ICLR 2025 spotlight
paper
構建能夠在少量樣本下學習出優良策略的深度強化學習(RL)智能體一直是一個極具挑戰性的任務。為了提高樣本效率,近期的研究嘗試在每獲取一個新樣本后執行大量的梯度更新。盡管這種高更新-數據比(UTD)策略在實證中表現良好,但它也會導致訓練過程中的不穩定性。以往方法常常依賴周期性地重置神經網絡參數以應對這種不穩定性,但在許多實際應用中,重啟訓練流程是不可行的,并且需要對重置的時間間隔進行調參。在本文中,我們關注于在有限樣本條件下實現穩定訓練所面臨的一個核心難點:學習得到的價值函數無法泛化到未觀察到的在策略動作上。我們通過引入由學習到的世界模型生成的少量數據,直接緩解了這一問題。我們提出的方法——用于時序差分學習的模型增強數據(Model-Augmented Data for Temporal Difference learning,簡稱 MAD-TD)——利用少量生成數據來穩定高 UTD 的訓練過程,并在 DeepMind 控制套件中最具挑戰性的任務上取得了有競爭力的性能。我們的實驗進一步強調了使用優質模型生成數據的重要性,MAD-TD 抗擊價值函數高估的能力,以及其在持續學習中帶來的實際穩定性提升。
MAD-TD基于TD3算法,并對參數采用UTD=8的默認更新。對critic的采用DYNA架構下的real-data以及simulate-data以5%混合比例采樣。
其中模型采用類似TD-MPC2,需要訓練encoder對狀態進行表征;對critic采用HL-Gauss (上一篇《Stop regressing: Training value functions via classification for scalable deep RL》);世界模型根據給定的encoder后的狀態和動作 a 預測下一狀態的潛在表示和觀察到的獎勵。模型訓練損失有三個項:編碼下一狀態的 SimNorm 表征的交叉熵損失、獎勵預測的 MSE 以及下一狀態critic估計與預測狀態的critic估計之間的交叉熵。
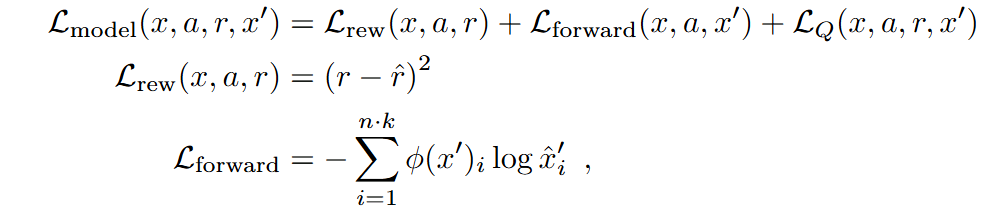
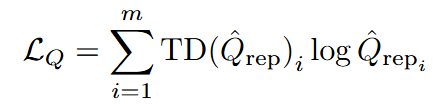
算法核心在基于模型的數據的合成,后面也對比了基于Diffusion-model的方法:
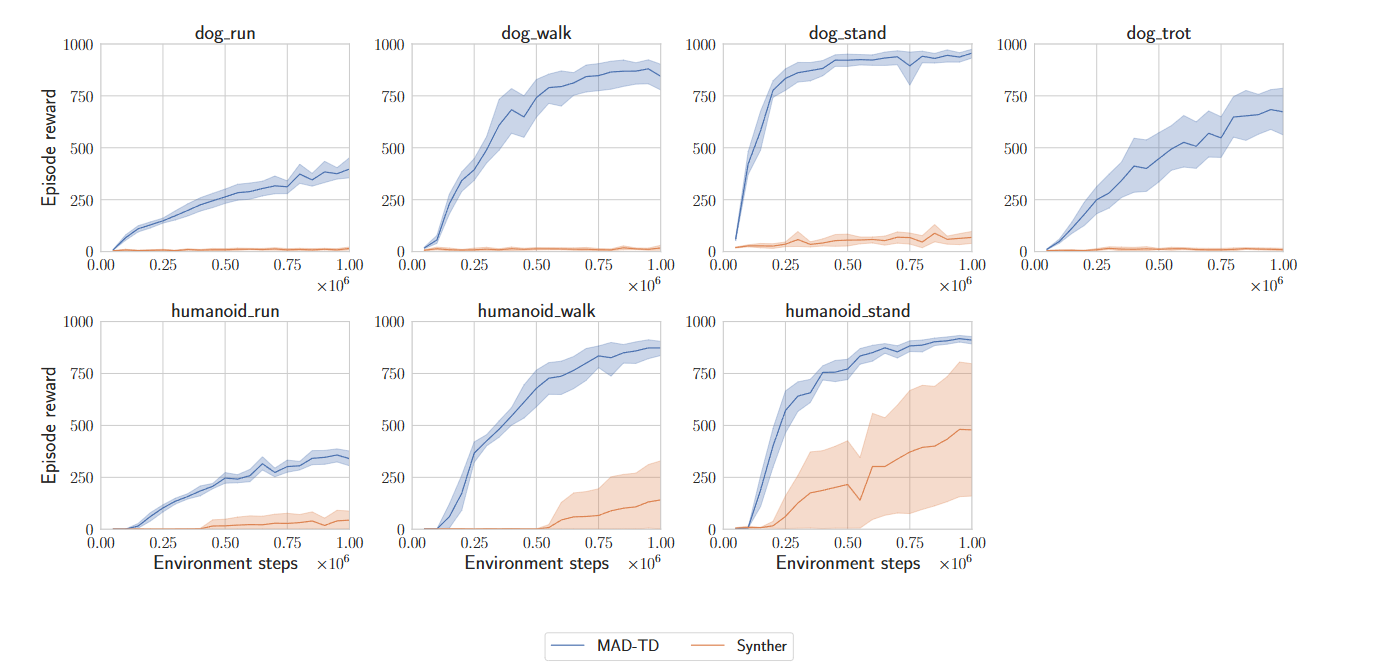
文章分析Synther失敗是由于Q值發散,學習的價值函數無法實現有效泛化。總結就是合成數據的同時能學習到有效的價值函數尤其重要。
)



)


)











)