Training data-efficient image transformers & distillation through attention
- 摘要-Abstract
- 引言-Introduction
- 相關工作-Related Work
- 視覺Transformer:概述-Vision transformer: overview
- 通過注意力機制蒸餾-Distillation through attention
- 實驗-Experiments
- 訓練細節和消融實驗-Training details & ablation
- 結論-Conclusion

論文鏈接
GitHub鏈接
本文提出數據高效的圖像 Transformer(DeiT),僅在 Imagenet 上訓練就能得到與卷積神經網絡(convnets)性能相當的無卷積 Transformer。引入基于蒸餾 token 的師生策略,該策略能讓學生模型通過注意力機制向教師模型學習,尤其是以 convnet 為教師時效果顯著,使得 DeiT 在 Imagenet 上最高可達 85.2% 的準確率,且在遷移學習任務中表現出色。
摘要-Abstract
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. These high-performing vision transformers are pre-trained with hundreds of millions of images using a large infrastructure, thereby limiting their adoption.
In this work, we produce competitive convolution-free transformers by training on Imagenet only. We train them on a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop) on ImageNet with no external data.
More importantly, we introduce a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention. We show the interest of this token-based distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks.
最近,純粹基于注意力機制的神經網絡已被證明能夠處理圖像分類等圖像理解任務。這些高性能的視覺Transformer通過大規模的基礎設施,利用數億張圖像進行預訓練,這限制了它們的廣泛應用。
