一、背景
本文主要記錄一下使用 LDMs?之前,學習 LDMs 的過程。
二、論文解讀
Paper:[2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models?
1.? 總體描述
????????LDMs 將傳統 DMs 在高維圖像像素空間(Pixel Space)上的 diffusion 操作轉移到低維潛空間(Latent Space)進行,大大降低了訓練和推理所需計算資源,生成的圖像細節更豐富,更真實,且能用于生成高分辨率(百萬級像素)圖像;同時引入的條件控制機制 Conditioning Mechanisms 使模型能夠用于多種條件圖像生成任務,如圖像超分、圖像修復、語義合成(文生圖、圖生圖,布局生圖)。
????????后面這幾位作者又提出了檢索增強擴散模型(Retrieval Augmented Diffusion Models, RDMs)并將其用于 LDMs 的文生圖任務中,大概作用就是進一步降低生成圖像所需計算資源,提升生成圖像的質量。
2. LDMs
2.1 主體框架
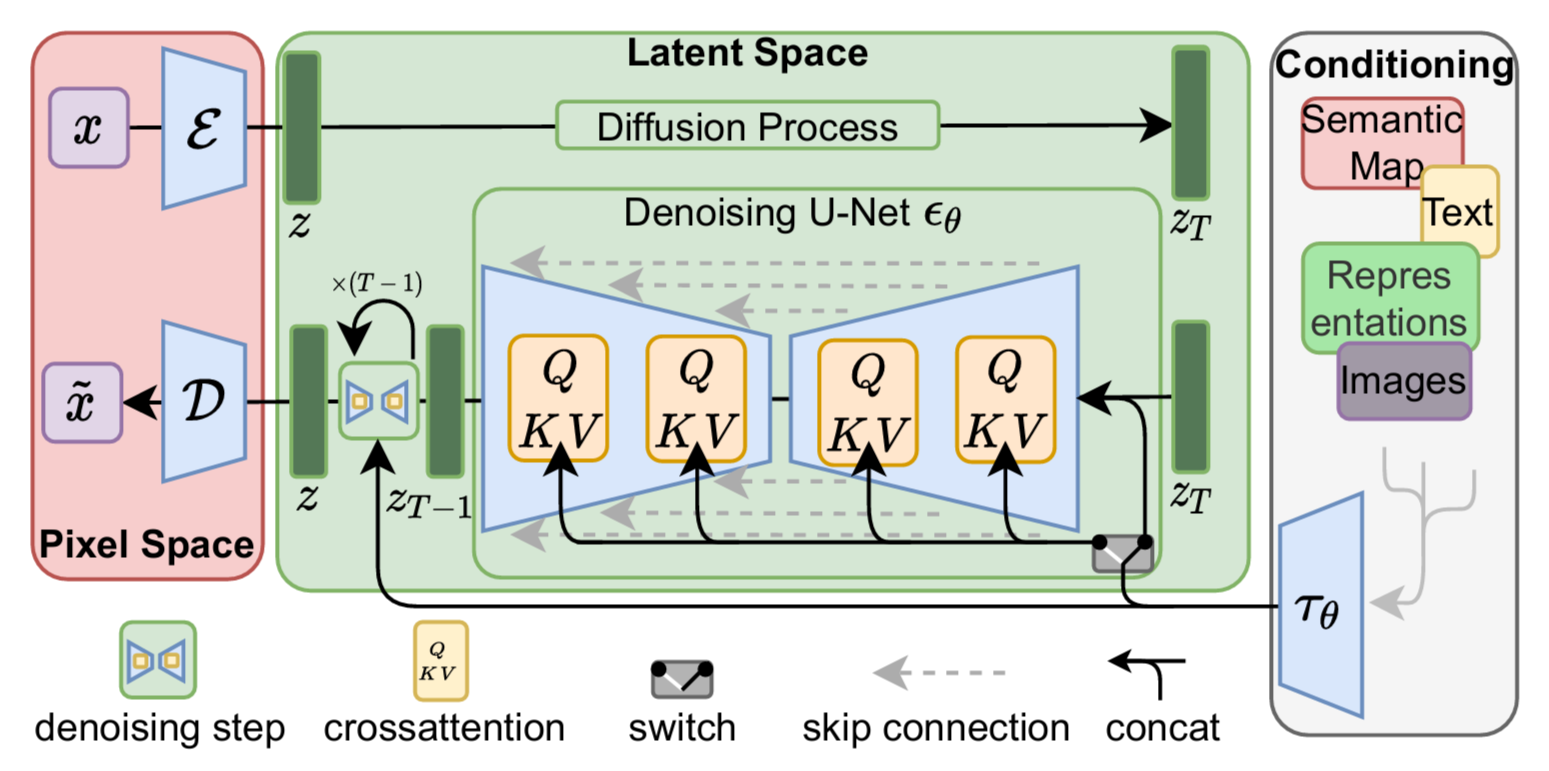
????????通過框架圖可知,在 LDMs 之前需要先訓練一個 Autoencoder,包含一個編碼器??和一個解碼器?
