文章目錄
- Update
- Delete
- 插入查詢結果(select + insert)
- 聚合函數
- 分組聚合統計

Update
1. 語法:
set后面加列屬性或者表達式
UPDATE table_name SET column = expr [, column = expr …][WHERE …] [ORDER BY …] [LIMIT …]
- 案例
- 將孫悟空同學的數學成績變更為 80 分
update exam_result set math=80 where name = '孫悟空';
- 將曹孟德同學的數學成績變更為 60 分,語文成績變更為 70 分
update exam_result set math=60,chinese=70 where name='曹孟德';
- 將總成績倒數前三的 3 位同學的數學成績加上 30 分
// 先查詢總分最后三名同學的總分
select name,math+english+chinese as total from exam_result order by total asc limit 3;
// 讓后三名同學的數學加上30分
// 先執行order by 再執行update 最后執行limit
update exam_result set math = math + 30 order by math+english+chinese asc limit 3;
// 再查詢最后三名同學的總分
select name,math+english+chinese as total from exam_result order by total asc limit 3;
可能倒數3名同學會發生變化
- 如果update沒有設置條件會進行全列的更改,沒有where子句則更新全表,更新全表的語句慎用
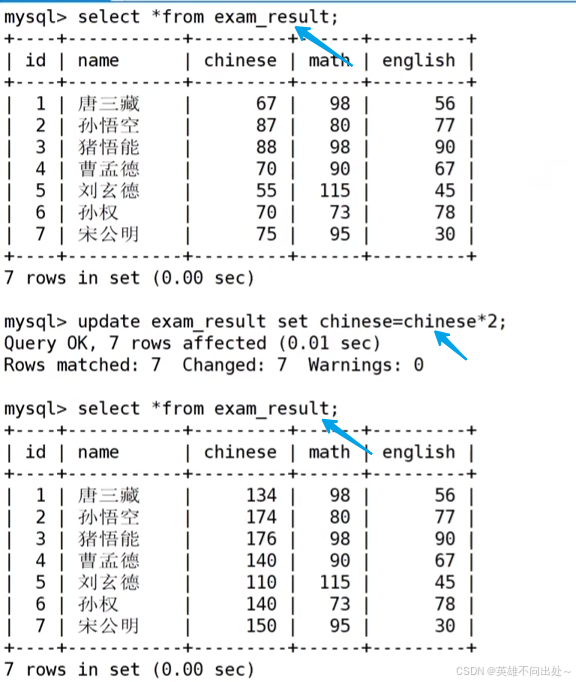
將所有同學的語文成績更新為原來的 2 倍
update exam_result set chinese = chinese*2;
Delete
- 語法:
DELETE FROM table_name [WHERE …] [ORDER BY …] [LIMIT …]
- 案例
- 刪除孫悟空同學的考試成績
delete from exam_result where name='孫悟空';
// 刪除全表的數據
delete from exam_result;
- 刪除倒數第一的人的成績
delete from exam_result order by math+english+chinese asc limit 1;
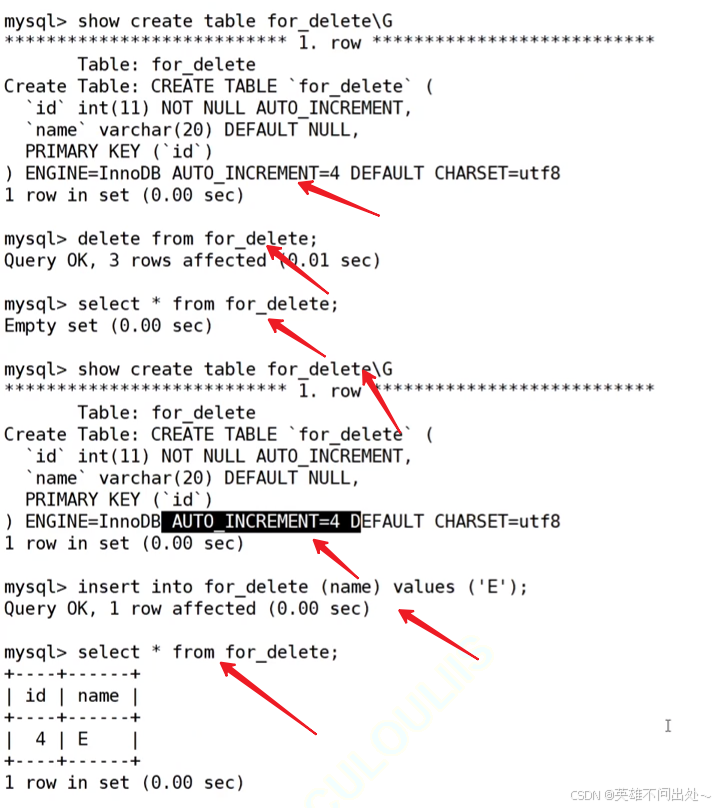
- 清空表的數據
這種做法是不會讓auto_increment的值置0的或者置空的
delete from 表名
4. 截斷表
語法:
TRUNCATE [TABLE] table_name
truncate table 表名
- 會重置 AUTO_INCREMENT 項,刪除表之后會重置auto_increment項,把它的值變為1
- truncate不會做更新日志的操作,delete from會做更新日志的操作
- 實際上 MySQL 不對數據操作,所以比 DELETE 更快,但是TRUNCATE在刪除數據的時候,并不經過真正的事
物,所以無法回滾 - 只能對整表操作,不能像 DELETE 一樣針對部分數據操作
- 三種日志:
<> bin log: 歷史上操作過的sql語句優化之后保留下來——方便主從同步、備份、恢復
<> redo log:確保宕機、斷電的時候數據不丟失(因為數據可能在內存中存著)——保證崩潰安全
<> undo log:做事務回滾、事務的隔離性

