
- 作者:Fei Lin 1 ^{1} 1, Yonglin Tian 2 ^{2} 2, Tengchao Zhang 1 ^{1} 1, Jun Huang 1 ^{1} 1, Sangtian Guan 1 ^{1} 1, and Fei-Yue Wang 2 , 1 ^{2,1} 2,1
- 單位: 1 ^{1} 1澳門科技大學創新工程學院工程科學系, 2 ^{2} 2中科院自動化研究所復雜系統管理與控制國家重點實驗室
- 論文標題:AirVista-II: An Agentic System for Embodied UAVs Toward Dynamic Scene Semantic Understanding
- 論文鏈接:https://arxiv.org/pdf/2504.09583
主要貢獻
- 提出AirVista-II系統:這是一個端到端的代理系統,用于使無人機(UAV)從被動的數據采集平臺向主動的語義交互范式轉變,實現了無人機在動態場景中的通用語義理解和推理。
- 設計自適應關鍵幀提取策略:針對長視頻場景,提出了一種結合運動感知采樣、聚類分析和模型引導選擇的自適應關鍵幀提取策略。該策略能夠有效地捕捉語義顯著的幀,增強無人機對復雜動態場景的理解能力。
- 在多個公共航拍視頻數據集上驗證:在零樣本(zero-shot)設置下,展示了系統在多樣化無人機動態場景中的高準確性和描述質量,證明了其在實際應用中的潛力。
研究背景
- 無人機在動態環境中的重要性:
- 無人機在物流運輸、災難響應等動態環境中扮演著越來越重要的角色。
- 然而,目前的任務通常依賴于人類操作員監控航拍視頻并做出決策,這種人機協作模式在效率和適應性方面存在顯著限制。
- 語義理解任務的需求:
- 為了實現更高效的自主操作,無人機需要具備語義理解能力,不僅作為數據采集平臺,還要能夠進行環境的語義建模和自然語言交互,從而根據感知信息生成對人類操作指令的高級語義響應。
- 現有方法的局限性:
- 近年來,以大型語言模型(LLM)為代表的基礎模型(FM)在具身智能領域展現了強大的自主性和領域適應性。
- 然而,現有方法通常缺乏顯式的任務規劃機制,導致響應可控性不穩定。此外,由于缺乏外部工具調用能力和協調多模塊框架,在處理結構復雜和開放性任務時泛化能力有限。
研究方法
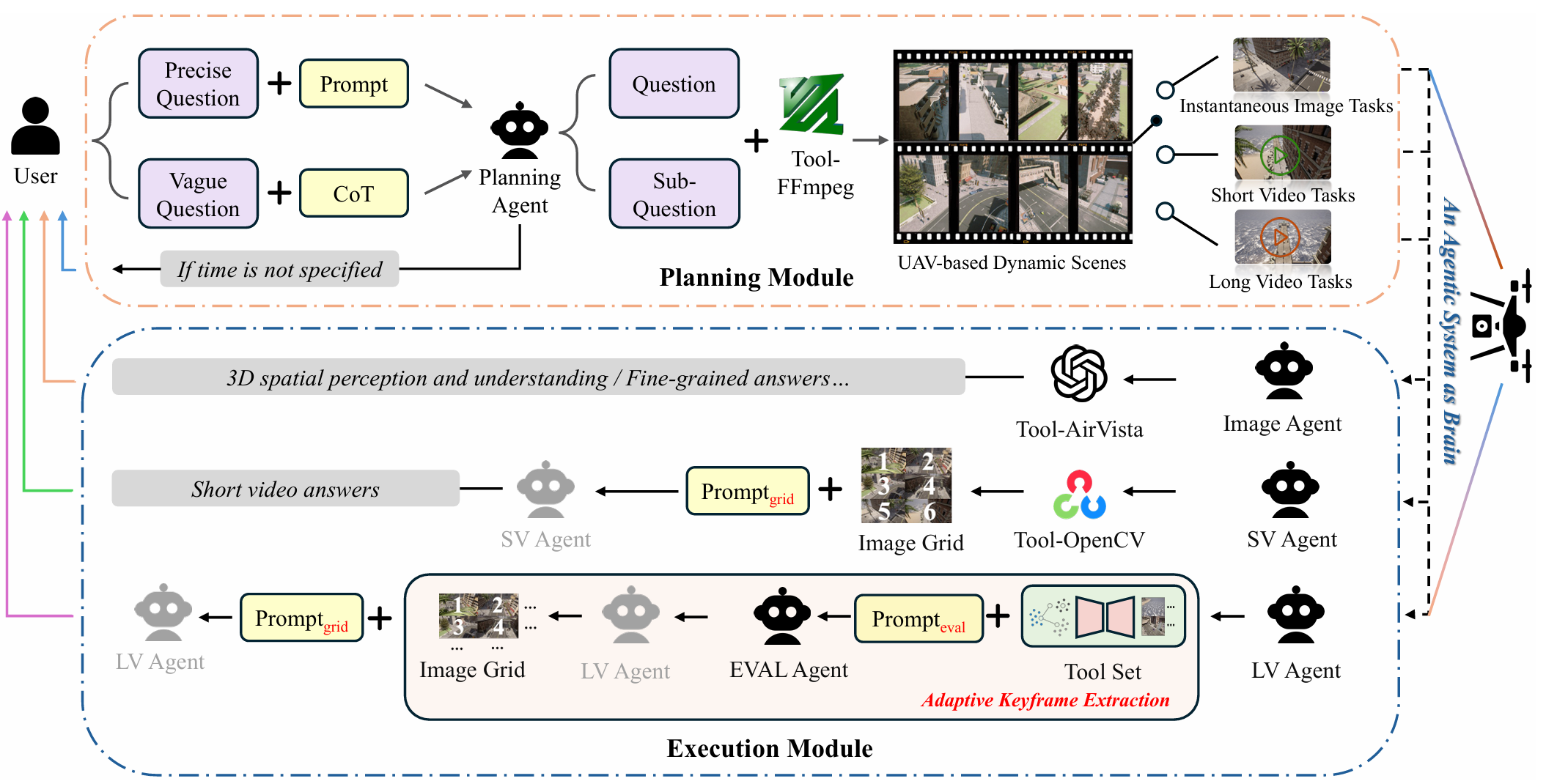
系統架構
AirVista-II系統由規劃模塊和執行模塊組成。根據輸入場景的時間長度,將動態場景分為三種類型:即時場景(單幀圖像)、短視頻(小于60秒)和長視頻(大于等于60秒),分別對應不同的任務形式和執行策略。
規劃模塊
- 核心功能:基于LLaVA或GPT-4o的規劃代理,將自然語言指令轉化為結構化任務,并分派給下游執行代理。
- 處理流程:
- 如果查詢缺乏明確的時間信息,則通過交互式細化模塊更新查詢。
- 對于語義模糊的查詢,應用鏈式思考(CoT)模板將其分解為更具體的子問題。
- 根據提取的時間信息,使用FFmpeg工具從輸入視頻中檢索圖像幀或視頻片段。
- 根據持續時間確定數據的模態標簽(圖像、短視頻或長視頻)。
執行模塊
即時圖像任務
- 處理方式:圖像代理接收圖像和用戶查詢,并調用AirVista工具生成答案。AirVista是一個專門針對無人機的多模態問答模型,能夠進行細粒度的語義理解和3D空間推理。
短視頻任務
- 關鍵幀提取:短視頻代理首先使用OpenCV從短視頻中提取6個均勻間隔的關鍵幀,形成一個3×2的時間網格圖像。
- 推理過程:在網格提示的引導下,代理對網格和查詢進行自我推理以產生答案。這種策略顯著減少了計算開銷,同時保留了時間上下文。
長視頻任務
- 自適應關鍵幀提取策略:
- 運動感知采樣:計算采樣步長 s = ? f ? λ v ? s = \left\lfloor \frac{f \cdot \lambda}{v} \right\rfloor s=?vf?λ??,其中 f f f 是幀率, v v v 是無人機的平均速度, λ \lambda λ 是期望的語義分辨率。這確保了無人機在采樣幀之間至少移動 λ \lambda λ 米,平衡了覆蓋范圍和效率。
- 聚類分析:使用CLIP ViT-B/16提取高維語義嵌入,對不同數量的聚類進行評估,選擇最優聚類數量。
- 模型引導選擇:從每個聚類中選擇最早時間戳的幀形成最終關鍵幀集,構建近方形網格圖像。
- 推理過程:在網格提示的引導下,代理對網格和查詢進行推理以生成答案。
實驗
短視視頻場景實驗
CapERA-QA任務

