Linux中斷是指在Linux操作系統中,當硬件設備或軟件觸發某個事件時,CPU會中斷正在執行的任務,并立即處理這個事件。它是實現實時響應和處理外部事件的重要機制,Linux中斷可以分為兩種類型:硬件中斷和軟件中斷(也稱為異常)。硬件中斷是由外部設備引發的,如磁盤I/O完成、網絡數據包到達等;而軟件中斷是由CPU內部產生的,如除零錯誤、頁面故障等。
當一個中斷被觸發時,CPU會根據預定義好的中斷向量表找到相應的處理程序,并跳轉執行該程序。在Linux內核源碼中,各種硬件設備及其對應的中斷處理程序都有相應的驅動程序進行管理,通過對Linux中斷源碼分析,可以深入了解內核是如何管理和響應不同類型的中斷,在調試和性能優化方面也具有重要作用。同時,掌握 Linux 中斷機制對于編寫高性能、穩定的驅動程序以及理解操作系統內核運行原理非常有幫助。
一、Linux中斷系統概述
在 Linux 系統的龐大體系中,中斷系統猶如其 “神經系統”,占據著核心地位。它是硬件與軟件之間進行高效交互的關鍵橋梁,對系統的響應性以及并發處理能力起著決定性作用。當系統中的硬件設備需要及時處理某些事件時,中斷機制便會迅速發揮作用,促使 CPU 暫停當前正在執行的任務,轉而優先處理這些緊急事務,處理完成后再返回原任務繼續執行。這種機制確保了系統能夠快速響應外部事件,極大地提升了系統的并發處理能力和整體性能。
1.1 中斷基礎概念
中斷,簡單來說,是指計算機在執行程序的過程中,當遇到急需處理的事件時,會暫停當前正在運行的程序,轉去執行相應的服務程序,待處理完畢后再自動返回原程序繼續執行,這一過程就稱為中斷。從硬件層面來看,中斷是由硬件設備產生的電子信號,這些信號通過中斷請求線(IRQ)發送到中斷控制器,再由中斷控制器將其傳遞給 CPU。例如,當鍵盤有按鍵被按下時,鍵盤控制器會立即產生一個中斷信號,通過特定的中斷請求線發送給中斷控制器,進而通知 CPU 有按鍵事件需要處理。
從軟件層面分析,當中斷信號被 CPU 接收后,CPU 會暫停當前執行的指令,保存當前程序的執行狀態(如寄存器的值、程序計數器的值等)到堆棧中,然后跳轉到對應的中斷處理程序(ISR,Interrupt Service Routine)去執行相應的處理操作。中斷處理程序完成任務后,會從堆棧中恢復之前保存的程序執行狀態,使 CPU 繼續執行原來被中斷的程序。在整個系統運行過程中,中斷扮演著至關重要的角色,它使得 CPU 能夠及時響應各種外部設備的請求,實現了硬件與軟件之間的高效協同工作,避免了 CPU 對外部設備狀態的持續輪詢,大大提高了系統的效率和資源利用率。
1.2 Linux 中斷的分類
在 Linux 系統中,中斷主要分為硬件中斷和軟件中斷兩大類,它們各自具有獨特的特點和應用場景。
硬件中斷:硬件中斷是由外部硬件設備(如鍵盤、鼠標、網卡、硬盤等)觸發的中斷。其特點是異步性,即可能在任何時間發生,不受 CPU 控制。硬件中斷具有較高的優先級,一旦發生,會立即打斷 CPU 當前正在執行的任務,使 CPU 迅速響應并處理相應的事件。例如,當網卡接收到網絡數據包時,會立即產生一個硬件中斷,通知 CPU 有新的數據需要處理。硬件中斷在系統中的應用場景非常廣泛,涵蓋了各種外部設備與 CPU 之間的交互。在實時控制系統中,傳感器的數據采集設備通過硬件中斷及時將采集到的數據傳遞給 CPU 進行處理,確保系統能夠對外部環境的變化做出快速響應。
軟件中斷:軟件中斷則是由軟件指令觸發的中斷,它是一種在操作系統內部使用的中斷機制,用于實現系統調用、任務調度、定時器處理等功能。軟件中斷通常是由內核在特定情況下主動觸發的,其優先級相對較低。例如,當用戶程序需要調用系統函數(如文件讀寫、進程創建等)時,會通過軟中斷指令(如 x86 架構中的 int 0x80 或 syscall 指令)將用戶態切換到內核態,內核根據調用號找到對應的系統調用處理函數進行處理,處理完成后再返回用戶態。軟件中斷在操作系統的任務調度方面發揮著重要作用。內核通過軟件中斷來實現進程的上下文切換,當一個進程的時間片用完或者有更高優先級的進程需要運行時,內核會觸發軟件中斷,暫停當前進程的執行,保存其上下文信息,然后調度其他進程運行。
1.3可編程中斷控制器(PIC、APIC)
為了方便說明,這里我們將PIC和APIC統稱為中斷控制器。中斷控制器是作為中斷(IRQ)和CPU核之間的一個橋梁而存在的,每個CPU內部都有一個自己的中斷控制器,中斷線并不是直接與CPU核相連,而是與CPU內部或外部的中斷控制器相連。而為什么叫做可編程中斷控制器,是因為其本身有一定的寄存器,CPU可以通過操作設置中斷控制器屏蔽某個中斷引腳的信號,實現硬件上的中斷屏蔽。中斷控制器也可以級聯提供更多的中斷線,具體如下:
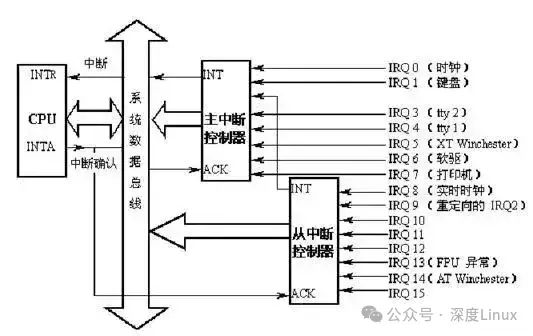
如上圖,CPU的INTR與中斷控制器的INT相連,INTA與ACK相連,當一個外部中斷發生時(比如鍵盤中斷IRQ1),中斷控制器與CPU交互操作如下:
-
IRQ1發生中斷,主中斷控制器接收到中斷信號,檢查中斷屏蔽寄存器IRQ1是否被屏蔽,如果屏蔽則忽略此中斷信號。
-
將中斷控制器中的中斷請求寄存器對應的IRQ1位置位,表示收到IRQ1中斷。
-
中斷控制器拉高INT引腳電平,告知CPU有中斷發生。
-
CPU每執行完一條指令時,都會檢查INTR引腳是否被拉高,這里已被拉高。
-
CPU檢查EFLAGS寄存器的中斷運行標志位IF是否為1,若為1,表明允許中斷,通過INTA向中斷控制器發出應答。
-
中斷控制器接收到應答信號,將IRQ1的中斷向量號發到數據總線上,此時CPU會通過數據總線讀取IRQ1的中斷向量號。
-
最后,如果中斷控制器需要EOI(End of Interrupt)信號,CPU則會發送,否則中斷控制器自動將INT拉低,并清除IRQ1對應的中斷請求寄存器位。
在linux內核中,用struct irq_chip結構體描述一個可編程中斷控制器,它的整個結構和調度器中的調度類類似,里面定義了中斷控制器的一些操作,如下:
struct irq_chip {/* 中斷控制器的名字 */const char ? ?*name;/* 控制器初始化函數 */unsigned int ? ?(*irq_startup)(struct irq_data *data);/* 控制器關閉函數 */void ? ? ? ?(*irq_shutdown)(struct irq_data *data);/* 使能irq操作,通常是直接調用irq_unmask(),通過data參數指明irq */void ? ? ? ?(*irq_enable)(struct irq_data *data);/* 禁止irq操作,通常是直接調用irq_mask,嚴格意義上,他倆其實代表不同的意義,disable表示中斷控制器根本就不響應該irq,而mask時,中斷控制器可能響應該irq,只是不通知CPU */void ? ? ? ?(*irq_disable)(struct irq_data *data);/* 用于CPU對該irq的回應,通常表示cpu希望要清除該irq的pending狀態,準備接受下一個irq請求 */void ? ? ? ?(*irq_ack)(struct irq_data *data);/* 屏蔽irq操作,通過data參數表明指定irq */void ? ? ? ?(*irq_mask)(struct irq_data *data);/* 相當于irq_mask() + irq_ack() */void ? ? ? ?(*irq_mask_ack)(struct irq_data *data);/* 取消屏蔽指定irq操作 */void ? ? ? ?(*irq_unmask)(struct irq_data *data);/* 某些中斷控制器需要在cpu處理完該irq后發出eoi信號 */void ? ? ? ?(*irq_eoi)(struct irq_data *data);/* ?用于設置該irq和cpu之間的親和力,就是通知中斷控制器,該irq發生時,那些cpu有權響應該irq */int ? ? ? ?(*irq_set_affinity)(struct irq_data *data, const struct cpumask *dest, bool force);int ? ? ? ?(*irq_retrigger)(struct irq_data *data);/* 設置irq的電氣觸發條件,例如 IRQ_TYPE_LEVEL_HIGH(電平觸發) 或 IRQ_TYPE_EDGE_RISING(邊緣觸發) */int ? ? ? ?(*irq_set_type)(struct irq_data *data, unsigned int flow_type);/* 通知電源管理子系統,該irq是否可以用作系統的喚醒源 */int ? ? ? ?(*irq_set_wake)(struct irq_data *data, unsigned int on);void ? ? ? ?(*irq_bus_lock)(struct irq_data *data);void ? ? ? ?(*irq_bus_sync_unlock)(struct irq_data *data);void ? ? ? ?(*irq_cpu_online)(struct irq_data *data);void ? ? ? ?(*irq_cpu_offline)(struct irq_data *data);void ? ? ? ?(*irq_suspend)(struct irq_data *data);void ? ? ? ?(*irq_resume)(struct irq_data *data);void ? ? ? ?(*irq_pm_shutdown)(struct irq_data *data);void ? ? ? ?(*irq_calc_mask)(struct irq_data *data);void ? ? ? ?(*irq_print_chip)(struct irq_data *data, struct seq_file *p);int ? ? ? ?(*irq_request_resources)(struct irq_data *data);void ? ? ? ?(*irq_release_resources)(struct irq_data *data);unsigned long ? ?flags;
};二、中斷管理機制剖析
深入探究 Linux 中斷管理機制,如同探索一座精密而復雜的 “機械迷宮”,其底層原理涵蓋多個關鍵方面,包括中斷向量表與中斷描述符的協同工作、中斷請求隊列的高效管理以及中斷上下文與進程上下文的清晰界定。這些要素相互配合,確保 Linux 系統在面對各種中斷請求時,能夠有條不紊地協調系統資源,實現高效穩定的運行。
2.1 中斷向量表與中斷描述符
中斷向量表在 Linux 中斷管理中扮演著 “索引目錄” 的關鍵角色,它是一個由中斷向量組成的數組,每個中斷向量都對應著一個唯一的中斷號,這些中斷號就像是一個個 “頁碼”,指向特定的中斷處理程序。在 x86 架構中,中斷向量表的大小通常為 256 個表項,其中 0 - 31 號向量被系統保留,用于處理 CPU 內部的異常和特殊中斷,如除零錯誤、頁面錯誤等;32 - 255 號向量則用于外部設備的中斷。中斷向量表的主要功能是為中斷處理提供快速的索引,當硬件設備產生中斷信號時,CPU 通過中斷控制器獲取中斷號,然后以這個中斷號作為索引,在中斷向量表中迅速定位到對應的中斷處理程序入口地址,從而實現對中斷的快速響應。
PU把中斷向量表的向量類型分為三種類型:任務門、中斷門、陷阱門。CPU為了防止惡意程序訪問中斷,限制了中斷門的權限,而在某些時候,用戶程序又必須使用中斷,所以Linux把中斷描述符的中斷向量類型改為了5種:中斷門,系統門,系統中斷門,陷阱門,任務門。這個中斷向量表的基地址保存在idtr寄存器中。
-
中斷門:用戶程序不能訪問的CPU中斷門(權限字段為0),所有的中斷處理程序都是這個,被限定在內核態執行。會清除IF標志,屏蔽可屏蔽中斷。
-
系統門:用戶程序可以訪問的CPU陷阱門(權限字段為3)。我們的系統調用就是通過向量128(0x80)系統門進入的。
-
系統中斷門:能夠被用戶進程訪問的CPU陷阱門(權限字段為3),作為一個特別的異常處理所用。
-
陷阱門:用戶進程不能訪問的CPU陷阱門(權限字段為0),大部分異常處理程序入口都為陷阱門。
-
任務門:用戶進程不能訪問的CPU任務門(權限字段為0),''Double fault"異常處理程序入口。
當我們發生異常或中斷時,系統首先會判斷權限字段(安全處理),權限通過則進入指定的處理函數,而所有的中斷門的中斷處理函數都是同一個,它首先是一段匯編代碼,匯編代碼操作如下:
-
執行SAVE_ALL宏,保存中斷向量號和寄存器上下文至當前運行進程的內核棧或者硬中斷請求棧(當內核棧大小為8K時保存在內核棧,若為4K,則保存在硬中斷請求棧)。
-
調用do_IRQ()函數。
-
跳轉到ret_from_intr,這是一段匯編代碼,主要用于判斷是否需要進行調度。
中斷描述符則是連接中斷向量與中斷處理程序的 “橋梁”,它包含了豐富的信息,用于詳細描述中斷的屬性和處理方式。每個中斷向量都有一個與之對應的中斷描述符,這些描述符通常存儲在中斷描述符表(IDT,Interrupt Descriptor Table)中。中斷描述符主要包含以下關鍵信息:段選擇子,用于指定中斷處理程序所在的代碼段;
偏移量,指示中斷處理程序在代碼段中的具體位置;訪問權限和標志位,這些信息用于控制中斷的優先級、特權級以及中斷處理過程中的一些特殊行為,如中斷是否可屏蔽、是否會導致任務切換等。通過這些信息,中斷描述符為 CPU 提供了準確的指令,使其能夠順利地跳轉到正確的中斷處理程序,并在處理中斷時遵循相應的規則和權限。
在處理一個外部設備的中斷時,CPU 首先根據中斷號在中斷向量表中找到對應的中斷描述符,從中獲取段選擇子和偏移量,然后通過這兩個信息計算出中斷處理程序的實際地址,進而跳轉到該地址執行中斷處理程序,完成對設備中斷的響應和處理。
2.2 中斷請求隊列與處理流程
中斷請求隊列是Linux系統為了高效管理中斷請求而采用的一種數據結構,它類似于一個 “任務隊列”,用于存放多個中斷請求。在實際的計算機系統中,由于硬件資源的限制,多個設備可能會共享同一條中斷請求線(IRQ),這就導致多個設備的中斷請求需要通過同一個中斷向量來處理。為了區分這些不同設備的中斷請求,Linux 系統為每個中斷向量設置了一個中斷請求隊列,將共享同一中斷向量的所有設備的中斷請求組織成一個隊列。
中斷請求隊列的數據結構主要由兩部分組成:irq_desc 結構體數組和 irqaction 結構體鏈表。irq_desc 結構體數組是中斷請求隊列的核心,數組中的每個元素都對應著一個中斷向量,它包含了與該中斷向量相關的各種信息,如中斷的狀態(是否被禁用、是否正在處理等)、中斷控制器的信息以及指向 irqaction 結構體鏈表的指針。irqaction 結構體鏈表則用于存儲具體的中斷處理信息,每個鏈表節點代表一個設備的中斷請求,包含了設備的中斷處理函數指針、中斷標志位、設備名稱以及設備 ID 等信息。通過這種數據結構,Linux 系統能夠清晰地管理和調度共享同一中斷向量的多個設備的中斷請求。
每個能夠產生中斷的設備或者模塊都會在內核中注冊一個中斷服務例程(ISR),當產生中斷時,中斷處理程序會被執行,在中斷處理程序中,首先會保存中斷向量號和上下文,之后執行中斷線對應的中斷服務例程。對于CPU來說,中斷線是非常寶貴的資源,而由于計算機的發展,外部設備數量和種類越來越多,導致了中斷線資源不足的情況,linux為了應對這種情況,實現了兩種中斷線分配方式,分別是:共享中斷線,中斷線動態分配。
-
共享中斷線:多個設備共用一條中斷線,當此條中斷線發生中斷時,因為不可能預先知道哪個特定的設備產生了中斷,因此,這條中斷線上的每個中斷服務例程都會被執行,以驗證是哪個設備產生的中斷(一般的,設備產生中斷時,會標記自己的狀態寄存器,中斷服務例程通過檢查每個設備的狀態寄存器來查找產生中斷的設備)。