插入查詢結果(select + insert)
1. 語法
INSERT INTO table_name [(column [, column …])] SELECT …
- 案例
刪除表中的的重復記錄,重復的數據只能有一份
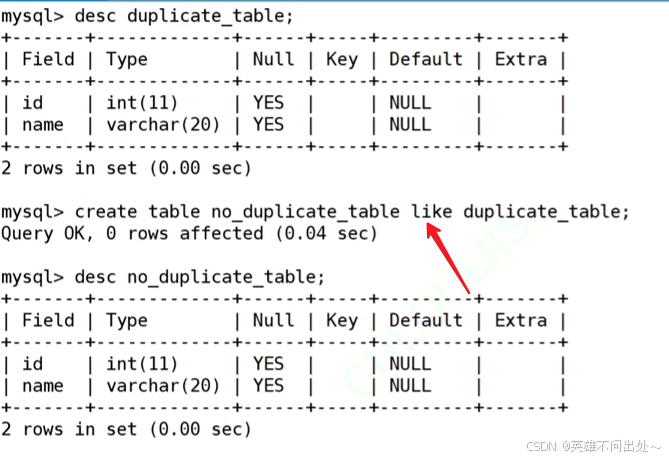
// 創建空表
create table no_duplicate_table like duplicate_table;
// 將去重之后的表插入到新表中
select distinct * from duplicate_table;
insert into no_duplicate_table select distinct * from duplicate_table;
// 查看no_duplicate_table得到去重之后的數據
select * from no_duplicate_table;
// 通過重命名表,實現原子的的去重操作
// 將原表重命名備份一下,然后把新表的名字改為原表的名字
rename table duplicate_table to old_duplicate_table;
rename table no_duplicate_table to duplicate_table;
// 查看最終的結果
select * from duplicate_table;
2. 只是打印去重,并沒有修改原表中的數據

