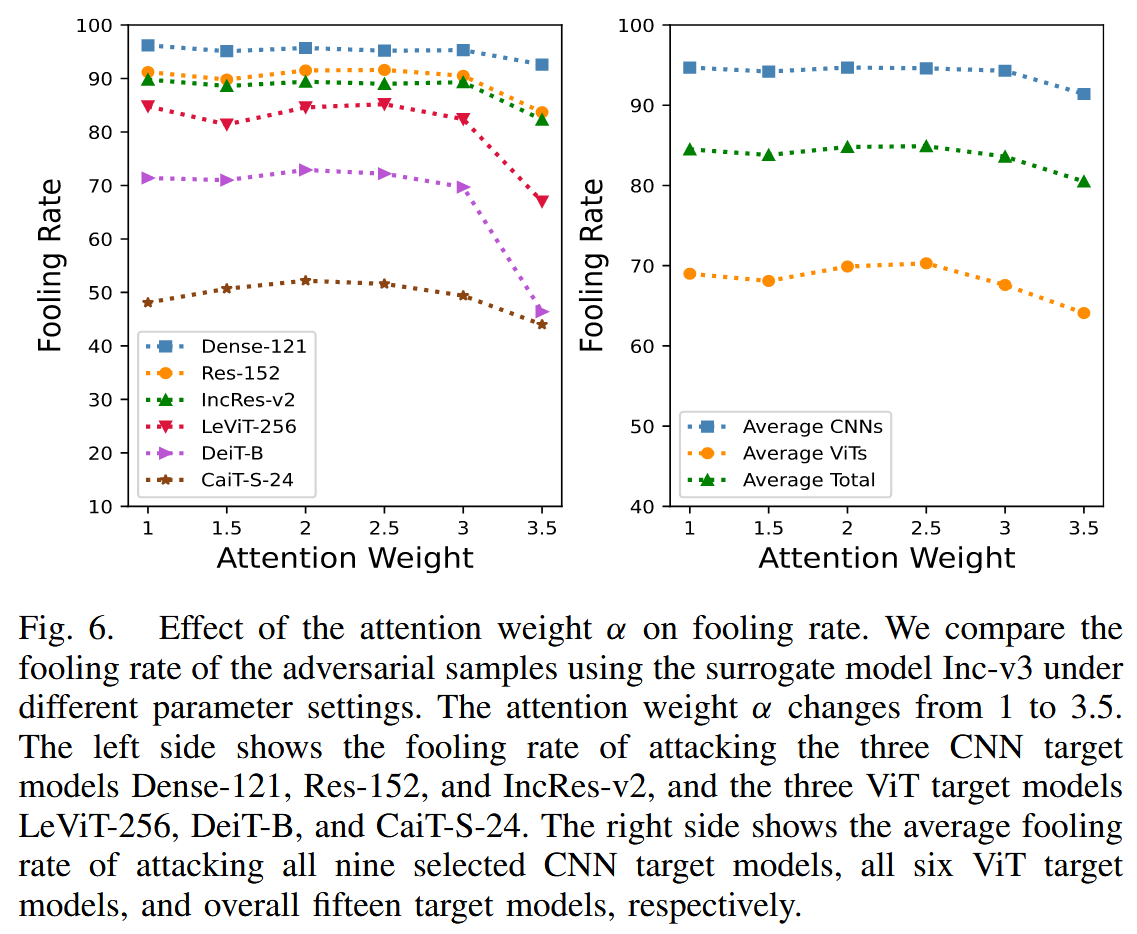
圖6. 注意力權重 α α α 對愚弄率的影響。我們比較了使用代理模型 Inception-v3 在不同參數設置下對抗樣本的愚弄率。注意力權重 α α α 在 1 到 3.5 之間變化。左側展示了攻擊三個卷積神經網絡(CNN)目標模型(Dense-121、Res-152和Inception-ResNet-v2)以及三個視覺Transformer(ViT)目標模型(LeViT-256、DeiT-B和CaiT-S-24)的愚弄率。右側分別展示了攻擊所有九個選定的 CNN 目標模型、所有六個 ViT 目標模型以及總共十五個目標模型的平均愚弄率。
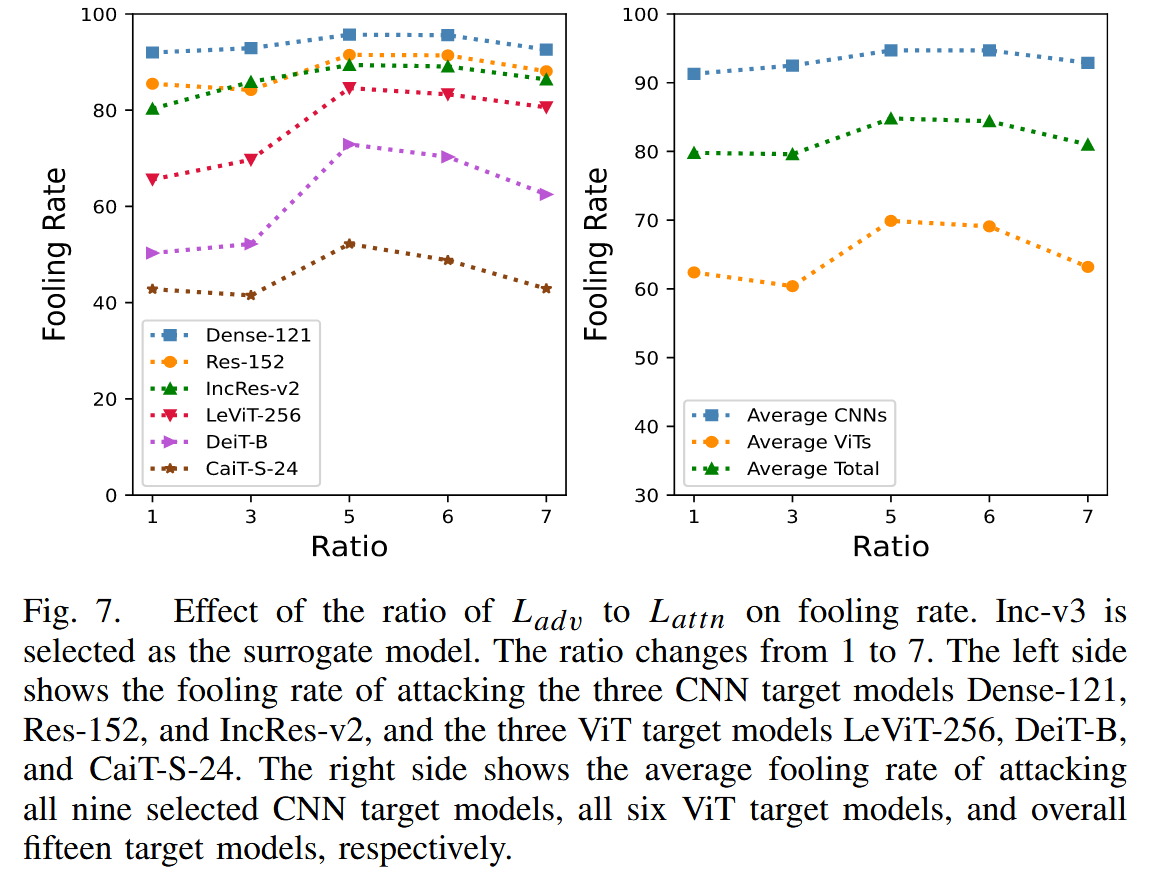
圖7. 對抗損失 L a d v L_{adv} Ladv? 與注意力損失 L a t t n L_{attn} Lattn? 的比率對愚弄率的影響。選取 Inception-v3 作為代理模型。該比率在 1 到 7 之間變化。左側展示了攻擊三個卷積神經網絡(CNN)目標模型(DenseNet-121、ResNet-152 和 Inception-ResNet-v2)以及三個視覺 Transformer(ViT)目標模型(LeViT-256、DeiT-B和CaiT-S-24)的愚弄率。右側分別展示了攻擊所有九個選定的 CNN 目標模型、所有六個 ViT 目標模型以及總共十五個目標模型的平均愚弄率。
