本博客來源于CSDN機器魚,未同意任何人轉載。
更多內容,歡迎點擊本專欄目錄,查看更多內容。
目錄
0 引言
1 數據準備
2 CNN-LSTM模型搭建
3 GTO超參數優化
3.1 GTO函數極值尋優
3.2 GTO優化CNN-LSTM超參數
3.3 主程序
4 結語
0 引言
基于MATLAB2020b的深度學習框架,提出了一種基于CNN-LSTM的多變量電力負荷預測方法,該方法將歷史負荷與氣象的多變量時間序列數據作為輸入,以當天的96個時刻負荷值為輸出,建模學習特征內部動態變化規律,即多變量輸入多輸出模型。同時,針對該模型超參數選擇困難的問題,提出利用人工大猩猩部隊GTO算法實現該模型超參數的優化選擇。
1 數據準備
數據為2016電工杯的電力負荷數據,數據可以在【這里】下載得到。數據包含20140101到20250110的375天多變量數據。每天含96個時刻的負荷數據,即每間隔15分鐘采集一次;以及當天的最高溫度℃、最低溫度℃、平均溫度℃、相對濕度(平均)、降雨量(mm),即一天101個數據。
我們做時間序列預測,采用的是滾動序列建模,即采用1到n天的n*101個值為輸入,第n+1天的96個負荷做輸出,然后第2到n+1天的n*101個值為輸入,第n+2天的96個負荷值為輸出,這樣進行滾動序列建模。數據劃分的代碼如下,我先區分了負荷數據與氣象數據,然后分別歸一化再劃分數據集,其實應該先劃分數據,再對訓練集歸一化,然后用訓練集的參數對測試集(驗證集)做歸一化,這個就不要糾結了,想改的自己改一下:
clc;clear;close all;
%%
data=xlsread('電荷數據.csv','B2:CX376');
%負荷數據--每天96個負荷值,氣象數據 最高溫度℃ 最低溫度℃ 平均溫度℃ 相對濕度(平均) 降雨量(mm)
power=data(:,1:96);
weather=data(:,97:end);
% 歸一化 或者 標準化 看哪個效果好
method=@mapminmax;% mapstd mapminmax
[x1,mappingx1]=method(power');
[x2,mappingx2]=method(weather');
data=[x1' x2'];
% 前steps天steps*101 為輸入,來預測未來一天的96負荷值 為輸出
steps=10;
samples=size(data,1)-steps;%樣本數
for i=1:samplesinput{i,:}=data(i:i+steps-1,:);output(i,:)=data(i+steps,1:96);
end
%% 數據劃分 8:1:1劃分訓練集、驗證集、測試集
n_samples=size(input,1);
n=1:n_samples;%順序劃分用這個n
m1=round(0.8*n_samples);
m2=round(0.9*n_samples);Train_X=input(n(1:m1));
Train_Y=output(n(1:m1),:);Val_X=input(n(m1+1:m2));
Val_Y=output(n(m1+1:m2),:);Ttest_X=input(n(m2+1:end));
Ttest_Y=output(n(m2+1:end),:);2 CNN-LSTM模型搭建
MATLAB2020b自帶的深度學習框架,其中會用到convolution2dLayer,sequenceFoldingLayer,reluLayer,averagePooling2dLayer,lstmLayer,fullyConnectedLayer等。需要的函數主要參考【這里】,據此我們建立CNN-LSTM模型如下:
clc;clear;close all;
%%
data=xlsread('電荷數據.csv','B2:CX376');
%負荷數據--每天96各負荷值,氣象數據 最高溫度℃ 最低溫度℃ 平均溫度℃ 相對濕度(平均) 降雨量(mm)
power=data(:,1:96);
weather=data(:,97:end);
% 歸一化 或者 標準化 看哪個效果好
method=@mapminmax;% mapstd mapminmax
[x1,mappingx1]=method(power');
[x2,mappingx2]=method(weather');
data=[x1' x2'];
% 前steps天steps*101 為輸入,來預測未來一天的96負荷值 為輸出
steps=10;
samples=size(data,1)-steps;%樣本數
for i=1:samplesinput{i,:}=data(i:i+steps-1,:);output(i,:)=data(i+steps,1:96);
end
%% 數據劃分 8:1:1劃分訓練集、驗證集、測試集
n_samples=size(input,1);
n=1:n_samples;%順序劃分用這個n
m1=round(0.8*n_samples);
m2=round(0.9*n_samples);Train_X=input(n(1:m1));
Train_Y=output(n(1:m1),:);Val_X=input(n(m1+1:m2));
Val_Y=output(n(m1+1:m2),:);Ttest_X=input(n(m2+1:end));
Ttest_Y=output(n(m2+1:end),:);%% 網絡搭建
lr=0.001;
epochs=100;
miniBatchSize = 32;
kernel1_num=8;
kernel1_size=3;
pool1_size=2;
kernel2_num=16;
kernel2_size=3;
pool2_size=2;
lstm_node=20;
fc_node=100;rng(0)
input_size=[size(Train_X{1}) 1];
output_size=size(Train_Y,2);
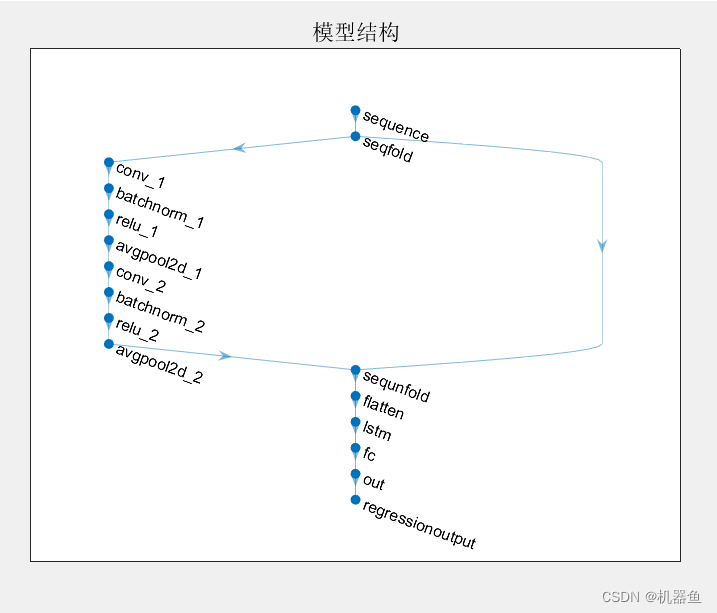
layers = [sequenceInputLayer(input_size,"Name","sequence")sequenceFoldingLayer("Name","seqfold")convolution2dLayer([kernel1_size kernel1_size],kernel1_num,"Name","conv_1","Padding","same")reluLayer("Name","relu_1")averagePooling2dLayer([1 pool1_size],"Name","avgpool2d_1")convolution2dLayer([kernel2_size kernel2_size],kernel2_num,"Name","conv_2","Padding","same")reluLayer("Name","relu_2")averagePooling2dLayer([1 pool2_size],"Name","avgpool2d_2")sequenceUnfoldingLayer("Name","sequnfold")flattenLayer("Name","flatten")lstmLayer(lstm_node,"Name","lstm",'OutputMode','last')fullyConnectedLayer(fc_node,"Name","fc")reluLayer("Name","relu_3")fullyConnectedLayer(output_size,"Name","out")regressionLayer("Name","regressionoutput")];
