簡介
智能制造與數據庫技術的深度融合,已成為現代工業技術進步的一個重要里程碑。隨著信息技術的飛速發展,智能制造已經成為推動工業轉型升級的關鍵動力。在這一進程中,數據庫技術扮演著不可或缺的角色,它不僅承載著海量的生產數據,還為智能制造提供了強大的數據支持和服務。
特別是隨著大數據、云計算等前沿技術的崛起,TDengine 憑借靈活多變的數據模型和卓越的數據處理能力,在智能制造領域大放異彩。TDengine 能夠高效地管理和分析制造過程中的各類數據,從生產線的實時監控到產品質量的精細管理,再到供應鏈的優化協調,它都能提供精準可靠的數據支持。
智能制造面臨的挑戰
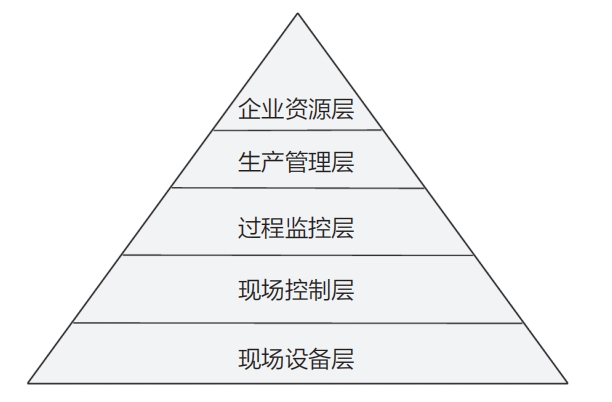
依照傳統的 IEC 62264-1 層次模型,工業制造領域被劃分為 5 個層級—現場設備層、現場控制層、過程監控層、生產管理層及企業資源層。這一模型清晰地描繪了從生產現場的實時操作到企業管理層面的戰略規劃,每一層級的躍遷都伴隨著數據量的急劇增長和需求的變化,如下圖所示。這種層級劃分不僅反映了工業制造過程中信息流動的復雜性,也揭示了隨著生產規模的擴大和自動程度的提高,對數據處理能力和效率的要求也在不斷提升。
隨著工業數字化的巨浪席卷而來,我們見證了數據采集量的爆炸式增長和分析需求的日益復雜化,隨之而來的問題和挑戰也愈發凸顯。
- 海量設備數據采集:在過去的十余年里,制造業的數字化進程取得了顯著進展。工廠的數據采集點從傳統的數千個激增至數十萬甚至數百萬個。面對如此龐大的數據采集需求,傳統的實時數據庫已顯得力不從心。
- 動態擴容:隨著數據的逐步接入,初期的硬件配置往往較為有限。隨著業務量的增加和數據量的上升,硬件資源必須迅速擴展以滿足業務的正常運行。然而,一旦系統上線運行,通常不允許進行停機擴容,這就要求系統在設計時就要考慮到未來的擴展性。
- 數據關聯與多維分析:傳統工業實時數據庫通常只包含幾個固定的字段,如變量名、變量值、質量戳和時間戳,缺乏信息間的關聯性,這使得復雜的多維分析變得難以執行。
- 截面查詢與插值查詢:為了滿足報表和其他統計需求,系統需要支持歷史截面查詢以及按指定時間間隔進行的線性插值查詢。
