關鍵詞:
Uniform Manifold Approximation and Projection (UMAP):均勻流形近似與投影
一、說明
對于降維,首先看數據集是否線性,如果是線性的用pca降維;如果是非線性數據,t-SNE或者UMAP,本文針對UMAP的實驗代碼進行記錄,但沒有說UMAP的原理,原理在其它文檔論述。
二、UMAP的基本概念
2.1 首先看什么是流形
流形(manifold)是一種數學概念,它描述了在局部看起來像歐幾里得空間的拓撲空間。換句話說,流形是一個可以在局部范圍內近似為歐幾里得空間的空間。流形在幾何、拓撲學、微分幾何以及物理學中有廣泛的應用。流形的基本概念包括連續性、局部坐標轉移性和可微性,常見的例子有閉合曲面和克萊因瓶等。
一般來說,微分幾何是建立在流形理論上的,學習這方面的理論可以參照微分幾何相關書籍。
2.2 UMAP
均勻流形近似與投影 (UMAP) 是一種降維技術,類似于 t-SNE,可用于可視化,也可用于一般的非線性降維。該算法基于以下三個關于數據的假設:
數據在黎曼流形上均勻分布;
黎曼度量是局部常數(或可以近似為局部常數);
流形是局部連通的。
基于這些假設,可以用模糊拓撲結構對流形進行建模。通過尋找具有最接近等效模糊拓撲結構的數據低維投影來找到嵌入。
2.3 UMAP 安裝
在conda上安裝umap
conda install -c conda-forge umap-learn
在pip安裝
pip install umap-learn
三、基本 UMAP 參數
UMAP 是一種相當靈活的非線性降維算法。它旨在學習數據的流形結構,并找到一個能夠保留該流形基本拓撲結構的低維嵌入。在本筆記中,我們將生成一些可可視化的四維數據,演示如何使用 UMAP 提供其二維表示,然后研究各種 UMAP 參數如何影響最終的嵌入。本文檔基于 Philippe Rivière 為 visionscarto.net 撰寫的研究成果。
首先,我們需要一些基礎庫。首先numpy,我們需要 來進行基本的數組操作。由于我們要可視化結果,因此需要matplotlib和seaborn。最后,我們需要 umap來進行維度縮減本身。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import seaborn as sns
import umap
%matplotlib inline
sns.set(style='white', context='poster', rc={'figure.figsize':(14,10)})
接下來,我們需要一些數據來嵌入到低維表示中。為了使四維數據“可視化”,我們將從一個四維立方體中均勻隨機地生成數據,以便我們可以將樣本解釋為指定顏色(和透明度)的 (R,G,B,a) 值的元組。這樣,當我們繪制低維表示時,每個點都可以根據其四維值進行著色。為此,我們可以使用numpy。為了保持一致性,我們將固定一個隨機種子。
np.random.seed(42)
data = np.random.rand(800, 4)
現在我們需要找到數據的低維表示。正如基礎用法文檔中所述,我們可以通過 在對象fit_transform()上使用方法來做到這一點UMAP。
fit = umap.UMAP()
%time u = fit.fit_transform(data)
CPU times: user 7.73 s, sys: 211 ms, total: 7.94 s
Wall time: 6.8 s
結果值u是數據的二維表示。我們可以用matplotlib繪制散點圖來可視化結果u。我們可以使用源數據中關聯的四維顏色為散點圖的每個點著色。
plt.scatter(u[:,0], u[:,1], c=data)
plt.title('UMAP embedding of random colours');

正如你所見,結果是數據被放置在二維空間中,使得四維空間中相鄰的點(即顏色相似的點)保持緊密相連。由于我們在顏色立方體中隨機抽取了一些點,因此在顏色空間中,這些隨機點恰好聚集在一起,從而產生了一定程度的誘導結構。
UMAP 有幾個超參數會對最終的嵌入產生重大影響。在本筆記中,我們將介紹其中四個主要參數:
n_neighbors
min_dist
n_components
metric
每個參數都有不同的效果,我們將依次進行討論。為了簡化探索,我們首先編寫一個簡短的效用函數,該函數可以在給定一組參數選擇的情況下使用 UMAP 擬合數據,并繪制結果圖。
def draw_umap(n_neighbors=15, min_dist=0.1, n_components=2, metric='euclidean', title=''):fit = umap.UMAP(n_neighbors=n_neighbors,min_dist=min_dist,n_components=n_components,metric=metric)u = fit.fit_transform(data);fig = plt.figure()if n_components == 1:ax = fig.add_subplot(111)ax.scatter(u[:,0], range(len(u)), c=data)if n_components == 2:ax = fig.add_subplot(111)ax.scatter(u[:,0], u[:,1], c=data)if n_components == 3:ax = fig.add_subplot(111, projection='3d')ax.scatter(u[:,0], u[:,1], u[:,2], c=data, s=100)plt.title(title, fontsize=18)- n_neighbors
此參數控制 UMAP 如何平衡數據的局部結構與全局結構。它通過限制 UMAP 在嘗試學習數據流形結構時所關注的局部鄰域的大小來實現這一點。這意味著,較低的 值n_neighbors 將迫使 UMAP 專注于非常局部的結構(可能會損害全局);而較大的 值將迫使 UMAP 在估計數據的流形結構時關注每個點的更大鄰域,從而為了獲取更廣泛的數據而丟失精細的細節結構。
在實踐中,我們可以通過使用一系列n_neighbors值來擬合數據集,從而看到這一點。UMAP 的默認值n_neighbors (如上所述)為 15,但我們將研究從 2(流形的局部視圖)到 200(數據的四分之一)范圍內的值。
for n in (2, 5, 10, 20, 50, 100, 200):draw_umap(n_neighbors=n, title='n_neighbors = {}'.format(n))


