目錄
摘要
18 層次聚類
18.1 本章工作任務
18.2 本章技能目標
18.3 本章簡介
18.4 編程實戰
18.5 本章總結
18.6 本章作業
本章已完結!!!
摘要
?
本章實現的工作是:首先導入20名學生的3科成績,然后根據優先聚合距離最近的兩個數據組的聚類標準,得到由20名學生劃分成的不同簇類。
本章掌握的技能是:1、使用 SciPy 包計算歐式距離。2、使用 dendrogram 畫出聚類樹圖。3、使用 matplotlib 包實現數據可視化,繪制熱度圖。
18 層次聚類
18.1 本章工作任務
采用層次聚類編寫程序,根據語文、數學、英語成績對不同學生進行分層。1、算法的輸入是:20名學生的語文、數學和英語成績。2、算法的模型需要求解的是:任意兩個數據集之間的距離。3、算法的結果是:20個數據組被先后聚合,最終逐層聚成一類。
18.2 本章技能目標
掌握層次聚類的原理。
使用Python計算出歐式距離。
使用Python畫出聚類樹圖。
使用Python畫出熱度圖。
18.3 本章簡介
層次聚類分析是指:一種分層聚類的方法,對目標數據集使用某種標準,先后進行聚合,直至聚合到最后一層,得到一個由所有數據集逐層聚合成的集合。
層次聚類分析算法可以解決的實際應用問題是:已知20名學生的語文、數學和英語3科成績(每一個學生的3科成績相當于一個原始數據組),計算出任意兩個數據組之間的距離后,將距離最近的先聚合,得到新的數據組,再計算任意兩個數據組的距離,將距離最近的先聚合,以此類推,聚成一類。
本章的重點是:層次聚類分析的理解和使用。
18.4 編程實戰
步驟1 引入相關包。引入pandas、numpy,seaborn和matplotlib,命名為pd,np,sns 和 plt。引入linkage、dendrogram 和 AgglomerativeClustering,以指定層次聚類判別相識度方法、畫聚類樹圖和熱度圖。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import pdist, squareform
from scipy.cluster.hierarchy import linkage
from scipy.cluster.hierarchy import dendrogram
from sklearn.cluster import AgglomerativeClustering
import seaborn as sns步驟2 顯示數據的絕對路徑,導入要使用的數據。
import os
thisFilePath = os.path.abspath('.')
os.chdir(thisFilePath)
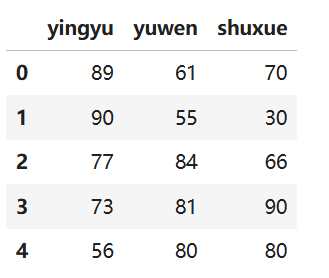
os.getcwd()輸出結果:'D:\\MyPythonFiles'myData = pd.read_csv('myData_.csv')
myData.head()輸出結果:
步驟3 計算距離關聯矩陣,任意兩個簇之間的歐式距離,使用single-linkage(即兩簇內最近元素的距離)作為組距。
row_clusters = linkage(pdist(myData, metric = 'euclidean'), method = 'single')
num = len(pdist(myData, metric = 'euclidean'))步驟4 生成聚類的結果。
print(pd.DataFrame(row_clusters, columns = ['row_label1', 'row_label2', 'distance', 'new'], index=['cluster %d'% (i+1) for i in range(row_clusters.shape[0])]))輸出結果:row_label1 row_label2 distance new
cluster 1 0.0 17.0 0.000000 2.0
cluster 2 3.0 11.0 0.000000 2.0
cluster 3 2.0 10.0 0.000000 2.0
cluster 4 19.0 22.0 0.000000 3.0