-
中斷線動態分配:一條中斷線在可能使用的時刻才與一個設備驅動程序關聯起來,這樣一來,即使幾個硬件設備并不共享中斷線,同一個中斷向量也可以由這幾個設備在不同時刻運行。
共享中斷線的分配方式是比較常見的,一次典型的基于共享中斷線的中斷處理流程如下:
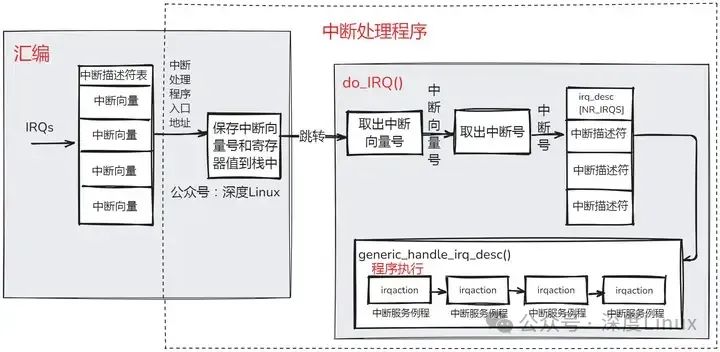
由于中斷處于中斷上下文中,所以在中斷處理過程中,會有以下幾個特性:
-
中斷處理程序正在運行時,CPU會通知中斷控制器屏蔽產生此中斷的中斷線。此中斷線發出的信號被暫時忽略,當中斷處理程序結束時恢復此中斷線。
-
在中斷服務例程的設計中,原則上是立即處理緊急的操作,將非緊急的操作延后處理(交給軟中斷進行處理)。
-
中斷處理程序是運行在中斷上下文,但是其是代表進程運行的,因此它所代表的進行必須處于TASK_RUNNING狀態,否則可能出現僵死情況,因此在中斷處理程序中不能執行任何阻塞過程
當硬件設備產生中斷請求時,Linux 系統的中斷處理流程可以分為以下幾個關鍵步驟:
-
中斷觸發與識別:硬件設備通過中斷請求線向中斷控制器發送中斷信號,中斷控制器接收到信號后,根據信號的來源和配置,生成相應的中斷號,并將其發送給 CPU。
-
中斷響應與上下文切換:CPU 在接收到中斷號后,暫停當前正在執行的任務,保存當前任務的上下文信息(如寄存器的值、程序計數器的值等)到堆棧中,然后根據中斷號在中斷向量表中查找對應的中斷處理程序入口地址,開始進入中斷處理程序執行。
-
中斷請求隊列處理:中斷處理程序首先根據中斷號找到對應的 irq_desc 結構體,從中獲取 irqaction 結構體鏈表的指針,然后遍歷鏈表,依次調用每個設備的中斷處理函數。在調用中斷處理函數之前,中斷處理程序會根據中斷標志位進行一些必要的檢查和準備工作,如判斷中斷是否可屏蔽、是否需要保存和恢復中斷現場等。
-
中斷處理與返回:設備的中斷處理函數執行完成后,返回一個狀態值,指示中斷處理的結果。中斷處理程序根據返回值進行相應的處理,如如果所有設備的中斷處理函數都返回成功,則清除中斷標志,通知中斷控制器中斷處理已完成;如果有設備的中斷處理函數返回失敗,則可能需要進行一些錯誤處理,如重新發送中斷請求或通知用戶程序。最后,中斷處理程序從堆棧中恢復之前保存的任務上下文信息,將 CPU 的控制權交還給被中斷的任務,使其繼續執行。
2.3 中斷上下文與進程上下文
中斷上下文和進程上下文是 Linux 系統中兩個重要的概念,它們分別代表了系統在不同運行狀態下的環境和資源。中斷上下文是指系統在處理中斷時所處的環境,當硬件設備產生中斷請求時,CPU 會暫停當前正在執行的任務,進入中斷處理程序執行,此時系統就處于中斷上下文。在中斷上下文下,系統主要關注的是如何快速響應和處理中斷事件,因此中斷處理程序通常具有較高的優先級,并且不能進行一些可能導致阻塞的操作,如睡眠、訪問文件系統等。
中斷上下文的特點是短暫而高效,它的存在是為了確保系統能夠及時處理硬件設備的請求,保證系統的實時性和穩定性。在處理網絡數據包接收中斷時,中斷處理程序需要迅速讀取網絡設備的緩沖區,將數據包復制到系統內存中,并通知相關的網絡協議棧進行后續處理,這個過程必須在短時間內完成,以避免數據包丟失或網絡延遲增加。
進程上下文則是指系統在執行進程時所處的環境,每個進程都有自己獨立的進程上下文,包括進程的地址空間、寄存器的值、程序計數器的值以及堆棧等。在進程上下文下,系統可以進行各種復雜的操作,如文件讀寫、內存分配、進程調度等,這些操作可以根據進程的需求進行靈活的調度和管理。進程上下文的切換相對較為復雜,需要保存和恢復大量的上下文信息,因此開銷較大。當一個進程需要進行系統調用時,它會通過軟中斷進入內核態,此時系統會將進程上下文切換到內核態的進程上下文,執行系統調用的處理函數,處理完成后再將上下文切換回用戶態的進程上下文。
在中斷處理過程中,中斷上下文和進程上下文會相互切換,這種切換對于系統的性能和穩定性有著重要的影響。當中斷發生時,系統會從當前的進程上下文切換到中斷上下文,執行中斷處理程序;中斷處理完成后,再切換回原來的進程上下文,繼續執行被中斷的任務。
在這個過程中,如果中斷處理程序執行時間過長,可能會導致其他進程的響應時間變長,影響系統的整體性能;如果中斷處理程序在執行過程中進行了一些不恰當的操作,如修改了進程上下文的關鍵數據,可能會導致系統出現錯誤或崩潰。因此,在設計和優化中斷處理程序時,需要充分考慮中斷上下文和進程上下文的特點和限制,合理安排中斷處理的流程和操作,以確保系統的高效穩定運行。
三、中斷實現原理
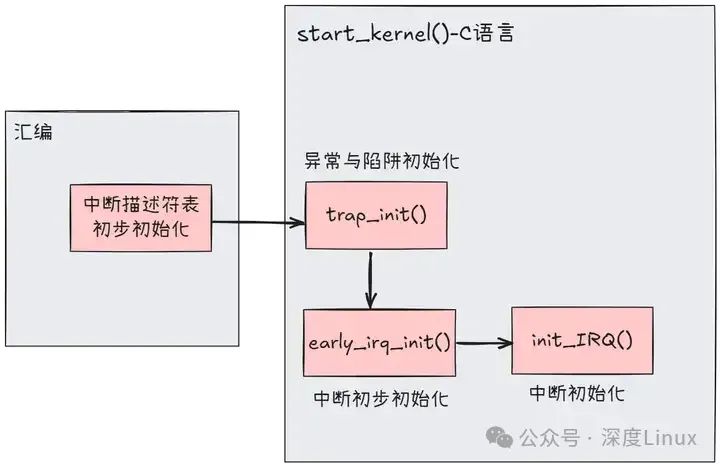
3.1中斷初始化
中斷向量表,中斷描述符表,中斷描述符,中斷控制器描述符,中斷服務例程。可以說這幾個結構組成了整個內核中斷框架主體,所以內核對整個中斷的初始化工作大多集中在了這幾個結構上。
在系統中,當一個中斷產生時,首先CPU會從中斷向量表中獲取相應的中斷向量,并根據中斷向量的權限位判斷是否處于該權限,之后跳轉至中斷處理函數,在中斷處理函數中會根據中斷向量號獲取中斷描述符,并通過中斷描述符獲取此中斷對應的中斷控制器描述符,然后對中斷控制器執行應答操作,最后執行此中斷描述符中的中斷服務例程鏈表,最后執行軟中斷。
而整個初始化的過程與中斷處理過程相應,首先先初始化中斷向量表,再初始化中斷描述符表和中斷描述符。中斷控制器描述符是系統預定編寫好的靜態變量,如i8259A中斷控制器對應的變量就是i8259A_chip。這時一個中斷已經初始化完畢,之后驅動需要使用此中斷時系統會將驅動中的中斷處理加入到該中斷的中斷服務例程鏈表中。
如下圖:

①初始化中斷向量
雖然稱之為中斷向量表,其實對于CPU來說只是一個起始地址,此地址開始每向上8個字節為一個中斷向量。我們的CPU上有一個idtr寄存器,它專門用于保存中斷向量表地址,當產生一個中斷時,CPU會自動從idtr寄存器保存的中斷向量表地址處獲取相應的中斷向量,然后判斷權限并跳轉至中斷處理函數。當計算機剛啟動時,首先會啟動引導程序(BIOS),在BIOS中會把中斷向量表存放在內存開始位置(0x00000000)。
BIOS會有自己的一些默認中斷處理函數,而當BIOS處理完后,會將計算機控制器轉交給linux,而linux會在使用BIOS的中斷向量表的同時重新設置新的中斷向量表(新的地址保存在配置中的CONFIG_VECTORS_BASE),之后會完全使用新的中斷向量表。
一般的,我們也把中斷向量表中的中斷向量稱為門描述符,其大小為64位,其主要保存了段選擇符、權限位和中斷處理程序入口地址。CPU主要將門分為三種:任務門,中斷門,陷阱門。雖然CPU把門描述符分為了三種,但是linux為了處理更多種情況,把門描述符分為了五種,分別為中斷門,系統門,系統中斷門,陷阱門,任務門;但其存儲結構與CPU定義的門不變。結構如下:

在一個門描述符中:
-
P:代表的是段是否處于內存中,因為linux從不把整個段交換的硬盤上,所以P都被置為1。
-
DPL:代表的是權限,用于限制對這個段的存取,當其為0時,只有CPL=0(內核態)才能夠訪問這個段,當其為3時,任何等級的CPL(用戶態及內核態)都可以訪問。
-
段選擇符:除了任務門設置為TSS段,陷阱門和中斷門都設置為__KERNER_CS(內核代碼段)。
-
偏移量:就是中斷處理程序入口地址。
門描述符的初始化主要分為兩部分,我們知道,中斷向量表中保存的是中斷和異常,所以整個中斷描述符的初始化需要分為中斷初始化和異常初始化。而中斷向量表的初始化情況是,第一部分是經過一段匯編代碼對整個中斷向量表進行初始化,第二部分是在系統進入start_kernel()函數后分別對異常和中斷進行初始化。在linux中,中斷向量表用idt_table[NR_VECTORS]數組進行描述,中斷向量(門描述符)在系統中用struct desc_struct結構表示,具體我們可以往下看。
第一部分 - 匯編代碼(arch/x86/kernel/head_32.S):
/** ?setup_once** ?The setup work we only want to run on the BSP.** ?Warning: %esi is live across this function.*/
__INIT
setup_once:movl $idt_table,%edi ? ? ? ? ? ? ? ? ? ? ? ? ? # idt_table就是中斷向量表,地址保存到edi中movl $early_idt_handlers,%eax ? ? ? ? ? ? ? ? ?# early_idt_handlers地址保存到eax中,early_idt_handlers是二維數組,每行9個字符movl $NUM_EXCEPTION_VECTORS,%ecx ? ? ? ? ? ? ? # NUM_EXCEPTION_VECTORS地址保存到ecx中,ecx用于循環,NUM_EXCEPTION_VECTORS為32
1:movl %eax,(%edi) ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? # 將eax的值保存到edi保存的地址中movl %eax,4(%edi) ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?# 將eax的值保存到edi保存的地址+4中/* interrupt gate, dpl=0, present */movl $(0x8E000000 + __KERNEL_CS),2(%edi) ? ? ? # 將(0x8E000000 + __KERNEL_CS)一共4個字節保存到edi保存的地址+2的位置中addl $9,%eax ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? # eax += 9,指向early_idt_handlers數組下一列addl $8,%edi ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? # edi += 8,就是下一個門描述符地址loop 1b ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?# 根據ecx是否為0進行循環# 前32個中斷向量初始化結果:# ?|63 ? ? ? ? ? ? ? ? ? ? ? ? 48|47 ? ? ? ? ? ? ? ? ? 32|31 ? ? ? ? ? ? ? ? ?16|15 ? ? ? ? ? ? ? ? ? ? ? ? ?0|# ?|early_idt_handlers[i](高16位)| ? ? ? ?0x8E00 ? ? ? ? | ? ? __KERNEL_CS ? ? ?|early_idt_handlers[i](低16位)| ? ? ? ? ? ? ? ? ? ? ? ? ??movl $256 - NUM_EXCEPTION_VECTORS,%ecx ? ? ? ? # 256 - 32 保存到ecx,進行新一輪的循環movl $ignore_int,%edx ? ? ? ? ? ? ? ? ? ? ? ? ?# ignore_int保存到edxmovl $(__KERNEL_CS << 16),%eax ? ? ? ? ? ? ? ? # (__KERNEL_CS << 16)保存到eaxmovw %dx,%ax ? ? ??movw $0x8E00,%dx 2:movl %eax,(%edi)movl %edx,4(%edi)addl $8,%edi ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? # edi += 8,就是下一個門描述符地址loop 2b# 其他中斷向量初始化結果:# ?|63 ? ? ? ? ? ? ? ? ? ? ?48|47 ? ? ? ? ? ? ? ? ? 32|31 ? ? ? ? ? ? ? ? ?16|15 ? ? ? ? ? ? ? ? ? ? ? 0|# ?| ? ?ignore_int(高16位) ? ?| ? ? ? ?0x8E00 ? ? ? ? | ? ? __KERNEL_CS ? ? ?| ? ?ignore_int(低16位) ? ?|如果CPU是486,之后會通過 lidt idt_descr 命令將中斷向量表(idt_descr)地址放入idtr寄存器;如果不是,則暫時不會將idt_descr放入idtr寄存器(在trap_init()函數再執行這步操作)。idtr寄存器一共是48位,低16位保存的是中斷向量表長度,高32位保存的是中斷向量表基地址。我們可以看看idt_descr的形式,如下:
idt_descr:.word IDT_ENTRIES*8-1 ? ? ? ?# 這里放入的是表長度, 256 * 8 - 1.long idt_table ? ? ? ? ? ? ? ?# idt_table地址放在這,idt_table定義在/arch/x86/kernel/trap.h中/* 我們再看看 idt_table 是怎么定義的,idt_table代表的就是中斷向量表 */
/* 代碼地址:arch/x86/kernel/Traps.c */
gate_desc idt_table[NR_VECTORS] __page_aligned_bss;/* 繼續,看看 gate_desc ,用于描述一個中斷向量 */
#ifdef CONFIG_X86_64
typedef struct gate_struct64 gate_desc;
#else
typedef struct desc_struct gate_desc;
#endif/* 我們看看32位下的 struct desc_struct,此結構就是一個中斷向量(門描述符) ?*/
struct desc_struct {union {struct {unsigned int a;unsigned int b;};struct {u16 limit0;u16 base0;unsigned base1: 8, type: 4, s: 1, dpl: 2, p: 1;unsigned limit: 4, avl: 1, l: 1, d: 1, g: 1, base2: 8;};};
} __attribute__((packed));可以看出,在匯編代碼初始化部分,所有的門描述符的DPL權限位都設置為0(用戶態不可訪問),段選擇符設置為__KERNEL_CS內核代碼段。而對于中斷處理函數設置則不同,前32個門描述符的中斷處理函數為early_idt_handlers,之后的門描述符的中斷處理函數為ignore_int。而在linux中,0~19的中斷向量是用于異常和陷阱。20~31的中斷向量是intel保留使用的。
②初始化異常向量
異常向量作為在中斷向量表中的前20個向量(0~19),在匯編代碼中已經將其的處理函數設置為early_idt_handlers,而進入start_kernel()函數后,系統會在trap_init()函數中重新設置它們的處理函數,由于異常和陷阱的特殊性,它們并沒有像中斷這樣復雜的數據結構,單純的,每個異常和陷阱有它們自己的中斷處理函數,系統只是簡單地把中斷處理函數放入異常和陷阱的門描述符中。在了解trap_init()函數之前,我們需要先了解如下幾個函數:
/* 設置一個中斷門* n:中斷號?* addr:中斷處理程序入口地址*/
#define set_intr_gate(n, addr) ? ? ? ? ? ? ? ? ? ? ? ?\do { ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?\BUG_ON((unsigned)n > 0xFF); ? ? ? ? ? ? ? ?\_set_gate(n, GATE_INTERRUPT, (void *)addr, 0, 0, ? ?\__KERNEL_CS); ? ? ? ? ? ? ? ? ? ?\_trace_set_gate(n, GATE_INTERRUPT, (void *)trace_##addr,\0, 0, __KERNEL_CS); ? ? ? ? ? ?\} while (0)/* 設置一個系統中斷門 */
