3.4.1 什么是Code Call Graph(CCG)
Code Call Graph(CCG)即業務代碼中的調用關系圖,是通過靜態分析手段分析并構建出的一種描述代碼間關系的圖。根據精度不同,一般分為類級別、方法級別、控制流級別,本文重點在方法級別上。
我們以一段代碼進行舉例:
class A {public void funA1() {funA2();C c = new C();c.funC1();}public void funA2() {B b = new B();b.funB1();}
}class B {public void funB1() {funB2();}public void funB2() {if (randN(10) < 5) {Logger.log("Hello B2");} else {funB2()}}
}class C {public void funC1() {B b = new B();b.funB2();}
}如上代碼所構建出的方法級別的CCG是這樣的:
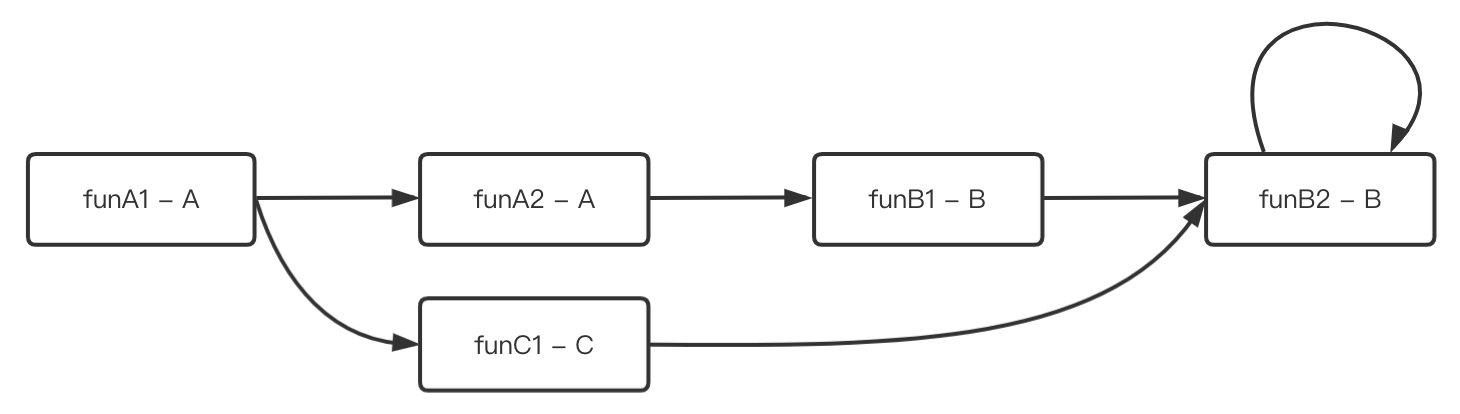
1,CCG的作用主要有兩個:
假設當我們出現一個需求改動到
1,funB1該方法時,我們可以從該圖上進行逆向查找,找到所有直接調用或者間接調用該方法的所有方法A2,A1,這個代表對B2的改動,會影響到A2,A1,{B1, A2, A1}即方法B2的代碼影響域。
2,在單元測試場景下,如果某個測試用例
testX是針對funC1的測試,那么我們可以從該方法上進行正向查找,找到所有它直接調用或者間接調用的方法B2,這個代表,我的測試用例testX的執行后可以測試到方法C1, B2,{B2, C1}即用例testX的關聯代碼。
