分享筆者在學習 MegEngine 對 DTR 的實現時的筆記。關于 DTR 可以參考:【翻譯】DTR_ICLR 2021
文章目錄
- MegEngine 架構設計
- MegEngine 的動態圖部分
- Imperative Runtime
- Imperative 與 MegDNN / MegBrain 的關系
- 靜態圖運行時管家 —— MegBrain
- 動態圖接口 —— Imperative
- 總結
- Imperative Runtime 架構解析
- MegEngine Python 層的 Tensor 行為
- MegEngine 引入 DTR 的過程
- MegEngine 1.4 實現 DTR 的核心代碼
- imperative/src/impl/interpreter/tensor_info.h
- imperative/src/impl/interpreter/interpreter_impl.h
- imperative/src/impl/interpreter/interpreter_impl.cpp
- 分配
- 刪除
- 核心實現
- 輔助函數
- 啟發式公式
- 重計算次數
- 空閑顯存塊大小
- 參考資料
MegEngine 架構設計
以下內容引用自:MegEngine 架構設計 — MegEngine 1.13.2 文檔
MegEngine 整體由兩部分 Runtime 加上底層的公共組件組成:
- 其中靜態圖部分(又稱 Graph Runtime )主要提供 C++ 推理接口;
- 動態圖部分(又稱 Imperative Runtime )主要提供 Python 接口供動態訓練使用;
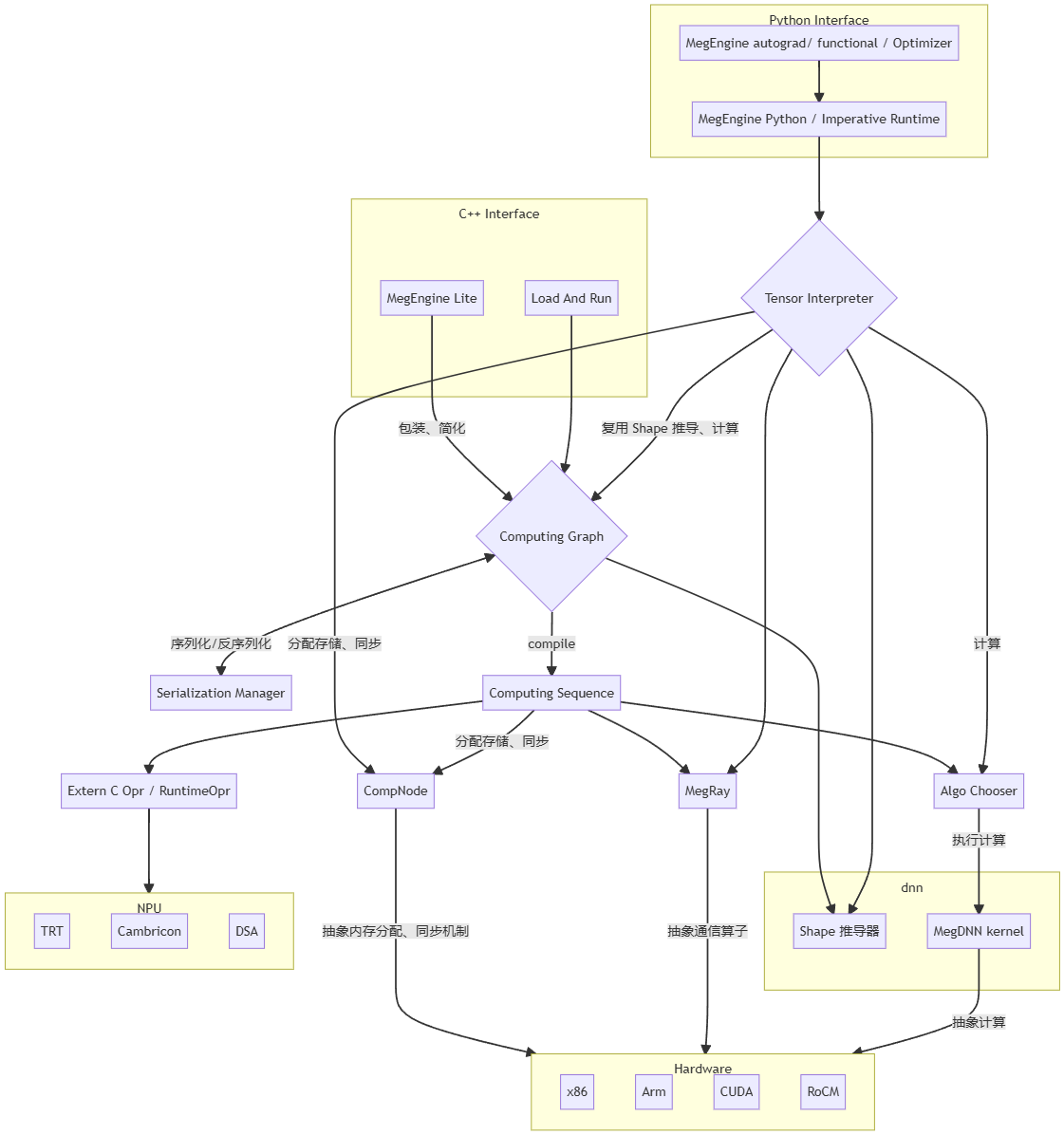
接口層
- MegEngine Imperative Runtime: 動態解釋執行接口
- MegEngine Lite: C++ 靜態圖推理接口
- Load and run: 一份用于調試性能的工具(可看做一種推理代碼的樣例)
核心模塊層
- Computing Graph: 一張以 OpNode 和 VarNode 依次相連的 DAG,用以表達全部計算依賴,是靜態圖的模式的核心。模塊內部包含了圖優化、靜態推導、自動求導的各類功能。通過 compile 可以產生 Computing Sequence 以用于實際執行
- Computing Sequence: 一個帶有依賴關系的執行序列,是 Computing Graph 的一種拓撲排序結果,其中包含了內存分配策略等資源信息,可以通過 execute 執行其中的全部 Op
- Tensor Interpreter: Tensor 解釋器,用于解釋執行動態模式下的計算操作;
- 其中部分操作是通過構建一張臨時的 Computing Graph 來復用原有操作,
- 另一部分通過直接調用底層實現(以獲得更高的性能)
工具模塊
- Shape 推導器: 用于靜態推導 shape
- Algo Chooser: 同一 Op 不同 kernel 的選擇器,用以挑選在當前參數下最快的 kernel,是 Fastrun 機制的核心
- Serialization Manager: 對 Computing Graph 進行序列化 / 反序列化,提供無限向后兼容性 (backward compatible)
硬件抽象層(HAL)
- MegDNN kernel: 包含各類平臺下的計算算子實現(部分簡單算子直接在 megengine src 目錄下實現,未包含在 dnn 中)
- Extern C Opr / Runtime Opr: 用于包裝 DSA / TRT 等子圖,對上層抽象為一個 Op
- CompNode: 對硬件的基本操作進行抽象,包括 執行計算、同步機制、內存分配、跨設備拷貝 等原語。一個 CompNode 對應一個 GPU stream 或 CPU 線程,部分硬件上實現了內存池以進一步提高性能
- MegRay: 對訓練場景下的集合通訊、點對點通信進行了設備無關的抽象,底層對應了 nccl / rccl / ucx / 自研方案 等不同實現
硬件層
MegEngine 的動態圖部分
以下內容引用自:Imperative Runtime — MegEngine 1.13.2 文檔
Imperative Runtime
以下內容引用自:MegEngine/imperative at master · MegEngine/MegEngine
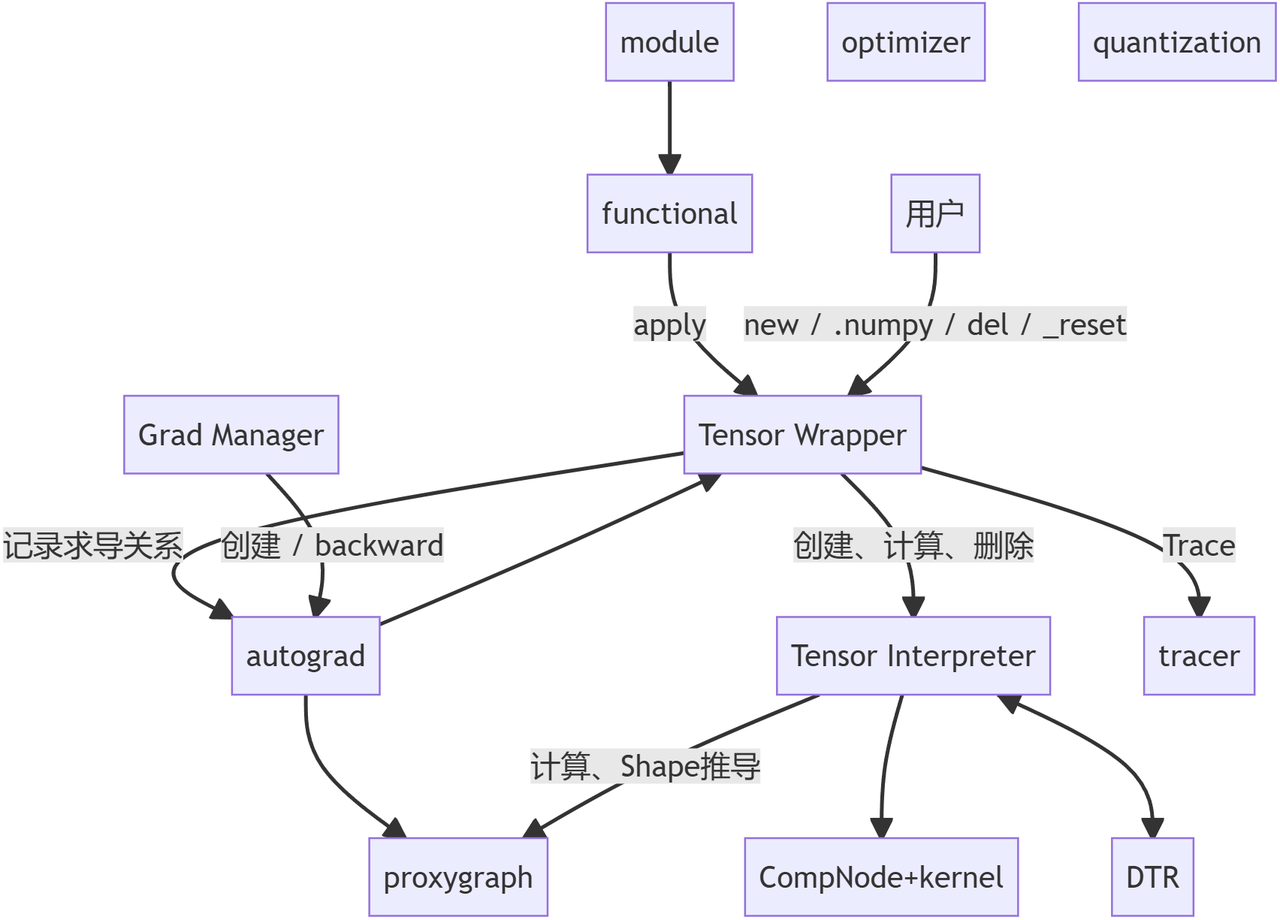
Imperative Runtime 是為了動態訓練單獨設計的一套新接口,其設計基本原則包含:
- 與 graph runtime 的計算行為盡可能復用相同的計算代碼,確保訓推一致性
- Pythonic 一切資源完全與 python 對象深度綁定
各類模塊:
- module / optimizer 等:Python 模塊
- functional: 各類計算函數,底層基本是直接調用 apply(OpDef, args)
- Tensor Wrapper: C++ 模塊,從 Python 層可以直接看到的 tensor 類型,提供計算、自動微分、trace 等功能
- Tensor Interpreter:
- 一切計算的入口,提供 put tensor, apply(OpDef, tensor), get tensor 三大類功能
- 所有計算操作均為異步,因此除可被外界觀測到的 put 和 get 外,其他操作均可被透明的調整順序或優化
- 底層計算部分直接調用 kernel,部分通過 proxygraph 調用 graph runtime 實現
- DTR: 動態重計算模塊,負責 Tensor Interpreter 的 drop 指令,確保記錄計算過程,確保被 drop 掉的 tensor 在被需要時重新計算得到
- autograd: 自動微分機制,負責記錄 Tensor Wrapper 的計算過程并通過 refcount 確保依賴的 tensor 不被釋放
- tracer: 在 trace 模式下記錄全部的計算過程,從而生成靜態圖
- proxygraph: 一系列橋接機制的統稱,通過建立臨時的計算圖實現復用 graph runtime 中的計算、shape 推導的能力;其中的 graph 與用戶實際計算無關,可隨時清空。
Imperative 與 MegDNN / MegBrain 的關系
以下內容引用自:MegEngine 動態執行引擎-Imperative Runtime 概述
MegEngine 自上向下包含三個層次:Imperative、MegBrain 和 MegDNN。它們的角色定位分別是:
- Imperative:MegEngine 為動態訓練設計的一套新接口,負責處理動態圖運行時(Imperative Runtime)。
↑- MegBrain:負責處理靜態圖運行時(Graph Runtime)。
↑- MegDNN:MegEngine 的底層計算引擎。
靜態圖運行時管家 —— MegBrain
為了確保訓練推理一致性, Imperative 中復用了 MegBrain 的計算代碼。
MegBrain 負責處理靜態圖的運行時,主要提供 C++ 的訓練和推理接口。
從 MegEngine 整體架構圖可以看出,Imperative 通過 Tensor Interpreter (張量解釋器)復用了許多 MegBrain 的代碼。比如 shape 推導、計算、求導、Trace 等。
在 MegBrain 中,一個 Computing Graph 由 SymbolVar 以及許多 op(算子,operator)組成。SymbolVar 是在 MegBrain 層面 Tensor 的表示,可以理解為傳遞給 op 進行計算的數據。作個類比,
op是類似加減乘除這樣的計算操作(在深度學習中常用的有convolution、pooling等),- SymbolVar 就是我們用來進行加減乘除的“數”(在深度學習中就是
Tensor)。
動態圖接口 —— Imperative
因為 MegEngine 是動靜合一的深度學習框架,MegBrain 解決了靜態圖的訓練和推理問題,還需要有一個“組件”負責處理動態圖的訓練和推理、以及 Python 側的訓練接口,于是便有了 Imperative,也就是說,Imperative Runtime 是為了動態訓練而單獨設計的一套新接口。