lgraph = layerGraph(layers);
lgraph = connectLayers(lgraph,"seqfold/miniBatchSize","sequnfold/miniBatchSize");
figure
plot(lgraph)
title("模型結構")options = trainingOptions('adam', ...'MiniBatchSize',miniBatchSize, ...'MaxEpochs',epochs, ...'InitialLearnRate',lr,...'LearnRateSchedule','piecewise',...'LearnRateDropFactor',1,...'Shuffle','every-epoch', ...'ValidationData',{Val_X,Val_Y}, ...'Verbose',1);train_again=1;% 為1就代碼重新訓練模型,為0就是調用訓練好的網絡
if train_again==1[net,traininfo] = trainNetwork(Train_X,Train_Y,lgraph,options);save result/cnn_lstm_net net traininfo
elseload result/cnn_lstm_net
endfigure
plot(traininfo.TrainingLoss);
grid on
title('CNN-LSTM');
xlabel('訓練次數');
ylabel('損失值');%% 預測,
YPred1=predict(net,Ttest_X);
YPred1=method('reverse',YPred1',mappingx1);
Ytest1=method('reverse',Ttest_Y',mappingx1);
[m,n]=size(Ytest1);
real=reshape(Ytest1,[1,m*n]);
pred=reshape(YPred1,[1,m*n]);
result(real,pred,'CNN-LSTM')
save result/cnn_lstm_result real pred
figure
plot(real)
hold on;grid on
plot(pred)
legend('真實值','預測值')function result(true_value,predict_value,type)
disp(type)
rmse=sqrt(mean((true_value-predict_value).^2));
disp(['根均方差(RMSE):',num2str(rmse)])
mae=mean(abs(true_value-predict_value));
disp(['平均絕對誤差(MAE):',num2str(mae)])
mape=mean(abs((true_value-predict_value)./true_value));
disp(['平均相對百分誤差(MAPE):',num2str(mape*100),'%'])R2 = 1 - norm(true_value-predict_value)^2/norm(true_value - mean(true_value))^2;disp(['決定系數(R2):',num2str(R2)])fprintf('\n')我們輸入的是[batchsize steps 101],MATLAB的這個convolution2dLayer是2d卷積,不符合我們輸入結構,好在提供了sequenceInputLayer,sequenceFoldingLayer,sequenceUnfoldingLayer這幾個函數,專門用來接收這樣的數據以便于連接conv2d與lstm。
與此同時,觀察模型搭建那里,我們發現有很多參數需要進行手動設置,這個參數直接影響最后的結果,而設置這些參數我們是沒有指導方法的,因此需要采用某些智能算法來優化選擇。
lr=0.001;
epochs=100;
miniBatchSize = 32;
kernel1_num=8;
kernel1_size=3;
pool1_size=2;
kernel2_num=16;
kernel2_size=3;
pool2_size=2;
lstm_node=20;
fc_node=100;3 GTO超參數優化
3.1 GTO函數極值尋優
首先貼一下網上找的GTO函數極值尋優代碼,如下:
function [Silverback_Score,Silverback,convergence_curve]=GTO(pop_size,max_iter,lower_bound,upper_bound,variables_no,fobj)% initialize Silverback
Silverback=[];
Silverback_Score=inf;%Initialize the first random population of Gorilla
X=initialization(pop_size,variables_no,upper_bound,lower_bound);convergence_curve=zeros(max_iter,1);for i=1:pop_sizePop_Fit(i)=fobj(X(i,:));%#okif Pop_Fit(i)<Silverback_ScoreSilverback_Score=Pop_Fit(i);Silverback=X(i,:);end
endGX=X(:,:);
lb=ones(1,variables_no).*lower_bound;
ub=ones(1,variables_no).*upper_bound;%% Controlling parameterp=0.03;
Beta=3;
w=0.8;%%Main loop
for It=1:max_itera=(cos(2*rand)+1)*(1-It/max_iter);C=a*(2*rand-1);%% Exploration:for i=1:pop_sizeif rand<pGX(i,:) =(ub-lb)*rand+lb;elseif rand>=0.5Z = unifrnd(-a,a,1,variables_no);H=Z.*X(i,:);GX(i,:)=(rand-a)*X(randi([1,pop_size]),:)+C.*H;elseGX(i,:)=X(i,:)-C.*(C*(X(i,:)- GX(randi([1,pop_size]),:))+rand*(X(i,:)-GX(randi([1,pop_size]),:))); %ok okendendendGX = boundaryCheck(GX, lower_bound, upper_bound);% Group formation operationfor i=1:pop_sizeNew_Fit= fobj(GX(i,:));if New_Fit<Pop_Fit(i)Pop_Fit(i)=New_Fit;X(i,:)=GX(i,:);endif New_Fit<Silverback_ScoreSilverback_Score=New_Fit;Silverback=GX(i,:);endend%% Exploitation:for i=1:pop_sizeif a>=wg=2^C;delta= (abs(mean(GX)).