簡介
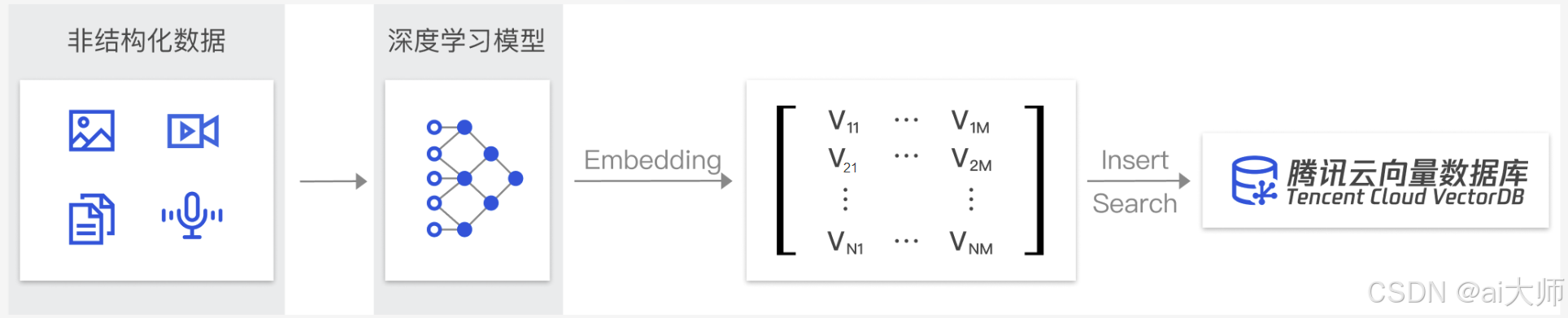
盡管目前大多數開源向量數據庫來自海外,配置簡單且性能優異,但由于網絡原因,如果向量數據庫部署在海外,而產品面向國內市場,網絡延遲將是必須考慮的問題。因此,選擇國內服務提供商的云向量數據庫往往是最佳選擇。
騰訊云向量數據庫(TCVectorDB)是一款全托管的、自研的企業級分布式數據庫服務,專用于存儲、檢索和分析多維向量數據。該數據庫支持多種索引類型和相似度計算方法,能夠處理千億級向量規模,支持百萬級 QPS 及毫秒級查詢延遲。目前,經過認證的騰訊云賬號可以免費使用 TCVectorDB 一個月。
相關文檔
- 💡大模型中轉API推薦
- ?中轉使用教程
- TCVectorDB 產品鏈接
- TCVectorDB 產品文檔
- LangChain TCVectorDB 翻譯文檔
TCVectorDB 的設計理念與 Pinecone 十分接近,其中也包含類似的概念,如數據庫、集合和記錄:
- 數據庫: 包括普通向量數據庫和 AI 數據庫。AI 數據庫無需外部配置文本分割、Embedding、文檔解析等功能,由騰訊云在底層實現。普通向量數據庫需要外部程序處理數據,這種數據庫功能更具可定制化。
- 集合: 集合是數據庫的下一級單位,類似于傳統數據庫中的表。需要在集合中設置集合名稱、分片數、索引等信息。
- 記錄: 集合中的每一條數據就是記錄。
TCVectorDB 默認只能在內網中使用,生產環境中也盡可能不將數據庫暴露到外網。不過在開發中,需要配置并開啟外網訪問功能,并在項目中導入相應的環境變量以使用 API 秘鑰。
TC_VECTOR_DB_URL=xxx
TC_VECTOR_DB_USERNAME=root
TC_VECTOR_DB_KEY=xxx
TC_VECTOR_DB_DATABASE=llmops
TC_VECTOR_DB_TIMEOUT=30
接下來,安裝對應的 Python 包,使用以下命令:
# 示例命令(請根據實際需求調整)
pip install tcvectordb
接下來就可以像 Faiss、Pinecone 一樣正常使用即可,整體功能和 Pinecone 幾乎一模一樣,只是 filter、namespace 等概念的操作有些許差異。
)














原理與實現細節)
)


)