3. create table no_duplicate_table like duplicate_table;創建像duplicate_table一樣的表結構
4. 為什么最后是通過rename的方式進行的?
單純就是想等一切都就緒了,然后統一放入、更新、生效等。因為我們的move操作和重命名操作實際上就是在文件系統里就是改這個文件所在的目錄里面文件名和inode的映射關系,他相較于冗長地向表中插入和冗長的上傳行為比起來非常輕。很有可能我這個目錄有很多文件包括正在操作的這個文件正在被外部的網站或者各種語言正在訪問,所以我們不能著急動這個表而是應該先把這個表先傳到臨時目錄然后再統一move過去,這是一種比較推薦的做法
聚合函數
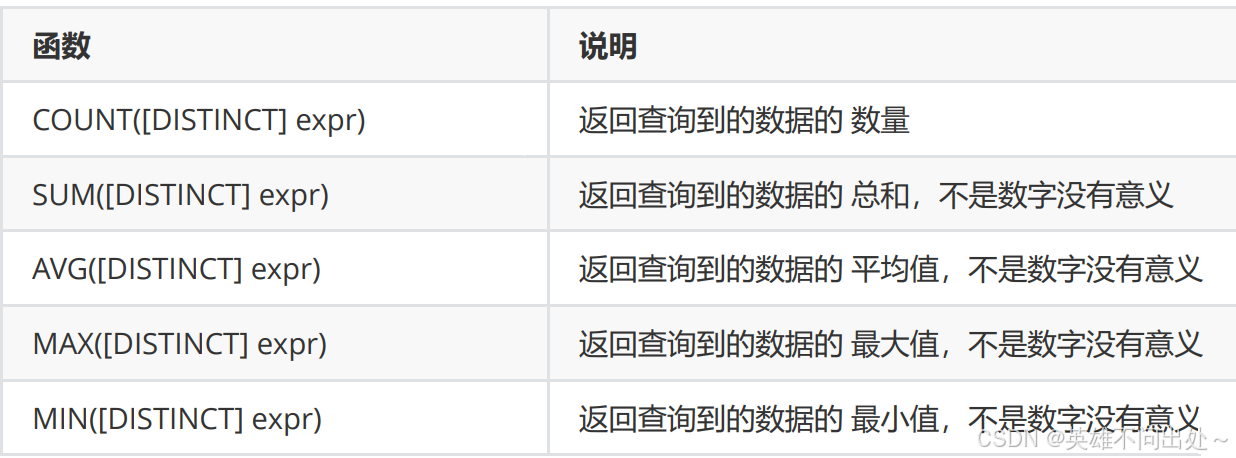
- 案例
統計班級共有多少同學
1. 用*做統計
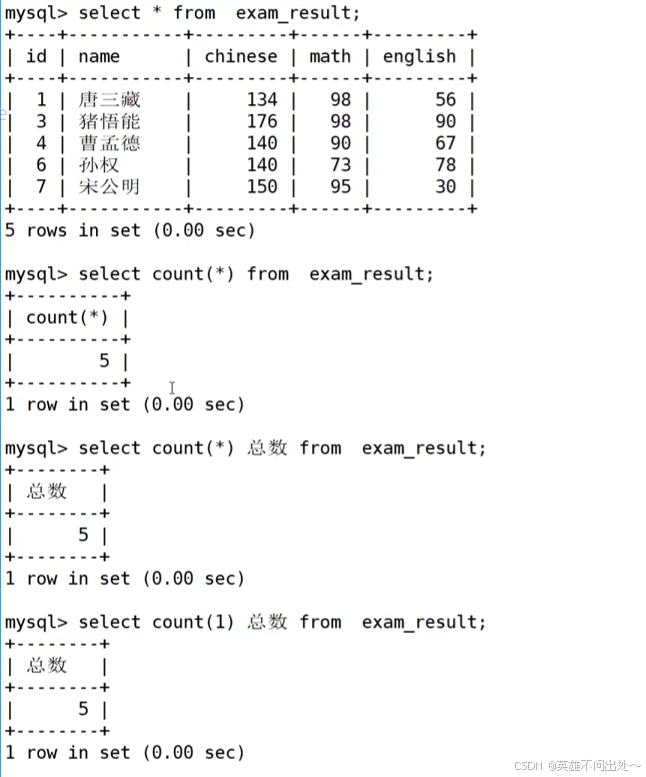
2. 統計數學成績有多少個
select count(math) as res from exam_result;
3. 聚合函數會先算出后面表達式的結果,得到一個數字
統計去重后的數學成績
select count(distinct math) from exam_result;
4. 統計我們班數學的總分和平均成績,英語的平均成績
select sum(math) from exam_result
select sum(math)/count( * ) from exam_result
select sum(english)/count( * ) from exam_result
5. 統計數學成績的平均分
select avg(math) from exam_result
6. 統計英語成績的最高分
select max(english) from exam_result
7.返回 > 70 分以上的數學最低分
select min(math) from exam_result where math > 70;
總結:
1.只屬于某一個人的信息是無法聚合的,比如名字和平均分在一起聚合就不行
分組聚合統計
- 分組的目的是為了進行分組之后進行每組的聚合統計
- 把數據拿出來(用select拿)再進行分組
- 語法:select column1, column2, … from table group by column;
- 指定列名,實際分組,使用該列的不同行數據進行分組的

