1、Nova Cell概述
(官方文檔:Cells (v2) — nova 25.2.2.dev5 documentation)
Nova中的cells功能的目的是允許較大的部署將其多個計算節點分割成多個cell。所有的nova部署都默認是cell部署,即使大多數情況下只有單一cell。這意味著多cell部署與“標準”nova部署不會有根本性的區別。
詳細講解:
1. 什么是 Cells 功能?
Nova 的 cells 功能是為了在大型 OpenStack 部署中提供擴展性和分片支持。隨著云環境中計算節點(虛擬機托管服務器)數量的增加,單個數據庫和單一調度器可能會成為瓶頸。為了應對這種擴展性問題,OpenStack Nova 引入了 cell v2 結構,將多個計算節點分成不同的 cell,以便將資源分布到不同的數據庫和服務中。
Cell 是對計算節點和資源的邏輯劃分,使得在一個 OpenStack 部署中,可以將計算資源分成多個 細分單元,每個單元負責自己的數據庫、計算節點和資源。
這種分片機制的目的是減少數據庫壓力、優化資源調度、提高可擴展性,尤其在大型部署中非常有用。
2. 所有 Nova 部署默認是 Cells 部署
無論你是部署單一 cell 還是多個 cell,所有的 Nova 部署從架構上來說都是 cell 部署。這意味著,即使你只在一個 cell 中運行計算節點,你依然是在使用 cells 功能的。換句話說,單一 cell 只不過是 cell 功能的一種默認實現,并沒有禁用這一功能。
這對于大多數普通用戶來說意味著什么呢?
即便你的部署只有一個 cell(只有一個數據庫和一組計算節點),你依然可以按照 cell v2 架構運行 OpenStack,只是沒有啟用多個 cell 來進行資源分片。
如果未來需要擴展部署,可以更輕松地啟用 多個 cells,而不會大幅度改變現有的架構。
3. 多 cell 部署與標準部署的區別
多 cell 部署:對于大規模的 OpenStack 環境,多個 cell 可以顯著提升管理和調度能力。每個 cell 負責一組計算節點和數據庫,它們通過消息隊列相互協作。
例如,cell1?可以管理一個數據中心的計算節點,cell2?可以管理另一個數據中心的計算節點。每個 cell 都有獨立的數據庫、消息隊列。調度請求會根據資源分布情況和 cell 的狀態來決定在哪個 cell 中運行虛擬機。
標準部署(單 cell 部署):如果只有一個 cell,Nova 將會將所有計算資源集中在一個 cell 中,所有計算節點、數據庫、消息隊列都在同一個單元中。這樣一來,數據庫的訪問和計算節點的調度不會被分片,所有的負載都集中在一個地方。
4. Multi-cell 部署的優勢
擴展性:通過將計算節點分配到多個 cell,每個 cell 可以獨立地進行資源管理、數據庫操作等,減輕單一節點的壓力。這種架構能支持更大規模的 OpenStack 部署。
故障隔離:一個 cell 的故障不會直接影響到其他 cell。這為大規模部署提供了更高的容錯性。
資源管理優化:不同的 cell 可以分別負責不同區域或不同數據中心的計算資源。每個 cell 都有獨立的數據庫,能夠減少單一數據庫的訪問壓力,提高資源調度的效率。
5. 總結
cells 功能 旨在支持大規模的 OpenStack 部署,將計算資源和數據庫進行分片管理。
所有的 Nova 部署 都是 cell 部署,即使默認配置下只有一個 cell,OpenStack 依然會按 cell 的方式處理。
多 cell 部署 適用于需要大規模擴展的環境,而單一 cell 部署更適合較小的環境。
即使未來需要擴展到多個 cell,原本的 單一 cell 部署 也不會對架構造成根本性的影響。
這意味著,即使你目前只運行一個 cell,你也可以在未來輕松地將部署擴展到多個 cell,支持更多的計算節點和更高的可用性。
考慮這樣一個部署,它將包括以下組件:
-
nova-api 服務,提供對用戶的外部 REST API。
-
nova-scheduler 和 placement 服務,負責跟蹤資源并決定實例應部署到哪個計算節點上。
-
一個 “API 數據庫”,主要供 nova-api 和 nova-scheduler(以下稱為 API 級服務)使用,用來跟蹤實例的位置信息,以及用于存儲尚未調度但正在構建的實例的臨時位置。
-
nova-conductor 服務,負責卸載 API 級服務的長時間運行任務,并將計算節點與數據庫訪問隔離開來。
-
nova-compute 服務,管理虛擬化驅動和虛擬化主機。
-
一個 “cell 數據庫”,被 API、conductor 和 compute 服務使用,存儲大多數與實例相關的信息。
-
一個 “cell0 數據庫”,它與 cell 數據庫相似,但只包含未成功調度的實例。這個數據庫類似于常規的 cell,但不包含計算節點,僅用來存放那些未能成功調度到實際計算節點的實例(因此也不會落在真實的 cell 上)。
-
一個 消息隊列,允許各服務通過 RPC 進行通信。
詳細講解:
這個部署描述了一個 OpenStack Nova 的多組件架構,其中涉及到多個服務和數據庫,分別處理不同的任務。下面是各個組件的詳細說明:
1. nova-api 服務:
功能:
nova-api是 Nova 的外部 API 服務,它暴露了 REST API 供用戶進行操作,例如啟動虛擬機、獲取實例狀態等。工作:當用戶發出請求時,
nova-api會處理這些請求并將其傳遞給其他服務(如nova-scheduler、nova-conductor)進行后續處理。2. nova-scheduler 和 placement 服務:
功能:
nova-scheduler和placement服務負責資源的調度和實例的部署決策。工作:
nova-scheduler根據計算資源(如 CPU、內存、存儲等)選擇合適的計算節點來部署虛擬機。
placement服務跟蹤每個計算節點的資源使用情況,確保合理的資源分配,并返回哪些節點有足夠的資源來容納新的實例。3. API 數據庫:
功能:
API 數據庫是nova-api和nova-scheduler使用的數據庫,主要用于存儲實例的位置信息及與虛擬機創建和調度相關的臨時信息。工作:這個數據庫包含了正在構建但尚未調度的虛擬機的臨時數據。它還存儲了與實例調度相關的元數據(如實例當前狀態)。
4. nova-conductor 服務:
功能:
nova-conductor服務的作用是將長時間運行的任務從 API 級服務中分離出來,并提供與計算節點的通信橋梁。工作:
nova-conductor可以執行一些需要較長時間的操作,如實例的遷移、快照、卷擴展等,同時也防止了nova-api直接訪問數據庫,從而提高了系統的效率和可靠性。它會向nova-compute和nova-scheduler等服務發送 RPC 請求,處理一些需要異步執行的任務。5. nova-compute 服務:
功能:
nova-compute服務負責管理虛擬化驅動程序和 hypervisor 主機(如 KVM、QEMU 等)。工作:
nova-compute在計算節點上執行虛擬機的創建、管理和銷毀等操作,它負責啟動和管理實例,并將實例的狀態與nova-api和其他服務同步。6. cell 數據庫:
功能:
cell 數據庫存儲了大多數關于實例的核心信息,包括虛擬機的狀態、配置信息等。工作:每個 cell 擁有自己的數據庫,存儲著屬于該 cell 的實例數據。
nova-compute、nova-conductor等服務會與對應的 cell 數據庫交互,從而保持各個 cell 之間的數據隔離并提高可擴展性。7. cell0 數據庫:
功能:
cell0 數據庫是一個特殊的數據庫,它與其他 cell 數據庫非常相似,但只存儲那些失敗的實例。工作:當一個實例無法在正常的計算節點上調度時,它會被暫時存儲在
cell0中。這個數據庫專門用于存儲無法調度的實例,直到它們能夠成功調度到其他的計算節點上。cell0并沒有計算節點,因此它主要作為一個臨時存儲失敗實例的地方。8. 消息隊列:
功能:消息隊列(通常使用 RabbitMQ 或其他消息隊列)是 OpenStack 服務之間進行通信的機制。
工作:服務之間通過消息隊列進行 RPC 通信,例如,
nova-api會通過消息隊列將調度任務發送到nova-scheduler,并通過nova-conductor與nova-compute進行通信。通過這種方式,服務之間可以解耦并異步處理請求。總結:
這個部署架構描述了 OpenStack Nova 在多組件環境下如何工作,以及各個服務如何協同配合以管理計算資源、虛擬機調度和管理。各個組件的作用如下:
nova-api提供外部 API 接口。
nova-scheduler和placement決定實例應該部署在哪個計算節點。
nova-conductor執行長時間運行的任務,解耦數據庫訪問。
nova-compute負責虛擬機的實際管理。數據庫和消息隊列在各個服務之間傳遞必要的信息和請求。
通過這些服務的協作,OpenStack Nova 能夠高效地管理大規模的計算資源,并實現彈性擴展。
在較小的部署中,通常會有一個共享的消息隊列和一個數據庫服務器,該服務器托管 API 數據庫、單個 cell 數據庫以及所需的 cell0 數據庫(a single message queue that all services share and a single database server which hosts the API database, a single cell database, as well as the required cell0 database.)。因為我們只有一個“真實”的 cell,所以這被認為是一個“單一 cell 部署”。(本次的OpenStack Yoga安裝就是采用較小的部署,在controller節點安裝了1個MQ軟件,給所有服務使用;一個mysql database軟件,里面安裝了nova-api db,nova db,nova-cell0 db,nova db也就是cell1的db,還有其他db)。
在較大的部署中,我們可以選擇使用多個 cell 來進行分片。在這種配置中,雖然仍然只有一個全局 API 數據庫,但每個 cell 都會有一個 cell 數據庫(存儲大多數實例信息),每個 cell 數據庫包含整個部署中一部分實例的數據,并且每個 cell 都會有單獨的消息隊列和 nova-conductor 實例。還會有一個額外的 nova-conductor 實例,稱為超級 conductor,用于處理 API 級操作。
在這些較大的部署中,每個 nova 服務將使用特定于 cell 的配置文件,每個配置文件至少會指定一個消息隊列端點(即 transport_url)。大多數服務還會包含數據庫連接配置信息(即 database.connection),而需要訪問全局路由和調度信息的 API 級服務,還需要配置以訪問 API 數據庫(即 api_database.connection)。
詳細講解:
這段文字描述了在 OpenStack Nova 部署中,單一 cell 部署 和 多 cell 部署 的不同配置和架構。我們可以根據部署的規模選擇不同的架構來滿足擴展性和高可用性的要求。下面是對每部分的詳細解釋。
1. 單一 Cell 部署:
在較小的 OpenStack 環境中,通常只有一個計算節點池和數據庫實例,所有的服務(包括 API 服務、計算服務、調度服務等)共享一個 消息隊列 和一個數據庫。
單一 cell 部署意味著只有一個 cell 數據庫,存儲所有實例的信息。這里沒有進行數據分片,所有的實例信息都集中在一個數據庫中。這種部署適用于規模較小的 OpenStack 環境。
在 單一 cell 部署 中:
只有 一個全局 API 數據庫,用于存儲實例的位置、狀態等信息。
一個 cell 數據庫 存儲所有實例的詳細數據。
一個 cell0 數據庫 只包含未能成功調度的實例信息,作為一個臨時存儲區。
共享消息隊列:所有服務使用相同的消息隊列進行通信,這簡化了配置,但可能會成為性能瓶頸。
2. 多 Cell 部署:
當 OpenStack 部署變得更大時,單一數據庫和單個消息隊列可能會成為瓶頸,因此可以選擇 多 cell 部署。在多 cell 部署中,系統將多個計算節點分成多個 cell,每個 cell 都有自己的數據庫、消息隊列和
nova-conductor實例。在 多 cell 部署 中:
依然有一個全局的 API 數據庫,用于存儲全局的路由信息、調度信息和 API 級別的數據。
每個 cell 數據庫 存儲該 cell 下所有實例的具體數據。每個 cell 包含整個部署的一部分實例數據,不同的 cell 數據庫負責不同的計算節點池。
每個 cell 都有獨立的 消息隊列 和 nova-conductor 實例,這使得各個 cell 可以獨立地處理實例調度、資源管理等任務。
超級 conductor(super conductor)是一個額外的
