?哈嘍,大家好,我是我不是小upper,?
今天系統梳理了線性回歸的核心知識,從模型的基本原理、參數估計方法,到模型評估指標與實際應用場景,幫助大家深入理解這一經典的機器學習算法,助力數據分析與預測工作。
非線性數據的回歸處理方法解答
讀者問:如果我的數據中的變量間關系不是線性的,是不是可以用多項式回歸和變換方法,比如對數變換,但不太明白它們是如何應用的。
答:當數據中的變量關系呈現非線性特征時,傳統的線性回歸模型往往難以實現良好的數據擬合效果,此時多項式回歸和變換方法就派上用場了,它們能夠有效捕捉數據中的非線性關系。下面我詳細為你介紹這兩種方法的應用方式,你可以動手實踐試試看。
1. 多項式回歸
多項式回歸是通過引入原始特征的高次冪項,對線性模型進行拓展,以此來描述數據間的非線性關系。例如,對于單個特征?x,除了考慮?x?本身,多項式回歸還會納入?、
?等高次項;而對于多個特征?
?的多元情況,會包含如?
、
、
?等組合項 。
以一元二次多項式回歸為例,其模型表達式為:
,其中?、
、
?是待估計的參數,
?是誤差項;多元多項式回歸(以兩個特征?
、
?為例)的表達式可能為:
。
在應用多項式回歸時,有 3 個關鍵要點需要注意:
- 防止過擬合:隨著高次項的引入,模型的復雜度大幅增加,很容易出現過擬合現象,即模型在訓練數據上表現良好,但在新數據上預測效果不佳。因此,在構建模型時,要謹慎選擇多項式的次數,不能盲目追求高次項。
- 選擇最佳次數:可以借助交叉驗證或學習曲線來確定最合適的多項式次數。交叉驗證通過將數據多次劃分成訓練集和驗證集,綜合評估不同次數下模型在驗證集上的表現;學習曲線則展示隨著訓練數據量變化,模型在訓練集和驗證集上的性能變化趨勢,幫助判斷模型是否處于過擬合或欠擬合狀態,從而選擇合適的次數。
- 特征縮放:由于多項式回歸中不同次冪的特征取值范圍差異較大,在使用前通常需要對特征進行縮放處理,比如采用標準化(將特征轉換為均值為 0,標準差為 1 的分布)或歸一化(將特征值映射到 [0, 1] 區間)等方法,確保不同特征的尺度一致,這樣有助于提升模型訓練的穩定性和收斂速度。
2. 變換方法(以對數變換為例)
變換方法的核心思路是對原始數據進行特定的數學變換,使變換后的數據更符合線性關系,進而能夠使用線性回歸模型進行處理。對數變換是眾多變換方法中較為常用的一種,尤其適用于數據呈現指數增長趨勢的情況。
對數變換的具體操作是對原始數據?y?取對數,即?(這里的對數可以是自然對數?
?,也可以是以 10 為底的對數?
?,具體根據數據特點和需求選擇)。經過對數變換后,原本指數增長的數據趨勢會變得相對平緩,更接近線性關系。
在應用對數變換時,有 2 個要點需要關注:
- 對數變換的條件:對數函數的定義域是正數,所以對數變換僅適用于數據全部為正數的情況。如果數據中存在 0 或負數,需要先對數據進行適當的平移處理(例如加上一個正數,確保所有數據大于 0),再進行對數變換。此外,當數據呈現明顯的指數增長趨勢時,對數變換往往能取得較好的效果。
- 恢復變換后的預測值:在使用對數變換后,模型得到的預測值是變換后數據的預測結果,需要通過指數函數進行逆變換,才能得到原始數據尺度下的預測值,即?
(如果之前是自然對數變換)。
注意點和建議
- 探索性數據分析(EDA):在決定使用多項式回歸或變換方法之前,一定要先進行探索性數據分析。通過繪制散點圖、箱線圖、直方圖等可視化圖表,直觀了解數據的分布形態、變量之間的關系以及是否存在異常值等特性,為后續選擇合適的方法提供依據。
- 嘗試不同方法:由于不同數據集的特點千差萬別,處理非線性關系時,可以嘗試多種方法,包括不同次數的多項式回歸、不同類型的變換(如平方根變換、倒數變換等),然后通過對比模型在驗證集上的性能指標(如均方誤差、決定系數?