2,CCG的應用場景
除了可以應用在精準測試場景下之外,還能在如下場景應用:
1,app啟動或頁面啟動場景下的性能分析與性能優化:當我們要進行某個場景下的耗時優化時,我們可以從幾個核心入口函數如android的下的application.onCreate(),application.onBaseContextAttached()的方法作為起點,查找后續調用方法,獲知在整個啟動流程里,哪些方法通過什么方式被執行了,幫助判斷這種執行是否是啟動場景下必須執行的任務。
2,組件化解耦:當我們需要判斷兩個組件間的耦合關系時,我們可以以其中一個組件中的方法作為起點,查找調用鏈上是否有另一個組件的方法,來尋找兩個組件間的詳細耦合關系,幫助后續進行解耦。相比傳統靜態分析方案,CCG可以更準確高效的查找出非直接依賴的隱性耦合。
3.4.2. CCG構建業界方案一覽
目前業界有一部分相對完成度比較高的開源callgraph或者AST生成方案:
Android/Java
1,soot/wala等靜態代碼分析框架:GitHub - soot-oss/soot: Soot - A Java optimization framework,soot是比較完善的靜態代碼分析框架,從能力設計上都符合我們的需求,但是soot本身是一個通用性框架,沒有專門為call graph場景去設計,比如匿名內部類,Runnable/Callable/Thread等線程類,lambda表達式,Stream調用,泛型處理等等,這些都需要我們去對soot做定制才能達到我們的需求。此外僅針對callgraph生成場景,soot設計是過復雜的,導致對于百萬級方法節點的處理性能并不足夠好。
