寫在前面
隨著Transformer架構的大語言模型(LLM)不斷發展,其參數規模也在迅速增加。無論是進行模型推理還是微調訓練,GPU顯存消耗都是開發和應用LLM時的重要考量。本文將詳細探討大模型運行(推理)與微調時的顯存計算方式。
隨著Transformer架構的大語言模型(LLM)不斷發展,模型參數規模急劇膨脹,顯存消耗成為推理和微調過程中的核心瓶頸。本文系統梳理了大模型在推理與微調階段的顯存計算方法,詳細分析了模型參數、優化器狀態、中間激活值、批處理大小等因素對顯存需求的影響。通過具體案例(如1.5B、7B模型)量化分析顯存占用,并總結了常用的顯存優化策略,包括混合精度訓練、梯度檢查點、模型并行、量化剪枝等。此外,還特別介紹了LoRA微調技術在降低顯存壓力方面的優勢。通過本文,讀者將能清晰掌握大模型顯存消耗的計算邏輯,從而更科學地進行資源規劃與優化實踐。
、
顯存計算的重要性
GPU顯存限制直接決定了你能運行的模型規模、批處理大小(batch size)和序列長度(sequence length)。因此,掌握顯存的計算方法對于優化和合理使用GPU資源尤為重要。
全量微調
我們在微調的過程中,顯存主要分布狀況梯度計算:
● 反向傳播需要存儲梯度,相比推理階段顯存占用會大幅增加。
● 優化器狀態:例如 Adam 之類的優化器會存儲額外的參數狀態(如一階、二階動量),通常會使顯存占用增加 2-3 倍。
● 計算圖:PyTorch 計算圖在反向傳播時需要保留中間激活值,會比前向推理額外消耗顯存。
● Batch Size:數據集的 batch size 會影響顯存消耗,較大的 batch 會顯著增加顯存占用。
● 混合精度訓練(FP16 vs FP32):如果是 FP32 訓練,會比 FP16 訓練占用更大顯存。
● 梯度累積:如果使用梯度累積(gradient accumulation),每一步的顯存占用會相對降低,但不會減少總需求。

