文章目錄
- 論文解決的問題
- 提出的算法以及啟發點
論文解決的問題
首先這是 Self-Supervised 3D Human mesh recovery from a single image with uncertainty-aware learning (AAAI 2024)的論文筆記。該文中主要提出了一個自監督的framework用于人體的姿態恢復。主要是解決了現有的方法對大型數據集的依賴。
提出的算法以及啟發點
論文總體的框架其實相對比較簡單
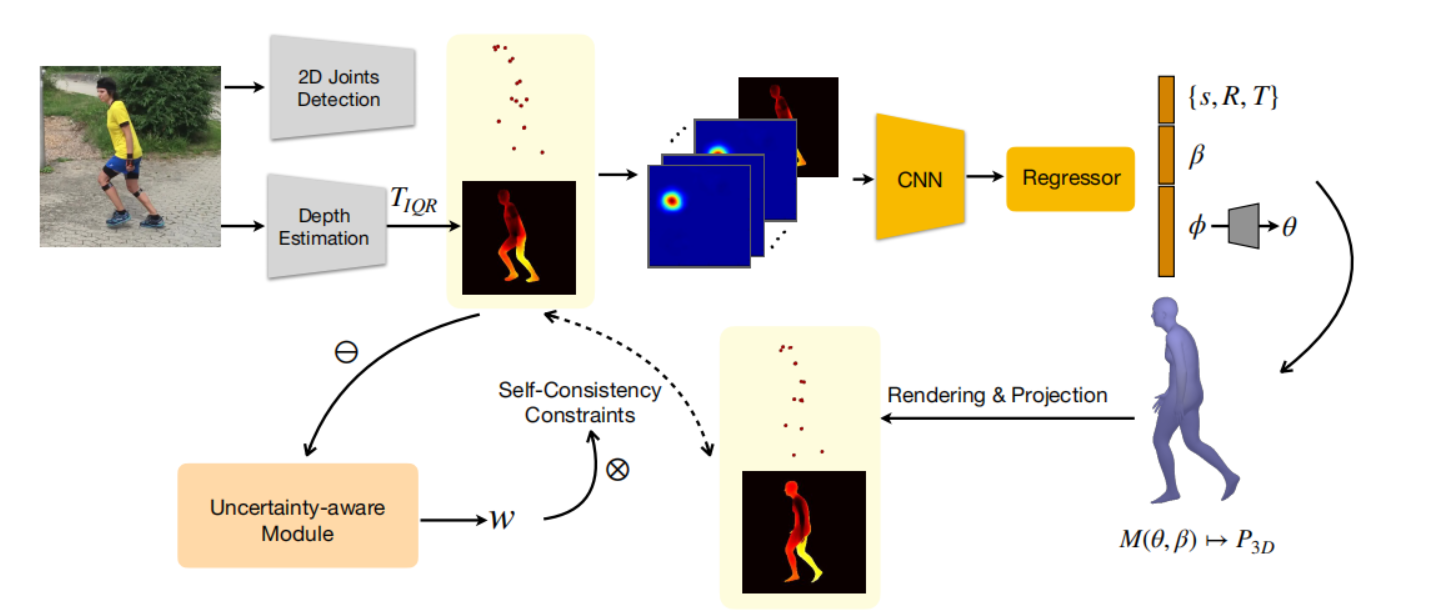
大概思路主要是集中再學習深度與關節之間的連續性。首先深度和2D關節的提取使用的方法都相對較老。整體的自監督模式也之前的方法其實很類似,就是通過2D 圖像提取人體的特征,比如關節特征,然后預測2.5D的特征,比如深度,為連接2D-3D打下基礎。然后依賴SMPL這樣的參數模型將2D 和2.5D特征轉移到3D 空間中。然后將3D的參數模型,2D化(提取關節點,和深度圖。)然后與圖片預測的關節點和3D 圖在 L2 loss的監督下,進行學習。
本文中提到了一個新的概念,就是使用相鄰關節點的深度差距來作為consistancy的一個評判標準是相對比較新的一個概念。 在3D到2D的投影過程中,關節長度(2D骨骼長度)與深度差距(Depth Discrepancy, DD)之間的關系存在反比趨勢, 當骨骼在3D空間中平行于圖像平面(即深度差DD≈0)時,其2D投影長度最大, 當骨骼朝向或遠離相機(DD增大)時,2D投影長度會因透視縮短而變小。例如,若手臂完全朝向相機(DD很大),2D圖像中手臂會顯得非常短(甚至接近一個點)。通過這個約束來作為自監督學習的基礎。
對我當前的研究有什么啟發。我當前通過生成模型將單目照片變成幾何連續的多視角照片。用于提供更加穩定和準確的2D 特征,也可從這些2D圖像中提取出更加穩定的3D cues,用于之后2D-3D 的橋梁。是否使用本文的方式來修正人體姿態的同時修正一些單視角的語義偏差?引入關節和深度的加權不確定性損失來抑制一些高不確定性的輸出。也是抑制人體重建中 不可能姿勢的出現。 該思想可嘗試泛化到語義層面。

)


)

——第二步和第三步)




: linux開發機有線連接android設備)







(第2版)學習筆記 01.環境搭建)