優化理論
梯度下降(Gradient Descent)
數學原理與可視化
梯度下降是優化領域的基石算法,其核心思想是沿負梯度方向迭代更新參數。數學表達式為:
θ t + 1 = θ t ? α ? θ J ( θ t ) \theta_{t+1} = \theta_t - \alpha \nabla_\theta J(\theta_t) θt+1?=θt??α?θ?J(θt?)
其中:
- α \alpha α:學習率,控制步長
- ? θ J \nabla_\theta J ?θ?J:損失函數關于參數的梯度
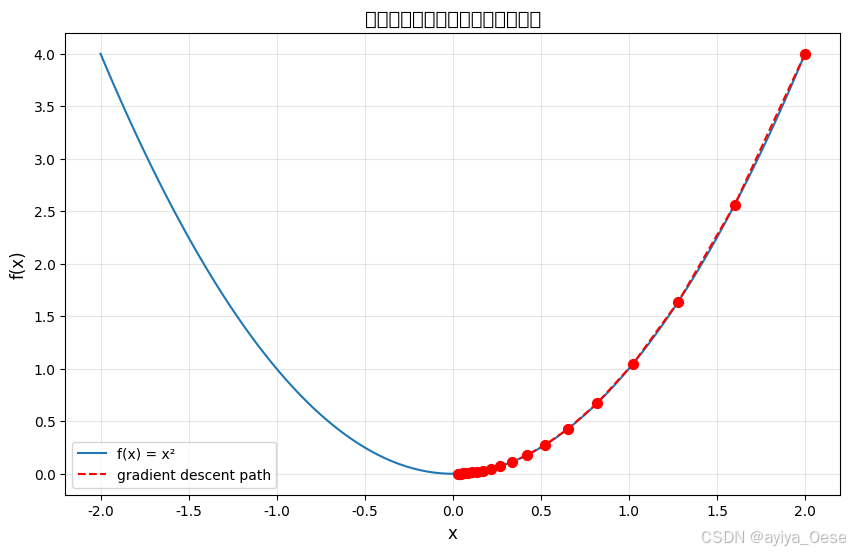
幾何解釋:在三維空間中,梯度下降如同沿著最陡下降方向下山。二維可視化展示參數更新路徑:
import matplotlib.pyplot as plt
import numpy as np# 定義二次函數及其梯度
def f(x): return x**2
def grad(x): return 2*x# 梯度下降軌跡可視化
x_path = []
x = 2.0
lr = 0.1
for _ in range(20):x_path.append(x)x -= lr * grad(x)# 繪制函數曲線和更新路徑
xs = np.linspace(-2, 2, 100)
plt.figure(figsize=(10,6))
plt.plot(xs, f(xs), label="f(x) = x2")
plt.scatter(x_path, [f(x) for x in x_path], c='red', s=50, zorder=3)
plt.plot(x_path, [f(x) for x in x_path], 'r--', label="gradient descent path")
plt.title("梯度下降在二次函數上的優化軌跡", fontsize=14)
plt.xlabel("x", fontsize=12)
plt.ylabel("f(x)", fontsize=12)
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
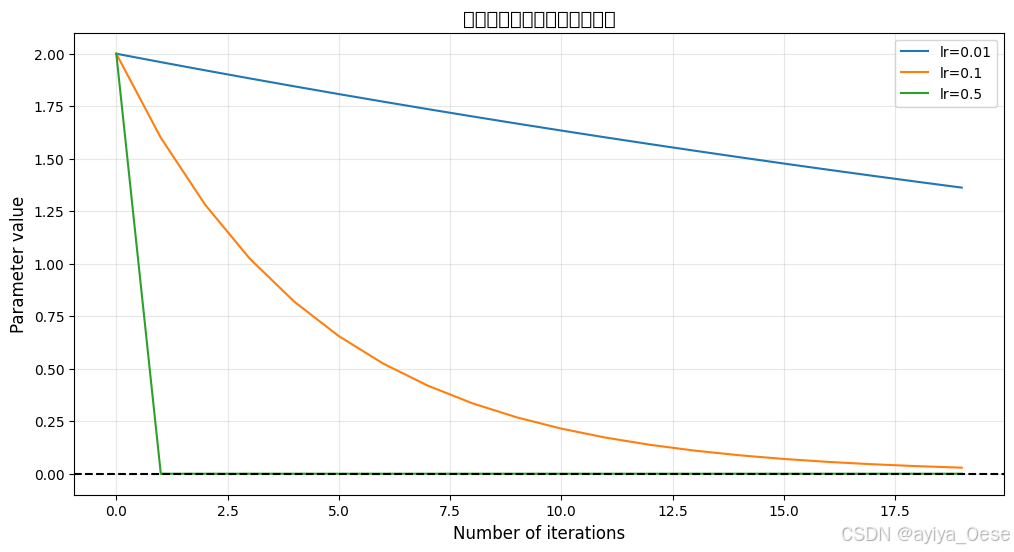
學習率對比實驗
lrs = [0.01, 0.1, 0.5] # 不同學習率plt.figure(figsize=(12,6))
for lr in lrs:x = 2.0path = []for _ in range(20):path.append(x)x -= lr * grad(x)plt.plot(path, label=f"lr={lr}")plt.title("不同學習率對收斂速度的影響", fontsize=14)
plt.xlabel("Number of iterations", fontsize=12)
plt.ylabel("Parameter value", fontsize=12)
plt.axhline(0, color='black', linestyle='--')
plt.legend()
plt.grid(True, alpha=0.3)
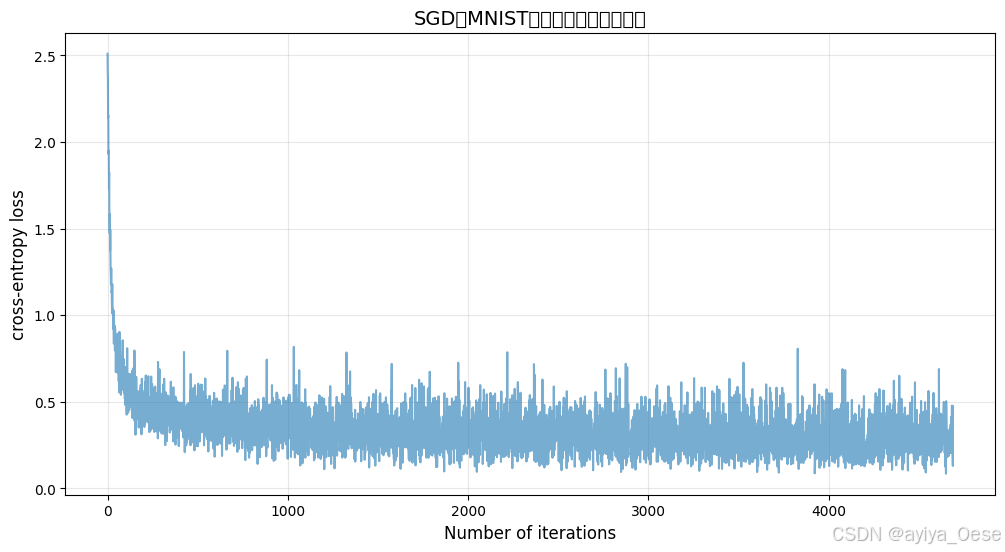