在這項工作中,我們僅通過在ImageNet數據集上進行訓練,就得到了具有競爭力的無卷積Transformer。我們在一臺計算機上用不到3天的時間完成訓練。我們的參考視覺Transformer(8600萬個參數)在不使用外部數據的情況下,在ImageNet上實現了單裁剪83.1%的Top-1準確率。
更重要的是,我們引入了一種專門針對Transformer的師生策略。該策略依賴于一個蒸餾token,確保學生模型通過注意力機制向教師模型學習。我們展示了這種基于token的蒸餾方法的優勢,特別是在使用卷積神經網絡作為教師模型時。這使得我們在ImageNet(我們在此獲得了高達85.2%的準確率)以及遷移到其他任務時,都能取得與卷積神經網絡相媲美的結果。
引言-Introduction
該部分主要介紹了研究背景、目標與貢獻。指出視覺Transformer雖能處理圖像理解任務,但預訓練依賴大量數據和計算資源。本文旨在僅用Imagenet訓練出有競爭力的無卷積Transformer,并提出特定的師生蒸餾策略,具體內容如下:
- 研究背景:卷積神經網絡(CNNs)憑借大規模訓練集(如Imagenet)在圖像理解任務中占據主導地位。受自然語言處理領域基于注意力模型成功的影響,研究人員開始探索在卷積網絡中融入注意力機制,同時也有將Transformer成分移植到卷積網絡的混合架構出現。視覺Transformer(ViT)直接應用自然語言處理架構處理圖像分類,在使用大規模私有數據集(JFT-300M)預訓練時效果優異,但存在訓練數據需求大、計算資源消耗多以及在少量數據上泛化能力差的問題。
- 研究目標:僅在Imagenet數據集上進行訓練,于單個8-GPU節點花費2-3天訓練出與卷積神經網絡性能相當的無卷積Transformer,即Data-efficient image Transformers(DeiT),改進訓練策略,減少對大規模訓練數據的依賴。
- 研究貢獻
- 不含卷積層的神經網絡在無外部數據情況下,于ImageNet上取得了具有競爭力的結果。新模型DeiT-S和DeiT-Ti參數更少,可分別視為ResNet-50和ResNet-18的對應模型。
- 引入基于蒸餾token的新蒸餾程序,該token與類token作用相似,但旨在再現教師模型估計的標簽,通過注意力機制與類token交互,顯著優于傳統蒸餾方法。
- 經蒸餾的圖像Transformer從卷積網絡教師模型學習的效果,優于從性能相當的Transformer教師模型的學習效果。
- 在多個流行公共基準測試(如CIFAR-10、CIFAR-100等)的下游任務中,基于ImageNet預訓練的DeiT模型表現出色。
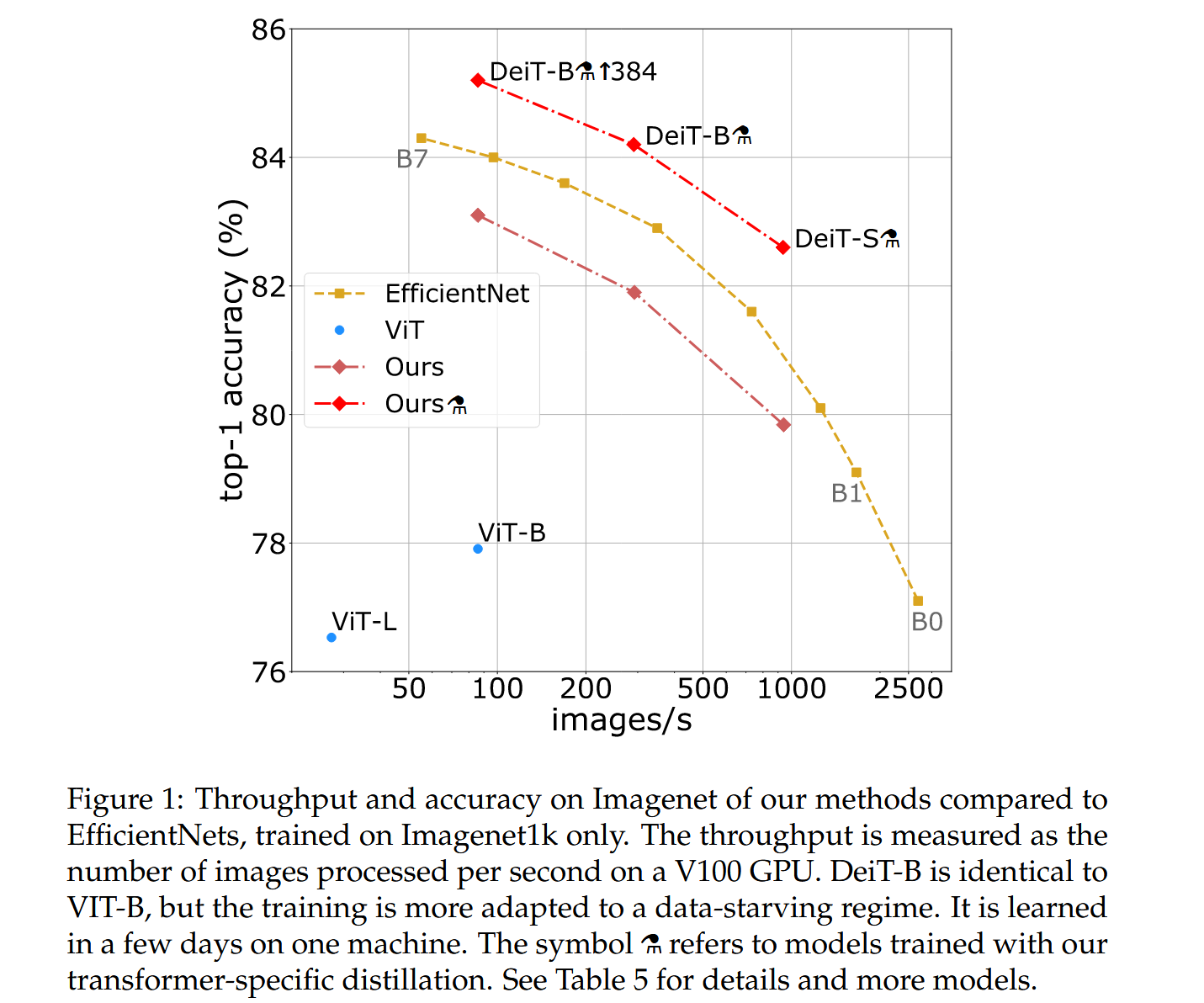
圖1:我們的方法與僅在Imagenet1k上訓練的EfficientNet相比,在Imagenet上的吞吐量和準確率。吞吐量是指在V100 GPU上每秒處理的圖像數量。DeiT-B與ViT-B架構相同,但DeiT-B的訓練更適用于數據稀缺的情況,它可以在一臺機器上用幾天時間完成訓練。符號?表示使用我們特定于Transformer的蒸餾方法訓練的模型。更多詳細信息和模型請見表5。
