大模型量化,剪枝
量化有助于減少顯存使用并加速推理
GPTQ 等后訓練量化方法(Post Training Quantization)是一種在訓練后對預訓練模型進行量化的方法。
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
template: llama3### export
export_dir: models/llama3_gptq
export_quantization_bit: 4
export_quantization_dataset: data/c4_demo.json
export_size: 2
export_device: cpu
export_legacy_format: false
QLoRA 是一種在 4-bit 量化模型基礎上使用 LoRA 方法進行訓練的技術。它在極大地保持了模型性能的同時大幅減少了顯存占用和推理時間。
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
finetuning_type: lora### export
export_dir: models/llama3_lora_sft
export_size: 2
export_device: cpu
export_legacy_format: false
量化7B模型,12GB顯存不夠用

增大至24G顯存就夠了
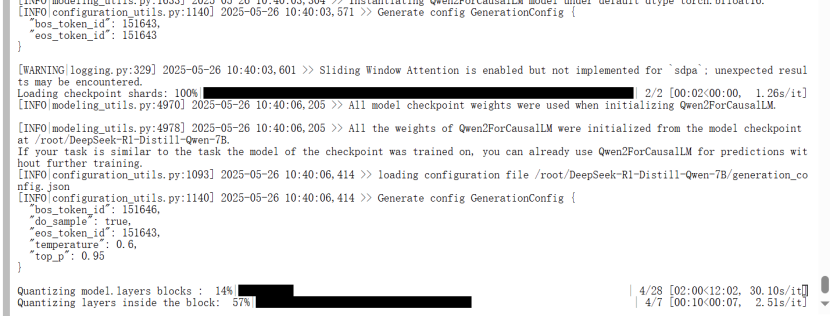
量化加載的參數更多,所以對顯存的需求更大
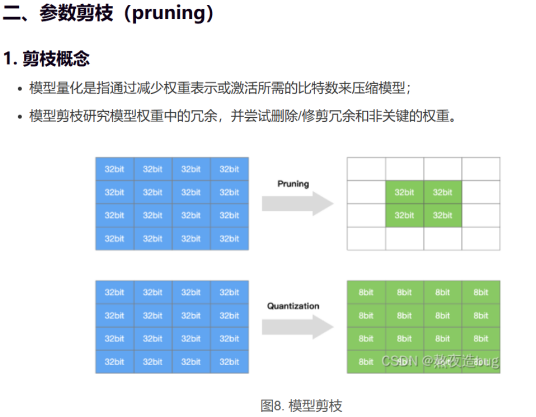
剪枝


)


)