^g).^(1/g);GX(i,:)=C*delta.*(X(i,:)-Silverback)+X(i,:);elseif rand>=0.5h=randn(1,variables_no);elseh=randn(1,1);endr1=rand;GX(i,:)= Silverback-(Silverback*(2*r1-1)-X(i,:)*(2*r1-1)).*(Beta*h);endendGX = boundaryCheck(GX, lower_bound, upper_bound);% Group formation operationfor i=1:pop_sizeNew_Fit= fobj(GX(i,:));if New_Fit<Pop_Fit(i)Pop_Fit(i)=New_Fit;X(i,:)=GX(i,:);endif New_Fit<Silverback_ScoreSilverback_Score=New_Fit;Silverback=GX(i,:);endendconvergence_curve(It)=Silverback_Score;end
end% This function initialize the first population of search agents
function Positions=initialization(SearchAgents_no,dim,ub,lb)Boundary_no= size(ub,2); % numnber of boundaries% If the boundaries of all variables are equal and user enter a signle
% number for both ub and lb
if Boundary_no==1Positions=rand(SearchAgents_no,dim).*(ub-lb)+lb;
end% If each variable has a different lb and ub
if Boundary_no>1for i=1:dimub_i=ub(i);lb_i=lb(i);Positions(:,i)=rand(SearchAgents_no,1).*(ub_i-lb_i)+lb_i;end
end
end
function [ X ] = boundaryCheck(X, lb, ub)for i=1:size(X,1)FU=X(i,:)>ub;FL=X(i,:)<lb;X(i,:)=(X(i,:).*(~(FU+FL)))+ub.*FU+lb.*FL;
end
end% This function draw the benchmark functionsfunction func_plot(func_name)[lb,ub,dim,fobj]=Get_Functions_details(func_name);switch func_name case 'F1' x=-100:2:100; y=x; %[-100,100]case 'F2' x=-100:2:100; y=x; %[-10,10]case 'F3' x=-100:2:100; y=x; %[-100,100]case 'F4' x=-100:2:100; y=x; %[-100,100]case 'F5' x=-200:2:200; y=x; %[-5,5]case 'F6' x=-100:2:100; y=x; %[-100,100]case 'F7' x=-1:0.03:1; y=x %[-1,1]case 'F8' x=-500:10:500;y=x; %[-500,500]case 'F9' x=-5:0.1:5; y=x; %[-5,5] case 'F10' x=-20:0.5:20; y=x;%[-500,500]case 'F11' x=-500:10:500; y=x;%[-0.5,0.5]case 'F12' x=-10:0.1:10; y=x;%[-pi,pi]case 'F13' x=-5:0.08:5; y=x;%[-3,1]case 'F14' x=-100:2:100; y=x;%[-100,100]case 'F15' x=-5:0.1:5; y=x;%[-5,5]case 'F16' x=-1:0.01:1; y=x;%[-5,5]case 'F17' x=-5:0.1:5; y=x;%[-5,5]case 'F18' x=-5:0.06:5; y=x;%[-5,5]case 'F19' x=-5:0.1:5; y=x;%[-5,5]case 'F20' x=-5:0.1:5; y=x;%[-5,5] case 'F21' x=-5:0.1:5; y=x;%[-5,5]case 'F22' x=-5:0.1:5; y=x;%[-5,5] case 'F23' x=-5:0.1:5; y=x;%[-5,5]
end L=length(x);
f=[];for i=1:Lfor j=1:Lif strcmp(func_name,'F15')==0 && strcmp(func_name,'F19')==0 && strcmp(func_name,'F20')==0 && strcmp(func_name,'F21')==0 && strcmp(func_name,'F22')==0 && strcmp(func_name,'F23')==0f(i,j)=fobj([x(i),y(j)]);endif strcmp(func_name,'F15')==1f(i,j)=fobj([x(i),y(j),0,0]);endif strcmp(func_name,'F19')==1f(i,j)=fobj([x(i),y(j),0]);endif strcmp(func_name,'F20')==1f(i,j)=fobj([x(i),y(j),0,0,0,0]);end if strcmp(func_name,'F21')==1 || strcmp(func_name,'F22')==1 ||strcmp(func_name,'F23')==1f(i,j)=fobj([x(i),y(j),0,0]);end end
endsurfc(x,y,f,'LineStyle','none');end
% This function containts full information and implementations of the benchmark
% lb is the lower bound: lb=[lb_1,lb_2,...,lb_d]
% up is the uppper bound: ub=[ub_1,ub_2,...,ub_d]