2,java-all-call-graph: GitHub - Adrninistrator/java-all-call-graph: Generate all call graph for Java Code.,這個項目是一個比較簡單的基于class字節碼分析生成callgraph的方案,解決了soot的各種缺失能力,同時在處理性能上要優于soot。但是仍然存在一定缺陷,比如無法支持使用Redux框架進行開發的代碼,反射,廣播等場景。
iOS/Objc-c, swift
1,Drafter: GitHub - L-Zephyr/Drafter: 在iOS項目中自動生成類圖和方法調用圖 - Generate call graph in iOS project,Drafter是一個簡單的語法+詞法分析器,由于不帶語義信息,只能支持單個類下的call graph生成,不符合我們的需求。
2,libTooling:官方工具,獨立AST生成工具,libTooling可以生成一個完整的帶語義分析的AST,我們可以基于該AST來生成所需的call graph,但是libTooling的性能非常差(需要為每個文件或者模塊生成編譯參數,并且無法應用各種編譯優化),在全量情況下快手app的call graph生成耗時達到數小時,增量情況下一個500行文件的生成耗時達到幾十秒,對于大型mr無法承受。
3,Clang Plugin:官方工具,集成進編譯流程中的AST生成插件,clang plugin方案通過集成在編譯流程里,目標產物為語義AST,由于可集成在編譯流程中,我們可以復用包括gundum在內的各種編譯優化手段,在增量情況下每個文件的生成耗時可以降到秒級,全量情況下為十幾分鐘。