,輸入圖像?
?經過編碼器?
?得到其潛在空間的特征表示?
,解碼器
?再將?
?從潛在空間重構回像素空間得到生成后的?
,上述過程(對應框架圖左部)可表示為:
Encode:
Decode:
其中降采樣因子?,且為 2 的冪次,即?
。
????????正向擴散(加噪)過程和反向去噪(重構)過程均發生在潛在空間,重構過程中通過加入一個條件降噪自編碼器??(UNet?
?cross attention,對應框架圖中部)可以將輸入條件?
?擴展到不同形態(對應框架圖右部),比如文本、語義圖、圖像等,進而可以實現如文生圖、布局生圖、圖生圖等多種生成任務。
2.2 感知圖像壓縮(Perceptual Image Compression)
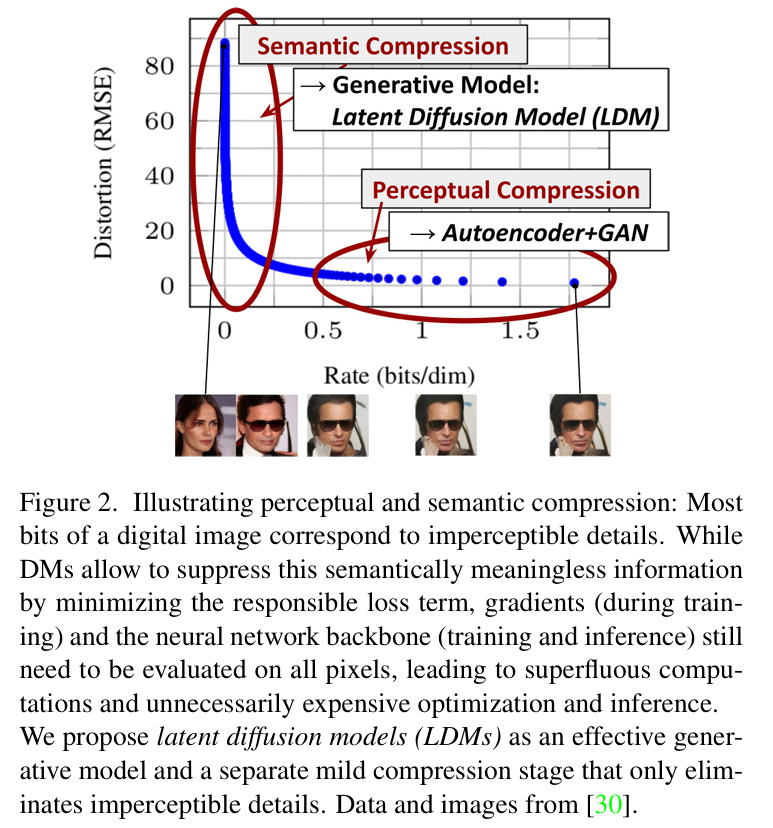
????????現有 DMs 的生成過程可以視為一個壓縮比(感知有效 bit 與圖像維度之比)和失真率的平衡問題(如上圖所示),壓縮比越低(高),說明圖像中感知有效的 bit 越少(多),因而生成的圖像失真程度越大(小)。其學習過程大致可分為兩個階段:感知壓縮階段和語義壓縮階段。在感知壓縮階段,模型會舍棄圖像中的高頻信息而只學習一些語義變化,在語義壓縮階段,生成模型會學習數據的語義和概念信息(高維抽象的信息)。
????????DMs 雖然可以忽略圖像中一些在感知上無關緊要的信息,但模型的計算和優化過程仍然在像素空間中,這就導致如果合成一些高分辨率圖像,空間維度就會非常高,在計算時間和計算資源上的花費會非常昂貴(heavy cost)。?
