FlashInfer - 介紹 LLM服務加速庫 地基的一塊石頭
flyfish
大型語言模型服務中的注意力機制
大型語言模型服務(LLM Serving)迅速成為重要的工作負載。Transformer中的算子效率——尤其是矩陣乘法(GEMM)、自注意力(Self-Attention)、矩陣向量乘法(GEMV)和逐元素計算,對LLM服務的整體性能至關重要。盡管針對GEMM和GEMV的優化已廣泛開展,但在LLM服務場景中,針對自注意力的性能研究仍較為缺乏。將自注意力拆解為三個階段:預填充(prefill)、解碼(decode)和追加(append),分析這三個階段在單請求和批處理場景下的性能瓶頸,并提出應對方案。這些思路已整合到FlashInfer中——一個基于Apache 2.0許可證開源的LLM服務加速庫。
FlashInfer概述
FlashInfer由華盛頓大學、卡內基梅隆大學和OctoAI的研究人員自2023年夏季起開發,提供PyTorch API用于快速原型設計,以及無依賴的純頭文件C++ API以便集成到LLM服務系統。相較現有庫,它具備以下獨特優勢:
- 全場景注意力核:實現覆蓋LLM服務所有常見場景的高性能注意力核,包括單請求和批處理版本的預填充、解碼、追加核,支持多種鍵值緩存(KV-Cache)格式(填充張量、不規則張量、頁表)。
- 優化的共享前綴批解碼:通過級聯技術提升共享前綴批解碼性能,在長提示(32768 tokens)和大批次(256)場景下,相比基線vLLM的PageAttention實現最高可達31倍加速(詳見另一篇博客)。
- 壓縮/量化KV-Cache加速:針對分組查詢注意力(Grouped-Query Attention)、融合RoPE注意力(Fused-RoPE Attention)和量化注意力進行優化,在A100和H100上,Grouped-Query Attention相比vLLM實現最高2-3倍加速。
FlashInfer已被MLC-LLM(CUDA后端)、Punica和sglang等LLM服務系統采用。
MLC-LLM(CUDA 后端)、Punica 和 sglang 的介紹:
1. MLC-LLM(CUDA 后端)
MLC-LLM 是一個 跨平臺高性能 LLM 推理框架,核心目標是通過編譯優化技術,讓大語言模型(如 LLaMA、Mistral、Qwen 等)能夠在 多種硬件平臺(包括 CUDA GPU、ARM 芯片、Web 瀏覽器等)上高效運行。其 CUDA 后端是針對 NVIDIA GPU 的深度優化版本,具備以下特點:
編譯優化:基于 Apache TVM 編譯棧,將模型計算圖轉換為高度優化的 CUDA 內核,顯著提升推理速度。
跨平臺支持:除 CUDA 外,還支持 WebGPU(通過 WebLLM)、iPhone 等本地環境,實現“一次編譯,多端運行”。
低延遲與高吞吐量:針對在線服務場景優化,支持動態批處理和顯存管理,適合實時對話、API 推理等高并發需求。
模型兼容性:原生支持 Hugging Face 模型格式,兼容主流量化技術(如 GPTQ、AWQ),并在 2025 年新增對 Qwen3 等模型的支持。
企業級部署:如金融交易、智能客服等需低延遲和高吞吐的場景。
邊緣設備:在消費級 GPU(如 RTX 3060)或 ARM 芯片上實現輕量化推理。
多模態任務:與視覺模型結合,支持圖像-文本聯合生成(如 LLaMA-Vision)。
已被集成到 sglang 等框架中,用于加速復雜 LLM 程序的執行。
提供 OpenAI 兼容 API,便于快速遷移現有應用。
2. Punica
Punica 是一個 開源的 LLM 多模型服務框架,專為 LoRA 微調模型設計,旨在簡化多模型部署和調用流程。其核心目標是為多個經過 LoRA 技術微調的模型提供 統一的 API 接口,降低企業級應用的開發成本。