但是clang plugin只能支持oc代碼,并且我們無法直接將打包集群的編譯環境替換掉,因此我們需要在clang plugin基礎上搞定swift/c++/c的支持,以及跨語言構建問題。同樣的,我們還需要支持泛型、代理、redux、廣播、KVO、oc runtime等特殊場景。
3.4.3 現在的CCG整體架構
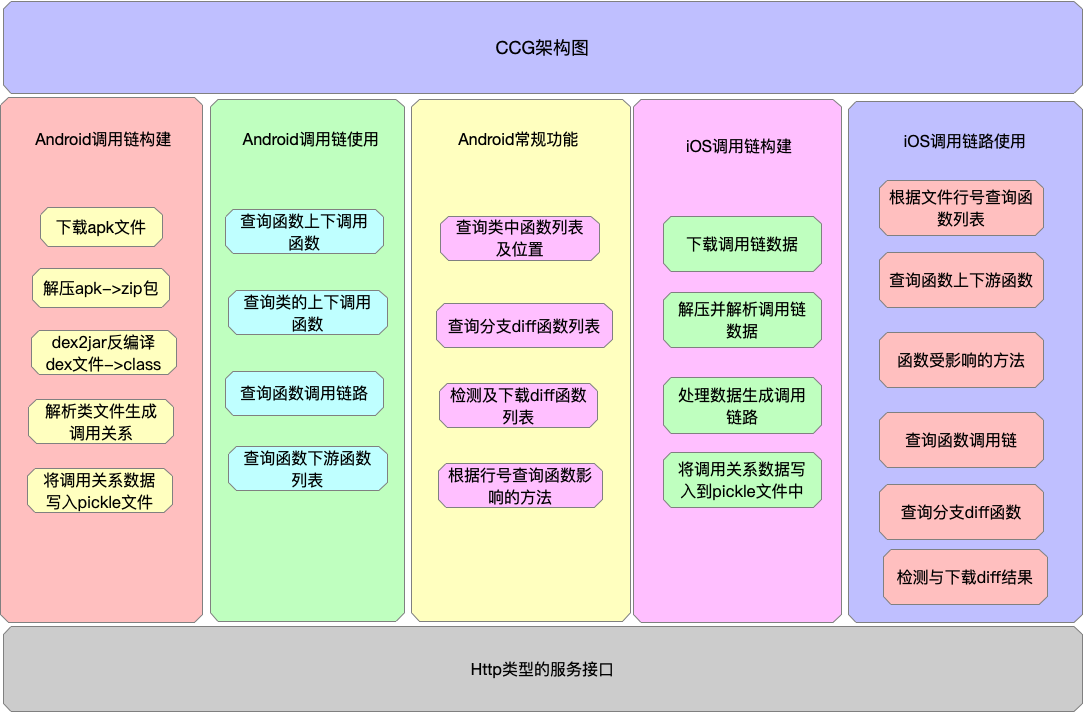
CCG服務提供了Android,IOS調用釧的生成,序列化保存,查詢等相關功能,以及對git diff獲取diff函數的相關功能和接口。
3.4.4 . 流水線上CCG服務構建與更新流程
隨著代碼的改動,CCG需要同步更新,因此CCG服務需要與流水線深度關聯。CCG服務主要分為3個階段:
1,全量構建階段
CCG全量構建基于定時觸發,每隔固定時間(目前為24小時),CCG服務平臺會觸發一次雙端全源碼包構建請求,完成一次全量CCG構建,流程如下
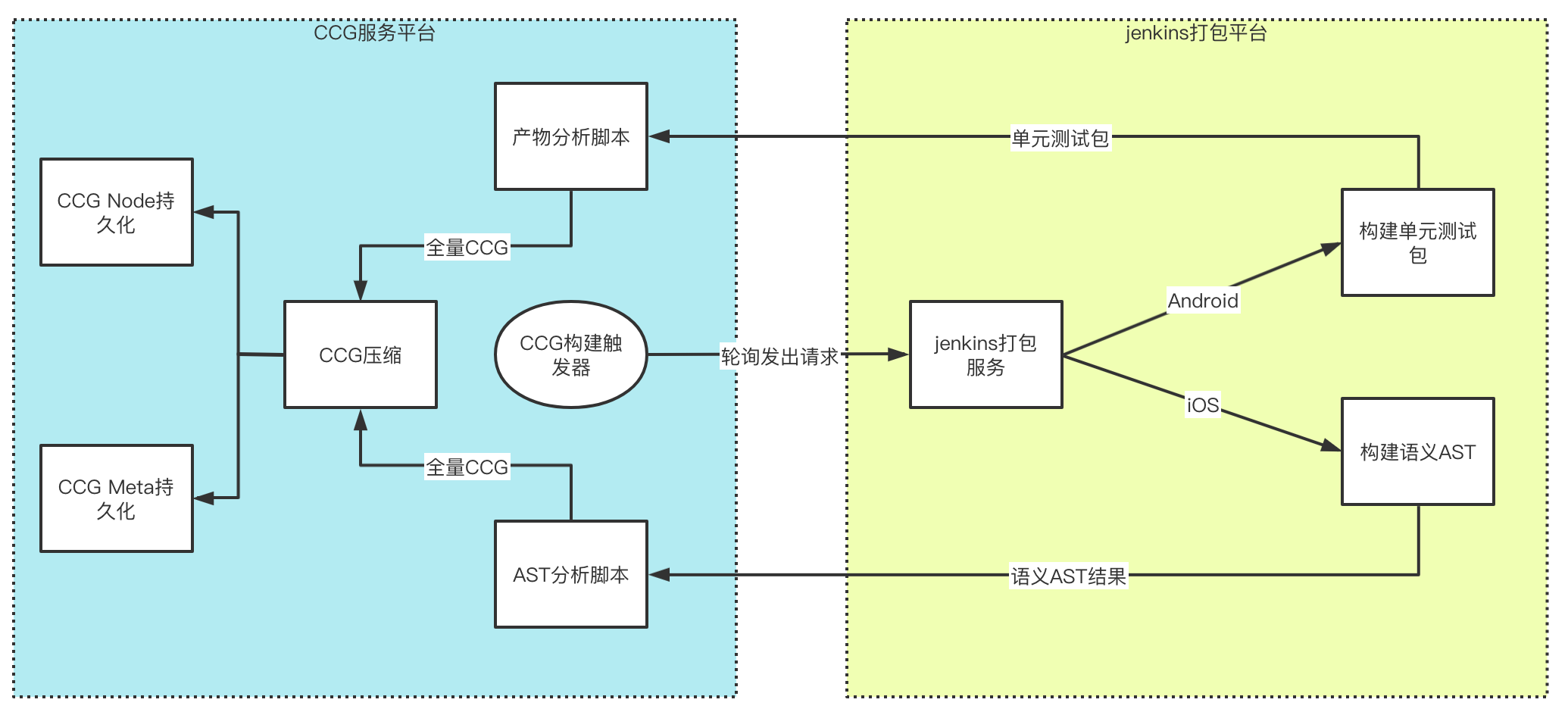
如前文提到,CCG構建時需要使用特定jenkins腳本構建相關產物,獲得產物后通過相關分析腳本得到完整版CCG:
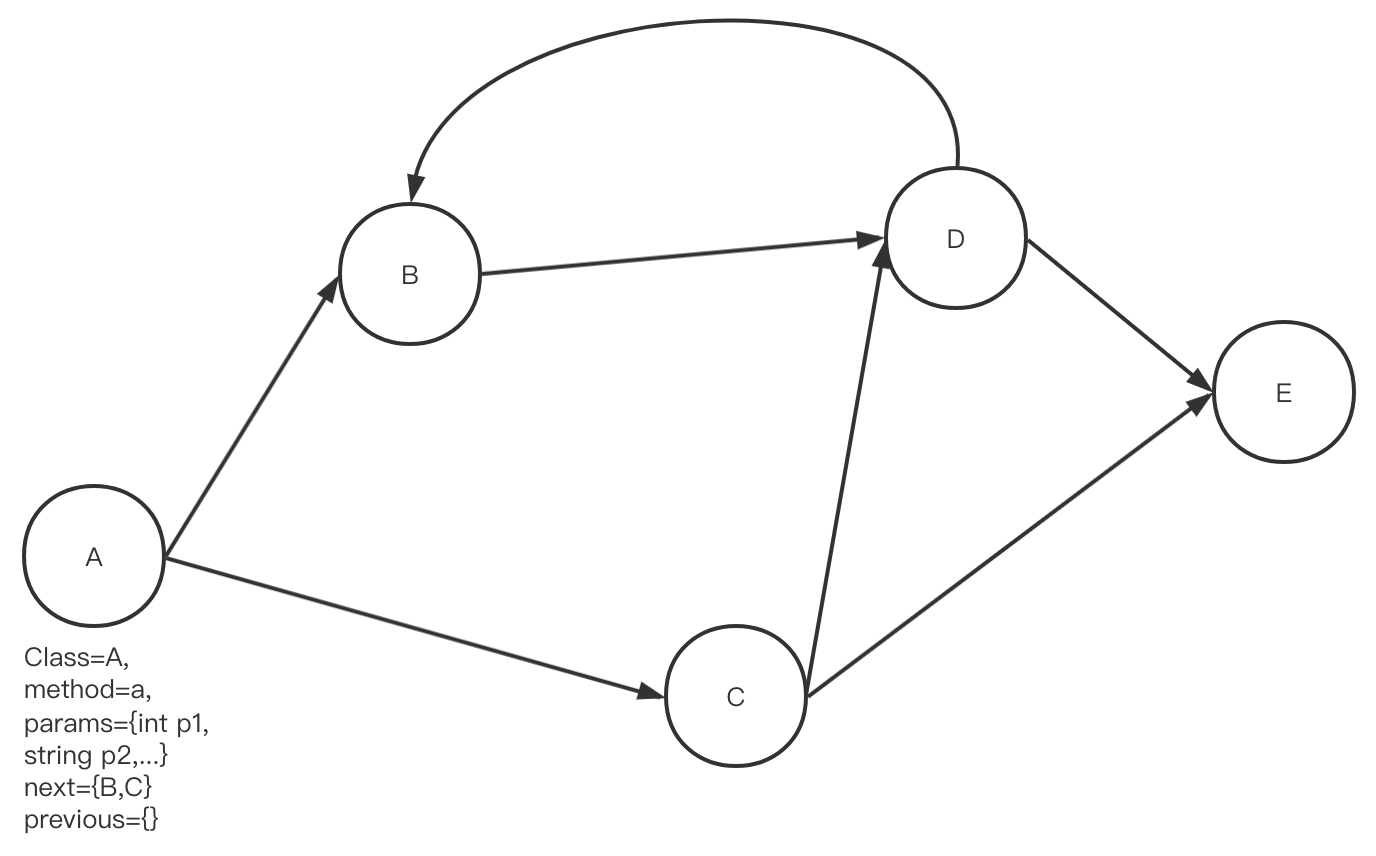
生成出的完整版本CCG大概長上面這個樣子,每個節點代表一個方法,我們需要存儲該方法本身信息,其所屬函數、參數列表,指向的前序與后序方法節點。對于一個超大型應用而言,我們可能有幾百萬個方法節點,這種存儲方式最后得到的CCG產物十分龐大,內存占用達到幾GB,顯然這對內存、磁盤甚至CPU都是很大的負擔(一個CCG服務器上需要同時維護多份CCG)。
