CLIP模型概述與落地測試
CLIP模型全稱是Contrastive Language-Image Pretraining??(對比語言圖像預訓練)。是OpenAI于2021年提出的多模態預訓練模型,通過對比學習對齊圖像和文本的表示,實現零樣本(zero-shot)遷移到多種視覺任務。其核心思想是??“用自然語言監督視覺模型”??,即利用互聯網規模的圖像-文本對訓練,使模型理解開放世界的視覺概念。
其特點總結如下:
1.采用多模態對齊,圖像用視覺編碼器VIT(vision transformer),或者resnet殘差網絡,文本用文本編碼器如transformer編碼。最終實現最大化匹配圖像和文本的相似度。CLIP對于圖像的編碼實際上用的是resnet 50
2.零樣本遷移,無需微調即可直接應用于新任務(如分類、檢索),通過文本提示(prompt)生成分類器。
3.prompt工程,提示工程與集成提高了零樣本性能。與使用無上下文類名的基線相比,提示工程與集成在 36 個數據集上平均將零樣本分類性能提高了近 5 個百分點。這種提升與使用基線零樣本方法時將計算量增加 4倍所獲得的提升相似,但在進行多次預測時,這種提升是“免費的”。
resnet50是五十層的殘差神經網絡,通過全局池化和批量歸一化來優化性能,可以用于對圖像進行特征提取。
在論文中闡述clip的圖例如下:
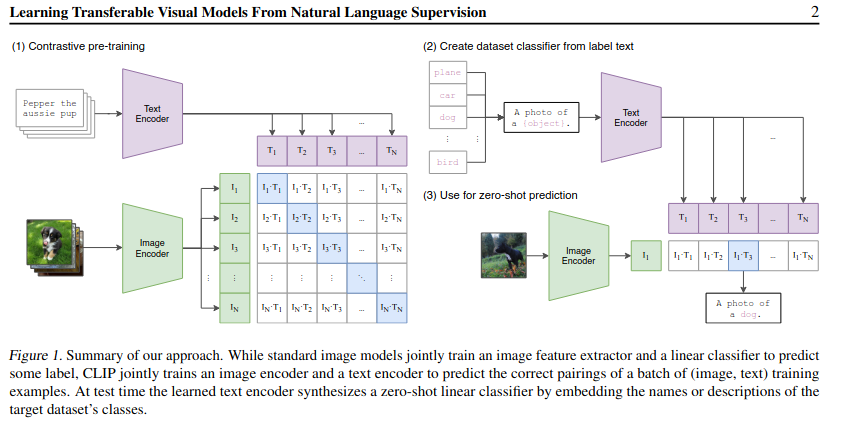
首先是預訓練,然后是構建數據集分類器,最后是用于零損失預測。
CLIP模型被發布在hugging face官網以供下載。
但是由于國內下載hugging face速度太慢,而模型本身大小較大,因此在國內鏡像網站上面下載,采用git lfs clone來下載。
測試辦法參考項目工程,該工程應用CLIP來做圖文等多模態信息檢索并求解相似度。
GitHub - pydaxing/clip_blip_embedding_rag: 在RAG技術中,嵌入向量的生成和匹配是關鍵環節。本文介紹了一種基于CLIP/BLIP模型的嵌入服務,該服務支持文本和圖像的嵌入生成與相似度計算,為多模態信息檢索提供了基礎能力。
比如:
git lfs clone https://www.modelscope.cn/<namespace>/<model-name>.git 然后將namespace/model-name.git替換成要下載的模型名稱。openai/clip-vit-large-patch14,namespace是出品方,model-name是下載的模型的名字。主要的代碼如下,運行時候
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import CLIPProcessor, CLIPModel
import torch
from PIL import Image
import requests
from io import BytesIO
import numpy as np
import time
import asyncio
from concurrent.futures import ThreadPoolExecutor
from typing import List # 導入 List 類型# Use a pipeline as a high-level helper# 加載模型和處理器
# Load model directly
processor = CLIPProcessor.from_pretrained("./dataroot/models/openai/clip-vit-large-patch14")
