1. 源碼環境搭建
1.1 主要功能模塊
? RocketMQ的官方Git倉庫地址:GitHub - apache/rocketmq: Apache RocketMQ is a cloud native messaging and streaming platform, making it simple to build event-driven applications.
? RocketMQ的官方網站上下載指定版本的源碼: http://rocketmq.apache.org/dowloading/releases/
源碼下很多的功能模塊,很容易讓人迷失方向,我們只關注下幾個最為重要的模塊:
-
broker: Broker 模塊(broke 啟動進程)
-
client :消息客戶端,包含消息生產者、消息消費者相關類
-
example: RocketMQ 例代碼
-
namesrv:NameServer模塊
-
store:消息存儲模塊
-
remoting:遠程訪問模塊
1.2 源碼啟動服務
? 將源碼導入IDEA后,需要先對源碼進行編譯。編譯指令 clean install -Dmaven.test.skip=true
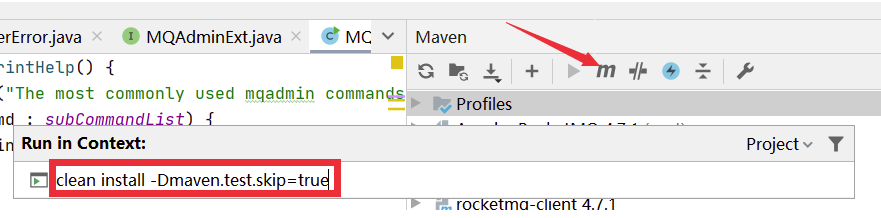
編譯完成后就可以開始調試代碼了。調試時需要按照以下步驟:
? 調試時,先在項目目錄下創建一個conf目錄,并從distribution拷貝broker.conf和logback_broker.xml和logback_namesrv.xml

2.1 啟動nameServer
? 展開namesrv模塊,運行NamesrvStartup類即可啟動NameServer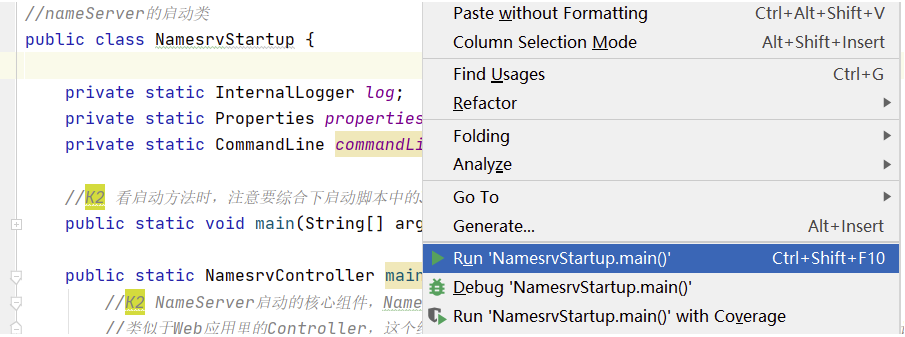
啟動時,會報錯,提示需要配置一個ROCKETMQ_HOME環境變量。這個環境變量我們可以在機器上配置,跟配置JAVA_HOME環境變量一樣。也可以在IDEA的運行環境中配置。目錄指向源碼目錄即可。
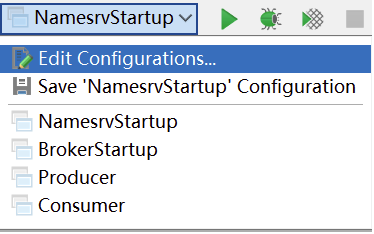
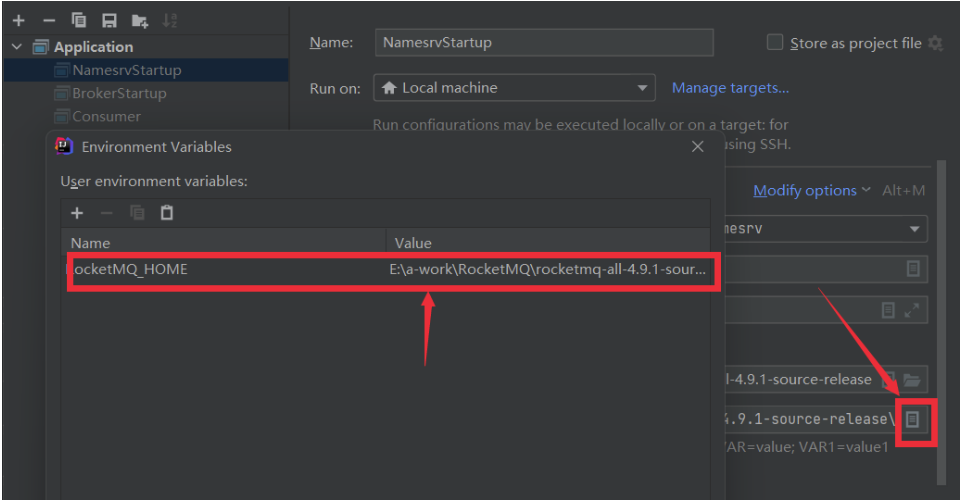
配置完成后,再次執行,看到以下日志內容,表示NameServer啟動成功
The Name Server boot success. serializeType=JSON2.2 啟動Broker
啟動Broker之前,我們需要先修改之前復制的broker.conf文件
brokerClusterName = DefaultCluster
brokerName = broker-a
brokerId = 0
deleteWhen = 04
fileReservedTime = 48
brokerRole = ASYNC_MASTER
flushDiskType = ASYNC_FLUSH# 自動創建Topic
autoCreateTopicEnable=true
# nameServ地址
namesrvAddr=127.0.0.1:9876
# 存儲路徑
storePathRootDir=D:\\RocketMQ\\data\\rocketmq\\dataDir
# commitLog路徑
storePathCommitLog=D:\\RocketMQ\\data\\rocketmq\\dataDir\\commitlog
# 消息隊列存儲路徑
storePathConsumeQueue=D:\\RocketMQ\\data\\rocketmq\\dataDir\\consumequeue
# 消息索引存儲路徑
storePathIndex=D:\\RocketMQ\\data\\rocketmq\\dataDir\\index
# checkpoint文件路徑
storeCheckpoint=D:\\RocketMQ\\data\\rocketmq\\dataDir\\checkpoint
# abort文件存儲路徑
abortFile=D:\\RocketMQ\\data\\rocketmq\\dataDir\\abort然后Broker的啟動類是broker模塊下的BrokerStartup。
啟動Broker時,同樣需要ROCETMQ_HOME環境變量,并且還需要配置一個-c 參數,指向broker.conf配置文件。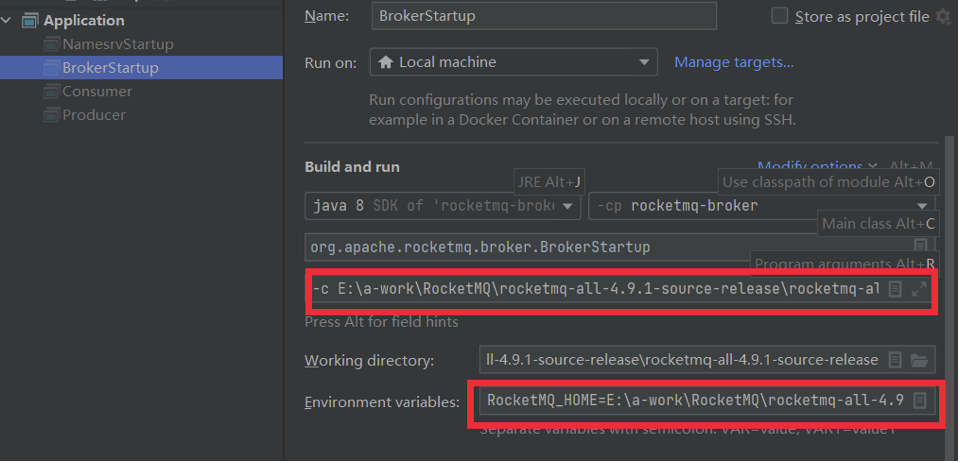
然后重新啟動,即可啟動Broker。
2.3 發送消息
在源碼的example模塊下,提供了非常詳細的測試代碼。例如我們啟動example模塊下的org.apache.rocketmq.example.quickstart.Producer類即可發送消息。
但是在測試源碼中,需要指定NameServer地址。這個NameServer地址有兩種指定方式,一種是配置一個NAMESRV_ADDR的環境變量。另一種是在源碼中指定。我們可以在源碼中加一行代碼指定NameServer
producer.setNamesrvAddr("127.0.0.1:9876");然后就可以發送消息了。
2.4 消費消息
我們可以使用同一模塊下的org.apache.rocketmq.example.quickstart.Consumer類來消費消息。運行時同樣需要指定NameServer地址
consumer.setNamesrvAddr("192.168.232.128:9876");這樣整個調試環境就搭建好了。
1.3 讀源碼的方法
? 1、帶著問題讀源碼。如果沒有自己的思考,源碼不如不讀!!!