static inline void set_system_intr_gate(unsigned int n, void *addr)
{BUG_ON((unsigned)n > 0xFF);_set_gate(n, GATE_INTERRUPT, addr, 0x3, 0, __KERNEL_CS);
}/* 設置一個系統門 */
static inline void set_system_trap_gate(unsigned int n, void *addr)
{BUG_ON((unsigned)n > 0xFF);_set_gate(n, GATE_TRAP, addr, 0x3, 0, __KERNEL_CS);
}/* 設置一個陷阱門 */
static inline void set_trap_gate(unsigned int n, void *addr)
{BUG_ON((unsigned)n > 0xFF);_set_gate(n, GATE_TRAP, addr, 0, 0, __KERNEL_CS);
}/* 設置一個任務門 */
static inline void set_task_gate(unsigned int n, unsigned int gdt_entry)
{BUG_ON((unsigned)n > 0xFF);_set_gate(n, GATE_TASK, (void *)0, 0, 0, (gdt_entry<<3));
}這幾個函數用于設置不同門的API函數,他們的參數n都為中斷號,而他們都會調用_set_gate()函數,只是參數不同,_set_gate()函數如下:
/* 設置一個門描述符,并寫入中斷向量表* gate: 中斷號* type: 門類型* addr: 中斷處理程序入口* dpl: ?權限位* ist: ?64位系統才使用* seg: ?段選擇符*/
static inline void _set_gate(int gate, unsigned type, void *addr,unsigned dpl, unsigned ist, unsigned seg)
{gate_desc s;/* 生成一個門描述符 */pack_gate(&s, type, (unsigned long)addr, dpl, ist, seg);/** does not need to be atomic because it is only done once at* setup time*//* 將新的門描述符寫入中斷向量表中的gate項,使用memcpy進行寫入 */write_idt_entry(idt_table, gate, &s);/* 用于跟蹤? 暫時還不清楚這個 trace_idt_table 的用途 */write_trace_idt_entry(gate, &s);
}
了解了以上的設置門描述符的函數,我們再看看trap_init()函數:
void __init trap_init(void)
{int i;/* 使用了EISA總線 */
#ifdef CONFIG_EISAvoid __iomem *p = early_ioremap(0x0FFFD9, 4);if (readl(p) == 'E' + ('I'<<8) + ('S'<<16) + ('A'<<24))EISA_bus = 1;early_iounmap(p, 4);
#endif/* Interrupts/Exceptions */
//enum {
// ? ?X86_TRAP_DE = 0, ? ?/* ?0, 除0操作 Divide-by-zero */
// ? ?X86_TRAP_DB, ? ? ? ?/* ?1, 調試使用 Debug */
// ? ?X86_TRAP_NMI, ? ? ? ?/* ?2, 非屏蔽中斷 Non-maskable Interrupt */
// ? ?X86_TRAP_BP, ? ? ? ?/* ?3, 斷點 Breakpoint */
// ? ?X86_TRAP_OF, ? ? ? ?/* ?4, 溢出 Overflow */
// ? ?X86_TRAP_BR, ? ? ? ?/* ?5, 越界異常 Bound Range Exceeded */
// ? ?X86_TRAP_UD, ? ? ? ?/* ?6, 無效操作碼 Invalid Opcode */
// ? ?X86_TRAP_NM, ? ? ? ?/* ?7, 無效設備 Device Not Available */
// ? ?X86_TRAP_DF, ? ? ? ?/* ?8, 雙重故障 Double Fault */
// ? ?X86_TRAP_OLD_MF, ? ?/* ?9, 協處理器段超限 Coprocessor Segment Overrun */
// ? ?X86_TRAP_TS, ? ? ? ?/* 10, 無效任務狀態段(TSS) Invalid TSS */
// ? ?X86_TRAP_NP, ? ? ? ?/* 11, 段不存在 Segment Not Present */
// ? ?X86_TRAP_SS, ? ? ? ?/* 12, 棧段錯誤 Stack Segment Fault */
// ? ?X86_TRAP_GP, ? ? ? ?/* 13, 保護錯誤 General Protection Fault */
// ? ?X86_TRAP_PF, ? ? ? ?/* 14, 頁錯誤 Page Fault */
// ? ?X86_TRAP_SPURIOUS, ? ?/* 15, 欺騙性中斷 Spurious Interrupt */
// ? ?X86_TRAP_MF, ? ? ? ?/* 16, X87 浮點數異常 Floating-Point Exception */
// ? ?X86_TRAP_AC, ? ? ? ?/* 17, 對齊檢查 Alignment Check */
// ? ?X86_TRAP_MC, ? ? ? ?/* 18, 設備檢查 Machine Check */
// ? ?X86_TRAP_XF, ? ? ? ?/* 19, SIMD 浮點數異常 Floating-Point Exception */
// ? ?X86_TRAP_IRET = 32, ? ?/* 32, 匯編指令異常 IRET Exception */
//};set_intr_gate(X86_TRAP_DE, divide_error);/* 在32位系統上其效果等同于 set_intr_gate ?*/set_intr_gate_ist(X86_TRAP_NMI, &nmi, NMI_STACK);/* int4 can be called from all */set_system_intr_gate(X86_TRAP_OF, &overflow);set_intr_gate(X86_TRAP_BR, bounds);set_intr_gate(X86_TRAP_UD, invalid_op);set_intr_gate(X86_TRAP_NM, device_not_available);
#ifdef CONFIG_X86_32set_task_gate(X86_TRAP_DF, GDT_ENTRY_DOUBLEFAULT_TSS);
#elseset_intr_gate_ist(X86_TRAP_DF, &double_fault, DOUBLEFAULT_STACK);
#endifset_intr_gate(X86_TRAP_OLD_MF, coprocessor_segment_overrun);set_intr_gate(X86_TRAP_TS, invalid_TSS);set_intr_gate(X86_TRAP_NP, segment_not_present);set_intr_gate(X86_TRAP_SS, stack_segment);set_intr_gate(X86_TRAP_GP, general_protection);set_intr_gate(X86_TRAP_SPURIOUS, spurious_interrupt_bug);set_intr_gate(X86_TRAP_MF, coprocessor_error);set_intr_gate(X86_TRAP_AC, alignment_check);
#ifdef CONFIG_X86_MCEset_intr_gate_ist(X86_TRAP_MC, &machine_check, MCE_STACK);
#endifset_intr_gate(X86_TRAP_XF, simd_coprocessor_error);/* 將前32個中斷號都設置為已使用狀態 */for (i = 0; i < FIRST_EXTERNAL_VECTOR; i++)set_bit(i, used_vectors);#ifdef CONFIG_IA32_EMULATION/* 設置0x80系統調用的系統中斷門 */set_system_intr_gate(IA32_SYSCALL_VECTOR, ia32_syscall);set_bit(IA32_SYSCALL_VECTOR, used_vectors);
#endif#ifdef CONFIG_X86_32/* 設置0x80系統調用的系統門 */set_system_trap_gate(SYSCALL_VECTOR, &system_call);set_bit(SYSCALL_VECTOR, used_vectors);
#endif/** Set the IDT descriptor to a fixed read-only location, so that the* "sidt" instruction will not leak the location of the kernel, and* to defend the IDT against arbitrary memory write vulnerabilities.* It will be reloaded in cpu_init() *//* 將中斷向量表設置在一個固定的只讀的位置,以便“sidt”指令不會泄漏內核的位置,和保護中斷向量表可以處于任意內存寫的漏洞。它將會在 cpu_init() 中被加載到idtr寄存器 */__set_fixmap(FIX_RO_IDT, __pa_symbol(idt_table), PAGE_KERNEL_RO);idt_descr.address = fix_to_virt(FIX_RO_IDT);/* 執行CPU的初始化,對于中斷而言,在 cpu_init() 中主要是將 idt_descr 放入idtr寄存器中 */cpu_init();/* x86_init是一個定義了很多x86體系上的初始化操作,這里執行的另一個trap_init()函數為空函數,什么都不做 */x86_init.irqs.trap_init();#ifdef CONFIG_X86_64/* 64位操作 *//* 將 idt_table 復制到 debug_idt_table 中 */memcpy(&debug_idt_table, &idt_table, IDT_ENTRIES * 16);set_nmi_gate(X86_TRAP_DB, &debug);set_nmi_gate(X86_TRAP_BP, &int3);
#endif
}在代碼中,used_vectors變量是一個bitmap,它用于記錄中斷向量表中哪些中斷已經被系統注冊和使用,哪些未被注冊使用。trap_init()已經完成了異常和陷阱的初始化。對于linux而言,中斷號0~19是專門用于陷阱和故障使用的,以上代碼也表明了這一點,而20~31一般是intel用于保留的。而我們的外部IRQ線使用的中斷為32~255(代碼中32號中斷被用作匯編指令異常中斷)。
所以,在trap_init()代碼中,專門對0~19號中斷的門描述符進行了初始化,最后將新的中斷向量表起始地址放入idtr寄存器中。在trap_init()中我們看到每個異常和陷阱都有他們自己的處理函數,不過它們的處理函數的處理方式都大同小異,如下:
#代碼地址:arch/x86/kernel/entry_32.S# 11號異常處理函數入口
ENTRY(segment_not_present)RING0_EC_FRAMEASM_CLACpushl_cfi $do_segment_not_presentjmp error_codeCFI_ENDPROC
END(segment_not_present)# 12號異常處理函數入口
ENTRY(stack_segment)RING0_EC_FRAMEASM_CLACpushl_cfi $do_stack_segmentjmp error_codeCFI_ENDPROC
END(stack_segment)# 17號異常處理函數入口
ENTRY(alignment_check)RING0_EC_FRAMEASM_CLACpushl_cfi $do_alignment_checkjmp error_codeCFI_ENDPROC
END(alignment_check)# 0號異常處理函數入口
ENTRY(divide_error)RING0_INT_FRAMEASM_CLACpushl_cfi $0 ? ? ? ? ? ?# no error codepushl_cfi $do_divide_errorjmp error_codeCFI_ENDPROC
END(divide_error)在trap_init()函數中調用了cpu_init()函數,在此函數中會將新的中斷向量表地址放入idtr寄存器中,而具體內核是如何實現的呢,之前已經說明,idtr寄存器的低16位保存的是中斷向量表長度,高32位保存的是中斷向量表基地址,相對于的,內核定義了一個struct desc_ptr結構專門用于保存idtr寄存器內容,其如下:
/* 代碼地址:arch/x86/include/asm/Desc_defs.h */
struct desc_ptr {unsigned short size;unsigned long address;
} __attribute__((packed)) ;/* 代碼地址:arch/x86/kernel/cpu/Common.c */
/* 專門用于保存需要寫入idtr寄存器值的變量,這里可以看出,中斷向量表長度為256 * 16 - 1,地址為idt_table */
struct desc_ptr idt_descr = { NR_VECTORS * 16 - 1, (unsigned long) idt_table };在cpu_init()中,會調用load_current_idt()函數進行寫入,如下:
static inline void load_current_idt(void)
{if (is_debug_idt_enabled())/* 開啟了中斷調試,用的是 debug_idt_descr 和 debug_idt_table */load_debug_idt();else if (is_trace_idt_enabled())/* 開啟了中斷跟蹤,用的是 trace_idt_descr 和 trace_idt_table */load_trace_idt();else/* 普通情況,用的是 idt_descr 和 idt_table */load_idt((const struct desc_ptr *)&idt_descr);
}/* load_idt()的定義 */
#define load_idt(dtr) ? ? ? ? ? ? ? ?native_load_idt(dtr)/* native_load_idt()的定義 */