% dim is the number of variables (dimension of the problem)function [lb,ub,dim,fobj] = Get_Functions_details(F)switch Fcase 'F1'fobj = @F1;lb=-100;ub=100;dim=30;case 'F2'fobj = @F2;lb=-10;ub=10;dim=30;case 'F3'fobj = @F3;lb=-100;ub=100;dim=30;case 'F4'fobj = @F4;lb=-100;ub=100;dim=30;case 'F5'fobj = @F5;lb=-30;ub=30;dim=30;case 'F6'fobj = @F6;lb=-100;ub=100;dim=30;case 'F7'fobj = @F7;lb=-1.28;ub=1.28;dim=30;case 'F8'fobj = @F8;lb=-500;ub=500;dim=30;case 'F9'fobj = @F9;lb=-5.12;ub=5.12;dim=30;case 'F10'fobj = @F10;lb=-32;ub=32;dim=30;case 'F11'fobj = @F11;lb=-600;ub=600;dim=30;case 'F12'fobj = @F12;lb=-50;ub=50;dim=30;case 'F13'fobj = @F13;lb=-50;ub=50;dim=30;case 'F14'fobj = @F14;lb=-65.536;ub=65.536;dim=2;case 'F15'fobj = @F15;lb=-5;ub=5;dim=4;case 'F16'fobj = @F16;lb=-5;ub=5;dim=2;case 'F17'fobj = @F17;lb=[-5,0];ub=[10,15];dim=2;case 'F18'fobj = @F18;lb=-2;ub=2;dim=2;case 'F19'fobj = @F19;lb=0;ub=1;dim=3;case 'F20'fobj = @F20;lb=0;ub=1;dim=6; case 'F21'fobj = @F21;lb=0;ub=10;dim=4; case 'F22'fobj = @F22;lb=0;ub=10;dim=4; case 'F23'fobj = @F23;lb=0;ub=10;dim=4;
endend% F1function o = F1(x)
o=sum(x.^2);
end% F2function o = F2(x)
o=sum(abs(x))+prod(abs(x));
end% F3function o = F3(x)
dim=size(x,2);
o=0;
for i=1:dimo=o+sum(x(1:i))^2;
end
end% F4function o = F4(x)
o=max(abs(x));
end% F5function o = F5(x)
dim=size(x,2);
o=sum(100*(x(2:dim)-(x(1:dim-1).^2)).^2+(x(1:dim-1)-1).^2);
end% F6function o = F6(x)
o=sum(abs((x+.5)).^2);
end% F7function o = F7(x)
dim=size(x,2);
o=sum([1:dim].*(x.^4))+rand;
end% F8function o = F8(x)
o=sum(-x.*sin(sqrt(abs(x))));
end% F9function o = F9(x)
dim=size(x,2);
o=sum(x.^2-10*cos(2*pi.*x))+10*dim;
end% F10function o = F10(x)
dim=size(x,2);
o=-20*exp(-.2*sqrt(sum(x.^2)/dim))-exp(sum(cos(2*pi.*x))/dim)+20+exp(1);
end% F11function o = F11(x)
dim=size(x,2);
o=sum(x.^2)/4000-prod(cos(x./sqrt([1:dim])))+1;
end% F12function o = F12(x)
dim=size(x,2);
o=(pi/dim)*(10*((sin(pi*(1+(x(1)+1)/4)))^2)+sum((((x(1:dim-1)+1)./4).^2).*...
(1+10.*((sin(pi.*(1+(x(2:dim)+1)./4)))).^2))+((x(dim)+1)/4)^2)+sum(Ufun(x,10,100,4));
end% F13function o = F13(x)
dim=size(x,2);
o=.1*((sin(3*pi*x(1)))^2+sum((x(1:dim-1)-1).^2.*(1+(sin(3.*pi.*x(2:dim))).^2))+...
((x(dim)-1)^2)*(1+(sin(2*pi*x(dim)))^2))+sum(Ufun(x,5,100,4));
end% F14function o = F14(x)
aS=[-32 -16 0 16 32 -32 -16 0 16 32 -32 -16 0 16 32 -32 -16 0 16 32 -32 -16 0 16 32;,...
-32 -32 -32 -32 -32 -16 -16 -16 -16 -16 0 0 0 0 0 16 16 16 16 16 32 32 32 32 32];for j=1:25bS(j)=sum((x'-aS(:,j)).^6);
end
o=(1/500+sum(1./([1:25]+bS))).^(-1);
end% F15function o = F15(x)
aK=[.1957 .1947 .1735 .16 .0844 .0627 .0456 .0342 .0323 .0235 .0246];
bK=[.25 .5 1 2 4 6 8 10 12 14 16];bK=1./bK;
o=sum((aK-((x(1).*(bK.^2+x(2).*bK))./(bK.^2+x(3).*bK+x(4)))).^2);
end% F16function o = F16(x)
o=4*(x(1)^2)-2.1*(x(1)^4)+(x(1)^6)/3+x(1)*x(2)-4*(x(2)^2)+4*(x(2)^4);
end% F17function o = F17(x)
o=(x(2)-(x(1)^2)*5.1/(4*(pi^2))+5/pi*x(1)-6)^2+10*(1-1/(8*pi))*cos(x(1))+10;
end% F18function o = F18(x)
o=(1+(x(1)+x(2)+1)^2*(19-14*x(1)+3*(x(1)^2)-14*x(2)+6*x(1)*x(2)+3*x(2)^2))*...(30+(2*x(1)-3*x(2))^2*(18-32*x(1)+12*(x(1)^2)+48*x(2)-36*x(1)*x(2)+27*(x(2)^2)));
end% F19function o = F19(x)
aH=[3 10 30;.1 10 35;3 10 30;.1 10 35];cH=[1 1.2 3 3.2];
pH=[.3689 .117 .2673;.4699 .4387 .747;.1091 .8732 .5547;.03815 .5743 .8828];
o=0;
for i=1:4o=o-cH(i)*exp(-(sum(aH(i,:).*((x-pH(i,:)).^2))));
end
end% F20function o = F20(x)
aH=[10 3 17 3.5 1.7 8;.05 10 17 .1 8 14;3 3.5 1.7 10 17 8;17 8 .05 10 .1 14];
cH=[1 1.2 3 3.2];
pH=[.1312 .1696 .5569 .0124 .8283 .5886;.2329 .4135 .8307 .3736 .1004 .9991;...