????????于是作者提出了對圖像的感知壓縮,使用一個 Autoencoder,該 Autoencoder (論文中叫感知壓縮模型)結合了感知損失和基于 patch 的對抗樣本進行訓練。在圖像生成之前會先學習一個與圖像空間感知等效(perceptually equivalent)的低維空間,即潛在空間,在這個空間中進行擴散過程和后續操作,有效降低模型計算復雜性,提高計算效率。
????????為了避免潛在空間的高方差,導致重構圖像與輸入圖像偏離過大,作者使用了兩種正則化方法,KL-reg. 和 VQ-reg.。使用 KL-reg. 的感知壓縮模型相當于一個 VAE,而使用了 VQ-reg. 的感知壓縮模型與一個 VQGAN 的工作過程類似。
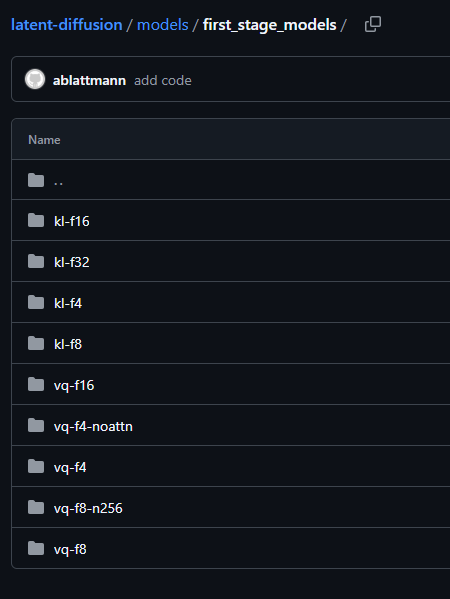
????????代碼中提供了使用 KL(AutoencoderKL 類)和 VQ(VQModel 類)正則配合不同降采樣因子的 AE。
2.3?潛在擴散模型(Latent Diffusion Models)
????????傳統 DMs 在對服從正態分布的變量逐漸去噪的過程中學習其數據分布?,可以看做是基于時序的降噪自編碼器(an equally weighted sequence of denoising autoencoders)?
,其中?
?是輸入樣本?
?的加噪版本,而 DMs 的任務就是學習如何從加噪版樣本?
?中預測去噪版的?
,這個?
?是輸入樣本?
?的變體,二者不完全一樣。對應目標函數可表示如下:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(公式1)
其中??均勻采樣自序列?
?。
????????LDMs 與DMs 相比,其訓練過程在計算高效的低維空間中進行,且模型會聚焦于圖像中的語義信息,丟棄高頻和感知無效的細節。該模型的 backbone 本質上是一個時序條件 UNet(time-conditional UNet),訓練時由編碼器?
?生成潛在空間表示?
,解碼器?
?將采樣自?
?的樣本解碼回圖像空間,得到重建后的?
。目標函數表示如下:
? ? ? ? ? ? ? ? ? ? ? ? ? ? (公式2)
可以看出 LDMs 就是將擴散過程由圖像空間??轉移到潛在空間?
。
2.4?條件機制(Conditioning Mechanisms)?
????????上面主要介紹的是 LDMs 的無條件生成機制,本章節介紹了如何實現 LDMs 的多模態條件生成,如文生圖、圖生圖、圖像轉換(image-to-image translation)等。
????????擴散模型原則上能夠對形如??的條件分布建模,借助一個條件降噪自編碼器(conditional denoising autoencoder)
?可以將生成過程中的控制條件
擴展到多種形式,如文本、語義圖(semantic maps)、圖像等。
????????在圖像生成任務中,如果 DMs 的條件輸入是除了類別標簽(class-label)和模糊版圖像(blurred variants of the input image,指圖像超分)的其它形式,那 DMs 的生成能力還有待探索(隨后本文就進行了探索)。
????????通過在 UNet 中加入交叉注意力機制,使得 DMs 能夠應對多種不同的條件輸入模態(比如prompts)。為了處理條件輸入?,作者引入了一個域專用編碼器(domain specific encoder)
,將?
?映射為一個中間表示(intermediate representation)
,之后通過交叉注意力層將其送入 UNet 的中間層(如框架圖中展示的)。
?
?
其中??是 UNet(執行
后)的一個中間表示,
,
?和?
?為映射矩陣。
????????借助圖像-條件對,條件控制 LDM 的學習可表示如下:
? ? ? ? ? ? ? ? ? ? (公式3)
與公式 2 相比多了一個條件?。?