因此我們在構建出全量CCG后,引入了CCG壓縮流程,壓縮后的CCG會被分成兩部分:CCG-Node Map,CCG-Meta DB。壓縮后的每個節點上只存儲了該Node的hash值,并以此hash值作為key,構建meta DB,存儲詳細信息。在后續查詢時,我們從Node Map中拿到對應的hash list后再從數據庫中做一次sql查詢,即可得到完整信息。這種方案也有利于獲取擴展更多的節點信息,比如我們要增加線上用戶熱度圖(見5.5)信息時,只需要在meta DB中插入即可。
全量構建完成的CCG我們稱之為Base CCG,會以commitID作為版本號進行持久化。
2. 更新階段
由于每個mr提交后都會改變局部CCG,因此我們需要引入實時CCG更新方案。我們選擇引入git webhook監聽所有mr merge操作,當一個mr合并入主分支后(dev分支),會觸發CCG更新機制。整個更新機制分成兩種平臺,四種場景:
Android(復用產物分析)
場景1. 如果mr有新增/更新/刪除單元測試case,一定會觸發單元測試節點,此時我們根據mr diff與已經打好的單元測試包做一次增量分析,得到增量CCG
場景2. 如果mr沒有相關單元測試case改動,我們根據mr diff與已經打好的編譯檢查包做一次增量分析,得到增量CCG
場景3. 如果因為各種原因沒有匹配的編譯檢查包,我們需要觸發一次jenkins debug包打包,再結合mr diff進行增量分析,得到增量CCG
iOS(無法使用產物結果,需要重新進行語義AST分析)