static inline void native_load_idt(const struct desc_ptr *dtr)
{asm volatile("lidt %0"::"m" (*dtr));
}到這,異常和陷阱已經初始化完畢,內核也已經開始使用新的中斷向量表了,BIOS的中斷向量表就已經遺棄,不再使用了。
③初始化中斷
內核是在異常和陷阱初始化完成的情況下才會進行中斷的初始化,中斷的初始化也是處于start_kernel()函數中,分為兩個部分,分別是early_irq_init()和init_IRQ()。early_irq_init()是第一步的初始化,其工作主要是跟硬件無關的一些初始化,比如一些變量的初始化,分配必要的內存等。init_IRQ()是第二步,其主要就是關于硬件部分的初始化了。首先我們先看看中斷描述符表irq_desc[NR_IRQS]:
/* 中斷描述符表 */
struct irq_desc irq_desc[NR_IRQS] __cacheline_aligned_in_smp = {[0 ... NR_IRQS-1] = {.handle_irq ? ?= handle_bad_irq,.depth ? ? ? ?= 1,.lock ? ? ? ?= __RAW_SPIN_LOCK_UNLOCKED(irq_desc->lock),}
};可以看到,irq_desc數組有NR_IRQS個元素,NR_IRQS并不是256-32,實際上,雖然中斷向量表中一共有256項(前32項用作異常和intel保留),但并不是所有中斷向量都會使用到,所以中斷描述符表也不一定是256-32項,CPU可以使用多少個中斷是由中斷控制器(PIC、APIC)或者內核配置決定的,我們看看NR_IRQS的定義:
/* IOAPIC為外部中斷控制器 */
#ifdef CONFIG_X86_IO_APIC
#define CPU_VECTOR_LIMIT ? ? ? ?(64 * NR_CPUS)
#define NR_IRQS ? ? ? ? ? ? ? ? ? ?\(CPU_VECTOR_LIMIT > IO_APIC_VECTOR_LIMIT ? ? ?\(NR_VECTORS + CPU_VECTOR_LIMIT) ?: ? ?\(NR_VECTORS + IO_APIC_VECTOR_LIMIT))
#else /* !CONFIG_X86_IO_APIC: NR_IRQS_LEGACY = 16 */
#define NR_IRQS ? ? ? ? ? ?NR_IRQS_LEGACY
#endif這時我們可以先看看early_irq_init()函數:
int __init early_irq_init(void)
{int count, i, node = first_online_node;struct irq_desc *desc;/* 初始化irq_default_affinity變量,此變量用于設置中斷默認的CPU親和力 */init_irq_default_affinity();printk(KERN_INFO "NR_IRQS:%d\n", NR_IRQS);/* 指向中斷描述符表irq_desc */desc = irq_desc;/* 獲取中斷描述符表長度 */count = ARRAY_SIZE(irq_desc);for (i = 0; i < count; i++) {/* 為kstat_irqs分配內存,每個CPU有自己獨有的kstat_irqs數據,此數據用于統計 */desc[i].kstat_irqs = alloc_percpu(unsigned int);/* 為 desc->irq_data.affinity 和 desc->pending_mask 分配內存 */alloc_masks(&desc[i], GFP_KERNEL, node);/* 初始化中斷描述符的鎖 */raw_spin_lock_init(&desc[i].lock);/* 設置中斷描述符的鎖所屬的類,此類用于防止死鎖 */lockdep_set_class(&desc[i].lock, &irq_desc_lock_class);/* 一些變量的初始化 */desc_set_defaults(i, &desc[i], node, NULL);}return arch_early_irq_init();
}更多的初始化在desc_set_defaults()函數中:
static void desc_set_defaults(unsigned int irq, struct irq_desc *desc, int node,struct module *owner)
{int cpu;/* 中斷號 */desc->irq_data.irq = irq;/* 中斷描述符的中斷控制器芯片為 no_irq_chip ?*/desc->irq_data.chip = &no_irq_chip;/* 中斷控制器的私有數據為空 */desc->irq_data.chip_data = NULL;desc->irq_data.handler_data = NULL;desc->irq_data.msi_desc = NULL;/* 設置中斷狀態 desc->status_use_accessors 為初始化狀態_IRQ_DEFAULT_INIT_FLAGS */irq_settings_clr_and_set(desc, ~0, _IRQ_DEFAULT_INIT_FLAGS);/* 中斷默認被禁止,設置 desc->irq_data->state_use_accessors = IRQD_IRQ_DISABLED */irqd_set(&desc->irq_data, IRQD_IRQ_DISABLED);/* 設置中斷處理回調函數為 handle_bad_irq,handle_bad_irq作為默認的回調函數,此函數中基本上不做什么處理,就是在屏幕上打印此中斷信息,并且desc->kstat_irqs++ */desc->handle_irq = handle_bad_irq;/* 嵌套深度為1,表示被禁止1次 */desc->depth = 1;/* 初始化此中斷發送次數為0 */desc->irq_count = 0;/* 無法處理的中斷次數為0 */desc->irqs_unhandled = 0;/* 在/proc/interrupts所顯名字為空 */desc->name = NULL;/* owner為空 */desc->owner = owner;/* 初始化kstat_irqs中每個CPU項都為0 */for_each_possible_cpu(cpu)*per_cpu_ptr(desc->kstat_irqs, cpu) = 0;/* SMP系統才使用的初始化,設置* desc->irq_data.node = first_online_node?* desc->irq_data.affinity = irq_default_affinity* 清除desc->pending_mask*/desc_smp_init(desc, node);
}整個early_irq_init()在這里就初始化完畢了,相對來說比較簡單,可以說early_irq_init()只是初始化了中斷描述符表中的所有元素。
在看init_IRQ()前需要看看legacy_pic這個變量,它其實就是CPU內部的中斷控制器i8259A,定義了與i8259A相關的一些處理函數和中斷數量,如下:
struct legacy_pic default_legacy_pic = {.nr_legacy_irqs = NR_IRQS_LEGACY,.chip ?= &i8259A_chip,.mask = mask_8259A_irq,.unmask = unmask_8259A_irq,.mask_all = mask_8259A,.restore_mask = unmask_8259A,.init = init_8259A,.irq_pending = i8259A_irq_pending,.make_irq = make_8259A_irq,
};struct legacy_pic *legacy_pic = &default_legacy_pic;在X86體系下,CPU使用的內部中斷控制器是i8259A,內核就定義了這個變量進行使用,在init_IRQ()中會將所有的中斷描述符的中斷控制器芯片指向i8259A,具體我們先看看init_IRQ()代碼:
void __init init_IRQ(void)
{int i;/** On cpu 0, Assign IRQ0_VECTOR..IRQ15_VECTOR's to IRQ 0..15.* If these IRQ's are handled by legacy interrupt-controllers like PIC,* then this configuration will likely be static after the boot. If* these IRQ's are handled by more mordern controllers like IO-APIC,* then this vector space can be freed and re-used dynamically as the* irq's migrate etc.*//* nr_legacy_irqs() 返回 legacy_pic->nr_legacy_irqs,為16* vector_irq是一個int型的數組,長度為中斷向量表長,其保存的是中斷向量對應的中斷號(如果中斷向量是異常則沒有中斷號)* i8259A中斷控制器使用IRQ0~IRQ15這16個中斷號,這里將這16個中斷號設置到CPU0的vector_irq數組的0x30~0x3f上。*/for (i = 0; i < nr_legacy_irqs(); i++)per_cpu(vector_irq, 0)[IRQ0_VECTOR + i] = i;/* x86_init是一個結構體,里面定義了一組X86體系下的初始化函數 */x86_init.irqs.intr_init();
}x86_init.irqs.intr_init()是一個函數指針,其指向native_init_IRQ(),我們可以直接看看native_init_IRQ():
void __init native_init_IRQ(void)
{int i;/* Execute any quirks before the call gates are initialised: *//* 這里又是執行x86_init結構中的初始化函數,pre_vector_init()指向 init_ISA_irqs ?*/x86_init.irqs.pre_vector_init();/* 初始化中斷向量表中的中斷控制器中默認的一些中斷門初始化 */apic_intr_init();/** Cover the whole vector space, no vector can escape* us. (some of these will be overridden and become* 'special' SMP interrupts)*//* 第一個外部中斷,默認是32 */i = FIRST_EXTERNAL_VECTOR;/* 在used_vectors變量中找出所有沒有置位的中斷向量,我們知道,在trap_init()中對所有異常和陷阱和系統調用中斷都置位了used_vectors,沒有置位的都為中斷* 這里就是對所有中斷設置門描述符*/for_each_clear_bit_from(i, used_vectors, NR_VECTORS) {/* IA32_SYSCALL_VECTOR could be used in trap_init already. *//* interrupt[]數組保存的是外部中斷的中斷門信息* 這里將中斷向量表中空閑的中斷向量設置為中斷門,interrupt是一個函數指針數組,其將31~255數組元素指向interrupt[i]函數*/set_intr_gate(i, interrupt[i - FIRST_EXTERNAL_VECTOR]);}/* 如果外部中斷控制器需要,則安裝一個中斷處理例程irq2到中斷IRQ2上 */if (!acpi_ioapic && !of_ioapic && nr_legacy_irqs())setup_irq(2, &irq2);#ifdef CONFIG_X86_32/* 在x86_32模式下,會為當前CPU分配一個中斷使用的棧空間 */irq_ctx_init(smp_processor_id());
#endif
}在native_init_IRQ()中,又使用了x86_init變量中的pre_vector_init函數指針,其指向init_ISA_irqs()函數:
void __init init_ISA_irqs(void)
{/* CHIP默認是i8259A_chip */struct irq_chip *chip = legacy_pic->chip;int i;#if defined(CONFIG_X86_64) || defined(CONFIG_X86_LOCAL_APIC)/* 使用了CPU本地中斷控制器 *//* 開啟virtual wire mode */init_bsp_APIC();
#endif/* 其實就是調用init_8259A(),進行8259A硬件的初始化 */legacy_pic->init(0);for (i = 0; i < nr_legacy_irqs(); i++)/* i為中斷號,chip是irq_chip結構,最后是中斷回調函數?* 設置了中斷號i的中斷描述符的irq_data.irq_chip = i8259A_chip* 設置了中斷回調函數為handle_level_irq*/irq_set_chip_and_handler(i, chip, handle_level_irq);
}在init_ISA_irqs()函數中,最主要的就是將內核使用的外部中斷的中斷描述符的中斷控制器設置為i8259A_chip,中斷回調函數為handle_level_irq。
回到native_init_IRQ()函數,當執行完x86_init.irqs.pre_vector_init()之后,會執行apic_initr_init()函數,這個函數中會初始化一些中斷控制器特定的中斷函數(這些中斷游離于之前描述的中斷體系中,它們沒有自己的中斷描述符,中斷向量中直接保存它們自己的中斷處理函數,類似于異常與陷阱的調用情況),具體我們看看:
static void __init apic_intr_init(void)
{smp_intr_init();#ifdef CONFIG_X86_THERMAL_VECTOR/* 中斷號為: 0xfa,處理函數為: thermal_interrupt */alloc_intr_gate(THERMAL_APIC_VECTOR, thermal_interrupt);
#endif
#ifdef CONFIG_X86_MCE_THRESHOLDalloc_intr_gate(THRESHOLD_APIC_VECTOR, threshold_interrupt);
#endif#if defined(CONFIG_X86_64) || defined(CONFIG_X86_LOCAL_APIC)/* self generated IPI for local APIC timer */alloc_intr_gate(LOCAL_TIMER_VECTOR, apic_timer_interrupt);/* IPI for X86 platform specific use */alloc_intr_gate(X86_PLATFORM_IPI_VECTOR, x86_platform_ipi);