實際上,在 MegBrain 的 Computing Graph 中已經有了非常多的算子實現,因此 MegEngine 的 Imperative 借助張量解釋器 Tensor Interpreter 較多地復用了 MegBrain 中的 op。這樣做的原因是:
- 重寫算子代價高,且容易寫錯。
- 若 Imperative 的實現和 MegBrain 的實現不一致的話,容易導致訓練推理不一致。
除了復用 MegBrain 的部分功能,Imperative 自身包含的模塊主要有:
Module(定義深度學習網絡的基礎類的實現)Optimizer(一些優化器的實現)Functional(提供 python 層的訓練接口)Interpreter(計算入口,底層會調用 kernel 或者 MegBrain 的算子實現)DTR(動態重計算模塊)Tracer(記錄計算圖的計算過程)等
總結
簡單來說,MegDNN 負責 MegEngine 中所有的計算操作在各個平臺(CUDA 等)的最終實現,無論是 MegBrain 還是 Imperative 的 op,最終都需要通過調用 MegDNN kernel 來完成計算。
既然 MegDNN 包攬了計算的活兒,那么在訓練推理過程中那些與計算無關的工作,自然就落到了 MegBrain 和 Imperative 的頭上。這些工作包括:
- 求導
- 內存分配
- 對
Tensor的shape進行推導 - 圖優化
- 編譯等
MegEngine 整體上是有兩部分 Runtime 以及底層的一些公共組件組成的。這兩部分的 Runtime 分別叫做 Graph Runtime(對應 MegBrain) 和 Imperative Runtime(對應 Imperative)。
- Graph Runtime 負責靜態圖部分,主要提供 C++ 訓練推理接口。實際計算時需要調用
MegDNN的實現。 - Imperative Runtime 負責動態圖部分,主要為動態訓練提供 Python 接口。實際計算時需要調用
MegBrain的已有實現或者直接調用MegDNN的 kernel。
Imperative Runtime 架構解析
以下內容引用自:MegEngine 動態執行引擎-Imperative Runtime 架構解析
計算圖可以認為是對輸入的數據(tensor)、op 以及 op 執行的順序的表示。
計算圖分為動態圖和靜態圖。
- 動態圖是在前向過程中創建、反向過程銷毀的。前向邏輯本身是可變的,所以執行流程也是可變的(因此叫動態圖),而靜態圖的執行流程是固定的。也就是說,動態圖在底層是沒有嚴格的圖的概念的(或者說這個圖本身一直隨執行流程變化)。
- 對于動態圖來說,graph 的 node 對應的概念是
function/ 算子,而 edge 對應的概念是tensor,所以在圖中需要記錄的是 graph 中node和edge之間的連接關系,以及tensor是function的第幾個輸入參數。 - 靜態圖需要先構建再運行,可以在運行前對圖結構進行優化(融合算子、常數折疊等),而且只需要構建一次(除非圖結構發生變化)。而動態圖是在運行時構建的,既不好優化還會占用較多顯存。
MegEngine Python 層的 Tensor 行為
以下內容引用自:MegEngine Python 層 Tensor 行為 — MegEngine 1.13.2 文檔
從邏輯上來講,各層之間的引用關系如下圖所示:
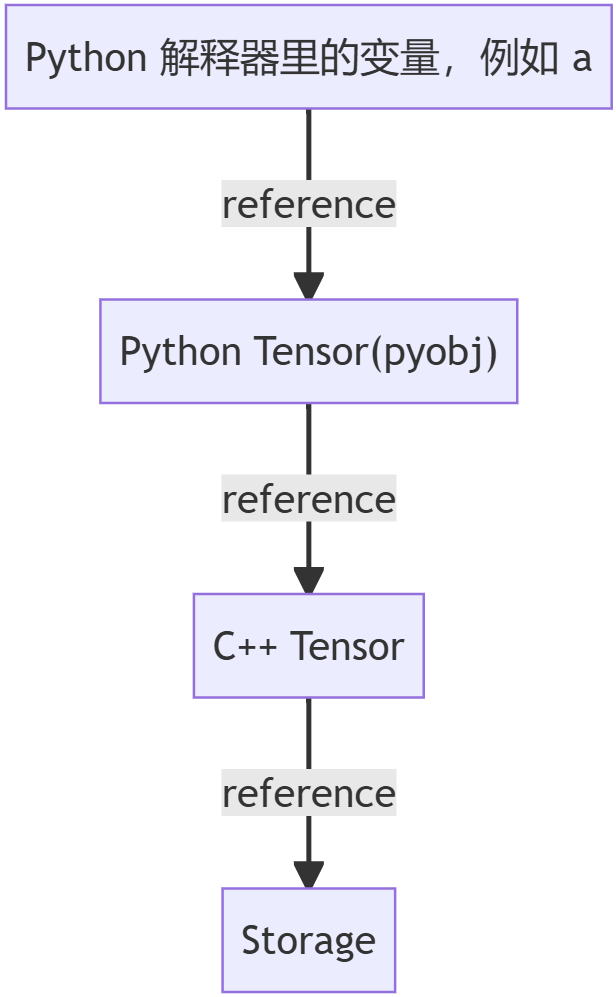
三者均通過 refcount 進行資源管理,在引用歸零時就釋放資源,其中:
- Python Tensor 只包含對 C++ Tensor 的引用;用戶可通過 id(a) 是否一直來驗證是否發生了變化
- C++ Tensor 包含:shape / stride / 對 Storage 的引用指針
Storage包含:一段顯存,即ptr + length
MegEngine 引入 DTR 的過程
- v1.4.0
- 重構 DTR 相關的 API 并修復其中隨機數算子相關的 bug。
- 在開啟DTR訓練時,可能會出現申請顯存失敗的報錯日志,這說明當前正在進行碎片整理,整理后程序可能可以繼續運行。
- v1.5.0
- DTR 升級
- 在 trace 的靜態構造模式下支持用 DTR 算法優化計算圖的顯存峰值,與 Sublinear 相比,ResNet 50 單卡最大 batch size 350->450,八卡 300→450。
- 動態圖模式下支持無閾值開啟,用戶無需指定 eviction_threshold。
- DTR 升級
- v1.6.0
- 修復開啟 DTR 時由于重算鏈過長導致遞歸棧溢出的問題。
- DTR 優化,各模型測試速度平均提升約10%,ResNet50 8 卡最大 batchsize 達500, GL 8 卡最大 batchsize 達 110, ViT 8 卡最大 batchsize 達 300 。
- v1.7.0
- 修復禁止 DTR 功能時未釋放相關資源的問題。
- 解決 DTR 平方根采樣不隨機的問題,解決后 resnet1202 訓練速度可提升5%。
- 刪除 DTR 中所有 swap 接口。
- 顯存分配默認開啟去碎片功能,去除 enable_defrag 接口。
- 訓練時自動打開 defrag 功能,顯存不夠且顯存碎片嚴重時可合并顯存碎片。
- v1.10.0
- v1.10 trace 模式下 sublinear 和靜態圖 dtr 是失效的。
- v1.11.0
- 修復參數 tensor 初始化中未考慮 DTR 導致的卡死問題。
- v1.12.2
- 修復開啟 DTR 時,使用 stack/concat 算子程序崩潰的問題。
- v1.12.4
- 修復了開啟 DTR 情況下多卡訓練概率性崩潰的問題。
MegEngine 1.4 實現 DTR 的核心代碼
imperative/src/impl/interpreter/tensor_info.h
代碼地址:MegEngine/imperative/src/impl/interpreter/tensor_info.h at release-1.4 · MegEngine/MegEngine
在網絡訓練的過程中,每個 tensor 的來源只有兩種情況:
- 由外部數據加載進來,例如:輸入數據;
- 是某個算子的輸出,例如:卷積層的輸出。
對于算子的輸出,我們可以記錄這個 tensor 的計算路徑(Compute Path),結構體如下所示:
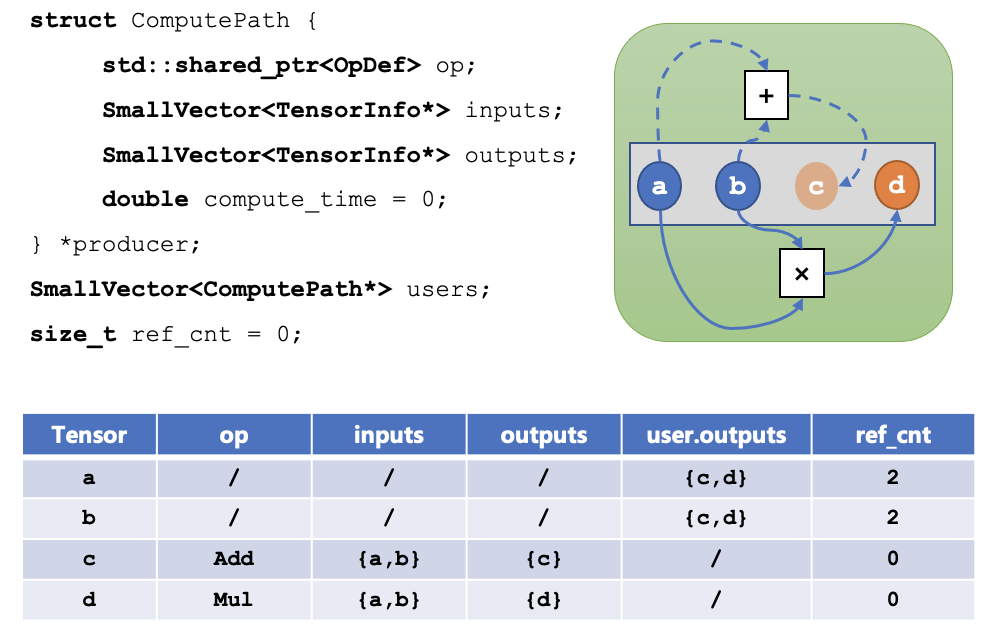
- 每個 tensor 都會有一個 producer,如果 producer 是空,就表示它是由外部數據加載進來的,否則它是一個計算路徑,其中:
op表示產生這個 tensor 的算子;inputs表示這個算子需要的輸入 tensor;outputs表示這個算子產生的輸出 tensor;compute_time表示這個算子實際的運行時間;
users中存儲的是所有依賴該 tensor 作為輸入的計算路徑;ref_cnt表示依賴該 tensor 作為輸入的 tensor 數量。
// 定義了三種逐出(eviction)類型
enum EvictType {NONE = 0,SWAP = 1,DROP = 2,
};/*!* an identifier to specify a component of evicted tensors * 用于指定被逐出張量的組成部分的標識符* Each component tracks the sum of the compute costs of its elements, with the union of two components having the sum of each constituent cost.* 每個組件跟蹤其元素的計算成本總和,兩個組件的并集具有每個組成成本的總和。* * 對應 CheckpointTensorImpl.h 里的 struct EquivalentClassNode*/
struct DsuNode {DsuNode(double _t): t(_t) {}std::shared_ptr<DsuNode> parent;bool is_root() {return !bool(parent);}double t;
};struct TensorInfo;