? 2、小步快走。不要覺得一兩遍就能讀懂源碼。這里我會分為三個階段來帶你逐步加深對源碼的理解。
? 3、分步總結。帶上自己的理解,及時總結。對各種擴展功能,嘗試驗證。對于RocketMQ,試著去理解源碼中的各種單元測試。
2. 源碼概識階段
? 梳理一些重要的服務端核心配置,找到一點點讀源碼的感覺。
2.1 NameServer的啟動過程
1、關注重點
? 在RocketMQ集群中,消息存儲、推送等核心功能點額是Broker。而NameServer的作用,其實和微服務中的注冊中心非常類似,他只是提供了Broker端的服務注冊與發現功能。
? 第一次看源碼,不要太過陷入具體的細節,先搞清楚NameServer的大體結構。
2、源碼重點
? NameServer的啟動入口類是org.apache.rocketmq.namesrv.NamesrvStartup。其中的核心是構建并啟動一個NamesrvController。這個Cotroller對象就跟MVC中的Controller是很類似的,都是響應客戶端的請求。只不過,他響應的是基于Netty的客戶端請求。
? 另外,他的實際啟動過程,其實可以配合NameServer的啟動腳本進行更深入的理解。
? 從NameServer啟動和關閉這兩個關鍵步驟,我們可以總結出NameServer的組件其實并不是很多,整個NameServer的結構是這樣的;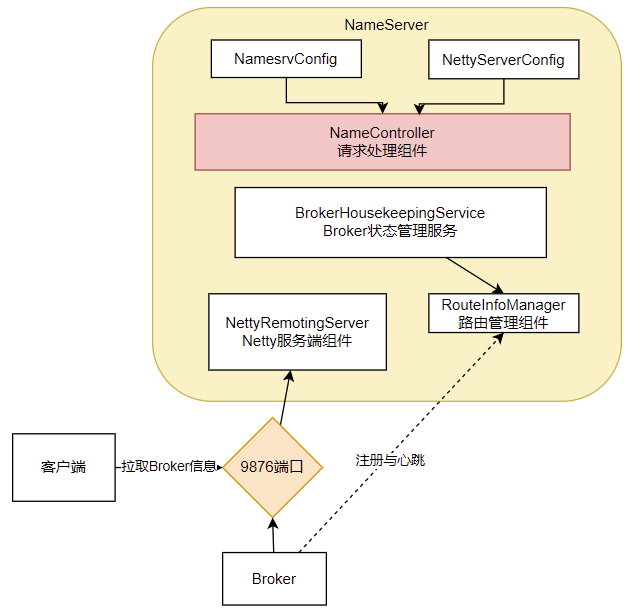
這兩個配置類就可以用來指導如何優化Nameserver的配置。比如,如何調整nameserver的端口?自己試試從源碼中找找答案。
? 從這里也能看出, RocketMQ的整體源碼風格就是典型的MVC思想。Controller響應請求,Service處理業務,各種Table保存消息。
2.2 Broker服務啟動過程
1、關注重點
? Broker是整個RocketMQ的業務核心。所有消息存儲、轉發這些重要的業務都是Broker進行處理。
? 這里重點梳理Broker有哪些內部服務。這些內部服務將是整理Broker核心業務流程的起點。
2、源碼重點
Broker啟動的入口在BrokerStartup這個類,可以從他的main方法開始調試。
啟動過程關鍵點:重點也是圍繞一個BrokerController對象,先創建,然后再啟動。
首先: 在BrokerStartup.createBrokerController方法中可以看到Broker的幾個核心配置:
-
BrokerConfig : Broker服務配置
-
MessageStoreConfig : 消息存儲配置。 這兩個配置參數都可以在broker.conf文件中進行配置
-
NettyServerConfig :Netty服務端占用了10911端口。同樣也可以在配置文件中覆蓋。
-
NettyClientConfig : Broker既要作為Netty服務端,向客戶端提供核心業務能力,又要作為Netty客戶端,向NameServer注冊心跳。
這些配置是我們了解如何優化 RocketMQ 使用的關鍵。
然后: 在BrokerController.start方法可以看到啟動了一大堆Broker的核心服務,我們挑一些重要的
this.messageStore.start();//啟動核心的消息存儲組件this.remotingServer.start();
this.fastRemotingServer.start(); //啟動兩個Netty服務this.brokerOuterAPI.start();//啟動客戶端,往外發請求BrokerController.this.registerBrokerAll: //向NameServer注冊心跳。this.brokerStatsManager.start();
this.brokerFastFailure.start();//這也是一些負責具體業務的功能組件我們現在不需要了解這些核心組件的具體功能,只要有個大概,Broker中有一大堆的功能組件負責具體的業務。后面等到分析具體業務時再去深入每個服務的細節。
我們需要抽象出Broker的一個整體結構: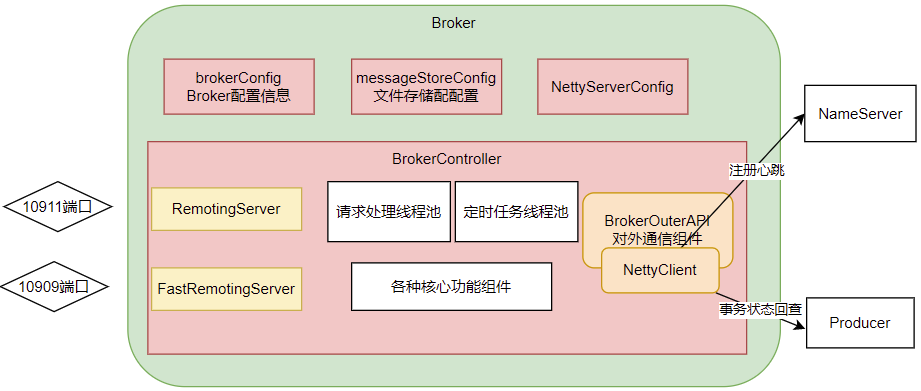
? 可以看到Broker啟動了兩個Netty服務,他們的功能基本差不多。實際上,在應用中,可以通過producer.setSendMessageWithVIPChannel(true),讓少量比較重要的producer走VIP的通道。而在消費者端,也可以通過consumer.setVipChannelEnabled(true),讓消費者支持VIP通道的數據。
3. 源碼入門階段
? 開始理解一些比較簡單的業務邏輯
3.1 Netty服務注冊框架
1、關注重點
?? ?網絡通信服務是構建分布式應用的基礎,也是我們去理解RocketMQ底層業務的基礎。這里就重點梳理RocketMQ的這個服務注冊框架,理解各個業務進程之間是如何進行RPC遠程通信的。
?? ?Netty的所有遠程通信功能都由remoting模塊實現。RemotingServer模塊里包含了RPC的服務端RemotingServer以及客戶端RemotingClient。在RocketMQ中,涉及到的遠程服務非常多,在RocketMQ中,NameServer主要是RPC的服務端RemotingServer,Broker對于客戶端來說,是RPC的服務端RemotingServer,而對于NameServer來說,又是RPC的客戶端。各種Client是RPC的客戶端RemotingClient。
?? ?需要理解的是,RocketMQ基于Netty保持客戶端與服務端的長連接Channel。只要Channel是穩定的,那么即可以從客戶端發請求到服務端,同樣服務端也可以發請求到客戶端。例如在事務消息場景中,就需要Broker多次主動向Producer發送請求確認事務的狀態。所以,RemotingServer和RemotingClient都需要注冊自己的服務。
2、源碼重點
? 1、哪些組件需要Netty服務端?哪些組件需要Netty客戶端? 比較好理解的,NameServer需要NettyServer。客戶端,Producer和Consuer,需要NettyClient。Broker需要NettyServer響應客戶端請求,需要NettyClient向NameServer注冊心跳。但是有個問題, 事務消息的Producer也需要響應Broker的事務狀態回查,他需要NettyServer嗎?
NameServer不需要NettyClient,這也驗證了之前介紹的NameServer之間不需要進行數據同步的說法。
? 2、所有的RPC請求數據都封裝成RemotingCommand對象。而每個處理消息的服務邏輯,都會封裝成一個NettyRequestProcessor對象。
? 3、服務端和客戶端都維護一個processorTable,這是個HashMap。key是服務碼requestCode,value是對應的運行單元 Pair<NettyRequestProcessor,ExecutorService>類型,包含了處理Processor和執行線程的線程池。具體的Processor,由業務系統自行注冊。
Broker服務注冊見,BrokerController.registerProcessor(),
客戶端的服務注冊見MQClientAPIImpl。
NameServer則會注冊一個大的DefaultRequestProcessor,統一處理所有服務。
? 4、請求類型分為REQUEST和RESPONSE。這是為了支持異步的RPC調用。NettyServer處理完請求后,可以先緩存到responseTable中,等NettyClient下次來獲取,這樣就不用阻塞Channel了,可以提升請求吞吐量。猜一猜Producer的同步請求的流程是什么樣的?
? 5、重點理解remoting包中是如何實現全流程異步化。
整體RPC框架流程如下圖: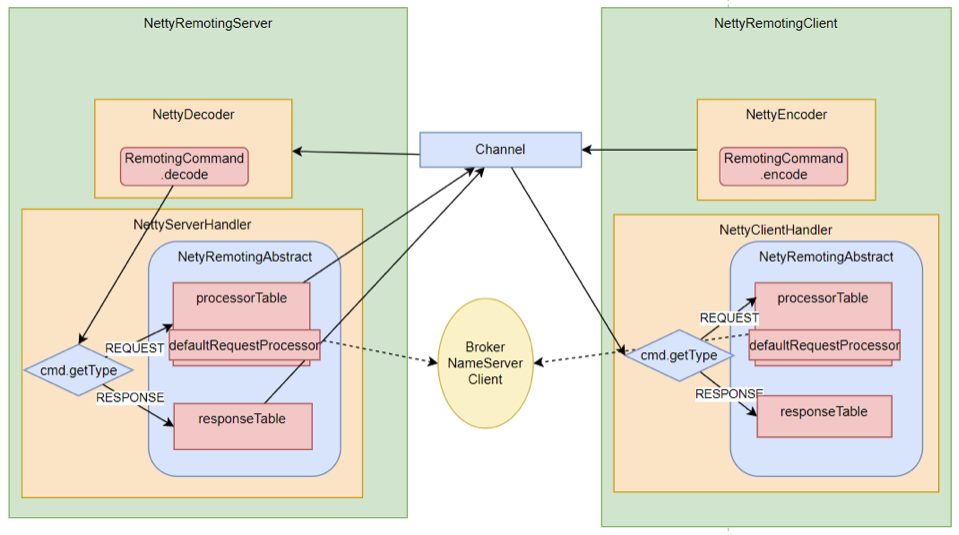
? RocketMQ使用Netty框架提供了一套基于服務碼的服務注冊機制,讓各種不同的組件都可以按照自己的需求,注冊自己的服務方法。RocketMQ的這一套服務注冊機制,是非常簡潔使用的。在使用Netty進行其他相關應用開發時,都可以借鑒他的這一套服務注冊機制。例如要開發一個大型的IM項目,要加減好友、發送文本,圖片,甚至紅包、維護群聊信息等等各種各樣的請求,這些請求如何封裝,就可以很好的參考這個框架。
3、關于RocketMQ的同步結果推送與異步結果推送
?? ?RocketMQ的RemotingServer服務端,會維護一個responseTable,這是一個線程同步的Map結構。 key為請求的ID,value是異步的消息結果。ConcurrentMap<Integer /* opaque */, ResponseFuture> 。
?? ?處理同步請求(NettyRemotingAbstract#invokeSyncImpl)時,處理的結果會存入responseTable,通過ResponseFuture提供一定的服務端異步處理支持,提升服務端的吞吐量。 請求返回后,立即從responseTable中移除請求記錄。
? 實際上,同步也是通過異步實現的。
//org.apache.rocketmq.remoting.netty.ResponseFuture//發送消息后,通過countDownLatch阻塞當前線程,造成同步等待的效果。public RemotingCommand waitResponse(final long timeoutMillis) throws InterruptedException {this.countDownLatch.await(timeoutMillis, TimeUnit.MILLISECONDS);return this.responseCommand;}//等待異步獲取到消息后,再通過countDownLatch釋放當前線程。public void putResponse(final RemotingCommand responseCommand) {this.responseCommand = responseCommand;this.countDownLatch.countDown();}? 處理異步請求(NettyRemotingAbstract#invokeAsyncImpl)時,處理的結果依然會存入responsTable,等待客戶端后續再來請求結果。但是他保存的依然是一個ResponseFuture,也就是在客戶端請求結果時再去獲取真正的結果。 另外,在RemotingServer啟動時,會啟動一個定時的線程任務,不斷掃描responseTable,將其中過期的response清除掉。
//org.apache.rocketmq.remoting.netty.NettyRemotingServer
this.timer.scheduleAtFixedRate(new TimerTask() {@Overridepublic void run() {try {NettyRemotingServer.this.scanResponseTable();} catch (Throwable e) {log.error("scanResponseTable exception", e);}}}, 1000 * 3, 1000);3.2 Broker心跳注冊管理
1、關注重點
?? 之前介紹過,Broker會在啟動時向所有NameServer注冊自己的服務信息,并且會定時往NameServer發送心跳信息。而NameServer會維護Broker的路由列表,并對路由表進行實時更新。這一輪就重點梳理這個過程。
2、源碼重點
?? Broker啟動后會立即發起向NameServer注冊心跳。方法入口:BrokerController.this.registerBrokerAll。 然后啟動一個定時任務,以10秒延遲,默認30秒的間隔持續向NameServer發送心跳。
? NameServer內部會通過RouteInfoManager組件及時維護Broker信息。同時在NameServer啟動時,會啟動定時任務,掃描不活動的Broker。方法入口:NamesrvController.initialize方法。
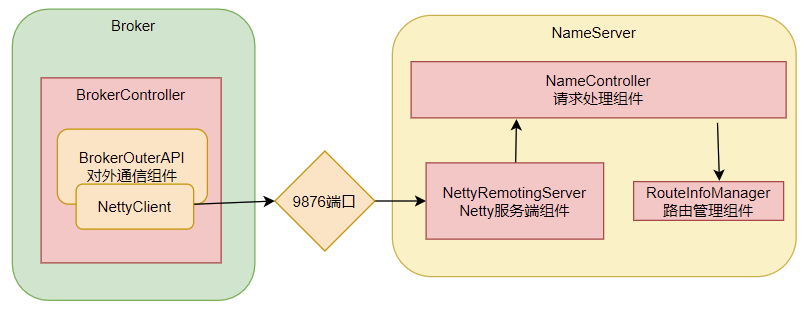
3、極簡化的服務注冊發現流程
? 為什么RocketMQ要自己實現一個NameServer,而不用Zookeeper、Nacos這樣現成的注冊中心?