model = CLIPModel.from_pretrained("./dataroot/models/openai/clip-vit-large-patch14")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)# 函數:生成文本嵌入
def get_text_embedding(text):inputs = processor(text=[text], return_tensors="pt", padding=True).to(device)with torch.no_grad():embedding = model.get_text_features(**inputs)return embedding.cpu().numpy()def get_image_embedding(image_url):try:response = requests.get(image_url)image = Image.open(BytesIO(response.content)).convert("RGB")inputs = processor(images=image, return_tensors="pt").to(device)with torch.no_grad():embedding = model.get_image_features(**inputs)return embedding.cpu().numpy()except Exception as e:return Noneclass EmbeddingService:def __init__(self, max_concurrency=5):self.semaphore = asyncio.Semaphore(max_concurrency)async def get_embedding(self, index, param, result, candidate_type):async with self.semaphore:loop = asyncio.get_running_loop()with ThreadPoolExecutor() as pool:if candidate_type == "text":result[index] = await loop.run_in_executor(pool, get_text_embedding, param)elif candidate_type == "image":result[index] = await loop.run_in_executor(pool, get_image_embedding, param)app = FastAPI()class QueryRequest(BaseModel):query: strcandidates: List[str]query_type: str = "text" # 默認為文本candidate_type: str = "text" # 默認為文本def cosine_similarity(vec1, vec2):return np.dot(vec1, vec2.T) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))@app.post("/similarity")