using TensorInfoPtr = std::shared_ptr<TensorInfo>;struct TensorInfo {enum Prop {Device, Shape, DType, DevValue, HostValue};uint64_t id;TensorPtr ptr; // 指向物理張量(TensorPtr)的指針。LogicalTensorDesc desc; // 邏輯張量描述double compute_time; // 計算時間size_t memory; // 占用的內存大小double last_used_time; // 最后使用時間// FIXME: broken by dropbool value_fetched = false;bool invalid = false;bool allow_delete = false;EvictType evict_type = NONE; // 逐出類型HostTensorND h_value; // 主機端的張量值// reserved for auto dropsize_t pinned = 0; // 固定計數,用于防止逐出。size_t recompute_times = 0; // 重新計算次數。size_t ref_cnt = 0; // 引用計數。表示依賴該 tensor 作為輸入的 tensor 數量。std::shared_ptr<DsuNode> dsu_ptr; // 對應 CheckpointTensorImpl.h 里的 ecn_ptr 驅逐鄰域struct ComputePath { // tensor 的計算路徑std::shared_ptr<OpDef> op; // 表示產生這個 tensor 的算子SmallVector<TensorInfo*> inputs; // 表示這個算子需要的輸入 tensorSmallVector<TensorInfo*> unique_inputs;SmallVector<TensorInfo*> outputs; // 表示這個算子產生的輸出 tensordouble compute_time = 0; // 表示這個算子實際的運行時間size_t ref_cnt() {return outputs.size() - std::count(outputs.begin(), outputs.end(), nullptr);}// 對應 CheckpointTensorImpl.h 里的 Tensors CheckpointTensorImpl::makestatic ComputePath* make(std::shared_ptr<OpDef> op, SmallVector<TensorInfo*> inputs, SmallVector<TensorInfo*> outputs) {auto* path = new TensorInfo::ComputePath();path->op = op;path->inputs = inputs;path->outputs = outputs;// dedupSmallVector<TensorInfo*> unique_inputs = inputs;std::sort(unique_inputs.begin(), unique_inputs.end());unique_inputs.erase(std::unique(unique_inputs.begin(), unique_inputs.end()), unique_inputs.end());path->unique_inputs = unique_inputs;// attach usersfor (auto input: unique_inputs) {input->users.push_back(path);}// attach producerfor (auto output: outputs) {output->producer = path;}// update ref_cntfor (auto input: inputs) {input->ref_cnt += outputs.size();}return path;}}* producer = nullptr; // 每個 tensor 都會有一個 producer,如果 producer 是空,就表示它是由外部數據加載進來的,否則它是一個計算路徑。// 改進的估價函數。對應 CheckpointTensorImpl.h 里的 struct CheckpointInfo → double cost(size_t memory, size_t staleness)double eval_func(double cost, double free_mem, double cur_time,double param_cost, double param_mem, double param_time, double param_recompute_times) {return pow(cost + 1e-3, param_cost) * pow(param_recompute_times, (double)recompute_times)/ (pow((memory + free_mem) / 1024.0 / 1024.0, param_mem) * pow((double)(cur_time - last_used_time + 1e-3), param_time));}void pin() { // 對應 CheckpointTensorImpl.h 里的 struct AliasPool → void lock()++pinned;}void unpin() { // 對應 CheckpointTensorImpl.h 里的 struct AliasPool → void unlock()--pinned;}void detach_producer() { // 斷開當前 TensorInfo 對象與其 producer(ComputePath對象)的連接if (!producer) {return;}auto output = std::find(producer->outputs.begin(), producer->outputs.end(), this);mgb_assert(output != producer->outputs.end());*output = nullptr;if (producer->ref_cnt() == 0) {for (auto* input: producer->unique_inputs) {input->users.erase(std::find(input->users.begin(), input->users.end(), producer));}delete producer;}producer = nullptr;}bool size_exceeds_thd(size_t thd) { // 檢查內存大小是否超過閾值return memory > thd;}SmallVector<ComputePath*> users; // 存儲的是所有依賴該 tensor 作為輸入的計算路徑
};
對using TensorInfoPtr = std::shared_ptr<TensorInfo>;的理解:
std::shared_ptr是一個模板類,它接受一個模板參數,這里是TensorInfo,表示這個智能指針將管理TensorInfo類型的動態對象。std::shared_ptr通過引用計數機制來管理內存。當一個shared_ptr被復制時,它所指向的對象的引用計數會增加;當shared_ptr超出作用域被銷毀時,引用計數會減少。當引用計數降到0時,shared_ptr會自動釋放它所管理的內存。- 這里的
TensorInfoPtr是一個類型別名,它指向std::shared_ptr<TensorInfo>。這意味著TensorInfoPtr是一個指向TensorInfo對象的共享指針類型。當使用TensorInfoPtr來聲明一個變量時,這個變量將是一個智能指針,它指向一個TensorInfo對象。
imperative/src/impl/interpreter/interpreter_impl.h
代碼地址:MegEngine/imperative/src/impl/interpreter/interpreter_impl.h at release-1.4 · MegEngine/MegEngine
