? 在人工智能蓬勃發展的當下,人臉相關技術廣泛應用于安防、金融、娛樂等諸多領域。然而,隨著人臉合成技術的日益成熟,人臉真假檢測成為保障這些應用安全的關鍵環節。本文將深入探討基于支持向量機(SVM)結合局部二值模式(LBP)特征,以及基于 ResNet18 神經網絡的人臉真假檢測方法,并通過 Python 代碼實戰進行詳細分析與對比。
一、技術原理
(一)SVM 與 LBP 特征
? LBP 特征提取:LBP 是一種用于描述圖像局部紋理特征的算子。其基本原理是對圖像每個像素點,以其為中心,設定鄰域像素點個數(如本文中的 8 個鄰域點)和半徑(本文為 1)。將鄰域像素點的灰度值與中心像素點灰度值進行比較,大于等于中心像素點灰度值的鄰域點記為 1,小于則記為 0,這些二進制值按順時針或逆時針順序排列形成一個二進制碼,該碼就是中心像素點的 LBP 值。對整幅圖像計算 LBP 值后,通過統計不同 LBP 值出現的頻率(即直方圖),得到圖像的 LBP 特征。這種特征對光照變化具有一定的魯棒性,能有效捕捉圖像的紋理細節 。
? SVM 模型:支持向量機是一種二分類模型,旨在尋找一個最優分類超平面,使得不同類別的樣本點盡可能地遠離該超平面。在本文中,采用徑向基函數(RBF)作為核函數,它能夠將低維空間中的數據映射到高維空間,從而更好地處理非線性分類問題。利用提取的 LBP 特征訓練 SVM 模型,實現對人臉真假的分類預測。
(二)ResNet18 神經網絡
? ResNet18 架構:ResNet(殘差網絡)是深度學習領域的經典網絡結構,通過引入殘差塊解決了深度神經網絡訓練過程中的梯度消失和梯度爆炸問題,使得網絡可以訓練得更深。ResNet18 包含 18 層卷積層和全連接層,能夠自動學習圖像的高級特征。
? 模型修改與訓練:在本文中,對預訓練的 ResNet18 模型進行了修改,將最后一層全連接層的輸出特征數量調整為 1,并添加了 Sigmoid 激活函數,使其輸出為 0 到 1 之間的概率值,用于二分類任務(判斷人臉真假)。訓練過程中,使用交叉熵損失函數(BCELoss)衡量預測結果與真實標簽之間的差異,通過 Adam 優化器調整模型參數,逐步降低損失,提高模型的準確性。
二、代碼實現
(一)環境設置與庫導入
? 首先,需要導入一系列必要的庫,包括用于圖像處理的 OpenCV、NumPy、scikit - image,用于深度學習的 PyTorch 及其相關工具,以及用于數據處理和評估的 scikit - learn 等:
import os
import cv2
import numpy as np
from skimage.feature import local_binary_pattern
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
from PIL import Image
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
import random?
(二)SVM 模型實現?
? LBP 特征提取函數:extract_lbp_features函數負責讀取圖像并提取其 LBP 特征。首先將圖像轉換為灰度圖,調整大小為指定尺寸,計算 LBP 值并生成直方圖,最后對直方圖進行歸一化處理:
def extract_lbp_features(image_path, target_size=(64, 64)):try:image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)if image is None:return Noneimage = cv2.resize(image, target_size)lbp = local_binary_pattern(image, 8, 1, method='uniform')(hist, _) = np.histogram(lbp.ravel(), bins=np.arange(0, 10), range=(0, 10))hist = hist.astype("float")hist /= (hist.sum() + 1e-7)return histexcept:return None?