nova-conductor實例,用于處理 API 級操作,特別是跨 cell 的任務和全局數據操作。3. 配置文件和服務:
在多 cell 部署中,為了確保每個 cell 獨立運行,每個 Nova 服務都會使用 特定于 cell 的配置文件。這些配置文件包括:
消息隊列端點(
transport_url):每個服務的配置文件中都會指定一個消息隊列的端點,這樣服務就知道如何通過消息隊列與其他服務進行通信。每個 cell 使用自己的消息隊列來進行內部通信,但仍然通過全局 API 數據庫進行必要的協調。數據庫連接(
database.connection):除了消息隊列,很多服務還需要指定數據庫連接信息,告訴服務要連接哪個 cell 的數據庫。例如,每個 cell 的nova-compute、nova-conductor等服務會配置連接到其對應的 cell 數據庫。API 數據庫連接(
api_database.connection):某些服務(如nova-api和nova-scheduler)需要訪問全局的 API 數據庫,以便獲取關于實例調度的全局信息。因此,它們的配置文件中會指定一個連接到全局 API 數據庫的連接字符串。4. 多 Cell 部署的優勢:
擴展性:每個 cell 可以獨立管理一組計算節點和實例數據,這樣可以輕松擴展到數千個節點,減少單個數據庫的負載。
性能優化:每個 cell 擁有獨立的消息隊列和
nova-conductor實例,減少了對單一服務的依賴,使得資源調度和任務處理更加高效。故障隔離:單個 cell 發生故障時,不會影響到其他 cell 的運行,因為每個 cell 都有獨立的數據庫、消息隊列和計算節點。
靈活的資源調度:每個 cell 可以根據自己的資源和需求進行調度,適應不同的數據中心和區域要求。
5. 總結:
單一 cell 部署 適用于小規模的環境,所有服務共享一個數據庫和消息隊列。
多 cell 部署 適用于大規模環境,通過分片和獨立的配置提供更好的擴展性、性能和故障隔離。
在 多 cell 部署 中,每個服務使用特定的配置文件來連接消息隊列和數據庫,同時需要通過全局 API 數據庫協調跨 cell 操作。
API 級服務需要能夠與所有 cell 中的其他服務進行通信。由于它們只配置了一個 transport_url 和 database.connection,因此它們通過在 API 數據庫 中查找其他 cell 的信息,具體通過叫做 cell mappings 的記錄來實現。?
詳細講解:
這段話講述了 API 級服務(如
nova-api、nova-scheduler等)如何與不同 cell 中的服務進行通信,以及如何通過查找 cell mappings 來獲取其他 cell 的信息。1. API 級服務與所有 cell 通信的需求:
在 OpenStack 部署中,API 級服務 需要能夠與所有 cell 中的服務進行通信。這是因為 OpenStack 的服務通常是分布式的,特別是在 多 cell 部署 中,實例、計算資源和調度任務會分布在不同的 cell 中。為了確保 API 級服務能夠協調并管理整個 OpenStack 部署,它們需要知道如何訪問每個 cell 中的服務。
API 級服務(如
nova-api)并不直接和每個 cell 中的數據庫或消息隊列進行交互,而是通過 API 數據庫 和 cell mappings 來間接獲取所需的連接信息。2. 單個配置的 transport_url 和 database.connection:
每個 API 級服務配置文件中只會有一個 transport_url 和 database.connection 配置。這些配置項指定了服務所使用的 消息隊列 和 數據庫,但是這些配置項只對應某一個特定的 cell。
由于 API 級服務需要能夠與多個 cell 進行通信,它們并不會硬編碼每個 cell 的連接信息,而是依賴于 API 數據庫 中的 cell mappings 記錄來動態獲取其他 cell 的相關信息。
3. cell mappings 記錄:
cell mappings 是存儲在 API 數據庫 中的一種記錄,包含了關于每個 cell 的配置信息。它們通常包括每個 cell 的 消息隊列端點(
transport_url)、數據庫連接(database.connection)等。通過查找 cell mappings,API 級服務能夠動態地知道如何與其他 cell 的服務進行通信。這意味著,API 級服務不需要在配置中直接定義每個 cell 的具體連接信息,而是通過查找這些 cell mappings 來決定如何訪問其他 cell 的服務。
4. 如何工作:
當 API 級服務 需要與其他 cell 的服務進行交互時,它會訪問 API 數據庫,并通過查詢 cell mappings 來獲取該 cell 的 消息隊列 和 數據庫連接 信息。
例如,假設 nova-api 需要調度一個實例到
cell2,它會查詢 cell mappings 來獲取cell2的 transport_url 和 database.connection,然后使用這些信息與cell2的服務進行通信。5. 多 Cell 部署中的作用:
在 多 cell 部署 中,由于每個 cell 都可能有獨立的資源、調度和計算服務,API 級服務需要能夠跨越所有 cell 進行操作。例如,nova-scheduler 需要了解所有 cell 中的資源情況,以便在多個 cell 之間進行實例調度。
cell mappings 在這種部署中起到了關鍵作用,它們確保了 API 級服務能夠查詢到每個 cell 的配置信息,并進行必要的跨 cell 操作。
6. 總結:
API 級服務 需要與 所有 cell 的服務進行通信,但它們只配置了一個 transport_url 和 database.connection。
通過查詢 API 數據庫 中的 cell mappings,它們能夠獲取其他 cell 的連接信息,確保跨 cell 通信的能力。
cell mappings 存儲了每個 cell 的 消息隊列端點 和 數據庫連接 等信息,是 API 級服務與多個 cell 服務之間實現通信的橋梁。
2、Nova服務布局
每個服務(nova service)通常具有明確定義的通信模式,這決定了它們在部署中的布局。在一個小型/簡單的場景中,這些規則的影響不大,因為所有服務可以在一個單一的消息總線和一個單一的 cell 數據庫中相互通信。然而,隨著部署規模的擴大,擴展性和安全性問題可能促使服務的分離和隔離。?