? 首先,依賴外部組件會對產品的獨立性形成侵入,不利于自己的版本演進。Kafka要拋棄Zookeeper就是一個先例。
? 另外,其實更重要的還是對業務的合理設計。NameServer之間不進行信息同步,而是依賴Broker端向所有NameServer同時發起注冊。這讓NameServer的服務可以非常輕量。如果可能,你可以與Nacos或Zookeeper的核心流程做下對比。
? 但是,要知道,這種極簡的設計,其實是以犧牲數據一致性為代價的。Broker往多個NameServer同時發起注冊,有可能部分NameServer注冊成功,而部分NameServer注冊失敗了。這樣,多個NameServer之間的數據是不一致的。作為注冊中心,這是不可接受的。但是對于RocketMQ,這又變得可以接受了。因為客戶端從NameServer上獲得的,只要有一個正常運行的Broker就可以了,并不需要完整的Broker列表。
3.3 Producer發送消息過程
1、關注重點
首先:回顧下我們之前的Producer使用案例。
Producer有兩種:
-
一種是普通發送者:DefaultMQProducer。只負責發送消息,發送完消息,就可以停止了。
-
另一種是事務消息發送者: TransactionMQProducer。支持事務消息機制。需要在事務消息過程中提供事務狀態確認的服務,這就要求事務消息發送者雖然是一個客戶端,但是也要完成整個事務消息的確認機制后才能退出。
? 事務消息機制后面將結合Broker進行整理分析。這一步暫不關注。我們只關注DefaultMQProducer的消息發送過程。
然后:整個Producer的使用流程,大致分為兩個步驟:
一是調用start方法,進行一大堆的準備工作。
二是各種send方法,進行消息發送。
? 那我們重點關注以下幾個問題:
1、Producer啟動過程中啟動了哪些服務
2、Producer如何管理broker路由信息。 可以設想一下,如果Producer啟動了之后,NameServer掛了,那么Producer還能不能發送消息?希望你先從源碼中進行猜想,然后自己設計實驗進行驗證。
3、關于Producer的負載均衡。也就是Producer到底將消息發到哪個MessageQueue中。這里可以結合順序消息機制來理解一下。消息中那個莫名奇妙的MessageSelector到底是如何工作的。
2、源碼重點
1、Producer的核心啟動流程
?? ?所有Producer的啟動過程,最終都會調用到DefaultMQProducerImpl#start方法。在start方法中的通過一個mQClientFactory對象,啟動生產者的一大堆重要服務。
?? ?這里其實就是一種設計模式,雖然有很多種不同的客戶端,但是這些客戶端的啟動流程最終都是統一的,全是交由mQClientFactory對象來啟動。而不同之處在于這些客戶端在啟動過程中,按照服務端的要求注冊不同的信息。例如生產者注冊到producerTable,消費者注冊到consumerTable,管理控制端注冊到adminExtTable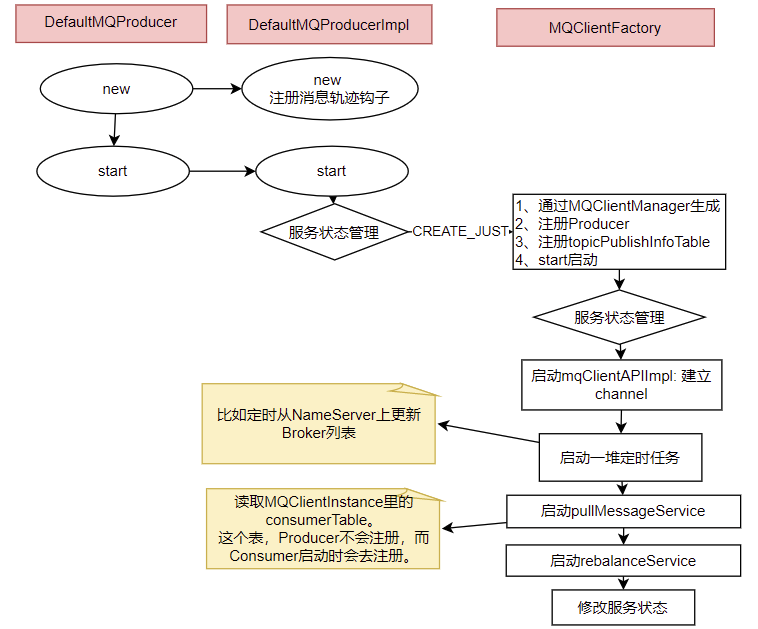
2、發送消息的核心流程
? 核心流程如下: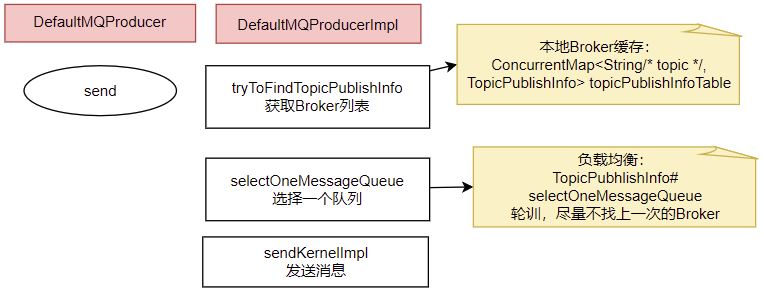
? 1、發送消息時,會維護一個本地的topicPublishInfoTable緩存,DefaultMQProducer會盡量保證這個緩存數據是最新的。但是,如果NameServer掛了,那么DefaultMQProducer還是會基于這個本地緩存去找Broker。只要能找到Broker,還是可以正常發送消息到Broker的。 --可以在生產者示例中,start后打一個斷點,然后把NameServer停掉,這時,Producer還是可以發送消息的。
? 2、生產者如何找MessageQueue: 默認情況下,生產者是按照輪詢的方式,依次輪詢各個MessageQueue。但是如果某一次往一個Broker發送請求失敗后,下一次就會跳過這個Broker。
//org.apache.rocketmq.client.impl.producer.TopicPublishInfo//如果進到這里lastBrokerName不為空,那么表示上一次向這個Broker發送消息是失敗的,這時就盡量不要再往這個Broker發送消息了。public MessageQueue selectOneMessageQueue(final String lastBrokerName) {if (lastBrokerName == null) {return selectOneMessageQueue();} else {for (int i = 0; i < this.messageQueueList.size(); i++) {int index = this.sendWhichQueue.incrementAndGet();int pos = Math.abs(index) % this.messageQueueList.size();if (pos < 0)pos = 0;MessageQueue mq = this.messageQueueList.get(pos);if (!mq.getBrokerName().equals(lastBrokerName)) {return mq;}}return selectOneMessageQueue();}}? 3、如果在發送消息時傳了Selector,那么Producer就不會走這個負載均衡的邏輯,而是會使用Selector去尋找一個隊列。 具體參見org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl#sendSelectImpl 方法。
3.4 Consumer拉取消息過程
1、關注重點
-
消費者也是有兩種,推模式消費者和拉模式消費者。優秀的MQ產品都會有一個高級的目標,就是要提升整個消息處理的性能。而要提升性能,服務端的優化手段往往不夠直接,最為直接的優化手段就是對消費者進行優化。所以在RocketMQ中,整個消費者的業務邏輯是非常復雜的,甚至某種程度上來說,比服務端更復雜,所以,在這里我們重點關注用得最多的推模式的消費者。
-
消費者組之間有集群模式和廣播模式兩種消費模式。我們就要了解下這兩種集群模式是如何做的邏輯封裝。
-
然后我們關注下消費者端的負載均衡的原理。即消費者是如何綁定消費隊列的,哪些消費策略到底是如何落地的。
-
最后我們來關注下在推模式的消費者中,MessageListenerConcurrently 和MessageListenerOrderly這兩種消息監聽器的處理邏輯到底有什么不同,為什么后者能保持消息順序。
2、源碼重點
? Consumer的核心啟動過程和Producer是一樣的, 最終都是通過mQClientFactory對象啟動。不過之間添加了一些注冊信息。整體的啟動過程如下:
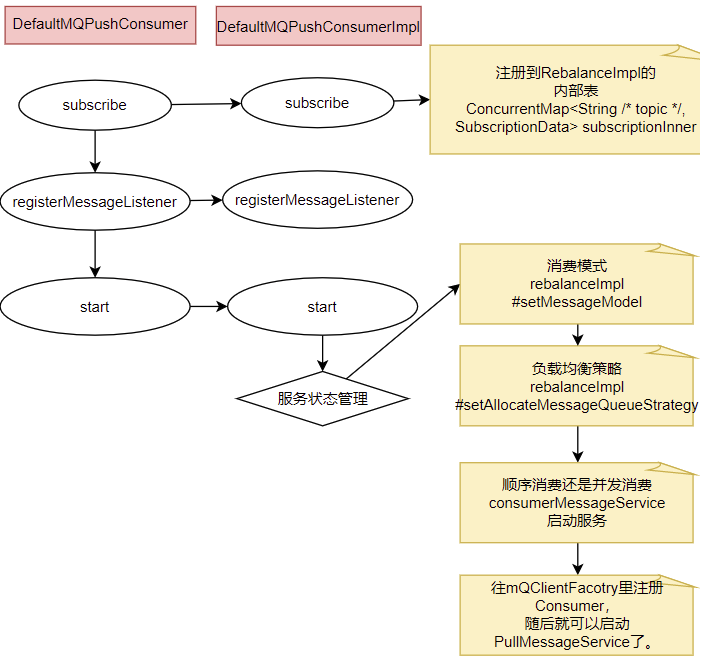
3、廣播模式與集群模式的Offset處理
? 在DefaultMQPushConsumerImpl的start方法中,啟動了非常多的核心服務。 比如,對于廣播模式與集群模式的Offset處理
if (this.defaultMQPushConsumer.getOffsetStore() != null) {this.offsetStore = this.defaultMQPushConsumer.getOffsetStore();} else {switch (this.defaultMQPushConsumer.getMessageModel()) {case BROADCASTING:this.offsetStore = new LocalFileOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());break;case CLUSTERING:this.offsetStore = new RemoteBrokerOffsetStore(this.mQClientFactory, this.defaultMQPushConsumer.getConsumerGroup());break;default:break;}this.defaultMQPushConsumer.setOffsetStore(this.offsetStore);}this.offsetStore.load();?? ?可以看到,廣播模式是使用LocalFileOffsetStore,在Consumer本地保存Offset,而集群模式是使用RemoteBrokerOffsetStore,在Broker端遠程保存offset。而這兩種Offset的存儲方式,最終都是通過維護本地的offsetTable緩存來管理Offset。
4、Consumer與MessageQueue建立綁定關系
? start方法中還一個比較重要的東西是給rebalanceImpl設定了一個AllocateMessageQueueStrategy,用來給Consumer分配MessageQueue的。
this.rebalanceImpl.setMessageModel(this.defaultMQPushConsumer.getMessageModel());
//Consumer負載均衡策略
this.rebalanceImpl.setAllocateMessageQueueStrategy(this.defaultMQPushConsumer.getAllocateMessageQueueStrategy());?? ?這個AllocateMessageQueueStrategy就是用來給Consumer和MessageQueue之間建立一種對應關系的。也就是說,只要Topic當中的MessageQueue以及同一個ConsumerGroup中的Consumer實例都沒有變動,那么某一個Consumer實例只是消費固定的一個或多個MessageQueue上的消息,其他Consumer不會來搶這個Consumer對應的MessageQueue。