?等),選擇最適合當前數據的方法。
- 注意異常值:異常值可能會對非線性關系的發現和模型擬合產生較大干擾。在建模之前,要仔細檢查并處理異常值,可以采用統計方法(如 3 倍標準差法)識別異常值,然后根據實際情況選擇刪除異常值、修正異常值或者將其作為特殊數據單獨處理。
- 模型評估:使用合適的評估指標(如均方誤差、平均絕對誤差、
總體而言,當數據呈現非線性關系時,多項式回歸和變換方法是兩種常見且有效的處理手段。但在實際應用中,需要根據數據特點謹慎選擇,并進行充分的模型評估和調整。如果還有問題,歡迎在評論區繼續探討!
L1 和 L2 正則化的區別與應用解析
讀者問:剛剛學習了 L1(LASSO)和 L2(嶺回歸)正則化,還是有點模糊其中的區別?它們是如何影響回歸模型的?
大壯答:你好!L1 正則化(LASSO)和 L2 正則化(嶺回歸)都是回歸模型中常用的正則化技術,它們的核心目的是通過對模型參數施加約束,防止模型過擬合,提升模型的泛化能力。下面我將詳細介紹它們之間的區別,以及對回歸模型的具體影響。
1. 區別
a. 正則化項的形式
- L1 正則化(LASSO):其正則化項是模型參數的絕對值之和,也就是 L1 范數,數學表達式為:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
?,? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 在損失函數中,最終的優化目標變為:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
?,? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 其中?
?是均方誤差,
?是正則化強度參數,用于控制正則化項對損失函數的影響程度。
- L2 正則化(嶺回歸):正則化項是模型參數平方和的平方根,即 L2 范數,表達式為:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
?,? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 在實際應用中,為了方便計算和優化,通常使用其平方形式,此時損失函數變為:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
?。
b. 特征選擇
- L1 正則化(LASSO):具有獨特的特征選擇能力。在優化過程中,隨著正則化強度?
- L2 正則化(嶺回歸):一般不會將模型參數壓縮到零,而是對所有參數進行均勻縮放。它通過減小參數的大小,降低模型對某些特征的依賴程度,但不會完全剔除某個特征,因此在處理特征間存在較強相關性(多重共線性)的問題時表現較好。
c. 解的穩定性
- L1 正則化(LASSO):由于其正則化項的形狀(棱角分明),在某些情況下,解可能會不穩定。當數據或模型結構發生微小變化時,某些參數可能會突然從非零值變為零,導致模型結構發生較大改變,進而影響模型的穩定性和預測結果的一致性。
- L2 正則化(嶺回歸):對參數施加的是平滑約束,使得參數的變化更加連續和穩定。即使數據存在一定波動或模型結構略有調整,參數也不會發生劇烈變化,因此更容易得到穩定的解,在實際應用中表現出更好的穩健性。
2. 影響回歸模型的方式
a. 參數收縮
- L1 正則化(LASSO):通過將部分不重要的參數縮小到零,實現了對模型參數的 “裁剪”,剔除了那些對預測結果貢獻較小的特征,從而有效降低了模型的復雜度,避免模型過度擬合訓練數據中的噪聲和細節。
- L2 正則化(嶺回歸):對所有參數進行收縮,使它們的絕對值都變小,但不會完全消除某個參數。這種方式有助于在保留所有特征信息的同時,降低每個特征的權重,緩解多重共線性問題對模型的影響,使得模型在面對新數據時更加魯棒。
b. 模型復雜度
- L1 正則化(LASSO):傾向于生成稀疏模型,當我們認為數據中只有少數關鍵特征對目標變量有實質性影響時,使用 L1 正則化可以自動篩選出這些重要特征,減少模型的冗余,降低模型復雜度,提高模型的可解釋性。
- L2 正則化(嶺回歸):主要作用是平滑參數,通過對所有參數進行調整,使得模型在各個特征上的權重分布更加均衡。在特征間關聯較強,且我們希望保留所有特征信息的情況下,嶺回歸能夠有效控制模型復雜度,避免過擬合,同時保持模型的穩定性和預測性能。
3. 注意點和建議
- 超參數調整:正則化強度參數?
