Vim技巧
- 一、按 按模 模式 式匹 匹配 配及 及按 按原 原義 義匹 匹配
- 1.1、調整查找模式的大小寫敏感性
- 1.2、按正則表達式查找時,使用 \v 模式開關
- 1.3、按原義查找文本時,使用 \V 原義開關
- 1.4、使用圓括號捕獲子匹配
- 1.5、界定單詞的邊界
- 1.6、界定匹配的邊界
- 二、查找
- 2.1、相關命令
- 2.2、統計當前模式的匹配個數
- 2.3、對完整的查找匹配進行操作
- 三、替換
- 3.1、substitute 命令
- 3.2、在文件范圍內查找并替換每一處匹配
- 3.3、手動控制每一次替換操作
- 3.4、用寄存器的內容替換
- 3.5、重復上一次 substitute 命令
- 3.6、使用子匹配重排 CSV 文件的字段
- 3.7、在替換過程中執行算術運算
- 四、global命令
- 4.1、基本語法
- 4.2、刪除所有包含模式的文本行
- 4.3、將匹配項收集到寄存器
- 4.4、為:global的[cmd]單獨指定范圍
一、按 按模 模式 式匹 匹配 配及 及按 按原 原義 義匹 匹配
1.1、調整查找模式的大小寫敏感性
全局設置大小寫敏感性:
set ignorecase
每次查找時設置大小寫敏感性:
通過使用元字符 \c 與 \C, 可以覆蓋 Vim 缺省的大小寫敏感性設置。 小寫字母 \c會讓查找模式忽略大小寫,而大寫字母 \C 則會強制區分大小寫。若在某個查找模式中使用了兩者中的某一個,‘ignorecase’的值將被這次查找忽略。
啟用更具智能的大小寫敏感性設置:
Vim 提供了一項額外設置,用于最大限度地推測我們是想用大寫還是小寫,這就是‘smartcase’選項。
set smartcase
該選項被啟用后,無論何時,只要我們在查找模式中輸入了大寫字母,‘ignorecase’設置就不再生效了。換句話說,如果我們的模式全是由小寫字母組成的,就會按照忽略大小寫的方式進行查找,但只要我們輸入一個大寫字母,查找方式就會變成區分大小寫的了。
總結:
| 模式 | ‘ignorecase’ | ‘smartcase’ | 匹配 |
|---|---|---|---|
| foo | off | - | foo |
| foo | on | - | foo Foo FOO |
| foo | on | on | foo Foo FOO |
| Foo | on | on | Foo |
| Foo | on | off | foo Foo FOO |
| \cfoo | - | - | foo Foo FOO |
| foo\C | - | - | foo |
1.2、按正則表達式查找時,使用 \v 模式開關
假設我們要構造一個正則表達式, 用于匹配以下 CSS 片段中的每一組顏色代碼:
body { color: #3c3c3c; }
a { color: #0000EE; }
strong { color: #000; }
我們需要匹配 1 個 # 字符以及緊隨其后的 3 個或 6 個十六進制字符 (包括所有數字以及大寫或小寫的字母 A 到 F) 。
可以利用 \v 模式開關來統一所有特殊符號的規則。該元字符將會激活 verymagic搜索模式,即假定除、大小寫字母以及數字 0 到 9 之外的所有字符都具有特殊含義。
# 正則
/#\([0-9a-fA-F]\{6}\|[0-9a-fA-F]\{3}\)# 由于出現在起始位置的 \v 開關,位于它后面的所有字符都具有特殊含義,那些反斜杠字符就可以去掉了
/\v#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})
1.3、按原義查找文本時,使用 \V 原義開關
The N key searches backward...
...the \v pattern switch (a.k.a. very magic search)...
假設我們想通過查找“a.k.a.” (此縮寫表示 also known as)的方式將光標移到該處。針對這種情況,第一反應就是執行以下這條查找命令:
/a.k.a.
但當我們按下回車鍵時,會發現此模式所匹配的內容比我們預想得要多。這是因為,符號“.”具有特殊含義。它匹配任意字符,而單詞“backward”的部分內容又恰好可以匹配該模式。
可以使用原義開關 \V,激活 very nomagic搜索模式:
/\Va.k.a.
1.4、使用圓括號捕獲子匹配
I love Paris in the
the springtime.
上文中the the重復了,需要匹配出來:
/\v<(\w+)\_s+\1>
1.5、界定單詞的邊界
the problem with these new recruits is that
they don't keep their boots clean.