討論-Discussion
這部分內容主要圍繞研究過程中發現的問題展開討論,并針對這些問題提出潛在的解決思路,具體內容如下:
- 多目標圖像模型注意力差異及潛在防御機制:研究揭示了不同模型在處理包含多個目標類對象的圖像時,注意力存在顯著差異。這種差異使得以往的特征級攻擊方法性能欠佳,因為改變模型注意力的方式可能導致對抗樣本陷入局部最優。基于此發現,文章提出了一種潛在的對抗防御機制。該機制通過引入額外網絡或進行模型微調,使模型注意力在目標對象間盡可能均勻地分散。這樣做的好處是,既可以維持模型訓練后的分類性能,又能防止對抗樣本使模型注意力偏離目標對象,進而降低模型對攻擊的敏感性,提高防御能力。
- RVR 方法的局限性與改進方向:文中提出的 RVR 方法雖然能有效增強對抗樣本對 ViTs 的遷移性,但存在一定的局限性。RVR 在選擇對 ViTs 輸出有重要影響的 patch 時,沒有對這些 patch 進行區分。這意味著所有被選中的 patch 在指導生成對抗樣本時被同等對待,忽略了不同 patch 可能具有不同重要性的情況。為了進一步提升對抗樣本的遷移性,文章指出需要設計一種更復雜、更精細的檢索算法。這種算法能夠為不同的 patch 分配不同的權重,使生成器可以更好地學習 ViTs 的先驗知識,從而在生成對抗樣本時更有針對性地對關鍵區域進行擾動,達到增強遷移性的目的。
結論-Conclusion
這部分內容總結了本文提出的方法、實驗驗證結果以及研究意義,具體如下:
- 提出的方法:提出了擾動注意力感知加權(PAW)和區域 ViT 關鍵檢索(RVR)兩種方法。PAW 通過使用近似注意力圖對對抗擾動進行加權,有效緩解了以往特征級攻擊在代理模型上的過擬合問題。它讓生成器在不顯著改變模型注意力的情況下,更聚焦于圖像的關鍵區域,進而顯著提升了對抗樣本在卷積神經網絡(CNNs)上的遷移性。RVR 則是通過向解碼器添加視覺Transformer(ViTs)的先驗知識,具體是搜索對 ViTs 輸出有重要影響的關鍵 patch,并將其作為加權項與對抗擾動相乘,使得對抗樣本能夠更好地適應 ViTs,提升了在 ViTs 上的遷移性 。
- 實驗驗證結果:經過大量實驗驗證,基于 PAW 和 RVR 構建的關鍵區域導向的特征級攻擊(CRFA)方法,在性能上優于現有的最先進的特征級攻擊方法。在針對 CNNs 的攻擊實驗中,CRFA 生成的對抗樣本愚弄率相比現有方法提高了19.9%;在針對 ViTs 的攻擊實驗中,愚弄率提高了25.0%。這充分證明了 CRFA 方法在提升對抗樣本遷移性方面的有效性和優越性。
- 研究意義:本文的研究成果對于理解和應對深度神經網絡的對抗攻擊具有重要意義。PAW 和 RVR 為提升對抗樣本在不同類型模型(CNNs 和 ViTs)上的遷移性提供了有效的解決方案,有助于深入研究神經網絡的脆弱性和安全性,也為后續相關研究和應用奠定了基礎。

)




—2D平行束投影公式)




——概述)
-變量)



?)