- 問題特征:根據具體問題和數據的特征來選擇合適的正則化方法。如果初步分析認為數據中存在大量冗余特征,且只有少數特征對目標變量起關鍵作用,那么 L1 正則化(LASSO)可能是更好的選擇;而當特征間存在較強的相關性,且我們不確定哪些特征更重要,希望保留所有特征信息時,L2 正則化(嶺回歸)更為合適。
- 綜合考慮:在一些復雜的實際問題中,還可以嘗試同時使用 L1 和 L2 正則化,這種方法被稱為彈性網絡(Elastic Net)。彈性網絡結合了 L1 和 L2 正則化的優點,既能夠實現特征選擇,又能處理多重共線性問題,在某些情況下可以取得比單獨使用 L1 或 L2 正則化更好的效果。
總的來說,L1 和 L2 正則化都是回歸模型中控制模型復雜度、提升模型泛化能力的有效工具。具體使用哪種方法,需要根據數據特點、問題需求以及模型評估結果進行綜合判斷。如果還有疑問,歡迎隨時提問!
學習曲線和驗證曲線在回歸模型評估中的應用
讀者問:這幾天遇到一個問題,就是我應該如何使用學習曲線和驗證曲線來評估我的回歸模型?這些曲線能告訴我什么,以及我該如何根據它們來調整模型參數?
大壯答:你好!在回歸模型的訓練和優化過程中,學習曲線和驗證曲線是非常實用的兩種分析工具,它們能夠幫助我們深入了解模型的性能,并為調整模型參數提供重要依據。下面我分別為你介紹這兩種曲線的原理、能傳達的信息,以及如何基于它們進行模型參數調整。
學習曲線
學習曲線是一種用于展示訓練數據大小與模型性能之間關系的圖表。在繪制學習曲線時,通常會在不同數量的訓練數據上訓練模型,并分別計算模型在訓練集和驗證集上的性能指標(如均方誤差、決定系數??等),然后以訓練數據量為橫坐標,性能指標為縱坐標進行繪圖。
學習曲線能告訴我們的信息
- 欠擬合:如果在學習曲線上,訓練集和驗證集的性能都較差,且隨著訓練數據量的增加,性能提升不明顯,那么很可能是模型過于簡單,無法捕捉數據中的復雜關系,處于欠擬合狀態。這意味著模型對數據的擬合程度不足,不能很好地反映數據的真實規律,在訓練數據和新數據上的預測效果都不理想。
- 過擬合:當訓練集上的性能很好,但驗證集上的性能較差,并且隨著訓練數據量的增加,兩者之間的差距逐漸增大時,說明模型可能過于復雜,學習到了訓練數據中的噪聲和特定樣本的細節,出現了過擬合現象。此時模型在訓練數據上表現出色,但在面對新的測試數據時,由于無法泛化到其他數據分布,預測準確率會大幅下降。
- 合適的模型復雜度:理想情況下,當訓練集和驗證集上的性能隨著訓練數據量的增加逐漸趨于穩定,并且兩者的差距較小,能夠收斂到相近的水平時,說明我們找到了合適的模型復雜度。此時模型既能夠充分學習數據的特征,又不會過度擬合,在新數據上具有較好的泛化能力。
如何根據學習曲線調整模型參數
- 欠擬合時:為了提高模型的擬合能力,可以嘗試增加模型復雜度。例如,對于線性回歸模型,可以引入多項式特征,將線性模型擴展為多項式回歸模型;或者更換為更復雜的模型,如決策樹回歸、隨機森林回歸、支持向量機回歸等,以增強模型對非線性關系的捕捉能力。
- 過擬合時:為了降低模型復雜度,緩解過擬合問題,可以采取多種措施。比如減少模型中的特征數量,通過特征選擇方法(如 L1 正則化、相關性分析等)剔除那些對目標變量貢獻較小或冗余的特征;增加正則化強度,對模型參數施加更嚴格的約束,防止參數過度擬合訓練數據;或者選擇更簡單的模型結構,避免模型過于復雜。
驗證曲線
驗證曲線是用于分析模型性能與某一特定參數(例如正則化參數、多項式次數、學習率等)之間關系的圖表。通過在不同的參數取值下訓練和評估模型,得到對應的性能指標,然后以該參數值為橫坐標,性能指標為縱坐標繪制曲線。
驗證曲線能告訴我們的信息
- 最優參數取值:觀察驗證曲線的變化趨勢,我們可以找到使模型在驗證集上性能最優的參數取值。在曲線的最高點(對于越大越好的指標,如?