有些單詞,尤其是短詞,常常出現在其他單詞內部。比如, “the”就會在“these”、“they”、“their”等單詞中出現。因此,如果我們在下面這段文本中執行 /the<CR> 進行查找的話,會發現實際匹配的內容比我們預想得要多。

如果我們想明確匹配“the”這個完整的單詞而不是其他詞的組成部分,可以使用單詞定界符。在 very magic 搜索模式下,用 <與> 符號表示單詞定界符。因此,如果我們將查找命令改為 /\v<the><CR> 的話,文中就只會出現一處匹配了。

1.6、界定匹配的邊界
有時候,我們可能想指定一個范圍較廣的模式,但只對匹配結果的一部分感興趣。Vim 中的元字符 \zs與 \ze可以幫助我們處理這種情況。
元字符 \zs標志著一個匹配的起始,而元字符 \ze則用來界定匹配的結束。將二者相結合,我們可以定義一個特殊的模式,它們可以讓我們定義一個模式匹配一個較大的文本范圍,然后再收窄匹配范圍。
| 按鍵操作 | 緩沖區內容 |
|---|---|
{start} |  |
/\v"[^"]+"<CR> |  |
/\v"\zs[^"]+\ze"<CR> |  |
注意:盡管引號被排除在匹配之外,但它們仍然是模式中的關鍵部分。
二、查找
2.1、相關命令
| 命令 | 用途 |
|---|---|
/ | 執行查找 |
n | 跳至下一處匹配,保持查找方向與偏移不變 |
N | 跳至上一處匹配,保持查找方向與偏移不變 |
/<CR> | 正向跳轉至相同模式的下一處匹配 |
?<CR> | 反向跳轉至相同模式的上一處匹配 |
2.2、統計當前模式的匹配個數
雖然沒有任何方法可以讓查找命令統計當前文檔中的匹配個數,但是用下面這條命令就可以做到這一點:
:%s///gn
實際上,我們調用的是 :substitute命令,但標志位 n會抑制正常的替換動作。該命令不會對每處匹配進行替換,而是簡單地統計匹配的次數,并將結果顯示到命令行上。此處我們將查找域留空,旨在讓 Vim 使用當前的查找模式。替換域(由于標志位 n的緣故)不管怎樣都將會被忽略,因此也可以將其留空。
2.3、對完整的查找匹配進行操作
class XhtmlDocument < XmlDocument; end
class XhtmlTag < XmlTag; end
假設想把它們改成下面這樣:
class XHTMLDocument < XMLDocument; end
class XHTMLTag < XMLTag; end
| 按鍵操作 | 緩沖區內容 |
|---|---|
{start} |  |
/\vX(ht)?ml\C<CR> |  |
gU//e<CR> |  |
//<CR> |  |
. |  |
//<CR>. |  |
//<CR>. |  |
三、替換
3.1、substitute 命令
語法:
:[range]s[ubstitute]/{pattern}/{string}/[flags]
標志位:
g使得 subsititute 命令可在全局范圍內執行c讓我們有機會可以確認或拒絕每一處修改n會抑制正常的替換行為,即讓 Vim 不執行替換操作&僅僅用于指示 Vim 重用上一次 substitute 命令所用過的標志位
替換域中的特殊字符:
通過查詢 :h sub-replace-special ,你可以找到完整的列表,
下表只是總結了其中的一部分常用符號:
| 符號 | 描述 |
|---|---|
\r | 插入一個換行符 |
\t | 插入一個制表符 |
\\ | 插入一個反斜杠 |
\1 | 插入第 1個子匹配 |
\2 | 插入第 2個子匹配(以此類推,最多到 \9) |
\0 | 插入匹配模式的所有內容 |
& | 插入匹配模式的所有內容 |
~ | 使用上一次調用 :substitute時的 {string} |
\={Vim script} | 執行 {Vim Script} 表達式;并將返回的結果作為替換 {string} |
3.2、在文件范圍內查找并替換每一處匹配
When the going gets tough, the tough get going.
If you are going through hell, keep going.
將所有單詞 going 替換為 rolling:
# 替換當前行第一個
:s/going/rolling# 替換當前行所有
:s/going/rolling/g # 全文替換
:%s/going/rolling/g
3.3、手動控制每一次替換操作
...We're waiting for content before the site can go live...
...If you are content with this, let's go ahead with it...
...We'll launch as soon as we have the content...