詳細講解:
這段話描述了 OpenStack 部署中各個服務之間的通信模式及其如何隨著部署規模的增長而發生變化,尤其是在 擴展性 和 安全性 方面的考慮。
1. 服務的通信模式:
OpenStack 中的每個服務(如
nova-api、nova-compute、nova-scheduler等)都有一個 通信模式,即它們如何通過消息隊列(如 RabbitMQ)和數據庫(如 MySQL)進行交互。每個服務之間通過特定的協議(如 RPC)進行通信。在 小型或簡單的部署 中,所有服務通常會共享一個 消息總線(即消息隊列)和一個 單一的 cell 數據庫。這種模式下,服務之間的通信是簡單且直接的,它們能夠輕松地相互訪問和協作。
2. 小型部署的通信模式:
在 小型/簡單的場景 中,OpenStack 的服務通常不會面臨很大的負載或擴展問題。所有服務都可以通過一個 共享的消息總線 進行通信,且所有實例數據都存儲在一個 單一的 cell 數據庫 中。
由于服務間的通信沒有太多復雜的隔離要求,部署和配置較為簡單。這使得在這種場景下,通信模式的規則(即各個服務如何配置消息隊列和數據庫連接)對部署的影響相對較小。
3. 隨著部署規模的增長:
當 OpenStack 的部署規模增大時,問題就開始出現了。服務的數量增加,負載也隨之增大。在這種情況下,單一的消息總線和單一的數據庫可能成為瓶頸。
此外,擴展性 和 安全性 的問題開始變得更加重要。為了應對更大規模的計算資源和更高的并發需求,部署可能需要采用 多 cell 部署,即將不同的服務和實例分配到不同的 cell 中。
在 多 cell 部署 中,不同的 cell 之間通常會有更嚴格的 隔離,每個 cell 都有自己的消息隊列、數據庫和計算節點池。服務之間的通信也可能被分隔開來,這樣可以更有效地管理資源、優化性能,并提高安全性。
4. 擴展性和安全性驅動的服務分離與隔離:
擴展性:當部署規模增大時,服務的分離 允許每個 cell 獨立擴展,避免了單個服務或單一數據庫的瓶頸。通過將服務分配到不同的 cell 中,可以更靈活地處理計算資源的需求,支持更多的節點和實例。
安全性:在多 cell 部署中,服務的 隔離 提高了安全性。例如,敏感數據和關鍵服務可以被放置在特定的 cell 中,而不與其他 cell 共享資源。這種隔離可以減少服務之間的不必要干擾,并降低潛在的安全風險。
另外,不同的 cell 可以使用不同的消息隊列、數據庫和網絡配置,這使得每個 cell 更容易控制和保護自己的資源,避免被其他 cell 影響。
5. 總結:
在 小型部署 中,OpenStack 服務通過單一的消息總線和數據庫通信,通信規則的影響較小,配置簡單。
隨著部署規模的增長,尤其是 擴展性 和 安全性 的考慮,部署模式需要進行優化。這可能會促使服務 分離 和 隔離,例如通過 多 cell 部署 來實現更高效的資源管理和更好的安全控制。
擴展性 和 安全性 是推動服務分離和隔離的主要因素,它們有助于優化性能、提高可維護性,并降低潛在的風險。
2.1 Single cell
2.1.1 服務布局
這是一個單cell部署中基本服務的示意圖,以及它們之間的關系(即通信路徑):
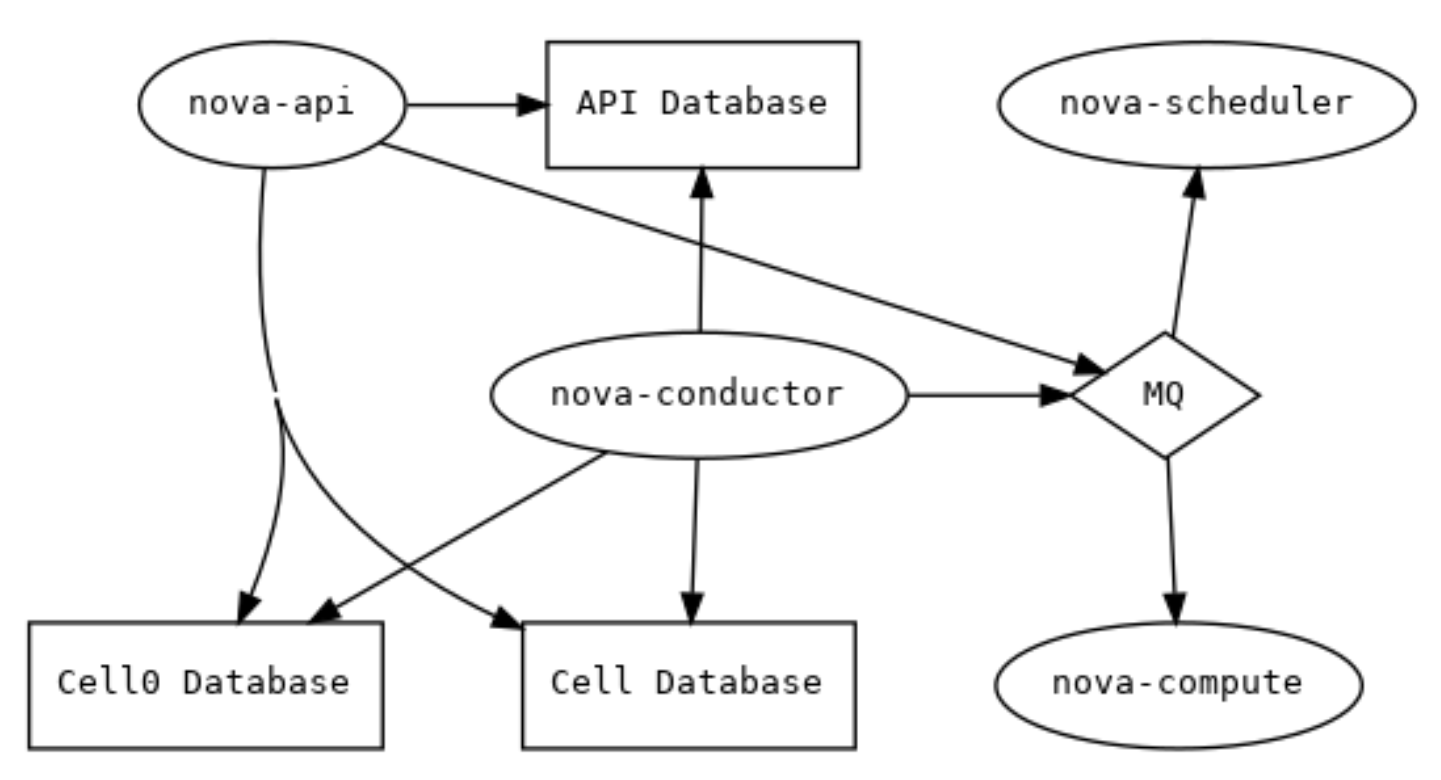
所有的服務都被配置為通過同一個消息總線進行通信,并且只有一個 cell 數據庫用于存儲實時實例數據。cell0 數據庫存在(并且是必須的),但是由于沒有計算節點連接到它,這仍然是一個“單一 cell”部署。
在 單?cell 部署 中,OpenStack 的服務相互連接,形成了一個簡單的通信架構。所有服務共享一個消息隊列(圖中MQ)和數據庫(Cell Database),因此配置和管理相對簡單。但隨著部署規模的增長,這種結構可能變得不再適用,可能需要拆分為多個 cell 以應對高負載和安全需求。
2.1.2 服務調用關系
在 單一 cell 部署 中,以創建一個虛擬機(VM)場景為例,涉及到的服務及其相互調用關系如下:
-
nova-api:-
用戶通過
nova-api發起創建虛擬機的請求。 -
nova-api接收到請求后,會首先與 API 數據庫 交互,記錄虛擬機的創建信息和狀態。
-
-
nova-scheduler:-
接著,
nova-api會將請求轉發給nova-scheduler。nova-scheduler的任務是決定虛擬機應該調度到哪個計算節點(nova-compute)上。 -
nova-scheduler會根據集群的資源情況(如 CPU、內存、存儲等)選擇一個合適的計算節點。
-
-
nova-conductor:-
一旦
nova-scheduler做出調度決策,nova-scheduler會通過 消息隊列(MQ) 向nova-conductor發送消息。nova-conductor會處理實際的任務,例如訪問數據庫、獲取必要的資源信息,并進行其他需要長時間運行的操作。 -
nova-conductor會與 Cell 數據庫 和 Cell0 數據庫 交互,更新相關信息,確保虛擬機創建的操作得到正確的記錄。
