目錄
一、創建工作流 應用
二、安裝硅基流動
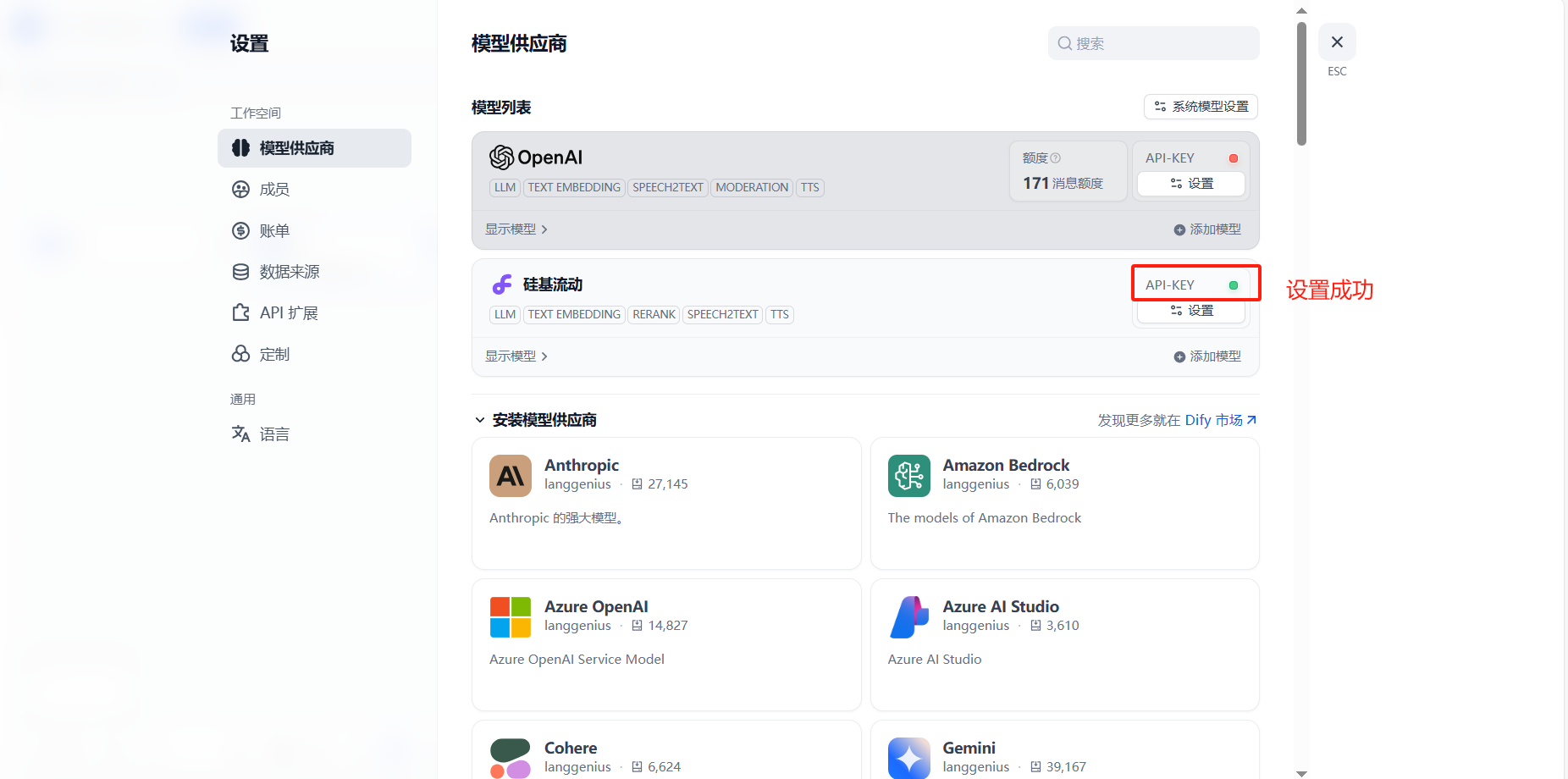
三、配置硅基流動
?四、API測試
(1)進入API文檔
?(2)復制curl代碼
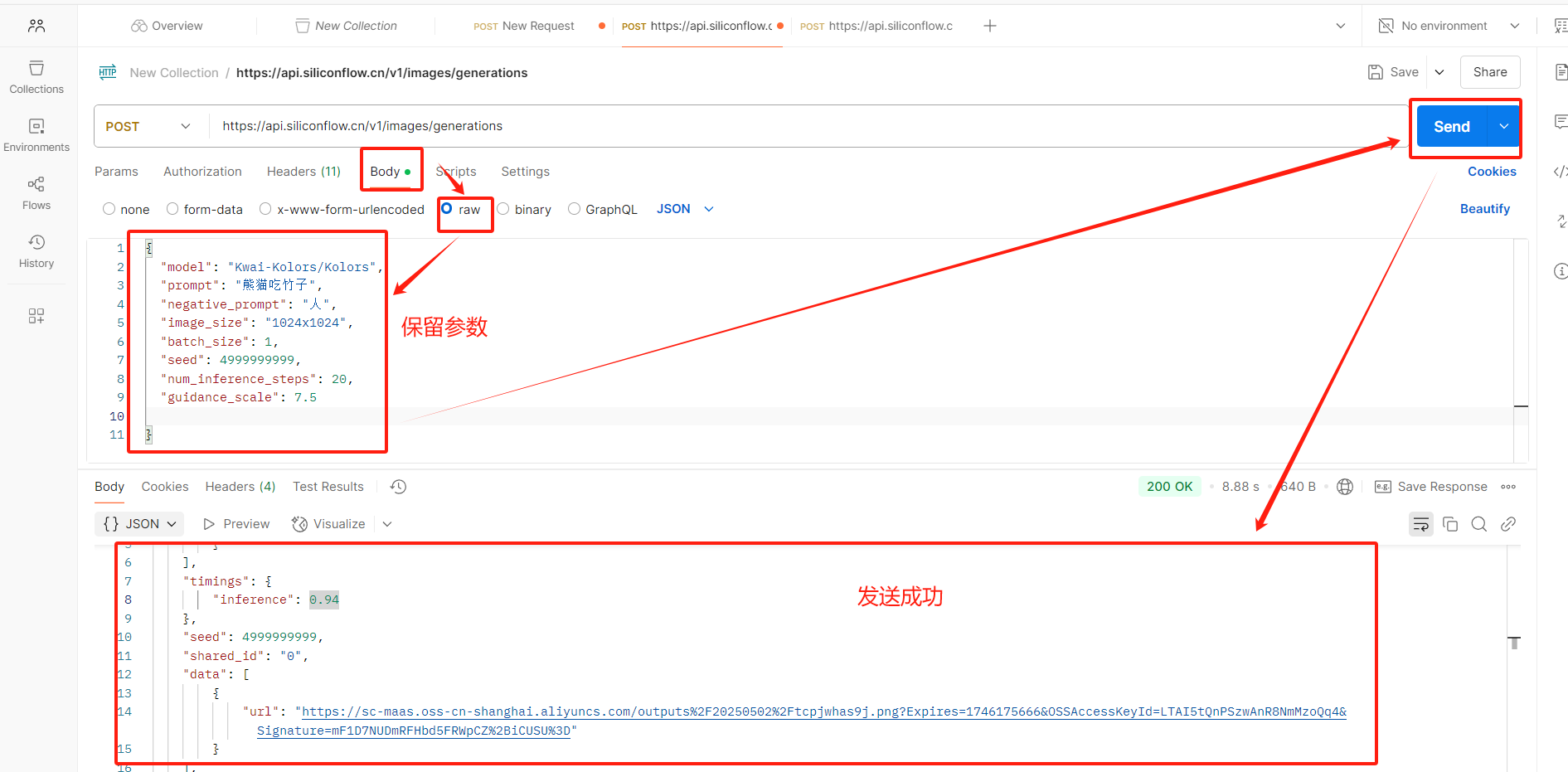
(3)Postman測試API
五、 建立文生圖工作流
(1)建立http請求
?(2)配置http請求信息?編輯
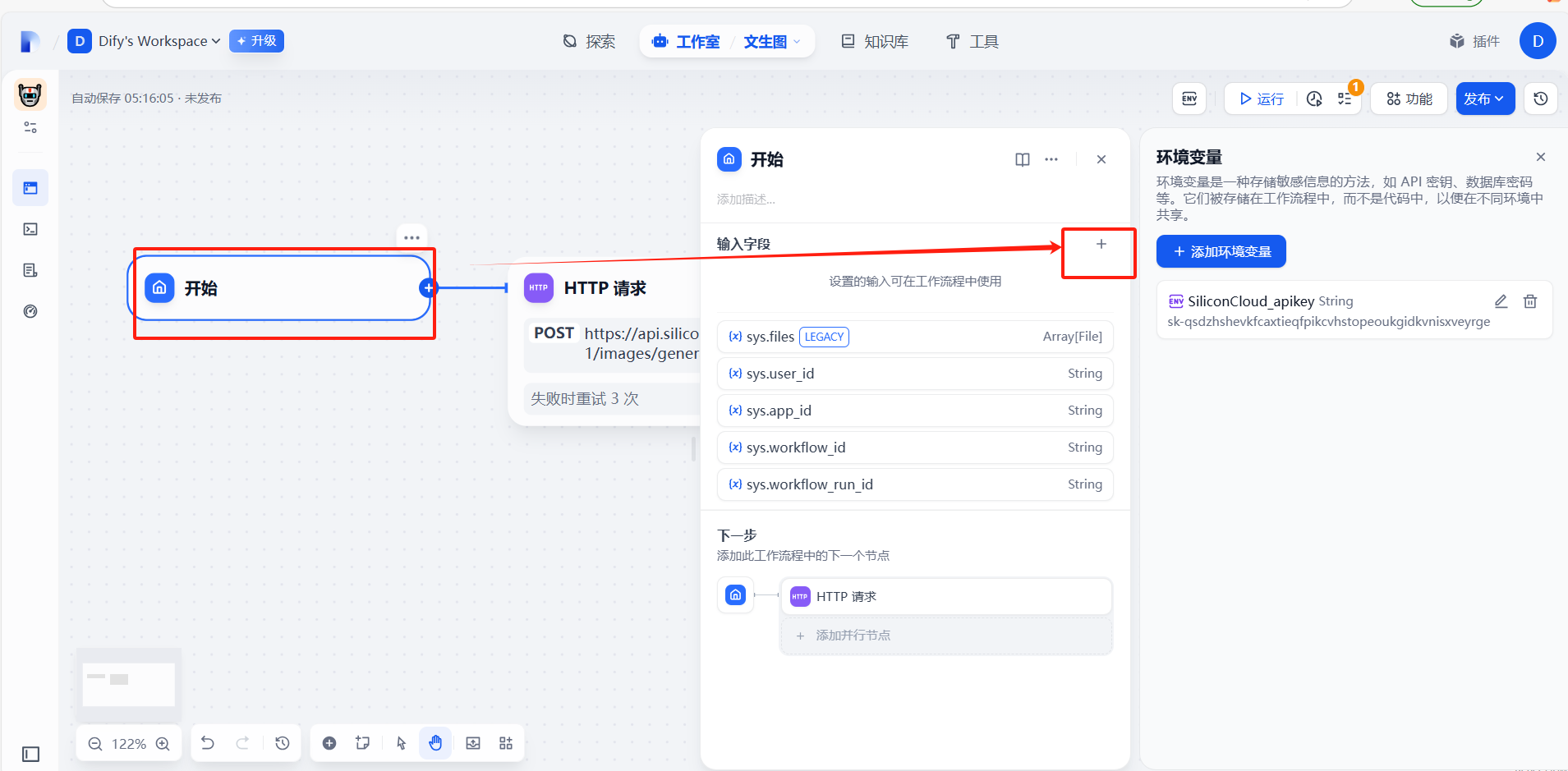
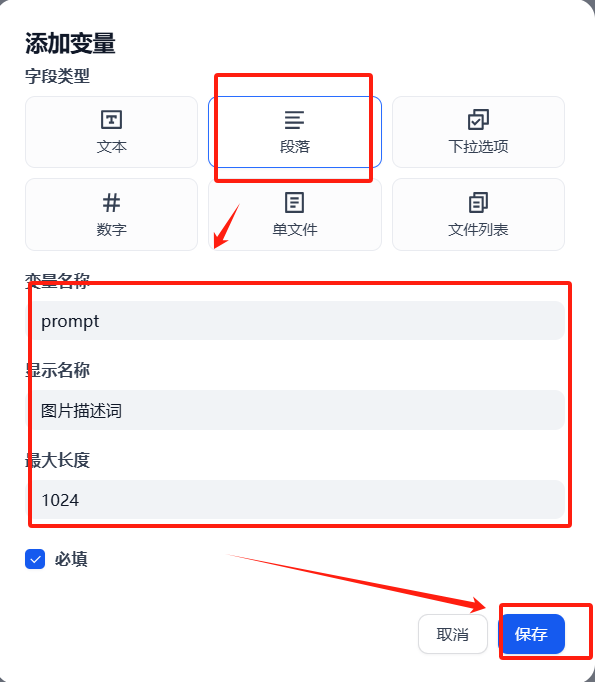
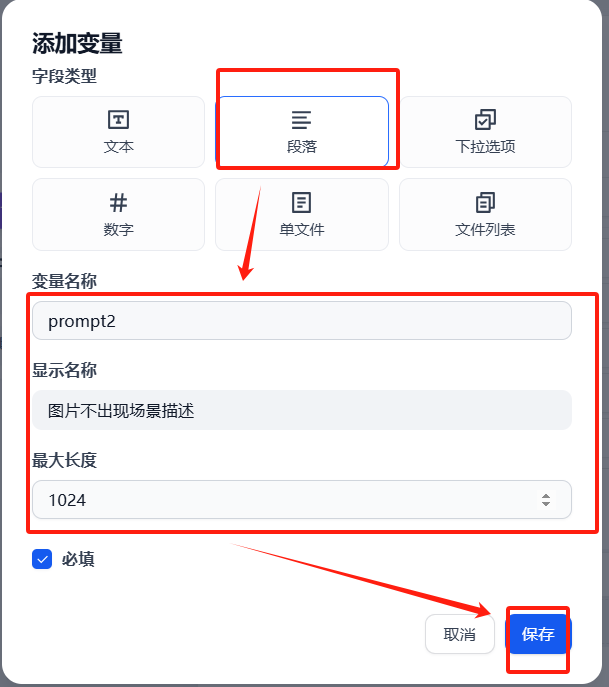
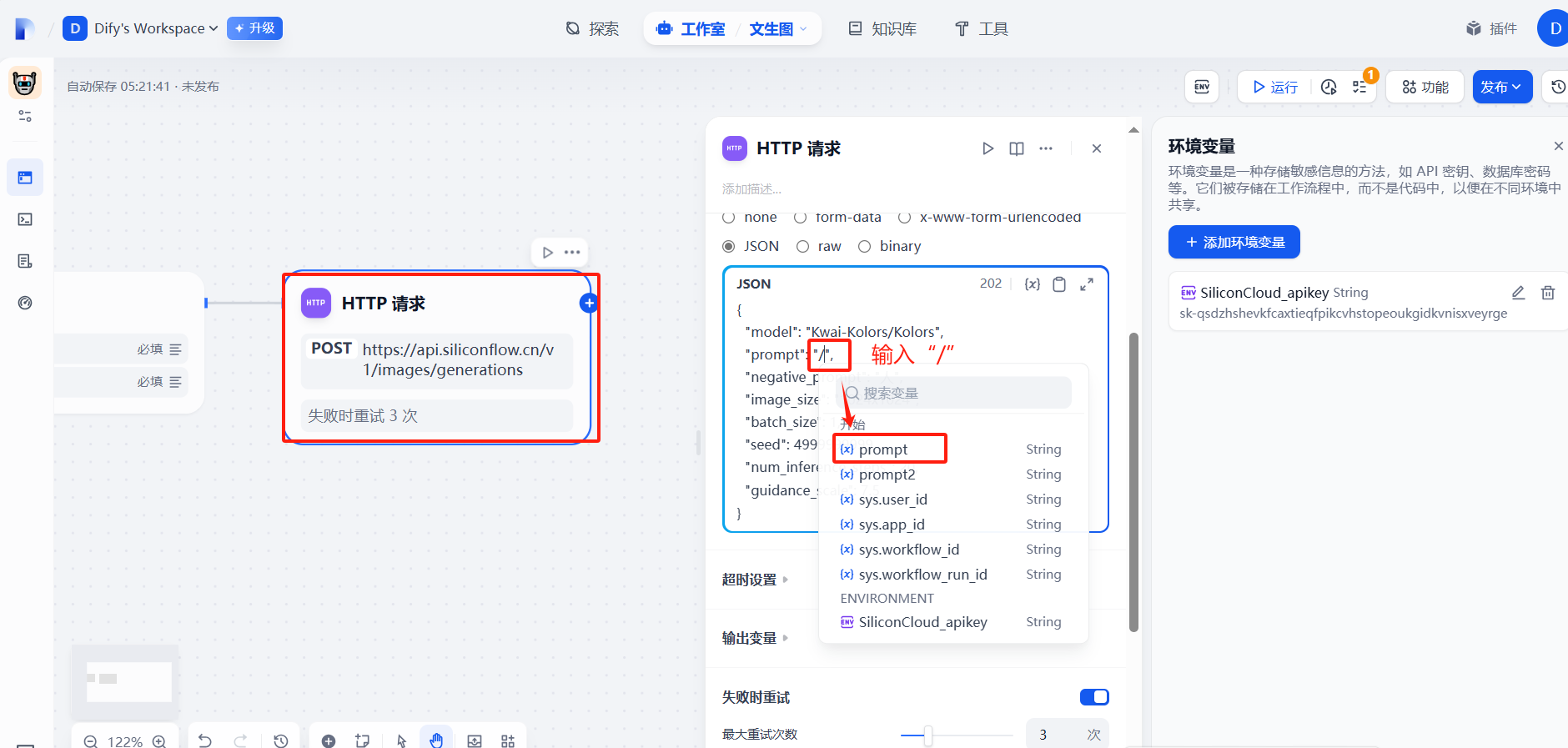
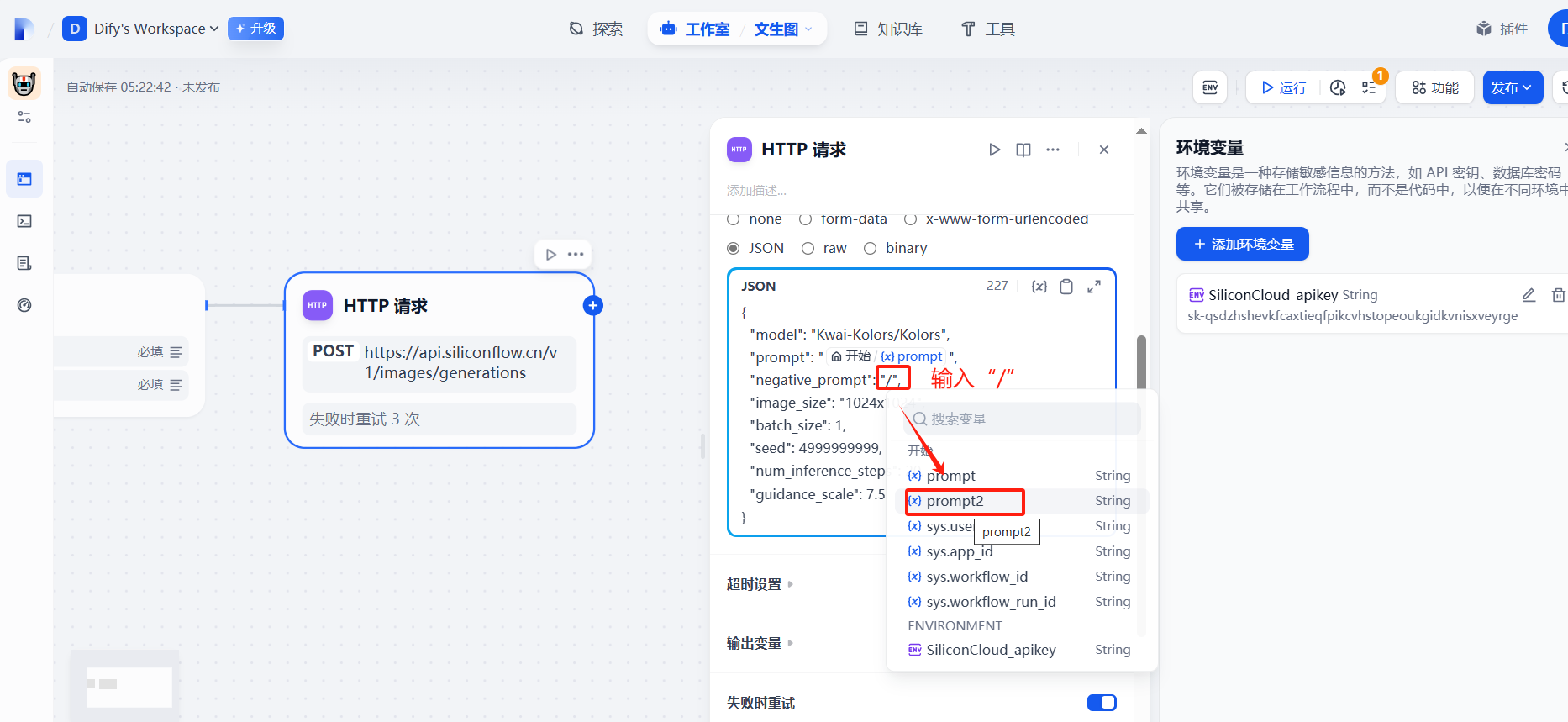
(3)提示詞prompt自定義
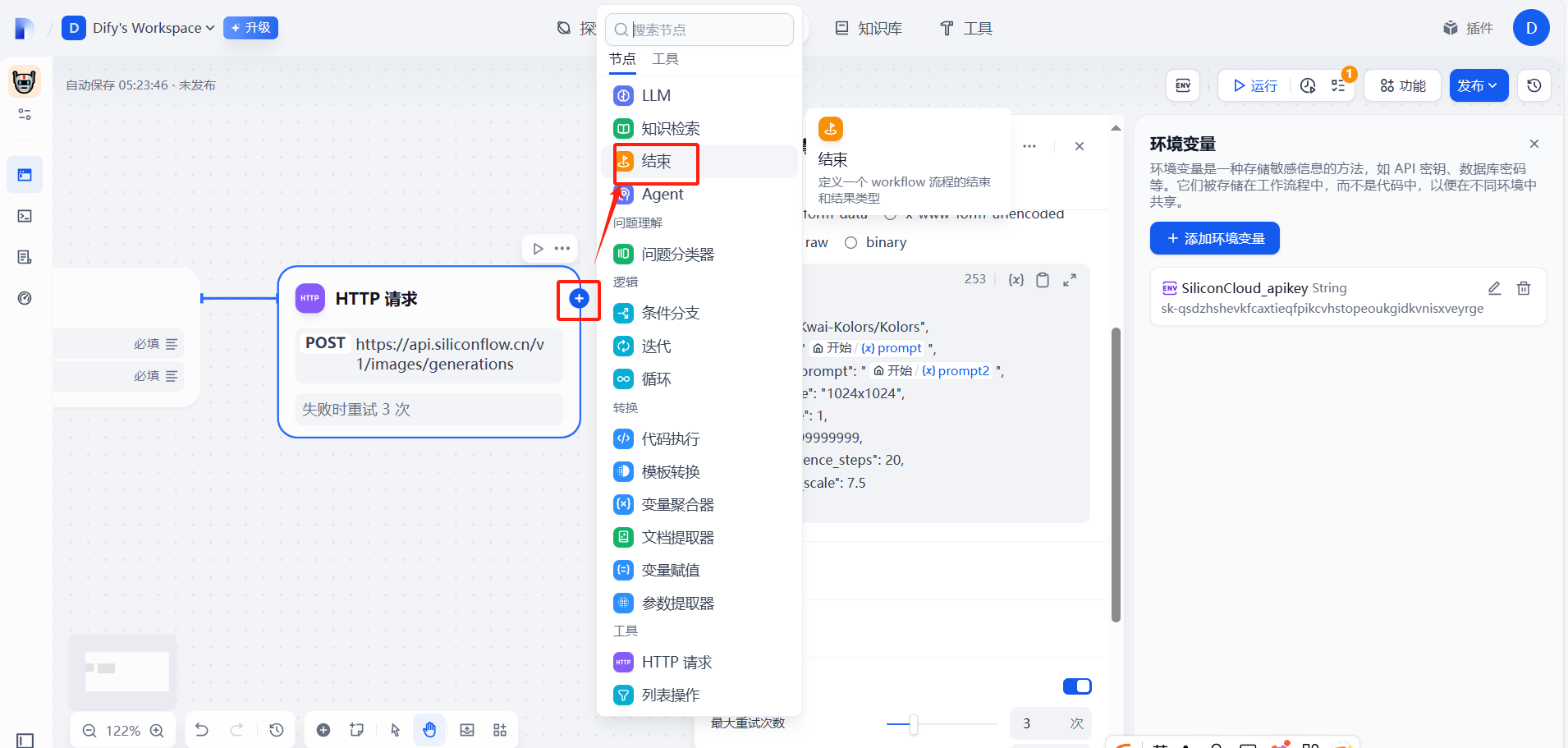
(4)添加結束回復節點
(5)測試運行
?編輯?(6)調整json格式
?(7)運行成功?編輯
?(8)查看圖片
六、提取json中url數據
(1)添加參數提取器?