?? ?關于負載均衡機制,會在后面結合Producer的發送消息策略一起總結。不過這里,你可以想一下為什么要讓一個MessageQueue只能由同一個ConsumerGroup中的一個Consumer實例來消費。
?? ?其實原因很簡單,因為Broker需要按照ConsumerGroup管理每個MessageQueue上的Offset,如果一個MessageQueue上有多個同屬一個ConsumerGroup的Consumer實例,他們的處理進度就會不一樣。這樣的話,Offset就亂套了。
5、順序消費與并發消費
? 同樣在start方法中,啟動了consumerMessageService線程,進行消息拉取。
//Consumer中自行指定的回調函數。if (this.getMessageListenerInner() instanceof MessageListenerOrderly) {this.consumeOrderly = true;this.consumeMessageService =new ConsumeMessageOrderlyService(this, (MessageListenerOrderly) this.getMessageListenerInner());} else if (this.getMessageListenerInner() instanceof MessageListenerConcurrently) {this.consumeOrderly = false;this.consumeMessageService =new ConsumeMessageConcurrentlyService(this, (MessageListenerConcurrently) this.getMessageListenerInner());}? 可以看到, Consumer通過registerMessageListener方法指定的回調函數,都被封裝成了ConsumerMessageService的子實現類。
? 而對于這兩個服務實現類的調用,會延續到DefaultMQPushConsumerImpl的pullCallback對象中。也就是Consumer每拉過來一批消息后,就向Broker提交下一個拉取消息的的請求。
這里也可以印證一個點,就是順序消息,只對異步消費也就是推模式有效。同步消費的拉模式是無法進行順序消費的。因為這個pullCallback對象,在拉模式的同步消費時,根本就沒有往下傳。
當然,這并不是說拉模式不能鎖定隊列進行順序消費,拉模式在Consumer端應用就可以指定從哪個隊列上拿消息。
PullCallback pullCallback = new PullCallback() {@Overridepublic void onSuccess(PullResult pullResult) {if (pullResult != null) {//...switch (pullResult.getPullStatus()) {case FOUND://...DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(pullResult.getMsgFoundList(),processQueue,pullRequest.getMessageQueue(),dispatchToConsume);//... break;//...}}}?? ?而這里提交的,實際上是一個ConsumeRequest線程。而提交的這個ConsumeRequest線程,在兩個不同的ConsumerService中有不同的實現。
? 這其中,兩者最為核心的區別在于ConsumerMessageOrderlyService是鎖定了一個隊列,處理完了之后,再消費下一個隊列。
public void run() {// ....final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);synchronized (objLock) {//....}}? 為什么給隊列加個鎖,就能保證順序消費呢?結合順序消息的實現機制理解一下。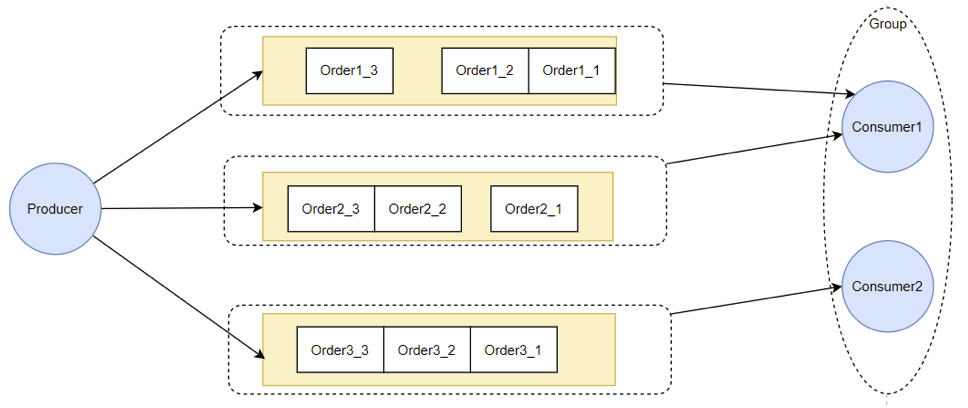
? 從源碼中可以看到,Consumer提交請求時,都是往線程池里異步提交的請求。如果不加隊列鎖,那么就算Consumer提交針對同一個MessageQueue的拉取消息請求,這些請求都是異步執行,他們的返回順序是亂的,無法進行控制。給隊列加個鎖之后,就保證了針對同一個隊列的第二個請求,必須等第一個請求處理完了之后,釋放了鎖,才可以提交。這也是在異步情況下保證順序的基礎思路。
6、實際拉取消息還是通過PullMessageService完成的。
? start方法中,相當于對很多消費者的服務進行初始化,包括指定一些服務的實現類,以及啟動一些定時的任務線程,比如清理過期的請求緩存等。最后,會隨著mQClientFactory組件的啟動,啟動一個PullMessageService。實際的消息拉取都交由PullMesasgeService進行。
? 所謂消息推模式,其實還是通過Consumer拉消息實現的。
//org.apache.rocketmq.client.impl.consumer.PullMessageServiceprivate void pullMessage(final PullRequest pullRequest) {final MQConsumerInner consumer = this.mQClientFactory.selectConsumer(pullRequest.getConsumerGroup());if (consumer != null) {DefaultMQPushConsumerImpl impl = (DefaultMQPushConsumerImpl) consumer;impl.pullMessage(pullRequest);} else {log.warn("No matched consumer for the PullRequest {}, drop it", pullRequest);}}4. 客戶端負載均衡管理總結
?? 從之前Producer發送消息的過程以及Conmer拉取消息的過程,我們可以抽象出RocketMQ中一個消息分配的管理模型。這個模型是我們在使用RocketMQ時,很重要的進行性能優化的依據。
1 Producer負載均衡
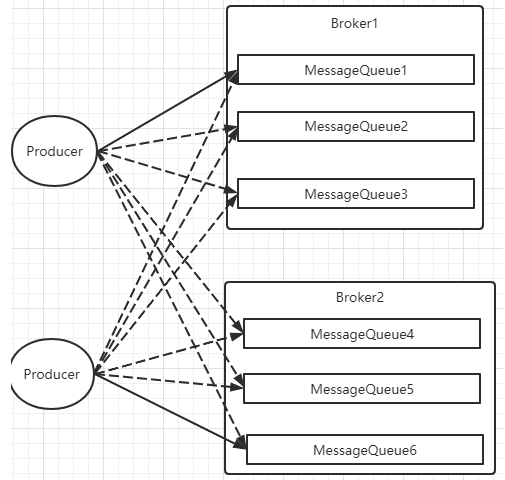
? Producer發送消息時,默認會輪詢目標Topic下的所有MessageQueue,并采用遞增取模的方式往不同的MessageQueue上發送消息,以達到讓消息平均落在不同的queue上的目的。而由于MessageQueue是分布在不同的Broker上的,所以消息也會發送到不同的broker上。
? 在之前源碼中看到過,Producer輪詢時,如果發現往某一個Broker上發送消息失敗了,那么下一次會盡量避免再往同一個Broker上發送消息。但是,如果你的應用場景允許發送消息長延遲,也可以給Producer設定setSendLatencyFaultEnable(true)。這樣對于某些Broker集群的網絡不是很好的環境,可以提高消息發送成功的幾率。
? 同時生產者在發送消息時,可以指定一個MessageQueueSelector。通過這個對象來將消息發送到自己指定的MessageQueue上。這樣可以保證消息局部有序。
2 Consumer負載均衡
? Consumer也是以MessageQueue為單位來進行負載均衡。分為集群模式和廣播模式。
1、集群模式
? 在集群消費模式下,每條消息只需要投遞到訂閱這個topic的Consumer Group下的一個實例即可。RocketMQ采用主動拉取的方式拉取并消費消息,在拉取的時候需要明確指定拉取哪一條message queue。
? 而每當實例的數量有變更,都會觸發一次所有實例的負載均衡,這時候會按照queue的數量和實例的數量平均分配queue給每個實例。
? 每次分配時,都會將MessageQueue和消費者ID進行排序后,再用不同的分配算法進行分配。內置的分配的算法共有六種,分別對應AllocateMessageQueueStrategy下的六種實現類,可以在consumer中直接set來指定。默認情況下使用的是最簡單的平均分配策略。
-
AllocateMachineRoomNearby: 將同機房的Consumer和Broker優先分配在一起。
? 這個策略可以通過一個machineRoomResolver對象來定制Consumer和Broker的機房解析規則。然后還需要引入另外一個分配策略來對同機房的Broker和Consumer進行分配。一般也就用簡單的平均分配策略或者輪詢分配策略。
感覺這東西挺雞肋的,直接給個屬性指定機房不是挺好的嗎。
? 源碼中有測試代碼AllocateMachineRoomNearByTest。
? 在示例中:Broker的機房指定方式: messageQueue.getBrokerName().split("-")[0],而Consumer的機房指定方式:clientID.split("-")[0]
? clinetID的構建方式:見ClientConfig.buildMQClientId方法。按他的測試代碼應該是要把clientIP指定為IDC1-CID-0這樣的形式。
-
AllocateMessageQueueAveragely:平均分配。將所有MessageQueue平均分給每一個消費者
-
AllocateMessageQueueAveragelyByCircle: 輪詢分配。輪流的給一個消費者分配一個MessageQueue。
-
AllocateMessageQueueByConfig: 不分配,直接指定一個messageQueue列表。類似于廣播模式,直接指定所有隊列。
-
AllocateMessageQueueByMachineRoom:按邏輯機房的概念進行分配。又是對BrokerName和ConsumerIdc有定制化的配置。
-