#ifdef CONFIG_HAVE_KVM/* IPI for KVM to deliver posted interrupt */alloc_intr_gate(POSTED_INTR_VECTOR, kvm_posted_intr_ipi);
#endif/* IPI vectors for APIC spurious and error interrupts */alloc_intr_gate(SPURIOUS_APIC_VECTOR, spurious_interrupt);alloc_intr_gate(ERROR_APIC_VECTOR, error_interrupt);/* IRQ work interrupts: */
# ifdef CONFIG_IRQ_WORKalloc_intr_gate(IRQ_WORK_VECTOR, irq_work_interrupt);
# endif#endif
}在apic_intr_init()函數中,使用了alloc_intr_gate()函數進行處理,這個函數的處理也很簡單,置位該中斷號所處used_vectors位置,調用set_intr_gate()設置一個中斷門描述符,到這里整個中斷及異常都已經初始化完成了。
-
在linux系統中,中斷一共有256個,0~19主要用于異常與陷阱,20~31是intel保留,未使用。32~255作為外部中斷進行使用。特別的,0x80中斷用于系統調用。
-
機器上電時,BIOS會初始化一個中斷向量表,當交接給linux內核后,內核會自己新建立一個中斷向量表,之后完全使用自己的中斷向量表,舍棄BIOS的中斷向量表。
-
在x86上系統默認使用的中斷控制器為i8259A。
-
中斷描述符的初始化過程中,內核會將中斷描述符的默認中斷控制器設置為i8259A,中斷處理回調函數為handle_level_irq()。
-
外部中斷的門描述的中斷處理函數都為interrupt[i]。
中斷的初始化大體上分為兩個部分,第一個部分為匯編代碼的中斷向量表的初次初始化,第二部分為C語言代碼,其又分為異常與陷阱的初始化和中斷的初始化。如圖:
在匯編的中斷向量表初始化過中,其主要對整個中斷向量表進行了初始化,其主要工作是:
-
所有的門描述符的權限位為0;
-
所有的門描述符的段選擇符為__KERNEL_CS;
-
0~31的門描述符的中斷處理程序為early_idt_handlers[i](0 <= i <= 31);
-
其他的門描述符的中斷處理程序為ignore_int;
而trap_init()所做的異常與陷阱初始化,就是修改中斷向量表的前19項(異常和中斷),主要修改他們的中斷處理函數入口和權限位,特殊的如任務門還會設置它們的段選擇符。在trap_init()中就已經把所有的異常和陷阱都初始化完成了,并會把新的中斷向量表地址放入idtr寄存器,開始使用新的中斷向量表。
在early_irq_init()中,主要工作是初始化整個中斷描述符表,將數組中的每個中斷描述符中的必要變量進行初始化,最后在init_IRQ()中,主要工作是初始化中斷向量表中的所有中斷門描述符,對于一般的中斷,內核將它們的中斷處理函數入口設置為interrupt[i],而一些特殊的中斷會在apic_intr_init()中進行設置。之后,init_IRQ()會初始化內部和外部的中斷控制器,最后將一般的中斷使用的中斷控制器設置為i8259A,中斷處理函數為handle_level_irq(電平觸發)。
3.2中斷運行流程
(2)禁止調度和搶占
首先我們需要了解,當系統處于中斷上下文時,是禁止發生調度和搶占的。進程的thread_info中有個preempt_count成員變量,其作為一個變量,包含了3個計數器和一個標志位,如下:
| 位 | 描述 | 解釋 |
|---|---|---|
| 0~7 | 搶占計數器 | 也可以說是鎖占用數 |
| 8~15 | 軟中斷計數器 | 記錄軟中斷被禁用次數,0表示可以進行軟中斷。 |
| 16~27 | 硬中斷計數器 | 表示中斷處理嵌套次數,irq_enter()增加它,irq_exit()減少它。 |
| 28 | PREEMPT_ACTIVE標志 | 表示正在進行內核搶占,設置此標志也禁止了搶占。 |
當進入到中斷時,中斷處理程序會調用irq_enter()函數禁止搶占和調度。當中斷退出時,會通過irq_exit()減少其硬件計數器。我們需要清楚的就是,無論系統處于硬中斷還是軟中斷,調度和搶占都是被禁止的。
(2)中斷產生
我們需要先明確一下,中斷控制器與CPU相連的三種線:INTR、數據線、INTA。
在硬件電路中,中斷的產生發生一般只有兩種,分別是:電平觸發方式和邊沿觸發方式。當一個外部設備產生中斷,中斷信號會沿著中斷線到達中斷控制器。中斷控制器接收到該外部設備的中斷信號后首先會檢測自己的中斷屏蔽寄存器是否屏蔽該中斷。
如果沒有,則設置中斷請求寄存器中中斷向量號對應的位,并將INTR拉高用于通知CPU,CPU每當執行完一條指令時都會去檢查INTR引腳是否有信號(這是CPU自動進行的),如果有信號,CPU還會檢查EFLAGS寄存器的IF標志位是否禁止了中斷(IF = 0),如果CPU未禁止中斷,CPU會自動通過INTA信號線應答中斷控制器。CPU再次通過INTA信號線通知中斷控制器,此時中斷控制器會把中斷向量號送到數據線上,CPU讀取數據線獲取中斷向量號。到這里實際上中斷向量號已經發送給CPU了,如果中斷控制器是AEIO模式,則會自動清除中斷向量號對應的中斷請求寄存器的位,如果是EIO模式,則等待CPU發送的EIO信號后在清除中斷向量號對應的中斷請求寄存器的位。
用步驟描述就是:
-
中斷控制器收到中斷信號
-
中斷控制器檢查中斷屏蔽寄存器是否屏蔽該中斷,若屏蔽直接丟棄
-
中斷控制器設置該中斷所在的中斷請求寄存器位
-
通過INTR通知CPU
-
CPU收到INTR信號,檢查是否屏蔽中斷,若屏蔽直接無視
-
CPU通過INTA應答中斷控制器
-
CPU再次通過INTA應答中斷控制器,中斷控制器將中斷向量號放入數據線
-
CPU讀取數據線上的中斷向量號
-
若中斷控制器為EIO模式,CPU發送EIO信號給中斷控制器,中斷控制器清除中斷向量號對應中斷請求寄存器位
SMP系統
在SMP系統,也就是多核情況下,外部的中斷控制器有可能會于多個CPU相連,這時候當一個中斷產生時,中斷控制器有兩種方式將此中斷送到CPU上,分別是靜態分發和動態分發。區別就是靜態分發設置了指定中斷送往指定的一個或多個CPU上。動態分發則是由中斷控制器控制中斷應該發往哪個CPU或CPU組。
CPU已經接收到了中斷信號以及中斷向量號。此時CPU會自動跳轉到中斷描述符表地址,以中斷向量號作為一個偏移量,直接訪問中斷向量號對應的門描述符。在門描述符中,有個特權級(DPL),系統會先檢查這個位,然后清除EFLAGS的IF標志位(這也說明了發發生中斷時實際上CPU是禁止其他可屏蔽中斷的),之后轉到描述符中的中斷處理程序中。在上一篇文章我們知道,所有的中斷門描述符的中斷處理程序都被初始化成了interrupt[i],它是一段匯編代碼。
(3)中斷和異常發生時CPU自動完成的工作
我們先注意看一下中斷描述符表,里面的每個中斷描述符都有一個段選擇符和一個偏移量以及一個DPL(特權級),而偏移量其實就是中斷處理程序的入口地址,當中斷或異常發生時:
-
CPU首先會確定是中斷或異常的向量號,然后根據這個向量號作為偏移量,通過讀取idtr中保存的中斷向量表(IDT)的基地址獲取相應的門描述符。并從門描述符中拿出其中的段選擇符
-
根據段選擇符從GDT中獲取這個段的段描述符(為什么只從GDT中獲取?因為初始化所有中段描述符時使用的段選擇符幾乎都是__USER_CS,__KERNEL_CS,TSS,這幾個段選擇符對應的段描述符都保存在GDT中)。而這幾個段描述符中的基地址都是0x00000000,所以偏移量就是中斷處理程序入口地址。
-
這時還沒有進入到中斷處理程序,CPU會先使用CS寄存器的當前特權級(CPL)與中斷向量描述符中對應的段描述符的DPL進行比較,如果DPL的值 <= CPL的值,則通過檢查,而DPL的值 > CPL的值時,會產生一個"通用保護"異常。這種情況發生的可能性很小,因為在上一篇初始化的文章中也可以看出來,中斷初始化所用的段選擇符都是__KERNEL_CS,而異常的段選擇符幾乎也都是__KERNEL_CS,只除了極特殊的幾個除外。也就是大多數中斷和異常的段選擇符DPL都是0,CPL無論是在內核態(CPL = 0)或者是用戶態(CPL = 3),都可以執行這些中斷和異常。這里的檢查可以理解為檢查是否需要切換段。
-
如果是用戶程序的異常(非CPU內部產生的異常),這里還需要再進行多一步的檢查(中斷和CPU內部異常則不用進行這步檢查), 我們回憶一下中斷初始化的文章,里面介紹了門描述符,在門描述符中也有一個DPL位,用戶程序的異常還要對這個位進行檢查,當前特權級CPL的值 <= DPL的值時,則通過檢查,否則不能通過檢查,而只有系統門和系統中斷門的DPL是3,其他的異常門的DPL都為0。這樣做的好處是避免了用戶程序訪問陷阱門、中斷門和任務門。 (這里可以理解為進入此"門"的權限, 所以只有系統門和系統中斷門是程序能夠主動進入的, 也就是我們做系統調用走的門)
-
如果以上檢查都通過,并且CS寄存器的特權級發生變化(用戶態陷入內核),則CPU會訪問此CPU的TSS段(通過tr寄存器),在TSS段中讀取當前進程的SS和ESP到SS和ESP寄存器中,這樣就完成了用戶態棧到內核態棧的切換。之后把之前的SS寄存器和ESP寄存器的值保存到當前內核棧中。
-
將eflags、CS、EIP寄存器的值壓入內核棧中。這樣就保存了返回后需要執行的上下文。
-
最后將剛才獲取到的段選擇符加載到CS寄存器(CS段切換),段描述符加載到CS對應的非編程寄存器中,也就是CS寄存器保存的是__KERNEL_CS,CS寄存器的非編程寄存器中保存的是對應的段描述符。而根據段描述符中的段基址+段內偏移量(保存在門描述符中),則得到了處理程序入口地址,實際上我們知道段基址是0x00000000,段內偏移量實際上就是處理程序入口地址,這個門描述符的段內偏移量會被放到IP寄存器中。
①interrupt[i]
interrupt[i]的每個元素都相同,執行相同的匯編代碼,這段匯編代碼實際上很簡單,它主要工作就是將中斷向量號和被中斷上下文(進程上下文或者中斷上下文)保存到棧中,最后調用do_IRQ函數。
# 代碼地址:arch/x86/kernel/entry_32.S# 開始
1: ? ?pushl_cfi $(~vector+0x80) ? ?/* Note: always in signed byte range */ # 先會執行這一句,將中斷向量號取反然后加上0x80壓入棧中.if ((vector-FIRST_EXTERNAL_VECTOR)%7) <> 6jmp 2f ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? # 數字定義的標號為臨時標號,可以任意重復定義,例如:"2f"代表正向第一次出現的標號"2:",3b代表反向第一次出現的標號"3:".endif.previous ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? # .previous使匯編器返回到該自定義段之前的段進行匯編,則回到上面的數據段.long 1b ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? # 在數據段中執行標號1的操作.section .entry.text, "ax" ? ? ? ? ? ? ? ? ? ? ? ? ? ? # 回到代碼段
vector=vector+1?.endif?.endr
2: ? ?jmp common_interruptcommon_interrupt:ASM_CLACaddl $-0x80,(%esp) ? ? ? # 此時棧頂是(~vector + 0x80),這里再加上-0x80,實際就是中斷向量號取反,用于區別系統調用,系統調用是正數,中斷向量是負數SAVE_ALL ? ? ? ? ? ? ? ? # 保存現場,將寄存器值壓入棧中TRACE_IRQS_OFF ? ? ? ? ? # 關閉中斷跟蹤movl %esp,%eax ? ? ? ? ? # 將棧指針保存到eax寄存器,供do_IRQ使用call do_IRQ ? ? ? ? ? ? ?# 調用do_IRQjmp ret_from_intr ? ? ? ?# 跳轉到ret_from_intr,進行中斷返回的一些處理
ENDPROC(common_interrupt)CFI_ENDPROC需要注意這里面有一個SAVE_ALL是用于保存用戶態寄存器值的,在上面的文章中有提到CPU會自動保存原來特權級的段和棧到內核棧中,但是通用寄存器并不會保存,所以這里會有個SAVE_ALL來保存通用寄存器的值。所以當SAVE_ALL執行完后,所有的上下文都已經保存完畢,最后結果如下:
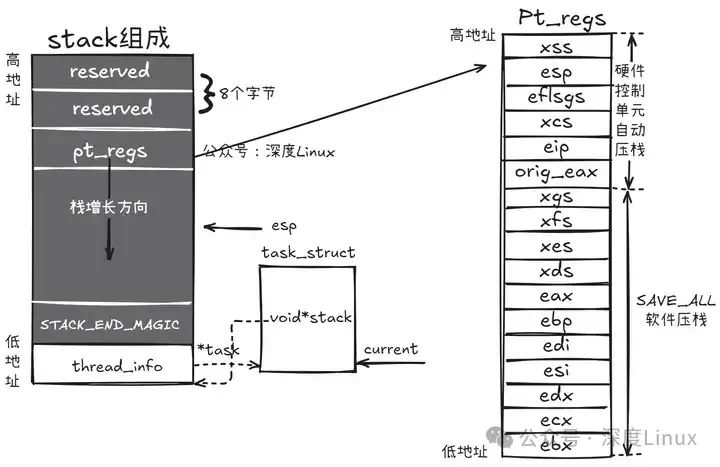
②do_IRQ
這是中斷處理的核心函數,來到這里時,系統已經做了兩件事
-
系統屏蔽了所有可屏蔽中斷(清除了CPU的IF標志位,由CPU自動完成)
-
將中斷向量號和所有寄存器值保存到內核棧中
在do_IRQ中,首先會添加硬中斷計數器,此行為導致了中斷期間禁止調度發送,此后會根據中斷向量號從vector_irq[]數組中獲取對應的中斷號,并調用handle_irq()函數出來該中斷號對應的中斷出來例程。
__visible unsigned int __irq_entry do_IRQ(struct pt_regs *regs)
{/* 將棧頂地址保存到全局變量__irq_regs中,old_regs用于保存現在的__irq_regs值,這一行代碼很重要,實現了嵌套中斷情況下的現場保存與還原 */struct pt_regs *old_regs = set_irq_regs(regs);/* 獲取中斷向量號,因為中斷向量號是以取反方式保存的,這里再次取反 */unsigned vector = ~regs->orig_ax;/* 中斷向量號 */unsigned irq;/* 硬中斷計數器增加,硬中斷計數器保存在preempt_count */irq_enter();/* 這里開始禁止調度,因為preempt_count不為0 *//* 退出idle進程(如果當前進程是idle進程的情況下) */exit_idle();/* 根據中斷向量號獲取中斷號 */irq = __this_cpu_read(vector_irq[vector]);/* 主要函數是handle_irq,進行中斷服務例程的處理 */if (!handle_irq(irq, regs)) {/* EIO模式的應答 */ack_APIC_irq();/* 該中斷號并沒有發生過多次觸發 */if (irq != VECTOR_RETRIGGERED) {pr_emerg_ratelimited("%s: %d.%d No irq handler for vector (irq %d)\n",__func__, smp_processor_id(),vector, irq);} else {/* 將此中斷向量號對應的vector_irq設置為未定義 */__this_cpu_write(vector_irq[vector], VECTOR_UNDEFINED);}}/* 硬中斷計數器減少 */irq_exit();/* 這里開始允許調度 *//* 恢復原來的__irq_regs值 */set_irq_regs(old_regs);return 1;
}do_IRQ()函數中最重要的就是handle_irq()處理了,我們看看:
bool handle_irq(unsigned irq, struct pt_regs *regs)