- 過擬合和欠擬合:驗證曲線也可以幫助我們檢測模型是否處于過擬合或欠擬合狀態。如果隨著參數值的變化,驗證集上的性能出現較大波動,例如在某些參數值下性能突然下降,可能是因為模型在這些參數設置下出現了過擬合或欠擬合現象。此外,如果訓練集和驗證集的性能差異較大,也可能暗示模型存在過擬合問題。
如何根據驗證曲線調整模型參數
- 選擇最優參數:根據驗證曲線的走勢,直接選取能夠使驗證集性能達到最佳的參數取值作為模型的最終參數設置。這樣可以確保模型在當前數據和任務下具有最優的性能表現。
- 調整模型復雜度:如果驗證曲線顯示模型存在過擬合或欠擬合情況,可以結合具體的參數含義,相應地調整模型復雜度或正則化強度。例如,如果驗證曲線是關于正則化參數的,當出現過擬合時,可以增大正則化參數,加強對模型參數的約束;當出現欠擬合時,可以減小正則化參數,讓模型有更多的自由度去學習數據特征。
下面通過代碼演示如何使用學習曲線和驗證曲線來評估回歸模型,并根據結果調整模型參數,這里以線性回歸模型為例,使用?scikit-learn?庫實現:
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import learning_curve, validation_curve# 生成隨機回歸數據
X, y = make_regression(n_samples=1000, n_features=20, noise=0.2, random_state=42)# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定義線性回歸模型
estimator = LinearRegression()def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=None, train_sizes=np.linspace(.1, 1.0, 5)):plt.figure()plt.title(title)if ylim is not None: # 修復此處語法錯誤plt.ylim(*ylim)plt.xlabel("Training examples")plt.ylabel("Score")train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)plt.grid()plt.fill_between(train_sizes, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.1,color="r")plt.fill_between(train_sizes, test_scores_mean - test_scores_std,test_scores_mean + test_scores_std, alpha=0.1, color="g")plt.plot(train_sizes, train_scores_mean, 'o-', color="r",label="Training score")plt.plot(train_sizes, test_scores_mean, 'o-', color="g",label="Cross-validation score")plt.legend(loc="best")return pltdef plot_validation_curve(estimator, title, X, y, param_name, param_range, cv=None, scoring=None):train_scores, test_scores = validation_curve(estimator, X, y, param_name=param_name, param_range=param_range,cv=cv, scoring=scoring)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)plt.title(title)plt.xlabel(param_name)plt.ylabel("Score")plt.ylim(0.0, 1.1)lw = 2plt.plot(param_range, train_scores_mean, label="Training score",color="darkorange", lw=lw)plt.fill_between(param_range, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.2,color="darkorange", lw=lw)plt.plot(param_range, test_scores_mean, label="Cross-validation score",color="navy", lw=lw)plt.fill_between(param_range, test_scores_mean - test_scores_std,test_scores_mean + test_scores_std, alpha=0.2,color="navy", lw=lw)plt.legend(loc="best")return plt# 使用示例
plot_learning_curve(estimator, "Learning Curve", X_train, y_train, cv=5)
plt.show()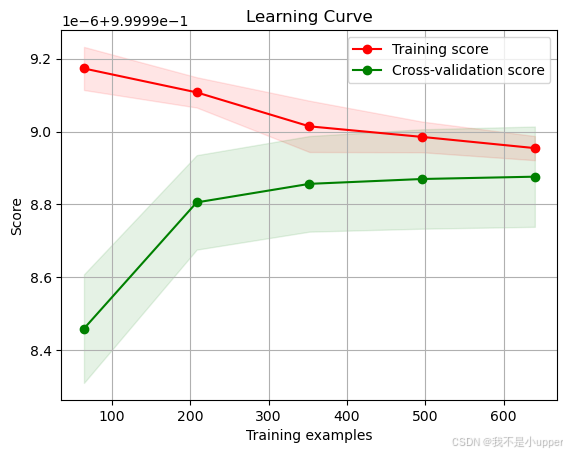
在這段代碼中,我們首先定義了一個線性回歸模型?LinearRegression(),然后將其傳遞給了?plot_learning_curve?函數。這樣就可以成功繪制學習曲線了。
非線性回歸模型的例子解析
讀者問:,能給我一些非線性回歸模型的例子嗎?它們與線性回歸主要不同點在哪里?