-
-
nova-compute:-
最后,
nova-conductor將調度信息傳遞給nova-compute,指示它在選定的計算節點上啟動虛擬機。 -
nova-compute負責在物理計算節點上實際啟動虛擬機,配置網絡、存儲、以及其他虛擬機所需的資源。
-
具體的調用流程:
-
用戶通過
nova-api發起虛擬機創建請求。 -
nova-api記錄請求信息,并通過 API 數據庫 更新實例狀態。 -
nova-api將請求轉發給nova-scheduler。 -
nova-scheduler選擇合適的計算節點后,將任務發送給nova-conductor。 -
nova-conductor在 Cell 數據庫 中查找資源,更新狀態,并與 Cell0 數據庫 交互(如果實例調度失敗)。 -
最后,
nova-conductor通過消息隊列向nova-compute發送創建虛擬機的命令。 -
nova-compute在計算節點上啟動虛擬機,并將狀態反饋給nova-conductor。
通過這個流程,所有相關的服務和數據庫共同協作,確保虛擬機的創建操作順利進行,并且實例的狀態在不同的組件間保持同步。
2.2 Multiple cells?
2.2.1 服務布局
為了將服務分片到多個 cells,必須進行若干操作。首先,消息總線必須按與 cell 數據庫相同的方式進行拆分。其次,必須為 API 級別的服務運行一個專門的 conductor,具有訪問 API 數據庫的權限并擁有一個專用的消息隊列。我們稱之為 super conductor,以區別于每個 cell 的 conductor 節點。
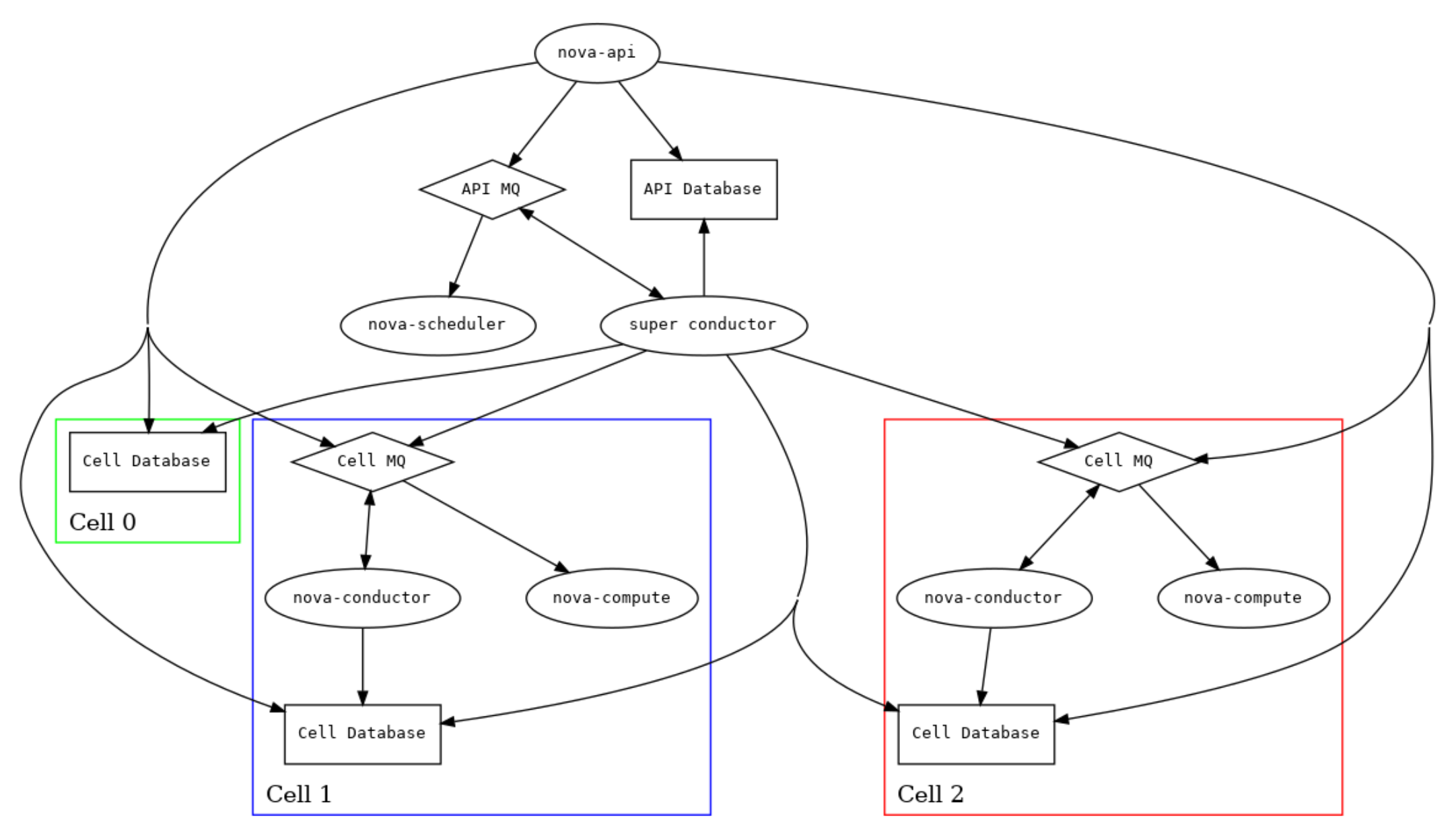
詳細講解:
這段話描述了如何將 OpenStack 的服務分片(shard)到多個 cell 中,以及如何配置相應的服務以支持這種多 cell 部署。下面是詳細的解析:
1. 將消息總線拆分為多個部分:
在 單一 cell 部署中,所有服務共享一個 消息總線(例如,RabbitMQ)。但在 多 cell 部署中,為了將服務分布到多個 cell 中,每個 cell 都會有自己的消息總線(或者至少是不同的消息隊列)。這就意味著消息總線會根據 cell 數據庫 的劃分進行拆分,使得每個 cell 內的服務能夠獨立地通過本地的消息隊列進行通信。
這種拆分有助于確保每個 cell 的服務之間的通信更加高效,并且減少了跨 cell 的通信延遲。
2. 專門的 conductor 為 API 級別服務提供支持:
在多 cell 部署中,除了每個 cell 運行一個 conductor 服務外,還需要一個專門的 super conductor 來處理 API 級別的操作。API 級別服務(例如
nova-api和nova-scheduler)需要訪問全局的 API 數據庫,并且它們需要處理來自不同 cell 的信息。super conductor 主要負責協調各個 cell 之間的操作,它與其他 cell 中的 conductor 區別開來,作用是處理更高層次的請求,確保 API 級別服務能夠跨 cell 正常工作。
3. super conductor 的作用和位置:
super conductor 是與每個 cell 內的 conductor 節點不同的,它主要服務于全局操作,如查詢、調度實例的跨 cell 操作等。它是一個獨立的服務,具有訪問全局 API 數據庫 和獨立消息隊列的權限。
super conductor 不直接管理實例,它的職責是協調多個 cell 之間的服務調用,確保整個 OpenStack 環境在多 cell 部署下能夠一致運行。
4. 每個 cell 的 conductor 節點:
每個 cell 都會有自己的 conductor 節點,負責與本 cell 相關的資源和實例的管理。它的作用是處理與計算節點和存儲節點的交互,不同的 cell 會有不同的 conductor 節點,獨立管理本 cell 內的資源。
每個 cell 的 conductor 節點與 super conductor 不同,前者專注于處理本 cell 內部的任務,而后者則負責協調整個 OpenStack 環境中的操作,尤其是在多個 cell 之間的跨 cell 操作。
5. 總結:
在 多 cell 部署 中,為了有效地管理跨 cell 的服務和資源,必須將消息總線拆分為多個部分,每個 cell 擁有獨立的消息隊列。此外,還需要一個 super conductor,它與各個 cell 中的 conductor 節點不同,主要負責協調 API 級別的全局操作,確保整個系統的穩定性和一致性。
這種結構有助于大規模 OpenStack 環境的擴展,確保每個 cell 的負載得到合理分配,同時保證服務間的高效通信。
2.2.2?服務調用關系
在多?cell 部署 中,以創建一個虛擬機(VM)場景為例,涉及到的服務及其相互調用關系如下:
1. 用戶通過 nova-api 創建虛擬機請求
-
用戶通過
nova-api提交創建虛擬機的請求。 -