{struct irq_desc *desc;int overflow;/* 檢查棧是否溢出 */overflow = check_stack_overflow();/* 獲取中斷描述符 */desc = irq_to_desc(irq);/* 檢查是否獲取到中斷描述符 */if (unlikely(!desc))return false;/* 檢查使用的棧,有兩種情況,如果進程的內核棧配置為8K,則使用進程的內核棧,如果為4K,系統會專門為所有中斷分配一個4K的棧專門用于硬中斷處理棧,一個4K專門用于軟中斷處理棧,還有一個4K專門用于異常處理棧 */if (user_mode_vm(regs) || !execute_on_irq_stack(overflow, desc, irq)) {if (unlikely(overflow))print_stack_overflow();/* 執行handle_irq */desc->handle_irq(irq, desc);}return true;
}好的,最后執行中斷描述符中的handle_irq指針所指函數,我們回憶一下,在初始化階段,所有的中斷描述符的handle_irq指針指向了handle_level_irq()函數,文章開頭我們也說過,中斷產生方式有兩種:一種電平觸發、一種是邊沿觸發。handle_level_irq()函數就是用于處理電平觸發的情況,系統內建了一些handle_irq函數,具體定義在include/linux/irq.h文件中,我們羅列幾種常用的:
-
handle_simple_irq() 簡單處理情況處理函數
-
handle_level_irq() 電平觸發方式情況處理函數
-
handle_edge_irq() 邊沿觸發方式情況處理函數
-
handle_fasteoi_irq() 用于需要EOI回應的中斷控制器
-
handle_percpu_irq() 此中斷只需要單一CPU響應的處理函數
-
handle_nested_irq() 用于處理使用線程的嵌套中斷
我們主要看看handle_level_irq()函數函數,有興趣的朋友也可以看看其他的,因為觸發方式不同,通知中斷控制器、CPU屏蔽、中斷狀態設置的時機都不同,它們的代碼都在kernel/irq/chip.c中。
/* 用于電平中斷,電平中斷特點:* 只要設備的中斷請求引腳(中斷線)保持在預設的觸發電平,中斷就會一直被請求,所以,為了避免同一中斷被重復響應,必須在處理中斷前先把mask irq,然后ack irq,以便復位設備的中斷請求引腳,響應完成后再unmask irq*/
void
handle_level_irq(unsigned int irq, struct irq_desc *desc)
{raw_spin_lock(&desc->lock);/* 通知中斷控制器屏蔽該中斷線,并設置中斷描述符屏蔽該中斷 */mask_ack_irq(desc);/* 檢查此irq是否處于運行狀態,也就是檢查IRQD_IRQ_INPROGRESS標志和IRQD_WAKEUP_ARMED標志。大家可以看看,還會檢查poll */if (!irq_may_run(desc))goto out_unlock;desc->istate &= ~(IRQS_REPLAY | IRQS_WAITING);/* 增加此中斷號所在proc中的中斷次數 */kstat_incr_irqs_this_cpu(irq, desc);/** If its disabled or no action available* keep it masked and get out of here*//* 判斷IRQ是否有中斷服務例程(irqaction)和是否被系統禁用 */if (unlikely(!desc->action || irqd_irq_disabled(&desc->irq_data))) {desc->istate |= IRQS_PENDING;goto out_unlock;}/* 在里面執行中斷服務例程 */handle_irq_event(desc);/* 通知中斷控制器恢復此中斷線 */cond_unmask_irq(desc);out_unlock:raw_spin_unlock(&desc->lock);
}這個函數還是比較簡單,看handle_irq_event()函數:
irqreturn_t handle_irq_event(struct irq_desc *desc)
{struct irqaction *action = desc->action;irqreturn_t ret;desc->istate &= ~IRQS_PENDING;/* 設置該中斷處理正在執行,設置此中斷號的狀態為IRQD_IRQ_INPROGRESS */irqd_set(&desc->irq_data, IRQD_IRQ_INPROGRESS);raw_spin_unlock(&desc->lock);/* 主要,具體看 */ret = handle_irq_event_percpu(desc, action);raw_spin_lock(&desc->lock);/* 取消此中斷號的IRQD_IRQ_INPROGRESS狀態 */irqd_clear(&desc->irq_data, IRQD_IRQ_INPROGRESS);return ret;
}再看handle_irq_event_percpu()函數:
irqreturn_t
handle_irq_event_percpu(struct irq_desc *desc, struct irqaction *action)
{irqreturn_t retval = IRQ_NONE;unsigned int flags = 0, irq = desc->irq_data.irq;/* desc中的action是一個鏈表,每個節點包含一個處理函數,這個循環是遍歷一次action鏈表,分別執行一次它們的處理函數 */do {irqreturn_t res;/* 用于中斷跟蹤 */trace_irq_handler_entry(irq, action);/* 執行處理,在驅動中定義的中斷處理最后就是被賦值到中斷服務例程action的handler指針上,這里就執行了驅動中定義的中斷處理 */res = action->handler(irq, action->dev_id);trace_irq_handler_exit(irq, action, res);if (WARN_ONCE(!irqs_disabled(),"irq %u handler %pF enabled interrupts\n",irq, action->handler))local_irq_disable();/* 中斷返回值處理 */switch (res) {/* 需要喚醒該中斷處理例程的中斷線程 */case IRQ_WAKE_THREAD:/** Catch drivers which return WAKE_THREAD but* did not set up a thread function*//* 該中斷服務例程沒有中斷線程 */if (unlikely(!action->thread_fn)) {warn_no_thread(irq, action);break;}/* 喚醒線程 */__irq_wake_thread(desc, action);/* Fall through to add to randomness */case IRQ_HANDLED:flags |= action->flags;break;default:break;}retval |= res;/* 下一個中斷服務例程 */action = action->next;} while (action);add_interrupt_randomness(irq, flags);/* 中斷調試會使用 */if (!noirqdebug)note_interrupt(irq, desc, retval);return retval;
}其實代碼上很簡單,我們需要注意幾個屏蔽中斷的方式:清除EFLAGS的IF標志、通知中斷控制器屏蔽指定中斷、設置中斷描述符的狀態為IRQD_IRQ_INPROGRESS。在上述代碼中這三種狀態都使用到了,我們具體解釋一下:
-
清除EFLAGS的IF標志:CPU禁止中斷,當CPU進入到中斷處理時自動會清除EFLAGS的IF標志,也就是進入中斷處理時會自動禁止中斷。在SMP系統中,就是單個CPU禁止中斷。
-
通知中斷控制器屏蔽指定中斷:在中斷控制器處就屏蔽中斷,這樣該中斷產生后并不會發到CPU上。在SMP系統中,效果相當于所有CPU屏蔽了此中斷。系統在執行此中斷的中斷處理函數才會要求中斷控制器屏蔽該中斷,所以沒必要在此中斷的處理過程中中斷控制器再發一次中斷信號給CPU。
-
設置中斷描述符的狀態為IRQD_IRQ_INPROGRESS:在SMP系統中,同一個中斷信號有可能發往多個CPU,但是中斷處理只應該處理一次,所以設置狀態為IRQD_IRQ_INPROGRESS,其他CPU執行此中斷時都會先檢查此狀態(可看handle_level_irq()函數)。
所以在SMP系統下,對于handle_level_irq而言,一次典型的情況是:中斷控制器接收到中斷信號,發送給一個或多個CPU,收到的CPU會自動禁止中斷,并執行中斷處理函數,在中斷處理函數中CPU會通知中斷控制器屏蔽該中斷,之后當執行中斷服務例程時會設置該中斷描述符的狀態為IRQD_IRQ_INPROGRESS,表明其他CPU如果執行該中斷就直接退出,因為本CPU已經在處理了。
四、中斷的上半部與下半部處理
在 Linux 中斷處理的復雜體系中,中斷的處理過程被巧妙地劃分為上半部和下半部,這種設計模式旨在實現中斷處理的高效性與及時性,充分滿足系統對不同類型任務處理的需求。
4.1 上半部:快速響應硬件
上半部在中斷處理流程中扮演著至關重要的 “先鋒官” 角色,其主要任務是對硬件中斷進行迅速響應,執行那些對時間極為敏感、需要立即完成的關鍵操作。當硬件設備產生中斷信號時,上半部會立即被觸發,它會迅速讀取硬件設備的狀態信息,以了解中斷產生的具體原因和相關情況,然后及時清除中斷標志,向硬件設備表明中斷已經被響應,避免中斷信號的持續干擾。在處理網卡中斷時,上半部會迅速讀取網卡的寄存器狀態,獲取數據包的基本信息,并清除網卡的中斷標志,確保網卡能夠繼續正常工作,接收后續的數據包。
上半部在中斷處理中具有關鍵作用,它是系統與硬件設備之間的 “快速通道”,能夠確保硬件設備的請求得到及時處理,維持系統的實時性和穩定性。由于硬件中斷可能隨時發生,并且具有較高的優先級,如果上半部不能快速執行,就會導致其他中斷無法及時響應,從而使系統的響應速度大幅下降,甚至可能影響整個系統的正常運行。因此,上半部的代碼通常需要經過精心優化,以確保其能夠在最短的時間內完成任務,快速釋放中斷線,讓系統能夠及時處理其他中斷請求。上半部還需要與下半部密切配合,將那些耗時較長、對時間敏感度較低的任務傳遞給下半部進行處理,從而實現中斷處理的高效分工。
4.2 下半部:延遲處理任務
下半部作為中斷處理的 “后續保障部隊”,主要負責處理那些在上半部無法完成的耗時任務。這些任務通常與硬件設備的基本操作關聯不大,但又需要對中斷事件進行進一步的處理和分析。當下半部被觸發時,它會根據上半部傳遞過來的信息,對中斷事件進行深入處理,如數據的進一步加工、存儲、傳輸等。在處理磁盤中斷時,上半部可能只是簡單地讀取磁盤控制器的狀態并清除中斷標志,而將數據從磁盤緩沖區讀取到內存中的操作則會交給下半部來完成。
下半部在處理耗時任務時具有明顯的優勢,它能夠避免阻塞系統的運行。由于下半部的任務通常不需要立即完成,因此可以在系統相對空閑的時候進行處理,不會影響系統對其他緊急事件的響應能力。下半部在執行任務時可以打開中斷,允許其他中斷的發生,這使得系統在處理耗時任務的同時,仍然能夠及時響應其他硬件設備的請求,提高了系統的并發處理能力。下半部與上半部之間存在著緊密的協作關系,上半部負責快速響應硬件中斷,為下半部的處理提供必要的信息和準備工作;下半部則根據上半部的結果,對中斷事件進行全面而細致的處理,完成整個中斷處理的任務。
4.3 軟中斷、Tasklet 和工作隊列
在 Linux 系統中,下半部的實現主要依賴于軟中斷、Tasklet 和工作隊列這三種機制,它們各自具有獨特的特點和適用場景,為 Linux 系統的中斷處理提供了豐富的選擇。
我們看到中斷實際分為了兩個部分,俗稱就是一部分是硬中斷,一部分是軟中斷。軟中斷是專門用于處理中斷過程中費時費力的操作,而為什么系統要分硬中斷和軟中斷呢?問得明白點就是為什么需要軟中斷。我們可以試著想想,如果只有硬中斷的情況下,我們需要在中斷處理過程中執行一些耗時的操作,比如浮點數運算,復雜算法的運算時,其他的外部中斷就不能得到及時的響應,因為在硬中斷過程中中斷是關閉著的,甚至一些很緊急的中斷會得不到響應,系統穩定性和及時性都受到很大影響。
所以linux為了解決上述這種情況,將中斷處理分為了兩個部分,硬中斷和軟中斷。首先一個外部中斷得到響應時,會先關中斷,并進入到硬中斷完成較為緊急的操作,然后開中斷,并在軟中斷執行那些非緊急、可延時執行的操作;在這種情況下,緊急操作可以立即執行,而其他的外部中斷也可以獲得一個較為快速的響應。這也是軟中斷存在的必要性。在軟中斷過程中是不可以被搶占也不能被阻塞的,也不能在一個給定的CPU上交錯執行。
(1)軟中斷詳解
軟中斷是在中斷框架中專門用于處理非緊急操作的,在SMP系統中,軟中斷可以并發地運行在多個CPU上,但在一些路徑在需要使用自旋鎖進行保護。在系統中,很多東西都分優先級,軟中斷也不例外,有些軟中斷要求更快速的響應運行,在內核中軟中斷一共分為10個,同時也代表著10種不同的優先級,系統用一個枚舉變量表示:
enum
{HI_SOFTIRQ=0, ? ? ? ? ? ? ? ? ? ? /* 高優先級tasklet */ ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?/* 優先級最高 */TIMER_SOFTIRQ, ? ? ? ? ? ? ? ? ? ?/* 時鐘相關的軟中斷 */NET_TX_SOFTIRQ, ? ? ? ? ? ? ? ? ? /* 將數據包傳送到網卡 */NET_RX_SOFTIRQ, ? ? ? ? ? ? ? ? ? /* 從網卡接收數據包 */BLOCK_SOFTIRQ, ? ? ? ? ? ? ? ? ? ?/* 塊設備的軟中斷 */BLOCK_IOPOLL_SOFTIRQ, ? ? ? ? ? ? /* 支持IO輪詢的塊設備軟中斷 */TASKLET_SOFTIRQ, ? ? ? ? ? ? ? ? ?/* 常規tasklet */SCHED_SOFTIRQ, ? ? ? ? ? ? ? ? ? ?/* 調度程序軟中斷 */HRTIMER_SOFTIRQ, ? ? ? ? ? ? ? ? ?/* 高精度計時器軟中斷 */RCU_SOFTIRQ, ? ? ? ? ? ? ? ? ? ? ?/* RCU鎖軟中斷,該軟中斷總是最后一個軟中斷 */ ?/* 優先級最低 */NR_SOFTIRQS ? ? ? ? ? ? ? ? ? ? ? /* 軟中斷數,為10 */
};注釋中的tasklet我們之后會說明,這里先無視它。每一個優先級的軟中斷都使用一個struct softirq_action結構來表示,在這個結構中,只有一個成員變量,就是action函數指針,因為不同的軟中斷它的處理方式可能不同,從優先級表中就可以看出來,有塊設備的,也有網卡處理的。系統將這10個軟中斷用softirq_vec[10]的數組進行保存。
/* 用于描述一個軟中斷 */
struct softirq_action
{/* 此軟中斷的處理函數 */ ? ? ? ?void ? ?(*action)(struct softirq_action *);
};/* 10個軟中斷描述符都保存在此數組 */
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;系統一般使用open_softirq()函數進行軟中斷描述符的初始化,主要就是將action函數指針指向該軟中斷應該執行的函數。在start_kernel()進行系統初始化中,就調用了softirq_init()函數對HI_SOFTIRQ和TASKLET_SOFTIRQ兩個軟中斷進行了初始化