- 案例
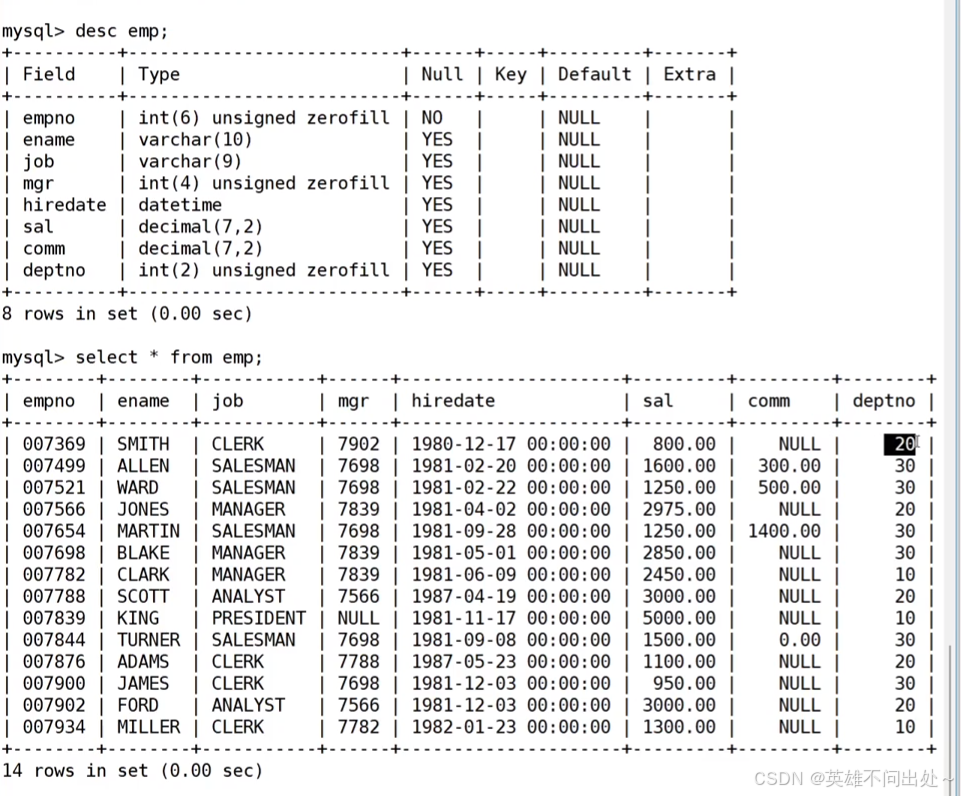
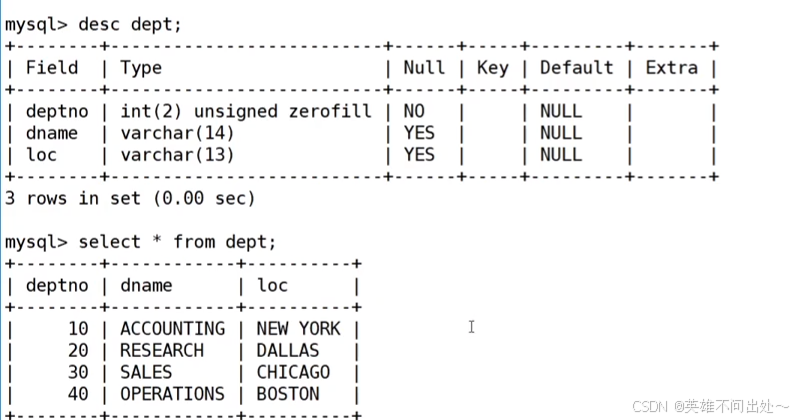
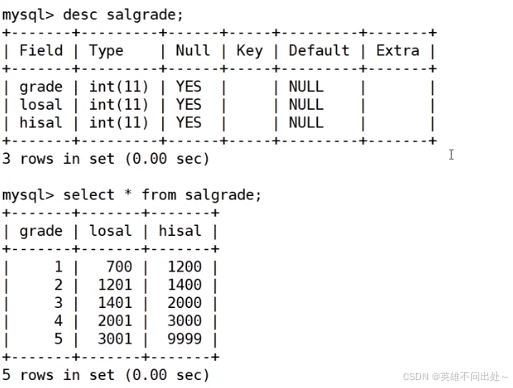
準備工作,創建一個雇員信息表(來自oracle 9i的經典測試表)
1、EMP員工表
2、DEPT部門表
3、SALGRADE工資等級表
// 準備工作
//利用source將該備份文件恢復到數據庫中
source /home/r/scott_data.sql;
use scott;
show tables;

emp
 dept
dept
salgrade
1. 分組進行統計每個組的最高工資和平均工資
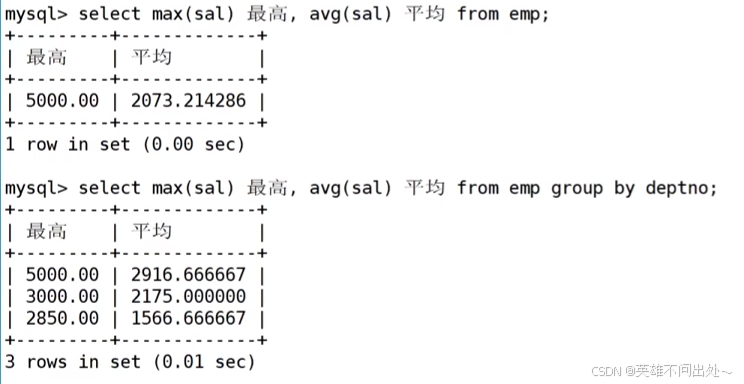