?(2)配置信息?編輯
?(3)運行測試
?編輯
(4)添加代碼執行
?(5)輸出參數
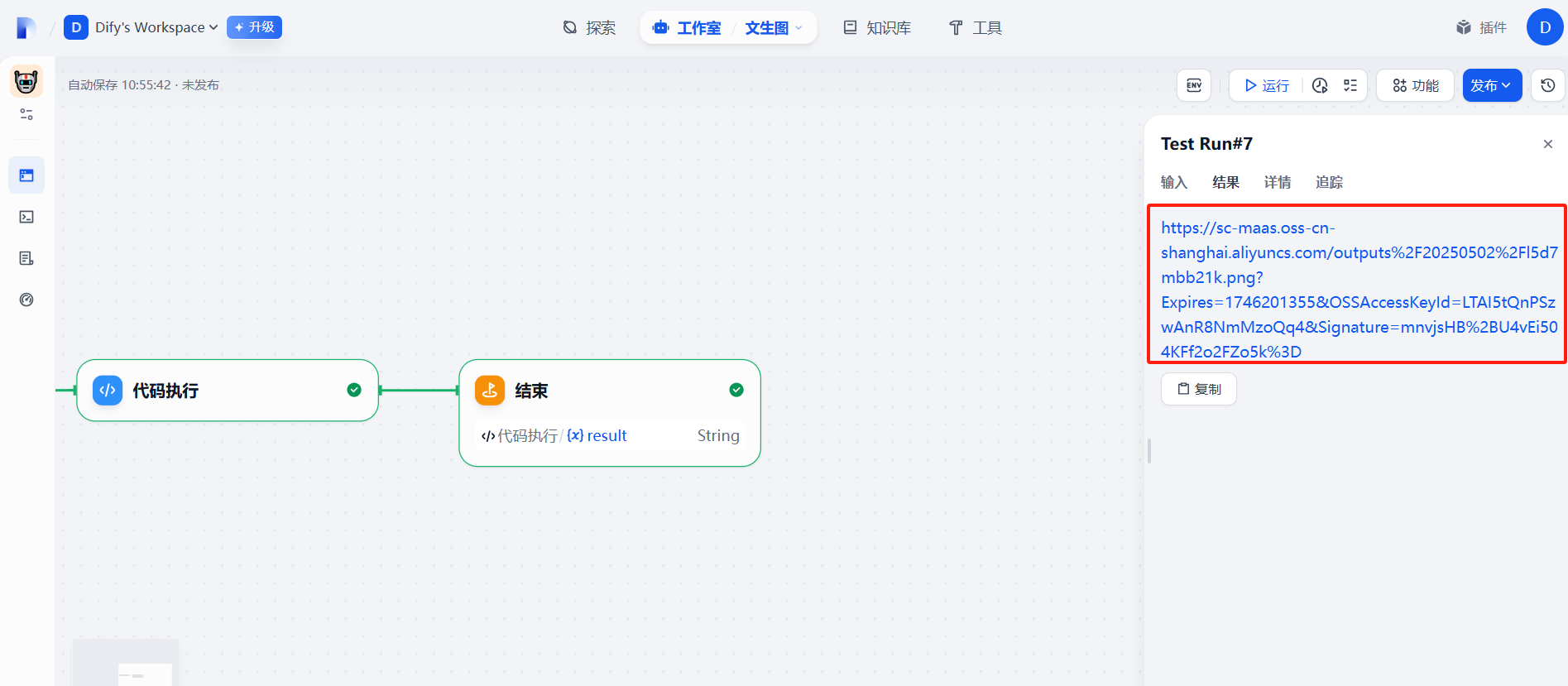
(6)運行
?七、發布為工具

第一部分:【dify+docker安裝教程】-CSDN博客
第二部分:【dify—2】docker重裝-CSDN博客
第三部分:【dify—3】拉取鏡像、本地訪問dify-CSDN博客
第四部分:【dify—4】安裝Ollama,部署Deepseek-R1模型-CSDN博客
第五部分:【dify—5】Dify關聯Ollama-CSDN博客
第六部分:【dify—6】聊天模型應用實踐-CSDN博客
第七部分:【dify—7】文本生成應用實戰——學員周報生成-CSDN博客
第八部分:【dify—8】Agent實戰——占星師-CSDN博客
第九部分:【dify—9】Chatflow實戰——博客文章生成器-CSDN博客
本文主要介紹了通過創建工作流 完成了一個文生圖的簡單流程。講解了從配置硅基流動,Postman測試API,代碼執行提取url地址到實現發布的全流程。
一、創建工作流應用
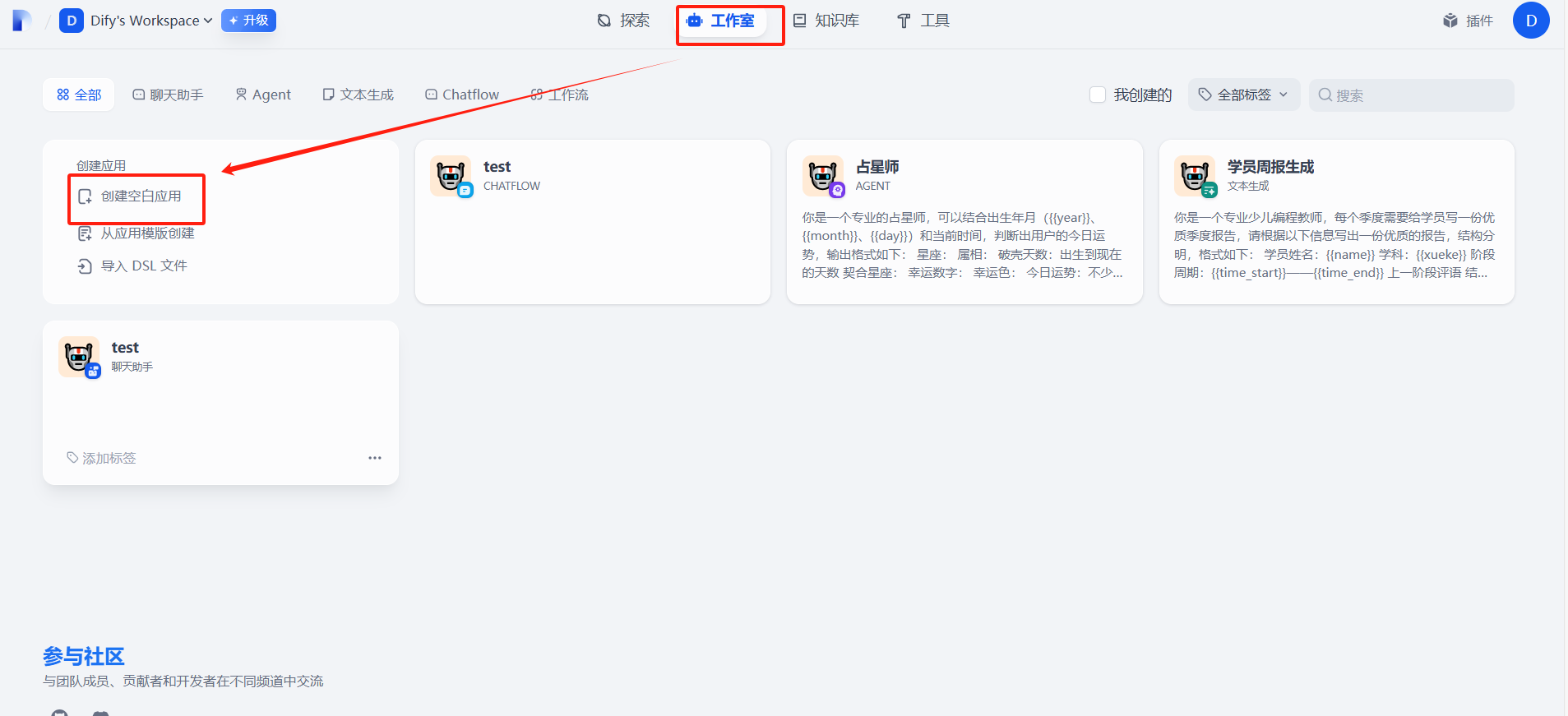
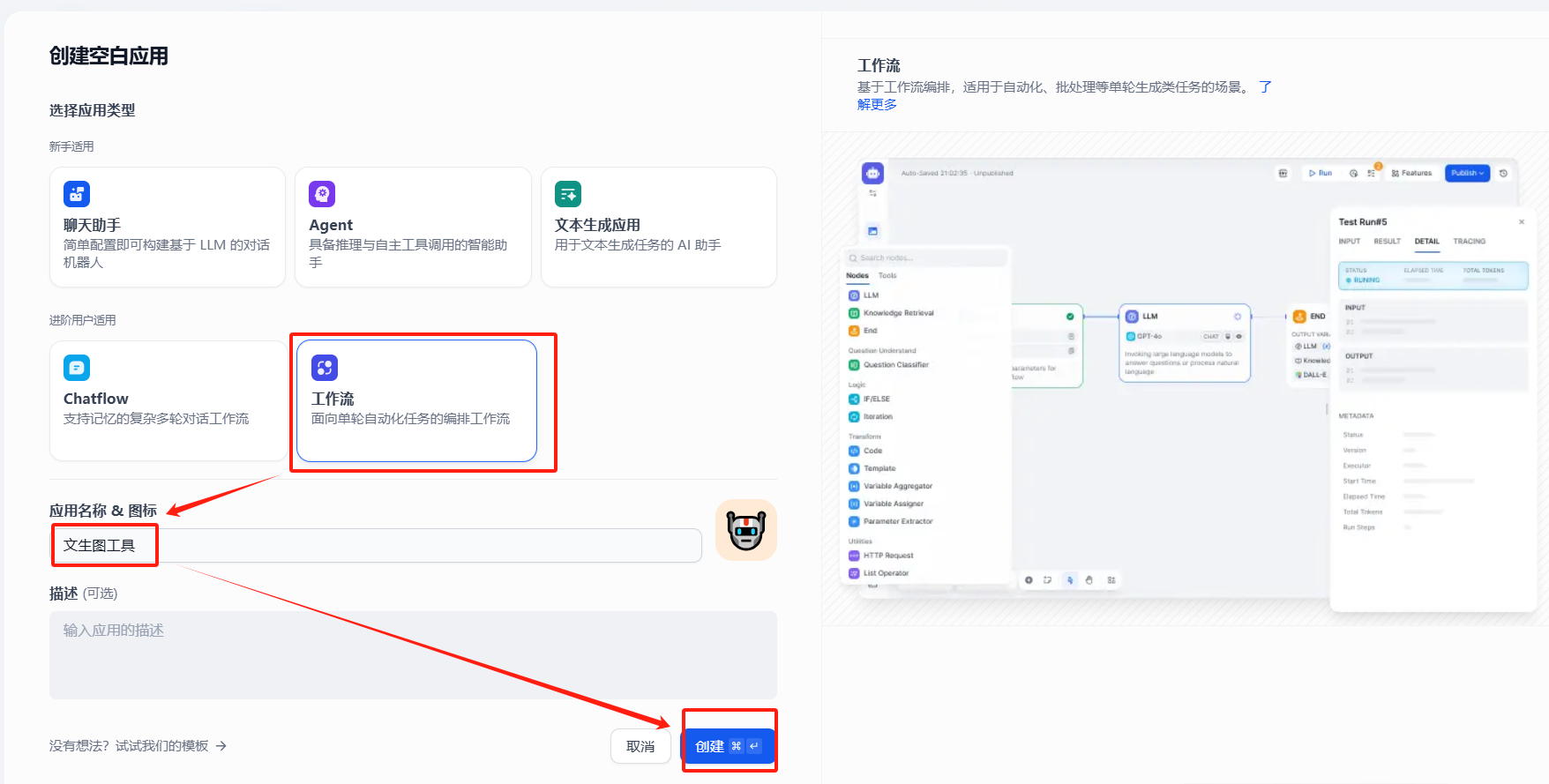
?
二、安裝硅基流動
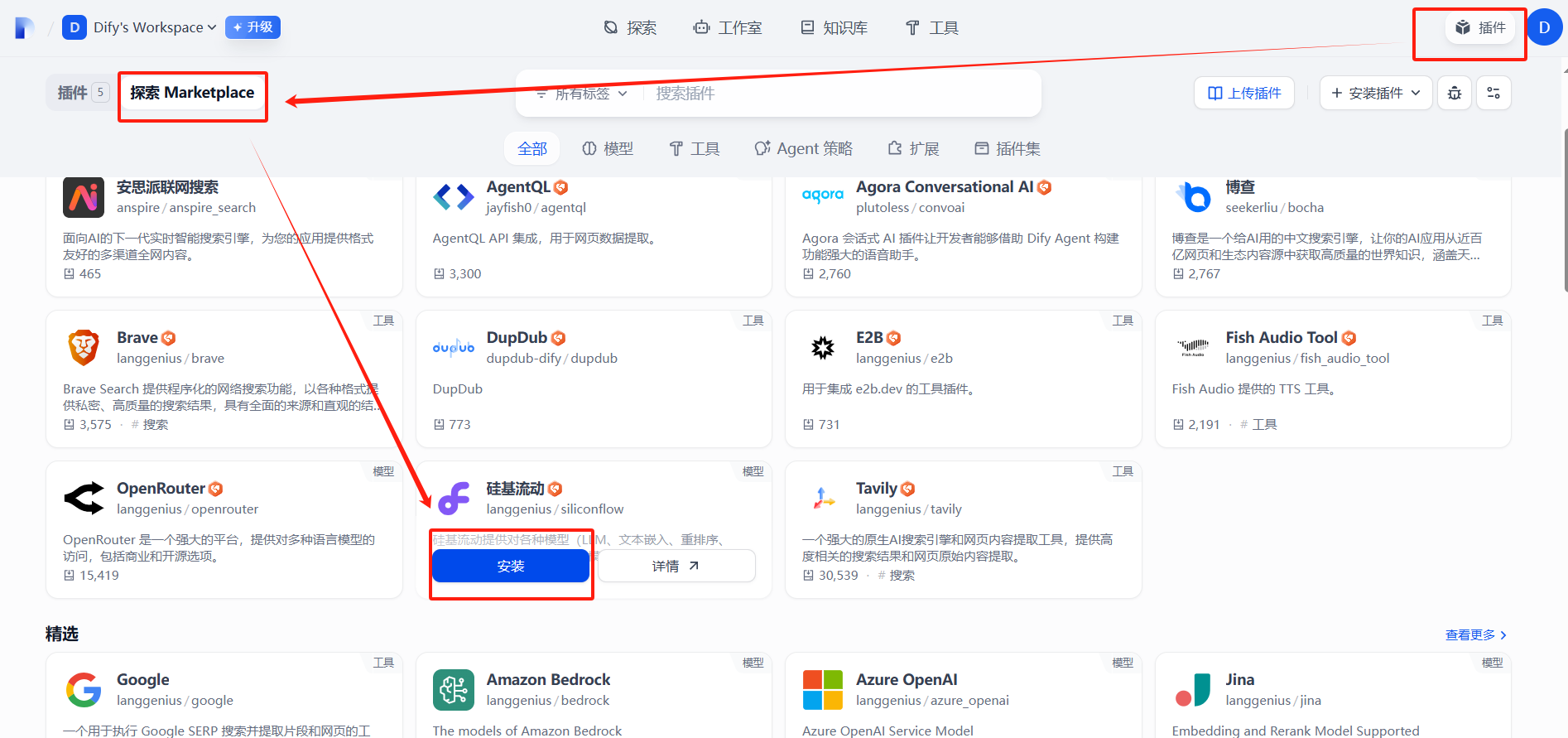
?