.2348 .1415 .3522 .2883 .3047 .6650;.4047 .8828 .8732 .5743 .1091 .0381];
o=0;
for i=1:4o=o-cH(i)*exp(-(sum(aH(i,:).*((x-pH(i,:)).^2))));
end
end% F21function o = F21(x)
aSH=[4 4 4 4;1 1 1 1;8 8 8 8;6 6 6 6;3 7 3 7;2 9 2 9;5 5 3 3;8 1 8 1;6 2 6 2;7 3.6 7 3.6];
cSH=[.1 .2 .2 .4 .4 .6 .3 .7 .5 .5];o=0;
for i=1:5o=o-((x-aSH(i,:))*(x-aSH(i,:))'+cSH(i))^(-1);
end
end% F22function o = F22(x)
aSH=[4 4 4 4;1 1 1 1;8 8 8 8;6 6 6 6;3 7 3 7;2 9 2 9;5 5 3 3;8 1 8 1;6 2 6 2;7 3.6 7 3.6];
cSH=[.1 .2 .2 .4 .4 .6 .3 .7 .5 .5];o=0;
for i=1:7o=o-((x-aSH(i,:))*(x-aSH(i,:))'+cSH(i))^(-1);
end
end% F23function o = F23(x)
aSH=[4 4 4 4;1 1 1 1;8 8 8 8;6 6 6 6;3 7 3 7;2 9 2 9;5 5 3 3;8 1 8 1;6 2 6 2;7 3.6 7 3.6];
cSH=[.1 .2 .2 .4 .4 .6 .3 .7 .5 .5];o=0;
for i=1:10o=o-((x-aSH(i,:))*(x-aSH(i,:))'+cSH(i))^(-1);
end
endfunction o=Ufun(x,a,k,m)
o=k.*((x-a).^m).*(x>a)+k.*((-x-a).^m).*(x<(-a));
end主函數如下所示,將上面幾個函數復制進matlab保存成m文件,然后運行下面這個主函數即可:?
clear ;close all;clc;format compact
%% 人工大猩猩部隊優化算法
N=30; % Number of search agents
T=500; % Maximum number of iterations
Function_name='F4'; % Name of the test function that can be from F1 to F23 (Table 1,2,3 in the paper) 設定適應度函數
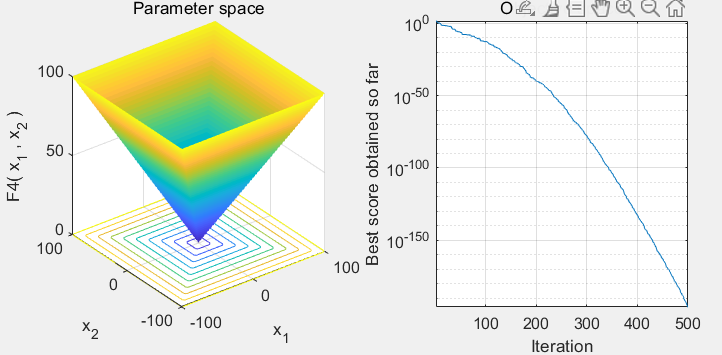
[lb,ub,dim,fobj]=Get_Functions_details(Function_name); %設定邊界以及優化函數[BestF,BestP,Convergence_curve]=GTO(N,T,lb,ub,dim,fobj);figure('Position',[269 240 660 290])
subplot(1,2,1);
func_plot(Function_name);
title('Parameter space')
xlabel('x_1');
ylabel('x_2');
zlabel([Function_name,'( x_1 , x_2 )'])subplot(1,2,2);
semilogy(Convergence_curve)
hold on;title('Objective space')
xlabel('Iteration');
ylabel('Best score obtained so far');
axis tight
grid on
box on
3.2 GTO優化CNN-LSTM超參數
看過我之前的博客都知道,任意優化算法來做超參數尋優是不需要懂優化算法的原理的,看3.1可知我們下載的這份GTO代碼是用來做極小值尋優的就行。然后遵循以下步驟進行代碼修改:
步驟1:知道要優化的參數與優化范圍。顯然就是第2節提到的11個參數。代碼如下,首先改寫lb與ub,然后初始化的時候注意除了學習率,其他的都是整數。并將原來里面的邊界判斷,改成了Bounds函數,方便在計算適應度函數值的時候轉化成整數與小數。如果學習率的位置不在最后,而是在其他位置,就需要改隨機初始化位置和Bounds函數與fitness函數里對應的地方,具體怎么改就不說了,很簡單。
%% 人工大猩猩部隊優化算法
function [Silverback,convergence_curve,process]=GTO(P_train,P_valid,T_train,T_valid)
%% 參數設置
%lb ub為尋優范圍 第一列是學習率[0.0001-0.01]
%然后分別是訓練次數 batchsize 卷積層1的卷積核數量、大小 池化層1的大小
%卷積層2的卷積核數量、大小 池化層1的大小 lstm層的節點數 全連接層的節點數
lb=[1e-4 10 8 1 1 1 1 1 1 1 1];
ub=[1e-2 100 64 20 10 5 20 10 5 50 200];
variables_no=length(lb);
pop_size=5;%種群數量
max_iter=10;%尋優代數% initialize Silverback
Silverback=[];
