先說緩存是什么?
緩存主要是解決高并發,大數據場景下,熱點數據快速訪問。緩存的原則首先保證數據的準確和最終數據一致,其次是距離用戶越近越好,同步越及時越好。
再說我們遇到的場景:
接手項目后,發現省市區前端調用,后臺整合了全國數據進行返回。文件超過了1MB。喊著前端同事進行整改,更改成選擇哪個獲取下級的級聯方式,前端的大爺們不配合。哎!催不動啊!你知道不合理但是優化不了。只能在不合理的基礎上進行優化。
指導思想:借鑒nacos的配置中心,通過版本號識別是否產生更改,進行數據同步。
這個方案改動比較小,僅額外增加了一個版本號字段,無特殊邏輯,前端接受了。
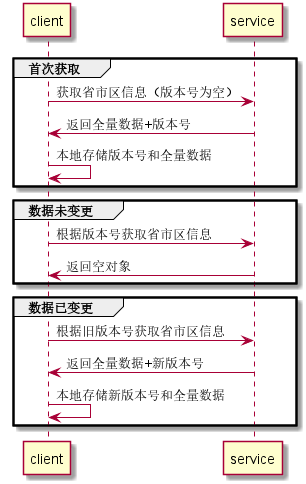
數據都存儲在哪兒了
第1層:客戶端緩存
app緩存了全量的數據。
檢測是否需要更新時,根據版本號查詢后臺數據,響應了具體數據就進行本地數據更新,否則保持原狀。
緩存的構建和更改: 根據版本號調用后臺服務,返回了非空的數據,進行緩存數據的更新。
第2層:nginx緩存
我們通過nginx配置,控制nginx自動緩存了這個版本號對應的數據,有效期是24小時。nginx緩存我們并沒有進行手動清理,因為改動不頻繁,并且能容忍24小時的時間差。真的想要立刻生效,就手動去進行nginx的緩存刪除。
緩存的構建:數據查詢完成,緩存對應的請求網址和響應結果。
緩存內容:
? ? ? ? 初始化后緩存內容:?老版本號/新版本號=空數據,空版本號=全量數據+新版本號
? ? ? ? 數據更改后緩存內容:空版本號/老版本號=全量數據+新版本號,新版本號=空數據。(緩存未清理則有延時)
第3層:本地服務的緩存
本地服務采用Ehcache,未配置失效時間。
緩存內容:最新版本號/最新數據。
查詢操作:比對傳入版本號是否和最新版本號相同,相同則返回空對象,否則返回全量數據
緩存的構建:當前緩存無數據,根據redis查詢的結果,進行本地緩存的重建。
緩存的清理:redis數據構建完畢,通過loadBalance讀取eureka服務名稱對應的所有節點信息,輪詢調用所有服務的數據清理接口。
第4層:分布式緩存redis
本地服務采用redis緩存,未配置失效時間。
緩存內容:最新版本號/最新數據。
業務操作:比對傳入版本號是否和最新版本號相同,相同則返回空對象,否則返回全量數據。
緩存的構建:當查詢redis無數據時,雙重檢查鎖防擊穿,查詢數據庫,進行redis緩存的構建。
緩存的清理:產生數據庫更新操作時,進行redis緩存的清理動作。
第5層:真實的數據庫
更新操作:進行數據庫的數據更新,調用redis的重新構建方法,集群輪詢調用本地緩存清理方法。
查詢操作:查詢數據庫,組裝前端期望的對象。
這樣搭建的效果:
當客戶端進行請求時, 調用nginx, nginx檢測自己的緩存, 根據緩存返回數據。
nginx緩存失效(1天失效一次),服務器本地緩存查詢并返回。
服務器本地緩存失效(服務重啟),通過redis查詢并返回。
redis數據失效(redis被清理),根據數據庫進行緩存的構建,并返回。
數據沒有產生變更,用戶持有的是最新的版本號,大部分場景下返回的都是空對象,減少了海量的io和網絡資源的消耗。
同時這個模型像是一個倒置的漏斗, 無論nginx接受了多少請求,相同的請求地址,一天最多放行了1個,撐住了絕大部分的請求流量,nginx每天放行的一個,也被本地緩存命中,減少了redis的查詢。



——概述)
-變量)



?)



)