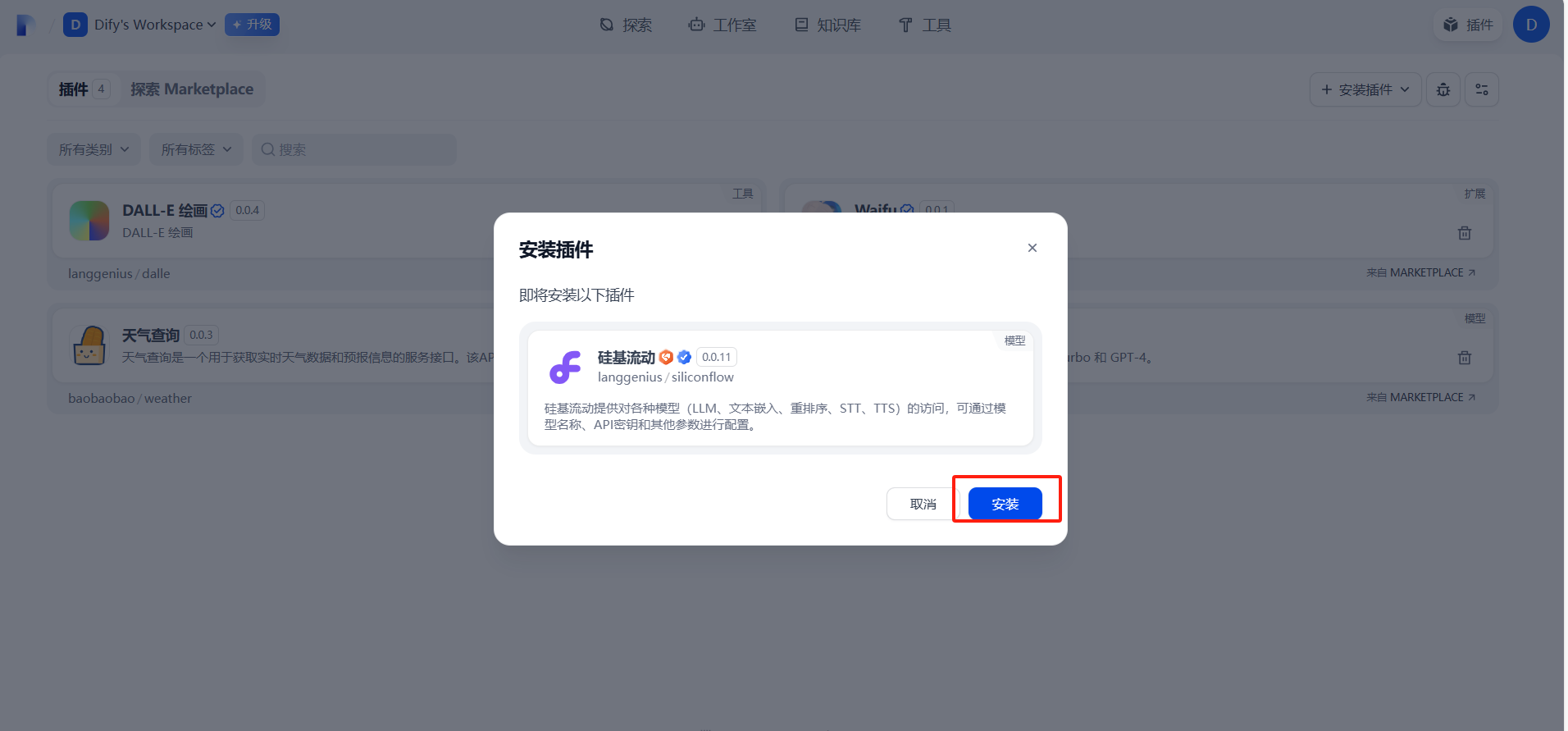
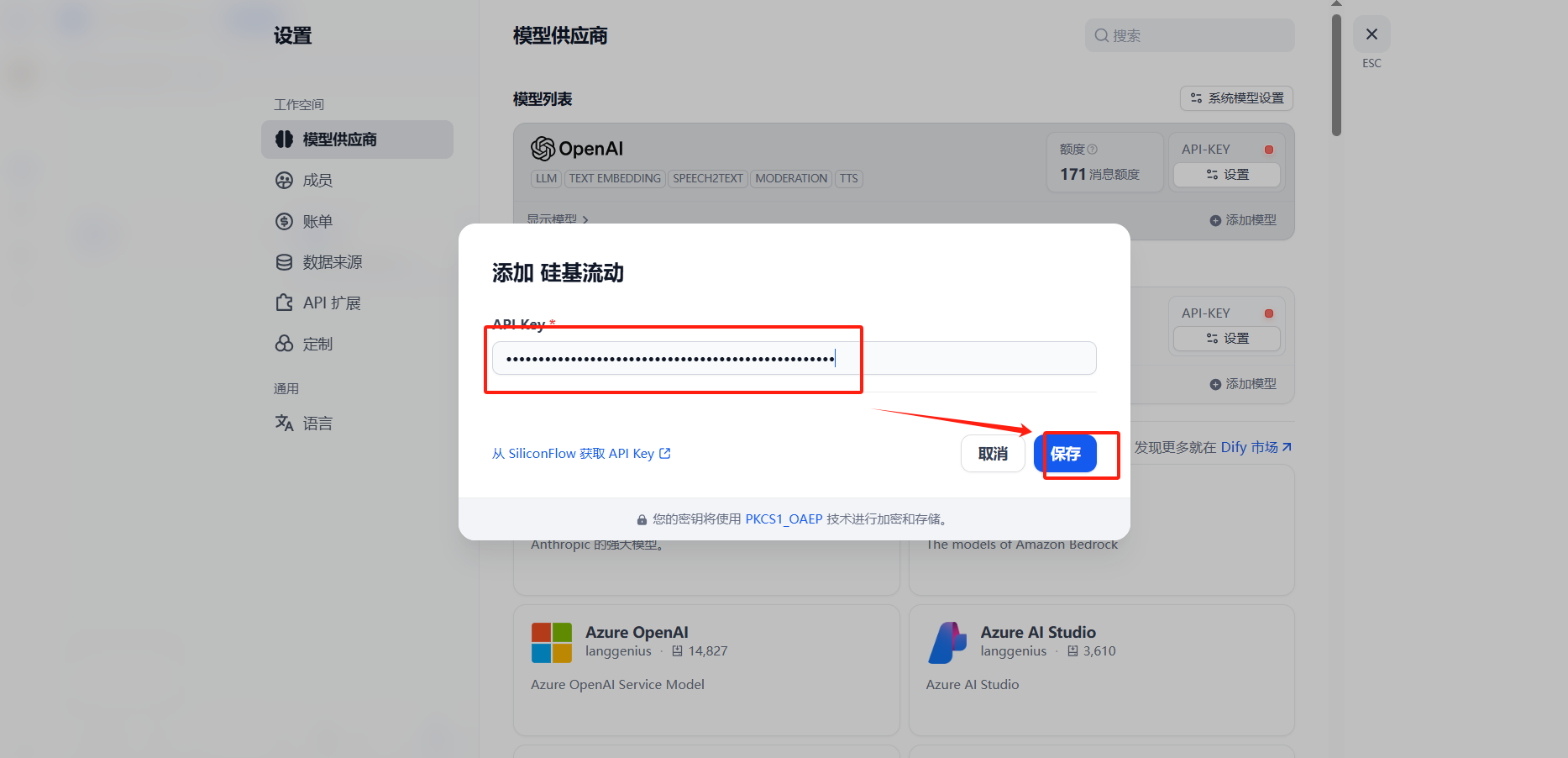
三、配置硅基流動
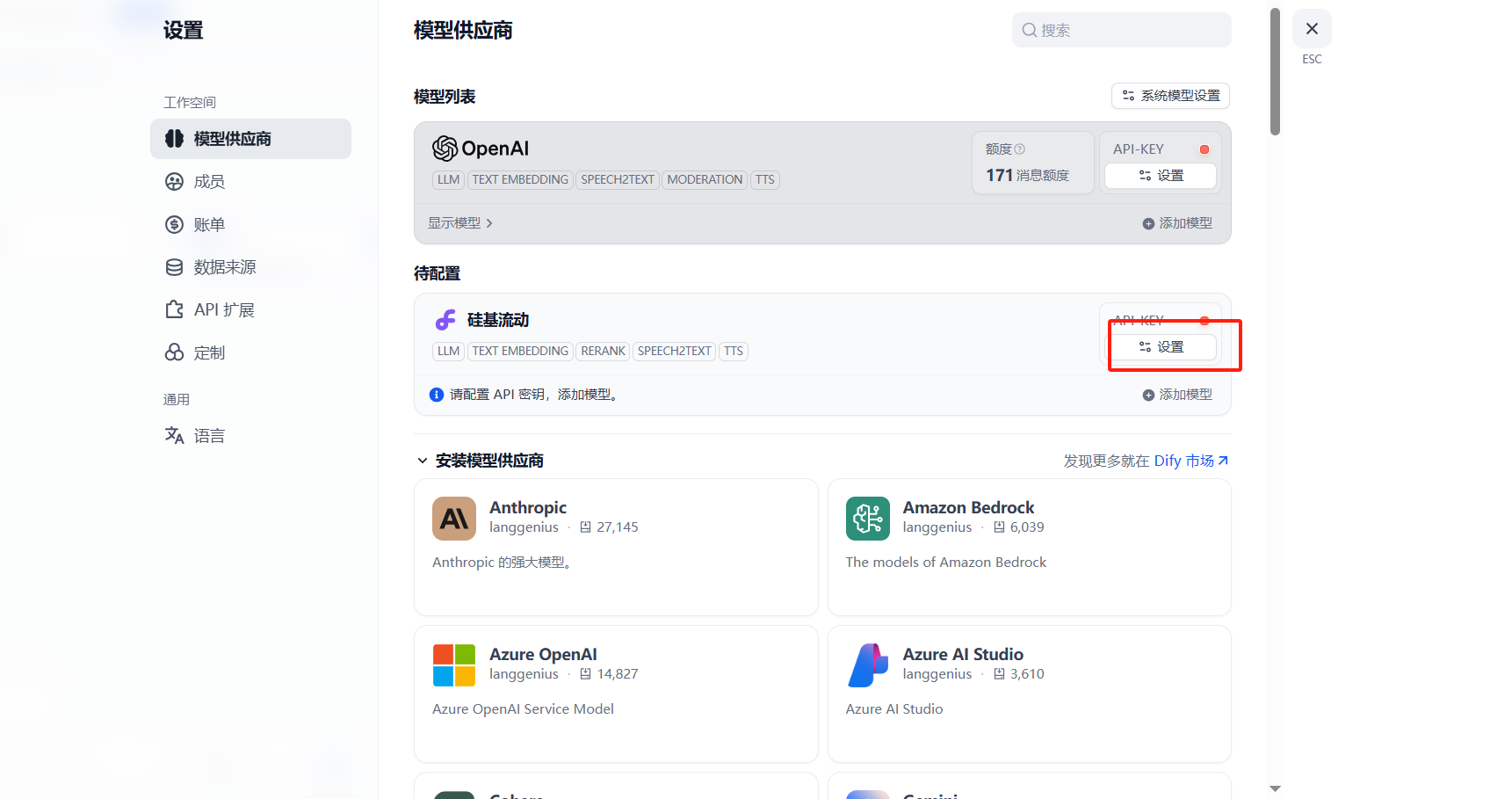
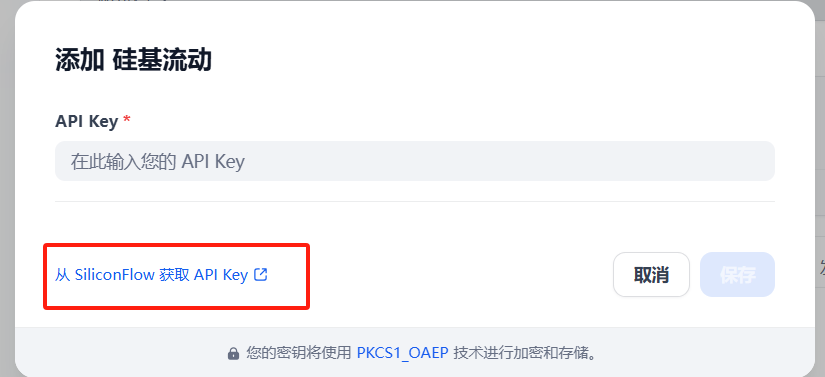

?四、API測試
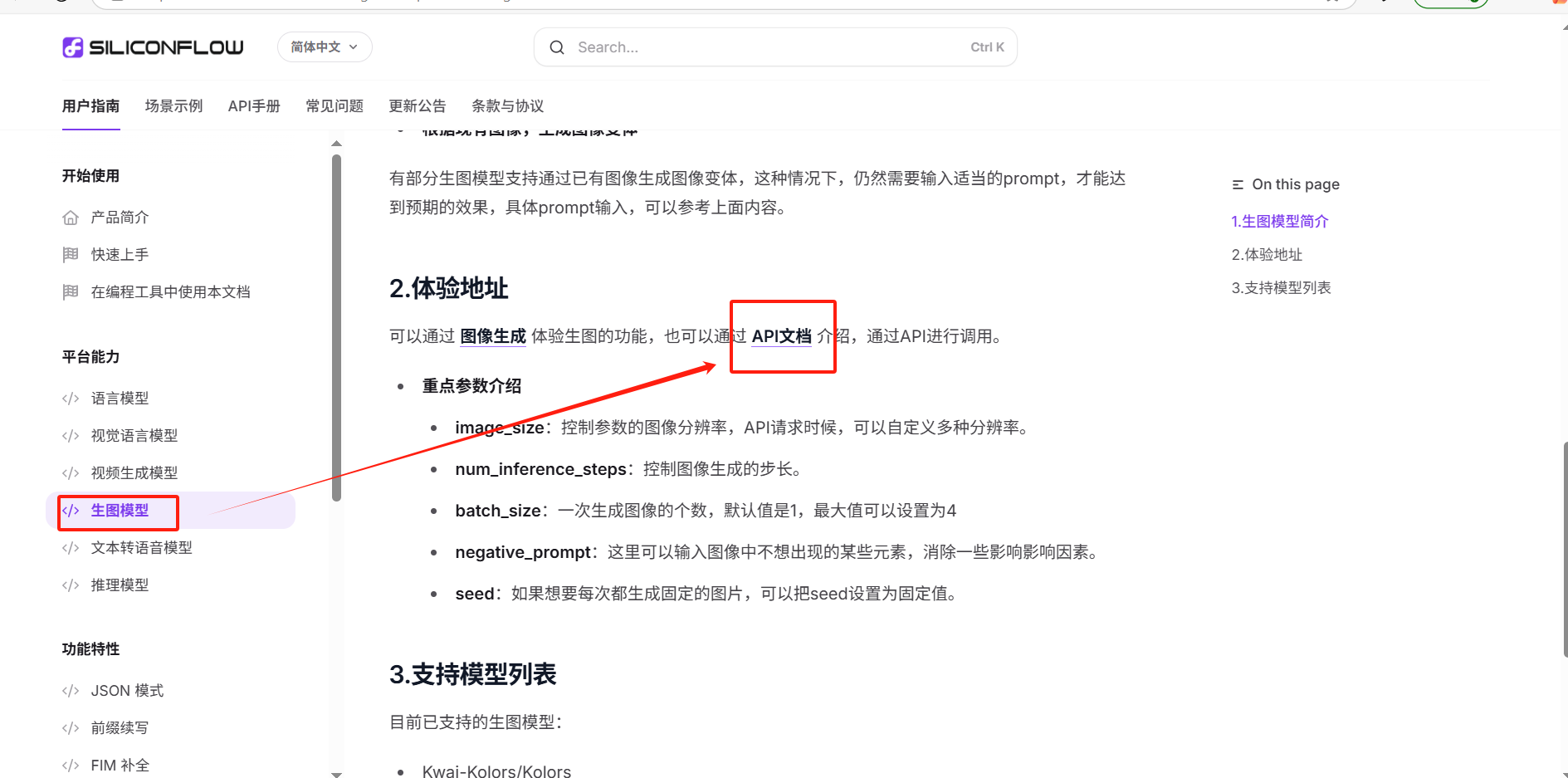
(1)進入API文檔
回到硅基流動,進入生圖模型的API文檔
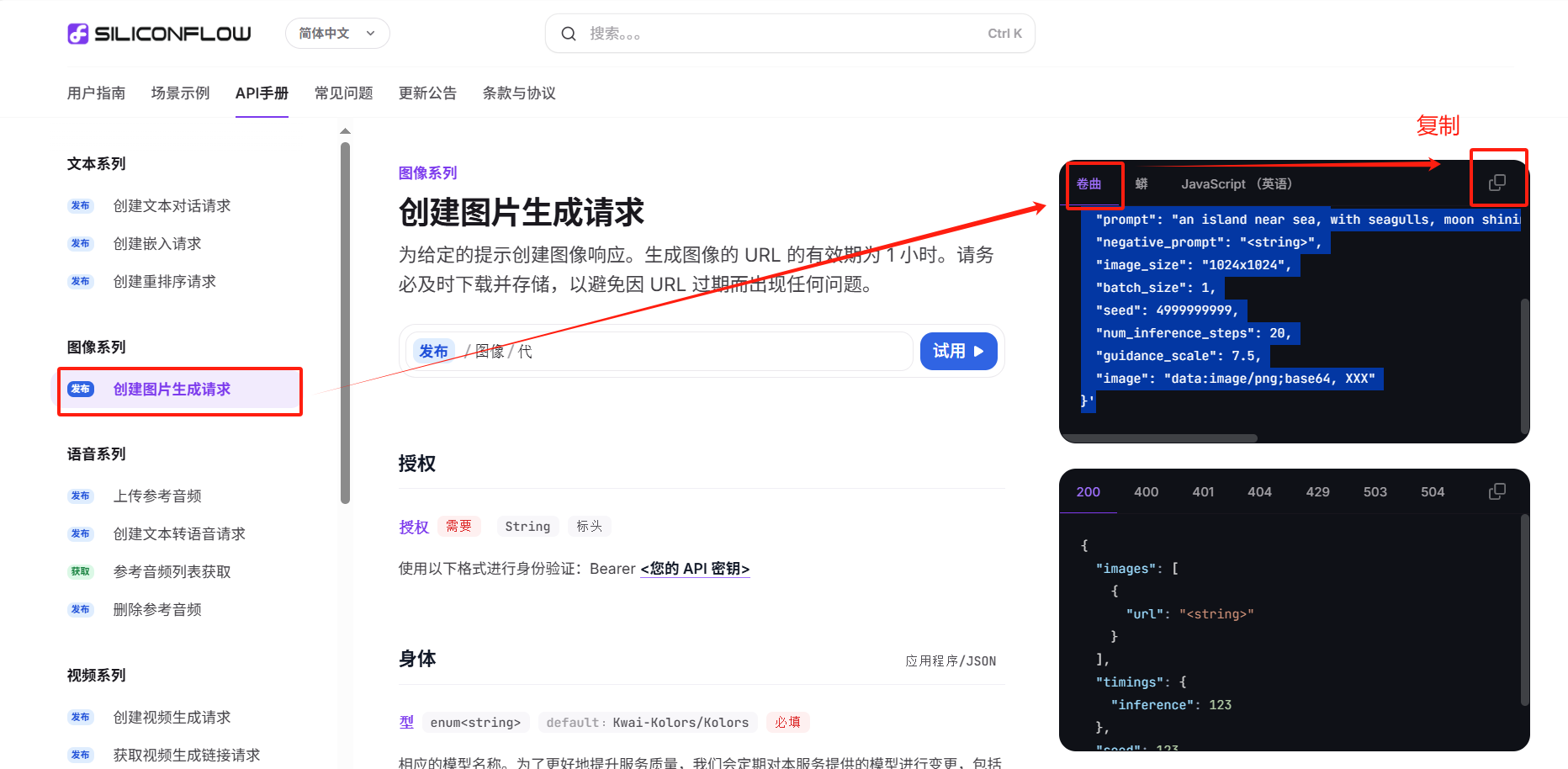
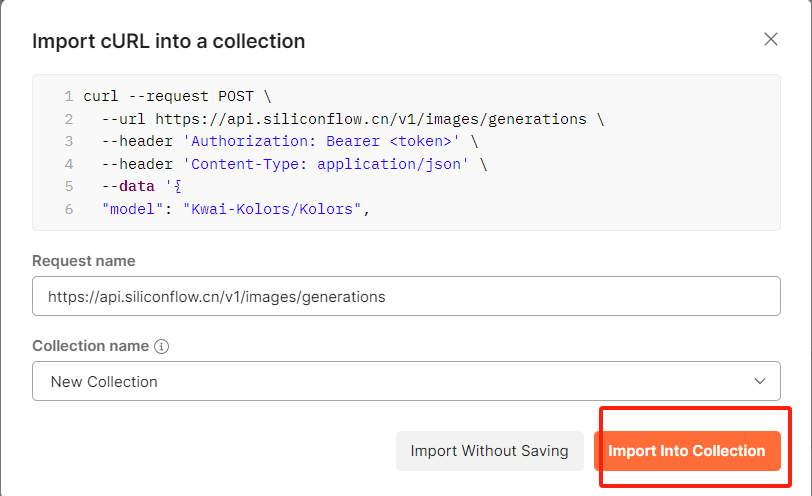
?(2)復制curl代碼
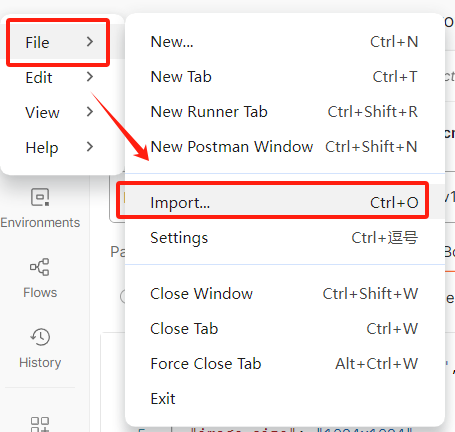
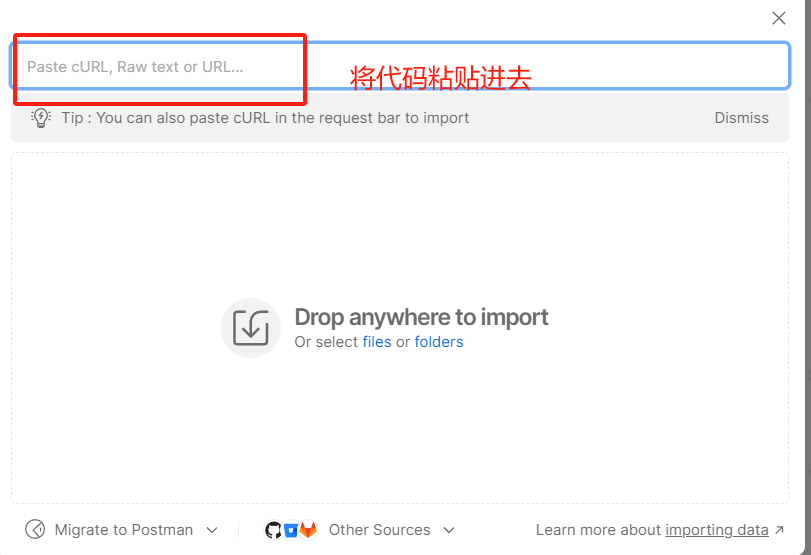
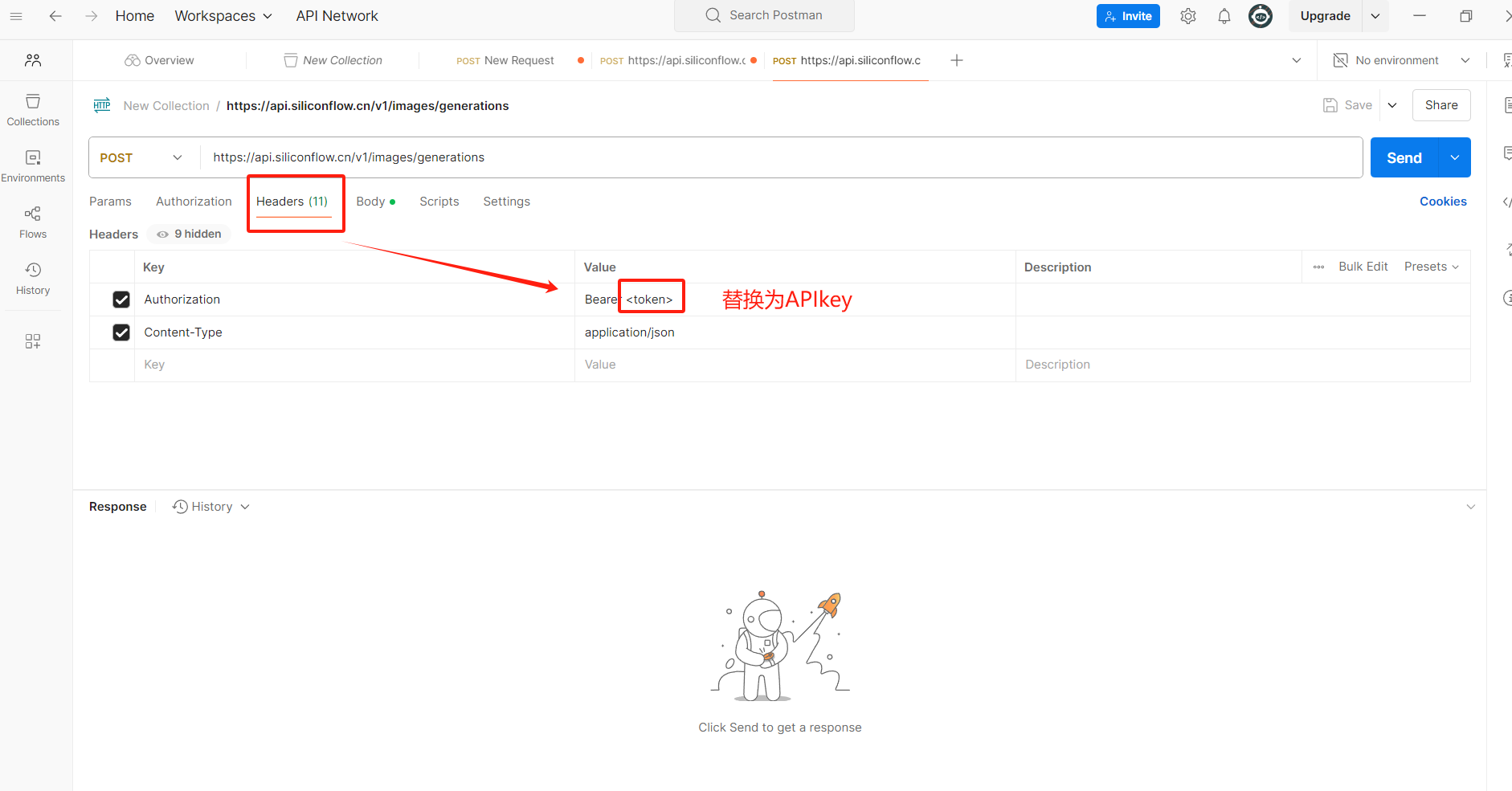
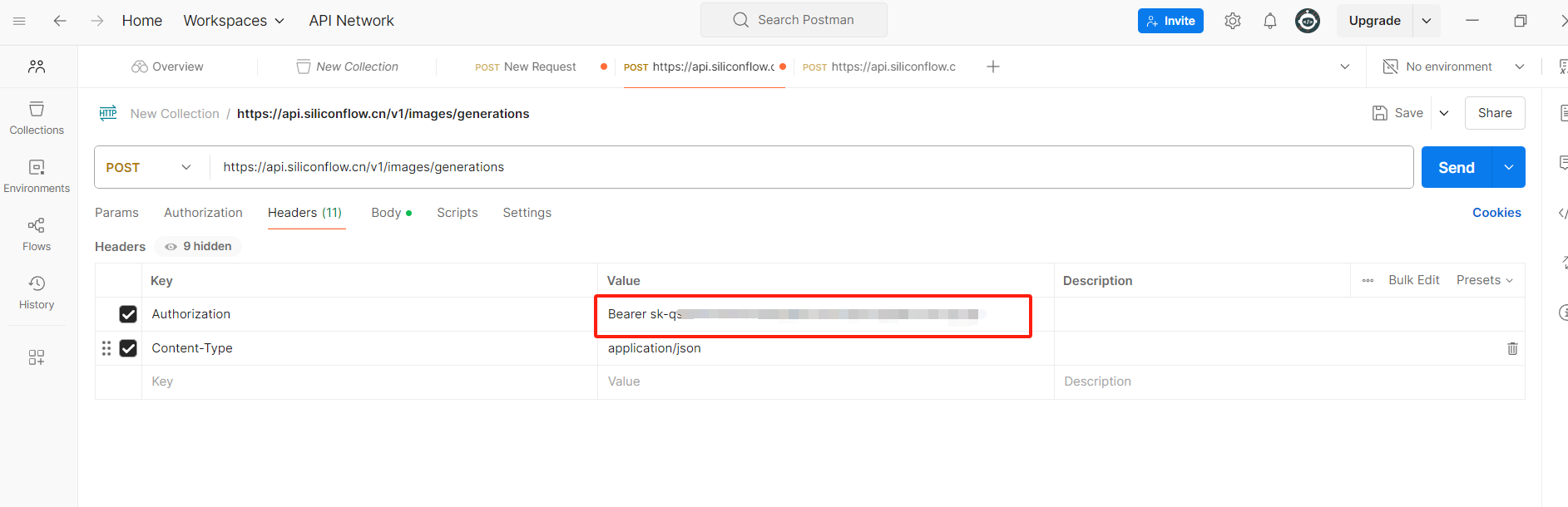