Silverback_Score=inf;%Initialize the first random population of Gorilla
for i=1:pop_size%隨機初始化速度,隨機初始化位置for j=1:variables_noX( i, j ) = (ub(j)-lb(j))*rand+lb(j);end
endconvergence_curve=zeros(max_iter,1);for i=1:pop_sizeX(i,:) = Bounds( X(i,:), lb, ub );Pop_Fit(i)=fitness(X(i,:),P_train,P_valid,T_train,T_valid);if Pop_Fit(i)<Silverback_ScoreSilverback_Score=Pop_Fit(i);Silverback=X(i,:);end
endGX=X(:,:);%% Controlling parameterp=0.03;
Beta=3;
w=0.8;%%Main loop
for It=1:max_itera=(cos(2*rand)+1)*(1-It/max_iter);C=a*(2*rand-1);%% Exploration:for i=1:pop_sizeif rand<pGX(i,:) =(ub-lb).*rand(1,variables_no)+ub;elseif rand>=0.5Z = unifrnd(-a,a,1,variables_no);H=Z.*X(i,:);GX(i,:)=(rand-a)*X(randi([1,pop_size]),:)+C.*H;elseGX(i,:)=X(i,:)-C.*(C*(X(i,:)- GX(randi([1,pop_size]),:))+rand*(X(i,:)-GX(randi([1,pop_size]),:))); %ok okendendend% Group formation operationfor i=1:pop_sizeGX(i,:) = Bounds( GX(i,:), lb, ub );New_Fit= fitness(GX(i,:),P_train,P_valid,T_train,T_valid);if New_Fit<Pop_Fit(i)Pop_Fit(i)=New_Fit;X(i,:)=GX(i,:);endif New_Fit<Silverback_ScoreSilverback_Score=New_Fit;Silverback=GX(i,:);endend%% Exploitation:for i=1:pop_sizeif a>=wg=2^C;delta= (abs(mean(GX)).^g).^(1/g);GX(i,:)=C*delta.*(X(i,:)-Silverback)+X(i,:);elseif rand>=0.5h=randn(1,variables_no);elseh=randn(1,1);endr1=rand;GX(i,:)= Silverback-(Silverback*(2*r1-1)-X(i,:)*(2*r1-1)).*(Beta*h);endend% Group formation operationfor i=1:pop_sizeGX(i,:) = Bounds( GX(i,:), lb, ub );New_Fit= fitness(GX(i,:),P_train,P_valid,T_train,T_valid);if New_Fit<Pop_Fit(i)Pop_Fit(i)=New_Fit;X(i,:)=GX(i,:);endif New_Fit<Silverback_ScoreSilverback_Score=New_Fit;Silverback=GX(i,:);endendIt,Silverback_Score,Silverbackconvergence_curve(It)=Silverback_Score;process(It,:)= Silverback;
end
endfunction s = Bounds( s, Lb, Ub)
temp = s;
for i=1:length(s)if temp(:,i)>Ub(i) || temp(:,i)<Lb(i)temp(:,i) =rand*(Ub(i)-Lb(i))+Lb(i);endif i>1temp(:,i)=round(temp(:,i));%除了學習率 其他的都是整數end
end
s = temp;
end
步驟2:知道優化的目標。優化的目標是提高的網絡的準確率,而GTO代碼我們這個代碼是最小值優化的,所以我們的目標可以是最小化CNN-LSTM的預測誤差。預測誤差具體是,測試集(或驗證集)的預測值與真實值之間的均方差。
步驟3:構建適應度函數。通過步驟2我們已經知道優化的目標,即采用GTO去找11個值,用這11個值構建的CNN-LSTM網絡,具備誤差最小化。觀察下面的代碼,首先我們將GTO的值傳進來,然后轉成需要的11個值,然后構建網絡,訓練集訓練、測試集預測,計算預測值與真實值的mse,將mse作為結果傳出去作為適應度值。
function fit=fitness(x,P_train,P_valid,T_train,T_valid)
lr=x(1);
epochs=x(2);
miniBatchSize = x(3);
kernel1_num=x(4);
kernel1_size=x(5);
pool1_size=x(6);
kernel2_num=x(7);
kernel2_size=x(8);