nova-api是接收外部請求的接口,它提供 RESTful API 供用戶進行虛擬機的創建、刪除等操作。
2. nova-api 通過 API MQ 與 super conductor 通信
-
當
nova-api接收到虛擬機創建請求后,它會通過 API MQ 向 super conductor 發送消息。 -
API MQ 是一個 全局消息隊列,用于跨 cell 服務之間的通信。它確保 API 服務(如
nova-api)能夠與 super conductor 和其他服務進行通信。
3. super conductor 訪問 API 數據庫
-
super conductor 是一個特殊的 conductor 實例,它主要負責處理 API 級別的操作,例如跨 cell 的調度任務。與每個 cell 的獨立 conductor 節點不同,super conductor 負責協調 API 請求和管理跨 cell 操作。
-
super conductor 通過訪問 API 數據庫 來獲取有關實例調度、資源分配等的全局信息。它還會在 API 數據庫中更新虛擬機的狀態。
4. super conductor 向相應的 Cell MQ 發送調度請求
-
super conductor 根據 API 請求將調度任務傳遞給相應的 cell,并通過 Cell MQ 與目標 cell conductor 進行通信。每個 cell 都有自己的 消息隊列(Cell MQ),用于該 cell 內部服務的通信。
-
super conductor 會通過 Cell MQ 向 cell conductor 發送虛擬機創建的指令,告知該 cell 執行具體的虛擬機創建操作。
5. cell conductor 選擇計算節點并與 nova-compute 交互
-
cell conductor 負責與 cell 數據庫 和 nova-compute 進行交互,執行虛擬機的實際創建操作。
-
cell conductor 會根據資源需求選擇一個適合的計算節點(
nova-compute)。它會與目標計算節點的nova-compute節點進行通信,指示計算節點啟動虛擬機。 -
cell conductor 還會更新 cell 數據庫,記錄實例的狀態。
6. nova-compute 啟動虛擬機
-
nova-compute 在目標計算節點上啟動虛擬機。它與 Hypervisor(如 KVM、Xen)進行交互,分配虛擬機的資源(如 CPU、內存、存儲等)并啟動虛擬機實例。
-
一旦虛擬機啟動成功,
nova-compute會將結果返回給 cell conductor,并通過消息隊列通知 super conductor 虛擬機創建成功。
7. super conductor 更新數據庫
-
super conductor 會更新數據庫中的虛擬機狀態,將其標記為“已創建”或“已啟動”,并將這些信息同步到 API 數據庫。
-
最后,super conductor 將虛擬機創建的成功信息通過 API MQ 返回給 nova-api,通知用戶虛擬機創建完成。
具體的調用流程:
-
nova-api接收用戶請求,發送虛擬機創建任務到 super conductor。 -
super conductor 通過 API MQ 獲取請求并訪問 API 數據庫,根據調度需要向 cell conductor 發送請求。
-
cell conductor 根據資源選擇目標計算節點,并與 nova-compute 進行交互,啟動虛擬機。
-
nova-compute 在計算節點上啟動虛擬機,并將結果返回給 cell conductor。
-
super conductor 更新數據庫中的虛擬機狀態,并將成功信息返回給 nova-api。
各個服務角色解釋:
API MQ:用于 nova-api 與 super conductor 之間的通信,確保 API 請求能夠傳遞給處理虛擬機創建的高層服務。
Cell MQ:用于 super conductor 與各個 cell conductor 之間的通信。每個 cell 都有自己的消息隊列,用于處理該 cell 內部的服務調用。
super conductor:跨 cell 的 conductor,處理 API 級別的任務,協調不同 cell 的服務操作。
cell conductor:每個 cell 中的 conductor 節點,負責與本 cell 內部的 nova-compute 和數據庫進行交互,執行實例創建等任務。
nova-compute:在計算節點上執行虛擬機的創建操作,啟動虛擬機并管理其生命周期。
這種設計使得 OpenStack 在多 cell 部署下能夠高效地調度資源、隔離各 cell 的服務、并且確保跨 cell 的操作協調和一致性。
3、Nova數據庫布局
所有的 Nova 部署都是Cell v2的部署方式,必須擁有并配置以下數據庫:
-
API 數據庫
-
一個特殊的 cell 數據庫,稱為 cell0
-
一個(或將來更多的)cell 數據庫