答:在數據分析與建模領域,當自變量和因變量之間的關系無法用直線(線性函數)準確描述,而是呈現曲線等復雜形態時,就需要借助非線性回歸模型。下面我為你詳細介紹幾種常見的非線性回歸模型,并深入對比它們與線性回歸的差異。
1. 多項式回歸
多項式回歸通過引入自變量的高次冪拓展線性模型,打破了自變量冪次為 1 的限制。例如一元二次多項式回歸模型表達式為:
?;
若拓展到三次項,則變為??
。
通過增加高次項,模型能擬合如拋物線、波浪線等復雜的非線性關系。與線性回歸?
?
相比,多項式回歸具備刻畫曲線趨勢的能力,可用于模擬商品價格隨時間先升后降、植物生長速度隨周期變化等場景。
2. 指數回歸
指數回歸采用指數函數??(a、b?為參數,e?是自然常數) 構建模型,適用于描述因變量隨自變量呈指數增長或衰減的現象。比如在研究細菌繁殖時,細菌數量會隨時間呈指數增長;放射性物質的衰變過程,其剩余質量隨時間呈指數衰減。這種模型通過指數函數的特性,精準捕捉數據在不同階段的快速變化趨勢,與線性回歸均勻變化的趨勢形成鮮明對比。
3. 對數回歸
對數回歸通過對自變量或因變量取對數實現非線性建模,常見形式有
??
或? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ???。
當數據呈現指數增長或衰減趨勢,且希望壓縮數據跨度、使數據分布更均勻時,對數變換能將其轉化為線性或更易處理的形式。例如在經濟學中,描述收入與消費的關系,隨著收入增加,消費增長速度逐漸放緩,對數回歸可有效擬合這種非線性關系,而線性回歸在此場景下則難以準確刻畫。
4. 廣義可加模型(Generalized Additive Models, GAM)
GAM 是一種高度靈活的非線性回歸模型,表達式為:
?。
其中,?是非線性函數,通常采用平滑的樣條函數等形式,可根據數據特點自適應調整形狀。GAM 不僅能處理單個自變量的非線性關系,還能綜合多個自變量的非線性效應,適用于復雜多因素影響的場景,如分析氣候因素(溫度、濕度、風速等)對農作物產量的影響 。相比之下,線性回歸要求自變量和因變量呈線性組合關系,難以應對此類復雜的非線性交互。
非線性回歸與線性回歸的核心差異
線性回歸基于自變量和因變量呈線性關系的假設,模型形式簡單,解釋性強,但在面對現實世界中廣泛存在的曲線趨勢、指數變化、復雜交互等數據時,擬合效果欠佳。而非線性回歸模型通過引入多項式、指數函數、對數變換或靈活的非線性函數,極大拓展了模型對復雜數據關系的刻畫能力,能更精準地描述數據內在規律。不過,這種靈活性也帶來弊端:一方面,模型結構復雜,計算復雜度增加,訓練耗時更長;另一方面,參數解釋難度加大,模型的可解釋性變弱,且存在過擬合風險,需要更精細的模型評估與調優。
多項式回歸代碼演示
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures# 生成帶噪聲的非線性數據
np.random.seed(0)
X = np.linspace(-3, 3, 100)
y = 2 * X**3 - 3 * X**2 + 4 * X - 5 + np.random.normal(0, 10, 100)# 將 X 轉換成矩陣形式