(3)Postman測試API
注意:需要先下載一個Postman
打開Postman
?????
?
重點參數介紹
image_size:控制參數的圖像分辨率,API請求時候,可以自定義多種分辨率。
num_inference_steps:控制圖像生成的步長。
batch_size:一次生成圖像的個數,默認值是1,最大值可以設置為4
negative_prompt:這里可以輸入圖像中不想出現的某些元素,消除一些影響影響因素。
seed:如果想要每次都生成固定的圖片,可以把seed設置為固定值。
??????
五、 建立文生圖工作流
(1)建立http請求
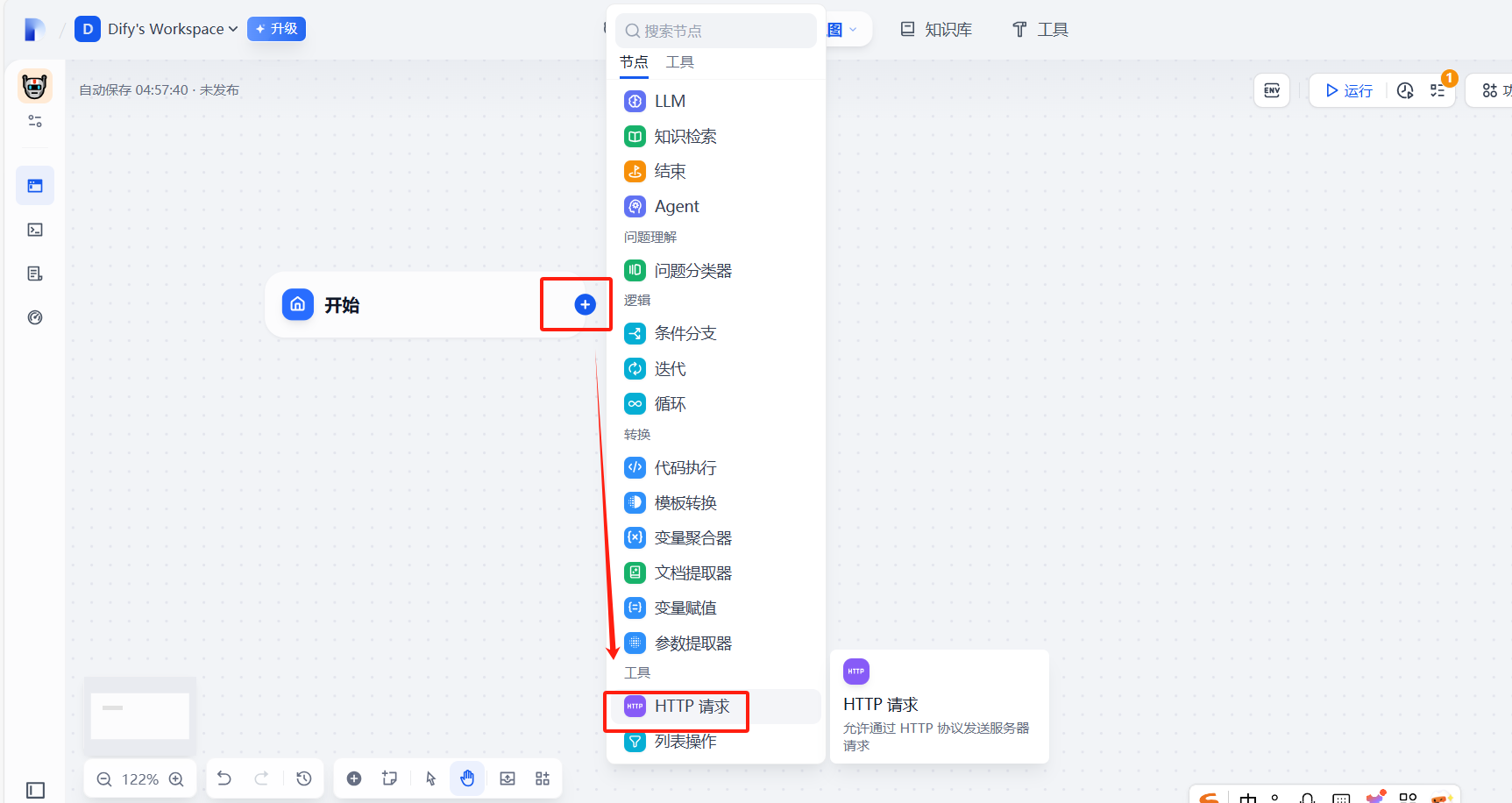
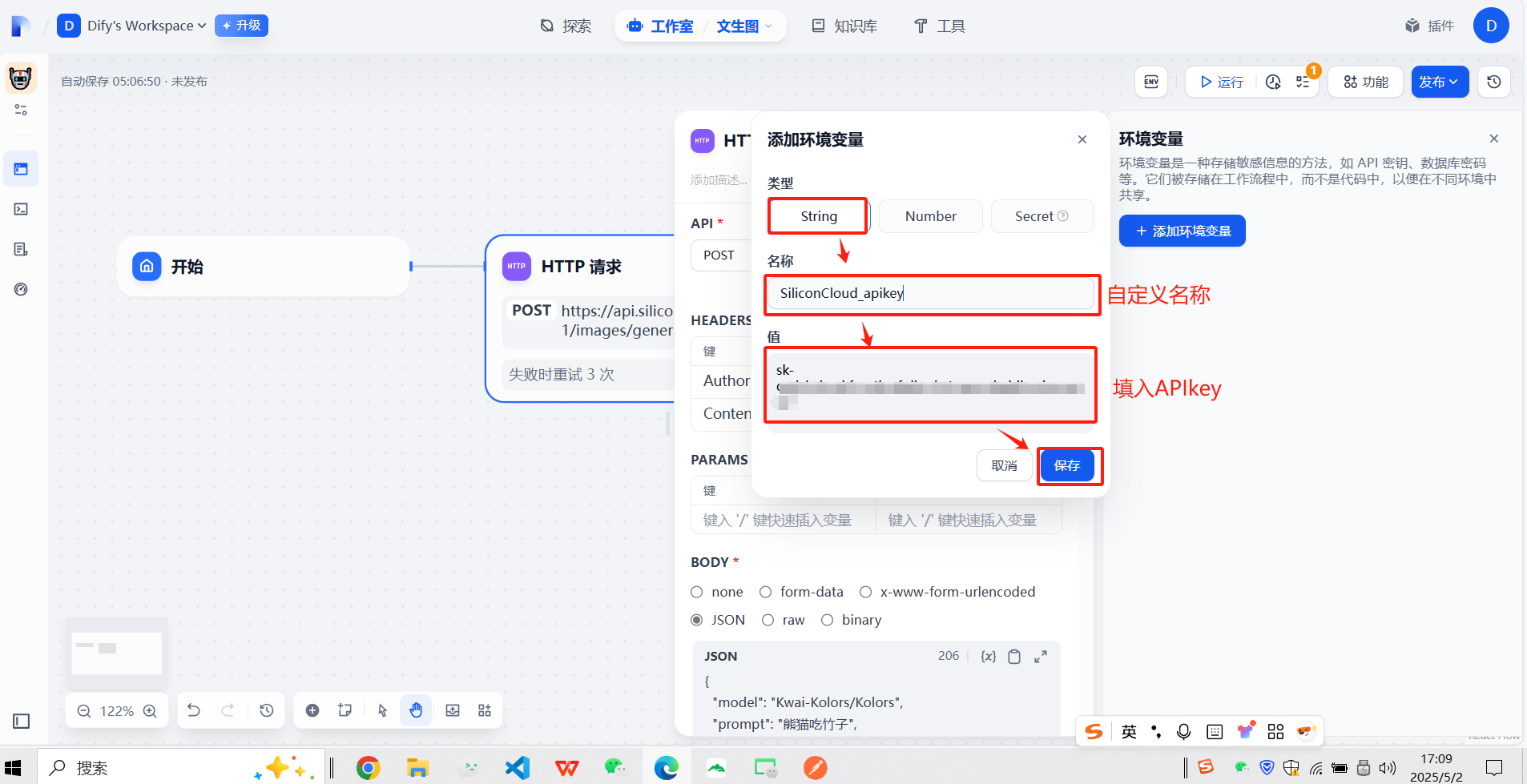
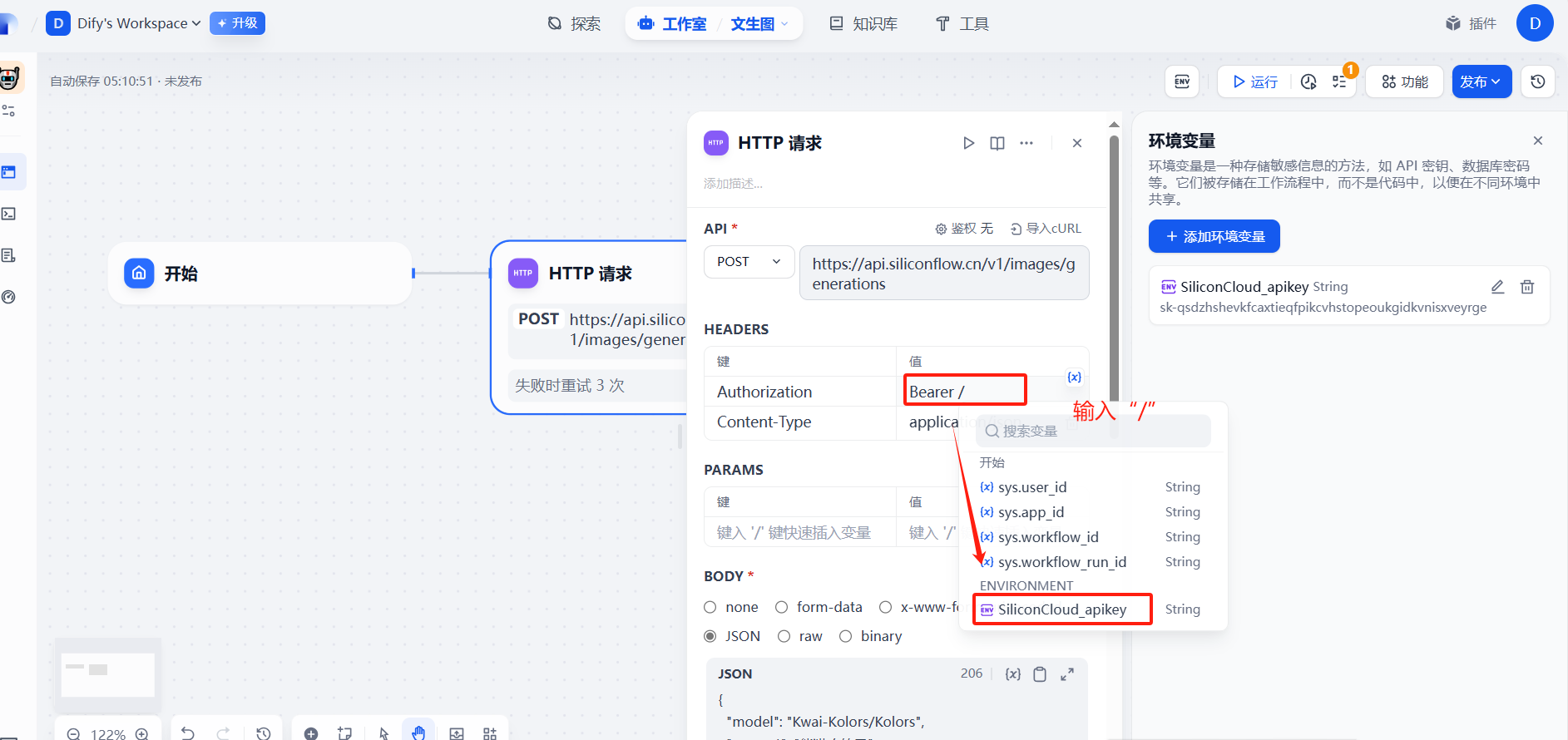
?(2)配置http請求信息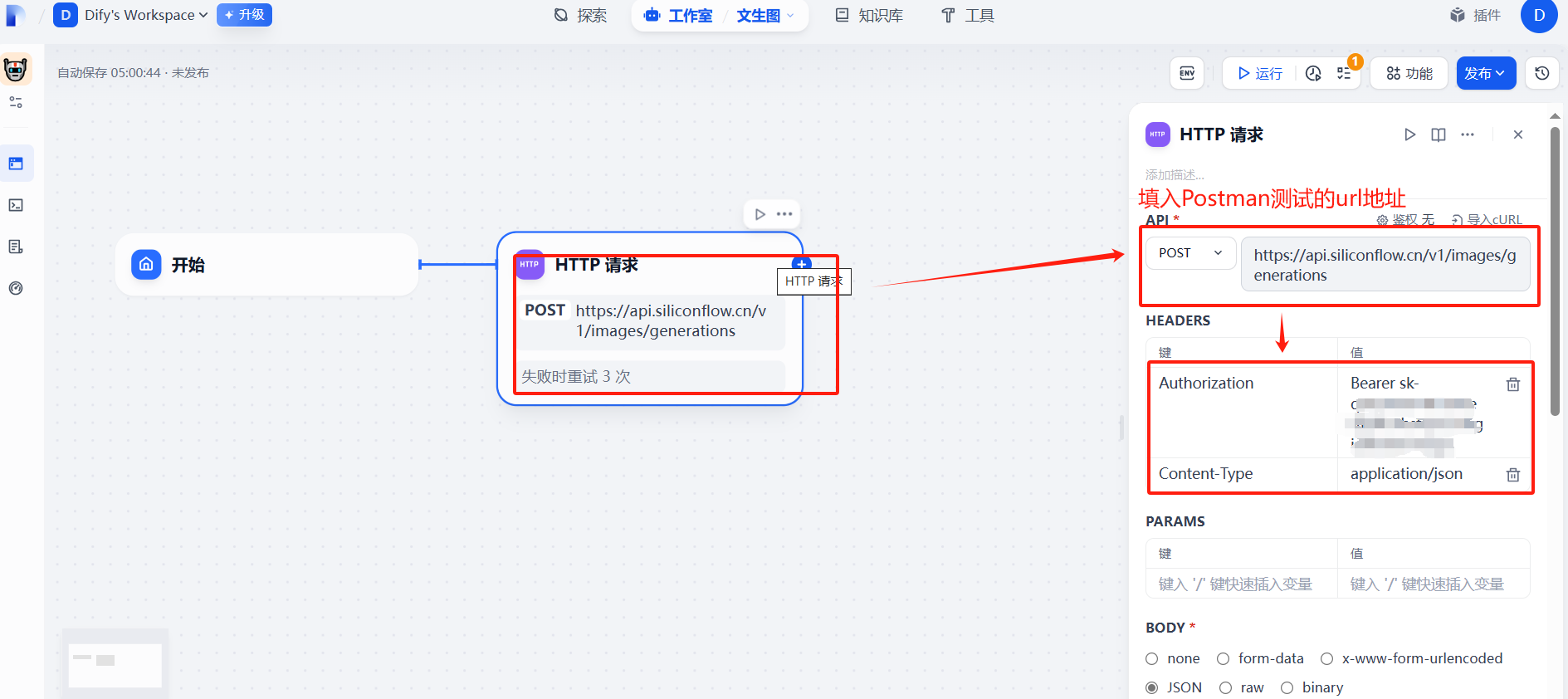
讓API不以明文顯示
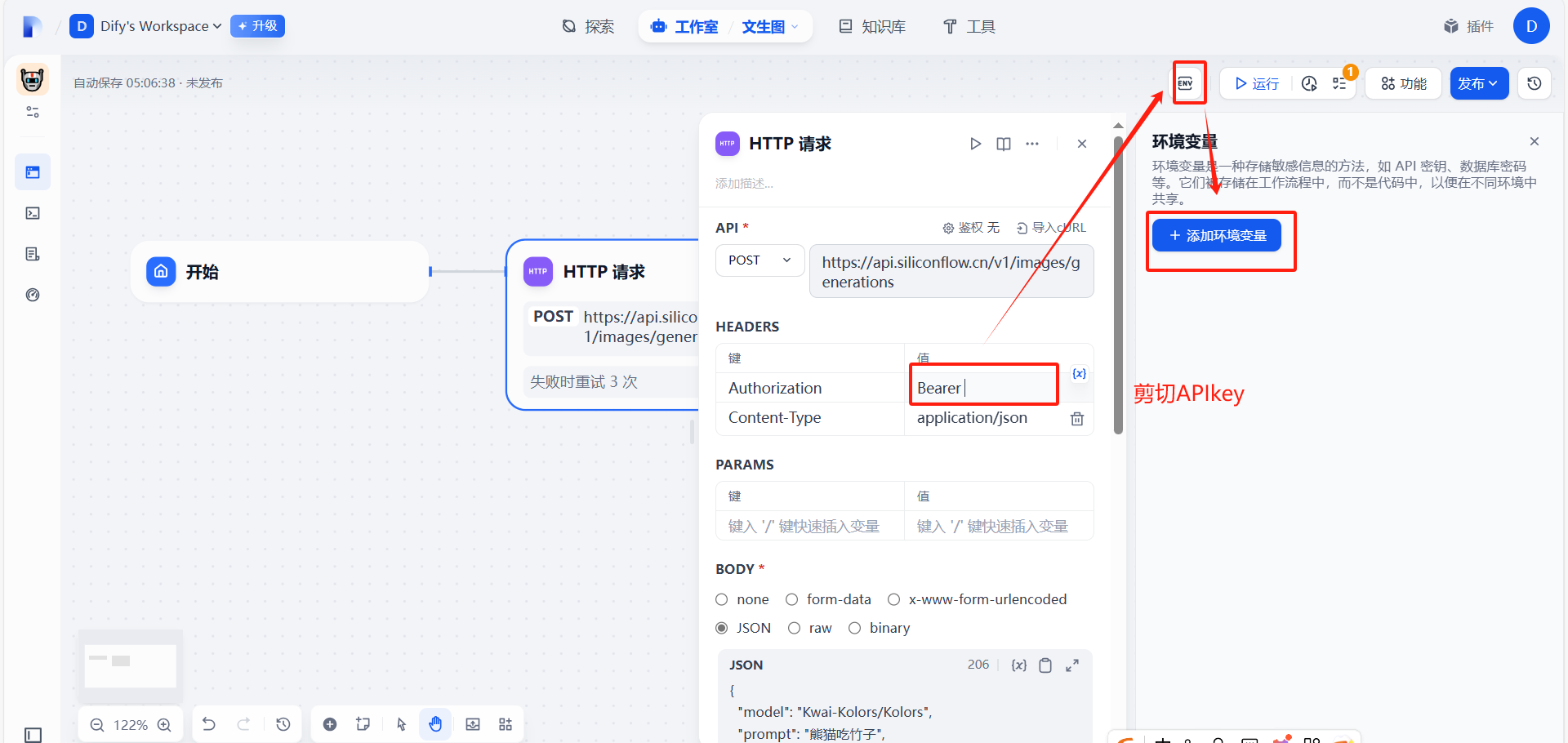
?