- 第三方系統數據庫對接:除了設備數據以外,還須采集來自各個生產系統的數據,這些系統通常位于過程監控層或生產管理層。這就要求系統能夠實時采集數據、遷移歷史數據,并在網絡斷開時能夠斷線續傳。除了 API 以外,常見的對接方式還包括數據庫對接,例如,與 LIMIS 對接,采集其關系型數據庫中存儲的時序數據,或與第三方生產數據庫(如 AVEVA PI System 或 Wonderware 系統)對接,獲取實時、歷史和報警數據。
- 與 SCADA(Supervisory Control and Data Acquisition,監控控制與數據采集)系統對接:SCADA 系統作為過程監控層的核心,匯集了站內和廠區的所有生產數據,并提供了直觀易用的開發、運行和管理界面。然而,其自帶的傳統實時數據庫在分析能力和高密度點位容量上存在限制,通常僅支持約 1 萬個點位。因此,將 SCADA 系統與性能更優越的數據庫相結合,充分發揮雙方的優勢,通過面向操作技術層的模塊化組態開發,為工業控制系統注入新的活力,已成為工業數字化發展的重要方向。
TDengine 在智能制造中的核心價值
智能制造領域涵蓋眾多類型的數據設備、系統以及復雜的數據分析方法。TDengine 不僅巧妙解決了數據接入和存儲的挑戰,更通過強大的數據分析功能,為黃金批次、設備綜合效率(Overall Equipment Effectiveness,OEE)、設備預防性維護、統計過程控制(Statistical Process Control,SPC)等關鍵分析系統提供了卓越的數據統計服務。這不僅顯著提高了生產效率和產品品質,還有效降低了生產成本。
- 廣泛兼容各種設備和系統:TDengine 配備了可視化配置的采集器,能夠輕松對接 SQL Server、MySQL、Oracle、AVEVA PI System、AVEVA Historian、In?uxDB、OpenTSDB、ClickHouse 等多種系統,支持實時數據采集、歷史數據遷移以及斷線續傳等功能。通過與諸如 Kepware 或 KingIOServer 這樣的強大第三方采集平臺對接,TDengine 能夠應對各種工業互聯網協議,實現海量生產設備數據的接入。
