文章目錄
- 1.關聯式容器
- 2.set
- 2.1 find
- 2.2 lower_bound、upper_bound
- 3.multiset
- 3.1 count
- 3.2 equal_range
- 4.map
- 4.1 insert
- 4.2 operate->
- 4.3 operate[ ]
- 4.4 map的應用實踐:隨機鏈表的復制
- 5.multimap
- 希望讀者們多多三連支持
- 小編會繼續更新
- 你們的鼓勵就是我前進的動力!
迄今為止,除了二叉搜索樹以外的結構,我們學習到的順序表,鏈表,棧和隊列等都屬于這些容器統稱為序列式容器,因為其底層為線性序列的數據結構,里面存儲的是元素本身
1.關聯式容器
根據應用場景的不同,
STL總共實現了兩種不同結構的管理式容器:樹型結構與哈希結構。樹型結構的關聯式容器主要有四種:map、set、multimap、multiset。這四種容器的共同點是:使用平衡搜索樹(即紅黑樹)作為其底層結果,容器中的元素是一個有序的序列
關聯式容器也是用來存儲數據的,與序列式容器不同的是,其里面存儲的是<key, value>結構的鍵值對,在數據檢索時比序列式容器效率更高
鍵對值中的 key 表示鍵值,value 表示與 key 對應的信息
SGI-STL中關于鍵值對的定義:
template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair() : first(T1()), second(T2()){}pair(const T1& a, const T2& b) : first(a), second(b){}
};
2.set

set 的主要特征可總結為:
set是按照一定次序存儲元素的容器- 在
set中,元素的value也標識它(value就是key,類型為T),并且每個value必須是唯一的set中的元素不能在容器中修改(元素總是const),但是可以從容器中插入或刪除它們 - 在內部,
set中的元素總是按照其內部比較對象(類型比較)所指示的特定嚴格弱排序準則進行排序 set容器通過key訪問單個元素的速度通常比unordered_set容器慢,但它們允許根據順序對子集進行直接迭代set在底層是用二叉搜索樹(紅黑樹)實現的
🔥值得注意的是:
- 與
map/multimap不同,map/multimap中存儲的是真正的鍵值對<key, value>,set中只放value,但在底層實際存放的是由<value, value>構成的鍵值對(后面底層的博客會解釋) set中插入元素時,只需要插入value即可,不需要構造鍵值對set中的元素不可以重復(因此可以使用set進行去重)。- 使用
set的迭代器遍歷set中的元素,可以得到有序序列 set中的元素默認按照小于來比較,即1、2、3…的順序set中查找某個元素,時間復雜度為: l o g 2 n log_2 n log2?nset中的元素不允許修改set中的底層使用二叉搜索樹(紅黑樹)來實現
2.1 find

由于 set 的基本功能,像 insert、erase、迭代器等都和 string、vector 等差不多,這里就不過多解釋,詳細的可以自行查看官方文檔,本文將針對部分特殊的函數進行解析
find 簡單來說,就是尋找特定的鍵值,那么可以提出一個問題:
set<int> s;
s.insert(3);
s.insert(2);
s.insert(4);
s.insert(5);
s.insert(1);
s.insert(5);
s.insert(2)
s.insert(5);auto pos = s.find(3);//第一種
auto pos = find(s.begin(), s.end(), 3);//第二種
s.erase(3);
哪一種 find 方式能更好的刪除?顯然是第一種
因為第一種是 set 里面的 find,會以平衡二叉搜索樹的方式去查找,大的往左走,小的往右走,時間復雜度為 O(logN);第二種是 algorithm(算法頭文件)中的 find,是以依次遍歷的方式,即中序遍歷的方式進行的,時間復雜度為 O(N)
2.2 lower_bound、upper_bound
set<int> myset;
set<int>::iterator itlow, itup;for (int i = 1; i < 10; i++) myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90itlow = myset.lower_bound(30); // ^
itup = myset.upper_bound(65); // ^myset.erase(itlow, itup); // 10 20 70 80 90cout << "myset contains:";
for (set<int>::iterator it = myset.begin(); it != myset.end(); ++it)cout << ' ' << *it;
cout << '\n';
因為迭代器的區間遵循左閉右開原則,所以 lower_bound 用于查找第一個大于等于給定值 val 的元素位置,upper_bound 用于查找第一個大于給定值 val 的元素位置
3.multiset