- 顯示每個部門的每種崗位的平均工資和最低工資

3. 跟在select 后面的必須是分組的列屬性或者是聚合函數,因為這些屬性有相同的,而下圖中名字是每個人都不同的屬性,無法分組

- 顯示平均工資低于2000的部門和它的平均工資
先統計每個部門的平均工資,結果先聚合出來
select deptno,avg(sal) as 平均工資 from emp group by deptno;
再判斷平均工資低于2000的部門再對聚合的結果進行判斷
select deptno,avg(sal) as 平均工資 from emp group bydeptno having 平均工資<2000
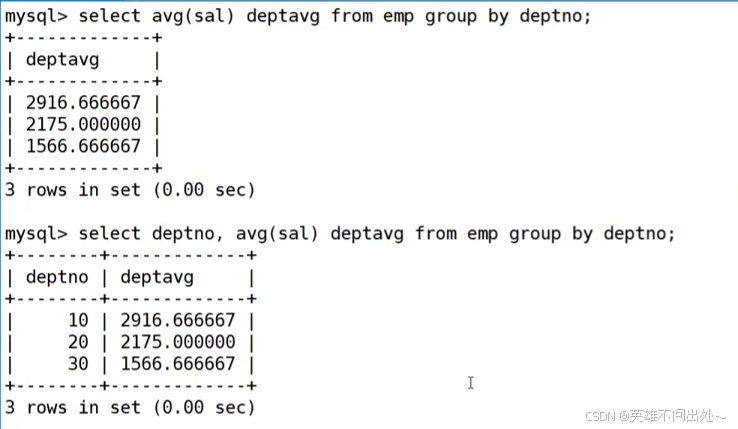

5. having是對聚合后的統計數據進行條件篩選

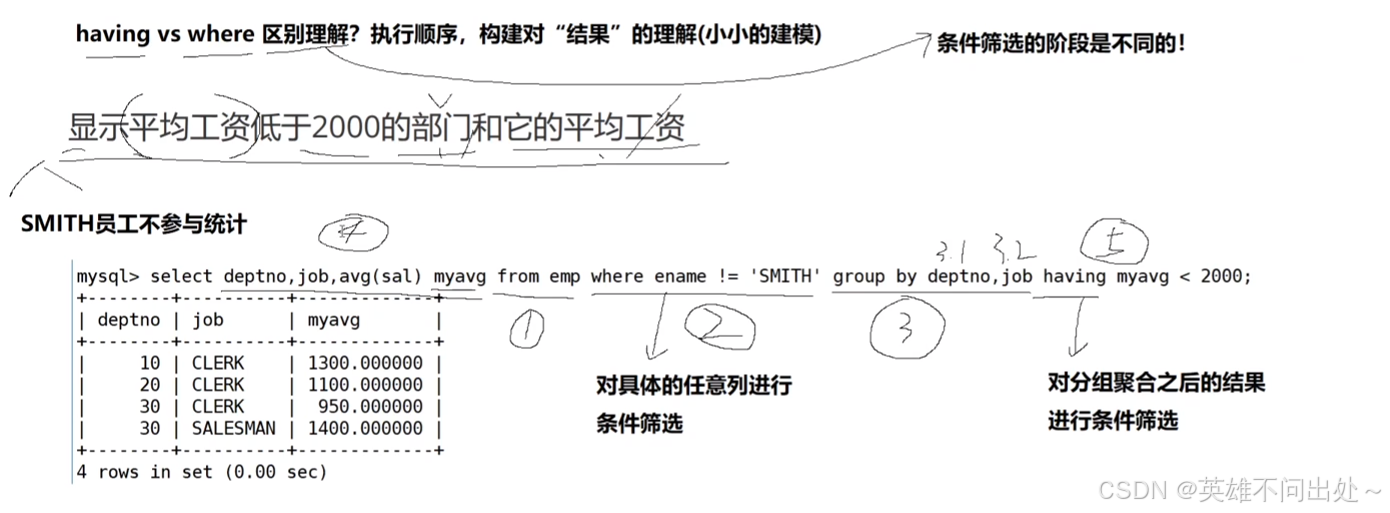
6. having 和 where 的區別
1,2,3,4,5表示順序
MySQL中在邏輯上一切皆表



)





RestAPI 毛子(Http resilience/Refit/游標分頁/異步大文件上傳))


)



)