AllocateMessageQueueConsistentHash。源碼中有測試代碼AllocateMessageQueueConsitentHashTest。這個一致性哈希策略只需要指定一個虛擬節點數,是用的一個哈希環的算法,虛擬節點是為了讓Hash數據在換上分布更為均勻。
最常用的就是平均分配和輪訓分配了。例如平均分配時的分配情況是這樣的: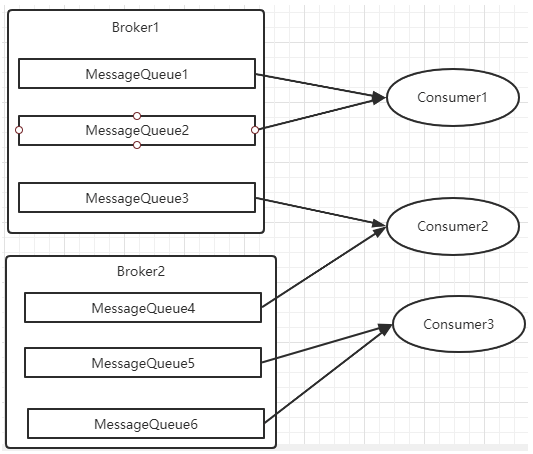
? 而輪詢分配就不計算了,每次把一個隊列分給下一個Consumer實例。
2、廣播模式
? 廣播模式下,每一條消息都會投遞給訂閱了Topic的所有消費者實例,所以也就沒有消息分配這一說。而在實現上,就是在Consumer分配Queue時,所有Consumer都分到所有的Queue。
? 廣播模式實現的關鍵是將消費者的消費偏移量不再保存到broker當中,而是保存到客戶端當中,由客戶端自行維護自己的消費偏移量。
4. 融匯貫通階段
? 開始梳理一些比較完整,比較復雜的完整業務線。
4.1 消息持久化設計
1、RocketMQ的持久化文件結構
? 消息持久化也就是將內存中的消息寫入到本地磁盤的過程。而磁盤IO操作通常是一個很耗性能,很慢的操作,所以,對消息持久化機制的設計,是一個MQ產品提升性能的關鍵,甚至可以說是最為重要的核心也不為過。這部分我們就先來梳理RocketMQ是如何在本地磁盤中保存消息的。
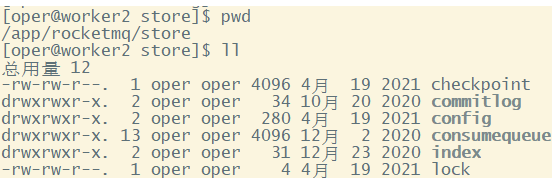
? 在進入源碼之前,我們首先需要看一下RocketMQ在磁盤上存了哪些文件。RocketMQ消息直接采用磁盤文件保存消息,默認路徑在${user_home}/store目錄。這些存儲目錄可以在broker.conf中自行指定。
-
存儲文件主要分為三個部分:
-
CommitLog:存儲消息的元數據。所有消息都會順序存入到CommitLog文件當中。CommitLog由多個文件組成,每個文件固定大小1G。以第一條消息的偏移量為文件名。
-
ConsumerQueue:存儲消息在CommitLog的索引。一個MessageQueue一個文件,記錄當前MessageQueue被哪些消費者組消費到了哪一條CommitLog。
-
IndexFile:為了消息查詢提供了一種通過key或時間區間來查詢消息的方法,這種通過IndexFile來查找消息的方法不影響發送與消費消息的主流程
? 另外,還有幾個輔助的存儲文件,主要記錄一些描述消息的元數據:
-
checkpoint:數據存盤檢查點。里面主要記錄commitlog文件、ConsumeQueue文件以及IndexFile文件最后一次刷盤的時間戳。
-
config/*.json:這些文件是將RocketMQ的一些關鍵配置信息進行存盤保存。例如Topic配置、消費者組配置、消費者組消息偏移量Offset 等等一些信息。
-
abort:這個文件是RocketMQ用來判斷程序是否正常關閉的一個標識文件。正常情況下,會在啟動時創建,而關閉服務時刪除。但是如果遇到一些服務器宕機,或者kill -9這樣一些非正常關閉服務的情況,這個abort文件就不會刪除,因此RocketMQ就可以判斷上一次服務是非正常關閉的,后續就會做一些數據恢復的操作。
-
? 整體的消息存儲結構,官方做了個圖進行描述: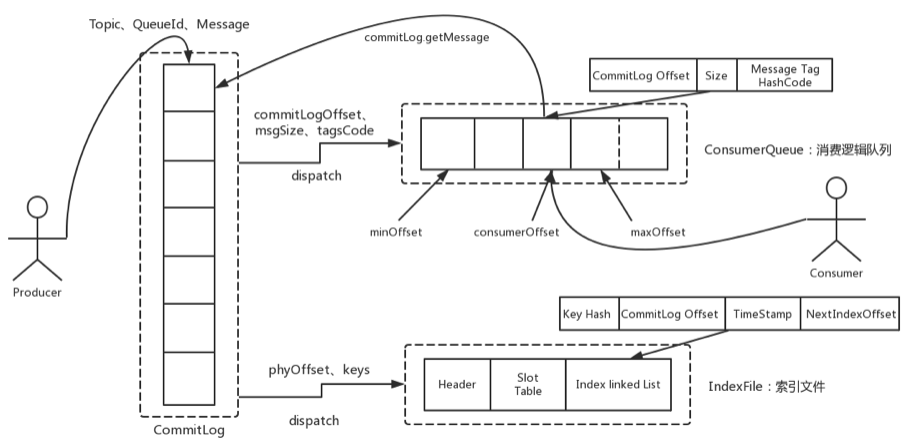
? 簡單來說,Producer發過來的所有消息,不管是屬于那個Topic,Broker都統一存在CommitLog文件當中,然后分別構建ConsumeQueue文件和IndexFile兩個索引文件,用來輔助消費者進行消息檢索。這種設計最直接的好處是可以較少查找目標文件的時間,讓消息以最快的速度落盤。對比Kafka存文件時,需要尋找消息所屬的Partition文件,再完成寫入。當Topic比較多時,這樣的Partition尋址就會浪費非常多的時間。所以Kafka不太適合多Topic的場景。而RocketMQ的這種快速落盤的方式,在多Topic的場景下,優勢就比較明顯了。
? 然后在文件形式上:
? CommitLog文件的大小是固定的。文件名就是當前CommitLog文件當中存儲的第一條消息的Offset。
? ConsumeQueue文件主要是加速消費者進行消息索引。每個文件夾對應RocketMQ中的一個MessageQueue,文件夾下的文件記錄了每個MessageQueue中的消息在CommitLog文件當中的偏移量。這樣,消費者通過ConsumeQueue文件,就可以快速找到CommitLog文件中感興趣的消息記錄。而消費者在ConsumeQueue文件中的消費進度,會保存在config/consumerOffset.json文件當中。
? IndexFile文件主要是輔助消費者進行消息索引。消費者進行消息消費時,通過ConsumeQueue文件就足夠完成消息檢索了,但是如果消費者指定時間戳進行消費,或者要按照MeessageId或者MessageKey來檢索文件,比如RocketMQ管理控制臺的消息軌跡功能,ConsumeQueue文件就不夠用了。IndexFile文件就是用來輔助這類消息檢索的。他的文件名比較特殊,不是以消息偏移量命名,而是用的時間命名。但是其實,他也是一個固定大小的文件。
? 這是對RocketMQ存盤文件最基礎的了解,但是只有這樣的設計,是不足以支撐RocketMQ的三高性能的。RocketMQ如何保證ConsumeQueue、IndexFile兩個索引文件與CommitLog中的消息對齊?如何保證消息斷電不丟失?如何保證文件高效的寫入磁盤?等等。如果你想要去抓住RocketMQ這些三高問題的核心設計,那么還是需要到源碼當中去深究。
? 以下幾個部分非常重要,所以有必要單獨拉出章節來詳細講解。
2、commitLog寫入
? 消息存儲的入口在: DefaultMessageStore.asyncPutMessage方法
怎么找到這個方法的?這個大家可以自行往上溯源。其實還是可以追溯到Broker處理Producer發送消息的請求的SendMessageProcessor中。
? CommitLog的asyncPutMessage方法中會給寫入線程加鎖,保證一次只會允許一個線程寫入。寫入消息的過程是串行的,一次只會允許一個線程寫入。
? 最終進入CommitLog中的DefaultAppendMessageCallback#doAppend方法,這里就是Broker寫入消息的實際入口。這個方法最終會把消息追加到MappedFile映射的一塊內存里,并沒有直接寫入磁盤。而是在隨后調用ComitLog#submitFlushRequest方法,提交刷盤申請。刷盤完成之后,內存中的文件才真正寫入到磁盤當中。
? 在提交刷盤申請之后,就會立即調用CommitLog#submitReplicaRequest方法,發起主從同步申請。
3、文件同步刷盤與異步刷盤
? 入口:CommitLog.submitFlushRequest
? 這里涉及到了對于同步刷盤與異步刷盤的不同處理機制。這里有很多極致提高性能的設計,對于我們理解和設計高并發應用場景有非常大的借鑒意義。
? 同步刷盤和異步刷盤是通過不同的FlushCommitLogService的子服務實現的。
//org.apache.rocketmq.store.CommitLog的構造方法if (FlushDiskType.SYNC_FLUSH == defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {this.flushCommitLogService = new GroupCommitService();} else {this.flushCommitLogService = new FlushRealTimeService();}this.commitLogService = new CommitRealTimeService();? 同步刷盤采用的是GroupCommitService子線程。雖然是叫做同步刷盤,但是從源碼中能看到,他實際上并不是來一條消息就刷一次盤。而是這個子線程每10毫秒執行一次doCommit方法,掃描文件的緩存。只要緩存當中有消息,就執行一次Flush操作。
? 而異步刷盤采用的是FlushRealTimeService子線程。這個子線程最終也是執行Flush操作,只不過他的執行時機會根據配置進行靈活調整。所以可以看到,這里異步刷盤和同步刷盤的最本質區別,實際上是進行Flush操作的頻率不同。
我們經常說使用RocketMQ的同步刷盤,可以保證Broker斷電時,消息不會丟失。但是可以看到,RocketMQ并不可能真正來一條消息就進行一次刷盤,這樣在海量數據下,操作系統是承受不了的。而只要不是來一次消息刷一次盤,那么在Broker直接斷電的情況接下,就總是會有內存中的消息沒有刷入磁盤的情況,這就會造成消息丟失。所以,對于消息安全性的設計,其實是重在取舍,無法做到絕對。
? 同步刷盤和異步刷盤最終落地到FileChannel的force方法。這個force方法就會最終調用一次操作系統的fsync系統調用,完成文件寫入。關于force操作的詳細演示,可以參考后面的零拷貝部分。