/*!* \brief A framework of dynamic sublienar memory optimization 動態次線內存優化框架** Note: The main idea is that during the training process, if the memory usage exceeds the threshold, select some tensors to evict until the memory usage is below the threshold.* 注意:主要思想是在訓練過程中,如果內存使用量超過閾值,則選擇一些張量進行驅逐,直到內存使用量低于閾值。*/struct DynamicSublinear {/*!* \brief find an available tensor with the largest evaluation function 找到具有最大評估函數的可用張量** Note: An available tensor must satisfy: (1) has computing path, (2) is in memory, (3) is not pinned. Evaluation function refers to:* 注意:可用的張量必須滿足:(1)具有計算路徑,(2)在內存中,(3)未固定。* 評價函數是指:TensorInfo::eval_func.** \return the pointer of the best tensor; nullptr is returned if no available tensor is found 最佳張量的指針;如果沒有找到可用的張量,則返回 nullptr*/TensorInfo* find_best_tensor();/*!* \brief estimate the cost of recomputing tensor ptr 估計重新計算張量 ptr 的成本** Note: We define the cost as the sum of the costs of each evicted components where all the neighbors of ptr are located.* 注意:我們將成本定義為 ptr 的所有鄰居所在的每個被驅逐組件的成本之和。*/double estimate_neighbor_cost(TensorInfo* ptr);/*!* \brief update the last used time of the tensor ptr 更新張量 ptr 的最后使用時間*/void update_used_time(TensorInfo* ptr);/*!* \brief merge the two specified sets (the set in which the element x is located, and the set in which the element y is located)* 合并兩個指定的集合(元素x所在的集合,和元素y所在的集合)*/void merge(std::shared_ptr<DsuNode> &x, std::shared_ptr<DsuNode> &y);/*!* \brief return the representative of the set that contains the element x 返回包含元素 x 的集合的代表*/std::shared_ptr<DsuNode> find_father(std::shared_ptr<DsuNode> &x);/*!* \brief update DSU after recomputing tensor ptr 重新計算張量 ptr 后更新 DSU** Delete ptr from the set where ptr is located. * 從ptr所在集合中刪除ptr。* Since DSU does not support this operation, instead, we reset the DSU father of ptr, and subtract the recomputation cost of ptr from the cost of the original set.* 由于DSU不支持此操作,因此我們重置ptr的DSU父親,并從原始集合的成本中減去ptr的重新計算成本。*/void update_dsu_after_recompute(TensorInfo* ptr);/*!* \brief update DSU after evicting tensor ptr 驅逐張量 ptr 后更新 DSU** Check the neighbors of x, that is, the input and output tensors, and if they are evicted, merge their respective sets.* 檢查 x 的鄰居,即輸入和輸出張量,如果它們被驅逐,則合并它們各自的集合。*/void update_dsu_after_evict(TensorInfo* ptr);/*!* \brief pin the tensors in vec 將張量固定在 vec 中*/void pin(const SmallVector<TensorInfo*>& vec);/*!* \brief unpin the tensors in vec 取消固定 vec 中的張量*/void unpin(const SmallVector<TensorInfo*>& vec);/*!* \brief add the tensor to the candidate set 將張量添加到候選集中** If the size of the tensor does not exceed the minimum threshold, it will do nothing.* 如果張量的大小沒有超過最小閾值,則不會執行任何操作。*/void insert_candidate(TensorInfo* ptr);/*!* \brief erase the tensor from the candidate set 從候選集中刪除張量** If the size of the tensor does not exceed the minimum threshold, it will do nothing.* 如果張量的大小沒有超過最小閾值,則不會執行任何操作。*/void erase_candidate(TensorInfo* ptr);//! estimate the current time, in order to reduce the overhead of timer// 估計當前時間,以減少定時器的開銷double estimate_timestamp = 0;//! the comp node where dynamic sublinear memory optimization works// 動態亞線性內存優化工作的 comp 節點CompNode comp_node;//! store all tensors that may be evicted // 存儲所有可能被驅逐的張量std::unordered_set<TensorInfo*> candidates;//! whether the warning message has been printed 是否打印警告信息bool warn_printed = false;bool is_bad_op(std::string op_name) {return std::find(op_blacklist.begin(), op_blacklist.end(), op_name) != op_blacklist.end();}std::vector<std::string> op_blacklist = {"CollectiveComm", "InplaceAdd","ParamPackSplit", "ParamPackConcat", "GaussianRNG"};} m_dtr;//! automatically evict an optimal tensor 自動驅逐最佳張量void auto_evict();
imperative/src/impl/interpreter/interpreter_impl.cpp
代碼地址:MegEngine/imperative/src/impl/interpreter/interpreter_impl.cpp at release-1.4 · MegEngine/MegEngine