3. 實驗
????????為了驗證 LDMs 的效果,作者進行了大量實驗,包括對下采樣因子??的調節,無條件圖形生成(基于 CelebA-HQ,FFHQ,LSUN-Churches 和 LSUN-Bedrooms 數據集,生成圖像分辨率為256
256) ,有條件圖像生成(文生圖、語義圖生圖、圖像超分、圖像修復等),基于多種評價指標分析生成圖像的質量和效果。45 頁的論文(加附錄)有 90% 的篇幅屬于實驗分析,可謂相當有說服力了。
????????實驗部分就不做過多記錄了,就簡單整理一下實驗類型和實驗結論。(主要還是能力有限,很多分析看不大懂,只能通過圖示來直觀感受了 - -)
3.1 感知壓縮的權衡(On Perceptual Compression Tradeoffs)
????????作者使用了 6 種下采樣因子()來分析其對圖像生成的影響,當
?時,LDMs 就是 DMs。
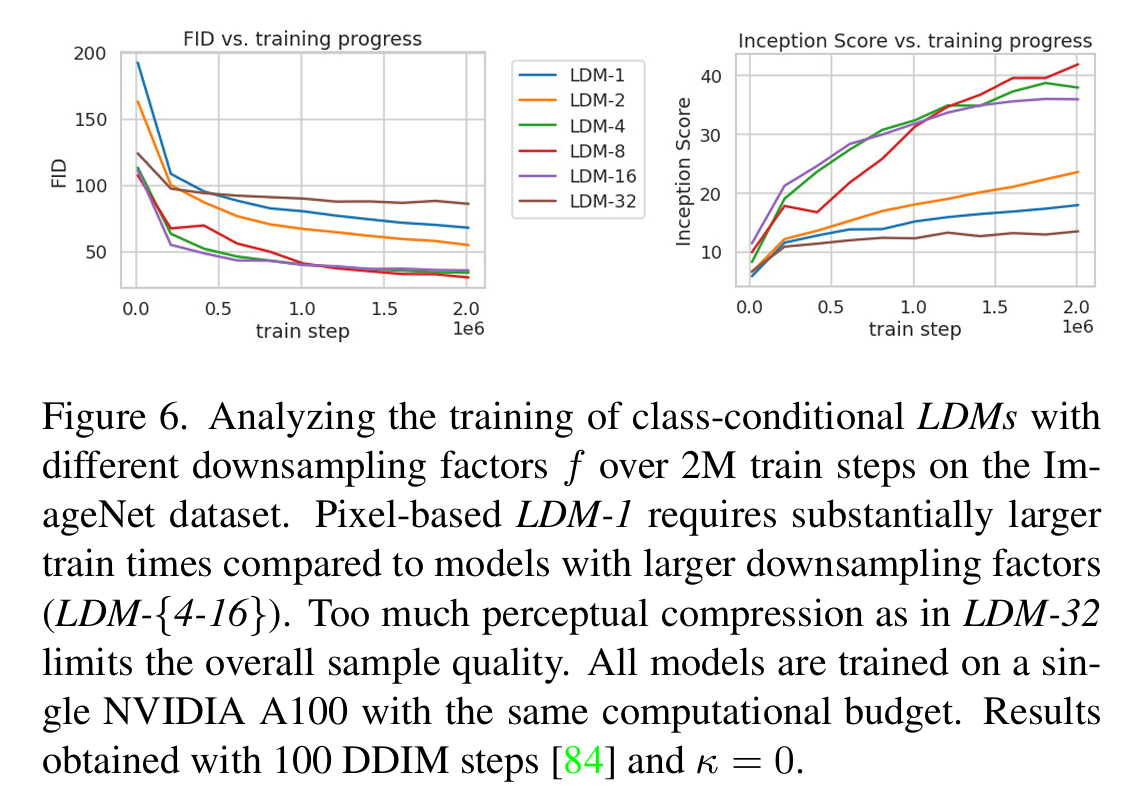