multiset 的主要特征可總結為:
multiset是按照特定順序存儲元素的容器,其中元素是可以重復的- 在
multiset中,元素的value也會識別它(因為multiset中本身存儲的就是<value, value>組成的鍵值對,因此value本身就是key,key就是value,類型為T),multiset元素的值不能在容器中進行修改(因為元素總是const的),但可以從容器中插入或刪除 - 在內部,
multiset中的元素總是按照其內部比較規則(類型比較)所指示的特定嚴格弱排序準則進行排序 multiset容器通過key訪問單個元素的速度通常比unordered_multiset容器慢,但當使用迭代器遍歷時會得到一個有序序列multiset底層結構為二叉搜索樹(紅黑樹)
🔥值得注意的是:
multiset中再底層中存儲的是<value, value>的鍵值對multiset的插入接口中只需要插入即可- 與
set的區別是,multiset中的元素可以重復,set是中value是唯一的 - 使用迭代器對
multiset中的元素進行遍歷,可以得到有序的序列 multiset中的元素不能修改- 在
multiset中找某個元素,時間復雜度為 O ( l o g 2 N ) O(log_2 N) O(log2?N) multiset的作用:可以對元素進行排序
3.1 count

multiset 同樣是這幾個,但是 count 和 equal_range 可以說是專門給 multiset 打造的,雖然 set 里也可以用,但是沒什么意義
count 用于統計容器中某個值出現的次數
3.2 equal_range
set<int> mySet = {1, 2, 3, 3, 4, 5};
auto result = mySet.equal_range(3);for (auto it = result.first; it != result.second; ++it)
{cout << *it << " ";
}
cout << endl;
equal_range 用于查找重復元素之間的區間,返回一個 pair 對象,該對象包含兩個迭代器:
- 第一個迭代器指向
multiset中第一個等于value的元素(如果存在),或者指向第一個大于value的元素(如果不存在等于 value 的元素) - 第二個迭代器指向
set中最后一個等于value的元素的下一個位置(如果存在等于value的元素),或者與第一個迭代器相等(如果不存在等于value的元素)
4.map