模型占用
首先根據模型參數大小計算出模型的大小:
比如7B模型:
● 如果是FP32則:7B4 = 28GB
● 如果是FP16則:7B2 = 14GB
優化器占用
Adam 優化器一般會占用 2~3倍參數大小的顯存:
● FP32 大約 28GB*3,大概是 56GB~84GB
● FP16 大約 28GB ~ 42GB
如果是 SGD 之類的優化器,占用會小很多(1 倍參數量)。
中間激活值
這個很難精確計算,但一般會比參數量多 1.5~3 倍。
例如,7B 模型 FP16 訓練時,激活值大概 21GB - 42GB。
批處理
每個 batch 會加載部分數據到顯存,每個 token 可能會占用 2-4B(FP16 vs FP32)。
如果 batch_size=8,每個序列 2048 個 token,假設 FP16,則是 8 * 2048 * 2B = 32MB
但是 Transformer 計算中間層需要額外的顯存,可能會放大到 3~4 倍,則 96MB~128MB
計算實例1.5B
模型本身
假設是一個未量化的 1.5B 模型,假設是 FP16(每個參數2B):
1.5B * 2B = 3GB,模型本身大約是3GB。
優化器
用 AdamW 的話,存儲:
● 權重參數(1x)
● 一階動量(1x)
● 二階動量(1x)
合計 3 倍參數量,AdamW 需要 9GB。
提取存儲
梯度和模型參數大小相同,FP16的話:1.5B * 2B = 3GB
激活中間值
Transformer 涉及到多個層的值,通常是模型參數的 1.5~3倍
3GB * 2 = 6GB
梯度存儲
gradient_accumulation_steps,梯度積累的話,我設置8,需要消耗 3GB * 8 = 24GB
總占用
總共顯存占用:54GB,PyTorch、CUDA等緩存還需要10%~20%,最終大約在 55GB ~ 65GB。
計算實例7B
模型本身
7B參數 FP16 訓練(每個參數2B)
7B * 2 = 14GB
優化器
● 權重參數(1x)
● 一階動量(1x)
● 二階動量(1x)
合計是3倍的參數量:14GB * 3 = 42GB
梯度占用
7B * 2 = 14GB
激活值
Transformer 涉及到多個層,激活值通常是模型參數的 1.5 ~ 3 倍
假設是2倍的話,14GB * 2 = 28GB
梯度累積
gradient_accumulation_steps 假設是8,則需要存儲8個梯度,14*8 = 112 GB
額外占用
PyTorch、CUDA等可能增加 10% ~ 20% 的顯存
總計占用
大概在 220GB ~ 230GB 之間,峰值可能更高(240GB 以內)。
優化顯存使用的策略
為降低顯存占用,常用以下策略:
- 使用混合精度訓練(如FP16)Mixed Precision:通過使用FP16或BF16等低精度數據類型,顯著減少模型參數和梯度存儲的顯存需求,同時提高訓練速度。
- 梯度檢查點(Gradient Checkpointing)以減少激活占用:梯度檢查點技術通過重新計算部分前向傳播結果,顯著減少訓練過程中需要存儲的激活內存,從而降低整體顯存消耗。
- 模型并行、流水線并行、張量并行:通過將模型的不同部分分配到多個GPU設備上,分擔單個GPU的顯存壓力。
- 量化和剪枝模型:通過減少參數精度或去除冗余參數,減少模型參數總量,有效降低模型的顯存需求和計算成本。
- 流水線并行(Pipeline Parallelism):模型各層或子模塊在不同GPU上流水線執行,有效提高顯存和計算資源的利用率。
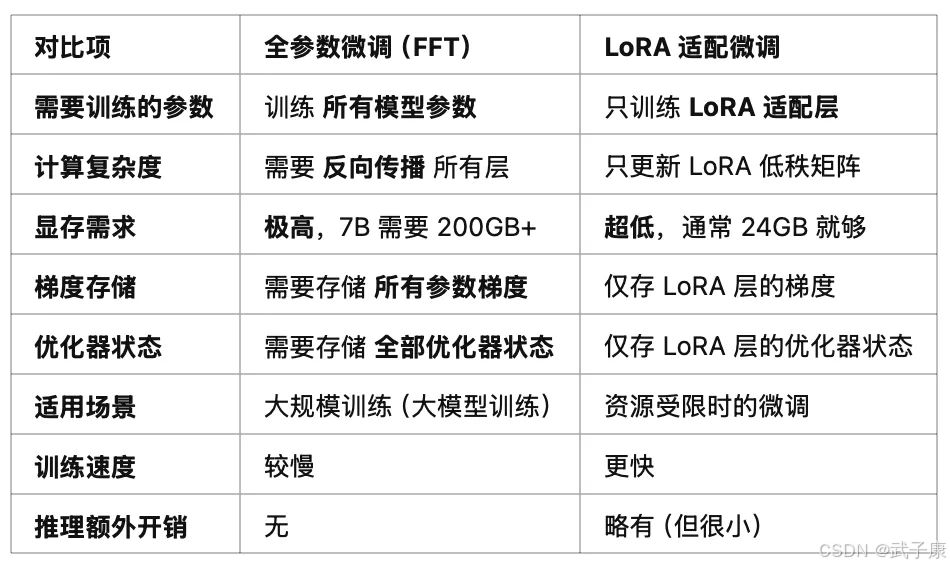
LoRA微調
LoRA 極大減少顯存需求,適合在消費級 GPU(如 24GB 4090)上微調大模型,而全參數微調需要多個高端 GPU(如 4×A100 80GB)。
參數計算
LoRA 只修改部分的 Transformer 層(通常是 Wq 和 Wv),所以顯存占比會比較低。
每層參數量通常縮小到 0.1% ~ 1%,設 rank = 16,則大概是 70M ~ 700M 參數,使用 FP16 存儲的話,大約140MB ~ 1.4GB 的顯存。

推理要求
● FP32(單精度浮點數):4字節(32位)
● FP16(半精度浮點數):2字節(16位)
● BF16(bfloat16):2字節(16位)
● INT8(8-bit整數):1字節(8位)
● INT4(4-bit整數):0.5字節(4位)
假設是 7B模型,7B * 0.5 / 10的9次 = 3.5GB
緩存、PyTorch、CUDA等緩存大約需要 1~2GB
顯存大約6GB左右
假設是 14B模型,14B * 0.5 / 10的9次 = 7GB
緩存、PyTorch、CUDA等緩存大約需要 1~2GB
顯存大約10GB左右
假設是32B模型,32B * 0.5 / 10的9次 = 16GB
緩存、PyTorch、CUDA等緩存大約需要 1~2GB
顯存大約18GB左右
假設是70B模型,70B * 0.5 / 10的9次 = 35GB
緩存、PyTorch、CUDA等緩存大約需要 1~2GB (雙卡可能要 2~4GB)
每張卡大約 35 GB / 2 + 2 = 20GB
暫時小節
正確評估顯存需求對合理分配計算資源和優化模型運行性能至關重要。理解以上顯存計算的基本公式,有助于高效地利用現有硬件資源,推動大模型的應用和開發。
希望本文能幫助讀者更深入地理解大模型在運行與微調階段顯存消耗的具體計算方法,進而優化自己的訓練與推理任務。




Ubuntu搭建LNMP(Linux + Nginx + MySQL + PHP)環境)





)

)

:C 語言函數可變參數詳解)
Nova Cell理解)