分配
/*** 被以下函數調用 * - Handle ChannelImpl::put* - void ChannelImpl::dispatch_kernel* * ★ 重要函數:分配一個新的 TensorInfo 對象,并將其加入到有效的處理列表中。*/
TensorInfo* ChannelImpl::alloc() {MGB_LOCK_GUARD(m_mutex);auto info = m_pool.alloc();m_valid_handle.insert(info);info->id = m_last_id++;if (m_channel_state.profiler->is_profiling()) {m_channel_state.profiler->record_host<TensorDeclareEvent>(info->id);}return info;
}
刪除
當一個 tensor 不會再被用戶和框架使用時,這個 tensor 就可以被刪除,從而釋放其占用的顯存。MegEngine 通過引用計數來控制 tensor 的刪除,當引用計數變為 0 的時候,這個 tensor 就會自動發一個刪除的語句給解釋器。這樣帶來的問題是,如果真的把這個 tensor 刪除的話,它確實可以立即節省顯存,但會讓整體的策略變得非常局限。
比如下面這張圖是某張計算圖的子圖,可以看到一個 9MB 的 tensor 經過一個卷積算子,得到了一個 25MB 的 tensor,再經過一個 Elemwise 算子,得到一個 25MB 的 tensor,再經過 BatchNorm 算子和 Elemwise 算子,得到的都是 25MB 的 tensor。

注意到,由于這里的 Elemwise 算子都是加法,所以它的輸入(兩個紅色的 tensor)在求導的時候都不會被用到。因此,求導器不需要保留住兩個紅色的 tensor,在前向計算完之后它們實際上是會被立即釋放掉的。這樣的好處是可以立即節省顯存,但在引入 DTR 技術之后,如果真的刪掉了這兩個紅色的 tensor,就會導致圖中綠色的 tensor 永遠不可能被釋放,因為它們的計算源(紅色 tensor)已經丟失了,一旦釋放綠色的 tensor 就再也恢復不出來了。解決方案是在前向的過程中用釋放來代替刪除,也就是“假刪除”——保留 tensorInfo,只是釋放掉 tensorInfo 下面對應的顯存。這樣只需要保留 9MB 的 tensor 就可以釋放掉后面 4 個 25MB 的 tensor,并且可以在將來的任意時刻恢復出它們。

上圖就是 MegEngine 中對 tensor 的刪除的偽代碼實現,
在解釋器收到 Del 指令時,會對 tensorInfo 調用 Free()函數,根據當前的狀態是否是前向計算來決定做真刪除還是假刪除。
- 假刪除的實現很簡單,打上刪除標記,釋放掉 tensorInfo 管理的顯存即可;
- 真刪除的實現比較復雜,
- 首先更新產生該 tensor 的輸入 tensor 的 ref_cnt,
- 然后調用 RemoveDep()檢查所有依賴該 tensor 作為輸入的 tensor,如果它們不在顯存中,必須現在調用 Regenerate 恢復出它們,因為一旦當前 tensor 被真刪除,這些 tensor 就恢復不出來了。
- 做完了上述操作之后,就可以真正釋放掉該 tensor 對應的 tensorInfo 了。釋放完還需要遞歸地檢查 x 的計算歷史輸入 tensor,如果這些 tensor 中有 ref_cnt=0 且被打上刪除標記的,就可以執行真刪除。
/*** 被 void ChannelImpl::process_one_task 調用 * * ★ 重要函數*/
void ChannelImpl::free(TensorInfo* ptr) { // 在解釋器收到 Del 指令時,會對 tensorInfo 調用 Free()函數if (m_worker_state.options.enable_dtr_auto_drop) {// Evicting a tensor, rather than freeing it, can avoid pinning potentially exploding amounts of memory and allow us to save more memory.// 驅逐張量而不是釋放它可以避免固定可能爆炸的內存量,并允許我們節省更多內存。ptr->allow_delete = true;// 如果引用計數(ref_cnt)為零,則遞歸地釋放 tensor(recursive_free),否則執行假刪除(do_drop)。if (!ptr->ref_cnt) {recursive_free(ptr);} else {do_drop(ptr);}} else {real_free(ptr);}
}/*** 被以下函數調用* - void ChannelImpl::free* - void ChannelImpl::auto_evict* - void ChannelImpl::process_one_task* * ★ 重要函數*/
void ChannelImpl::do_drop(TensorInfo* ptr, bool user=false) { // 假刪除的實現很簡單,打上刪除標記,保留 tensorInfo,釋放掉 tensorInfo 管理的顯存if (!ptr->producer) {if (user) { // 生成張量 ptr 的輸入已被刪除,此刪除操作將被忽略mgb_log_warn("the input that produced tensor %p has been deleted, this drop operation will be ignored", ptr);}return;}if (ptr->evict_type != EvictType::NONE) {return;}ptr->evict_type = EvictType::DROP; // 打上刪除標記release_tensor(ptr); // 釋放掉 tensorInfo 管理的顯存
}/*** 被以下函數調用* - void ChannelImpl::do_drop* - void ChannelImpl::process_one_task* * ★ 重要函數*/
void ChannelImpl::release_tensor(TensorInfo* dest) { // 釋放掉 tensorInfo 管理的顯存MGB_LOCK_GUARD(m_mutex);dest->ptr.reset(); // 通過重置 ptr 來釋放與之關聯的 Tensor 對象
}/*** 被 void ChannelImpl::free 調用* * ★ 重要函數*/
void ChannelImpl::recursive_free(TensorInfo* ptr) { SmallVector<TensorInfo*> inps(0);if (ptr->producer) {for (auto i : ptr->producer->inputs) {if (i && --i->ref_cnt == 0) { // 更新產生該 tensor 的輸入 tensor 的 ref_cntinps.push_back(i); // 如果引用計數降至零,則將這些輸入加入到遞歸釋放的列表中。}}}real_free(ptr); // 真正釋放掉該 tensor 對應的 tensorInfo// 釋放完還需要遞歸地檢查 x 的計算歷史輸入 tensor,如果這些 tensor 中有 ref_cnt=0 且被打上刪除標記的,就可以執行真刪除。for (auto i : inps) {if (i->allow_delete) {recursive_free(i);}}
}/*** 被以下函數調用* - void ChannelImpl::free* - void ChannelImpl::recursive_free* * ★ 重要函數*/