當值為 時,n_neighbors=2我們可以看到 UMAP 僅僅將一些小的鏈粘合在一起,但由于視角狹窄/局部,無法看到它們是如何連接的。它還留下了許多不同的組成部分(甚至是單點)。這表明,從細節的角度來看,數據在整個空間中非常不連貫且分散。
隨著n_neighborsUMAP 的增加,它能夠更好地洞察數據的整體結構,將更多組件粘合在一起,并更好地覆蓋數據的整體結構。到這個階段, n_neighbors=20我們對數據有了相當好的整體視圖,展示了各種顏色在整個數據集中是如何相互關聯的。
隨著n_neighbors數據的整體結構越來越受到關注。結果,雖然 n_neighbors=200圖中能夠很好地捕捉到整體結構(藍色、綠色和紅色;高亮度與低亮度),但卻丟失了一些更精細的局部結構(單個顏色不再必然與其最接近的顏色匹配)。
這種效果很好地體現了所提供的局部/全局權衡 n_neighbors。
- min_dist
該min_dist參數控制 UMAP 將點打包的緊密程度。它實際上規定了低維表示中允許點之間的最小距離。這意味著較低的 值min_dist將導致嵌入更加塊狀。如果您對聚類或更精細的拓撲結構感興趣,這將非常有用。較大的 值 min_dist將阻止 UMAP 將點打包在一起,而是專注于保留大致的拓撲結構。
min_dist(如上所述)的默認值為0.1。我們將查看從 0.0 到 0.99 的值范圍。
for d in (0.0, 0.1, 0.25, 0.5, 0.8, 0.99):draw_umap(min_dist=d, title='min_dist = {}'.format(d))
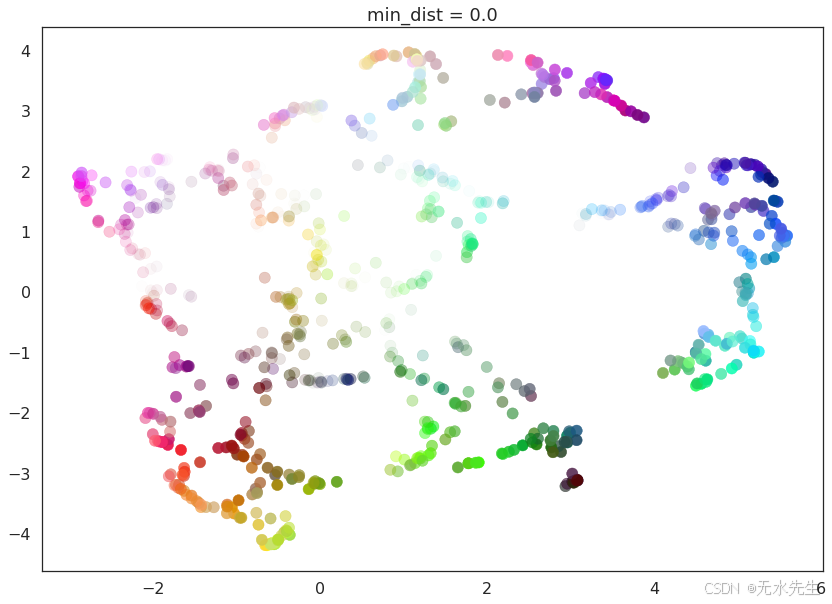


這里我們看到,min_dist=0.0UMAP 能夠找到數據中較小的連通分量、團塊和字符串,并在生成的嵌入中強調這些特征。隨著 的min_dist增加,這些結構被分解成更柔和、更通用的特征,從而在損失更詳細的拓撲結構的情況下,提供更好的數據總體視圖。
- n_components
scikit-learn與許多降維算法一樣, UMAP 提供了一個n_components參數選項,允許用戶確定我們將數據嵌入到的降維空間的維數。與其他一些可視化算法(例如 t-SNE)不同,UMAP 在嵌入維度上具有良好的擴展性,因此您不僅可以將其用于二維或三維可視化,還可以將其用于其他領域。
為了演示的目的(以便我們可以看到參數的效果),我們將只研究一維和三維嵌入,我們希望將其可視化。
首先,我們將設置n_components為 1,強制 UMAP 將數據嵌入到一條線中。為了便于可視化,我們將在 y 軸上隨機分布數據,以便在點之間提供一定的分隔。
draw_umap(n_components=1, title='n_components = 1')