? 數據加載函數:load_svm_data函數從指定的真假人臉圖像文件夾中讀取圖像,提取 LBP 特征,并為每個樣本標記對應的標簽(0 表示假臉,1 表示真臉):
def load_svm_data(fake_dir, real_dir):X, y = [], []for img_name in os.listdir(fake_dir):img_path = os.path.join(fake_dir, img_name)features = extract_lbp_features(img_path)if features is not None:X.append(features)y.append(0)for img_name in os.listdir(real_dir):img_path = os.path.join(real_dir, img_name)features = extract_lbp_features(img_path)if features is not None:X.append(features)y.append(1)return np.array(X), np.array(y)?
? 模型訓練與評估函數:train_svm函數加載訓練數據和測試數據,訓練 SVM 模型,并對模型進行評估,輸出準確率和分類報告:
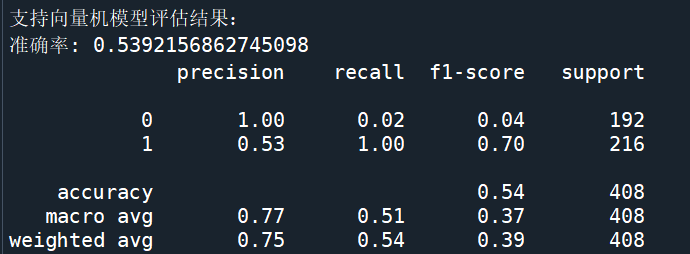
def train_svm():X_train, y_train = load_svm_data("training_fake", "training_real")X_test, y_test = load_svm_data("testing_fake", "testing_real")svm = SVC(kernel='rbf', random_state=42)svm.fit(X_train, y_train)y_pred = svm.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print("\n支持向量機模型評估結果:")print("準確率:", accuracy)print(classification_report(y_test, y_pred))return accuracy?
(三)ResNet18 模型實現?
? 自定義數據集類:FaceDataset類繼承自Dataset,用于加載真假人臉圖像數據。在初始化時,將圖像路徑和對應的標簽存儲起來,并支持數據增強操作(如隨機水平翻轉):
class FaceDataset(Dataset):def __init__(self, fake_dir, real_dir, transform=None):self.image_paths = []self.labels = []for img_name in os.listdir(fake_dir):self.image_paths.append(os.path.join(fake_dir, img_name))self.labels.append(0)for img_name in os.listdir(real_dir):self.image_paths.append(os.path.join(real_dir, img_name))self.labels.append(1)self.transform = transformdef __len__(self):return len(self.image_paths)def __getitem__(self, idx):try:image = Image.open(self.image_paths[idx]).convert("RGB")label = self.labels[idx]if self.transform:image = self.transform(image)return image, labelexcept:return None?
? ResNet18 模型定義與修改:get_resnet18函數獲取預訓練的 ResNet18 模型,并修改其最后一層全連接層和添加 Sigmoid 激活函數:
def get_resnet18():model = models.resnet18(pretrained=True)num_ftrs = model.fc.in_featuresmodel.fc = nn.Linear(num_ftrs, 1)model = nn.Sequential(model, nn.Sigmoid())return model?