map的主要特征可總結為:
map是關聯容器,它按照特定的次序(按照key來比較)存儲由鍵值key和值value組合而成的元素- 在
map中,鍵值key通常用于排序和唯一地標識元素,而值value中存儲與此鍵值key關聯的內容。鍵值key和值value的類型可能不同,并且在map的內部,key與value通過成員類型value_type綁定在一起,為其取別名稱為pair : typedef pair<const key, T>value_type - 在內部,
map中的元素總是按照鍵值key進行比較排序的 map中通過鍵值訪問單個元素的速度通常比unordered_map容器慢,但map允許根據順序對元素進行直接迭代(即對map中的元素進行迭代時,可以得到一個有序的序列)map支持下標訪問符,即在[]中放入key,就可以找到與key對應的valuemap通常被實現為二叉搜索樹(更準確的說:平衡二叉搜索樹(紅黑樹))
由于 map 的基本功能,像 insert、erase、迭代器等都和 string、vector 等差不多,這里就不過多解釋,詳細的可以自行查看官方文檔,本文將針對部分函數進行解析
4.1 insert
map 中的 insert 插入的是一個 pair 結構對象,下面將列舉多種插入方式:
🚩創建普通對象插入
pair<string, string> kv1("insert", "插入");
dict.insert(kv1);
🚩創建匿名對象插入
dict.insert(pair<string, string>("sort", "排序"));
🚩調用make_pair函數插入
dict.insert(make_pair("string", "字符串"));
調用 make_pair 省去了聲明類型的過程
🚩隱式類型轉換插入
dict.insert({ "string","字符串" });
通常 C++98 只支持單參數隱式類型轉換,到 C++11 的時候就開始支持多參數隱式類型轉換
有這么一個問題:為什么加上了引用反而要加const
pair<string, string> kv2 = { "insert", "插入" };
const pair<string, string>& kv2 = { "insert", "插入" };
無引用情況: 對于 pair<string, string> kv2 = { "string", "字符串" }; ,編譯器可能會執行拷貝省略(也叫返回值優化 RVO 或命名返回值優化 NRVO )。比如在創建 kv2 時,直接在其存儲位置構造對象,而不是先創建一個臨時對象再拷貝 / 移動過去
加引用情況: 使用 const pair<string, string>& kv2 = { "string", "字符串" }; 時,這里 kv2 是引用,它綁定到一個臨時對象(由大括號初始化列表創建 )。因為引用本身不持有對象,只是給對象取別名,所以不存在像非引用對象構造時那種在自身存儲位置直接構造的情況。不過,這種引用綁定臨時對象的方式,只要臨時對象的生命周期延長到與引用一樣長(C++ 規則規定,常量左值引用綁定臨時對象時,臨時對象生命周期延長 ),也不會額外增加拷貝 / 移動開銷
4.2 operate->
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{//it->first = "xxx";//it->second = "xxx";//cout << (*it).first << ":" << (*it).second << endl;cout << it->first << ":" << it->second << endl;++it;
}
cout << endl;
map 中并沒有對 pair 進行流插入運算符重載,(*it).first 這樣子的方式又不太簡潔不好看,所以進行了 -> 運算符重載,返回的是 first 的地址,因此 (*it).first 等價于 it->->first,為了代碼可讀性,就省略一個 ->
4.3 operate[ ]
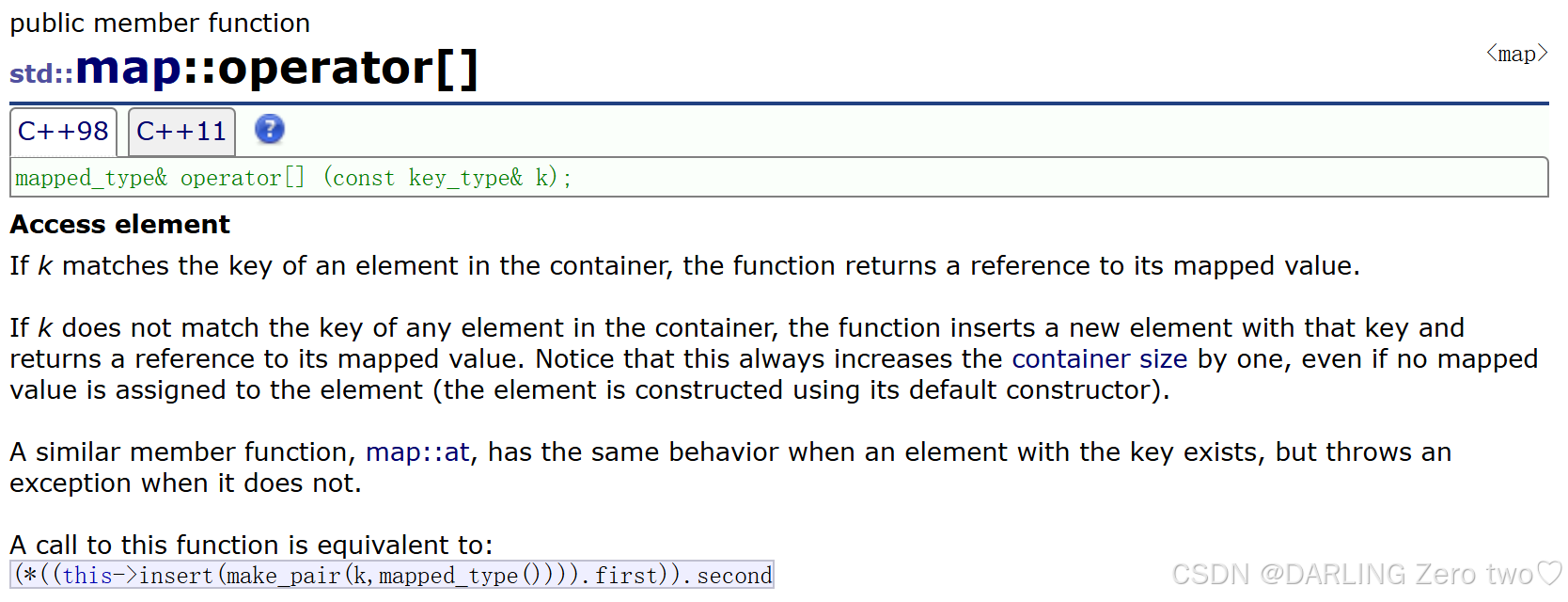
map 中提供了 [] 運算符重載,可以通過 key 來訪問 value