現在我們來嘗試一下n_components=3。為了實現可視化,我們將利用的matplotlib基本三維繪圖。
draw_umap(n_components=3, title='n_components = 3')

在這里我們可以看到,有了更多的工作維度,UMAP 可以更輕松地以尊重數據拓撲結構的方式分離出顏色。
如上所述,實際上沒有必要止步于n_components=3。如果您對(基于密度的)聚類或其他機器學習技術感興趣,那么選擇一個更大的嵌入維度(例如 10 或 50)并使其更接近數據所在的底層流形的維度可能會有所幫助。
- metric(度量)
我們將在本筆記本中考慮的最后一個 UMAP 參數是 metric參數。它控制如何在輸入數據的環境空間中計算距離。默認情況下,UMAP 支持多種指標,包括:
閔可夫斯基風格度量
歐幾里得
曼哈頓
切比雪夫
閔可夫斯基
其他空間指標
堪培拉
布雷柯蒂斯
半正矢
規范化空間度量
馬哈拉諾比斯
明科夫斯基
塞克利德
角度和相關性指標
余弦
相關性
二進制數據的指標
漢明
雅卡德
骰子
羅素·拉奧
庫爾辛斯基
羅杰斯塔尼莫托
索卡爾米切納
索卡爾斯尼斯
圣誕節
四、預先計算
以上所有指標都假設你的輸入數據是某個 N 維空間中的“原始”數據。有時,你已經計算了點之間的成對距離,并且輸入數據是一個距離/相似度矩陣。在這種情況下,你可以執行以下操作。
UMAP(metric='precomputed').fit_transform(<distance matrix>)
其中任何一個都可以通過設置。metric=''metric='cosine’來指定;例如使用余弦距離作為您將使用的度量
然而,UMAP 提供的遠不止這些——它支持自定義用戶指標,只要這些指標能夠nopython通過 numba 編譯即可。在本筆記中,我們將研究此類自定義指標。要定義此類指標,我們需要 numba……
import numba
對于我們的第一個自定義指標,我們將距離定義為紅色通道中差異的絕對值。
@numba.njit()
def red_channel_dist(a,b):return np.abs(a[0] - b[0])
為了更具冒險精神,進行一些色彩空間轉換會很有用——為了簡單起見,我們只需使用 HSL 公式從 (R,G,B) 元組中提取色調、飽和度和亮度。
@numba.njit()
def hue(r, g, b):cmax = max(r, g, b)cmin = min(r, g, b)delta = cmax - cminif cmax == r:return ((g - b) / delta) % 6elif cmax == g:return ((b - r) / delta) + 2else:return ((r - g) / delta) + 4@numba.njit()
def lightness(r, g, b):cmax = max(r, g, b)cmin = min(r, g, b)return (cmax + cmin) / 2.0@numba.njit()
def saturation(r, g, b):cmax = max(r, g, b)cmin = min(r, g, b)chroma = cmax - cminlight = lightness(r, g, b)if light == 1:return 0else:return chroma / (1 - abs(2*light - 1))
有了這些,我們可以定義三個額外的距離。第一個簡單地測量色調的差異,第二個測量飽和度和亮度組合空間中的歐氏距離,第三個測量完整 HSL 空間中的距離。
@numba.njit()
def hue_dist(a, b):diff = (hue(a[0], a[1], a[2]) - hue(b[0], b[1], b[2])) % 6if diff < 0:return diff + 6else:return diff@numba.njit()
def sl_dist(a, b):a_sat = saturation(a[0], a[1], a[2])b_sat = saturation(b[0], b[1], b[2])a_light = lightness(a[0], a[1], a[2])b_light = lightness(b[0], b[1], b[2])return (a_sat - b_sat)**2 + (a_light - b_light)**2@numba.njit()
def hsl_dist(a, b):a_sat = saturation(a[0], a[1], a[2])b_sat = saturation(b[0], b[1], b[2])a_light = lightness(a[0], a[1], a[2])b_light = lightness(b[0], b[1], b[2])a_hue = hue(a[0], a[1], a[2])b_hue = hue(b[0], b[1], b[2])return (a_sat - b_sat)**2 + (a_light - b_light)**2 + (((a_hue - b_hue) % 6) / 6.0)
有了這些自定義指標,我們就可以讓 UMAP 使用這些指標來嵌入數據,以測量輸入數據點之間的距離。需要注意的是,這numba為我們定義距離函數提供了極大的靈活性。盡管如此,即使使用這些自定義函數,我們仍然能夠保持 UMAP 所期望的高性能。
for m in ("euclidean", red_channel_dist, sl_dist, hue_dist, hsl_dist):name = m if type(m) is str else m.__name__draw_umap(n_components=2, metric=m, title='metric = {}'.format(name))





在這里,我們可以清楚地看到這些指標的效果。純紅色通道正確地將數據視為位于一維流形上,色調指標將數據解釋為位于一個圓圈內,而 HSL 指標則根據飽和度和亮度使圓圈變胖。這合理地證明了 UMAP 在理解數據底層拓撲結構以及找到該拓撲結構的合適低維表示方面的強大功能和靈活性。


)
——合作共享——數據交流)





)

)



)