void ChannelImpl::real_free(TensorInfo* ptr) { MGB_LOCK_GUARD(m_mutex);if (m_channel_state.profiler->is_profiling()) {m_channel_state.profiler->record_host<TensorEraseEvent>(ptr->id);}if (ptr->size_exceeds_thd(m_worker_state.options.dtr_evictee_minimum_size)) {m_dtr.erase_candidate(ptr);}detach_users(ptr);ptr->detach_producer();m_pool.free(ptr);
}/*** 被 void ChannelImpl::real_free 調用* * ★ 重要函數*/
void ChannelImpl::detach_users(TensorInfo* dest) {SmallVector<TensorInfo::ComputePath*> users = dest->users;for (auto* user: users) { // 檢查所有依賴該 tensor 作為輸入的 tensorSmallVector<TensorInfo*> outputs = user->outputs;SmallVector<TensorInfo*> inputs = user->inputs;for (auto* output: outputs) {if (output == nullptr) {continue;}regenerate(output); // 如果它們不在顯存中,必須現在調用 Regenerate 恢復出它們,因為一旦當前 tensor 被真刪除,這些 tensor 就恢復不出來了。output->detach_producer();for (auto* input: inputs) {input->ref_cnt --;}}}mgb_assert(dest->users.size() == 0);//dest->users.clear();
}
核心實現
/*** 被以下函數調用* - void ChannelImpl::regenerate* - void ChannelImpl::recompute* - void ChannelImpl::process_one_task* * ★ 重要函數:創建一個新的張量,并將其與 TensorInfo 結構關聯起來。對應 void CheckpointTensorCell::fill* * @param dest: 指向 TensorInfo 結構的指針,它將被用來存儲有關新張量的信息。* @param ptr: 一個 TensorPtr,表示一個智能指針,指向新創建的 Tensor 對象。*/
void ChannelImpl::produce_tensor(TensorInfo* dest, TensorPtr ptr, bool notice=true) {auto lock = notice ? std::unique_lock<std::mutex>(m_mutex): std::unique_lock<std::mutex>();m_dtr.update_used_time(dest);if (notice && m_worker_state.profiler->is_profiling()) {m_worker_state.profiler->record_host<TensorProduceEvent>(dest->id, ptr->layout(), ptr->comp_node());}dest->value_fetched = ptr->value_fetched();// update tensor desc for static infer 更新靜態推斷的張量 descdest->desc.layout = ptr->layout();dest->desc.comp_node = ptr->comp_node();dest->memory = ptr->blob()->size();dest->ptr = std::move(ptr);dest->evict_type = EvictType::NONE;// 如果 notice 為 true 并且張量大小超過了某個閾值,則將該張量作為候選加入到動態內存優化的數據結構中。if (notice && dest->size_exceeds_thd(m_worker_state.options.dtr_evictee_minimum_size)) {m_dtr.insert_candidate(dest);}if (notice && m_waitee == dest) {m_cv.notify_all();}
}/** * 被以下函數調用* - void ChannelImpl::recompute* - void ChannelImpl::detach_users* - void ChannelImpl::process_one_task* * ★ 重要函數*/
void ChannelImpl::regenerate(TensorInfo* dest) {if (dest->evict_type == EvictType::DROP) { // 重新計算recompute(dest->producer);} else if (dest->evict_type == EvictType::SWAP) { // 從主機值創建張量produce_tensor(dest, Tensor::make(dest->h_value));}
}/*** 被 void ChannelImpl::regenerate 調用* * ★ 重要函數*/
void ChannelImpl::recompute(TensorInfo::ComputePath* path) {SmallVector<TensorPtr> inputs;inputs.reserve(path->inputs.size());m_dtr.pin(path->inputs);for (auto i : path->inputs) {if (!i->ptr) {regenerate(i); // 在 regenerate inputs 張量時,可能會 OOM}inputs.push_back(i->ptr);m_dtr.update_used_time(i); // 這里更新一下 update_used_time 合理嗎?// 如果一個張量在當前的計算路徑中被用作輸入,那么它的使用時間應該被更新為當前時間,這樣在內存緊張時,那些更久未使用的張量將更有可能被逐出。}if (m_worker_state.options.enable_dtr_auto_drop && m_worker_state.options.dtr_eviction_threshold > 0) {auto_evict();}auto outputs = OpDef::apply_on_physical_tensor(*path->op, inputs);m_dtr.estimate_timestamp += path->compute_time / 1e8;m_dtr.unpin(path->inputs);for (size_t i = 0;i < outputs.size();i ++) {auto&& o = path->outputs[i];if (o) {o->recompute_times ++; // 重計算次數if (!o->ptr) { // 如果輸出張量的 ptr 為空(即之前被逐出了),則使用 produce_tensor 函數重新創建它。produce_tensor(o, std::move(outputs[i]), false);if (m_worker_state.options.enable_dtr_auto_drop) {m_dtr.update_dsu_after_recompute(o);}}}}
}/*** 被以下函數調用* - void ChannelImpl::recompute* - void ChannelImpl::process_one_task* * ★ 重要函數*/