cluster 5 1.0 18.0 0.000000 2.0
cluster 6 6.0 14.0 4.000000 2.0
cluster 7 5.0 15.0 6.928203 2.0
cluster 8 4.0 12.0 9.000000 2.0
cluster 9 13.0 21.0 11.401754 3.0
cluster 10 26.0 28.0 13.000000 5.0
cluster 11 8.0 16.0 14.000000 2.0
cluster 12 7.0 29.0 17.000000 6.0
cluster 13 27.0 31.0 17.058722 8.0
cluster 14 23.0 32.0 19.131126 11.0
cluster 15 20.0 33.0 22.158520 13.0
cluster 16 30.0 34.0 25.019992 15.0
cluster 17 25.0 35.0 26.851443 17.0
cluster 18 9.0 36.0 32.124757 18.0
cluster 19 24.0 37.0 32.202484 20.0提示:
(1) 聚類樹形成的過程:將符合 single-linkage 的兩個簇合并為一個新簇,去除合并前的簇,之后迭代進行此過程。當合并到只有一個簇(聚類樹的主干)時,迭代完成,聚類結束。
(2) 聚類的結果:row_label1 和 row_label2 表示聚類合并前的兩個簇內最近元素,distance 表示合并前兩個簇的距離,new 即為新簇內的元素個數。
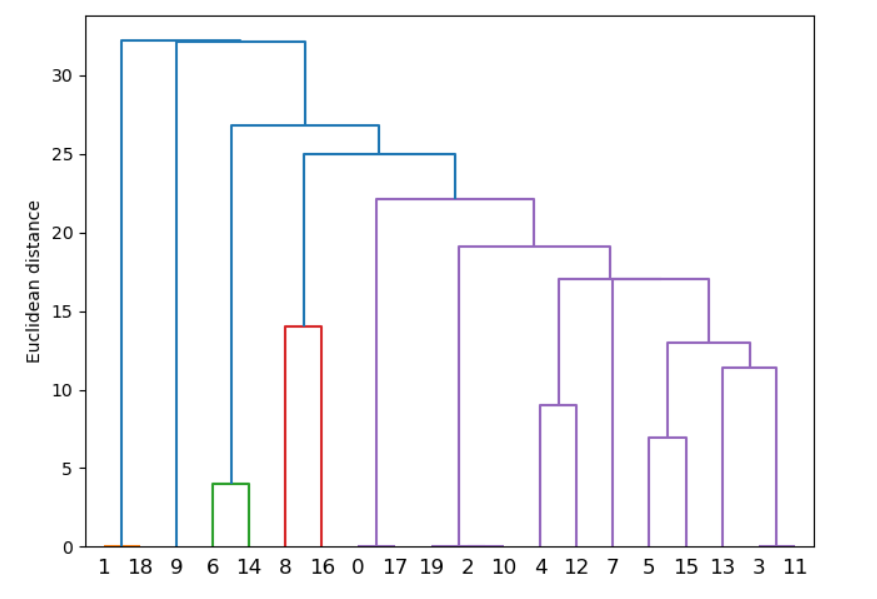
步驟5 畫出聚類樹樹圖。
row_dendr = dendrogram(row_clusters, 1)
plt.tight_layout()
plt.ylabel('Euclidean distance')
plt.show()輸出結果:
提示:
圖的橫坐標是簇的類別,縱坐標是簇與簇之間的歐式距離(即簇與簇內元素的最近距離),同色的折線表示兩個簇合并。
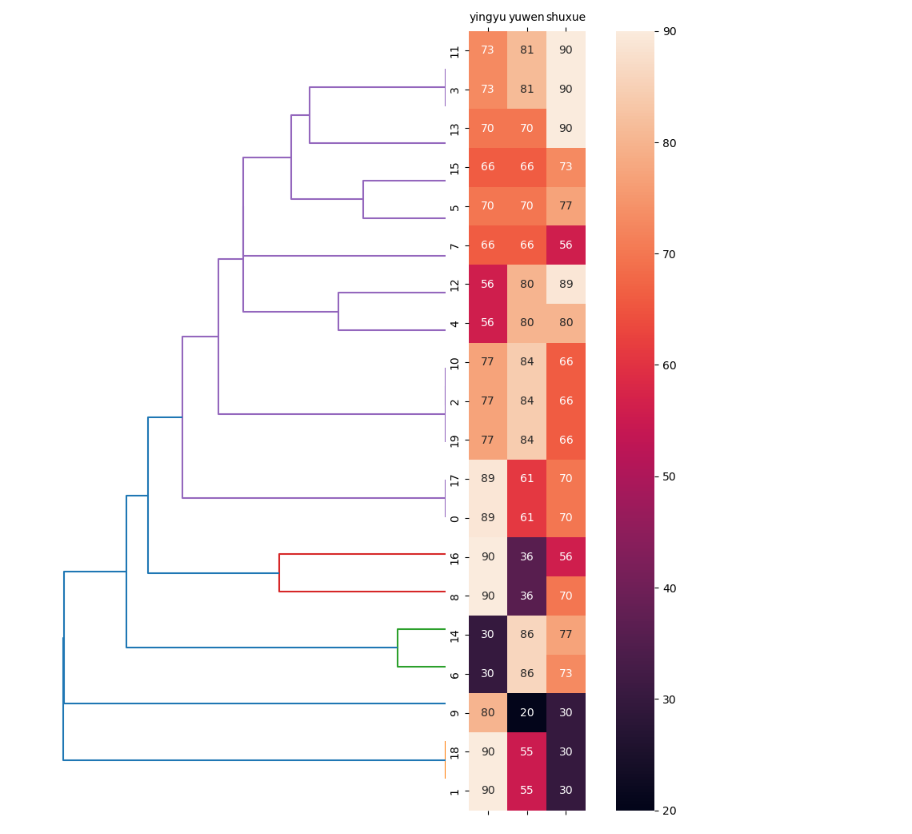
步驟6 畫出熱度圖。
%matplotlib inline
fig = plt.figure(figsize=(12, 13))
axd = fig.add_axes([0.02, 0.138, 0.418, 0.719])
row_dendr = dendrogram(row_clusters, orientation='left')
myData_rowclust = myData.iloc[row_dendr['leaves'][::-1]]
axm = fig.add_axes([0.08, 0.1255, 0.63, 0.75])
cax = axm.matshow(myData_rowclust, interpolation='nearest', cmap='hot_r')
axd.set_xticks([])
axd.set_yticks([])for i in axd.spines.values():i.set_visible(False)
axm = sns.heatmap(myData_rowclust, annot = True, fmt = "d")
plt.show()輸出結果:
?
提示:
顏色深度和數據大小正相關(最右邊的長條圖說明了顏色深淺和數值大小的關系,顏色越深,數值越大),從熱圖上可以直觀地看出簇內元素之間的距離關系,直觀理解樹圖的合并過程。
18.5 本章總結
本章實現的工作是:首先導入20名學生的3科成績,然后根據優先聚合距離最近的兩個數據組的聚類標準,得到由20名學生劃分成的不同簇類。
本章掌握的技能是:1、使用 SciPy 包計算歐式距離。2、使用 dendrogram 畫出聚類樹圖。3、使用 matplotlib 包實現數據可視化,繪制熱度圖。
18.6 本章作業
實現本章的案例,即求出任意兩個數組之間的距離,畫出聚類樹圖和熱度圖。

》閱讀筆記:p4-p5)
















——進一步完善內核)