因此,一個小型的 Nova 部署(Single cell)將有一個 API 數據庫,一個 cell0 數據庫,以及我們在此稱之為 cell1 的數據庫。高層次的跟蹤信息存儲在 API 數據庫中。那些從未調度成功的實例會被放到 cell0 數據庫中,實際上它是一個存放調度失敗實例的“墓地”。所有成功運行的實例則存儲在 cell1 中。
詳細講解:
這段話講述了 cells v2 架構在 Nova 部署中的應用和數據庫配置要求。根據 OpenStack Nova 的 cells v2 架構,即使是 單一 cell 部署,也需要進行相關的 cells 配置,并確保一定的數據庫配置。
1. 所有部署都是 cells v2 部署
現在,OpenStack Nova 的所有部署都基于 cells v2 架構。這意味著,不管是 單一 cell 部署 還是 多 cell 部署,都需要使用 cells v2 的配置和數據庫結構。
cells v2 架構讓 Nova 支持將計算節點分割成多個 cell,每個 cell 具有獨立的數據庫和資源池。這樣可以提高部署的可擴展性、資源隔離性和容錯性。
2. 配置要求
由于所有部署都需要支持 cells v2,即使是單個 cell 部署,也需要進行一定的 cells 配置。
配置內容不僅僅是在 nova.conf 配置文件中設置,還包括在數據庫中添加相關記錄。特別是,數據庫中需要有用于 cell 的標識、實例狀態等信息。
3. 所需數據庫
在 cells v2 架構中,所有 Nova 部署都需要以下數據庫:
API 數據庫:這是一個全局數據庫,用于存儲 Nova API 和 Nova 調度器 需要的高層次信息(如虛擬機的調度狀態、位置等)。所有實例的高層次元數據和調度狀態都存儲在這個數據庫中。
cell0 數據庫:這是一個特殊的 cell 數據庫。它存儲那些沒有成功調度的實例,即那些由于某些原因無法啟動的實例。可以把它看作是一個“墓地”數據庫,用來存放那些在調度過程中失敗的虛擬機實例。通常,調度失敗的實例(如由于計算節點資源不足或其他錯誤而無法啟動的實例)會被暫時存儲在 cell0 數據庫中,直到它們能夠被重新調度。
cell 數據庫(如 cell1):每個實際使用的 cell 都會有自己的數據庫(例如 cell1)。在這個數據庫中,會存儲 所有成功啟動的實例 的數據。每個 cell 都有自己的數據庫,用于存儲該 cell 內部的虛擬機實例的狀態和資源信息。
4. 單一 cell 部署的數據庫
在 單一 cell 部署 中,會有以下三種數據庫:
API 數據庫:存儲全局的調度信息和實例狀態。
cell0 數據庫:存儲調度失敗的實例。
cell1 數據庫:存儲所有成功調度并正在運行的虛擬機實例。
這種配置對于 小型部署 非常適用,因為它通過將所有實例數據存儲在一個 cell1 數據庫中,實現了較為簡單的管理。
5. 虛擬機的存儲和調度
API 數據庫 主要存儲的是關于虛擬機和實例的高層信息,例如實例的調度狀態、位置等。
cell0 數據庫 僅包含那些未能成功調度的虛擬機。即,如果 Nova 無法將一個實例調度到一個合適的計算節點,實例信息就會被存放在 cell0 中,等待重新調度。
cell1 數據庫 存儲的是所有已經成功調度和正在運行的虛擬機的信息。這些實例可以跨多個計算節點,
nova-compute服務會定期與 cell1 數據庫同步虛擬機狀態。6. 總結
cells v2 架構不僅在 多 cell 部署 中有應用,在 單一 cell 部署 中也必須進行一些基本的配置,尤其是數據庫配置。
在 單一 cell 部署 中,Nova 部署會涉及 API 數據庫、cell0 數據庫 和 cell1 數據庫,它們分別用于存儲全局的調度信息、失敗的實例信息和正在運行的實例信息。
這些數據庫的設計確保了 OpenStack 在 單一 cell 和 多 cell 部署中都能夠高效地進行資源管理和調度,同時處理失敗的實例并保證系統的高可用性。
通過這種架構,即使是小規模的部署,也能保證高效的資源管理,并為未來擴展到多 cell 部署做好準備。
4、Nova安裝筆記回顧
在《OpenStack Yoga版安裝筆記(十二)nova(下)》中,OpenStack Nova 采用 Cells v2 架構,配置為單一cell(Single cell)部署模式。
1、創建nova_api,nova,nova_cell0數據庫:
MariaDB [(none)]> CREATE DATABASE nova_api;
Query OK, 1 row affected (0.001 sec)MariaDB [(none)]> CREATE DATABASE nova;
Query OK, 1 row affected (0.000 sec)MariaDB [(none)]> CREATE DATABASE nova_cell0;
Query OK, 1 row affected (0.000 sec)2、編輯/etc/nova/nova.conf,配置數據庫和MQ連接信息
[api_database]