? 訓練與評估函數:train_resnet18函數對數據進行預處理,創建數據集和數據加載器,初始化模型、損失函數和優化器,進行模型訓練和測試評估,并繪制訓練過程中的損失和準確率曲線:
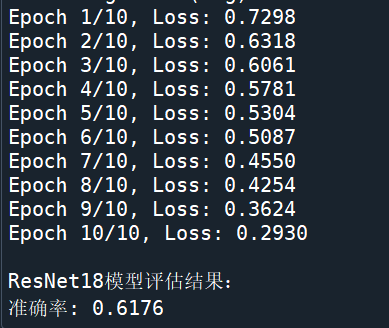
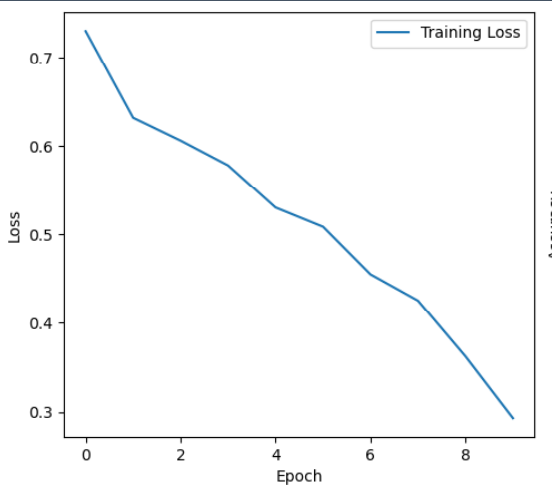
def train_resnet18():transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])def create_dataset(fake_dir, real_dir, transform):dataset = FaceDataset(fake_dir, real_dir, transform)valid_indices = [i for i in range(len(dataset)) if dataset[i] is not None]return torch.utils.data.Subset(dataset, valid_indices)train_dataset = create_dataset("training_fake", "training_real", transform)test_dataset = create_dataset("testing_fake", "testing_real", transform)train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, num_workers=4)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = get_resnet18().to(device)criterion = nn.BCELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)losses = []accuracies = []model.train()for epoch in range(10):running_loss = 0.0for images, labels in train_loader:images, labels = images.to(device), labels.float().to(device).unsqueeze(1)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()epoch_loss = running_loss / len(train_loader)losses.append(epoch_loss)print(f"Epoch {epoch + 1}/10, Loss: {epoch_loss:.4f}")model.eval()correct, total = 0, 0test_images = []test_labels = []test_predictions = []with torch.no_grad():for images, labels in test_loader:test_images.extend(images.cpu().numpy())test_labels.extend(labels.cpu().numpy())images, labels = images.to(device), labels.float().to(device).unsqueeze(1)outputs = model(images)predicted = (outputs > 0.5).float()total += labels.size(0)correct += (predicted == labels).sum().item()test_predictions.extend(predicted.cpu().numpy())accuracy = correct / totalprint("\nResNet18模型評估結果:")print(f"準確率: {accuracy:.4f}")plt.figure(figsize=(12, 5))plt.subplot(1, 2, 1)plt.plot(losses, label='Training Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.subplot(1, 2, 2)plt.plot(accuracies, label='Training Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.show()return accuracy, test_images, test_labels, test_predictions?
? 可視化隨機五張識別結果:visualize_random_five函數從測試數據中隨機選取五張圖像,展示其真實標簽和預測結果:
def visualize_random_five(test_images, test_labels, test_predictions):indices = random.sample(range(len(test_images)), 5)plt.figure(figsize=(15, 7))for i, idx in enumerate(indices):img = np.transpose(test_images[idx], (1, 2, 0))img = (img - np.min(img)) / (np.max(img) - np.min(img))label = 'Real' if test_labels[idx] == 1 else 'Fake'prediction = 'Real' if test_predictions[idx] == 1 else 'Fake'plt.subplot(1, 5, i + 1)plt.imshow(img)plt.title(f'Label: {label}\nPred: {prediction}')plt.axis('off')plt.show()?
(四)主程序入口?
? 在主程序中,依次訓練 SVM 模型和 ResNet18 模型,比較兩個模型的準確率并進行可視化,同時可視化 ResNet18 模型隨機五張測試圖像的識別結果:
if __name__ == "__main__":print("正在訓練支持向量機模型...")svm_accuracy = train_svm()print("\n正在訓練ResNet18模型...")resnet_accuracy, test_images, test_labels, test_predictions = train_resnet18()models = ['SVM', 'ResNet18']accuracies = [svm_accuracy, resnet_accuracy]plt.bar(models, accuracies)plt.xlabel('Models')plt.ylabel('Accuracy')plt.title('Model Accuracy Comparison')for i, v in enumerate(accuracies):plt.text(i, v, str(round(v, 4)), ha='center')plt.show()visualize_random_five(test_images, test_labels, test_predictions)?
三、實驗結果與分析?
?
 ?
?
 ?
?
 ?
?
?