- 高效的集群管理:與傳統實時數據庫相比,TDengine 采用了基于云原生技術的先進架構,能夠輕松實現動態擴容。TDengine 集群采用 Raft 強一致性協議,確保生產數據對外查詢結果的一致性。集群的運維管理簡便,內部自動完成數據分區和數據分片,實現了分布式、高可用性和負載均衡的集群環境。
- 設備物模型:TDengine 秉承“一臺設備一張表”的設計策略,構建了以設備對象為核心的變量關系模型,為相關分析提供了堅實的基礎。
- 先進的時序分析:TDengine 支持時序領域的截面查詢、步進查詢、線性插值查詢等多種查詢方式,并提供了窗口查詢功能,使得設備狀態時長統計、連續過載報警等時序分析變得簡單易行。
TDengine 在智能制造中的應用
作為新一代時序大數據平臺的杰出代表,TDengine 針對工業場景中的種種挑戰,憑借獨特的設計理念和卓越的性能,為智能制造領域注入了強大的動力。接下來以某煙廠的實際應用案例為例進行闡述。
在該項目中,TDengine 集群為工廠內的各類業務提供了堅實的時序數據服務。無論是看板展示還是預警系統等對實時數據要求極高的業務場景,TDengine 都能夠提供低延遲、高質量的數據響應。自系統上線以來,已穩定運行超過兩年,成功存儲超過 2 萬億條數據,且查詢最新數據的延遲控制在毫秒級,完全達到項目立項的預期要求。該項目的亮點設計如下
- 高效采集:煙草項目初期規模有限,全廠測點數不足 10 萬。數據采集網關將部分測點數據寫入 OPC(OLE for Process Control,用于過程控制的 OLE)服務器,并通過 OPC 協議接入 TDengine;另一部分測點數據則寫入 Kafka,進而接入 TDengine。客戶無須開發 OPC 或 Kafka 接口應用程序,即可實現數據的高效接入。對于采用關系型數據庫如 LIMIS 的場景,TDengine 通過可視化配置 SQL Server 采集器,實現了數據的同步更新、歷史數據遷移、斷線續傳以及故障診斷等功能,無須編寫代碼,大幅降低了開發和運維成本。