- 任務描述:基于CapERA數據集構建內容總結問答任務,隨機選擇一個人類標注的字幕作為參考答案,并手動構建相應的問題。
- 評估方法:采用基于GPT的語義評估方法,結果顯示準確率為75.6%,平均得分為3.703。這表明系統能夠準確捕捉大多數航拍視頻中的主要事件和動態語義。
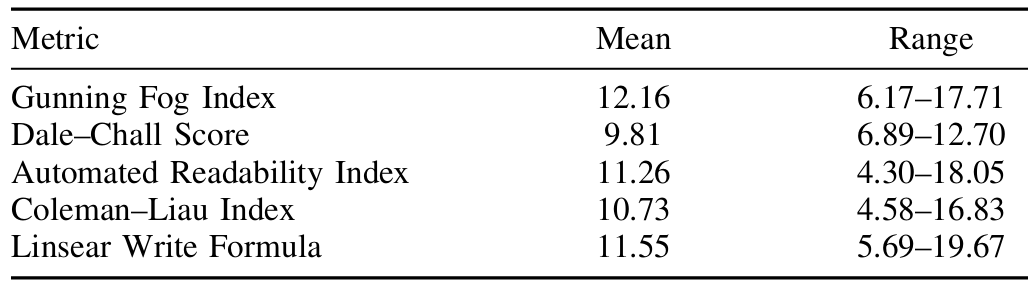
- 可讀性評估:采用多種主流英語可讀性指標(如Gunning Fog Index、Dale–Chall Readability Formula等),統計結果顯示生成答案的可讀性較好。