?
添加成功
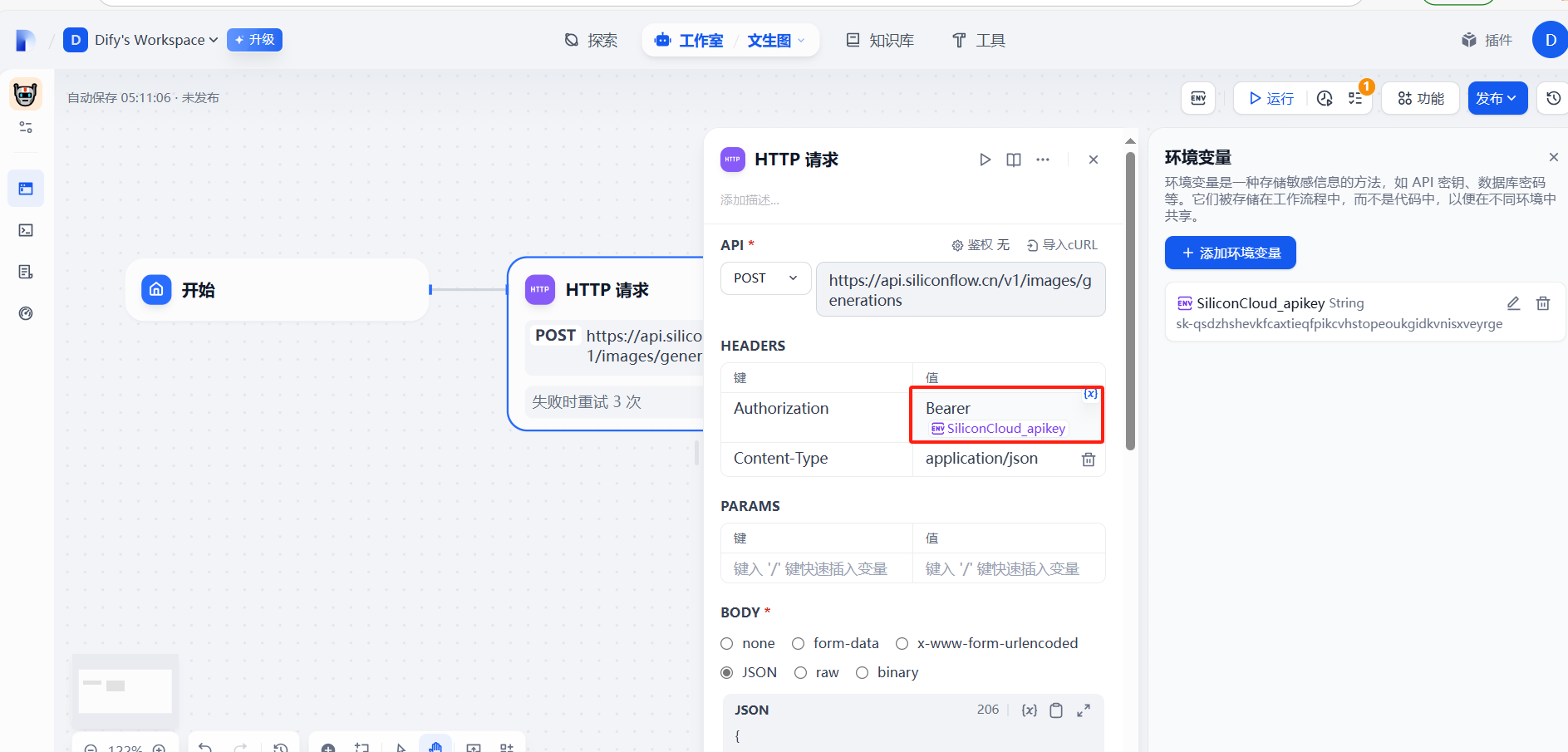
?
(3)提示詞prompt自定義
?
?
 ?
?
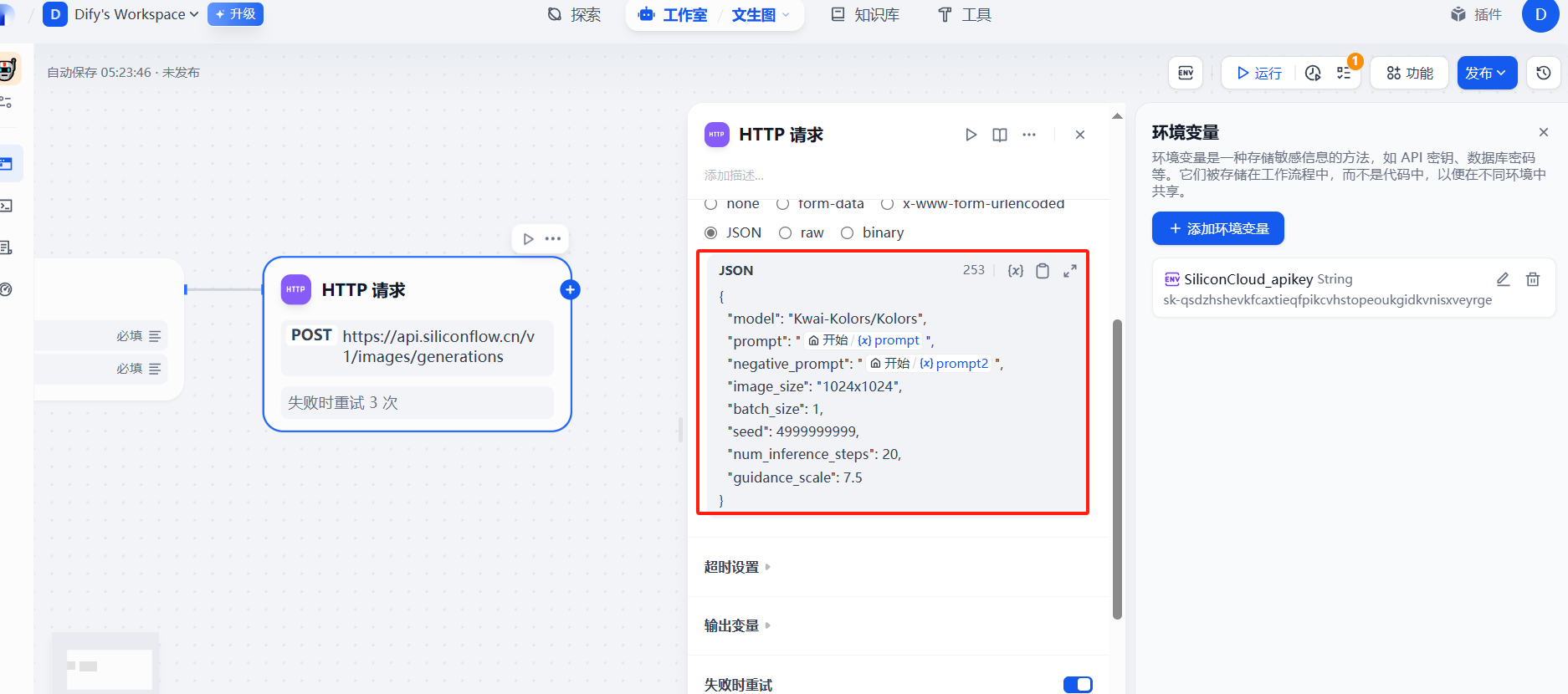
(4)添加結束回復節點
?
(5)測試運行
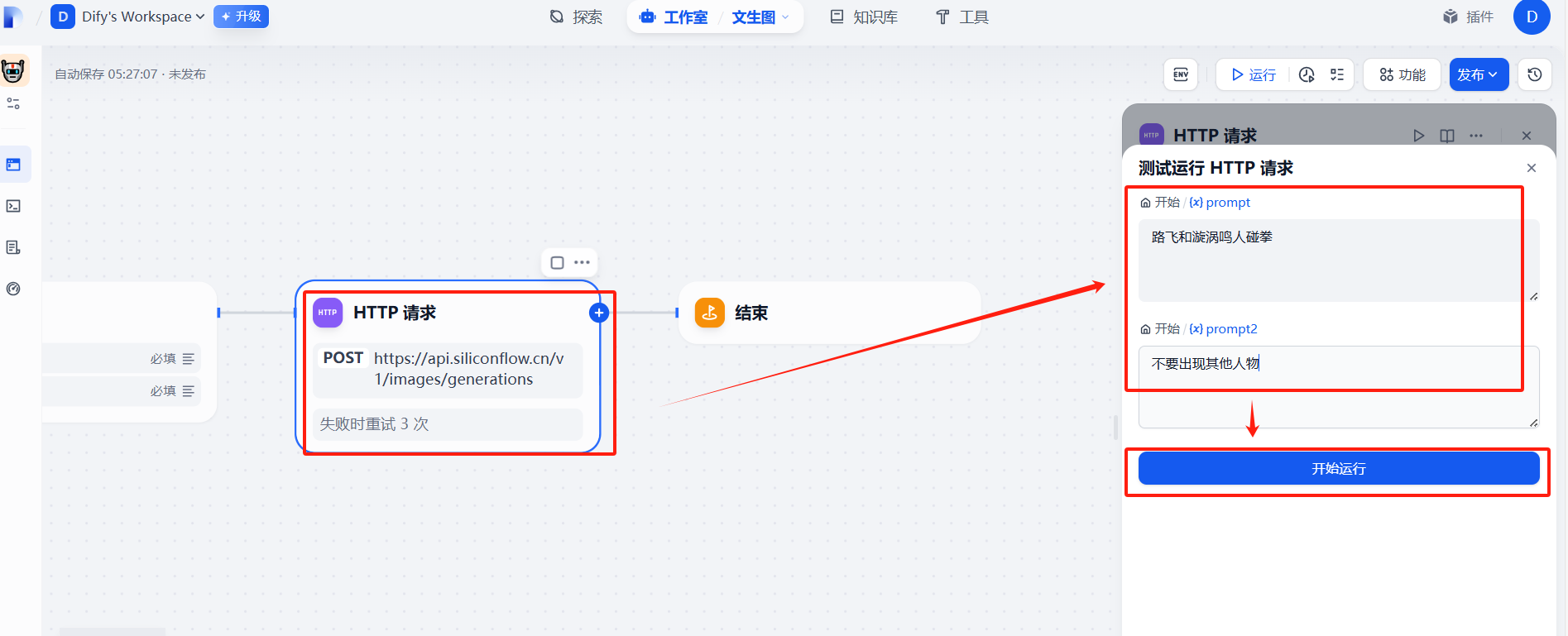
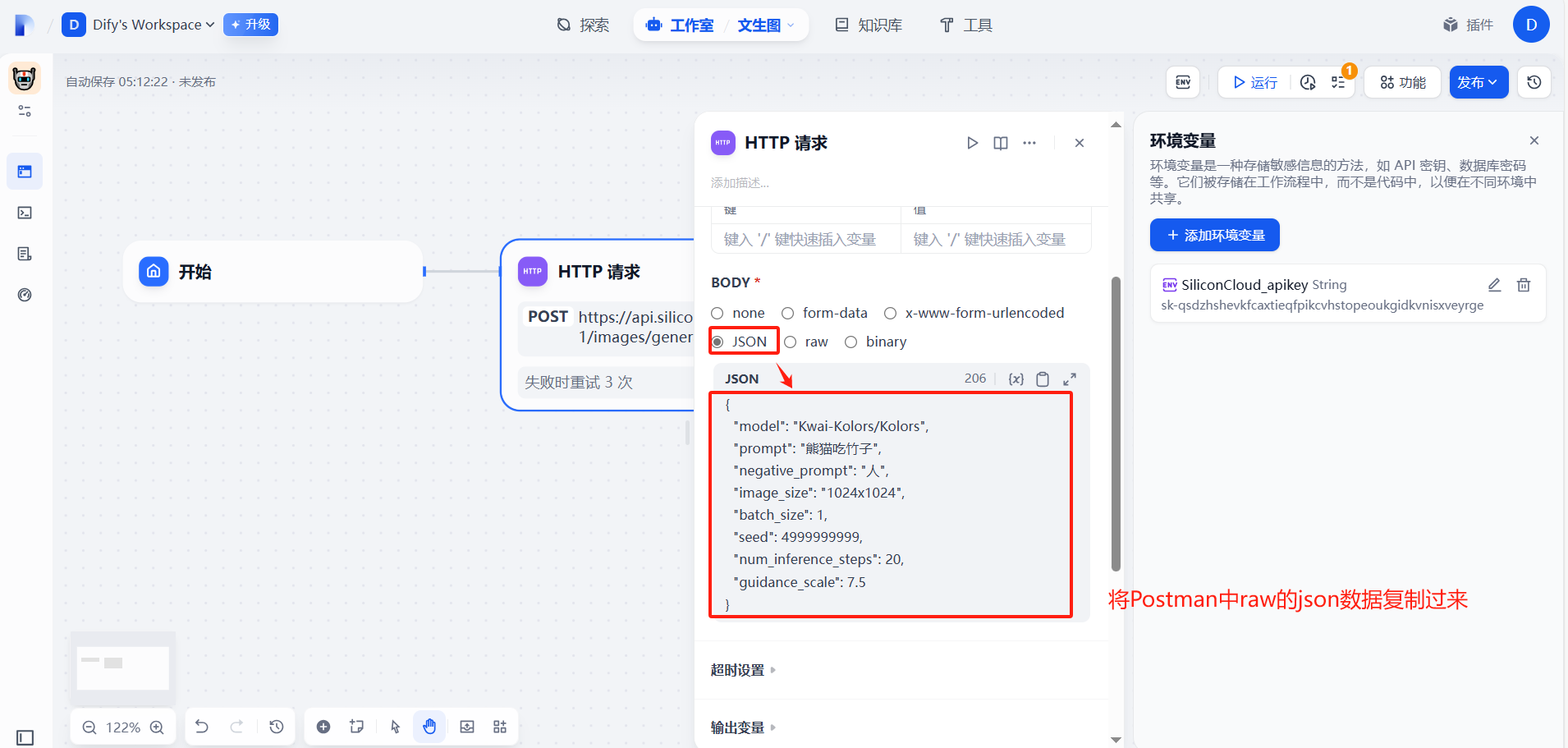
報錯,這里是json數據格式會出現問題,需要處理一下
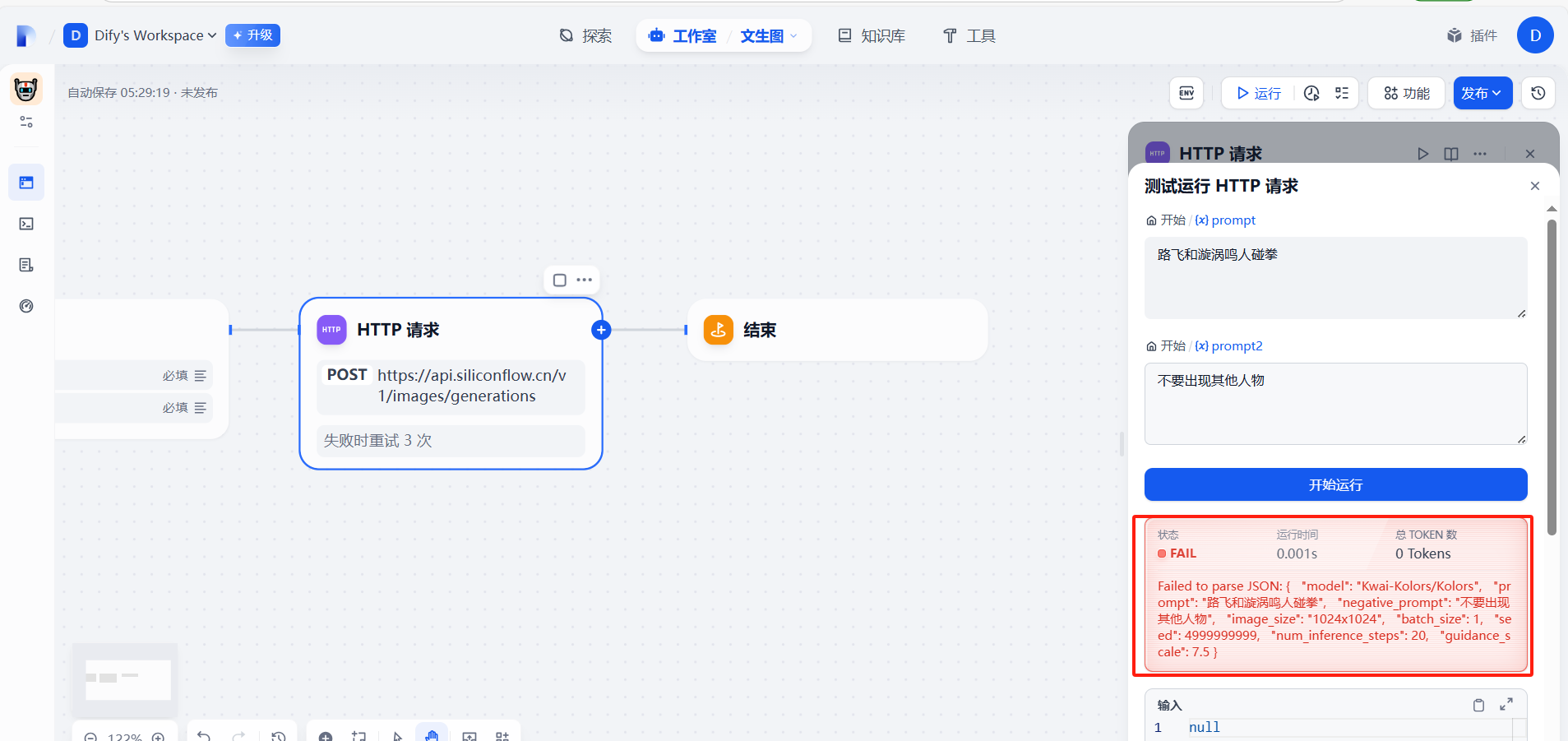 ?(6)調整json格式
?(6)調整json格式
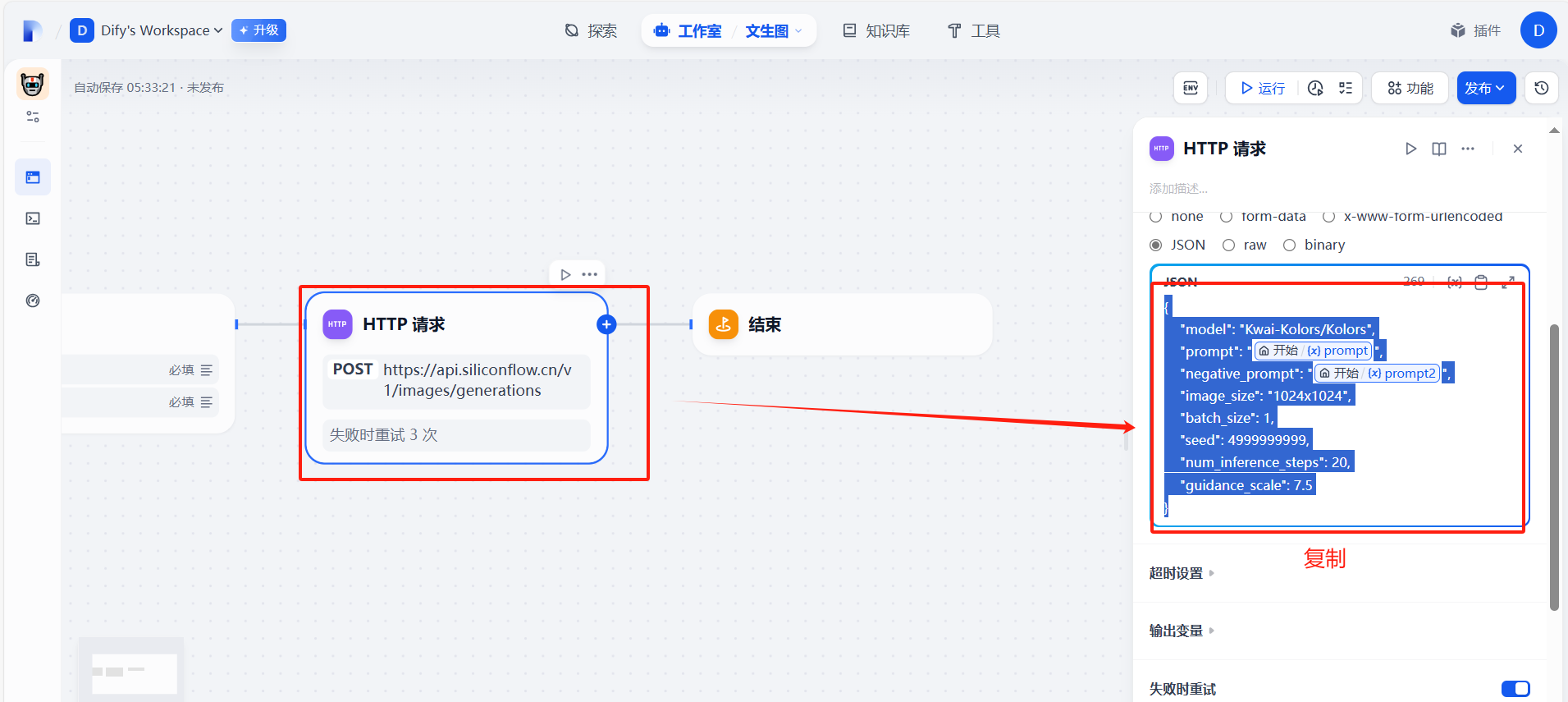