# ...
connection = mysql+pymysql://nova:NOVA_DBPASS@controller/nova_api[database]
# ...
connection = mysql+pymysql://nova:NOVA_DBPASS@controller/nova[DEFAULT]
transport_url = rabbit://openstack:openstack@controller:5672/3、同步 Nova API 數據庫架構:
root@controller:~# su -s /bin/sh -c "nova-manage api_db sync" nova
- api_db sync 是同步 Nova API 數據庫架構的子命令。它應用任何待處理的數據庫遷移(架構更改),以確保 API 數據庫與當前版本的 Nova 所需的結構匹配。
4、在 Nova cell_v2 架構中注冊特殊的 cell0:
root@controller:~# su -s /bin/sh -c "nova-manage cell_v2 map_cell0" nova
- cell_v2 map_cell0 是一個子命令,用于在 Nova API 數據庫中為 cell0 創建映射 ,將其注冊為用于處理調度失敗的實例的特殊 cell。?
5、在 Nova cell_v2 架構中創建一個名為 cell1 的新單元:
root@controller:~# su -s /bin/sh -c "nova-manage cell_v2 create_cell --name=cell1 --verbose" nova
Modules with known eventlet monkey patching issues were imported prior to eventlet monkey patching: urllib3. This warning can usually be ignored if the caller is only importing and not executing nova code.
--transport-url not provided in the command line, using the value [DEFAULT]/transport_url from the configuration file
--database_connection not provided in the command line, using the value [database]/connection from the configuration file
8b1967df-7901-42b3-8b03-fc4e884f490d
root@controller:~#
- cell_v2 create_cell 是在 Nova cell_v2 體系結構中創建新單元的子命令。
6、將 Nova 主數據庫架構與已安裝的 Nova 軟件定義的最新版本同步:
root@controller:~# su -s /bin/sh -c "nova-manage db sync" nova
- db sync 是同步 Nova 主數據庫架構的子命令。它會應用任何待處理的數據庫遷移(架構更改),以確保數據庫與當前版本的 Nova 所需的結構匹配。?
7、發現和注冊 Nova cell_v2 架構中的計算節點(nova-compute):
root@controller:~# su -s /bin/sh -c "nova-manage cell_v2 discover_hosts --verbose" nova
Modules with known eventlet monkey patching issues were imported prior to eventlet monkey patching: urllib3. This warning can usually be ignored if the caller is only importing and not executing nova code.
Found 2 cell mappings.
Skipping cell0 since it does not contain hosts.
Getting computes from cell 'cell1': 8b1967df-7901-42b3-8b03-fc4e884f490d
Checking host mapping for compute host 'compute1': 205c89e0-fb82-4def-a0f6-bfe4b120ab79
Creating host mapping for compute host 'compute1': 205c89e0-fb82-4def-a0f6-bfe4b120ab79
Found 1 unmapped computes in cell: 8b1967df-7901-42b3-8b03-fc4e884f490d
root@controller:~# root@controller:~# nova-manage cell_v2 list_hosts --cell_uuid 8b1967df-7901-42b3-8b03-fc4e884f490d
Modules with known eventlet monkey patching issues were imported prior to eventlet monkey patching: urllib3. This warning can usually be ignored if the caller is only importing and not executing nova code.
+-----------+--------------------------------------+----------+
| Cell Name | Cell UUID | Hostname |
+-----------+--------------------------------------+----------+
| cell1 | 8b1967df-7901-42b3-8b03-fc4e884f490d | compute1 |
+-----------+--------------------------------------+----------+
root@controller:~#
root@controller:~# su -s /bin/sh -c "nova-manage cell_v2 discover_hosts --verbose" nova
Modules with known eventlet monkey patching issues were imported prior to eventlet monkey patching: urllib3. This warning can usually be ignored if the caller is only importing and not executing nova code.
Found 2 cell mappings.
Skipping cell0 since it does not contain hosts.
Getting computes from cell 'cell1': 8b1967df-7901-42b3-8b03-fc4e884f490d
Found 0 unmapped computes in cell: 8b1967df-7901-42b3-8b03-fc4e884f490d
root@controller:~#
root@controller:~# nova-manage cell_v2 list_hosts --cell_uuid 8b1967df-7901-42b3-8b03-fc4e884f490d
Modules with known eventlet monkey patching issues were imported prior to eventlet monkey patching: urllib3. This warning can usually be ignored if the caller is only importing and not executing nova code.
+-----------+--------------------------------------+----------+
| Cell Name | Cell UUID | Hostname |
+-----------+--------------------------------------+----------+
| cell1 | 8b1967df-7901-42b3-8b03-fc4e884f490d | compute1 |
+-----------+--------------------------------------+----------+
- cell_v2 discover_hosts 是一個子命令,用于掃描尚未在 Cell 數據庫中注冊的計算主機(運行 nova-compute 的服務器 ),并將它們映射到相應的 Cell。








)

)








技術的優勢和挑戰(本片為InsCode))