ERA-QA任務
- 任務描述:基于ERA數據集構建開放性問答任務,包含運動理解、空間關系、時間關系和自由形式問題四種類型。
- 評估方法:比較基于LLaVA-1.6-34B和GPT-4o的短視頻代理的性能,結果顯示LLaVA-1.6-34B的準確率為66.5%,平均得分為3.715;GPT-4o的準確率為53.0%,平均得分為3.140。
長視頻場景實驗
- 任務描述:基于SynDrone數據集構建長視頻問答任務,手動設計開放性問題以評估系統在長時間、多事件動態場景中的綜合問答能力。
- 聚類評估:通過視覺分析聚類評估結果,選擇最優聚類數量。實驗結果表明,自適應關鍵幀提取策略能夠根據場景復雜性動態選擇不同數量的關鍵幀。
- 性能對比:與固定幀采樣策略(如均勻采樣6幀)相比,自適應關鍵幀提取策略更有效地捕捉長視頻的關鍵語義內容,使代理能夠生成完整準確的響應。
結論與未來工作
- 結論:
- AirVista-II系統通過自適應關鍵幀提取方法,有效提高了無人機對復雜動態內容的感知和推理性能,增強了無人機在動態環境中的通用語義理解和推理能力。
- 該系統在多個公共航拍視頻數據集上的實驗結果表明,其在零樣本設置下具有高準確性和描述質量,展示了良好的實際應用潛力。
- 未來工作:
- 優化流程:將專注于優化流程以減少計算開銷,特別是在長視頻處理中,進一步提高系統的實時性和效率。
- 增強魯棒性:通過更多的實驗和測試,增強整個系統在復雜環境下的魯棒性,確保其在實際應用中的穩定性和可靠性。


應用開發入門教程)

)




:曲面上點集距離求解)

)






原因排查)