async def similarity(request: QueryRequest):# 解析請求數據query = request.querycandidates = request.candidatesquery_type = request.query_typecandidate_type = request.candidate_type# 生成查詢嵌入if query_type == "text":query_embedding = get_text_embedding(query).tolist() # 轉換為可序列化格式elif query_type == "image":query_embedding = get_image_embedding(query)if query_embedding is None:raise HTTPException(status_code=400, detail="Failed to load query image from URL")query_embedding = query_embedding.tolist() # 轉換為可序列化格式else:raise HTTPException(status_code=400, detail="Invalid query_type")# 使用并發生成候選嵌入result = [None] * len(candidates)embedding_service = EmbeddingService(max_concurrency=5)# 并發執行任務,限制同時運行的任務數await asyncio.gather(*[embedding_service.get_embedding(i, candidate, result, candidate_type)for i, candidate in enumerate(candidates)])# 計算相似度similarities = []for candidate, candidate_embedding in zip(candidates, result):if candidate_embedding is None:raise HTTPException(status_code=400, detail=f"Failed to load candidate image from URL: {candidate}")similarity_score = cosine_similarity(query_embedding, candidate_embedding)similarities.append((candidate, float(similarity_score))) # 確保 similarity_score 是 float 類型# 按相似度排序并返回最相似的候選結果similarities.sort(key=lambda x: x[1], reverse=True)return {"similarities": similarities}uvicorn是一個基于 Python 的 ??ASGI(Asynchronous Server Gateway Interface)服務器??,專為高性能異步 Web 應用設計。通過uvicorn啟動服務器的命令如下:
uvicorn embedding:app --host 0.0.0.0 --port 9502得到的測試結果如下:
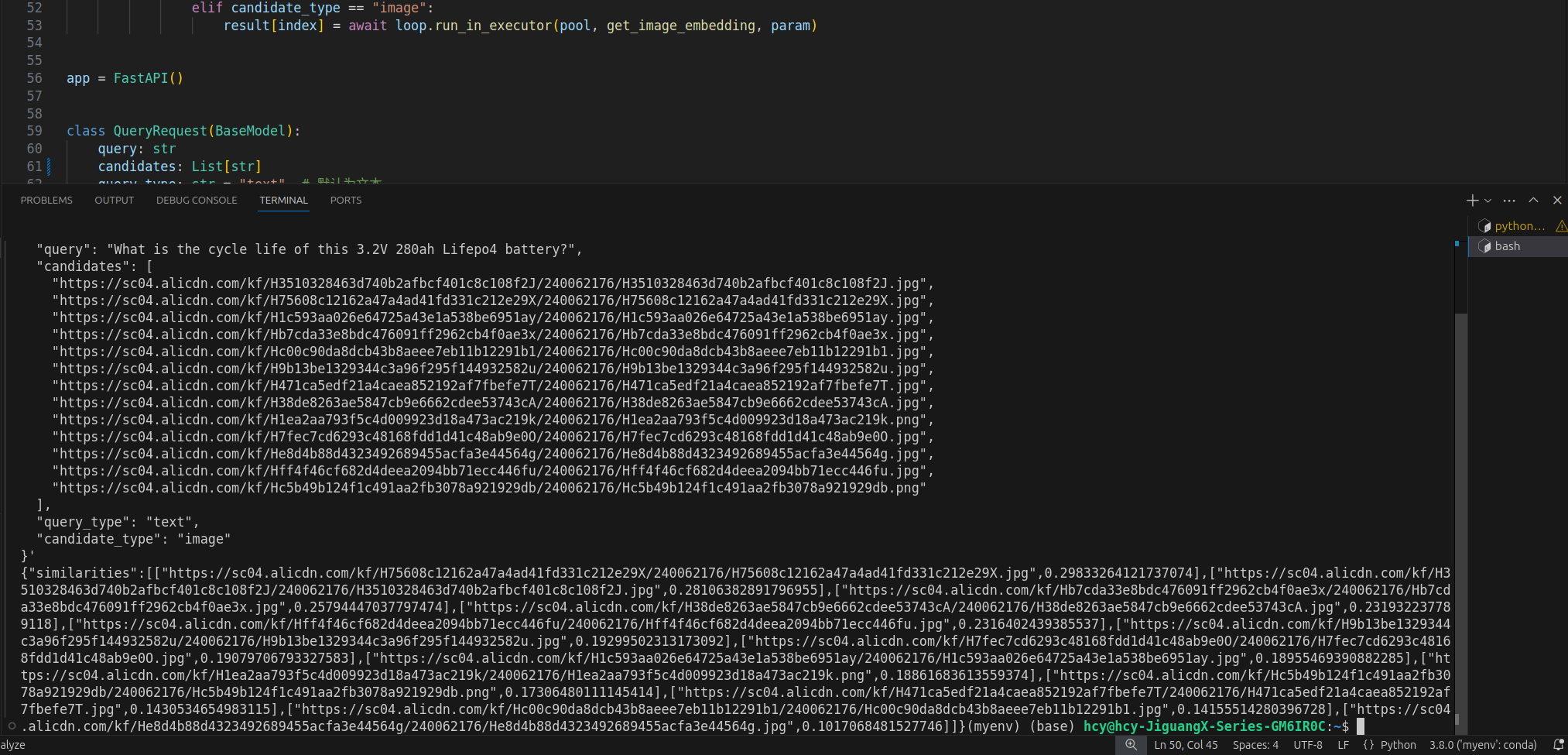
在上圖中和鋰電池查詢What is the cycle life of this 3.2V 280ah Lifepo4 battery匹配最高的圖像是,相似度為0.2983

?
videochat模型概述與部署測試
?videochat-flash模型是由上海AI lab研究人員等開發的一款MLLM模型,以往模型的難點在于如何處理長時間的視頻。該模型的創新點在于:
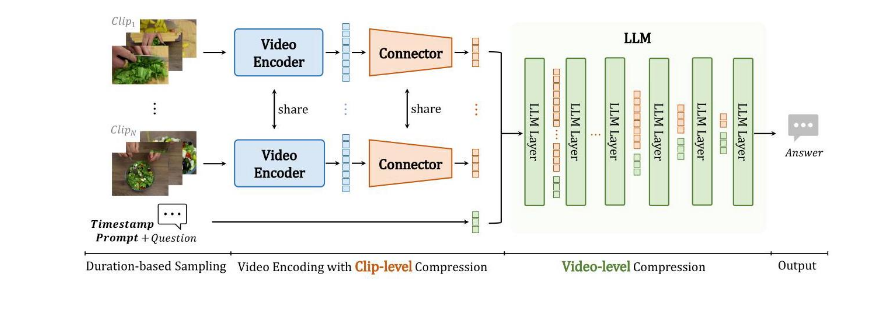