void __init softirq_init(void)
{int cpu;for_each_possible_cpu(cpu) {per_cpu(tasklet_vec, cpu).tail =&per_cpu(tasklet_vec, cpu).head;per_cpu(tasklet_hi_vec, cpu).tail =&per_cpu(tasklet_hi_vec, cpu).head;}/* 開啟常規tasklet */open_softirq(TASKLET_SOFTIRQ, tasklet_action);/* 開啟高優先級tasklet */open_softirq(HI_SOFTIRQ, tasklet_hi_action);
}/* 開啟軟中斷 */
void open_softirq(int nr, void (*action)(struct softirq_action *))
{softirq_vec[nr].action = action;
}
可以看到,TASKLET_SOFTIRQ的action操作使用了tasklet_action()函數,HI_SOFTIRQ的action操作使用了tasklet_hi_action()函數,這兩個函數我們需要結合tasklet進行說明。我們也可以看看其他的軟中斷使用了什么函數:
open_softirq(TIMER_SOFTIRQ, run_timer_softirq);
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
open_softirq(BLOCK_SOFTIRQ, blk_done_softirq);
open_softirq(BLOCK_IOPOLL_SOFTIRQ, blk_iopoll_softirq);
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
open_softirq(HRTIMER_SOFTIRQ, run_hrtimer_softirq);
open_softirq(RCU_SOFTIRQ, rcu_process_callbacks);實很明顯可以看出,除了TASKLET_SOFTIRQ和HI_SOFTIRQ,其他的軟中斷更多地是用于特定的設備和環境,對于我們普通的IO驅動和設備而已,使用的軟中斷幾乎都是TASKLET_SOFTIRQ和HI_SOFTIRQ,而系統為了對這些不同IO設備進行統一的處理,就在TASKLET_SOFTIRQ和HI_SOFTIRQ的action函數中使用到了tasklet。
對于每個CPU,都有一個irq_cpustat_t的數據結構,里面有一個__softirq_pending變量,這個變量很重要,用于表示該CPU的哪個軟中斷處于掛起狀態,在軟中斷處理時可以根據此值跳過不需要處理的軟中斷,直接處理需要處理的軟中斷。內核使用local_softirq_pending()獲取此CPU的__softirq_pending的值。
當使用open_softirq設置好某個軟中斷的action指針后,該軟中斷就會開始可以使用了,其實更明了地說,從中斷初始化完成開始,即使所有的軟中斷都沒有使用open_softirq()進行初始化,軟中斷都已經開始使用了,只是所有軟中斷的action都為空,系統每次執行到軟中斷都沒有軟中斷需要執行罷了。
在每個CPU上一次軟中斷處理的一個典型流程是:
-
硬中斷執行完畢,開中斷。
-
檢查該CPU是否處于嵌套中斷的情況,如果處于嵌套中,則不執行軟中斷,也就是在最外層中斷才執行軟中斷。
-
執行軟中斷,設置一個軟中斷執行最多使用時間和循環次數(10次)。
-
進入循環,獲取CPU的__softirq_pending的副本。
-
執行此__softirq_pending副本中所有需要執行的軟中斷。
-
如果軟中斷執行完畢,退出中斷上下文。
-
如果還有軟中斷需要執行(在軟中斷期間又發發生了中斷,產生了新的軟中斷,新的軟中斷記錄在CPU的__softirq_pending上,而我們的__softirq_pending只是個副本)。
-
檢查此次軟中斷總共使用的時間和循環次數,條件允許繼續執行軟中斷,循環次數減一,并跳轉到第4步。
我們具體看一下代碼,首先在irq_exit()中會檢查是否需要進行軟中斷處理:
void irq_exit(void)
{
#ifndef __ARCH_IRQ_EXIT_IRQS_DISABLEDlocal_irq_disable();
#elseWARN_ON_ONCE(!irqs_disabled());
#endifaccount_irq_exit_time(current);/* 減少preempt_count的硬中斷計數器 */preempt_count_sub(HARDIRQ_OFFSET);/* in_interrupt()會檢查preempt_count上的軟中斷計數器和硬中斷計數器來判斷是否處于中斷嵌套中 *//* local_softirq_pending()則會檢查該CPU的__softirq_pending變量,是否有軟中斷掛起 */if (!in_interrupt() && local_softirq_pending())invoke_softirq();tick_irq_exit();rcu_irq_exit();trace_hardirq_exit(); /* must be last! */
}我們再進入到invoke_softirq():
static inline void invoke_softirq(void)
{if (!force_irqthreads) {
#ifdef CONFIG_HAVE_IRQ_EXIT_ON_IRQ_STACK/** We can safely execute softirq on the current stack if* it is the irq stack, because it should be near empty* at this stage.*//* 軟中斷處理函數 */__do_softirq();
#else/** Otherwise, irq_exit() is called on the task stack that can* be potentially deep already. So call softirq in its own stack* to prevent from any overrun.*/do_softirq_own_stack();
#endif} else {/* 如果強制使用軟中斷線程進行軟中斷處理,會通知調度器喚醒軟中斷線程ksoftirqd */wakeup_softirqd();}
}重頭戲就在__do_softirq()中,我已經注釋好了,方便大家看:
asmlinkage __visible void __do_softirq(void)
{/* 為了防止軟中斷執行時間太長,設置了一個軟中斷結束時間 */unsigned long end = jiffies + MAX_SOFTIRQ_TIME;/* 保存當前進程的標志 */unsigned long old_flags = current->flags;/* 軟中斷循環執行次數: 10次 */int max_restart = MAX_SOFTIRQ_RESTART;/* 軟中斷的action指針 */struct softirq_action *h;bool in_hardirq;__u32 pending;int softirq_bit;/** Mask out PF_MEMALLOC s current task context is borrowed for the* softirq. A softirq handled such as network RX might set PF_MEMALLOC* again if the socket is related to swap*/current->flags &= ~PF_MEMALLOC;/* 獲取此CPU的__softirq_pengding變量值 */pending = local_softirq_pending();/* 用于統計進程被軟中斷使用時間 */account_irq_enter_time(current);/* 增加preempt_count軟中斷計數器,也表明禁止了調度 */__local_bh_disable_ip(_RET_IP_, SOFTIRQ_OFFSET);in_hardirq = lockdep_softirq_start();/* 循環10次的入口,每次循環都會把所有掛起需要執行的軟中斷執行一遍 */
restart:/* 該CPU的__softirq_pending清零,當前的__softirq_pending保存在pending變量中 *//* 這樣做就保證了新的軟中斷會在下次循環中執行 */set_softirq_pending(0);/* 開中斷 */local_irq_enable();/* h指向軟中斷數組頭 */h = softirq_vec;/* 每次獲取最高優先級的已掛起軟中斷 */while ((softirq_bit = ffs(pending))) {unsigned int vec_nr;int prev_count;/* 獲取此軟中斷描述符地址 */h += softirq_bit - 1;/* 減去軟中斷描述符數組首地址,獲得軟中斷號 */vec_nr = h - softirq_vec;/* 獲取preempt_count的值 */prev_count = preempt_count();/* 增加統計中該軟中斷發生次數 */kstat_incr_softirqs_this_cpu(vec_nr);trace_softirq_entry(vec_nr);/* 執行該軟中斷的action操作 */h->action(h);trace_softirq_exit(vec_nr);/* 之前保存的preempt_count并不等于當前的preempt_count的情況處理,也是簡單的把之前的復制到當前的preempt_count上,這樣做是防止最后軟中斷計數不為0導致系統不能夠執行調度 */if (unlikely(prev_count != preempt_count())) {pr_err("huh, entered softirq %u %s %p with preempt_count %08x, exited with %08x?\n",vec_nr, softirq_to_name[vec_nr], h->action,prev_count, preempt_count());preempt_count_set(prev_count);}/* h指向下一個軟中斷,但下個軟中斷并不一定需要執行,這里只是配合softirq_bit做到一個處理 */h++;pending >>= softirq_bit;}rcu_bh_qs();/* 關中斷 */local_irq_disable();/* 循環結束后再次獲取CPU的__softirq_pending變量,為了檢查是否還有軟中斷未執行 */pending = local_softirq_pending();/* 還有軟中斷需要執行 */if (pending) {/* 在還有軟中斷需要執行的情況下,如果時間片沒有執行完,并且循環次數也沒到10次,繼續執行軟中斷 */if (time_before(jiffies, end) && !need_resched() &&--max_restart)goto restart;/* 這里是有軟中斷掛起,但是軟中斷時間和循環次數已經用完,通知調度器喚醒軟中斷線程去執行掛起的軟中斷,軟中斷線程是ksoftirqd,這里只起到一個通知作用,因為在中斷上下文中是禁止調度的 */wakeup_softirqd();}lockdep_softirq_end(in_hardirq);/* 用于統計進程被軟中斷使用時間 */account_irq_exit_time(current);/* 減少preempt_count中的軟中斷計數器 */__local_bh_enable(SOFTIRQ_OFFSET);WARN_ON_ONCE(in_interrupt());/* 還原進程標志 */tsk_restore_flags(current, old_flags, PF_MEMALLOC);
}流程就和上面所說的一致,如果還有不懂,可以去內核代碼目錄/kernel/softirq.c查看源碼。
(2)tasklet
軟中斷有多種,部分種類有自己特殊的處理,如從NET_TX_SOFTIRQ和NET_RT_SOFTIRQ、BLOCK_SOFTIRQ等,而如HI_SOFTIRQ和TASKLET_SOFTIRQ則是專門使用tasklet。它是在I/O驅動程序中實現可延遲函數的首選方法,如上一句所說,它建立在HI_SOFTIRQ和TASKLET_SOFTIRQ這兩種軟中斷之上,多個tasklet可以與同一個軟中斷相關聯,系統會使用一個鏈表組織他們,而每個tasklet執行自己的函數處理。而HI_SOFTIRQ和TASKLET_SOFTIRQ這兩個軟中斷并沒有什么區別,他們只是優先級上的不同而已,系統會先執行HI_SOFTIRQ的tasklet,再執行TASKLET_SOFTIRQ的tasklet。同一個tasklet不能同時在幾個CPU上執行,一個tasklet在一個時間上只能在一個CPU的軟中斷鏈上,不能同時在多個CPU的軟中斷鏈上,并且當這個tasklet正在執行時,其他CPU不能夠執行這個tasklet。也就是說,tasklet不必要編寫成可重入的函數。
系統會為每個CPU維護兩個鏈表,用于保存HI_SOFTIRQ的tasklet和TASKLET_SOFTIRQ的tasklet,這兩個鏈表是tasklet_vec和tasklet_hi_vec,它們都是雙向鏈表,如下:
struct tasklet_head {struct tasklet_struct *head;struct tasklet_struct **tail;
};static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);在softirq_init()函數中,會將每個CPU的tasklet_vec鏈表和tasklet_hi_vec鏈表進行初始化,將他們的頭尾相連,實現為一個空鏈表。由于tasklet_vec和tasklet_hi_vec處理方式幾乎一樣,只是軟中斷的優先級別不同,我們只需要理解系統如何對tasklet_vec進行處理即可。需要注意的是,tasklet_vec鏈表都是以順序方式執行,并不會出現后一個先執行,再到前一個先執行(在軟中斷期間被中斷的情況)。
介紹完tasklet_vec和tasklet_hi_vec鏈表,我們來看看tasklet,tasklet簡單來說,就是一個處理函數的封裝,類似于硬中斷中的irqaction結構。一般來說,在一個驅動中如果需要使用tasklet進行軟中斷的處理,只需要一個中斷對應初始化一個tasklet,它可以在每次中斷產生時重復使用。系統使用tasklet_struct結構進行描述一個tasklet,而且對于同一個tasklet_struct你可以選擇放在tasklet_hi_vec鏈表或者tasklet_vec鏈表上。我們來看看:
struct tasklet_struct
{struct tasklet_struct *next; ? ? ?/* 指向鏈表下一個tasklet */unsigned long state; ? ? ? ? ? ? ?/* tasklet狀態 */atomic_t count; ? ? ? ? ? ? ? ? ? /* 禁止計數器,調用tasklet_disable()會增加此數,tasklet_enable()減少此數 */void (*func)(unsigned long); ? ? ?/* 處理函數 */unsigned long data; ? ? ? ? ? ? ? /* 處理函數使用的數據 */