隨機梯度下降(Stochastic Gradient Descent, SGD)
算法原理
與傳統梯度下降的對比:
| 方法 | 梯度計算 | 內存需求 | 收斂性 | 適用場景 |
|---|---|---|---|---|
| 批量梯度下降 | 全數據集 | 高 | 穩定 | 小數據集 |
| SGD | 單樣本 | 低 | 震蕩 | 在線學習 |
| 小批量SGD | 批量樣本 | 中 | 平衡 | 最常見 |
數學表達式:
θ t + 1 = θ t ? α ? θ J ( θ t ; x ( i ) , y ( i ) ) \theta_{t+1} = \theta_t - \alpha \nabla_\theta J(\theta_t; x^{(i)}, y^{(i)}) θt+1?=θt??α?θ?J(θt?;x(i),y(i))
實際應用示例(MNIST分類)
import torchvision
from torch.utils.data import DataLoader# 數據準備
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))
])
train_set = torchvision.datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=64, shuffle=True)# 模型定義
model = torch.nn.Sequential(torch.nn.Flatten(),torch.nn.Linear(784, 10)
)# 優化器配置
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 訓練循環
losses = []
for epoch in range(5):for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = torch.nn.functional.cross_entropy(output, target)loss.backward()optimizer.step()# 記錄損失losses.append(loss.item())# 繪制損失曲線
plt.figure(figsize=(12,6))
plt.plot(losses, alpha=0.6)
plt.title("SGD在MNIST分類任務中的損失曲線", fontsize=14)
plt.xlabel("Number of iterations", fontsize=12)
plt.ylabel("Cross-entropy loss", fontsize=12)
plt.grid(True, alpha=0.3)
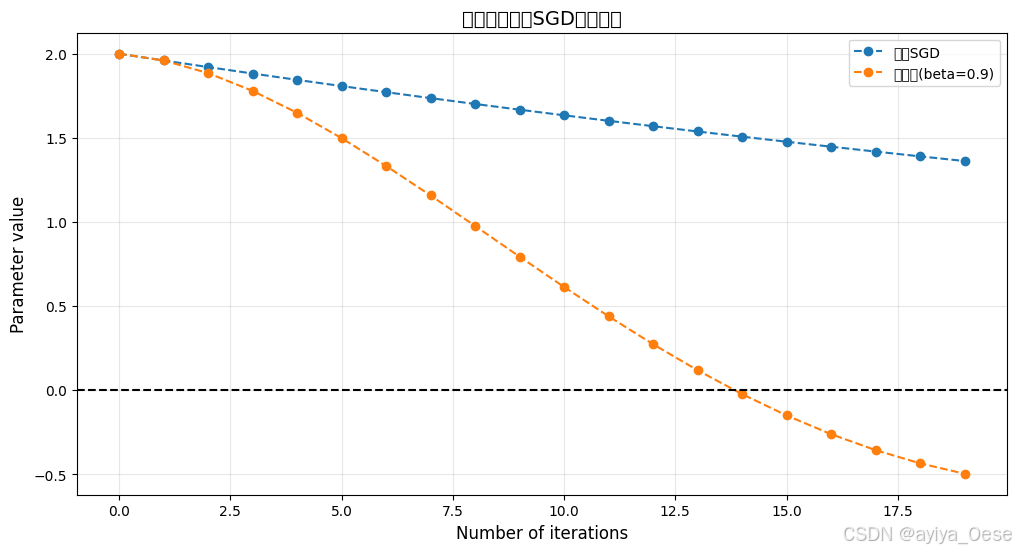
動量法(Momentum)
物理類比與數學表達
動量法引入速度變量 v v v,模擬物體運動慣性:
更新規則:
v t + 1 = β v t ? α ? θ J ( θ t ) θ t + 1 = θ t + v t + 1 \begin{aligned} v_{t+1} &= \beta v_t - \alpha \nabla_\theta J(\theta_t) \\ \theta_{t+1} &= \theta_t + v_{t+1} \end{aligned} vt+1?θt+1??=βvt??α?θ?J(θt?)=θt?+vt+1??