?在線插件json數據格式處理:爬蟲工具庫-spidertools.cn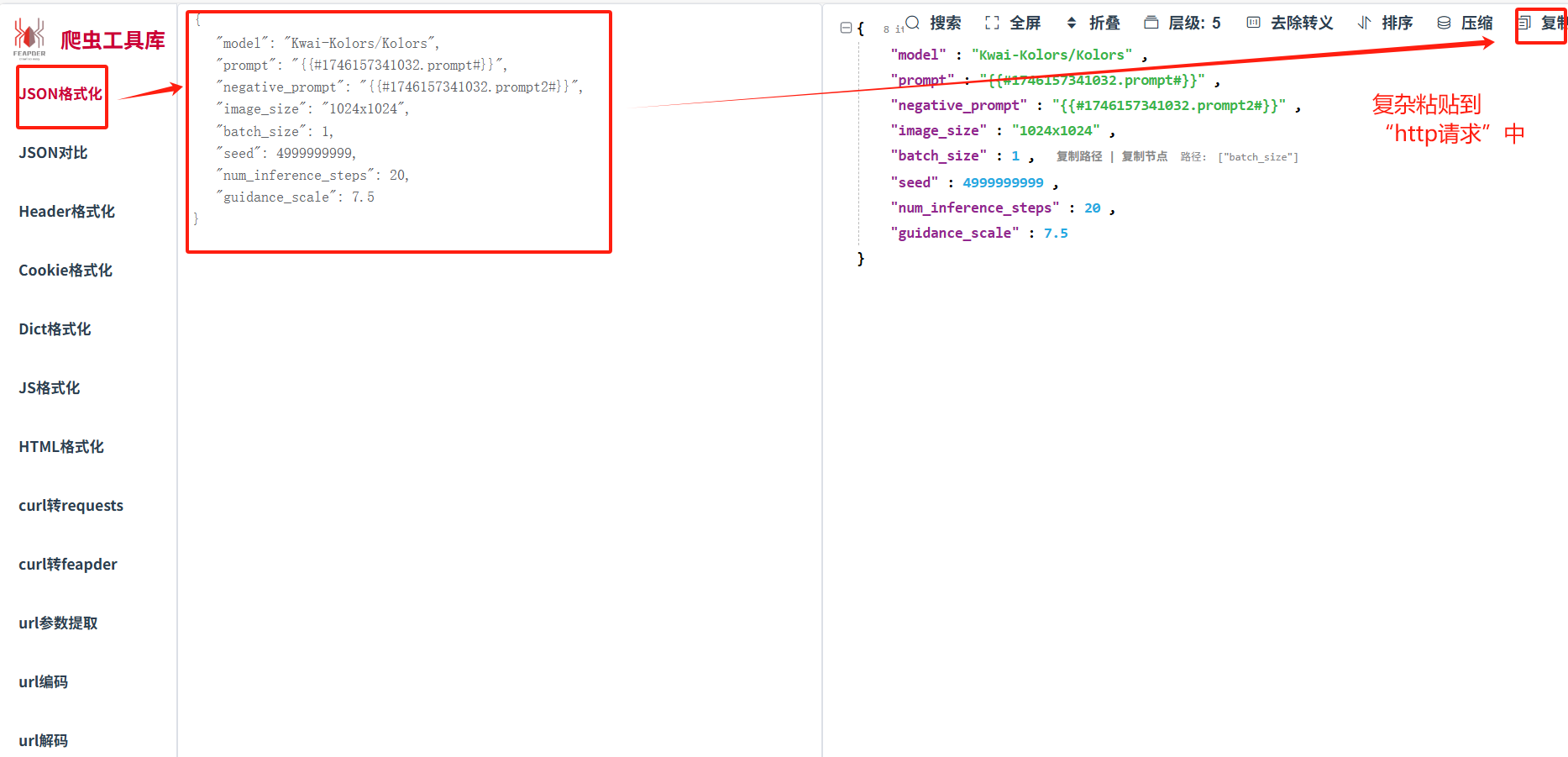
?(7)運行成功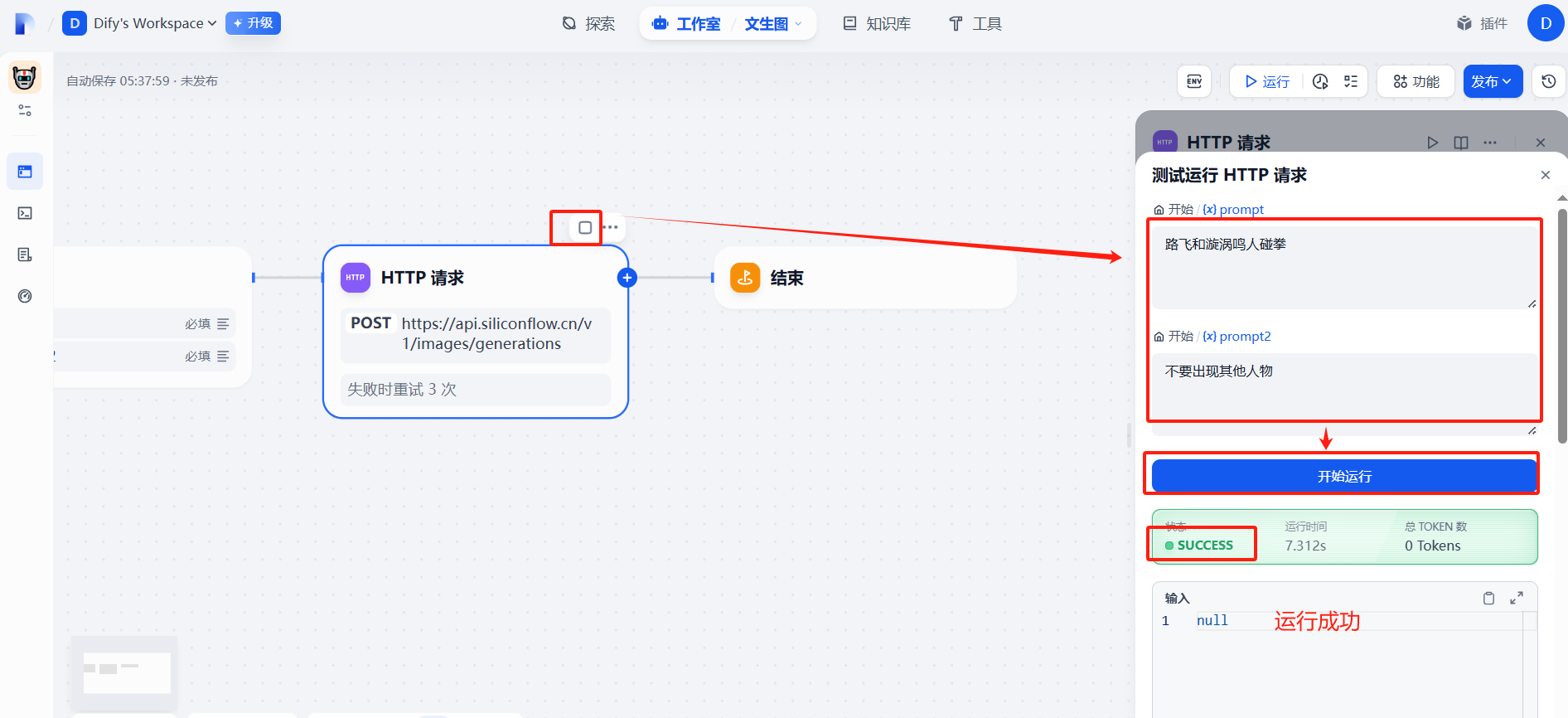
?(8)查看圖片
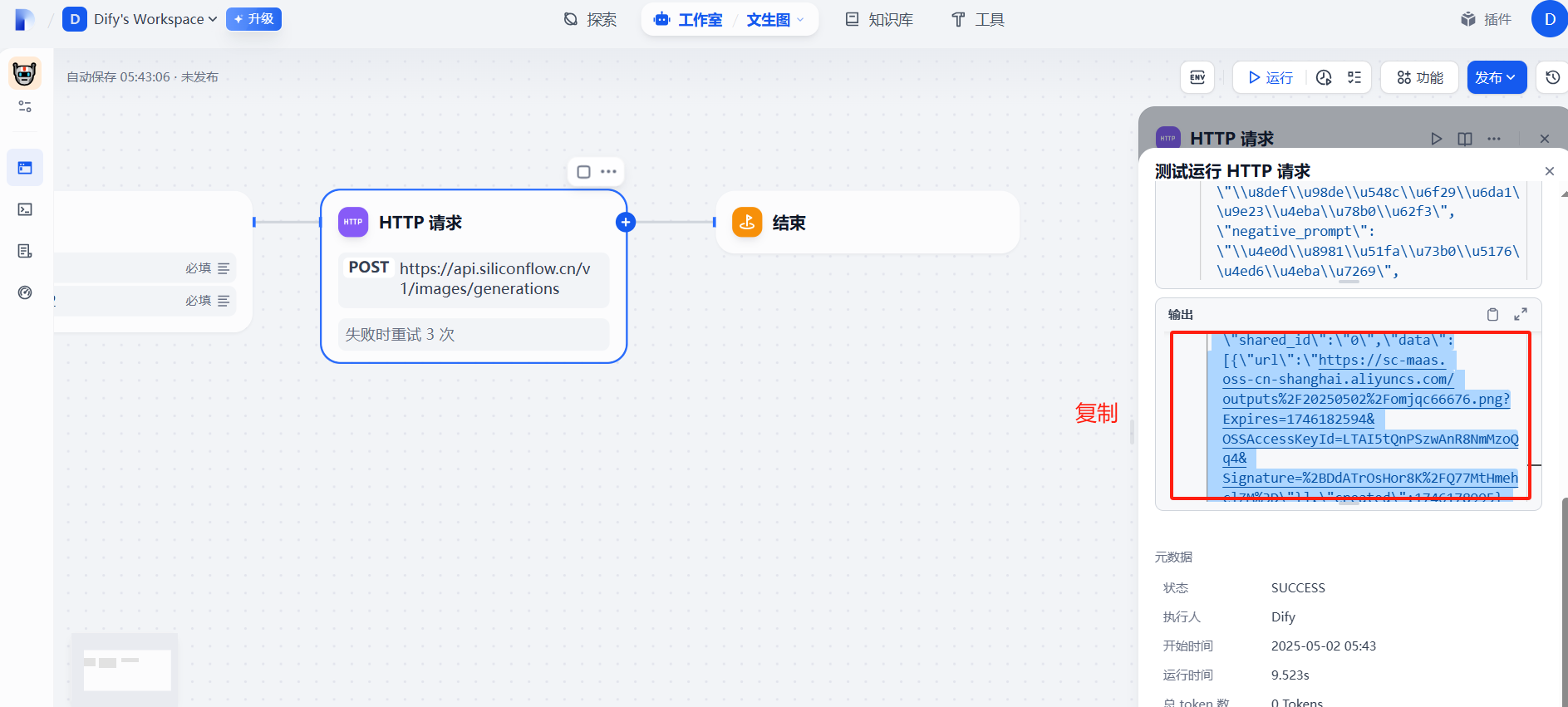
?
 ?
?
?查看圖片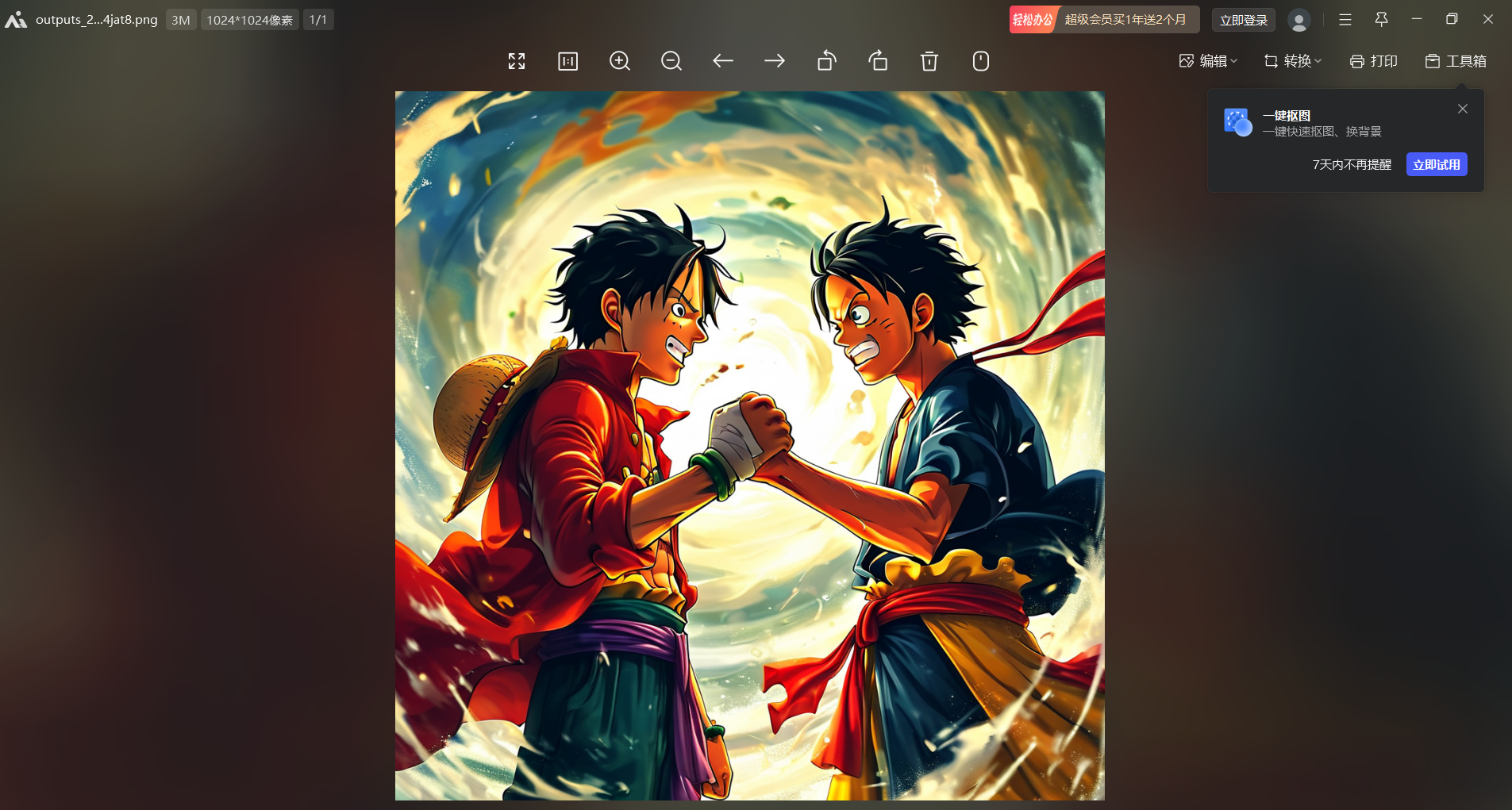
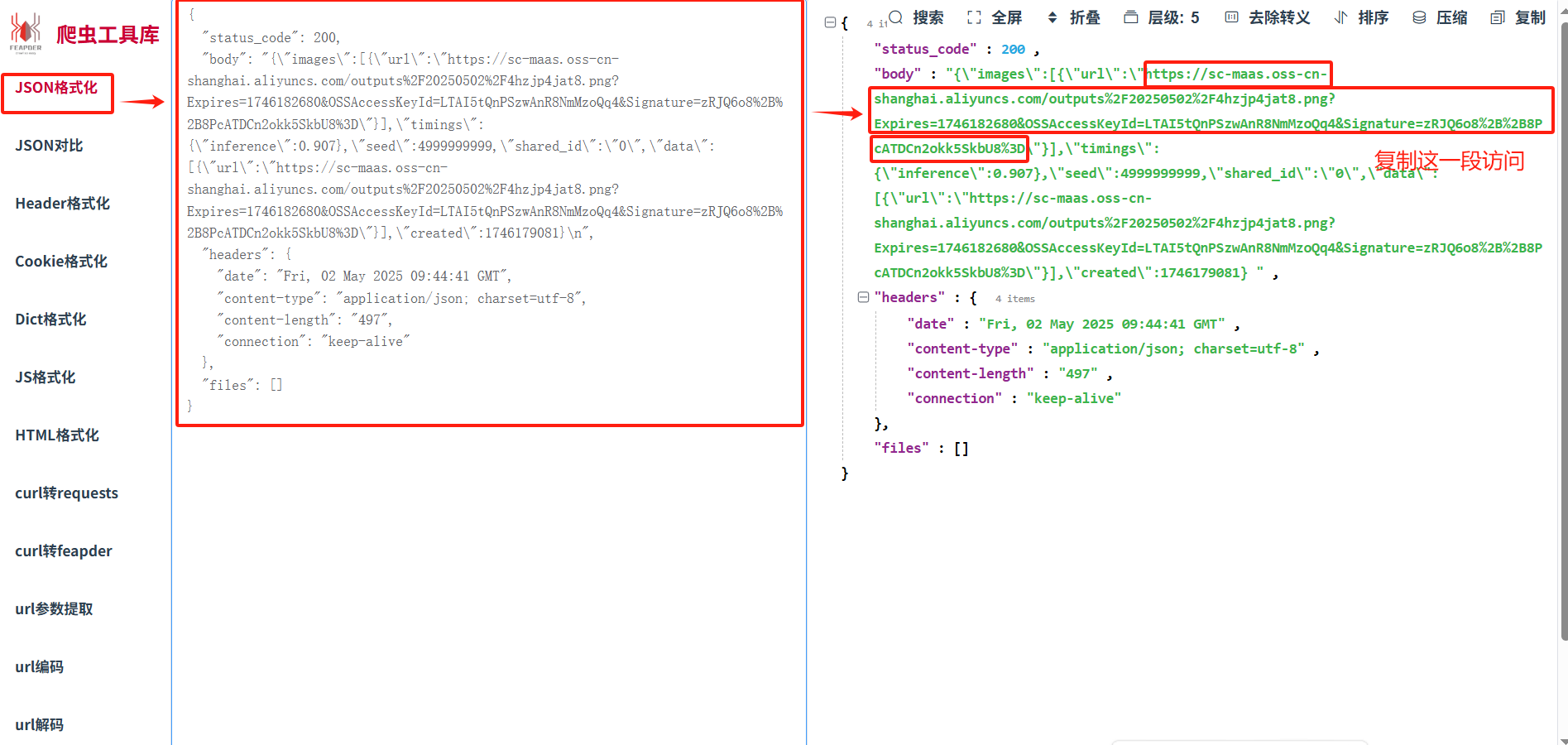
通過上面的步驟可以發現,要提取圖片信息時,會摻雜很多其他數據,下面我們將對json數據去進行精化。?