相關工作-Related Work
該部分主要回顧了與本文研究相關的工作,涵蓋圖像分類領域的發展、視覺Transformer(ViT)的進展、Transformer架構在自然語言處理中的地位以及知識蒸餾(KD)的應用,具體內容如下:
- 圖像分類的發展歷程:圖像分類是計算機視覺的核心任務,常作為衡量圖像理解進展的基準,其成果通常可遷移至檢測、分割等相關任務。自2012年AlexNet出現,卷積神經網絡(CNNs)便主導該領域,成為事實上的標準,ImageNet數據集推動了CNNs架構和學習方法的不斷演進。
- 視覺變換器(ViT)的發展:早期Transformer用于圖像分類的性能不如CNNs,但結合了CNNs和Transformer(包括自注意力機制)的混合架構在圖像分類、檢測、視頻處理、無監督對象發現以及統一文本 - 視覺任務等方面展現出競爭力。ViT的出現縮小了與ImageNet上最先進的CNNs的差距,盡管其性能顯著,但ViT需要在大量精心整理的數據上進行預訓練才能有效,而本文僅使用Imagenet1k數據集就實現了強大的性能。
- Transformer架構在自然語言處理中的地位:Transformer架構由Vaswani等人提出用于機器翻譯,目前是所有自然語言處理(NLP)任務的參考模型。許多用于圖像分類的CNNs改進方法都受到Transformer的啟發,例如Squeeze and Excitation、Selective Kernel和Split-Attention Networks等都利用了類似于Transformer自注意力機制的原理。
- 知識蒸餾(KD)的應用:KD是一種訓練范式,學生模型利用來自強大教師網絡的“軟”標簽(教師softmax函數的輸出向量)進行訓練,而非僅使用“硬”標簽(分數最高值對應的標簽),這可以提高學生模型的性能,也可看作是將教師模型壓縮為較小的學生模型的一種形式。KD能夠以軟方式在學生模型中傳遞歸納偏差,例如使用卷積模型作為教師模型可以在Transformer模型中引入卷積相關的偏差。本文研究了用卷積網絡或Transformer作為教師模型對Transformer學生模型進行蒸餾,并引入了一種特定于Transformer的新蒸餾過程,展示其優越性。
視覺Transformer:概述-Vision transformer: overview
該部分主要介紹了視覺Transformer的關鍵組件和特性,包括多頭自注意力層、圖像Transformer塊、位置編碼和分辨率處理,為理解后續提出的DeiT模型及相關改進奠定基礎,具體內容如下:
- 多頭自注意力層(MSA):注意力機制基于可訓練的關聯記憶,通過查詢向量與鍵向量的內積匹配,經縮放和softmax歸一化后得到權重,進而對值向量加權求和得到輸出。Self-attention層中,查詢、鍵和值矩陣由輸入向量通過線性變換計算得出。多頭自注意力層則是將h個自注意力函數應用于輸入,再重新投影到指定維度 。其公式為 A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K ? / d ) V Attention(Q, K, V)=Softmax\left(Q K^{\top} / \sqrt{d}\right) V Attention(Q,K,V)=Softmax(QK?/d?)V,其中 Q Q Q、 K K K、 V V V分別為查詢、鍵和值矩陣, d d d為維度。
- 圖像Transformer塊:在MSA層之上添加前饋網絡(FFN)構成完整的Transformer塊。FFN由兩個線性層和中間的GeLu激活函數組成,先將維度從 D D D擴展到 4 D 4D 4D,再還原回 D D D。MSA和FFN都通過殘差連接和層歸一化操作,提升模型性能。
- 視覺Transformer處理圖像的方式:基于ViT模型,將固定大小的輸入RGB圖像分解為多個固定尺寸(16×16像素)的圖像塊,每個圖像塊通過線性層投影保持維度不變。由于Transformer塊對圖像塊嵌入順序不變性,需添加固定或可訓練的位置嵌入來融入位置信息,同時還會添加一個可訓練的類token,最終僅使用類向量預測輸出。
- 位置編碼與分辨率:在訓練和微調網絡時,改變輸入圖像分辨率時,保持圖像塊大小不變會導致輸入圖像塊數量改變。因Transformer塊和類token的架構,模型和分類器無需修改即可處理更多token,但需調整位置嵌入。常見做法是在改變分辨率時對位置編碼進行插值,實驗證明這種方法在后續微調階段有效。
通過注意力機制蒸餾-Distillation through attention
該部分主要介紹了通過注意力機制進行蒸餾的方法,涵蓋了硬蒸餾與軟蒸餾的對比,以及引入蒸餾令牌改進蒸餾效果的內容,具體如下:
- 軟蒸餾與硬標簽蒸餾
- 軟蒸餾:軟蒸餾通過最小化教師模型和學生模型softmax輸出之間的Kullback - Leibler散度來實現。其蒸餾目標為 L g l o b a l = ( 1 ? λ ) L C E ( ψ ( Z s ) , y ) + λ τ 2 K L ( ψ ( Z s / τ ) , ψ ( Z t / τ ) ) \mathcal{L}_{global }=(1-\lambda) \mathcal{L}_{CE}\left(\psi\left(Z_{s}\right), y\right)+\lambda \tau^{2} KL\left(\psi\left(Z_{s} / \tau\right), \psi\left(Z_{t} / \tau\right)\right) Lglobal?=(1?λ)LCE?(ψ(Zs?),y)+λτ2KL(ψ(Zs?/τ),ψ(Zt?/τ)),其中 Z t Z_{t} Zt?、 Z s Z_{s} Zs? 分別是教師和學生模型的logits, τ \tau τ 為蒸餾溫度, λ \lambda λ 用于平衡散度損失和交叉熵損失, ψ \psi ψ 為softmax函數。