其中 β ∈ [ 0 , 1 ) \beta \in [0,1) β∈[0,1)為動量系數,典型值為0.9
對比實驗
def optimize_with_momentum(lr=0.01, beta=0.9):x = torch.tensor([2.0], requires_grad=True)velocity = 0path = []for _ in range(20):path.append(x.item())loss = x**2loss.backward()with torch.no_grad():velocity = beta * velocity - lr * x.gradx += velocityx.grad.zero_()return path# 運行對比實驗
paths = {'普通SGD': optimize_with_momentum(beta=0),'動量法(beta=0.9)': optimize_with_momentum()
}# 可視化對比
plt.figure(figsize=(12,6))
for label, path in paths.items():plt.plot(path, marker='o', linestyle='--', label=label)plt.title("動量法與普通SGD收斂對比", fontsize=14)
plt.xlabel("Number of iterations", fontsize=12)
plt.ylabel("Parameter value", fontsize=12)
plt.axhline(0, color='black', linestyle='--')
plt.legend()
plt.grid(True, alpha=0.3)
算法選擇指南
| 算法 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| 梯度下降 | 穩定收斂 | 計算成本高 | 小規模數據集 |
| SGD | 內存需求低 | 收斂路徑震蕩 | 在線學習、大規模數據 |
| 動量法 | 加速收斂、抑制震蕩 | 需調參動量系數 | 高維非凸優化 |
實踐建議
- 學習率設置:從3e-4開始嘗試,按數量級調整
- 批量大小:通常選擇2的冪次(32, 64, 128)
- 動量系數:默認0.9,對RNN可嘗試0.99
- 學習率衰減:配合StepLR或CosineAnnealing使用效果更佳
# 最佳實踐示例:帶學習率衰減的動量SGD
optimizer = torch.optim.SGD(model.parameters(),lr=0.1,momentum=0.9,weight_decay=1e-4 # L2正則化
)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)

)
![洛谷P12238 [藍橋杯 2023 國 Java A] 單詞分類](http://pic.xiahunao.cn/洛谷P12238 [藍橋杯 2023 國 Java A] 單詞分類)




)











)