多模型管理:支持同時加載和服務多個 LoRA 微調模型,動態切換推理配置。
性能優化:通過顯存復用和計算圖優化,提升多模型并行推理的效率,尤其適用于需頻繁切換模型的場景(如 A/B 測試)。
低代碼集成:提供 Python API 和 RESTful 接口,開發者可快速將多個微調模型整合到現有系統中。
兼容性:支持主流 LoRA 工具(如 Hugging Face PEFT),并與 vLLM、MLC-LLM 等框架協同工作。
垂直領域定制:在金融、醫療等領域,同時部署多個針對不同任務的 LoRA 模型(如情感分析、實體識別)。
模型迭代管理:通過 Punica 統一管理模型版本,無縫切換新舊版本,減少運維復雜度。
輕量級部署:適用于中小型企業,無需復雜分布式架構即可實現多模型服務。
目前主要聚焦于 LoRA 模型,對其他微調技術(如 IA3、QLoRA)的支持有限。
高并發場景下的吞吐量優化仍依賴底層框架(如 vLLM)的支持。
3. sglang
sglang 是一個 結構化語言模型程序執行框架,專為復雜 LLM 任務設計,通過 前端 DSL 和后端優化的協同設計,顯著提升多輪對話、邏輯推理、多模態交互等場景的效率。
前端 DSL:嵌入 Python 的領域特定語言,提供 gen(生成)、select(選擇)、fork(并行)等原語,簡化多調用工作流的編程復雜度。例如,可直接在代碼中定義 JSON 約束、多分支邏輯,避免手動處理字符串和 API 調用。
后端運行時優化:
RadixAttention:通過基數樹結構自動復用 KV 緩存,減少冗余計算。例如,在多輪對話中,共享前綴的 KV 緩存可被自動識別并復用,吞吐量最高提升 6.4 倍。
壓縮有限狀態機:加速結構化輸出解碼(如 JSON),一次解碼多個 token,降低延遲。
多模態支持:原生集成視覺模型(如 BLIP-2),支持圖像-文本聯合生成。
高性能推理:在 NVIDIA A100/H100 上,相比 vLLM 實現 2-5 倍吞吐量提升,尤其適合高并發結構化查詢(如金融數據解析、醫療報告生成)。
復雜任務流程:代理控制、思維鏈推理、檢索增強生成(RAG)等需多步驟交互的場景。
結構化輸出需求:如 JSON 生成、表格提取,通過約束解碼保證輸出格式合規。
多模態交互:同時處理圖像和文本數據,適用于工業質檢、智能教育等領域。
與 FlashInfer 深度集成,優化量化 KV 緩存和 RoPE 融合的推理性能。
兼容 OpenAI API,支持無縫遷移現有應用。
對比
| 框架 | 核心定位 | 技術亮點 | 典型場景 |
|---|---|---|---|
| MLC-LLM | 跨平臺推理引擎 | 編譯優化、多硬件支持、低延遲 | 企業級部署、邊緣設備、多模態 |
| Punica | 多模型服務框架(LoRA 專用) | 統一 API、顯存復用、低代碼集成 | 垂直領域定制、模型迭代管理 |
| sglang | 結構化 LLM 程序執行框架 | 前端 DSL、RadixAttention、多模態支持 | 復雜任務流程、高并發結構化查詢 |
LLM服務中的注意力階段
LLM服務包含三個通用階段:
- 預填充(Prefill):注意力在KV-Cache與所有查詢之間計算,填充完整的注意力圖(受因果掩碼約束)。
- 解碼(Decode):模型逐token生成,僅在KV-Cache與單個查詢間計算注意力,每次填充注意力圖的一行。
- 追加(Append):在KV-Cache與新追加的token查詢間計算注意力,形成梯形區域的注意力圖。該階段在推測解碼中尤為重要——草稿模型生成候選token序列后,大模型通過追加注意力計算決定是否接受,同時將候選token添加到KV-Cache。