//org.apache.rocketmq.storepublic int flush(final int flushLeastPages) {if (this.isAbleToFlush(flushLeastPages)) {if (this.hold()) {int value = getReadPosition();try {//We only append data to fileChannel or mappedByteBuffer, never both.if (writeBuffer != null || this.fileChannel.position() != 0) {this.fileChannel.force(false);} else {this.mappedByteBuffer.force();}} catch (Throwable e) {log.error("Error occurred when force data to disk.", e);}this.flushedPosition.set(value);this.release();} else {log.warn("in flush, hold failed, flush offset = " + this.flushedPosition.get());this.flushedPosition.set(getReadPosition());}}return this.getFlushedPosition();}? 而另外一個CommitRealTimeService這個子線程則是用來寫入堆外內存的。應用可以通過配置TransientStorePoolEnable參數開啟對外內存,如果開啟了堆外內存,會在啟動時申請一個跟CommitLog文件大小一致的堆外內存,這部分內存就可以確保不會被交換到虛擬內存中。而CommitRealTimeService處理消息的方式則只是調用mappedFileQueue的commit方法。這個方法只是往操作系統的PagedCache里寫入消息,并不主動進行刷盤操作。會由操作系統通過Dirty Page機制,在某一個時刻進行統一刷盤。例如我們在正常關閉操作系統時,經常會等待很長時間。這里面大部分的時間其實就是在做PageCache的刷盤。
public boolean commit(final int commitLeastPages) {boolean result = true;MappedFile mappedFile = this.findMappedFileByOffset(this.committedWhere, this.committedWhere == 0);if (mappedFile != null) {int offset = mappedFile.commit(commitLeastPages);long where = mappedFile.getFileFromOffset() + offset;result = where == this.committedWhere;this.committedWhere = where;}return result;}? 然后,在梳理同步刷盤與異步刷盤的具體實現時,可以看到一個小點,RocketMQ是如何讓兩個刷盤服務間隔執行的?RocketMQ提供了一個自己實現的CountDownLatch2工具類來提供線程阻塞功能,使用CAS驅動CountDownLatch2的countDown操作。每來一個消息就啟動一次CAS,成功后,調用一次countDown。而這個CountDonwLatch2在Java.util.concurrent.CountDownLatch的基礎上,實現了reset功能,這樣可以進行對象重用。如果你對JUC并發編程感興趣,那么這也是一個不錯的學習點。
? 到這里,我們只是把同步刷盤和異步刷盤的機制梳理清楚了。但是關于force操作跟刷盤有什么關系?如果你對底層IO操作不是很理解,那么很容易產生困惑。沒關系,保留你的疑問,下一部分我們會一起梳理。
4、CommigLog主從復制
? 入口:CommitLog.submitReplicaRequest
? 主從同步時,也體現到了RocketMQ對于性能的極致追求。最為明顯的,RocketMQ整體是基于Netty實現的網絡請求,而在主從復制這一塊,卻放棄了Netty框架,轉而使用更輕量級的Java的NIO來構建。
? 在主要的HAService中,會在啟動過程中啟動三個守護進程。
//HAService#startpublic void start() throws Exception {this.acceptSocketService.beginAccept();this.acceptSocketService.start();this.groupTransferService.start();this.haClient.start();}? 這其中與Master相關的是acceptSocketService和groupTransferService。其中acceptSocketService主要負責維護Master與Slave之間的TCP連接。groupTransferService主要與主從同步復制有關。而slave相關的則是haClient。
? 至于其中關于主從的同步復制與異步復制的實現流程,還是比較復雜的,有興趣的同學可以深入去研究一下。
推薦一篇可供參考的博客 RocketMQ源碼分析之主從數據復制_rocketmq commitlog復制-CSDN博客
5、分發ConsumeQueue和IndexFile
? 當CommitLog寫入一條消息后,在DefaultMessageStore的start方法中,會啟動一個后臺線程reputMessageService。源碼就定義在DefaultMessageStore中。這個后臺線程每隔1毫秒就會去拉取CommitLog中最新更新的一批消息。如果發現CommitLog中有新的消息寫入,就會觸發一次doDispatch。
//org.apache.rocketmq.store.DefaultMessageStore中的ReputMessageService線程類public void doDispatch(DispatchRequest req) {for (CommitLogDispatcher dispatcher : this.dispatcherList) {dispatcher.dispatch(req);}}? dispatchList中包含兩個關鍵的實現類CommitLogDispatcherBuildConsumeQueue和CommitLogDispatcherBuildIndex。源碼就定義在DefaultMessageStore中。他們分別用來構建ConsumeQueue索引和IndexFile索引。
具體的構建邏輯比較復雜,在下面章節了解ConsumeQueue文件和IndexFile文件的具體構造后,會比較容易看懂一點。
? 并且,如果服務異常宕機,會造成CommitLog和ConsumeQueue、IndexFile文件不一致,有消息寫入CommitLog后,沒有分發到索引文件,這樣消息就丟失了。DefaultMappedStore的load方法提供了恢復索引文件的方法,入口在load方法。
6、過期文件刪除機制
? 入口: DefaultMessageStore.addScheduleTask -> DefaultMessageStore.this.cleanFilesPeriodically()
? 在這個方法中會啟動兩個線程,cleanCommitLogService用來刪除過期的CommitLog文件,cleanConsumeQueueService用來刪除過期的ConsumeQueue和IndexFile文件。
? 在刪除CommitLog文件時,Broker會啟動后臺線程,每60秒,檢查CommitLog、ConsumeQueue文件。然后對超過72小時的數據進行刪除。也就是說,默認情況下, RocketMQ只會保存3天內的數據。這個時間可以通過fileReservedTime來配置。
? 觸發過期文件刪除時,有兩個檢查的緯度,一個是,是否到了觸發刪除的時間,也就是broker.conf里配置的deleteWhen屬性。另外還會檢查磁盤利用率,達到閾值也會觸發過期文件刪除。這個閾值默認是72%,可以在broker.conf文件當中定制。但是最大值為95,最小值為10。
? 然后在刪除ConsumeQueue和IndexFile文件時,會去檢查CommitLog當前的最小Offset,然后在刪除時進行對齊。
? 需要注意的是,RocketMQ在刪除過期CommitLog文件時,并不檢查消息是否被消費過。 所以如果有消息長期沒有被消費,是有可能直接被刪除掉,造成消息丟失的。
? RocketMQ整個文件管理的核心入口在DefaultMessageStore的start方法中,整體流程總結如下: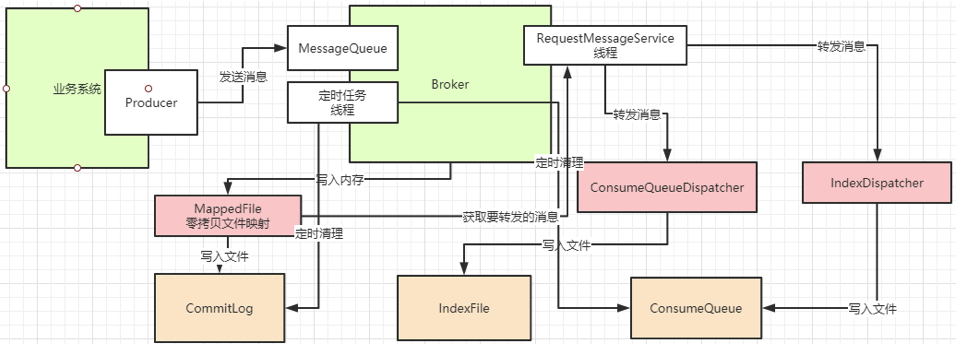
7、文件索引結構
? 了解了大部分的文件寫入機制之后,最后我們來理解一下RocketMQ的索引構建方式。
? 1、CommitLog文件的大小是固定的,但是其中存儲的每個消息單元長度是不固定的,具體格式可以參考org.apache.rocketmq.store.CommitLog中計算消息長度的方法
--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
protected static int calMsgLength(int sysFlag, int bodyLength, int topicLength, int propertiesLength) {int bornhostLength = (sysFlag & MessageSysFlag.BORNHOST_V6_FLAG) == 0 ? 8 : 20;int storehostAddressLength = (sysFlag & MessageSysFlag.STOREHOSTADDRESS_V6_FLAG) == 0 ? 8 : 20;final int msgLen = 4 //TOTALSIZE+ 4 //MAGICCODE+ 4 //BODYCRC+ 4 //QUEUEID+ 4 //FLAG+ 8 //QUEUEOFFSET+ 8 //PHYSICALOFFSET+ 4 //SYSFLAG+ 8 //BORNTIMESTAMP+ bornhostLength //BORNHOST+ 8 //STORETIMESTAMP+ storehostAddressLength //STOREHOSTADDRESS+ 4 //RECONSUMETIMES+ 8 //Prepared Transaction Offset+ 4 + (bodyLength > 0 ? bodyLength : 0) //BODY+ 1 + topicLength //TOPIC+ 2 + (propertiesLength > 0 ? propertiesLength : 0) //propertiesLength+ 0;return msgLen;}? 正因為消息的記錄大小不固定,所以RocketMQ在每次存CommitLog文件時,都會去檢查當前CommitLog文件空間是否足夠,如果不夠的話,就重新創建一個CommitLog文件。文件名為當前消息的偏移量。