首先我們知道 insert 的返回值 key 的部分是一個迭代器,value 的部分是個布爾值,文檔中對該返回值的解釋是:
key已經在樹里面,返回pair<樹里面key所在節點的iterator,false>,false表示不用插入了key不在樹里面,返回pair<樹里面key所在節點的iterator,true>,true表示需要插入新節點

再來看,左邊是官方文檔的原始定義,那么轉化成右邊的定義能夠更直觀理解其底層
這里 V 代表值類型,K 代表鍵類型 。operator[] 是操作符重載函數,接受一個常量引用類型的鍵 key ,返回值類型 V 的引用。這樣設計是為了支持對容器內元素的讀寫操作。例如,可以通過 map[key] = newValue; 來修改值,或者通過 auto value = map[key]; 來讀取值
然后通過 insert 判斷是否插入新節點,最后返回指定節點的 value 值
4.4 map的應用實踐:隨機鏈表的復制
??題目描述:

??示例:
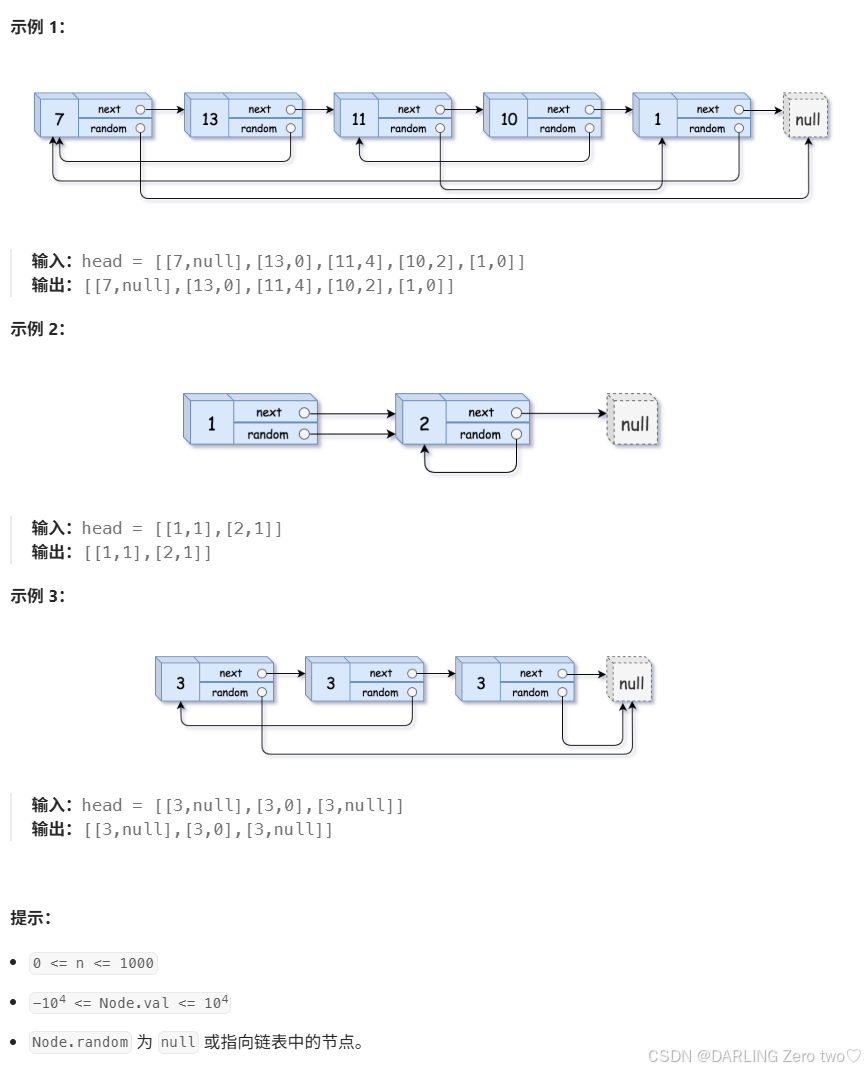
傳送門: 隨機鏈表的復制
題解:
利用 map 的映射機制,首先,在第一次遍歷原鏈表時,為原鏈表的每個節點創建一個對應的新節點,并將原節點和新節點的映射關系存儲在 map 中。然后,在第二次遍歷原鏈表時,對于原鏈表中的每個節點 cur,我們可以通過 cur->random 找到其隨機指針指向的原節點,再利用之前存儲的映射關系,在 map 中查找該原節點對應的新節點,將這個新節點賦值給當前新節點 copynode 的隨機指針 copynode->random
🔥值得注意的是:
記錄的不是cur和newnode的關系嗎,為什么可以通過cur->random找到newnode->random?
假設原鏈表有三個節點
A、B、C,節點A的隨機指針指向節點C
建立映射階段: 會為A、B、C分別創建對應的新節點A'、B'、C',并在nodeCopyMap中記錄映射關系:{A->A',B->B',C->C'}。
設置隨機指針階段: 當處理節點A時,cur指向A,cur->random指向C。由于C作為鍵存在于nodeCopyMap中,通過nodeCopyMap[cur->random]也就是nodeCopyMap[C]可以找到C',接著把C'賦值給A'的隨機指針A'->random,這樣新鏈表中節點A'的隨機指針就正確地指向了節點C',和原鏈表中節點A的隨機指針指向C相對應
💻代碼實現:
class Solution {