影響注意力計算效率的關鍵因素是查詢長度( l q l_q lq?),它決定了操作是計算密集型還是IO密集型。注意力的操作強度(每字節內存流量的操作數)為 O ( 1 1 / l q + 1 / l k v ) O\left(\frac{1}{1/l_q + 1/l_{kv}} \right) O(1/lq?+1/lkv?1?),其中 l k v l_{kv} lkv?為KV-Cache長度:
- 解碼階段: l q = 1 l_q=1 lq?=1,操作強度接近 O ( 1 ) O(1) O(1),完全受限于GPU內存帶寬(IO密集型)。
- 預填充/追加階段:操作強度約為 O ( l q ) O(l_q) O(lq?),當 l q l_q lq?較大時為計算密集型,較小時為IO密集型。
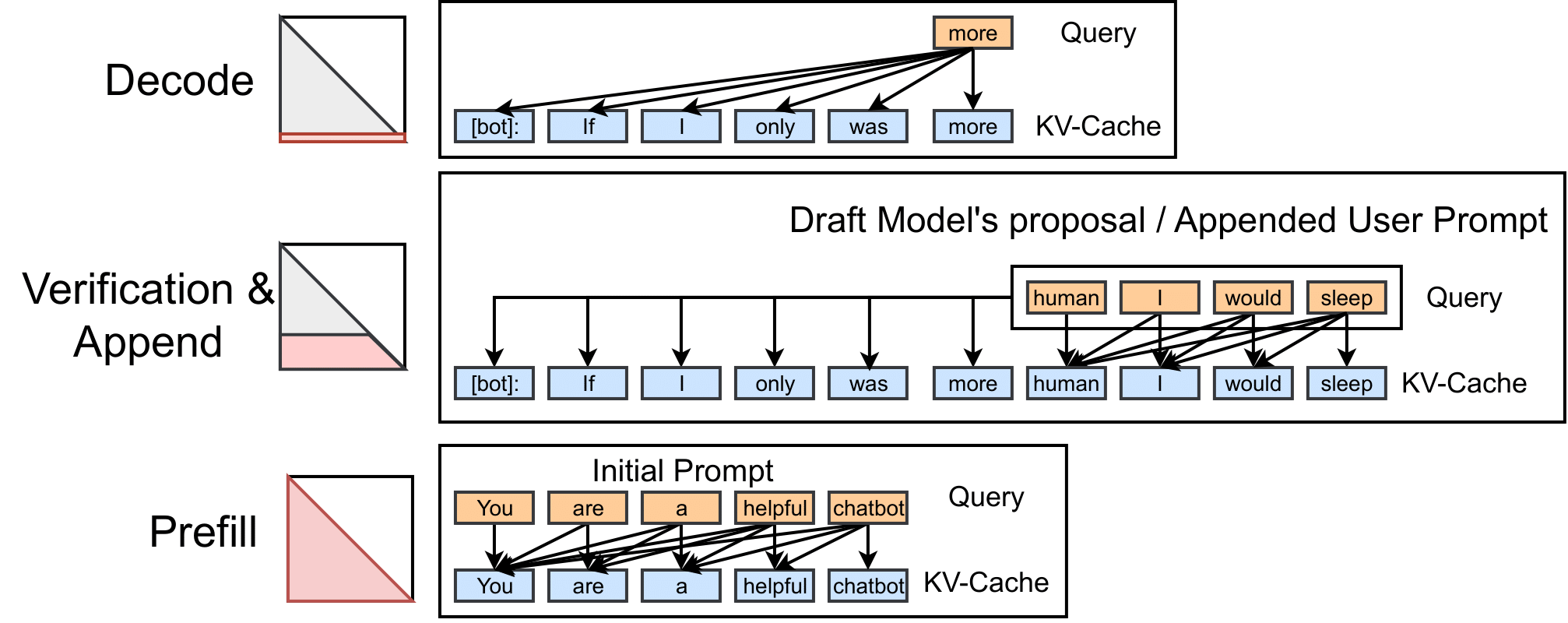
(圖1:注意力計算示意圖。解碼注意力每次填充一行,預填充填充完整注意力圖,追加填充梯形區域。)

圖2:注意力算子的屋頂線模型(數據來自A100 PCIe 80GB)。解碼注意力受限于峰值帶寬(IO瓶頸),預填充受限于峰值計算性能(計算瓶頸),追加注意力在短查詢時為IO密集型,長查詢時為計算密集型。)
單請求與批處理服務
LLM服務主要有兩種模式:
- 批處理:將多個用戶請求合并并行處理以提升吞吐量,但注意力核的操作強度與批大小無關——批解碼注意力的操作強度仍為 O ( 1 ) O(1) O(1),仍受限于IO。
- 單請求:直接處理單個用戶請求,需針對低操作強度場景(如解碼階段)優化內存訪問效率。
FlashInfer的核心優化
FlashInfer在以下方面實現創新,支持多階段、多KV-Cache格式的高效注意力計算:
1. 全場景注意力核支持
- 實現單請求/批處理版本的FlashAttention,覆蓋預填充、解碼、追加三個階段,支持不規則張量、頁表等KV-Cache格式。
- 針對頁表KV-Cache實現預填充/追加核(現有庫未支持),適用于推測解碼等復雜場景。
2. 壓縮/量化KV-Cache優化
- 分組查詢注意力(GQA):通過減少鍵值頭數降低內存流量,操作強度隨查詢頭數與鍵值頭數的比值提升。FlashInfer利用預填充核(張量核心)優化GQA的解碼階段,在A100/H100上相比vLLM實現2-3倍加速。
- 融合RoPE注意力:針對需動態修剪KV-Cache的場景(如StreamingLLM),將RoPE位置編碼融合到注意力核中,直接在計算時動態應用,避免修剪后舊編碼失效的問題,開銷可忽略。
- 量化注意力:支持4位/8位低精度核,壓縮比接近線性加速(4位約4倍,8位約2倍),平衡精度與效率。
3. 頁表KV-Cache優化
針對LightLLM、sglang等系統采用的單頁大小頁表結構,FlashInfer通過在GPU共享內存預取頁索引,消除頁大小對核性能的影響,提升復雜場景下的緩存管理效率。
底層優化基石
1. 技術互補:分層協作的技術棧
FlashInfer:底層優化基石
- 定位:提供高性能的 GPU 注意力內核(如 FlashAttention、PageAttention、量化注意力等),專注于自注意力計算的底層優化。
- 角色:作為基礎庫被 vLLM 和 sglang 集成,為兩者提供核心計算能力。例如:
vLLM 的 PageAttention 內核部分依賴 FlashInfer 的優化技術。
sglang 直接復用 FlashInfer 的 CUDA 內核,結合自身 RadixAttention 技術實現 KV 緩存高效重用。
針對量化、壓縮 KV 緩存(如 Grouped-Query Attention、Fused-RoPE)的優化,顯著提升推理效率,尤其在 A100/H100 等 GPU 上實現 2-3 倍加速。
vLLM:高性能批處理引擎
- 定位:專注于高吞吐量的批處理推理,通過 PagedAttention 技術優化內存管理,適用于單輪生成場景(如 API 服務)。
- 與 FlashInfer 的關系:
- 技術依賴:部分優化(如 GQA)可能采用 FlashInfer 的內核,但 vLLM 仍以自主開發的 PageAttention 為核心。
- 競爭與互補:在通用批處理場景中,vLLM 的性能與 FlashInfer 優化后的 sglang 接近,但在復雜任務(如多輪對話)中,sglang 更具優勢。
sglang:復雜任務執行框架
- 定位:通過前端 DSL 和后端優化(如 RadixAttention、壓縮有限狀態機),支持多輪對話、結構化輸出(如 JSON)、多模態交互等復雜任務。
- 與 FlashInfer 的關系:
- 深度集成:直接調用 FlashInfer 的注意力內核,結合自身調度器實現更高吞吐量。
- 場景擴展:利用 FlashInfer 的量化和壓縮優化,支持更高效的 KV 緩存管理,尤其在推測解碼等場景中表現突出。
- 與 vLLM 的關系:
- 技術繼承:sglang 團隊部分成員來自 vLLM 原班人馬,繼承了 vLLM 的部分設計思想(如動態批處理),但更專注于復雜任務的優化。
- 場景分工:vLLM 適合高吞吐單輪推理,sglang 擅長多輪對話和結構化輸出,兩者在不同場景下形成互補。
底層優化關鍵方向
在系統、框架或軟件棧中,為上層功能提供核心性能支撐的基礎優化技術或組件。這些底層技術是整個架構的“根基”,其設計和實現直接決定了上層應用的效率、穩定性和可擴展性。
這些底層技術看似不直接面向用戶,但卻是上層框架實現高性能的前提:
無底層優化,則上層功能無法高效落地*:例如,若沒有高效的Decode核函數,即使上層支持千萬級Token處理,單Token生成延遲也會極高;
跨框架通用性*:底層優化(如內存管理、硬件適配)可被多個上層框架復用。
例如FlashInfer中的“核心組件*:針對三種注意力階段的專用核函數、KV-Cache格式無關的優化、量化/分組注意力的高效實現;為上層LLM Serving系統提供“高性能引擎”,使其能在復雜場景(如推測解碼、動態Token處理)下保持低延遲和高吞吐量。
底層優化主要指以下關鍵方向
1. 核心計算原語的優化
- 注意力機制(Self-Attention)的高效實現:如將注意力分解為Prefill、Decode、Append三個階段,針對每個階段的計算特性(計算密集型 vs. IO密集型)設計專用核函數(Kernel)。例如:
- Decode階段(單Query)因計算量小,優化重點是減少內存訪問開銷(IO-bound);
- Prefill階段(批量Query)則利用GPU張量核心(Tensor Core)加速矩陣運算(計算密集型)。
- 基礎線性代數操作(GEMM/GEMV)的優化:這些操作是Transformer的核心,底層優化(如融合計算、數據布局調整)直接影響整體吞吐量。
2. 內存與數據管理優化
- KV-Cache格式適配:支持多種KV-Cache格式(Padded Tensor、Ragged Tensor、Page Table),針對不同場景(如稀疏解碼、動態Token處理)優化內存訪問模式,減少碎片和帶寬浪費。
- 量化與壓縮技術:如4-bit/8-bit量化KV-Cache,在降低內存占用的同時保持計算效率,是底層優化的關鍵手段(如FlashInfer的量化注意力核函數)。
3. 硬件特性適配
- GPU專用優化:針對A100/H100等GPU的架構特性(如低非張量核心性能、高帶寬內存)設計算法,例如:
- 利用張量核心加速Grouped-Query Attention(GQA),避免傳統實現的計算瓶頸;
- 預取頁索引到共享內存,優化PageAttention的訪存效率。
4. 基礎架構與算法創新
- 融合技術:如將RoPE位置編碼融合到注意力核函數中(Fused-RoPE),避免中間數據讀寫開銷;
- 批處理策略:優化共享前綴批解碼(Cascading Batch Decoding),提升長序列場景下的并行效率。

)
















)