? 2、ConsumeQueue文件主要是加速消費者的消息索引。他的每個文件夾對應RocketMQ中的一個MessageQueue,文件夾下的文件記錄了每個MessageQueue中的消息在CommitLog文件當中的偏移量。這樣,消費者通過ComsumeQueue文件,就可以快速找到CommitLog文件中感興趣的消息記錄。而消費者在ConsumeQueue文件當中的消費進度,會保存在config/consumerOffset.json文件當中。
? 文件結構: 每個ConsumeQueue文件固定由30萬個固定大小20byte的數據塊組成,數據塊的內容包括:msgPhyOffset(8byte,消息在文件中的起始位置)+msgSize(4byte,消息在文件中占用的長度)+msgTagCode(8byte,消息的tag的Hash值)。
msgTag是和消息索引放在一起的,所以,消費者根據Tag過濾消息的性能是非常高的。
? 在ConsumeQueue.java當中有一個常量CQ_STORE_UNIT_SIZE=20,這個常量就表示一個數據塊的大小。
? 例如,在ConsumeQueue.java當中構建一條ConsumeQueue索引的方法 中,就是這樣記錄一個單元塊的數據的。
--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
private boolean putMessagePositionInfo(final long offset, final int size, final long tagsCode,final long cqOffset) {if (offset + size <= this.maxPhysicOffset) {log.warn("Maybe try to build consume queue repeatedly maxPhysicOffset={} phyOffset={}", maxPhysicOffset, offset);return true;}this.byteBufferIndex.flip();this.byteBufferIndex.limit(CQ_STORE_UNIT_SIZE);this.byteBufferIndex.putLong(offset);this.byteBufferIndex.putInt(size);this.byteBufferIndex.putLong(tagsCode);//.......}? 3、IndexFile文件主要是輔助消息檢索。他的作用主要是用來支持根據key和timestamp檢索消息。他的文件名比較特殊,不是以消息偏移量命名,而是用的時間命名。但是其實,他也是一個固定大小的文件。
? 文件結構: 他的文件結構由 indexHeader(固定40byte)+ slot(固定500W個,每個固定20byte) + index(最多500W*4個,每個固定20byte) 三個部分組成。
indexFile的詳細結構有大廠之前面試過,可以參考一下我的博文: RocketMQ之底層IndexFile存儲協議_roketmq有了consumequeue為啥還需要indexfile-CSDN博客
? 然后,了解這些文件結構有什么用呢?下面的延遲消息機制就是一個例子。
4.2 延遲消息機制
1、關注重點
? 延遲消息是RocketMQ非常有特色的一個功能,其他MQ產品中,往往需要開發者使用一些特殊方法來變相實現延遲消息功能。而RocketMQ直接在產品中實現了這個功能,開發者只需要設定一個屬性就可以快速實現。
? 延遲消息的核心使用方法就是在Message中設定一個MessageDelayLevel參數,對應18個延遲級別。然后Broker中會創建一個默認的Schedule_Topic主題,這個主題下有18個隊列,對應18個延遲級別。消息發過來之后,會先把消息存入Schedule_Topic主題中對應的隊列。然后等延遲時間到了,再轉發到目標隊列,推送給消費者進行消費。
2、源碼重點
? 延遲消息的處理入口在scheduleMessageService這個組件中。 他會在broker啟動時也一起加載。
1、消息寫入到系統內置的Topic中
? 代碼見CommitLog.putMessage方法。
? 在CommitLog寫入消息時,會判斷消息的延遲級別,然后修改Message的Topic和Queue,將消息轉儲到系統內部的Topic中,這樣消息就對消費者不可見了。而原始的目標信息,會作為消息的屬性,保存到消息當中。
--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
if (tranType == MessageSysFlag.TRANSACTION_NOT_TYPE|| tranType == MessageSysFlag.TRANSACTION_COMMIT_TYPE) {// Delay Delivery//K1 延遲消息轉到系統Topicif (msg.getDelayTimeLevel() > 0) {if (msg.getDelayTimeLevel() > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {msg.setDelayTimeLevel(this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel());}topic = TopicValidator.RMQ_SYS_SCHEDULE_TOPIC;int queueId = ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel());// Backup real topic, queueIdMessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));//修改消息的Topic和Queue,轉儲到系統的Topic中。msg.setTopic(topic);msg.setQueueId(queueId);}}? 十八個隊列對應了十八個延遲級別,這也說明了為什么這種機制下不支持自定義時間戳。
2、消息轉儲到目標Topic
? 接下來就是需要過一點時間,再將消息轉回到Producer提交的Topic和Queue中,這樣就可以正常往消費者推送了。
? 這個轉儲的核心服務是scheduleMessageService,他也是Broker啟動過程中的一個功能組件。隨DefaultMessageStore組件一起構建。這個服務只在master節點上啟動,而在slave節點上會主動關閉這個服務。
--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
//org.apache.rocketmq.store.DefaultMessageStore@Overridepublic void handleScheduleMessageService(final BrokerRole brokerRole) {if (this.scheduleMessageService != null) {if (brokerRole == BrokerRole.SLAVE) {this.scheduleMessageService.shutdown();} else {this.scheduleMessageService.start();}}}? 由于RocketMQ的主從節點支持切換,所以就需要考慮這個服務的冪等性。在節點切換為slave時就要關閉服務,切換為master時就要啟動服務。并且,即便節點多次切換為master,服務也只啟動一次。所以在ScheduleMessageService的start方法中,就通過一個CAS操作來保證服務的啟動狀態。
--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
if (started.compareAndSet(false, true)) {? 這個CAS操作還保證了在后面,同一時間只有一個DeliverDelayedMessageTimerTask執行。這種方式,給整個延遲消息服務提供了一個基礎保證。
? ScheduleMessageService會每隔1秒鐘執行一個executeOnTimeup任務,將消息從延遲隊列中寫入正常Topic中。 代碼見ScheduleMessageService中的DeliverDelayedMessageTimerTask.executeOnTimeup方法。
? 在executeOnTimeup方法中,就會去掃描SCHEDULE_TOPIC_XXXX這個Topic下的所有messageQueue,然后掃描這些MessageQueue對應的ConsumeQueue文件,找到沒有處理過的消息,計算他們的延遲時間。如果延遲時間沒有到,就等下一秒再重新掃描。如果延遲時間到了,就進行消息轉儲。將消息轉回到原來的目標Topic下。
? 整個延遲消息的實現方式是這樣的: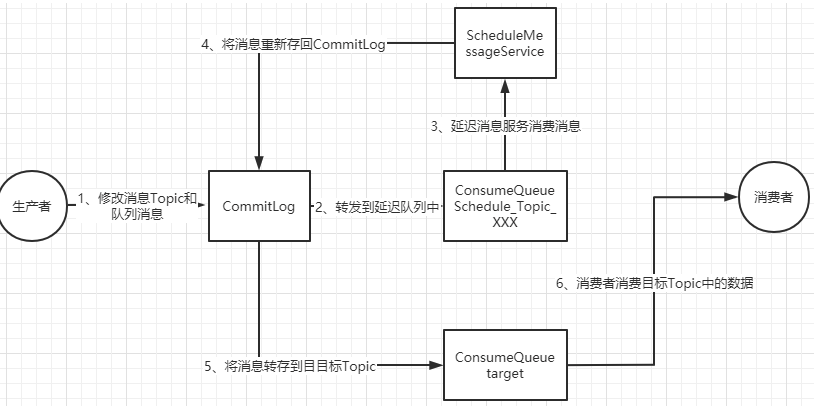
? 而ScheduleMessageService中掃描延遲消息的主要邏輯是這樣的:
--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