public:Node* copyRandomList(Node* head) {map<Node*, Node*> nodeCopyMap;Node* copyhead = nullptr;Node* copytail = nullptr;Node* cur = head;while (cur){Node* copynode = new Node(cur->val);if (copytail == nullptr){copyhead = copytail = copynode;}else{copytail->next = copynode;copytail = copynode;}nodeCopyMap[cur] = copynode;cur = cur->next;}Node* copy = copyhead;cur = head;while (cur){if (cur->random == nullptr){copy->random = nullptr;}else{copy->random = nodeCopyMap[cur->random];}cur = cur->next;copy = copy->next;}return copyhead;}
};
5.multimap
multimap的主要特征可總結為:
multimaps是關聯式容器,它按照特定的順序,存儲由key和value映射成的鍵值對<key, value>,其中多個鍵值對之間的key是可以重復的。- 在
multimap中,通常按照key排序和惟一地標識元素,而映射的value存儲與key關聯的內容。key和value的類型可能不同,通過multimap內部的成員類型value_type組合在一起,value_type是組合key和value的鍵值對:typedef pair<const Key, T> value_type; - 在內部,
multimap中的元素總是通過其內部比較對象,按照指定的特定嚴格弱排序標準對key進行排序的。 multimap通過key訪問單個元素的速度通常比unordered_multimap容器慢,但是使用迭代器直接遍歷multimap中的元素可以得到關于key有序的序列multimap在底層用二叉搜索樹(紅黑樹)來實現
注意:multimap 和 map 的唯一不同就是:map 中的 key 是唯一的,而 multimap 中key 是可以重復的
🔥值得注意的是:
multimap中的key是可以重復的multimap中的元素默認將key按照小于來比較multimap中沒有重載operator[]操作,因為一個key對應多個value,不知道找哪個value- 使用時與
map包含的頭文件相同
multimap 和 mutiset 是差不多的,而且在實際應用中用的不多,所以這里就不細講了
希望讀者們多多三連支持
小編會繼續更新
你們的鼓勵就是我前進的動力!





)
實現指南)








)