“content”到“copy”:
:%s/content/copy/gc
Vim提示選項:
| 答案 | 用途 |
|---|---|
y | 替換此處匹配 |
n | 忽略此處匹配 |
q | 退出替換過程 |
l | “last” —— 替換此處匹配后退出 |
a | “all” —— 替換此處與之后所有的匹配 |
<C-e> | 向上滾動屏幕 |
<C-y> | 向下滾動屏幕 |
3.4、用寄存器的內容替換
實際上,我們不必手動輸入完整的替換字符串。如果某段文本已在當前文檔中出現,我們可以先把它復制到寄存器,再通過傳值或引用的方式將寄存器的內容應用至替換域。
傳值:
通過輸入 <C-r>{register}, 我們可以將寄存器的內容插入到命令行。 假設我們已經復制了一些文本,如果要將它們粘貼到 substitute 命令的替換域,需要輸入以下命令:
:%s//<C-r>0/g
當我們輸入 0 時,Vim 會把寄存器 0 的內容粘貼進來,這意味著我們可以在執行 substitute 命令之前對其進行一番檢查。在大多數情況下,它工作得都很好,但也引入了新的問題。
如果寄存器 0 中的文本包含了在替換域中具有特殊含義的字符(例如 & 或~) ,我們必須手動編輯這段文本,對這些字符進行轉義。另外,如果寄存器 0 包含多行文本,有可能在命令行上顯示不全。
為了避免這些問題,我們可以在替換域中簡單地引用某個寄存器,從而得到該寄存器的內容。
引用:
假設我們已經復制了多行文本,并存放于寄存器 0 中。我們現在的目標是在substitute 命令的替換域中使用這段文本。通過運行以下命令,可以做到這一點:
:%s//\=@0/g
替換域中出現的 \= 將指示 Vim 執行一段表達式腳本。在 Vim 腳本中,我們可以用 @{register} 來引用某個寄存器的內容。具體來說,@0 會返回復制專用寄存器的內容,而 @" 則返回無名寄存器的內容。因此,表達式 :%s//\=@0/g 表示 Vim 將會用復制專用寄存器的內容替換上一次的模式。
3.5、重復上一次 substitute 命令
有的時候,我們可能要修正 substitute 命令的執行范圍。原因多種多樣,有可能是由于在第一次嘗試運行 substitute 命令時犯了錯,也有可能是我們想在另一個緩沖區中再次運行相同的命令。我們可以利用一些快捷方式更容易地重復 substitute 命令。
在整個文件范圍內重復面向行的替換操作:
假設我們剛剛執行完以下命令(其作用范圍為當前行) :
:s/target/replacement/g
突然,我們意識到了失誤,應該加上前綴 % 才對。幸好該命令沒有造成什么不良后果。
接下來,我們只需輸入 g& ,即可在整個文件的范圍內重復這條命令。在效果上,它等同于以下命令:
:%s//~/&
修正 substitute 命令的執行范圍:
mixin = {applyName: function(config) {return Factory(config, this.getName());},
}
假設我們想把它擴展成以下模樣:
mixin = {applyName: function(config) {return Factory(config, this.getName());},applyNumber: function(config) {return Factory(config, this.getNumber());},
}
采用符號 % 作為范圍值,從而導致每一處“Name”都被改成了“Number” 。這樣做顯然不對,我們應該指定一個范圍,限定
substitute 命令只作用于第二個函數(副本)中的那幾行文本才對。
錯誤用法:
| 按鍵操作 | 緩沖區內容 |
|---|---|
{start} |  |
Vjj |  |
yP |  |
:%s/Name/Number/g | 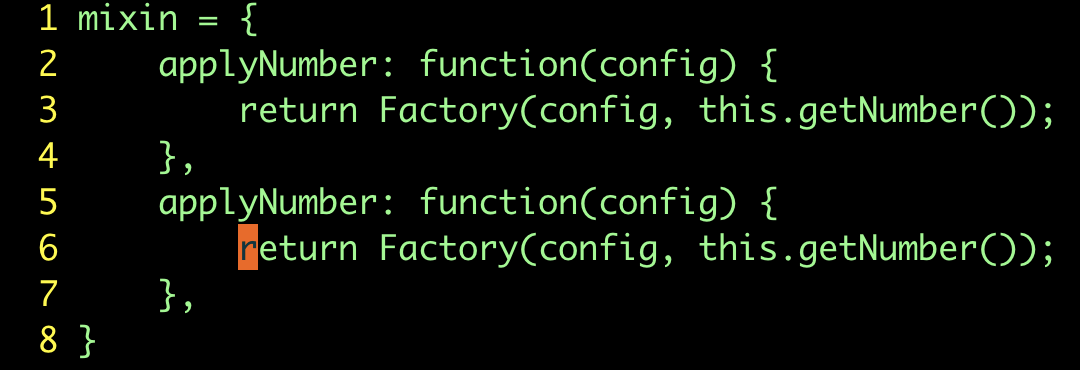 |
重新指定范圍:
| 按鍵操作 | 緩沖區內容 |
|---|---|
u | 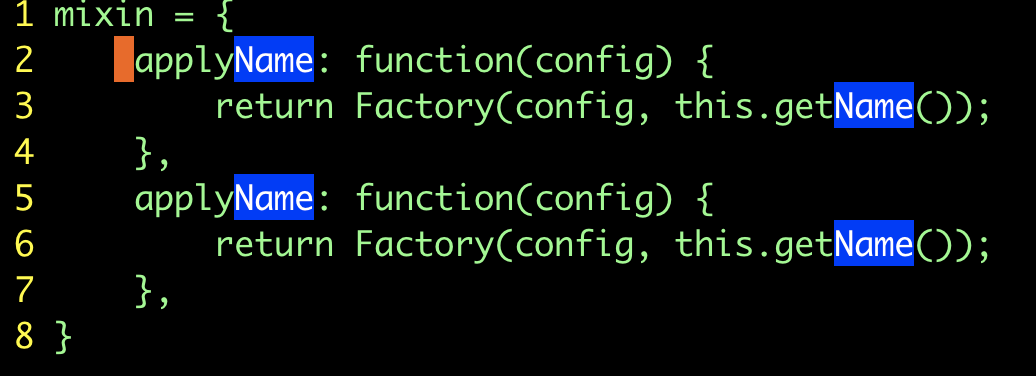 |
gv |  |
:'<,'>&& |  |
&& 命令,因為這兩處 & 符號的含義有所不同。前一
個 & 作為 Ex 命令 :& 的組成部分, 用作重復上一次的 :substitute命令 ,而第二個 & 則會重用上一次 :s命令的標志位。
3.6、使用子匹配重排 CSV 文件的字段