六、提取json中url數據
HTTP請求提取的參數
{
? ? "status_code": 200,
? ? "body": "{\"images\":[{\"url\":\"https://sc-maas.oss-cn-shanghai.aliyuncs.com/outputs%2F20250502%2F4hzjp4jat8.png?Expires=1746182680&OSSAccessKeyId=LTAI5tQnPSzwAnR8NmMzoQq4&Signature=zRJQ6o8%2B%2B8PcATDCn2okk5SkbU8%3D\"}],\"timings\":{\"inference\":0.907},\"seed\":4999999999,\"shared_id\":\"0\",\"data\":[{\"url\":\"https://sc-maas.oss-cn-shanghai.aliyuncs.com/outputs%2F20250502%2F4hzjp4jat8.png?Expires=1746182680&OSSAccessKeyId=LTAI5tQnPSzwAnR8NmMzoQq4&Signature=zRJQ6o8%2B%2B8PcATDCn2okk5SkbU8%3D\"}],\"created\":1746179081}\n",
? ? "headers": {
? ? ? ? "date": "Fri, 02 May 2025 09:44:41 GMT",
? ? ? ? "content-type": "application/json; charset=utf-8",
? ? ? ? "content-length": "497",
? ? ? ? "connection": "keep-alive"
? ? },
? ? "files": []
}
(1)添加參數提取器?
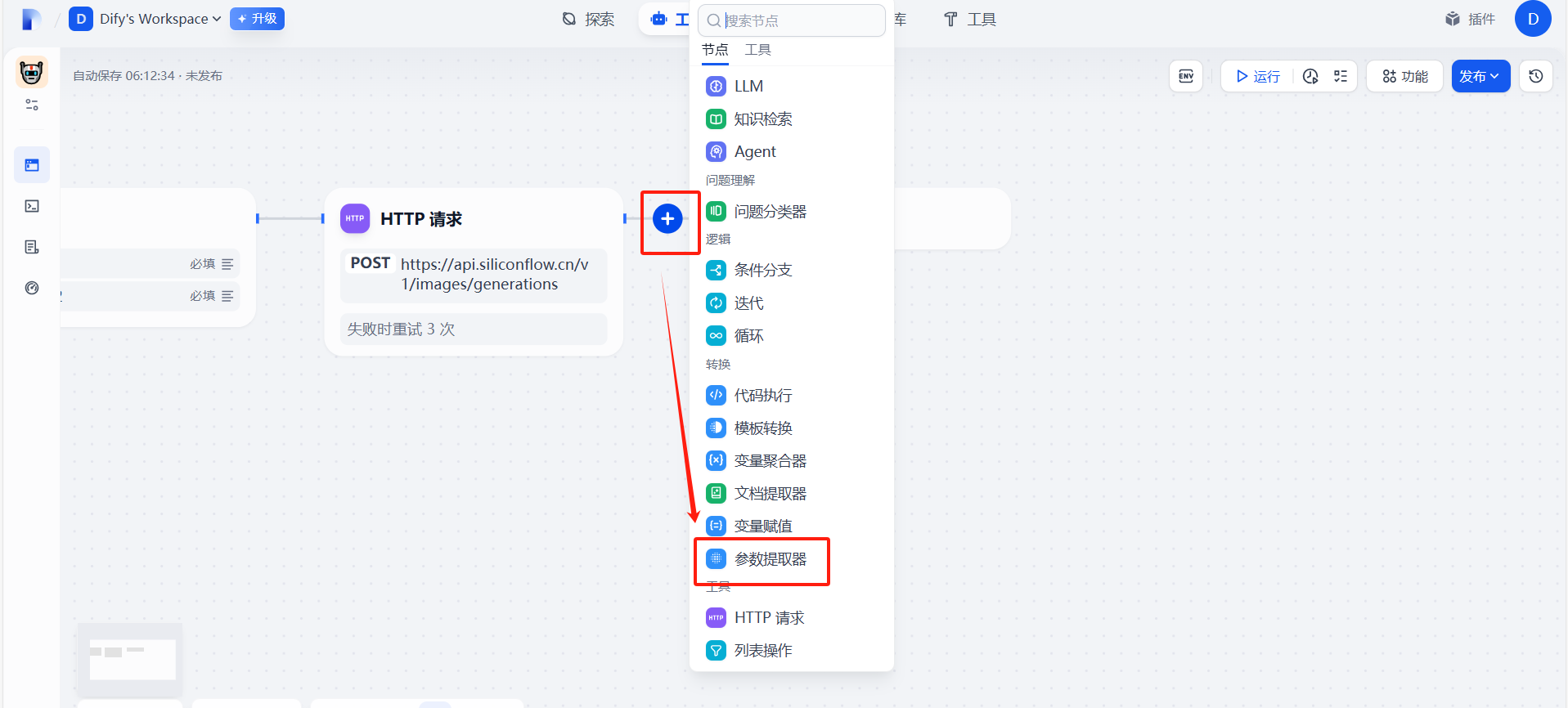
?(2)配置信息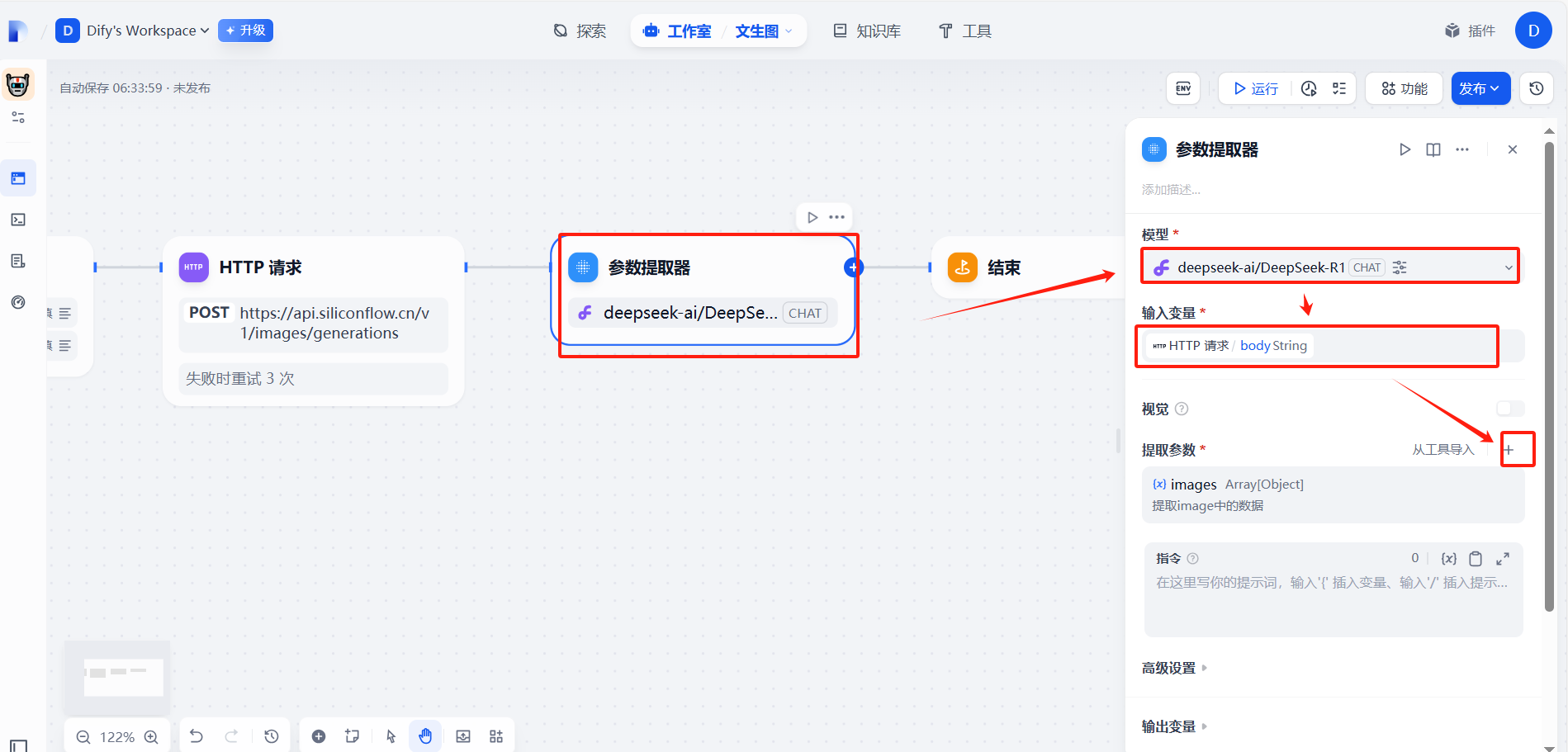
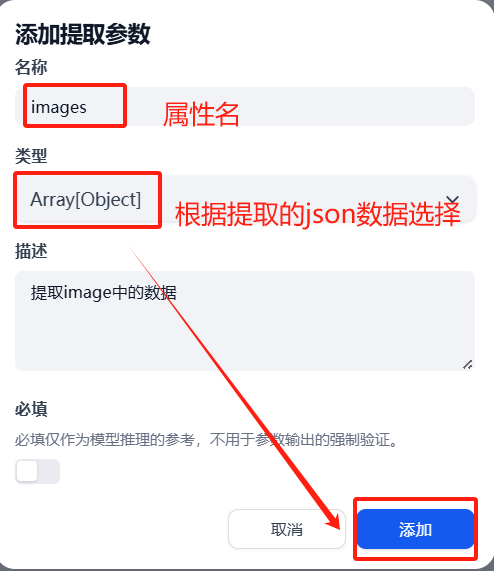
?
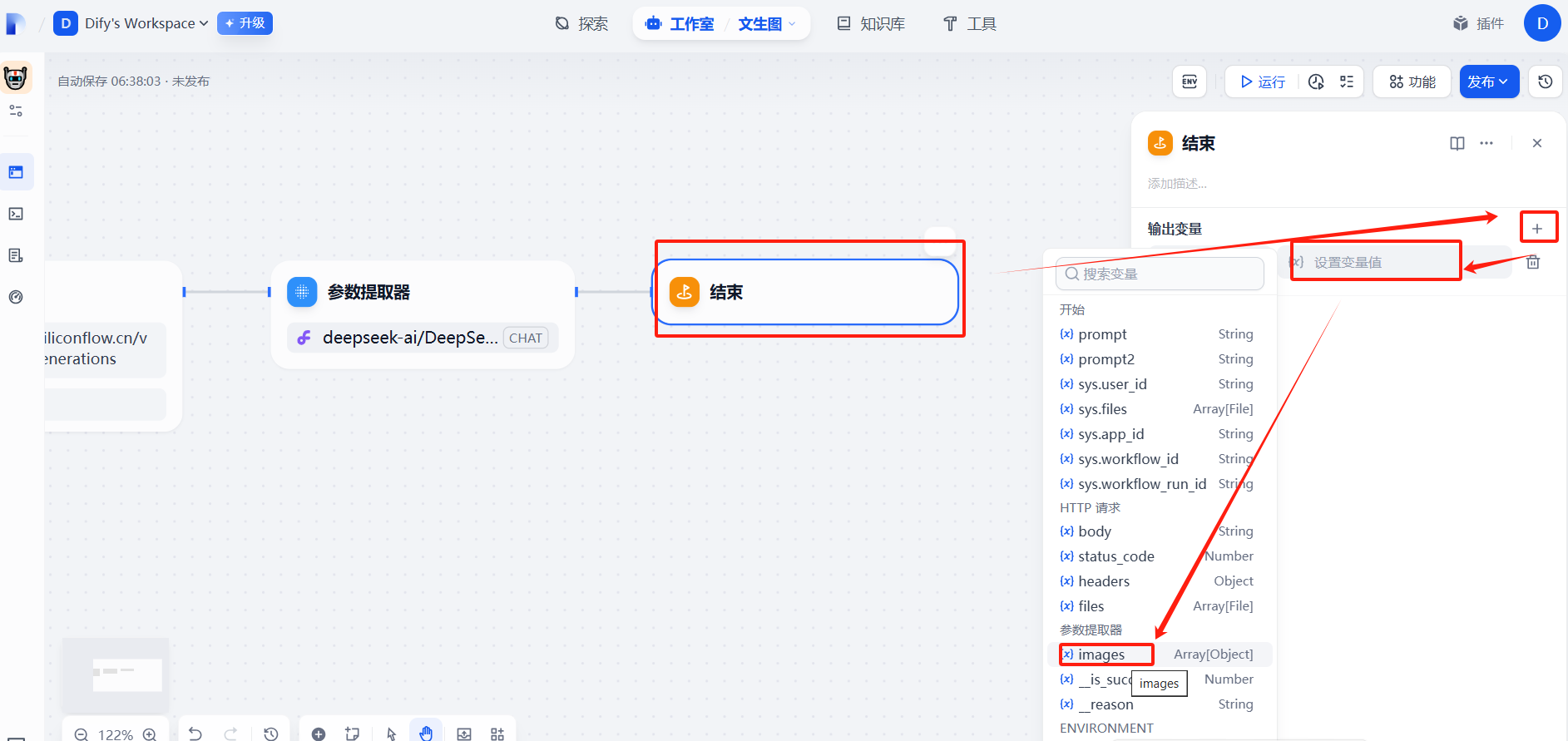
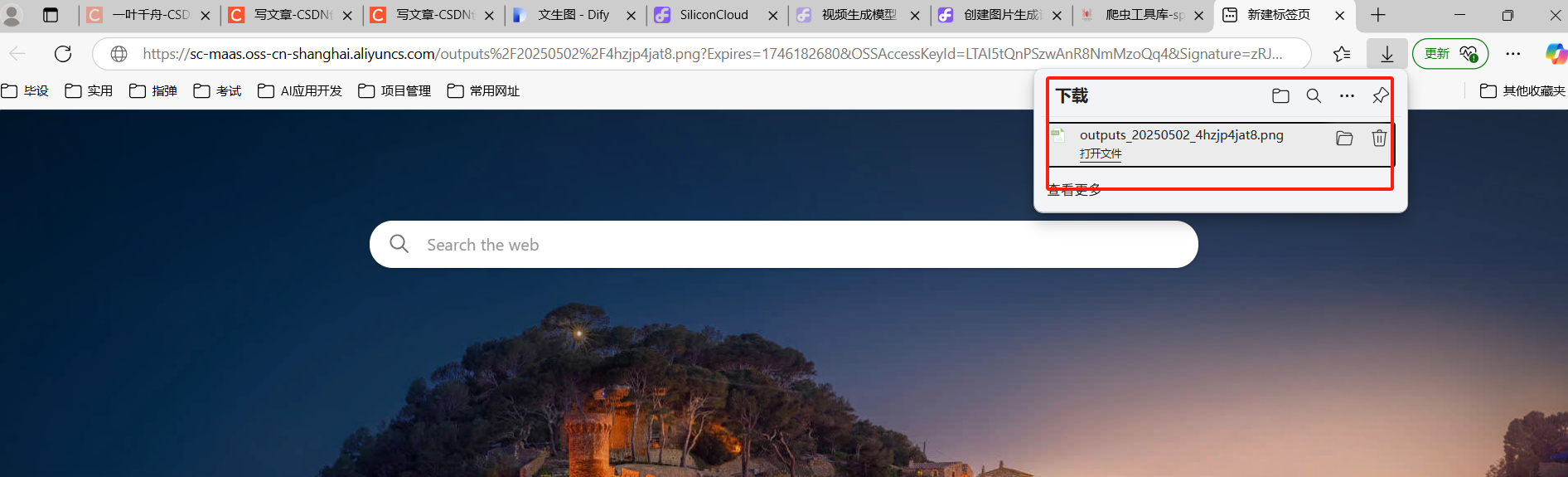
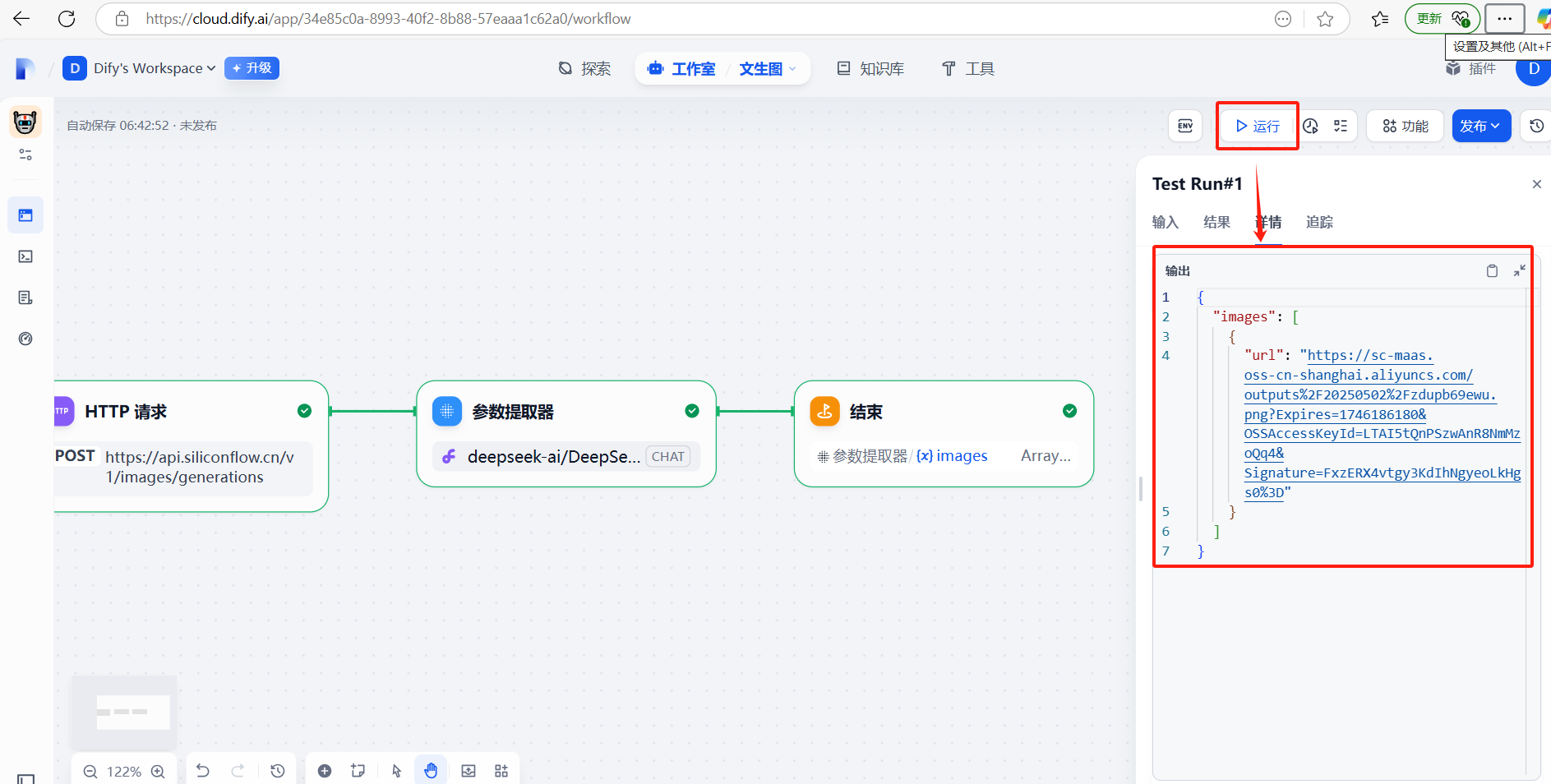
?(3)運行測試
復制url中的地址信息,訪問即可
?