1.片段級壓縮??:將視頻分割為片段,通過時空注意力(UMT-L編碼器)和相似令牌合并(ToMe),將每幀壓縮至16個令牌(壓縮比1/50)。
2.視頻級壓縮??:在LLM推理時漸進丟棄冗余令牌(淺層均勻丟棄,深層基于文本引導的注意力選擇),減少計算量且提升性能。
訓練的數據集為:
?LongVid數據集??:30萬小時長視頻+20億文本注釋,覆蓋5類任務(字幕生成、時間定位等),整合Ego4D、HowTo100M等數據。
通過這些辦法最終在處理長視頻時候計算量大大降低。性能大大提高。圖例如下:
在鏡像網站上的開源模型為:
本地的測試代碼如下,在實際測試中引起問題的主要來源在transformer的版本。
還有其他的下載的包應當保持對齊為:
pip install transformers==4.40.1
pip install timm
pip install av
pip install imageio
pip install decord
pip install opencv-python
# optional
pip install flash-attn --no-build-isolation
from modelscope import AutoModel, AutoTokenizer
import torch# model setting
model_path = './VideoChat-Flash-Qwen2_5-2B_res448'tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda()
image_processor = model.get_vision_tower().image_processormm_llm_compress = False # use the global compress or not
if mm_llm_compress:model.config.mm_llm_compress = Truemodel.config.llm_compress_type = "uniform0_attention"model.config.llm_compress_layer_list = [4, 18]model.config.llm_image_token_ratio_list = [1, 0.75, 0.25]
else:model.config.mm_llm_compress = False# evaluation setting
max_num_frames = 512
generation_config = dict(do_sample=False,temperature=0.0,max_new_tokens=1024,top_p=0.1,num_beams=1
)video_path = "./testvideo.mp4"# single-turn conversation
question1 = "Describe this video in detail."
output1, chat_history = model.chat(video_path=video_path, tokenizer=tokenizer, user_prompt=question1, return_history=True, max_num_frames=max_num_frames, generation_config=generation_config)print(output1)# multi-turn conversation
question2 = "How many people appear in the video?"