- 硬標簽蒸餾:該方法將教師模型的硬決策作為真實標簽。其目標函數為 L g l o b a l h a r d D i s t i l l = 1 2 L C E ( ψ ( Z s ) , y ) + 1 2 L C E ( ψ ( Z s ) , y t ) \mathcal{L}_{global }^{hardDistill }=\frac{1}{2} \mathcal{L}_{CE}\left(\psi\left(Z_{s}\right), y\right)+\frac{1}{2} \mathcal{L}_{CE}\left(\psi\left(Z_{s}\right), y_{t}\right) LglobalhardDistill?=21?LCE?(ψ(Zs?),y)+21?LCE?(ψ(Zs?),yt?),其中 y t = a r g m a x c Z t ( c ) y_{t}=argmax_{c} Z_{t}(c) yt?=argmaxc?Zt?(c) 是教師模型的硬決策。硬標簽可通過標簽平滑轉化為軟標簽,實驗中 ε \varepsilon ε 固定為0.1。
- 蒸餾token
- token作用:在初始嵌入(圖像塊和類token)中添加新的蒸餾token,它與類token類似,通過自注意力與其他嵌入交互,網絡輸出時其目標是再現教師模型預測的(硬)標簽,而非真實標簽,從而讓模型從教師輸出中學習。
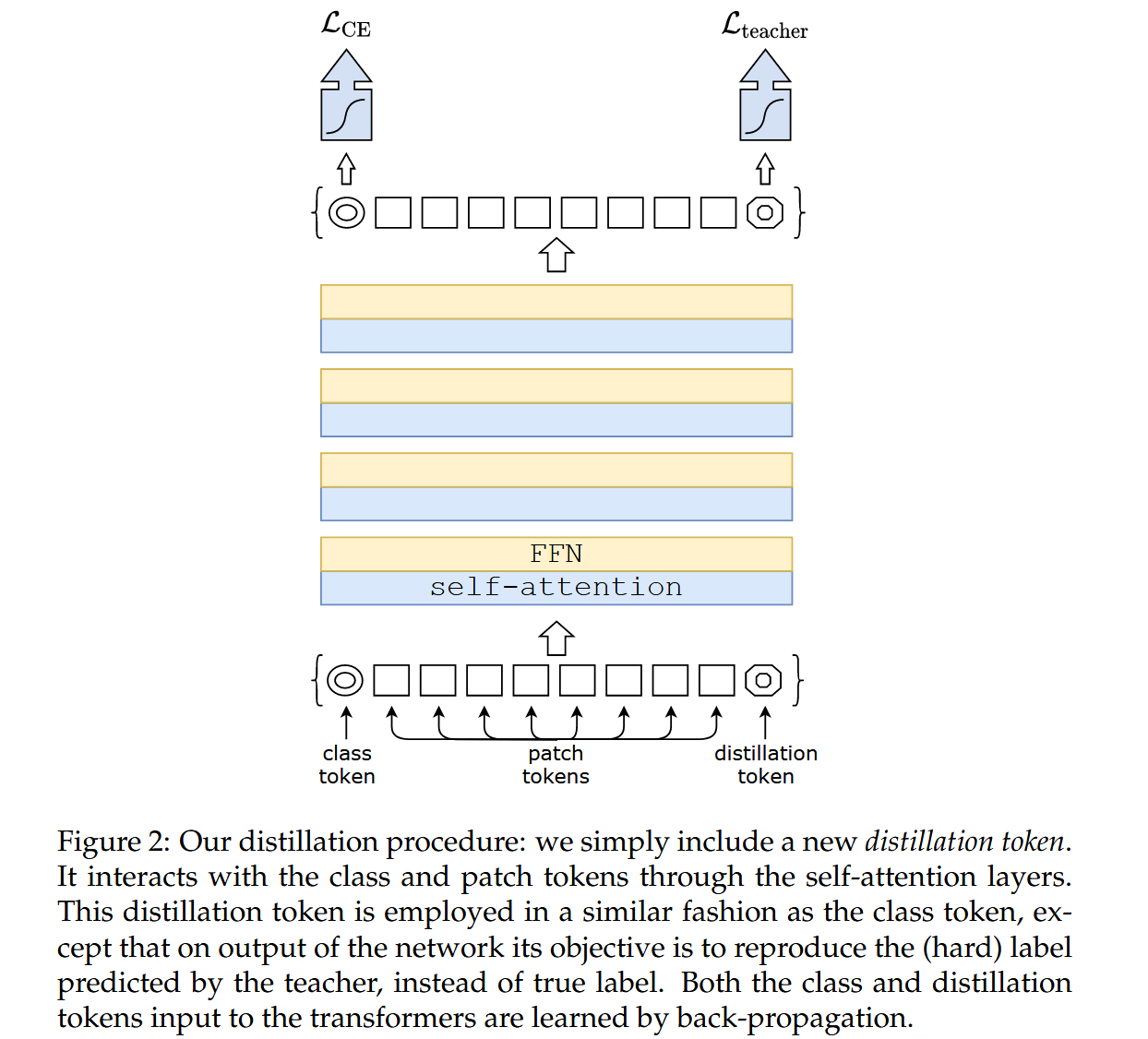
圖2:我們的蒸餾過程:我們簡單地引入了一個新的蒸餾token。它通過自注意力層與類別token和圖像塊token進行交互。這個蒸餾token的使用方式與類別token類似,不同之處在于,在網絡輸出時,它的目標是再現教師模型預測的(硬)標簽,而不是真實標簽。輸入到Transformer中的類別token和蒸餾token都是通過反向傳播學習得到的。 - 對比實驗:實驗表明,學習到的類token和蒸餾token會收斂到不同向量。與簡單添加額外類token相比,蒸餾token能顯著提升模型性能。例如,兩個隨機初始化的類token在訓練中會收斂到相同向量,對分類性能無提升,而蒸餾策略則優于普通蒸餾基線。
- token作用:在初始嵌入(圖像塊和類token)中添加新的蒸餾token,它與類token類似,通過自注意力與其他嵌入交互,網絡輸出時其目標是再現教師模型預測的(硬)標簽,而非真實標簽,從而讓模型從教師輸出中學習。
- 微調與分類
- 微調:在更高分辨率的微調階段,同時使用真實標簽和教師預測,使用與目標分辨率相同的教師模型(通常由低分辨率教師模型轉換得到)。僅使用真實標簽會降低教師模型的作用,導致性能下降。
- 分類:測試時,Transformer產生的類嵌入和蒸餾嵌入都可與線性分類器結合進行圖像標簽推斷。推薦方法是對兩個分類器的softmax輸出進行后期融合來進行預測。