在其兄弟單位中,部分生產系統使用 Wonderware 數據庫(現 AVEVA Historian),TDengine 通過建立 AVEVA Historian 采集器,同樣實現了零代碼可視化配置,輕松完成實時數據接入、歷史數據遷移及斷線續傳等功能。相較于初次定制化開發長達 3 個月的交付周期,TDengine 采集器的部署僅需要十幾分鐘,且具有更強的可靠性和靈活性。
- 動態擴容和負載再均衡:為應對未來業務的增長,TDengine 支持在不停止服務的前提下進行動態的縱向和水平擴容。在單臺計算機資源充足的場景下,TDengine 可通過拆分虛擬節點服務,充分利用計算機的額外 CPU 資源來提高數據庫性能。而在資源不足的情況下,只須增加物理節點,TDengine 集群便能根據需求進行自動負載均衡。
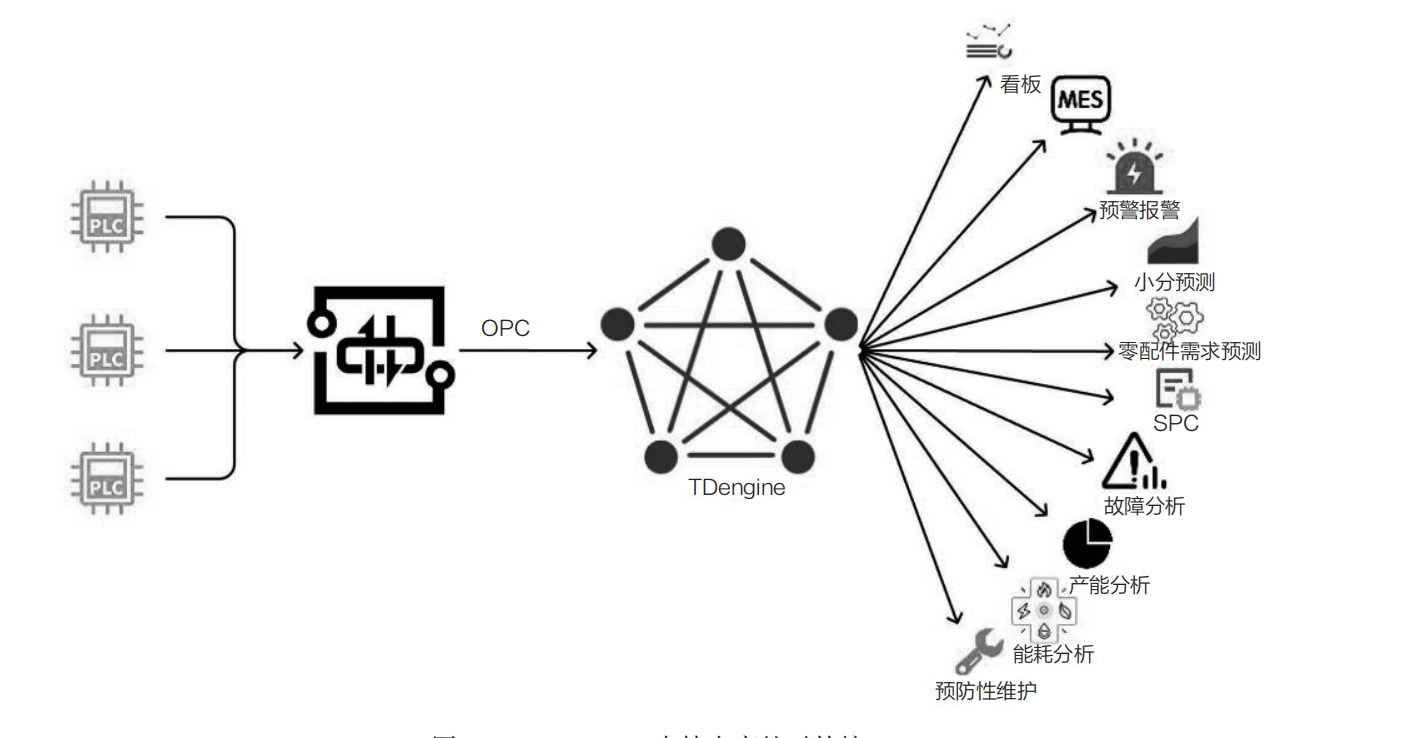
- 支持建立大寬表:TDengine 的這一設計滿足了數據關聯和多維分析的需求,解決了傳統工業實時數據庫固定格式數據存儲的限制。通過超級表的靜態標簽設計,
用戶可以便捷地進行多維度數據分析。 - 支持豐富的對外接口:作為數據中心,TDengine 可對接第三方可視化界面(如看板)、MES、預警報警、水分預測、零配件需求預測、SPC、故障分析、產能分析、能耗分析、預防性維護等系統,如下圖所示:
- TDengine 與 SCADA 系統的融合:生產調度中心常采用 SCADA 系統進行數據采集、監視和控制。SCADA 系統通過 TDengine 的 ODBC 接口,將實時和歷史數據、設備報警、操作記錄、登錄信息以及系統事件等數據存儲到 TDengine 中。與 SCADA 系統自帶的歷史庫相比,客戶在查詢曲線、報表等歷史數據時耗時更短、響應更快、靈活性更強,這不僅降低了對 SCADA 系統的壓力,還提高了整個系統的效率和穩定性。
此外,TDengine 還支持云邊系統部署,如下圖所示:
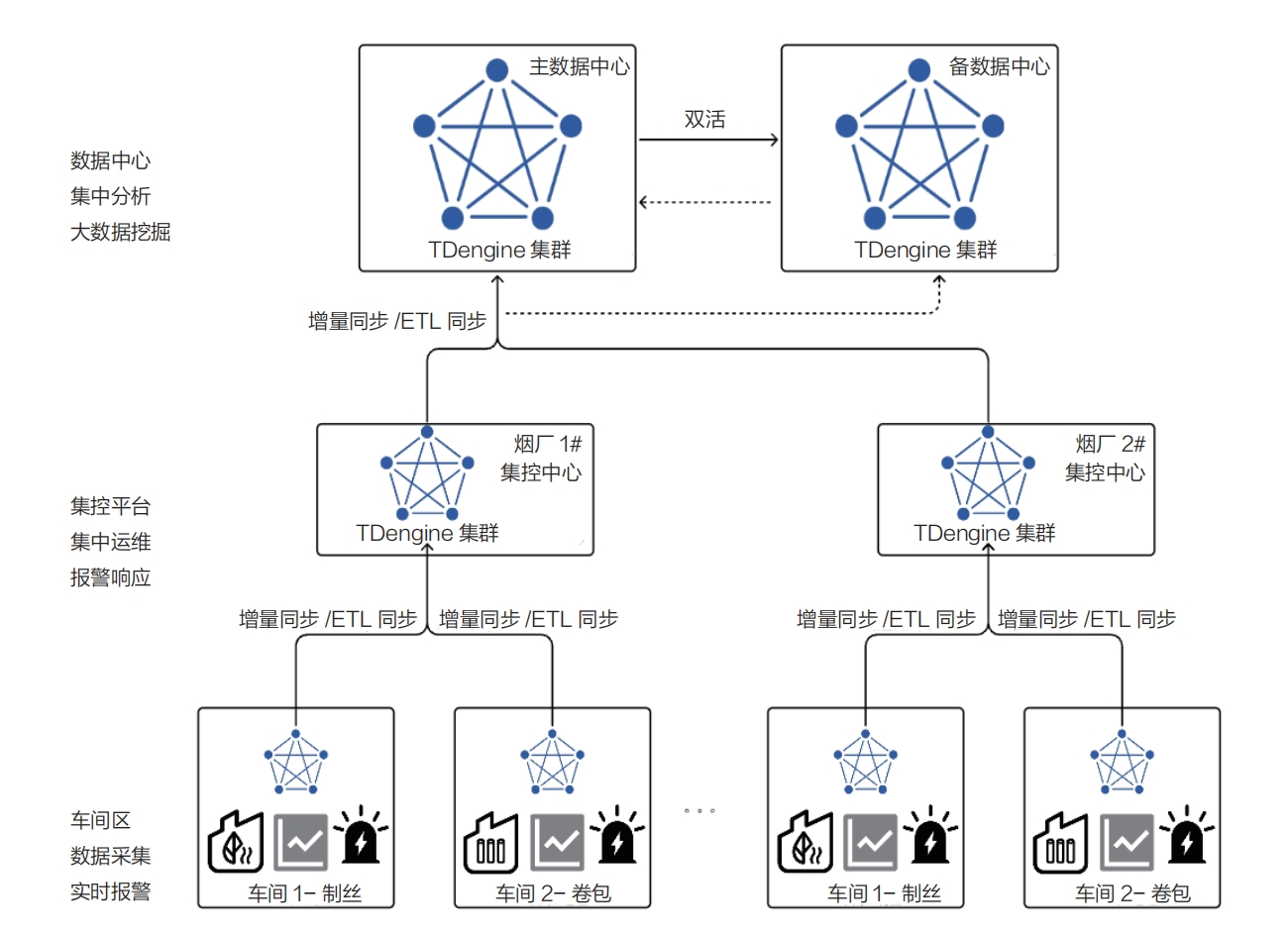