場景1. iOS場景下,在mr merge觸發后,會直接觸發jenkins打包服務,構建語義AST,與全量構建場景不同的是,這種場景下只會觸發增量編譯,因此語義AST構建只針對mr diff中的增量文件進行觸發(目前主站增量編譯是pod級緩存,AST構建也是pod級,當文件級緩存上線后,AST構建也將變成文件級)。
增量更新的CCG我們稱之為Diff CCG,以mrId + 最新commitId作為索引值持久化,該CCG唯一綁定某個版本的Base CCG(取決于基于哪個base版本進行的diff),并存儲指向對應版本的Base CCG的文件指針。
Diff CCG尋找綁定Base CCG的算法可以簡化描述為:從提交mr對應的開發分支上向前尋找到最近的與dev分支的共同祖先節點,以這個節點commitId作為基準值,再向前尋找最鄰近的關聯有Base CCG的commitId,該Base CCG即目標CCG。
Question1. 為什么可以使用開發分支上的編譯產物獲取增量CCG并合入dev分支后的CCG?
事實上CCG的merge操作和git代碼的merge操作是類似的,由于開發分支合并入dev分支時,代碼層面一定不存在沖突,因此我們可以保證CCG merge時也不存在沖突。
另一方面對于代碼層面的merge,最終可以歸類為三種情況:add method,change method,delete method。這幾種情況,反應到CCG上對應于添加一個方法節點,修改某個方法節點的出邊,刪除一個方法節點,可以實現一一對應。
因此我們在開發分支上獲得增量CCG可以與當前mr的diff代碼保證一一對應,merge進主干分支的CCG上時也等價于mr merge進主干分支。