pool2_size=x(9);
lstm_node=x(10);
fc_node=x(11);rng(0)
input_size=[size(P_train{1}) 1];
output_size=size(T_train,2);
layers = [sequenceInputLayer(input_size,"Name","sequence")sequenceFoldingLayer("Name","seqfold")convolution2dLayer([kernel1_size kernel1_size],kernel1_num,"Name","conv_1","Padding","same")reluLayer("Name","relu_1")averagePooling2dLayer([1 pool1_size],"Name","avgpool2d_1")convolution2dLayer([kernel2_size kernel2_size],kernel2_num,"Name","conv_2","Padding","same")reluLayer("Name","relu_2")averagePooling2dLayer([1 pool2_size],"Name","avgpool2d_2")sequenceUnfoldingLayer("Name","sequnfold")flattenLayer("Name","flatten")lstmLayer(lstm_node,"Name","lstm",'OutputMode','last')fullyConnectedLayer(fc_node,"Name","fc")reluLayer("Name","relu_3")fullyConnectedLayer(output_size,"Name","out")regressionLayer("Name","regressionoutput")];
lgraph = layerGraph(layers);
lgraph = connectLayers(lgraph,"seqfold/miniBatchSize","sequnfold/miniBatchSize");options = trainingOptions('adam', ...'MiniBatchSize',miniBatchSize, ...'MaxEpochs',epochs, ...'InitialLearnRate',lr,...'LearnRateSchedule','piecewise',...'LearnRateDropFactor',1,...'Shuffle','every-epoch', ...'Verbose',0);[net,~] = trainNetwork(P_train,T_train,lgraph,options);
YPred1=predict(net,P_valid);
[m,n]=size(T_valid);
real=reshape(T_valid,[1,m*n]);
pred=reshape(YPred1,[1,m*n]);
fit =mse(real-pred);% 以mse為適應度函數,優化算法目的就是找到一組超參數 使網絡的mse最低
rng((100*sum(clock)))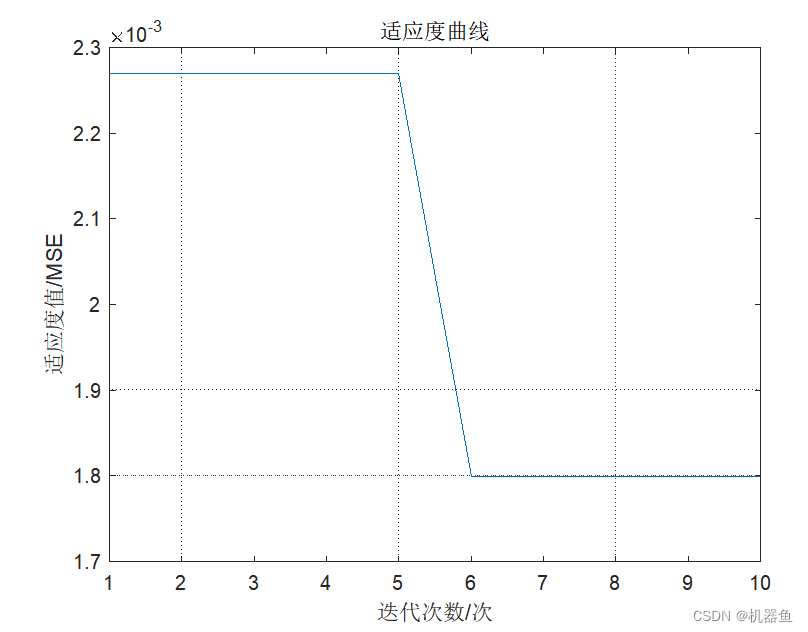
3.3 主程序
?以下是調用上面這個優化算法的主程序,如下:
clc;clear;close all;format compact;format short
%%
data=xlsread('電荷數據.csv','B2:CX376');
%負荷數據--每天96各負荷值,氣象數據 最高溫度℃ 最低溫度℃ 平均溫度℃ 相對濕度(平均) 降雨量(mm)
power=data(:,1:96);
weather=data(:,97:end);
% 歸一化 或者 標準化 看哪個效果好
method=@mapminmax;% mapstd mapminmax
[x1,mappingx1]=method(power');
[x2,mappingx2]=method(weather');
data=[x1' x2'];
% 前steps天steps*101 為輸入,來預測未來一天的96負荷值 為輸出
steps=10;
samples=size(data,1)-steps;%樣本數
for i=1:samplesinput{i,:}=data(i:i+steps-1,:);output(i,:)=data(i+steps,1:96);
end
%% 數據劃分 8:1:1劃分訓練集、驗證集、測試集
n_samples=size(input,1);
n=1:n_samples;
m1=round(0.8*n_samples);
m2=round(0.9*n_samples);Train_X=input(n(1:m1));
Train_Y=output(n(1:m1),:);Val_X=input(n(m1+1:m2));
Val_Y=output(n(m1+1:m2),:);Ttest_X=input(n(m2+1:end));
Ttest_Y=output(n(m2+1:end),:);
%% 參數優化
optimization=0;%是否重新優化
if optimization==1[x ,fit_gen,process]=GTO(Train_X,Val_X,Train_Y,Val_Y);save result/optim_result x fit_gen process