};tasklet狀態主要分為以下兩種:
-
TASKLET_STATE_SCHED:這種狀態表示此tasklet處于某個tasklet鏈表之上(可能是tasklet_vec也可能是tasklet_hi_vec)。
-
TASKLET_STATE_RUN:表示此tasklet正在運行中。
這兩個狀態主要就是用于防止tasklet同時在幾個CPU上運行和在同一個CPU上交錯執行。
而func指針就是指向相應的處理函數。在編寫驅動時,我們可以使用tasklet_init()函數或者DECLARE_TASKLET宏進行一個task_struct結構的初始化,之后可以使用tasklet_schedule()或者tasklet_hi_schedule()將其放到相應鏈表上等待CPU運行。我們使用一張圖描述一下軟中斷和tasklet結合運行的情況:
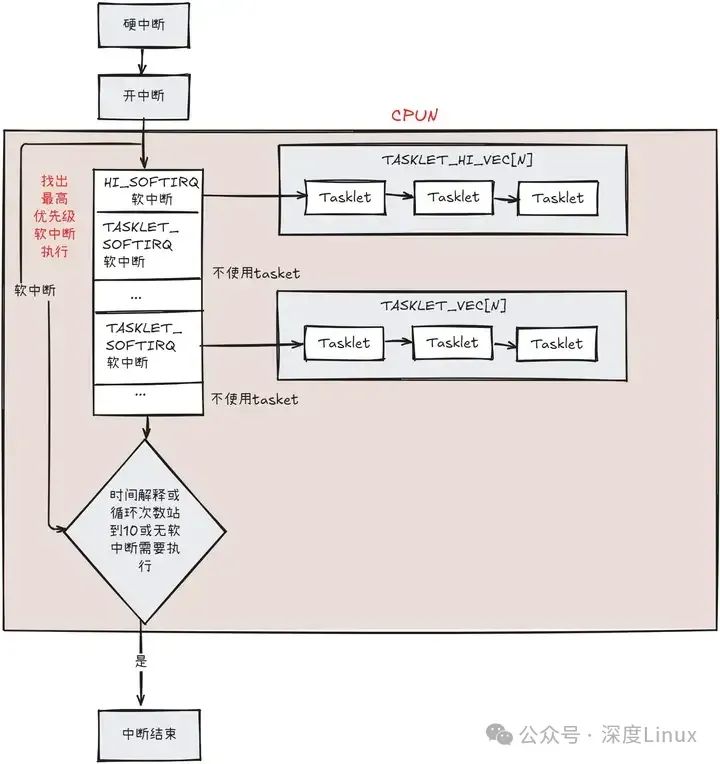
我們知道,每個軟中斷都有自己的action函數,在HI_SOFTIRQ和TASKLET_SOFTIRQ的action函數中,就用到了它們對應的TASKLET_HI_VEC鏈表和TASKLET_VEC鏈表,并依次順序執行鏈表中的每個tasklet結點。
在SMP系統中,我們會遇到一個問題:兩個CPU都需要執行同一個tasklet的情況,雖然一個tasklet只能放在一個CPU的tasklet_vec鏈表或者tasklet_hi_vec鏈表上,但是這種情況是有可能發生的,我們設想一下,中斷在CPU1上得到了響應,并且它的tasklet放到了CPU1的tasklet_vec上進行執行,而當中斷的tasklet上正在執行時,此中斷再次發生,并在CPU2上進行了響應,此時CPU2將此中斷的tasklet放到CPU2的tasklet_vec上,并執行到此中斷的tasklet。
實際上,為了處理這種情況,在HI_SOFTIRQ和TASKLET_SOFTIRQ的action函數中,會先將對應的tasklet鏈表取出來,并把對應的tasklet鏈表的head和tail清空,如果在執行過程中,某個tasklet的state為TASKLET_STATE_RUN狀態,說明其他CPU正在處理這個tasklet,這時候當前CPU則會把此tasklet加入到當前CPU已清空的tasklet鏈表的末尾,然后設置__softirq_pending變量,這樣,在下次循環軟中斷的過程中,會再次檢查這個tasklet。也就是如果其他CPU的這個tasklet一直不退出,當前CPU就會不停的置位tasklet的pending,然后不停地循環檢查。
我們可以看看TASKLET_SOFTIRQ的action處理:
static void tasklet_action(struct softirq_action *a)
{struct tasklet_struct *list;local_irq_disable();/* 將tasklet鏈表從該CPU中拿出來 */list = __this_cpu_read(tasklet_vec.head);/* 將該CPU的此軟中斷的tasklet鏈表清空 */__this_cpu_write(tasklet_vec.head, NULL);__this_cpu_write(tasklet_vec.tail, this_cpu_ptr(&tasklet_vec.head));local_irq_enable();/* 鏈表已經處于list中,并且該CPU的tasklet_vec鏈表為空 */while (list) {struct tasklet_struct *t = list;list = list->next;/* 檢查并設置該tasklet為TASKLET_STATE_RUN狀態 */if (tasklet_trylock(t)) {/* 檢查是否被禁止 */if (!atomic_read(&t->count)) {/* 清除其TASKLET_STATE_SCHED狀態 */if (!test_and_clear_bit(TASKLET_STATE_SCHED,&t->state))BUG();/* 執行該tasklet的func處理函數 */t->func(t->data);/* 清除該tasklet的TASKLET_STATE_RUN狀態 */tasklet_unlock(t);continue;}tasklet_unlock(t);}/* 以下為tasklet為TASKLET_STATE_RUN狀態下的處理 *//* 禁止中斷 */local_irq_disable();/* 將此tasklet添加的該CPU的tasklet_vec鏈表尾部 */t->next = NULL;*__this_cpu_read(tasklet_vec.tail) = t;__this_cpu_write(tasklet_vec.tail, &(t->next));/* 設置該CPU的此軟中斷處于掛起狀態,設置irq_cpustat_t的__sofirq_pending變量,這樣在軟中斷的下次執行中會再次執行此tasklet */__raise_softirq_irqoff(TASKLET_SOFTIRQ);/* 開啟中斷 */local_irq_enable();}
}(3)軟中斷處理線程
當有過多軟中斷需要處理時,為了保證進程能夠得到一個滿意的響應時間,設計時給定軟中斷一個時間片和循環次數,當時間片和循環次數到達但軟中斷又沒有處理完時,就會把剩下的軟中斷交給軟中斷處理線程進行處理,這個線程是一個內核線程,其作為一個普通進程,優先級是120。其核心處理函數是run_ksoftirqd(),其實此線程的處理也很簡單,就是調用了上面的__do_softirq()函數,我們可以具體看看:
/* 在smpboot_thread_fun的一個死循環中被調用 */
static void run_ksoftirqd(unsigned int cpu)
{/* 禁止中斷,在__do_softirq()中會開啟 */local_irq_disable();/* 檢查該CPU的__softirq_pending是否有軟中斷被掛起 */if (local_softirq_pending()) {/** We can safely run softirq on inline stack, as we are not deep* in the task stack here.*//* 執行軟中斷 */__do_softirq();rcu_note_context_switch(cpu);/* 開中斷 */local_irq_enable();/* 檢查是否需要調度 */cond_resched();return;}/* 開中斷 */local_irq_enable();
}五、中斷性能分析
5.1性能指標解讀
在 Linux 系統中,中斷性能的評估涉及多個關鍵指標,這些指標如同精密儀器上的刻度,精準地反映著系統的運行狀態和性能表現。
中斷響應時間是其中最為關鍵的指標之一,它是指從硬件設備發出中斷請求的那一刻起,到 CPU 開始執行對應的中斷處理程序所經歷的時間間隔。這一指標直接體現了系統對外部事件的即時反應能力,在實時性要求極高的應用場景中,如工業自動化控制系統,傳感器不斷產生中斷請求以匯報設備的運行狀態,此時中斷響應時間的長短將直接影響系統對設備狀態變化的捕捉和應對速度。若響應時間過長,可能導致設備控制的延遲,進而引發生產事故。
中斷處理頻率同樣不容忽視,它表示在單位時間內系統處理中斷的次數。中斷處理頻率反映了系統對外部事件的處理效率和負載程度。在網絡服務器中,網卡會頻繁產生中斷以通知系統有新的數據包到達,若中斷處理頻率過高,可能意味著網絡流量過大,系統需要投入大量的資源來處理這些中斷,從而影響其他任務的執行效率。過高的中斷處理頻率還可能導致 CPU 頻繁切換上下文,增加系統的開銷。
此外,中斷處理時間也是一個重要的考量因素,它指的是中斷處理程序從開始執行到執行完畢所花費的時間。中斷處理時間的長短直接影響系統的整體性能和響應能力。如果中斷處理時間過長,會導致 CPU 長時間被中斷處理程序占用,無法及時處理其他任務,從而使系統的響應速度變慢,甚至可能造成系統的卡頓或死機。在處理磁盤 I/O 中斷時,如果中斷處理程序需要花費大量時間來讀寫磁盤數據,就會導致其他任務的執行被阻塞,影響系統的整體運行效率。
5.2 性能分析工具與方法
在 Linux 系統中,有許多實用的工具可用于中斷性能分析,這些工具就像一把把精準的 “手術刀”,幫助系統管理員和開發者深入剖析系統中斷性能,找出潛在的問題和瓶頸。
top 命令是一款常用的系統性能分析工具,它能夠實時顯示系統中各個進程的資源占用狀況,包括 CPU、內存等,同時也提供了有關中斷的重要信息。在 top 命令的輸出結果中,“% hi” 字段表示硬中斷占用 CPU 的百分比,“% si” 字段表示軟中斷占用 CPU 的百分比。通過觀察這兩個字段的值,我們可以直觀地了解到系統中硬中斷和軟中斷對 CPU 資源的消耗情況。如果 “% hi” 值過高,說明硬件中斷頻繁,可能是某些硬件設備出現故障或配置不當,需要進一步檢查硬件連接和驅動程序;如果 “% si” 值過高,則可能表示系統中存在大量的軟件中斷,如網絡數據包的處理、內核定時器的管理等,需要優化相關的軟件代碼或調整系統配置。
sar(System Activity Reporter)命令是另一個功能強大的系統性能分析工具,它可以從多個方面對系統的活動進行詳細報告,其中就包括中斷信息。使用 sar -I 命令可以查看系統的中斷統計信息,包括每個中斷源的中斷次數、中斷頻率等。通過分析這些數據,我們可以深入了解系統中各個中斷源的活動情況,找出中斷頻繁的設備或驅動程序。sar -I SUM 命令可以統計系統總的中斷次數和中斷頻率,sar -I 1,2 命令可以分別查看中斷源 1 和中斷源 2 的中斷統計信息。
除了 top 和 sar 命令外,還有一些其他的工具和方法也可用于中斷性能分析。/proc/interrupts 文件記錄了系統中所有中斷源的中斷次數和中斷處理程序的相關信息,通過查看這個文件,我們可以獲取系統中斷的詳細狀態。proc/softirqs 文件則提供了軟中斷的運行情況,包括各種軟中斷的類型和計數。使用 perf 工具可以對系統進行性能剖析,它能夠跟蹤中斷處理程序的執行過程,分析中斷處理過程中的性能瓶頸,從而為優化提供有力的依據。
六、中斷性能優化策略
6.1 優化中斷處理程序
編寫高效的中斷處理程序是提升中斷性能的關鍵所在,其要點涵蓋多個重要方面。首要原則是盡量精簡中斷處理程序中的操作,摒棄一切不必要的計算和數據處理任務。在處理網絡中斷時,若僅需提取數據包的關鍵信息(如源 IP 地址、目的 IP 地址等),就應避免對整個數據包進行復雜的解析和處理,可將這些操作推遲到中斷處理程序之后的其他任務中執行。中斷處理程序應盡可能縮短執行時間,以減少對 CPU 資源的占用,從而使系統能夠及時響應其他中斷請求。在處理硬件設備的中斷時,應迅速讀取設備狀態、完成必要的操作后,立即返回,避免在中斷處理程序中執行耗時較長的 I/O 操作、復雜的算法計算等。
合理運用算法和數據結構同樣至關重要。對于頻繁訪問的數據,應采用高效的數據結構進行存儲和管理,以減少數據訪問的時間開銷。使用哈希表來存儲設備狀態信息,能夠快速定位和獲取所需數據,大大提高中斷處理的效率。在算法選擇上,應優先選擇時間復雜度較低的算法,以確保在最短的時間內完成任務。在對數據進行排序時,選擇快速排序算法而非冒泡排序算法,因為快速排序算法的平均時間復雜度為 O (n log n),而冒泡排序算法的時間復雜度為 O (n^2),在數據量較大時,快速排序算法的效率優勢將更加明顯。
6.2 中斷親和性設置
中斷親和性是指將特定的中斷固定分配給指定的 CPU 核心進行處理,這一技術能夠顯著提升 CPU 緩存的利用率。在多核心 CPU 系統中,每個核心都擁有獨立的緩存,當一個中斷被分配到某個核心上處理時,該核心的緩存中會存儲與該中斷相關的數據和指令。如果后續的中斷也能被分配到同一個核心上處理,就可以直接從緩存中讀取數據,避免了緩存未命中帶來的性能損耗,從而提高中斷處理的速度和效率。在網絡服務器中,將網卡中斷固定分配給特定的核心處理,能夠確保該核心的緩存中始終保存著與網絡數據包處理相關的數據,如網絡協議棧的相關信息、數據包的緩存等,當新的網絡數據包到達時,該核心能夠迅速從緩存中獲取所需信息,快速處理中斷,提高網絡數據的處理速度。
設置中斷親和性的方法在 Linux 系統中較為直觀。可以通過修改 /proc/irq/[中斷號]/smp_affinity 文件來實現,該文件中的每一位對應一個 CPU 核心,通過設置相應位的值為 1,即可將中斷綁定到對應的核心上。例如,要將中斷號為 8 的中斷綁定到 CPU 核心 0 和核心 1 上,可以執行命令 “echo 3 > /proc/irq/8/smp_affinity”(因為 3 的二進制表示為 0011,對應 CPU 核心 0 和核心 1)。也可以使用工具如 irqbalance 來自動管理中斷親和性,irqbalance 能夠根據系統的負載情況,動態地調整中斷的分配,使中斷均勻地分布在各個 CPU 核心上,避免某個核心因中斷負載過重而導致性能下降。
6.3 中斷合并與節流
中斷合并和節流是兩種行之有效的優化技術,它們能夠有效降低中斷頻率,提升系統性能。中斷合并的原理是將多個連續的中斷請求合并為一個中斷進行處理。在網絡設備中,當有大量的網絡數據包到達時,如果每個數據包都產生一個中斷,會導致中斷頻率過高,占用大量的 CPU 資源。通過中斷合并技術,可以將多個數據包的中斷請求合并為一個,當一定數量的數據包到達或者經過一定的時間間隔后,才產生一個中斷,通知 CPU 進行處理。這樣可以減少中斷的次數,降低 CPU 的中斷處理開銷,提高系統的整體性能。
中斷節流則是通過限制中斷的產生頻率,來控制中斷對系統資源的占用。它的實現方式是在一定的時間間隔內,只允許產生一定數量的中斷。在磁盤 I/O 操作中,如果磁盤頻繁地產生中斷,會影響系統的其他任務。通過設置中斷節流,規定每 10 毫秒只允許產生一次磁盤中斷,這樣可以避免磁盤中斷過于頻繁,使 CPU 能夠更合理地分配資源,同時處理其他任務。中斷節流可以通過修改設備驅動程序或者使用系統提供的相關工具來實現,具體的設置參數需要根據系統的實際情況和應用需求進行調整。
6.4 案例分析與實踐
在某服務器應用場景中,系統面臨著高并發網絡請求的挑戰,大量的網絡中斷使得 CPU 負載居高不下,系統性能嚴重下降。通過深入分析,發現網絡中斷處理程序存在效率低下的問題,其中包含許多不必要的操作和復雜的算法,導致中斷處理時間過長。中斷親和性設置不合理,網絡中斷在各個 CPU 核心上分布不均衡,部分核心因中斷負載過重而出現性能瓶頸。
針對這些問題,采取了一系列優化措施。對網絡中斷處理程序進行了全面優化,去除了不必要的操作,簡化了算法,將一些復雜的數據處理任務推遲到中斷處理之后的工作隊列中執行,大大縮短了中斷處理時間。通過修改 /proc/irq/[中斷號]/smp_affinity 文件,將網絡中斷合理地分配到多個 CPU 核心上,實現了中斷親和性的優化,使各個核心的負載更加均衡。還啟用了中斷合并和節流機制,減少了網絡中斷的頻率,降低了 CPU 的中斷處理開銷。
經過優化后,系統性能得到了顯著提升。CPU 負載從原來的經常超過 90% 降低到了 50% 左右,網絡請求的響應時間從平均幾十毫秒縮短到了幾毫秒,系統的并發處理能力大幅提高,能夠穩定地應對高并發的網絡請求,滿足了業務的發展需求。通過這個案例可以看出,綜合運用中斷性能優化策略,能夠有效地解決系統中的中斷性能問題,提升系統的整體性能和穩定性。在實際的系統優化過程中,需要根據具體的問題和需求,有針對性地選擇和實施優化措施,不斷調整和優化,以達到最佳的性能效果。










 day_02)







)