實驗-Experiments
該部分主要通過一系列實驗,對模型、蒸餾策略、效率與精度權衡以及遷移學習等方面進行了分析和評估,具體內容如下:
-
Transformer模型:文中的DeiT架構與ViT相同但訓練策略和蒸餾令牌有差異,不使用MLP頭預訓練,僅用線性分類器。介紹了DeiT - B、DeiT - S和DeiT - Ti三種模型,其參數數量和計算量依次減小。
表1:我們DeiT架構的變體。較大的模型DeiT-B與ViT-B具有相同的架構。不同模型之間僅有的變化參數是嵌入維度和頭數,我們保持每個頭的維度不變(等于64)。較小的模型參數數量較少,吞吐量更快。吞吐量是針對分辨率為224×224的圖像進行測量的。

-
蒸餾策略分析
-
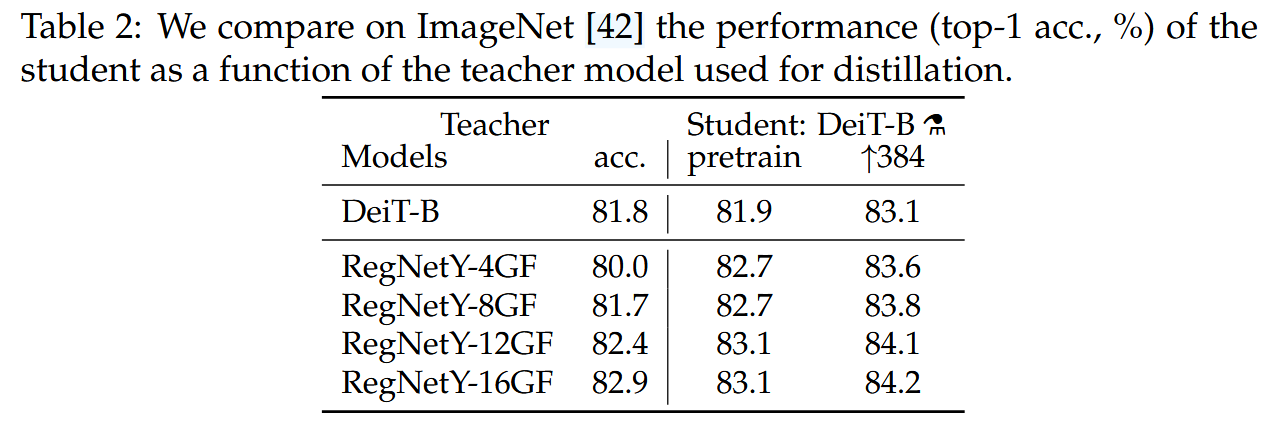
不同教師模型的影響:使用convnet作為教師模型比使用transformer性能更好。以RegNetY - 16GF為默認教師模型,它在ImageNet上top - 1準確率達82.9%。
表2:我們在ImageNet數據集上比較了作為蒸餾所用教師模型函數的學生模型性能(top-1準確率,%)。
-
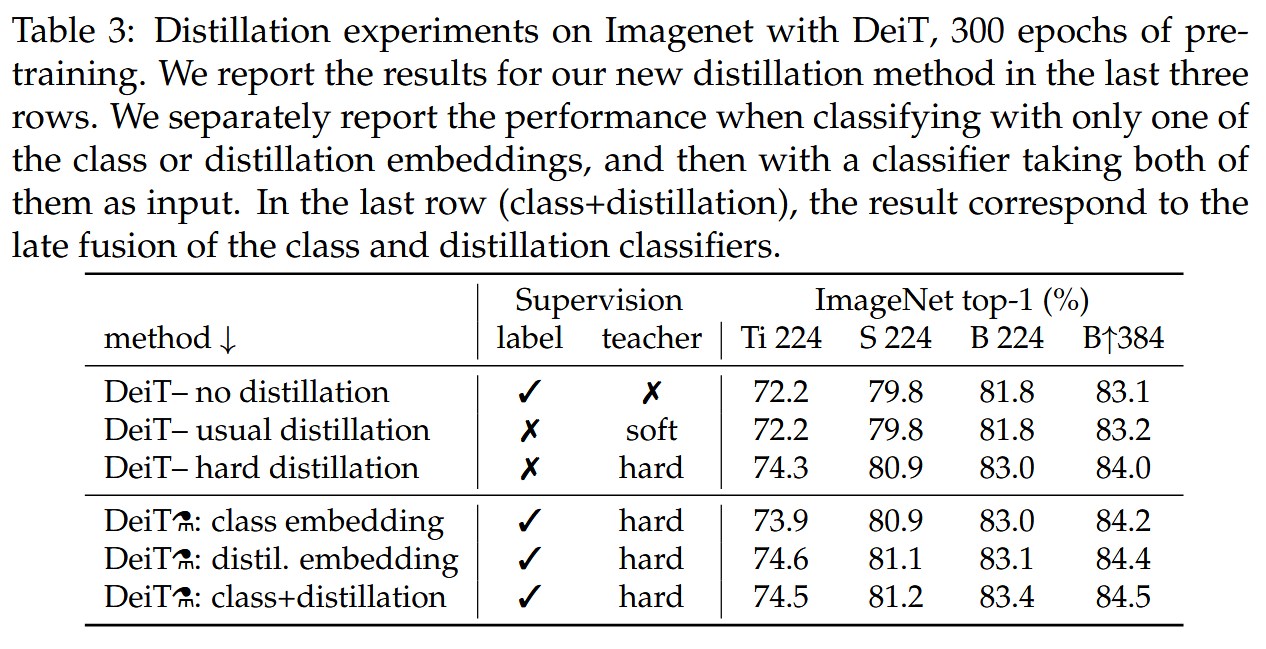
不同蒸餾方法對比:硬蒸餾在transformer中表現優于軟蒸餾,如在224×224分辨率下,硬蒸餾準確率可達83.0%,而軟蒸餾僅為81.8%。基于蒸餾token的策略進一步提升了性能,聯合使用類token和蒸餾token的分類器效果最佳。
表3:使用DeiT在ImageNet上進行的蒸餾實驗,預訓練300個epoch。最后三行報告了我們新蒸餾方法的結果。我們分別報告僅使用類嵌入或蒸餾嵌入進行分類時的性能,以及將兩者都作為輸入的分類器的性能。在最后一行(類+蒸餾)中,結果對應于類分類器和蒸餾分類器的后期融合。
-
蒸餾令牌的優勢:蒸餾token比類token效果略好,且與convnet預測更相關,在初始訓練階段優勢明顯。
表4:卷積神經網絡、圖像Transformer和經過蒸餾的變換器之間的分歧分析:我們報告了所有分類器對中分類結果不同的樣本比例,即不同決策的比率。我們納入了兩個未經過蒸餾的模型(一個RegNetY和DeiT-B),以便比較我們經過蒸餾的模型和分類頭與這些教師模型的相關性。
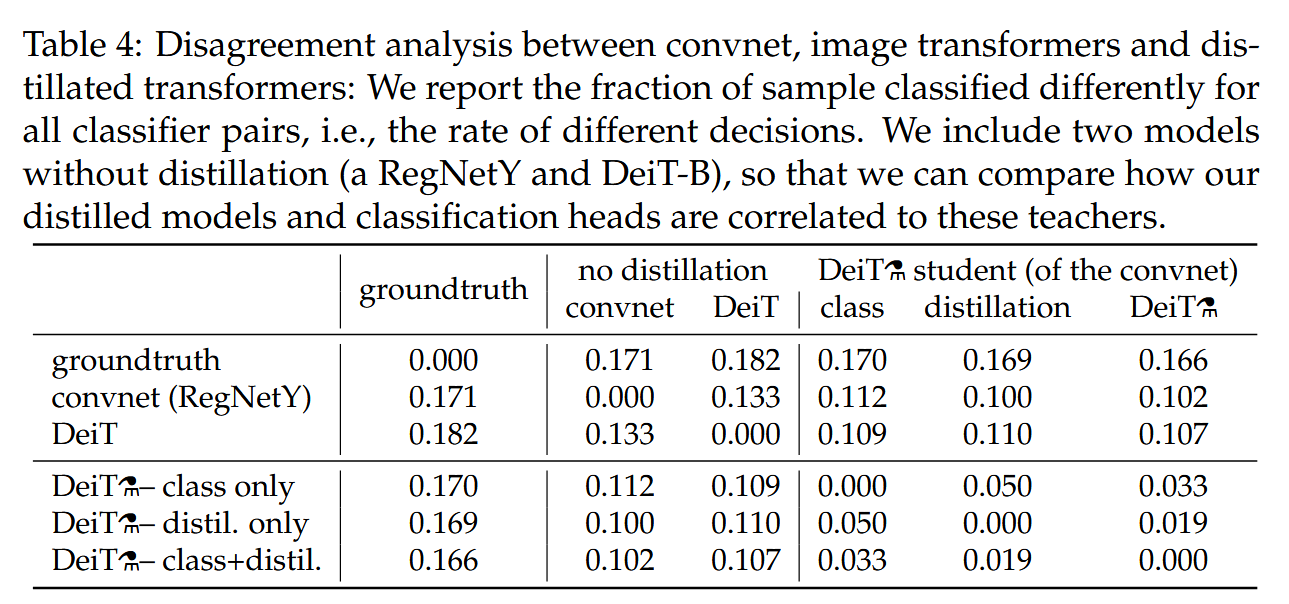
-
訓練輪數的影響:增加訓練輪數可顯著提升蒸餾訓練的性能,DeiT - B?在300輪訓練時已優于DeiT - B,且繼續訓練仍可受益。
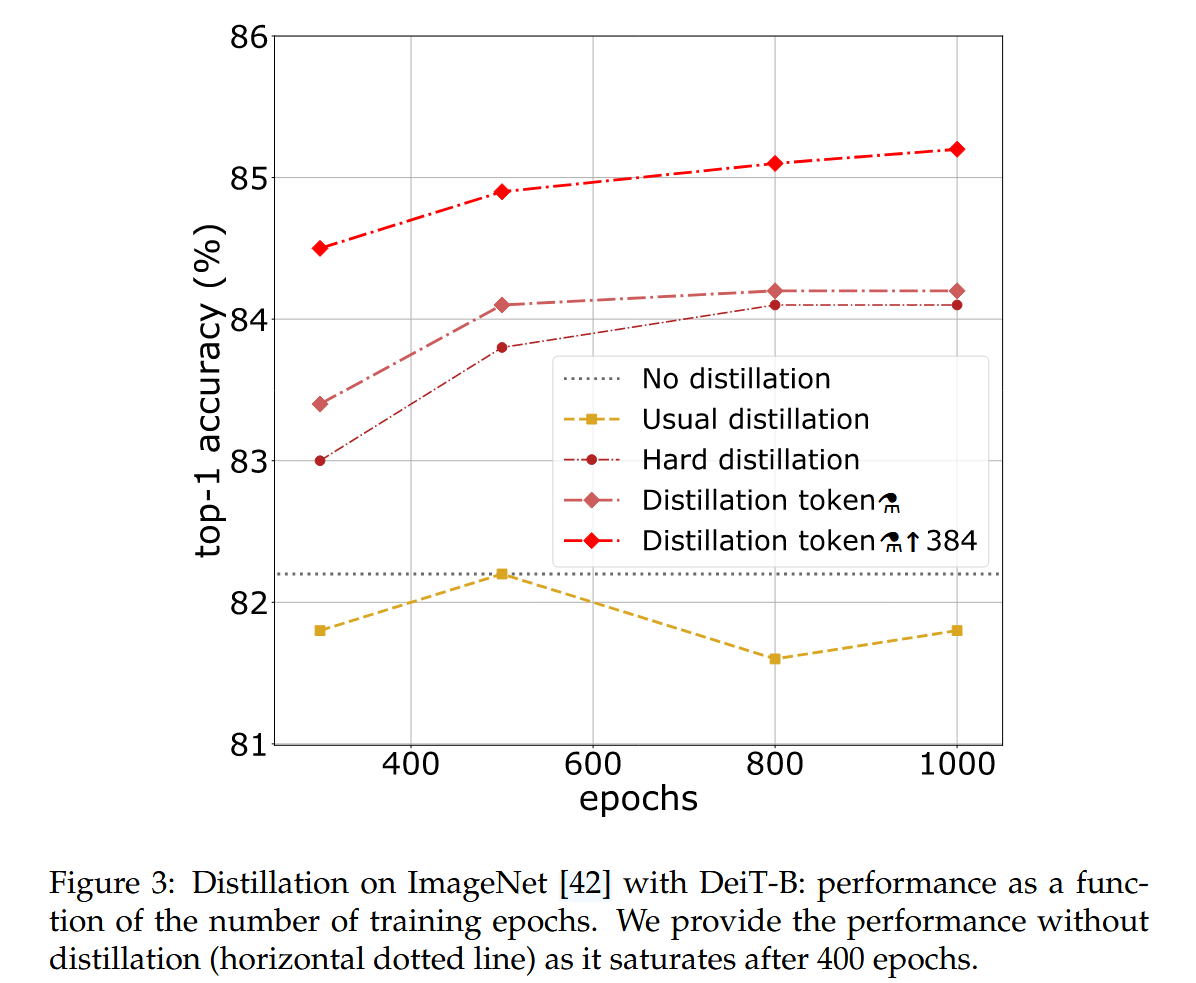
圖3:使用DeiT-B在ImageNet上進行蒸餾:性能隨訓練輪數的變化。我們給出了未進行蒸餾時的性能(水平虛線),因為它在400輪訓練后達到飽和。
-
-