X = X[:, np.newaxis]# 使用多項式特征進行變換
poly = PolynomialFeatures(degree=3)
X_poly = poly.fit_transform(X)# 構建并擬合多項式回歸模型
model = LinearRegression()
model.fit(X_poly, y)# 繪制原始數據和擬合曲線
plt.scatter(X, y, color='blue')
plt.plot(X, model.predict(X_poly), color='red')
plt.title('Polynomial Regression')
plt.xlabel('X')
plt.ylabel('y')
plt.show()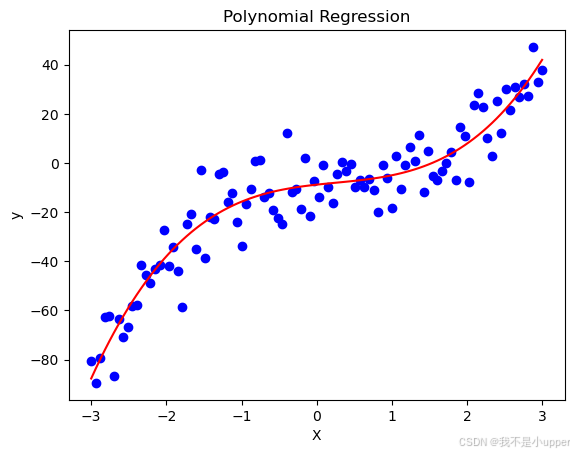
上述代碼先生成包含三次函數趨勢與隨機噪聲的非線性數據,隨后借助?PolynomialFeatures?將原始自變量?X?轉換為包含一次、二次、三次項的多項式特征矩陣。基于此,使用?
LinearRegression?擬合多項式回歸模型,并繪制原始數據散點圖與擬合曲線。從圖像中可直觀看到,多項式回歸模型能夠較好地捕捉數據的非線性趨勢,而普通線性回歸難以實現如此精準的擬合效果,這也凸顯了非線性回歸模型在處理復雜數據關系時的獨特優勢。?
自相關性詳解
讀者問:我看到關于自相關性的描述,但不太明白時間序列數據中的自相關是什么意思。如果我的數據存在自相關,會對我的模型造成什么影響?有沒有簡單的方法可以檢測和處理自相關性?
大壯答:你好!時間序列數據中的自相關性是一個核心概念,許多實際問題都與之緊密相關。后續我會專門出一期內容系統講解時間序列分析,今天先聚焦自相關性。
自相關性,簡單來說,指的是同一變量在時間序列中不同時間點的觀測值之間的關聯程度。例如,今天的氣溫與昨天、前天的氣溫存在關聯,股票今日收盤價與過去幾日的價格存在某種趨勢聯系,這些都是自相關的體現。通過分析自相關性,我們可以挖掘數據中的周期性(如每日、每月的規律波動)或趨勢性(如逐年增長或下降),這對預測未來數據至關重要。
然而,自相關性會給回歸模型帶來挑戰。線性回歸模型的一個基本假設是殘差(預測值與真實值的差值)相互獨立,即不同時間點的誤差之間不存在關聯。但當數據存在自相關時,殘差會呈現出某種規律(例如連續多個正殘差或負殘差),導致殘差不再獨立。這會引發一系列問題:
- 參數估計偏差:模型可能錯誤地將自相關的影響歸因于自變量,導致系數估計不準確;
- 預測失效:模型無法有效捕捉數據的真實波動,預測結果的誤差增大;
- 模型評估失效:傳統的統計檢驗(如顯著性檢驗)結果可能失去可靠性,無法真實反映模型性能。
在實際分析中,我們可以通過以下 4 種方法檢測和處理自相關性:
- 自相關函數(ACF)與偏自相關函數(PACF):通過繪制 ACF 和 PACF 圖,直觀展示不同時間間隔下數據的相關性。ACF 衡量所有滯后階數的總相關性,而 PACF 剔除中間階數的影響,僅顯示當前階數的直接相關性。這些圖能幫助我們判斷時間序列的階數,進而選擇合適的自回歸(AR)或移動平均(MA)模型。