?越小({1-2})訓練時間越長,
?過大({32})?導致信息損失過多,進而導致生成圖像質量差,
?時平衡效果最好。
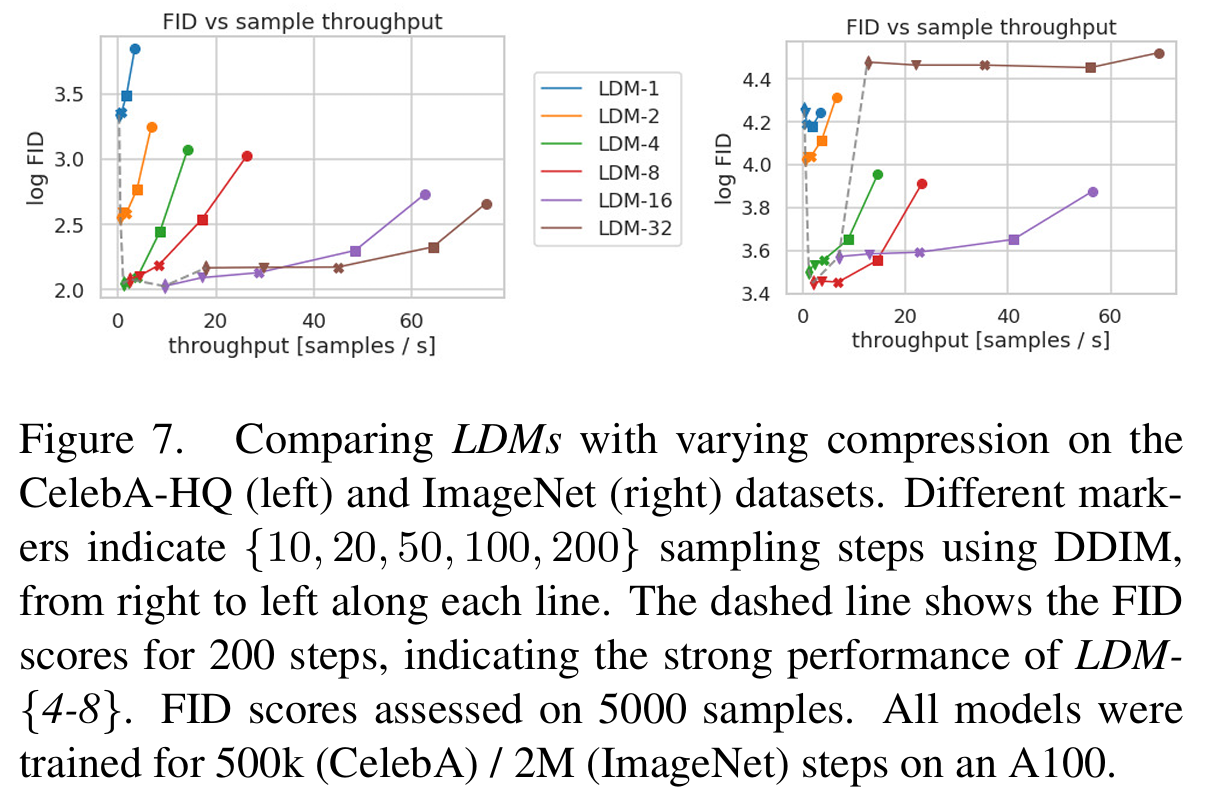
????????在兩個數據集上比較了不同采樣速度對 FID 分數的影響,當??時同樣的采樣速度下 FID 最低。所以綜合分析來看,
?時模型性能最好。
3.2 無條件圖像生成(Image Generation with Latent Diffusion)
????????作者在四個數據集上訓練無條件 LDMs,基于 FID 和 PR 兩個指標評價生成圖像的質量。
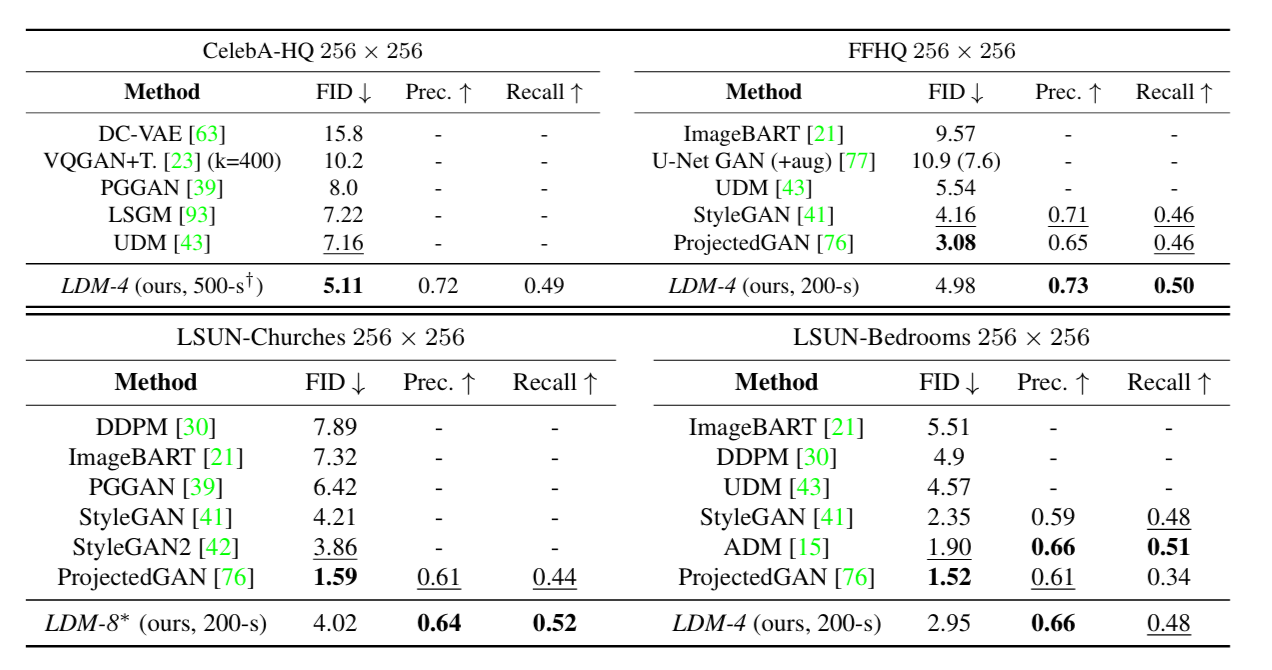
在 CelebA-HQ 數據集上 LDM 的 FID 分數達到最優,在另外幾個數據集上也表現優秀。
在各數據集上生成圖像的效果:

3.3 條件 LDM(Conditional Latent Diffusion)?