效率與精度的權衡:將DeiT與流行的EfficientNet進行對比,結果表明DeiT在僅使用Imagenet訓練時,已接近EfficientNet的性能,縮小了視覺transformer與convnet的差距。使用蒸餾策略后,DeiT?超越了EfficientNet,且在準確率和推理時間的權衡上表現更優,在ImageNet V2和ImageNet Real數據集上也有出色表現。
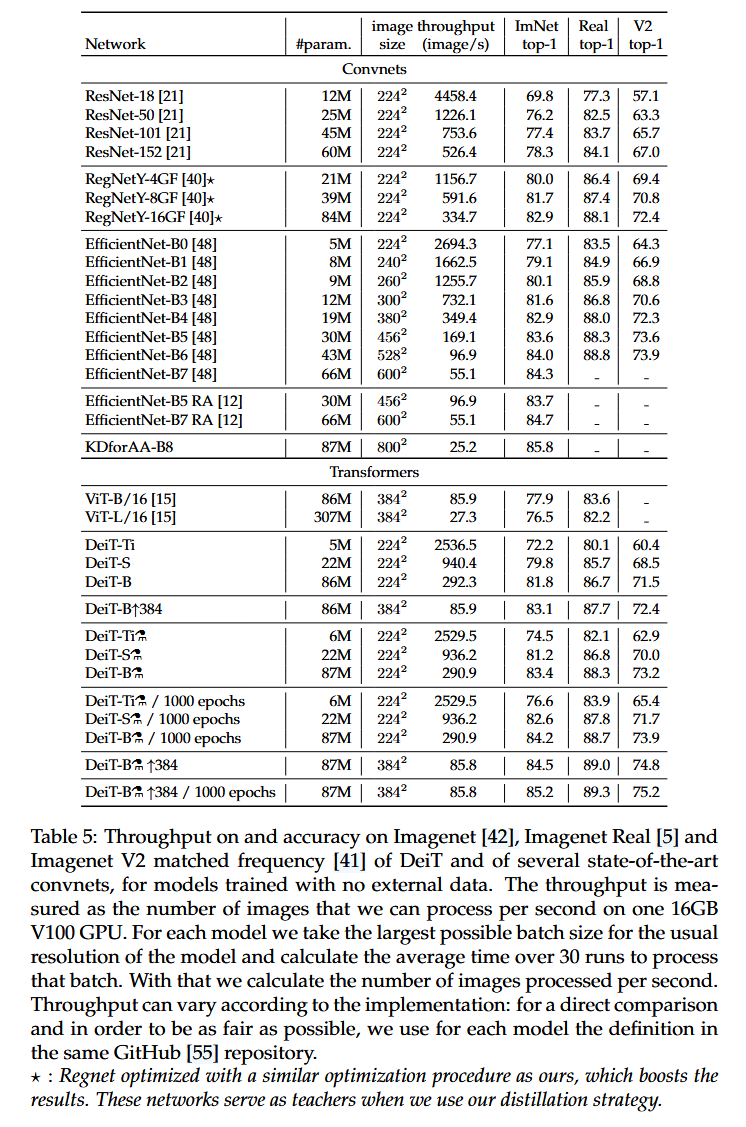
表5:DeiT以及幾種最先進的卷積神經網絡在無外部數據訓練情況下,在ImageNet、ImageNet Real和ImageNet V2匹配頻率數據集上的吞吐量和準確率。吞吐量是指在一塊16GB的V100 GPU上每秒能夠處理的圖像數量。對于每個模型,我們采用其常規分辨率下最大可能的批量大小,并計算處理該批量30次運行的平均時間,由此計算出每秒處理的圖像數量。吞吐量會因實現方式而異:為了進行直接比較并盡可能保證公平性,我們對每個模型都采用相同GitHub代碼庫中的定義。 -
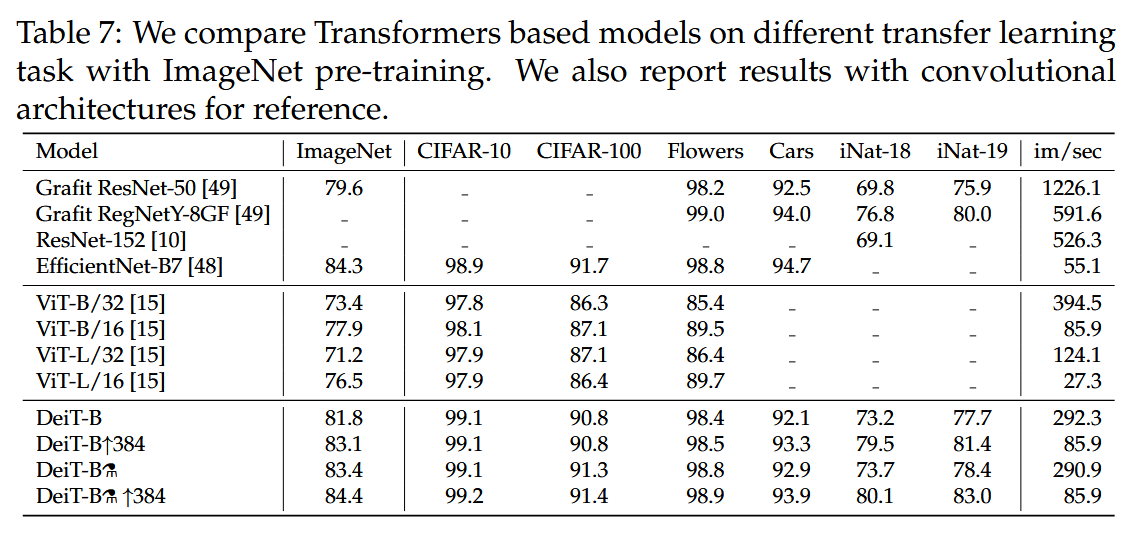
遷移學習性能:在多個下游任務(如CIFAR - 10、CIFAR - 100、Oxford - 102 flowers、Stanford Cars和iNaturalist - 18/19)上對DeiT進行微調評估,結果顯示其與有競爭力的convnet模型表現相當,證明了DeiT良好的泛化能力。在小數據集CIFAR - 10上從頭訓練,DeiT也能取得一定成果,但不如經過ImageNet預訓練的效果好。
表6:用于我們不同任務的數據集。
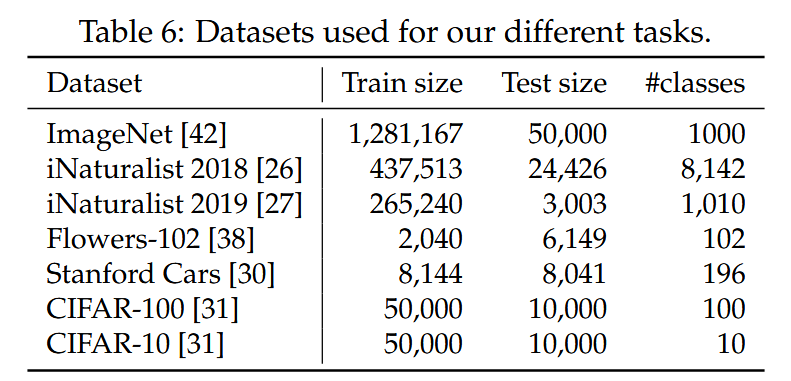
表7:我們比較了基于Transformer的模型在不同的ImageNet預訓練遷移學習任務中的表現。同時,我們也報告了卷積架構的結果以供參考。
訓練細節和消融實驗-Training details & ablation
該主要介紹了DeiT的訓練細節,并對訓練方法進行消融實驗分析,以探究各因素對模型性能的影響,具體內容如下:
- 初始化和超參數設置:Transformer對初始化較為敏感,文中遵循Hanin和Rolnick的建議,使用截斷正態分布初始化權重。在蒸餾時,依據Cho等人的建議選取超參數,如通常(軟)蒸餾中 τ = 3.0 \tau = 3.0 τ=3.0, λ = 0.1 \lambda = 0.1 λ=0.1。同時給出了默認的訓練超參數,包括優化器、學習率、權重衰減等設置。
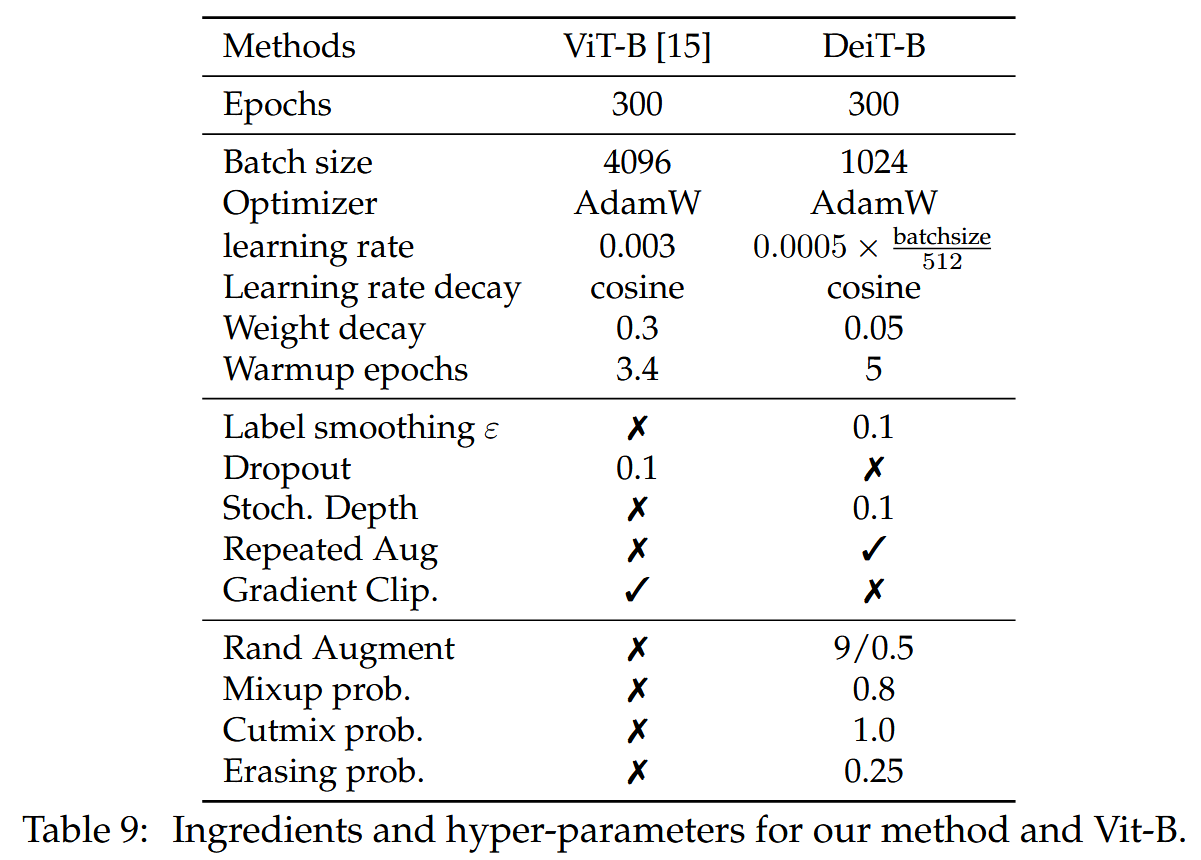
表9:我們的方法以及ViT-B所使用的要素和超參數。 - 數據增強:與集成更多先驗(如卷積)的模型相比,Transformer需要更多數據,因此依賴大量數據增強方法來實現高效訓練。評估了Auto - Augment、Rand - Augment、隨機擦除等多種強數據增強方法,發現幾乎所有方法都有用,最終選擇Rand - Augment。而dropout對訓練無明顯幫助,故被排除在訓練過程之外。