- 差分法:對時間序列進行一階或多階差分(即計算相鄰時間點的差值),可有效消除趨勢和季節性,使數據更平穩,從而減弱自相關性。例如,一階差分公式為:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
。
- 自回歸移動平均模型(ARMA):結合自回歸(AR)和移動平均(MA)兩種機制,直接建模自相關性。AR 項描述當前值與過去值的關系,MA 項描述當前值與過去誤差的關系,二者結合可精準刻畫時間序列的動態特征。
- 自回歸積分移動平均模型(ARIMA):在 ARMA 基礎上加入差分操作,專門處理非平穩時間序列。通過 “差分→擬合 ARMA→逆差分” 的流程,既能消除自相關性,又能保留數據的原始趨勢和特征。
下面通過代碼演示差分法處理自相關性的過程:
import torch
import numpy as np
import matplotlib.pyplot as plt# 生成示例時間序列數據
np.random.seed(0)
n = 100
t = np.arange(n)
y = 0.5 * t + 0.3 * np.sin(0.1 * t) + np.random.normal(0, 1, n)# 繪制原始時間序列圖
plt.figure(figsize=(10, 4))
plt.plot(t, y, label='Original Time Series')
plt.xlabel('Time')
plt.ylabel('Value')
plt.title('Original Time Series Data')
plt.legend()
plt.grid(True)
plt.show()# 計算一階差分
diff_y = np.diff(y)# 繪制一階差分后的時間序列圖
plt.figure(figsize=(10, 4))
plt.plot(t[1:], diff_y, label='First Difference')
plt.xlabel('Time')
plt.ylabel('Value')
plt.title('First Difference Time Series Data')
plt.legend()
plt.grid(True)
plt.show()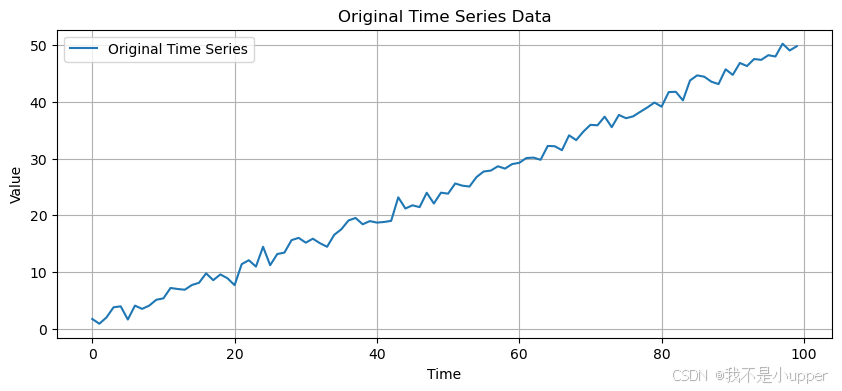
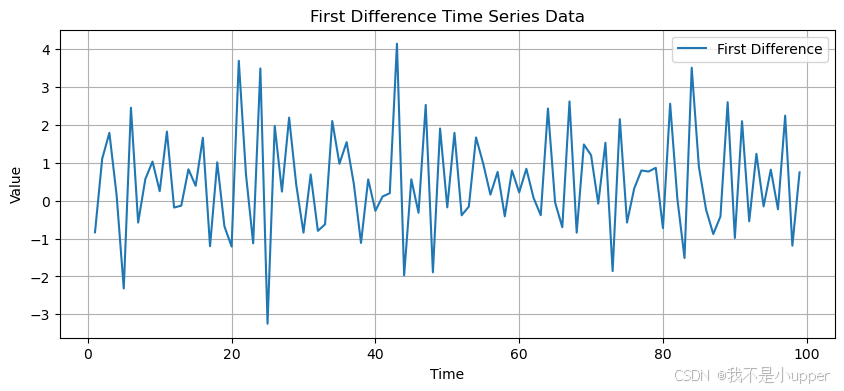
上述代碼中,我們首先生成了一條包含線性趨勢、周期性波動和隨機噪聲的時間序列數據。從原始序列圖中可以觀察到明顯的上升趨勢和周期性正弦波動,這些特征可能導致數據存在自相關。
隨后,通過計算一階差分(np.diff(y)),我們得到相鄰時間點的差值。對比前后圖像可以發現,差分后的數據趨勢消失,波動更加平穩,自相關性顯著減弱。這驗證了差分法在去除時間序列趨勢、降低自相關性上的有效性。在實際應用中,可根據數據特點選擇更高階的差分,或結合其他方法進一步優化模型性能。



)

)





RestAPI 毛子(Http resilience/Refit/游標分頁/異步大文件上傳))


)



)