在工廠側部署 TDengine,不僅為該煙廠提供數據存儲、查詢和分析服務,還能通過高效的數據同步工具,實現工廠數據實時同步至上一級或集團中心。TDengine 的量化裁剪功能使其能夠適應資源有限的計算機或邊緣盒子環境,滿足不同規模部署的需求。TDengine 的同步特性如下。
- 統計意義的降采樣同步:TDengine 利用流計算技術,實現了具有統計意義的降采樣數據同步。通過這種方式,可以在不損失數據精度的前提下,對數據進行降采樣處理,確保即使在數據時間顆粒度增大的情況下,也能保持數據的準確性。流計算的使用方式簡便,無須復雜配置,客戶只須根據自己的需求編寫 SQL 即可實現。
- 訂閱式傳輸:TDengine 采用了類似 Kafka 的消息訂閱方式進行數據同步,相較于傳統的周期性同步和普通訂閱訪問,這種方式實現了負載隔離和流量削峰,提高了同步的穩定性和效率。消息訂閱機制遵循至少一次消費原則,確保在網絡斷線故障恢復后,能夠從斷點處繼續消費數據,或者從頭開始消費,以保證消費者能夠接收到完整的生產數據。
- 操作行為同步:TDengine 能夠將操作行為同步到中心端,確保設備故障或人為對邊緣側數據的修改和刪除操作能夠實時反映到中心側,維護了數據的一致性。
- 數據傳輸壓縮:在數據傳輸過程中,TDengine 實現了高達 20% 的數據壓縮率,結合流計算的降采樣同步,顯著降低了同步過程對帶寬的占用,提高了數據傳輸效率。
- 多種同步方式:TDengine 支持多對一、一對多以及多對多的數據同步模式,滿足不同場景下的數據同步需求。
- 支持雙活:數據中心側可實現異地災備。邊緣側的 TDengine 或第三方客戶端能夠根據集團中心側的 TDengine 狀態進行智能連接。若主 TDengine 集群發生故障,無法對外提供服務,異地備用的 TDengine 集群將立即激活,接管所有客戶端的訪問連接,包括寫入和查詢功能。一旦主 TDengine 集群恢復正常,備用集群會將歷史緩存和實時數據同步回主集群,整個過程對客戶端透明,無須人工干預。
訪問官網
更多內容歡迎訪問 TDengine 官網



)

)



)


)