? 從訓練過程輸出的日志來看,ResNet18 模型在 10 個訓練輪次(Epoch)中,損失(Loss)不斷下降,從 Epoch 1 的 0.7298 逐步降低到 Epoch 10 的 0.2930 ,這表明模型在訓練過程中不斷學習,對訓練數據的擬合能力逐漸增強。最終在測試集上得到的準確率為 0.6176 。
? 對比 SVM 模型與 ResNet18 模型的準確率柱狀圖,SVM 模型的準確率為 0.5392,而 ResNet18 模型的準確率為 0.6176,ResNet18 模型的準確率相對更高。這是因為 ResNet18 作為深度神經網絡,具備強大的自動特征提取能力,能夠從大量圖像數據中學習到更復雜、更具區分性的特征表示,從而在分類任務中表現更優。而 SVM 雖然在處理一些簡單特征和小規模數據時表現良好,但在面對人臉真假檢測這種復雜的圖像分類任務時,其特征表示能力相對有限,導致準確率略低。
? 觀察 ResNet18 模型訓練損失曲線,其呈現出持續下降的趨勢,說明模型在訓練過程中能夠有效優化,不斷調整參數以降低損失。但從下降的速率和幅度來看,在前期下降較快,后期下降逐漸變緩,這可能意味著模型在后期逐漸接近收斂狀態,進一步提升的難度增大。同時,由于未給出測試集上的損失或準確率隨 Epoch 的變化情況,暫時無法確定是否存在過擬合現象。不過僅從當前訓練損失持續下降且測試準確率有所提升來看,模型在一定程度上能夠泛化到測試數據,但后續仍需進一步分析驗證。
? 從這五張隨機選取的測試圖像可視化結果來看,模型在部分樣本上預測準確,但也存在誤判情況。其中,第一張、第二張和第四張圖像真實標簽為 “Real”,模型預測也為 “Real” ,說明對于這類圖像,模型能夠較好地提取特征并做出正確判斷。第五張圖像真實標簽為 “Fake”,模型預測也為 “Fake”,表明模型在識別這類假臉圖像時具備一定能力。
? 然而,第三張圖像真實標簽為 “Fake”,但模型卻預測為 “Real” ,出現了誤判。這可能是由于該假臉圖像具有一些與真臉相似的特征,或者其合成技術較為特殊,導致模型提取的特征不足以準確區分真假。通過對這類誤判樣本的深入分析,我們可以針對性地改進模型。比如,進一步挖掘該圖像中模型未能有效捕捉的特征差異,調整模型結構或訓練策略,以增強模型對這類特殊樣本的識別能力。這也再次強調了在實際應用中,不能僅依賴模型的準確率指標,還需關注模型在具體樣本上的預測表現,通過對誤判樣本的研究來不斷優化模型性能。
四、總結與展望
? 本文通過代碼實現并對比了 SVM 結合 LBP 特征與 ResNet18 神經網絡在人臉真假檢測任務中的應用。實驗結果表明,ResNet18 在準確率上優于 SVM,展現出深度神經網絡在圖像分類任務中的強大性能。SVM 結合 LBP 特征的方法雖然計算相對簡單,但在復雜圖像特征提取方面存在不足,導致準確率受限。
? 在實際應用中,對于計算資源有限、數據規模較小的場景,SVM 方法可作為一種輕量級的解決方案;而對于追求高準確率、數據量充足的場景,ResNet18 等深度神經網絡更為合適。未來可嘗試將兩者結合,比如先用 SVM 進行初步篩選,再利用 ResNet18 進行精細分類,發揮各自優勢,提升檢測性能。
? 此外,當前模型的準確率仍有提升空間。未來可從以下幾方面改進:一是進一步優化模型結構,如調整 ResNet18 的層數、參數,或嘗試其他更先進的神經網絡架構;二是擴充數據集,引入更多不同場景、光照條件、合成技術的人臉圖像,增強模型的泛化能力。
?
?
?














)

)