3.3.1 引入Transformer 編碼器的LDM
????????作者使用了 BERT-Tokenizer,并將?(前面提到的域專用編碼器)作為一個 transformer 來生成潛在特征,通過多頭交叉注意力將潛在特征映射到 UNet。
(1)文生圖
????????作者在 LAION-400M 數據集上,以 prompts 為條件輸入,訓練了一個條件 LDM(使用 KL 正則優化),并在 MS-COCO 驗證集上進行驗證。
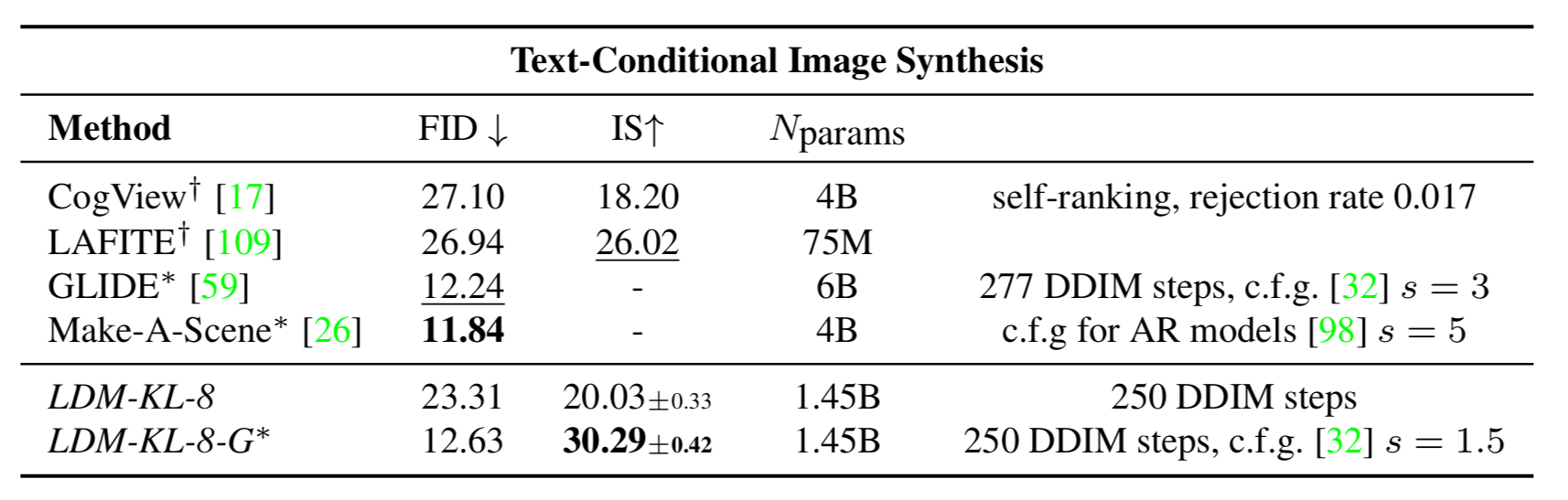
????????LDM-KL-8-G(加入 classifier-free diffusion guidance) 的表現與當時的 SOTA 表現相當,但參數量明顯更少。
生成效果展示

(2) 布局生圖
????????作者在 OpenImages 數據集(語義布局圖,semantic layouts)上訓練,在 COCO 數據集上微調。
生成結果展示:


(3)類別條件圖像生成(ImageNet)?
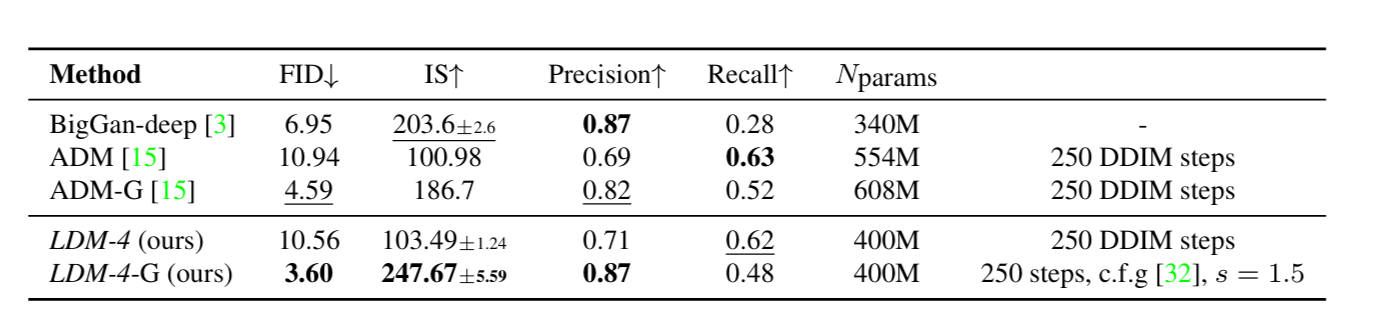
結論也是:指標表現媲美 SOTA,參數量更少。?