void ChannelImpl::auto_evict() {if (!m_dtr.comp_node.valid()) {return;}size_t current_memory = m_dtr.comp_node.get_used_memory();while (current_memory > m_worker_state.options.dtr_eviction_threshold) {auto best = m_dtr.find_best_tensor();if (!best) {if (!m_dtr.warn_printed) {m_dtr.warn_printed = true;mgb_log_warn("No tensors on %s can be evicted automatically ""when memory usage is %.0lfMB. Maybe memory ""budget is too small.",m_dtr.comp_node.to_string().c_str(),current_memory / 1024.0 / 1024.0); // 確實,內存預算太小的話,可能找不到 best_tensor}break;}if (best->ptr.unique() && best->ptr->blob().unique()) {current_memory -= best->memory;}do_drop(best);if (best->evict_type == EvictType::DROP) {m_dtr.update_dsu_after_evict(best);}}
}/*** 被 void ChannelImpl::auto_evict() 調用* * ★ 重要函數*/
TensorInfo* ChannelImpl::DynamicSublinear::find_best_tensor() {double min_msps = -1;TensorInfo* best = nullptr;for (auto i : candidates) {if (i->producer && i->ptr && !i->pinned && i->evict_type == EvictType::NONE) {double neighbor_cost = estimate_neighbor_cost(i);// 引入了一些碎片相關的信息,希望換出的 tensor 除了自己占用的顯存越大越好之外,還希望它在顯存中兩端的空閑顯存塊大小之和越大越好。size_t begin_ptr = reinterpret_cast<size_t>(i->ptr->blob()->storage().get());auto side_info = i->ptr->comp_node().get_free_left_and_right(begin_ptr, begin_ptr + i->ptr->blob()->size());double free_mem = side_info.first + side_info.second;double msps = i->eval_func(neighbor_cost, free_mem, estimate_timestamp, 1.0, 1.0, 1.0, 1.0001);if (min_msps < 0 || msps < min_msps) {min_msps = msps;best = i;}}}return best;
}
輔助函數
/*** 被以下函數調用* - void ChannelImpl::recompute* - void ChannelImpl::process_one_task* * ★ 重要函數*/
void ChannelImpl::DynamicSublinear::pin(const SmallVector<TensorInfo*>& vec) {for (auto i : vec) {i->pin();}
}/*** 被以下函數調用* - void ChannelImpl::recompute* - void ChannelImpl::process_one_task* * ★ 重要函數*/
void ChannelImpl::DynamicSublinear::unpin(const SmallVector<TensorInfo*>& vec) {for (auto i : vec) {i->unpin();}
}/** * 被 void ChannelImpl::recompute 調用* * ★ 重要函數:更新并查集(Disjoint Set Union,DSU)數據結構*/
void ChannelImpl::DynamicSublinear::update_dsu_after_recompute(TensorInfo* ptr) {auto&& dsu_fa = find_father(ptr->dsu_ptr);dsu_fa->t -= ptr->compute_time;ptr->dsu_ptr->parent.reset();ptr->dsu_ptr->t = ptr->compute_time;
}/*** 被 void ChannelImpl::auto_evict() 調用* * ★ 重要函數:更新并查集(Disjoint Set Union,DSU)數據結構*/
void ChannelImpl::DynamicSublinear::update_dsu_after_evict(TensorInfo* ptr) {for (auto i : ptr->producer->inputs) {if (i->evict_type == EvictType::DROP) {merge(i->dsu_ptr, ptr->dsu_ptr);}}for (auto i : ptr->producer->outputs) {if (i && i->evict_type == EvictType::DROP) {merge(ptr->dsu_ptr, i->dsu_ptr);}}
}/*** 被 TensorInfo* ChannelImpl::DynamicSublinear::find_best_tensor 調用* * ★ 重要函數*/
double ChannelImpl::DynamicSublinear::estimate_neighbor_cost(TensorInfo* ptr) {double cost = 0;for (auto i : ptr->producer->inputs) {if (i->evict_type == EvictType::DROP) {double t = find_father(i->dsu_ptr)->t;if (t < i->compute_time) {t = i->compute_time;}cost += t;}}for (auto i : ptr->producer->outputs) {if (i && i->evict_type == EvictType::DROP) {double t = find_father(i->dsu_ptr)->t;if (t < i->compute_time) {t = i->compute_time;}cost += t;}}return cost;
}/*** 被 void ChannelImpl::DynamicSublinear::update_dsu_after_evict 調用* * ★ 重要函數*/
void ChannelImpl::DynamicSublinear::merge(std::shared_ptr<DsuNode> &x, std::shared_ptr<DsuNode> &y) {auto&& f_x = find_father(x);auto&& f_y = find_father(y);if (f_x.get() == f_y.get()) {return;}f_y->t += f_x->t;f_x->parent = f_y;
}/*** 被以下函數調用* - void ChannelImpl::DynamicSublinear::update_dsu_after_recompute* - double ChannelImpl::DynamicSublinear::estimate_neighbor_cost* - void ChannelImpl::DynamicSublinear::merge* * ★ 重要函數*/
std::shared_ptr<DsuNode> ChannelImpl::DynamicSublinear::find_father(std::shared_ptr<DsuNode>& x) {if (x->is_root()) {return x;} else {auto&& fa = find_father(x->parent);return x->parent = fa;}
}/*** 被 void ChannelImpl::produce_tensor 調用* * ★ 重要函數*/