通過上面步驟,json數據已經進一步簡化,但我們最終要的是只輸出圖片地址,接下來將通過代碼對json數據做進一步處理。?
(4)添加代碼執行
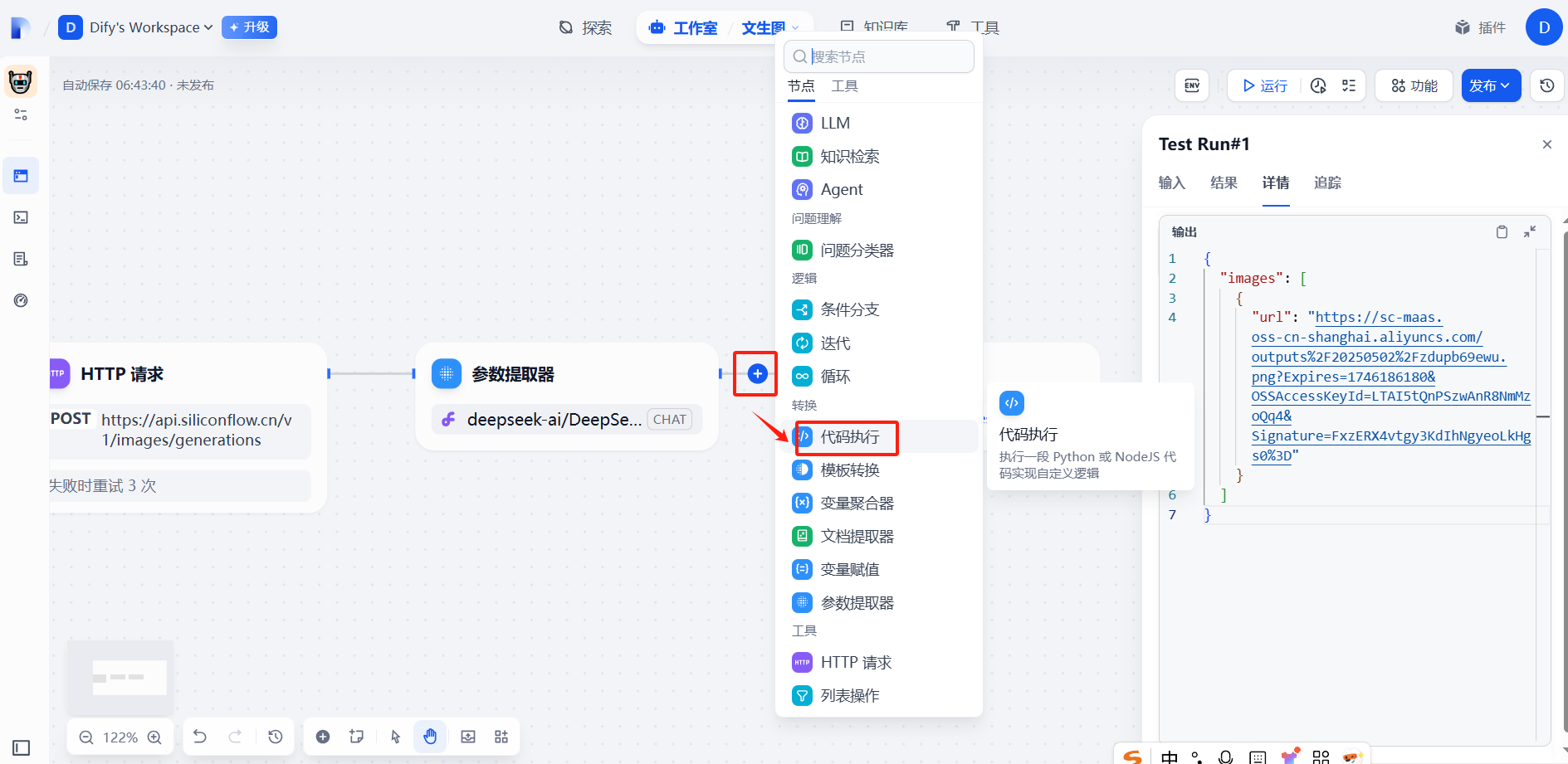 ?
?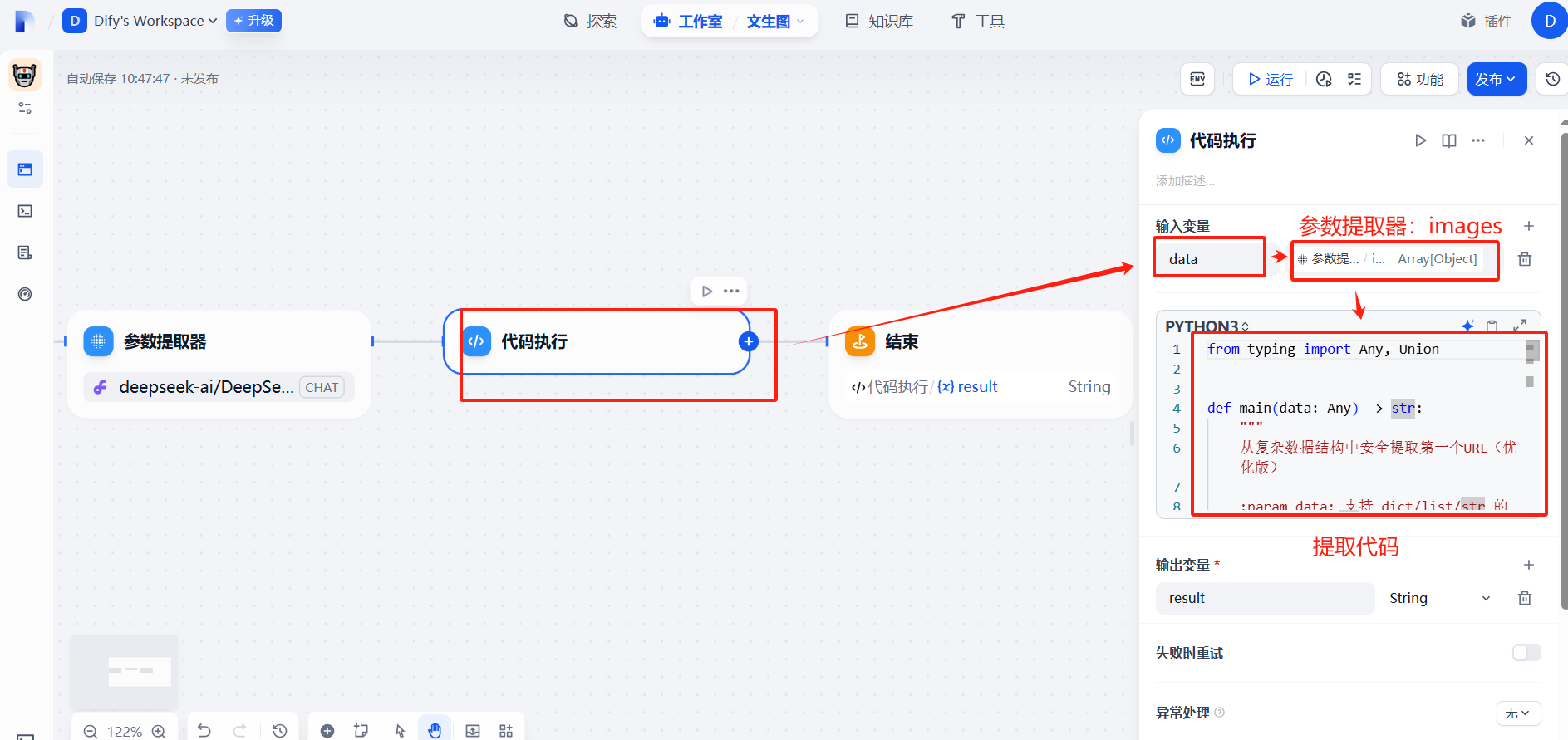
url提取代碼
from typing import Any, Uniondef main(data: Any) -> str:"""從復雜數據結構中安全提取第一個URL(優化版):param data: 支持 dict/list/str 的任意嵌套數據結構:return: 總是返回字符串類型,找不到時返回空字符串"""def extract_url(value: Union[dict, list, str]) -> str:""" 遞歸提取的核心邏輯 """if isinstance(value, str):return value if value.startswith(('http://', 'https://', 'data:image')) else ''if isinstance(value, dict):# 優先檢查單數形式字段for field in ['url', 'image', 'link', 'src']:if field in value:found = extract_url(value[field])if found: return found# 檢查復數形式字段for list_field in ['urls', 'images', 'links', 'sources']:if isinstance(value.get(list_field), list):found = extract_url(value[list_field])if found: return found# 深度搜索字典值for v in value.values():found = extract_url(v)if found: return foundif isinstance(value, list):for item in value:found = extract_url(item)if found: return foundreturn ''return {"result":extract_url(data)}?(5)輸出參數
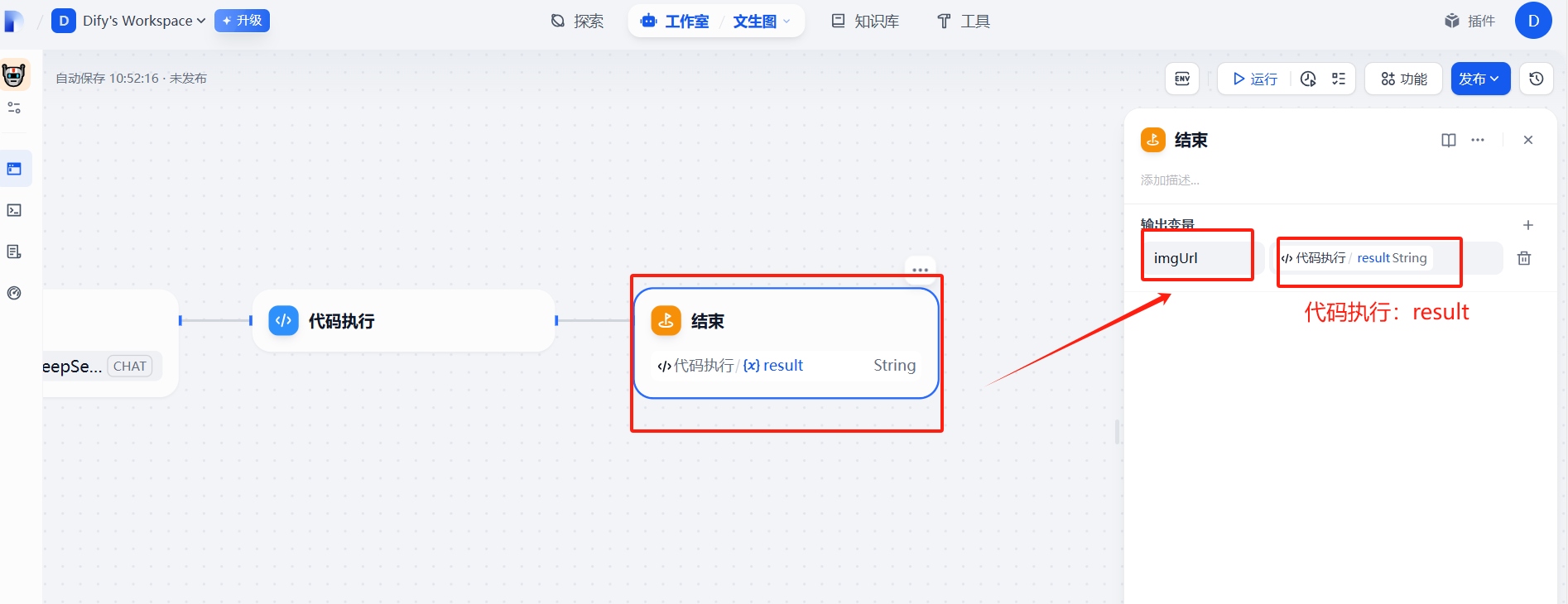
(6)運行
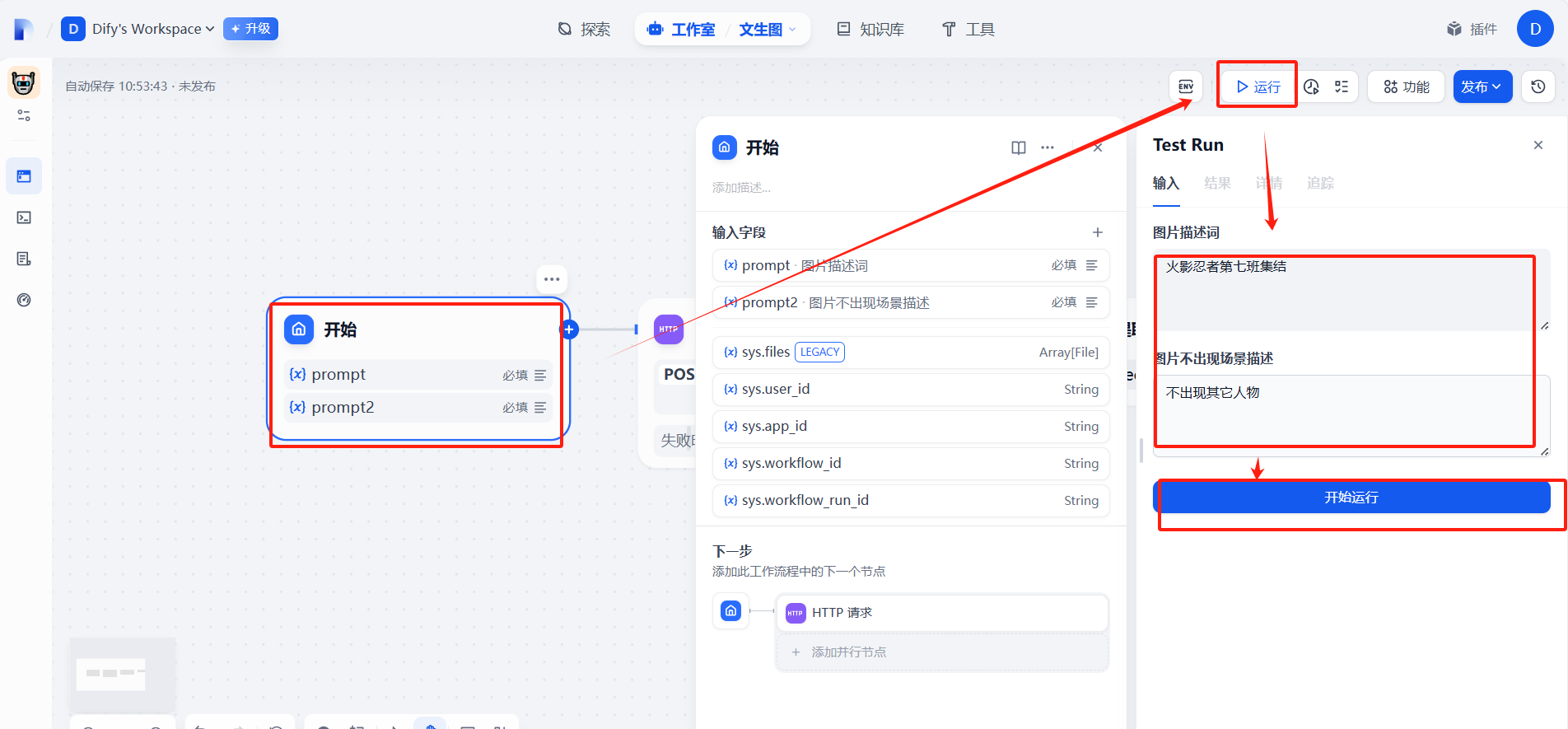
?
?
?七、發布為工具
通過發布為工具后,如果我們在后續需要做更完善的文生圖的項目時,可以直接導入調用該工具,節省開發步驟。
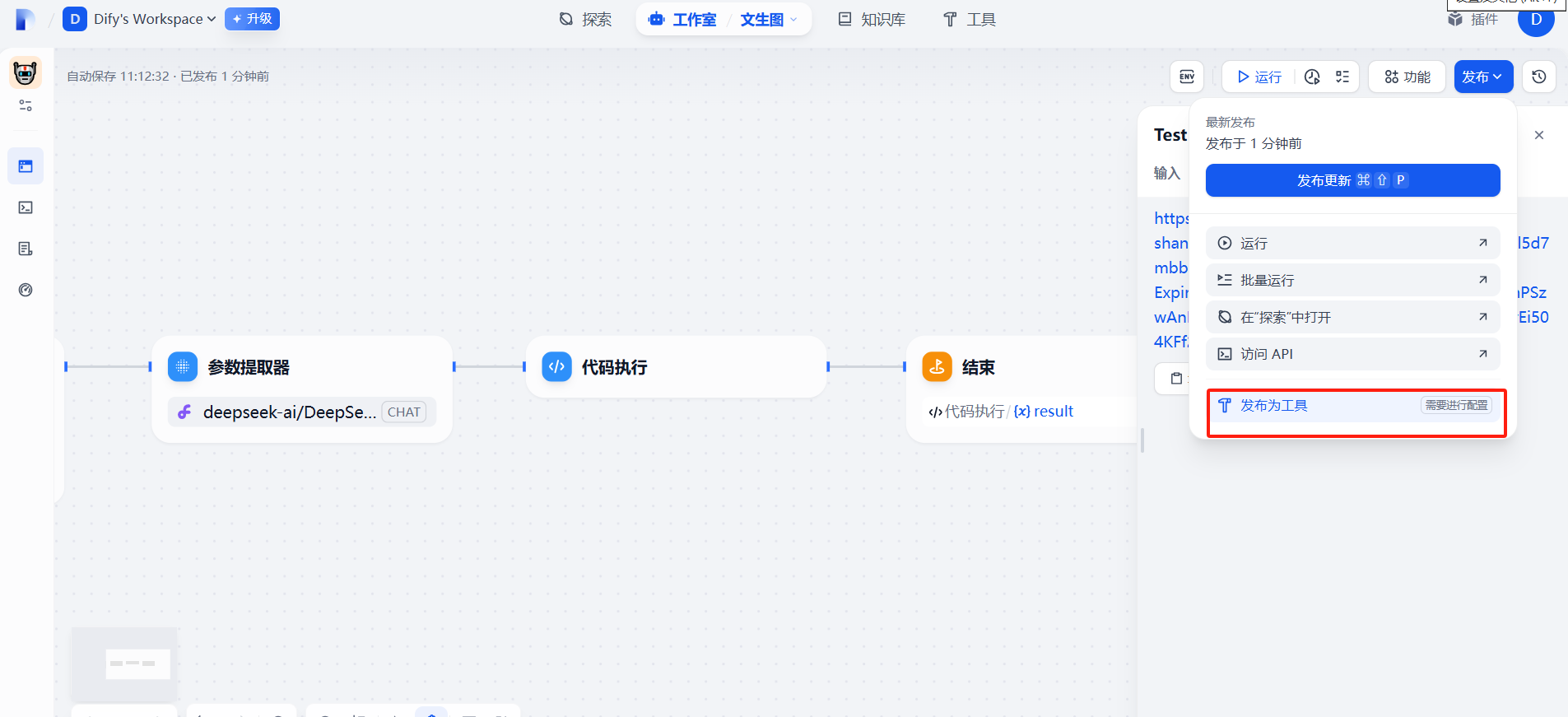



)

)





RestAPI 毛子(Http resilience/Refit/游標分頁/異步大文件上傳))


)



)