3.3.2 卷積采樣(Convolutional Sampling Beyond )?
????????以語義圖(semantic maps)生成為例,作者在分辨率為??的圖像上訓練模型,但模型卻可以生成分辨率更高的圖像。

3.4 圖像超分(Super-Resolution with Latent Diffusion)?
????????作者使用的是在 OpenImages 數據集上預訓練的 Autoencoder(使用 VQ 正則優化,),條件輸入?
?為低分圖像(對原圖做 4 倍下采樣),在 ImageNet 上訓練 LDM。
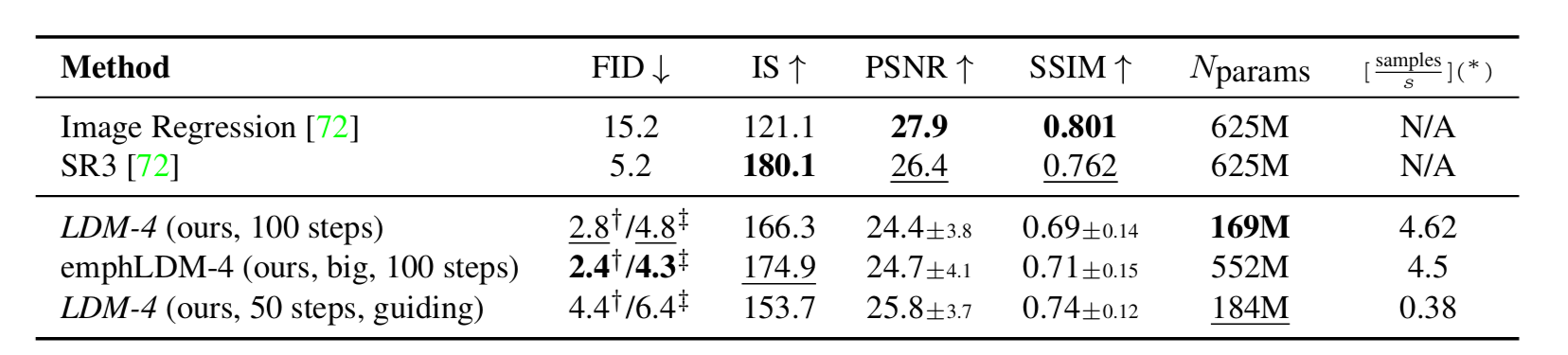
LDM-SR 的 FID 分數超過 SR3,參數量最少。
超分效果展示

????????然后作者又做了一個觀察者實驗,向受試者展示兩張高分辨率圖像(分別由 LDM-SR 和對比模型生成)和二者之間的一張低分圖像,?然后統計受試者對這兩張圖像的評價,結果顯示由 LDM-SR 生成的超分圖像評價更高。

更多效果展示
 ?
?
3.5 圖像修復(Inpainting with Latent Diffusion)
????????作者在 Places 數據集上訓練和驗證模型。首先分析了在第一階段選擇不同可調因子(降采樣因子、正則化項、注意力機制)對生成結果的影響。總體來說,LDM 與普通 DM(?的LDM)相比,速度上至少 2.7倍+,FID 分數高了 1.6倍+。
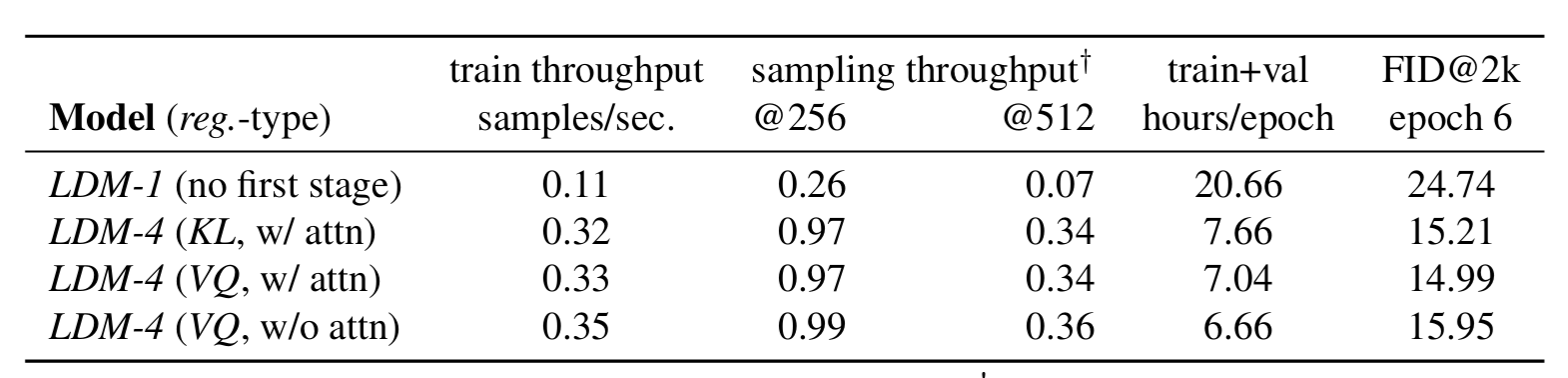
????????加入注意力機制之后提高了生成圖像的質量(從 FID 分數上反應)。從之前的觀察者實驗結果表中也可以反映 LDM 修復的圖像質量更佳。