void ChannelImpl::DynamicSublinear::insert_candidate(TensorInfo* ptr) {candidates.insert(ptr);if (!comp_node.valid()) {comp_node = ptr->ptr->comp_node();}
}/*** 被 void ChannelImpl::real_free 調用* * ★ 重要函數*/
void ChannelImpl::DynamicSublinear::erase_candidate(TensorInfo* ptr) {candidates.erase(ptr);
}/** * 被以下函數調用* - void ChannelImpl::produce_tensor* - void ChannelImpl::recompute* - void ChannelImpl::process_one_task* * ★ 重要函數
*/
void ChannelImpl::DynamicSublinear::update_used_time(TensorInfo* ptr) {ptr->last_used_time = estimate_timestamp;
}
啟發式公式
( cost + 1 0 ? 3 ) param_cost ? ( param_recompute_times ) recompute_times ( memory + free_mem 1024.0 × 1024.0 ) param_mem ? ( cur_time ? last_used_time + 1 0 ? 3 ) param_time \frac{\left( \text{cost} + 10^{-3} \right)^{\text{param\_cost}} \cdot \left( \text{param\_recompute\_times} \right)^{\text{recompute\_times}}}{\left( \frac{\text{memory} + \text{free\_mem}}{1024.0 \times 1024.0} \right)^{\text{param\_mem}} \cdot \left( \text{cur\_time} - \text{last\_used\_time} + 10^{-3} \right)^{\text{param\_time}}} (1024.0×1024.0memory+free_mem?)param_mem?(cur_time?last_used_time+10?3)param_time(cost+10?3)param_cost?(param_recompute_times)recompute_times?
對于函數中的四個屬性,增設了一些超參數,這樣我們可以通過改變這些超參數來使啟發式策略側重于不同的屬性。
重計算次數
我們引入了重計算次數這一懲罰系數,希望每個算子被重算的次數盡量均勻。
void ChannelImpl::recompute(TensorInfo::ComputePath* path) {SmallVector<TensorPtr> inputs;inputs.reserve(path->inputs.size());m_dtr.pin(path->inputs);for (auto i : path->inputs) {if (!i->ptr) {regenerate(i); // 在 regenerate inputs 張量時,可能會 OOM}inputs.push_back(i->ptr);m_dtr.update_used_time(i); // 這里更新一下 update_used_time 合理嗎?// 如果一個張量在當前的計算路徑中被用作輸入,那么它的使用時間應該被更新為當前時間,這樣在內存緊張時,那些更久未使用的張量將更有可能被逐出。}if (m_worker_state.options.enable_dtr_auto_drop && m_worker_state.options.dtr_eviction_threshold > 0) {auto_evict();}auto outputs = OpDef::apply_on_physical_tensor(*path->op, inputs);m_dtr.estimate_timestamp += path->compute_time / 1e8;m_dtr.unpin(path->inputs);for (size_t i = 0;i < outputs.size();i ++) {auto&& o = path->outputs[i];if (o) {o->recompute_times ++; // 重計算次數if (!o->ptr) { // 如果輸出張量的 ptr 為空(即之前被逐出了),則使用 produce_tensor 函數重新創建它。produce_tensor(o, std::move(outputs[i]), false);if (m_worker_state.options.enable_dtr_auto_drop) {m_dtr.update_dsu_after_recompute(o);}}}}
}
空閑顯存塊大小
獲取顯存碎片相關信息的過程是通過計算一個張量在其內存塊兩側的空閑內存量來實現的。這種方法可以幫助確定逐出操作后可能獲得的內存整理效果。
TensorInfo* ChannelImpl::DynamicSublinear::find_best_tensor() {double min_msps = -1;TensorInfo* best = nullptr;for (auto i : candidates) {if (i->producer && i->ptr && !i->pinned && i->evict_type == EvictType::NONE) {double neighbor_cost = estimate_neighbor_cost(i);// 獲取 TensorInfo 對象所關聯的張量數據的內存地址,并將這個地址以 size_t 類型的數值形式存儲在變量 begin_ptr 中。size_t begin_ptr = reinterpret_cast<size_t>(i->ptr->blob()->storage().get());// 調用計算節點(comp_node)的 get_free_left_and_right 方法,傳入張量的起始地址和結束地址(起始地址加上大小)。// 返回一個包含兩部分空閑內存的 side_info:// - side_info.first:張量左側的空閑內存量。// - side_info.second:張量右側的空閑內存量。auto side_info = i->ptr->comp_node().get_free_left_and_right(begin_ptr, begin_ptr + i->ptr->blob()->size());// 將兩側的空閑內存量相加,得到張量兩側的總空閑內存量 free_mem。double free_mem = side_info.first + side_info.second;double msps = i->eval_func(neighbor_cost, free_mem, estimate_timestamp, 1.0, 1.0, 1.0, 1.0001);if (min_msps < 0 || msps < min_msps) {min_msps = msps;best = i;}}}return best;
}
參考資料
- MegEngine 1.13.2 文檔
- MegEngine 架構設計 — MegEngine 1.13.2 文檔
- Imperative Runtime — MegEngine 1.13.2 文檔
- MegEngine Python 層 Tensor 行為 — MegEngine 1.13.2 文檔
- 使用 DTR 進行顯存優化 — MegEngine 1.13.2 文檔
- MegEngine/MegEngine: MegEngine 是一個快速、可拓展、易于使用且支持自動求導的深度學習框架
- 國產開源深度學習框架,深度學習,簡單開發-曠視天元MegEngine
- MegEngine 架構系列:靜態內存分析







)
實現指南)








)