Question2. 如果CCG更新太慢,后續mr所基于的dev分支代碼已經領先于最新CCG會出現什么后果?
由于指向dev分支的merge操作是保證原子時序性的(不會出現兩個merge操作并發執行),因此我們對于git merge的webhook也是時序性,在CCG更新操作上我們采用了同步非阻塞設計,即當出現一次merge操作后,我們觸發更新操作,該更新操作會被push到執行隊列中并立刻返回,執行隊列是一個順序的任務隊列,保證前一個更新任務完全完成后,后一個才會執行。
當出現一個查詢任務時,如果該查詢任務所基于dev分支節點的CCG還未更新完成,為了避免阻塞等待,我們會使用最鄰近CCG進行查詢,這會帶來一定程度的誤差(事實上這種誤差可以忽略,大多數情況下不會存在兩個mr在很短的時間內去更新同一個功能模塊)。
3,查詢階段
用戶提交mr后,會通過流水線觸發代碼影響域查詢服務,輸入為mr diff文件,輸出為受影響的方法list,以及相關權重信息。
- 查詢可以分為兩個階段:
- mr diff分析找到所有改動方法
根據改動方法,在CCG上找到所有受影響的方法
MR Diff分析
MR分析階段,我們會根據mr diff信息使用前置分析器找到變動方法,為了確保分析性能(MR分析階段需要足夠快,否則會影響整個流水線的執行速度),我們引入/自研了高性能的詞法語法分析器作為我們的前置分析器,可以非常快的構建出一棵不帶語義信息的AST。關于前置分析器的具體實現細節可見3.4、3.5節。
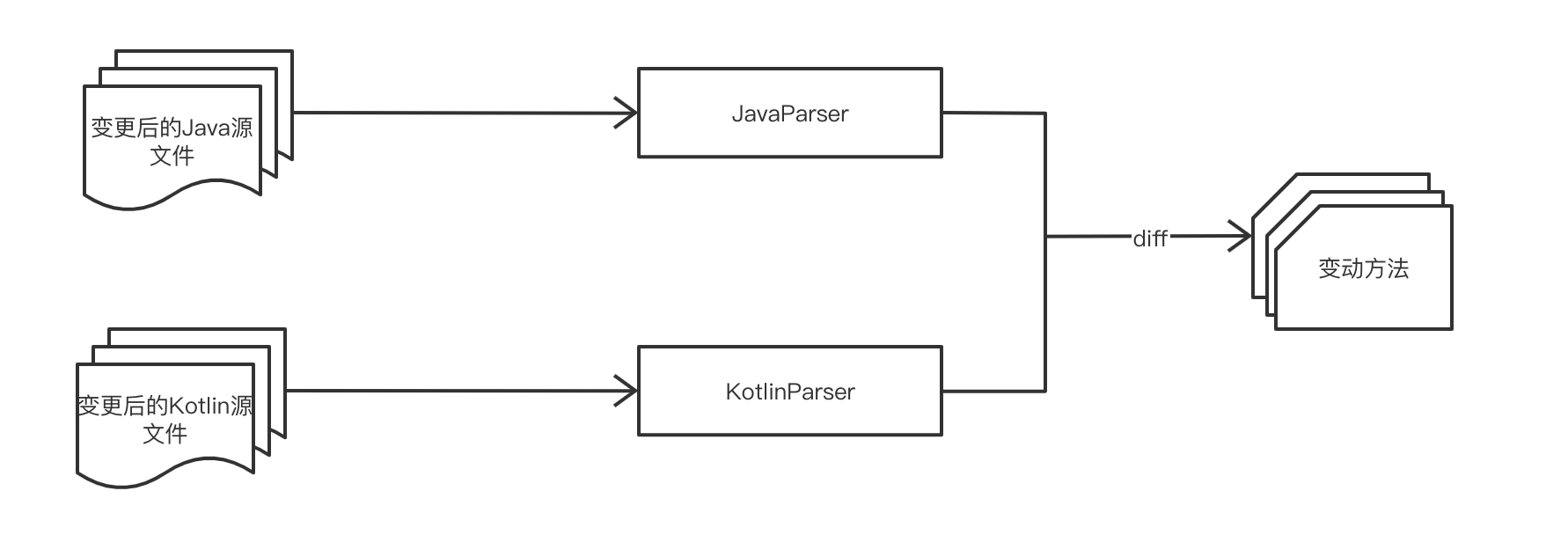
CCG查詢階段
拿到變動方法列表后,我們還無法直接進行查詢,因為在CCG平臺上存儲的是一系列Base CCG和Diff CCG,我們需要找到并構建出我們的mr所匹配的CCG。