elseload result/optim_result
end
figure
plot(fit_gen)
grid on
title('適應度曲線')
xlabel('迭代次數/次')
ylabel('適應度值/MSE')
%% 網絡搭建
lr=x(1)
epochs=x(2)
miniBatchSize = x(3)
kernel1_num=x(4)
kernel1_size=x(5)
pool1_size=x(6)
kernel2_num=x(7)
kernel2_size=x(8)
pool2_size=x(9)
lstm_node=x(10)
fc_node=x(11)rng(0)
input_size=[size(Train_X{1}) 1];
output_size=size(Train_Y,2);
layers = [sequenceInputLayer(input_size,"Name","sequence")sequenceFoldingLayer("Name","seqfold")convolution2dLayer([kernel1_size kernel1_size],kernel1_num,"Name","conv_1","Padding","same")reluLayer("Name","relu_1")averagePooling2dLayer([1 pool1_size],"Name","avgpool2d_1")convolution2dLayer([kernel2_size kernel2_size],kernel2_num,"Name","conv_2","Padding","same")reluLayer("Name","relu_2")averagePooling2dLayer([1 pool2_size],"Name","avgpool2d_2")sequenceUnfoldingLayer("Name","sequnfold")flattenLayer("Name","flatten")lstmLayer(lstm_node,"Name","lstm",'OutputMode','las')fullyConnectedLayer(fc_node,"Name","fc")reluLayer("Name","relu_3")fullyConnectedLayer(output_size,"Name","out")regressionLayer("Name","regressionoutput")];
lgraph = layerGraph(layers);
lgraph = connectLayers(lgraph,"seqfold/miniBatchSize","sequnfold/miniBatchSize");
figure
plot(lgraph)
title("模型結構")
options = trainingOptions('adam', ...'MiniBatchSize',miniBatchSize, ...'MaxEpochs',epochs, ...'InitialLearnRate',lr,...'LearnRateSchedule','piecewise',...'LearnRateDropFactor',1,...'Shuffle','every-epoch', ...'ValidationData',{Val_X,Val_Y}, ...'Verbose',1);train_again=0;% 為1就代碼重新訓練模型,為0就是調用訓練好的網絡
if train_again==1[net,traininfo] = trainNetwork(Train_X,Train_Y,lgraph,options);save result/cnn_lstm_net2 net traininfo
elseload result/cnn_lstm_net2
endfigure
plot(traininfo.TrainingLoss);
grid on
title('CNN-LSTM');
xlabel('訓練次數');
ylabel('損失值');%% 預測,
YPred1=predict(net,Ttest_X);
YPred1=method('reverse',YPred1',mappingx1);
Ytest1=method('reverse',Ttest_Y',mappingx1);
[m,n]=size(Ytest1);
real=reshape(Ytest1,[1,m*n]);
pred=reshape(YPred1,[1,m*n]);
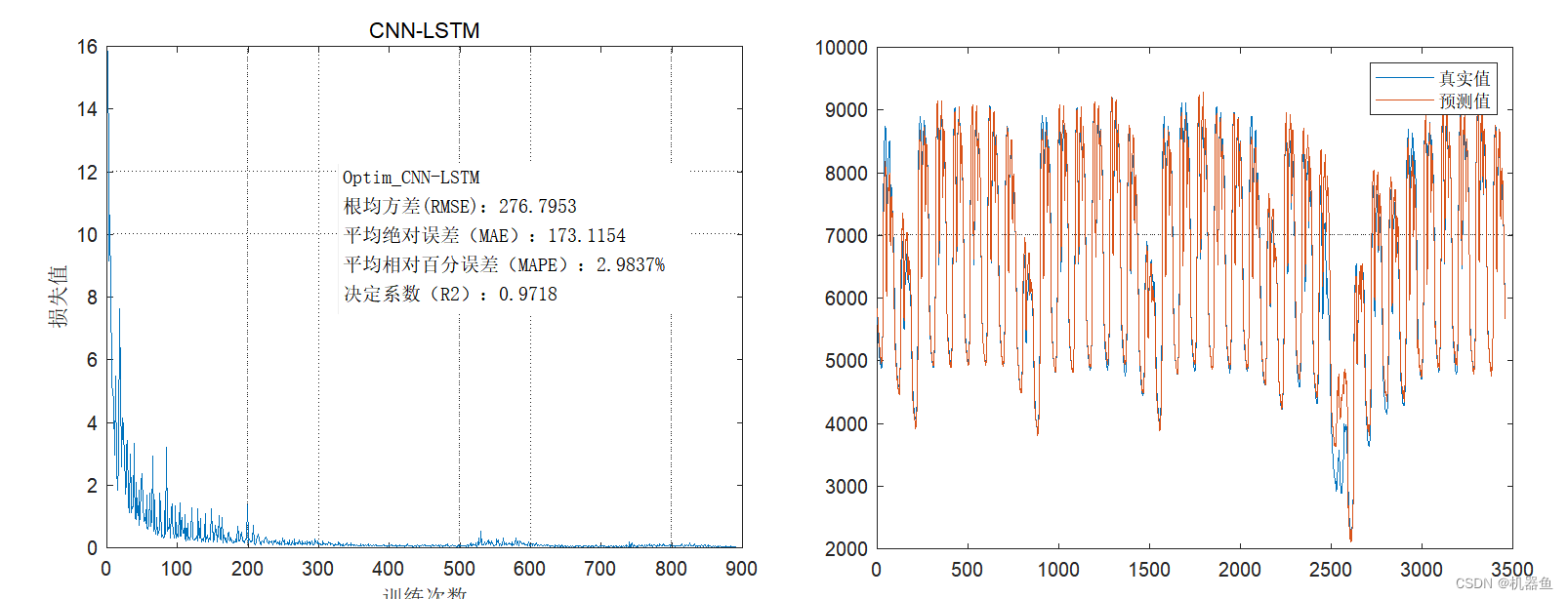
result(real,pred,'Optim_CNN-LSTM')
save result/optim_cnn_lstm_result real pred
figure
plot(real)
hold on;grid on
plot(pred)
legend('真實值','預測值')4 結語
優化網絡超參數的格式都是這樣的!只要會改一種,那么隨便拿一份能跑通的優化算法,在不管原理的情況下,都能用來優化網絡的超參數。
更多內容【點擊專欄】目錄,您的點贊、關注、收藏是我更新【MATLAB神經網絡1000個案例分析】的動力。



)

)


)

——第二步和第三步)




: linux開發機有線連接android設備)