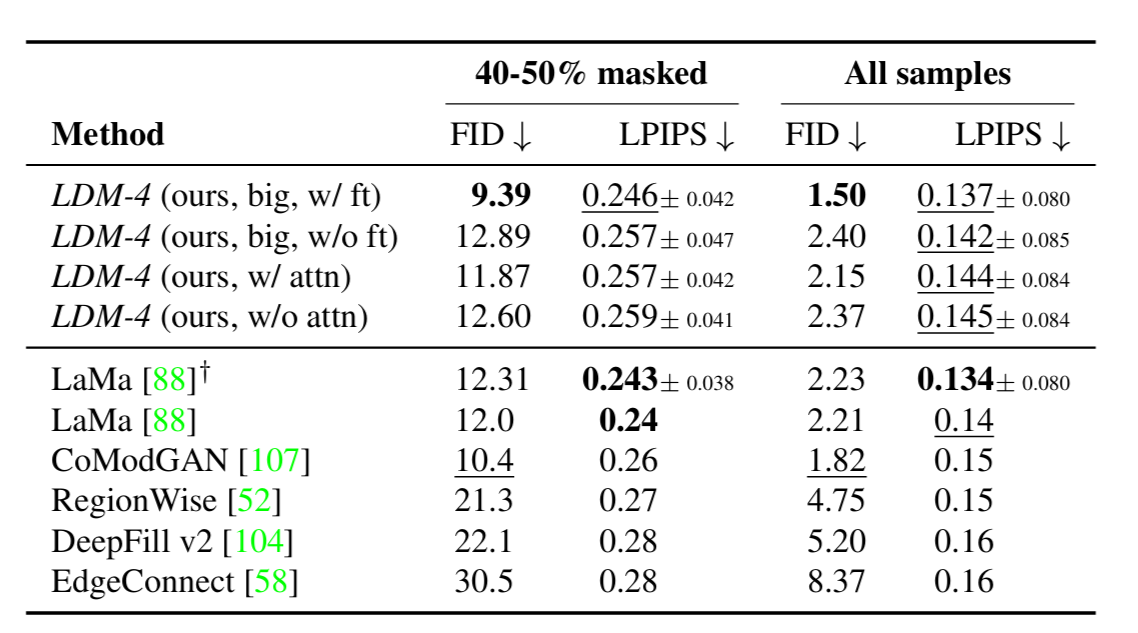
?修復效果展示


????????實驗部分梳理完畢(信息量確實太大了 - -)。后面作者提到了 LDMs 存在的局限性(順序采樣比 GANs 慢,生成高精度圖像的能力等)以及模型可能造成的社會影響(生成假數據等)。
????????以上就是基于本人目前水平對論文所做的解讀,會有很多地方理解不夠準確,建議大家看原文更有助于理解。
三、總結
????????這篇文章屬于無意之舉,畢竟沒有涉獵過圖像生成相關領域,原本只是想記錄一下使用 LDMs 的過程,但在看別人教程還是 github 的過程中有很多概念不太理解,就去搜搜看看,慢慢看得多了就想說要不干脆學習一下論文,原理上多理解一些對于后面模型使用也有好處。
????????這一讀不要緊,越讀不懂的越多,搜的越多,費的時間越多,斷斷續續花了好幾天才算把論文主要內容看完,配上自己粗淺的理解,才算有了這篇文章。說實話自己可能也就理解了一半,還有很多東西看不懂,比如什么是 ddpm,ddim?什么叫卷積采樣?等等,留待以后再慢慢學習吧。
????????Stable Diffusion 大火那會自己也是第一時間上手試玩,當時來說確實很驚艷,但也只是會用,不知道背后竟然是 LDMs,又轉回來了。
參考資料
[1]?[論文筆記] Semi-parametric Image Synthesis -知乎
[2]?Retrieval-Augmented Diffusion Models -知乎
[3]?Latent Diffusion Models論文解讀 -知乎
[4]?stable diffusion原始論文翻譯(LDM latent diffusion model) -知乎



)




—2D平行束投影公式)




——概述)
-變量)



?)