- 正則化與優化器:考慮了不同優化器,并對學習率和權重衰減進行交叉驗證。結果表明,AdamW優化器在與ViT相同學習率但更小權重衰減的設置下表現最佳,因為原論文中的權重衰減在該實驗設置下會影響收斂。此外,采用隨機深度、Mixup、Cutmix和重復增強等正則化方法,這些方法有助于模型收斂和性能提升,其中重復增強是訓練過程的關鍵成分之一。
- 指數移動平均(EMA):評估了訓練后網絡的EMA,發現其有少量性能提升,但微調后與普通模型性能相同,即微調后優勢消失。
- 不同分辨率下的微調:采用Touvron等人的微調過程,保持訓練時的數據增強,對位置嵌入采用雙三次插值,以近似保留向量范數,避免直接使用雙線性插值導致的精度下降。對比了AdamW和SGD兩種優化器在微調階段的性能,發現二者表現相似。還研究了不同微調分辨率對模型性能的影響,默認在224分辨率訓練,384分辨率微調,實驗表明更高分辨率微調可提升性能。

表8:在ImageNet上對訓練方法進行的消融研究。最上面一行(“無”)對應我們用于DeiT的默認配置。符號“√”和“×”分別表示我們使用和不使用相應的方法。我們報告了在分辨率為224×224下初始訓練后的準確率得分(%),以及在分辨率為384×384下微調后的準確率得分。超參數根據表9進行固定,可能并非是最優設置。“*”表示模型訓練效果不佳,可能是因為超參數不適用。
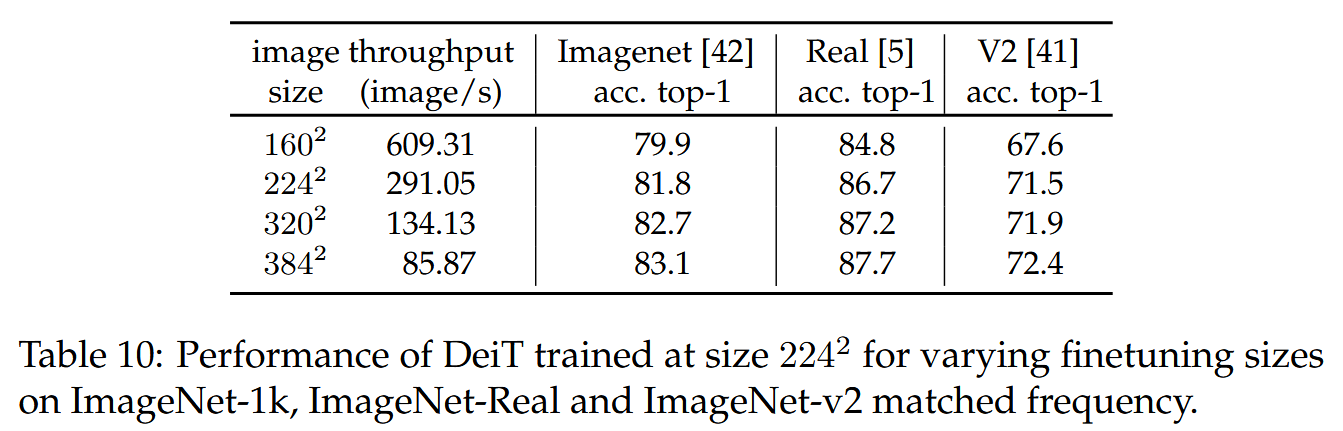
表10:在ImageNet-1k、ImageNet-Real和ImageNet-v2匹配頻率數據集上,初始訓練尺寸為224的DeiT模型在不同微調尺寸下的性能表現。 - 訓練時間:DeiT - B進行300輪典型訓練,在2個節點上需37小時,在單個節點上需53小時,相比之下RegNetY - 16GF訓練慢20%。DeiT - S和DeiT - Ti在4個GPU上訓練不到3天。可選在更大分辨率下微調,在單個8 GPU節點上需20小時(對應25輪),使用重復增強使每輪訓練實際看到的圖像數量為三分之一,但整體訓練效果更好。
結論-Conclusion
該部分總結了研究成果,分析了研究的局限性與未來方向,并介紹了代碼開源情況,具體內容如下:
- 研究成果:提出數據高效的圖像Transformer - DeiT,通過改進訓練方法,尤其是引入新穎的蒸餾程序,使得模型無需大量數據訓練就能取得與卷積神經網絡相當的性能。在ImageNet數據集上,DeiT展現出強大的競爭力,如DeiT - B模型在無外部數據情況下單裁剪top - 1準確率達83.1%,使用蒸餾策略后最高可達85.2% 。
- 研究局限性與未來方向:卷積神經網絡經過近十年優化,包括易過擬合的架構搜索,而DeiT僅采用現有數據增強和正則化策略,未對架構做重大改變。因此,研究更適合Transformer的數據增強方法有望進一步提升DeiT性能。















)