假設有一個 CSV 格式的文件,其中包含了一份含有電子郵箱地址以及姓名的列表。
last name,first name,email
neil,drew,drew@vimcasts.org
doe,john,john@example.com
現在假設我們想交換這些字段的次序,即把電子郵箱放到首列,其次是名字,最后一列為姓氏。通過使用以下 substitute 命令,我們可以做到這一點:
/\v^([^,]*),([^,]*),([^,]*)$
:%s//\3,\2,\1
3.7、在替換過程中執行算術運算
換域中的內容不一定非得是簡單的字符串。 我們可以執行一段 Vim 腳本表達式,然后用其結果充當替換字符串使用。具體到本節而言,僅憑一條 substitute 命令,我們就可以提升文檔中每一級 HTML 標題標簽的層級。
<h2>Heading number 1</h2>
<h3>Number 2 heading</h3>
<h4>Another heading</h4>
我們的目標是提升每一處標題的層級,將 <h2> 變為 <h1>,<h3> 變為 <h2>,以此類推。換言之,我們要將現有的 HTML 標題標簽中的數字部分減 1。
# 匹配緊跟在 <h或者 </h之后的數字
/\v\<\/?h\zs\d# 替換
:%s//\=submatch(0)-1/g
四、global命令
4.1、基本語法
:[range] global[!] /{pattern}/ [cmd]
- 首先,在缺省情況下,:global命令的作用范圍是整個文件(%) ,這一點與其他大多數 Ex 命令(包括:delete、:substitute 以及 :normal)有所不同,這些命令的缺省范圍僅為當前行(.) 。
- 其次,{pattern} 域與查找歷史相互關聯。這意味著如果將該域留空的話,Vim會自動使用當前的查找模式。
- 另外,[cmd] 可以是除 :global命令之外的任何 Ex 命令。
- 可以用
:global!或者:vglobal(v 表示 invert)反轉 :global 命令的行為。兩條命令將指示 Vim 在沒有匹配到指定模式的行上執行 [cmd]。
4.2、刪除所有包含模式的文本行
<ol><li><a href="/episodes/show-invisibles/">Show invisibles</a></li><li><a href="/episodes/tabs-and-spaces/">Tabs and Spaces</a></li><li><a href="/episodes/whitespace-preferences-and-filetypes/">Whitespace preferences and filetypes</a></li>
</ol>
顯而易見,所有列表項均由兩部分數據構成:主題的標題及其 URL。接下來,我們將利用一條 :global命令分別取出這兩組數據。
用 :g/re/d 刪除所有的匹配行:
果我們只想保留 <a> 標簽內的標題, 而把其他行刪掉:
/\v\<\/?\w+>
:g//d


用 :v/re/d 只保留匹配行:
# 刪除所有不包含 href的文本行
:v/href/d

4.3、將匹配項收集到寄存器
Markdown.dialects.Gruber = {lists: function() {// TODO: Cache this regexp for certain depths.function regex_for_depth(depth) { /* implementation */ }},"`": function inlineCode( text ) {var m = text.match( /(`+)(([\s\S]*?)\1)/ );if ( m && m[2] )return [ m[1].length + m[2].length ];else {// TODO: No matching end code found - warn!return [ 1, "`" ];}}
}
假設我們想把所有 TODO 項收集到一起。只需輸入以下命令,這些信息就會變得一覽無余:
:g/TODO# 結果 :print是 :global命令的缺省 [cmd] ,它只是簡單地回顯所有匹配單
詞“TODO”的文本行3 // TODO: Cache this regexp for certain depths.11 // TODO: No matching end code found - warn!