output2, chat_history = model.chat(video_path=video_path, tokenizer=tokenizer, user_prompt=question2, chat_history=chat_history, return_history=True, max_num_frames=max_num_frames, generation_config=generation_config)print(output2)#multi-turn
question3="who is the oldest in this video?"
output3, chat_history = model.chat(video_path=video_path, tokenizer=tokenizer, user_prompt=question3, chat_history=chat_history, return_history=True, max_num_frames=max_num_frames, generation_config=generation_config)
print(output3)然后問題在于如何找到測試視頻,這里采用的是python中的you-get模塊:
pip install you-get后通過下面的命令就可以實現視頻的爬取,這里下載了一段電視劇片段,2720幀,視頻大意是一個老人去法國買羊角面包回去給他的老朋友帶去吃。
you-get https://www.bilibili.com/video/爬取后進行模型測試,備注,此處還需要使用CUDA支持,需要電腦裝有invidia顯卡并下載CUDA相應工具包。得到結果如下,符合視頻實際邏輯。

VICLIP模型概述與部署測試
viclip 是由上海ai lab的opengv-lab等團隊聯合實現的,這篇論文,arxiv鏈接如下:
https://arxiv.org/pdf/2307.06942
其中首先提出了一個intern vid數據集,其具備大范圍多國源視頻和高質量文本標注,用BLIP-2為視頻中間幀生成描述。用Tag2Text逐幀標注,再通過大語言模型(如LLaMA)匯總為整體描述。
隨后介紹了VICLIP模型,其基于CLIP的對比學習框架,視頻編碼器為ViT-L(加入時空注意力),文本編碼器與CLIP相同。VICLIP的創新點在于使用了視頻掩碼學習來隨機遮蔽視頻塊(類似MAE),降低計算成本。?視頻掩碼學習(Video Masked Learning)?? 是一種受自然語言處理(NLP)和計算機視覺中掩碼建模(如BERT、MAE)啟發的自監督學習方法,旨在通過遮蔽部分視頻數據并讓模型預測被遮蔽的內容,從而學習視頻的時空表征。
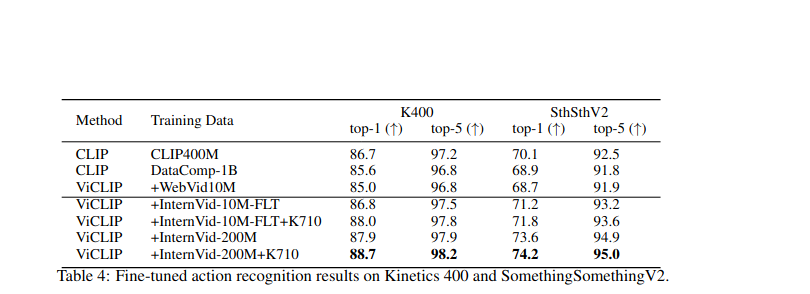
VCLIP采用兩段訓練,關注infoNCE損失度,最大化視頻-文本對的相似度。
VICLIP在訓練過程中使用了64張A100,訓練了三天在五千萬的視頻-文本對上。結果較好
viclip在hugging face平臺的模型如下:
在下載好后,使用其示例中的視頻,一個男人和狗在雪地中玩的視頻。

在jupyter筆記本的demo中跑得結果如下:
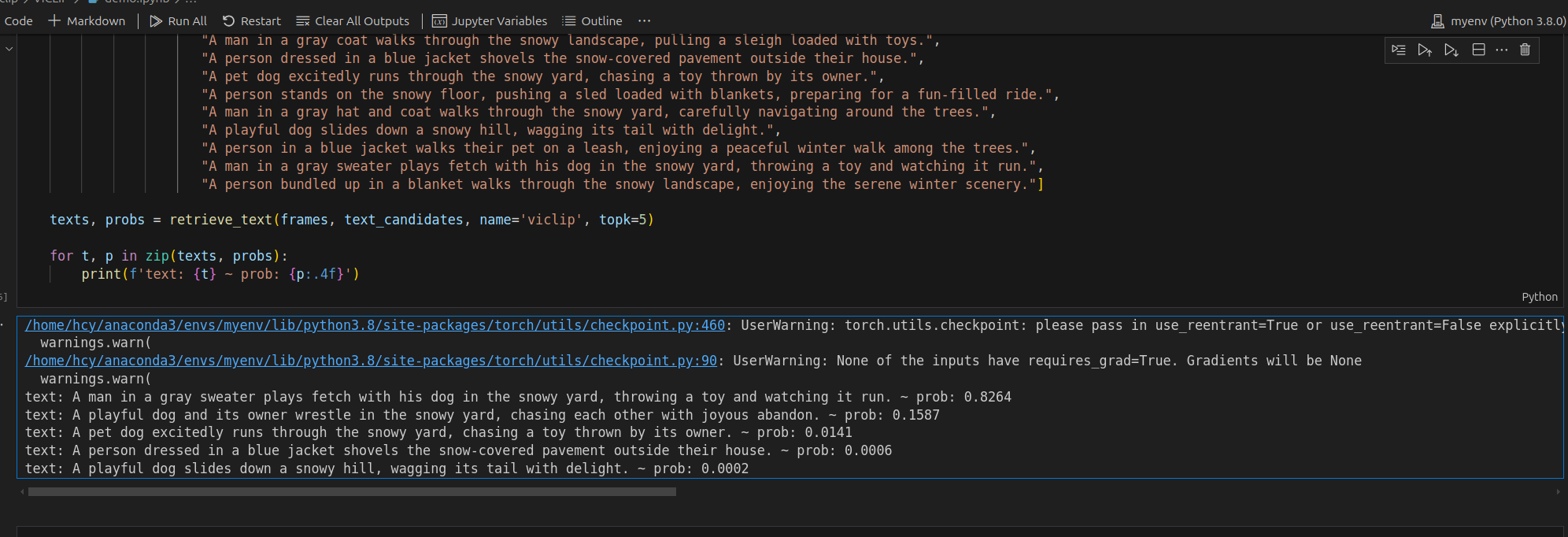
text: A man in a gray sweater plays fetch with his dog in the snowy yard, throwing a toy and watching it run. ~ prob: 0.8264 該文本最和視頻相符。

)


)











)