考慮如下的一個Git分支模型:
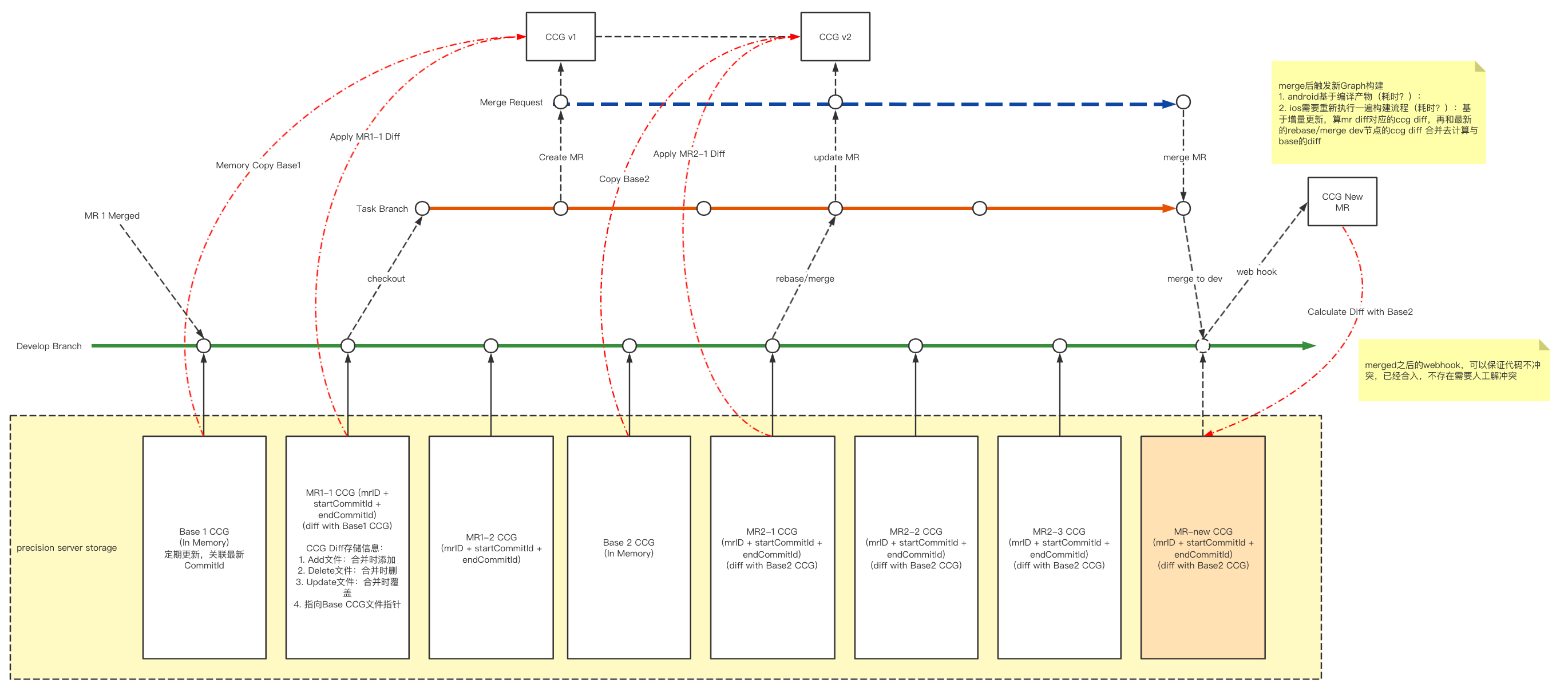
我們從Dev分支拉出Task分支后,當我們第一次提交mr到流水線上時(圖中create MR),我們的CCG服務會基于該mr的最新commit(紅色分支第二個節點)向前尋找最近一次checkout/merge/rebase Dev分支的節點(綠色第二個節點),找到該節點后,向CCG持久化服務中搜索對應的CCG圖,此時我們找到了MR1-1 CCG,這是一個Diff CCG,該Diff CCG中存儲了它依賴的Base CCG指針,然后對這兩個CCG進行一次merge操作,即得到了我們想要的CCG(即CCG v1),在該圖上即可進行后續的查詢服務。當我們后續有新的commit提交到MR上時,重復上述操作即可獲得新的CCG版本。
在具體查詢上,我們根據變動類型將查詢分為三類:
- 新增方法:新增方法不會影響其它方法,并且在沒有匹配的新增case時,該新增方法也不會存在關聯存量用例,而對于新增用例的場景,這些用例無論怎么樣都會直接推薦,因此在CCG階段直接忽略新增方法
- 刪除方法:刪除方法不會影響其它方法,也不會對測試產生影響,直接忽略
- 變更方法:變更方法是我們唯一需要進行查詢的場景,我們以變更方法作為起始節點,向前追溯該方法的所有前序節點,即可獲得對應變更方法的代碼影響域,為了提供更多信息,我們會引入更多的權重信息來輔助后續的推薦策略,在第五章中會作詳述。
至此整個CCG服務完成,作為一個單獨的服務,為整個精準測試平臺提供調用鏈路查詢和分析相關功能。





 day_02)







)