先將所有包含單詞“TODO”的文本行復制到某個寄存器,再把寄存器的內容粘貼到其他文件中,以備不時之需。
:qaq #清空寄存器
:reg a # 查看寄存器a
:g/TODO/yank A #將TODO行復制到寄存器中
:reg a
4.4、為:global的[cmd]單獨指定范圍
當 Ex 命令與 :global一起組合使用時, 我們也可以為 [cmd] 單獨指定范圍。 Vim允許我們以 :g/{pattern} 為參考點,動態地設定范圍。
html { margin: 0;padding: 0;border: 0;font-size: 100%;font: inherit;vertical-align: baseline;
}
body { line-height: 1.5;color: black;background: white;
}
假設我們想把每一組規則內的屬性都按照字母順序排序。借助 Vim 的內置命令 :sort,就可以實現這一功能。
對單條規則的屬性進行排序:
| 按鍵操作 | 緩沖區內容 |
|---|---|
{start} | 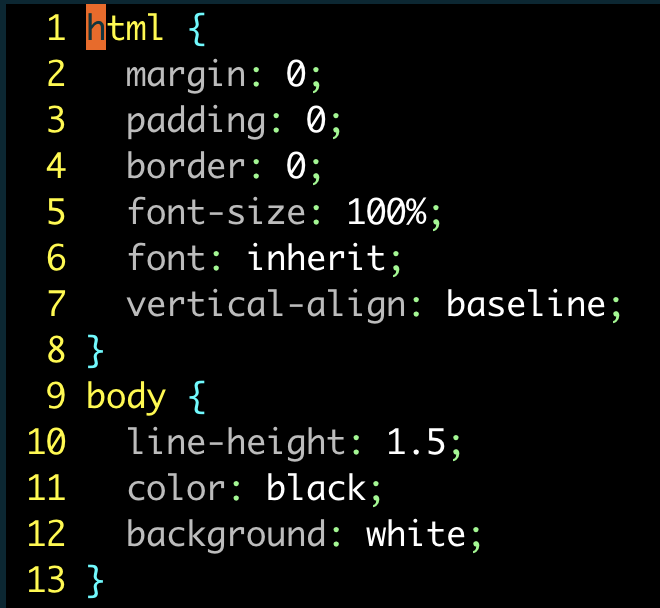 |
vi{ | 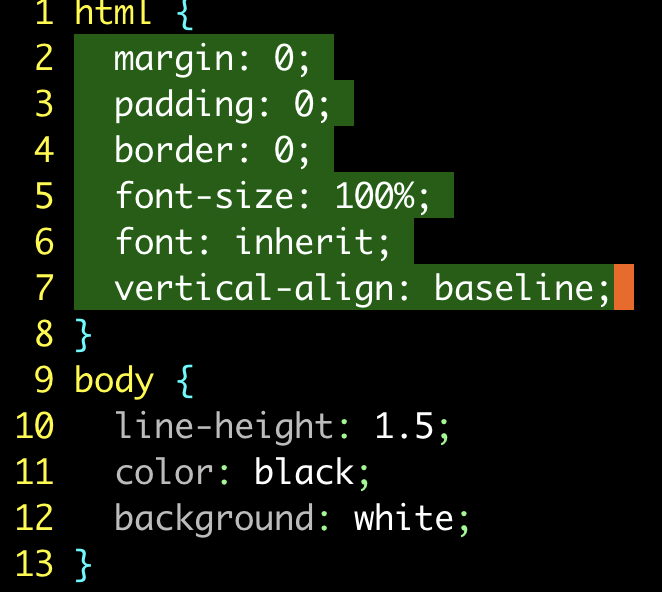 |
:'<,'>sort | 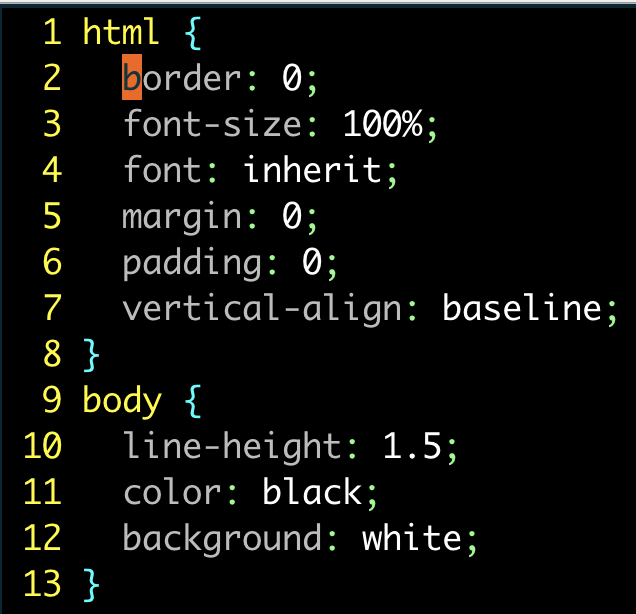 |
對所有規則的屬性進行排序:
其實,我們可以用一條 :global 命令對文件中所有規則的屬性進行排序。假設我們在本例的樣式表中運行以下命令:
:g/{/ .+1,/}/-1 sort
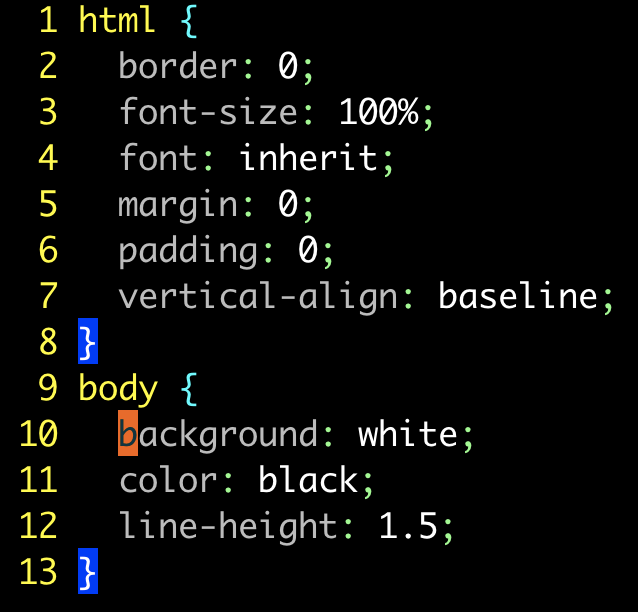
這條命令很復雜,但掌握其機理后,我們將會由衷地贊嘆 :global 命令的強大。:global命令的標準格式如下所示:
:g/{pattern}/[cmd]
Ex 命令通常都會接受“范圍”作為其參數。對于 :global命令內部的 [cmd],該規則依然有效。因此,我們可以將命令的模板擴展成以下形式:
:g/{pattern}/[range][cmd]
實 際 上 , 我 們 可 以 用 :g/{pattern} 匹 配 作 為 參 考 點 , 動 態 設 置 [cmd] 的[range]。. 符號通常表示光標所在行,但在 :global 命令的上下文中,它則表示{pattern} 的匹配行。
:g/{/ .+1,/}/-1 sort
# :g/{/ 匹配{.+1,/}/-1 sort
# 去掉偏移,移值 +1 與 —1 僅僅用于縮小操作范圍.,/}/
# 含義為從當前行開始,直到匹配到模式 /}/ 的那一行為止
也就是說,我們只需將光標置于每個{} 塊的起始位置,再運行
:.,/}/ sort命令,即可將其中的規則按照字母順序重新進行排序了。
: 數據集-語料庫(Corpus))









)





下的傳感器數據和軌跡信息。)


)