選擇依據
1.業務需求與技術要求
用戶需要根據自己的業務需求來選擇架構,如果業務對于Hadoop、Spark、Strom等關鍵技術有強制性依賴,選擇Lambda架構可能較為合適;如果處理數據偏好于流式計算,又依賴Flink計算引擎,那么選擇Kappa架構可能更為合適。
2.復雜度
如果項目中需要頻繁地對算法模型參數進行修改,Lambda架構需要反復修改兩套代碼,則顯然不如Kappa架構簡單方便。同時,如果算法模型支持同時執行批處理和流式計算,或者希望用一份代碼進行數據處理,那么可以選擇Kappa架構。
在某些復雜的案例中,其實時處理和離線處理的結果不能統一,比如某些機器學習的預測模型,需要先通過離線批處理得到訓練模型,再交由實時流式處理進行驗證測試,那么這種情況下,批處理層和流處理層不能進行合并,因此應該選擇Lambda架構。
3.開發維護成本
Lambda架構需要有一定程度的開發維護成本,包括兩套系統的開發、部署、測試、維護,適合有足夠經濟、技術和人力資源的開發者。而Kappa架構只需要維護一套系統,適合不希望在開發維護上投入過多成本的開發者。
4.歷史數據處理能力
有些情況下,項目會頻繁接觸海量數據集進行分析,比如過往十年內的地區降水數據等,這種數據適合批處理系統進行分析,應該選擇Lambda架構。如果始終使用小規模數據集,流處理系統完全可以使用,則應該選擇Kappa架構。
Kappa架構
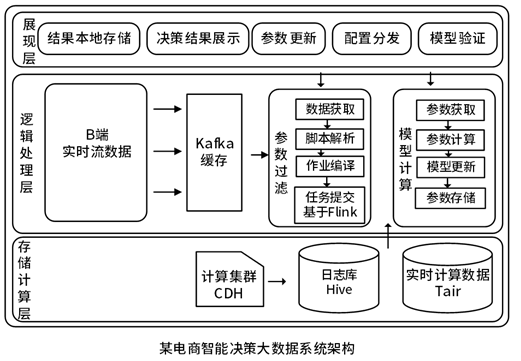
實時智能決策大數據平臺基于Kappa架構,使用統一的數據處理引擎Flink可實時處理流數據,并將其存儲到Hive與Tair中,以供后續決策服務的使用。實時處理的過程如下:
一是數據采集,即B端系統會實時收集用戶的點擊,下單以及廣告的曝光和出價數據并輸出到Kafka緩存。
二是數據的清洗與聚合,即基于大數據計算集群Flink計算框架,實時讀取Kafka中的實時流數據,過濾出需要參與計算的字段,根據業務需求,聚合指定時間段的數據并轉換成指標。
三是數據存儲,即將Flink計算得到數據存儲到Hive日志庫中,需要參與模型計算的字段存儲到Tair分布式緩存中。當需要進行模型計算時,決策服務會從Tair中讀取數據,進行模型的計算,得到新的決策參數和模型。決策服務可以基于微服務架構,客戶端部署在業務方系統中,服務端主要用于計算決策參數和模型,當服務端計算得到新的參數,此時會通過分布式任務協調程序(如Zookeeper)通知部署到業務方系統的客戶端,客戶端此時會拉取新的參數并存儲到本地,并且客戶端提供了獲取參數的接口,業務方可以無感知調用。





基本概念)



 分析)
【vulhub靶場】)





應用開發入門教程)

)