//ScheduleMessageService.DeliverDelayedMessageTimerTask#executeOnTimeuppublic void executeOnTimeup() {//找到延遲隊列對應的ConsumeQueue文件ConsumeQueue cq = ScheduleMessageService.this.defaultMessageStore.findConsumeQueue(TopicValidator.RMQ_SYS_SCHEDULE_TOPIC,delayLevel2QueueId(delayLevel));//...//通過計算,找到這一次掃描需要處理的的ConsumeQueue文件SelectMappedBufferResult bufferCQ = cq.getIndexBuffer(this.offset);//...try {//...//循環過濾ConsumeQueue文件當中的每一條消息索引for (; i < bufferCQ.getSize() && isStarted(); i += ConsumeQueue.CQ_STORE_UNIT_SIZE) {//解析每一條ConsumeQueue記錄long offsetPy = bufferCQ.getByteBuffer().getLong();int sizePy = bufferCQ.getByteBuffer().getInt();long tagsCode = bufferCQ.getByteBuffer().getLong();//...//計算延遲時間long now = System.currentTimeMillis();long deliverTimestamp = this.correctDeliverTimestamp(now, tagsCode);nextOffset = offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);//延遲時間沒到就等下一次掃描。long countdown = deliverTimestamp - now;if (countdown > 0) {this.scheduleNextTimerTask(nextOffset, DELAY_FOR_A_WHILE);return;}//...//時間到了就進行轉儲。boolean deliverSuc;if (ScheduleMessageService.this.enableAsyncDeliver) {deliverSuc = this.asyncDeliver(msgInner, msgExt.getMsgId(), nextOffset, offsetPy, sizePy);} else {deliverSuc = this.syncDeliver(msgInner, msgExt.getMsgId(), nextOffset, offsetPy, sizePy);}
//...}//計算下一次掃描時的Offset起點。nextOffset = this.offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);} catch (Exception e) {log.error("ScheduleMessageService, messageTimeup execute error, offset = {}", nextOffset, e);} finally {bufferCQ.release();}//部署下一次掃描任務this.scheduleNextTimerTask(nextOffset, DELAY_FOR_A_WHILE);}? 你看。這段代碼,如果你不懂ConsumeQueue文件的結構,大概率是看不懂他是在干什么的。但是如果清楚了ConsumeQueue文件的結構,就可以很清晰的感受到RocketMQ其實就是在Broker端,像一個普通消費者一樣去進行消費,然后擴展出了延遲消息的整個擴展功能。而這,其實也是很多互聯網大廠對RocketMQ進行自定義功能擴展的很好的參考。
? 當然,如果你有心深入分析下去的話,可以針對掃描的效率做更多的梳理以及總結。因為只要是延遲類任務,都需要不斷進行掃描。但是如何提升掃描的效率其實是一個非常核心的問題。各種框架都有不同的設計思路,而RocketMQ其實就是給出了一個很高效的參考。
? 例如下面的長輪詢機制,就是在普通消息流轉過程中加入一些小邏輯,擴展出來的一種很好的優化機制。在花聯網大廠中,會有很多類似這樣的自定義優化機制。比如對于延遲消息,只支持十八個固定的延遲級別,但是在很多互聯網大廠,其實早在官方提出5.0版本之前,就已經定制形成了支持任意延遲時間的擴展功能。
4.3 長輪詢機制
1、功能回顧
? RocketMQ對消息消費者提供了Push推模式和Pull拉模式兩種消費模式。但是這兩種消費模式的本質其實都是Pull拉模式,Push模式可以認為是一種定時的Pull機制。但是這時有一個問題,當使用Push模式時,如果RocketMQ中沒有對應的數據,那難道一直進行空輪詢嗎?如果是這樣的話,那顯然會極大的浪費網絡帶寬以及服務器的性能,并且,當有新的消息進來時,RocketMQ也沒有辦法盡快通知客戶端,而只能等客戶端下一次來拉取消息了。針對這個問題,RocketMQ實現了一種長輪詢機制 long polling。
? 長輪詢機制簡單來說,就是當Broker接收到Consumer的Pull請求時,判斷如果沒有對應的消息,不用直接給Consumer響應(給響應也是個空的,沒意義),而是就將這個Pull請求給緩存起來。當Producer發送消息過來時,增加一個步驟去檢查是否有對應的已緩存的Pull請求,如果有,就及時將請求從緩存中拉取出來,并將消息通知給Consumer。
2、源碼重點
? Consumer請求緩存,代碼入口PullMessageProcessor#processRequest方法
? PullRequestHoldService服務會隨著BrokerController一起啟動。
? 生產者線:從DefaultMessageStore.doReput進入
? 整個流程以及源碼重點如下圖所示: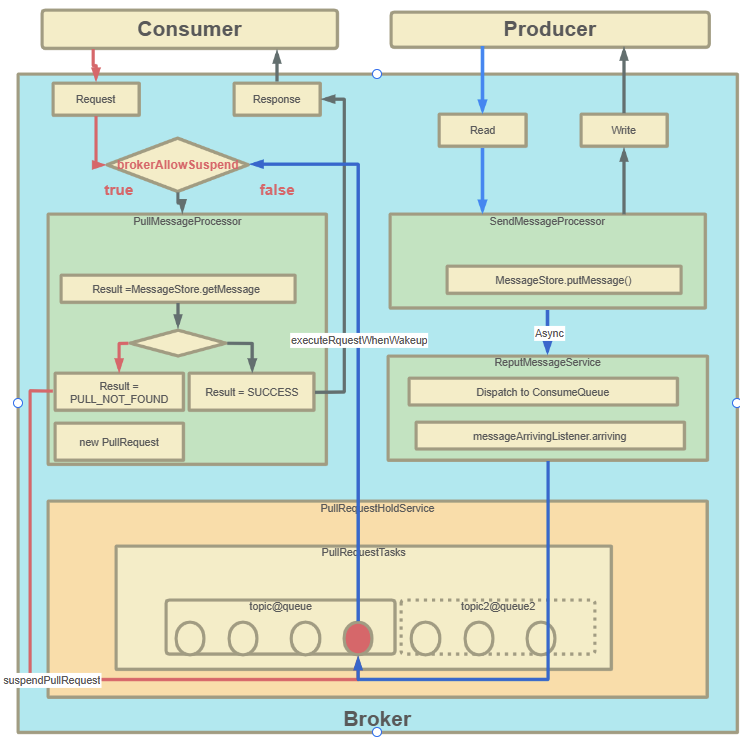
5. 關于零拷貝與順序寫
5.1 刷盤機制保證消息不丟失
? 在操作系統層面,當應用程序寫入一個文件時,文件內容并不會直接寫入到硬件當中,而是會先寫入到操作系統中的一個緩存PageCache中。PageCache緩存以4K大小為單位,緩存文件的具體內容。這些寫入到PageCache中的文件,在應用程序看來,是已經完全落盤保存好了的,可以正常修改、復制等等。但是,本質上,PageCache依然是內存狀態,所以一斷電就會丟失。因此,需要將內存狀態的數據寫入到磁盤當中,這樣數據才能真正完成持久化,斷電也不會丟失。這個過程就稱為刷盤。
Java當中使用FileOutputStream類或者BufferedWriter類,進行write操作,就是寫入的Pagecache。
RocketMQ中通過fileChannel.commit方法寫入消息,也是寫入到Pagecache。
? PageCache是源源不斷產生的,而Linux操作系統顯然不可能時時刻刻往硬盤寫文件。所以,操作系統只會在某些特定的時刻將PageCache寫入到磁盤。例如當我們正常關機時,就會完成PageCache刷盤。另外,在Linux中,對于有數據修改的PageCache,會標記為Dirty(臟頁)狀態。當Dirty Page的比例達到一定的閾值時,就會觸發一次刷盤操作。例如在Linux操作系統中,可以通過/proc/meminfo文件查看到Page Cache的狀態。
--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
[root@192-168-65-174 ~]# cat /proc/meminfo
MemTotal: 16266172 kB
.....
Cached: 923724 kB
.....
Dirty: 32 kB
Writeback: 0 kB
.....
Mapped: 133032 kB
.....? 但是,只要操作系統的刷盤操作不是時時刻刻執行的,那么對于用戶態的應用程序來說,那就避免不了非正常宕機時的數據丟失問題。因此,操作系統也提供了一個系統調用,應用程序可以自行調用這個系統調用,完成PageCache的強制刷盤。在Linux中是fsync,同樣我們可以用man 2 fsync 指令查看。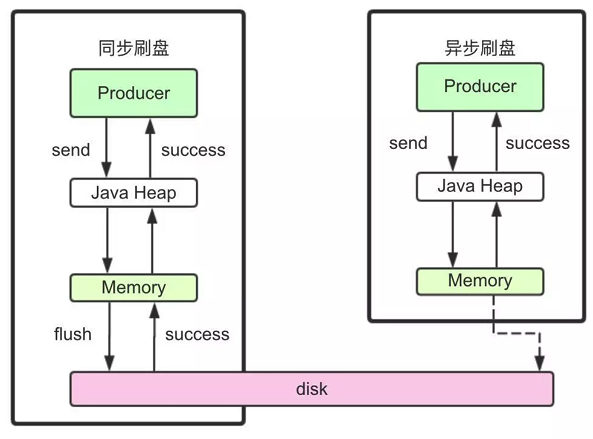
RocketMQ對于何時進行刷盤,也設計了兩種刷盤機制,同步刷盤和異步刷盤。只需要在broker.conf中進行配置就行。
? RocketMQ到底是怎么實現同步刷盤和異步刷盤的,還記得嗎?
5.2 零拷貝加速文件讀寫
? 零拷貝(zero-copy)是操作系統層面提供的一種加速文件讀寫的操作機制,非常多的開源軟件都在大量使用零拷貝,來提升IO操作的性能。對于Java應用層,對應著mmap和sendFile兩種方式。接下來,咱們深入操作系統來詳細理解一下零拷貝。
1:理解CPU拷貝和DMA拷貝
? 我們知道,操作系統對于內存空間,是分為用戶態和內核態的。用戶態的應用程序無法直接操作硬件,需要通過內核空間進行操作轉換,才能真正操作硬件。這其實是為了保護操作系統的安全。正因為如此,應用程序需要與網卡、磁盤等硬件進行數據交互時,就需要在用戶態和內核態之間來回的復制數據。而這些操作,原本都是需要由CPU來進行任務的分配、調度等管理步驟的,早先這些IO接口都是由CPU獨立負責,所以當發生大規模的數據讀寫操作時,CPU的占用率會非常高。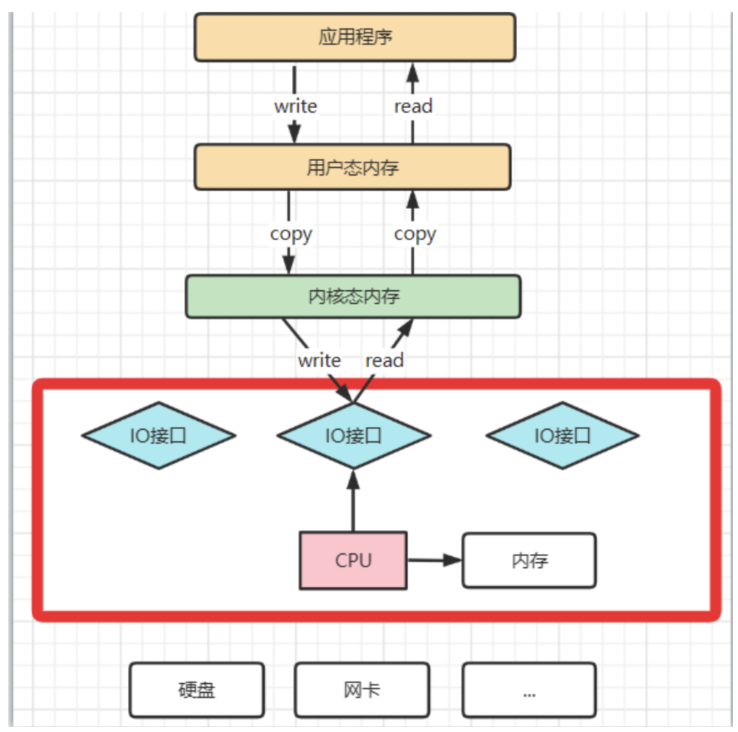
之后,操作系統為了避免CPU完全被各種IO調用給占用,引入了DMA(直接存儲器存儲)。由DMA來負責這些頻繁的IO操作。DMA是一套獨立的指令集,不會占用CPU的計算資源。這樣,CPU就不需要參與具體的數據復制的工作,只需要管理DMA的權限即可。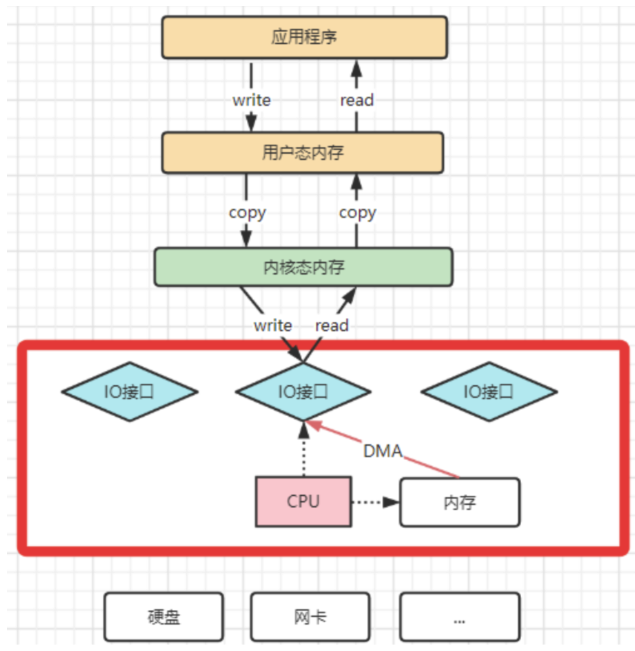
? DMA拷貝極大的釋放了CPU的性能,因此他的拷貝速度會比CPU拷貝要快很多。但是,其實DMA拷貝本身,也在不斷優化。
? 引入DMA拷貝之后,在讀寫請求的過程中,CPU不再需要參與具體的工作,DMA可以獨立完成數據在系統內部的復制。但是,數據復制過程中,依然需要借助數據總進線。當系統內的IO操作過多時,還是會占用過多的數據總線,造成總線沖突,最終還是會影響數據讀寫性能。
? 為了避免DMA總線沖突對性能的影響,后來又引入了Channel通道的方式。Channel,是一個完全獨立的處理器,專門負責IO操作。既然是處理器,Channel就有自己的IO指令,與CPU無關,他也更適合大型的IO操作,性能更高。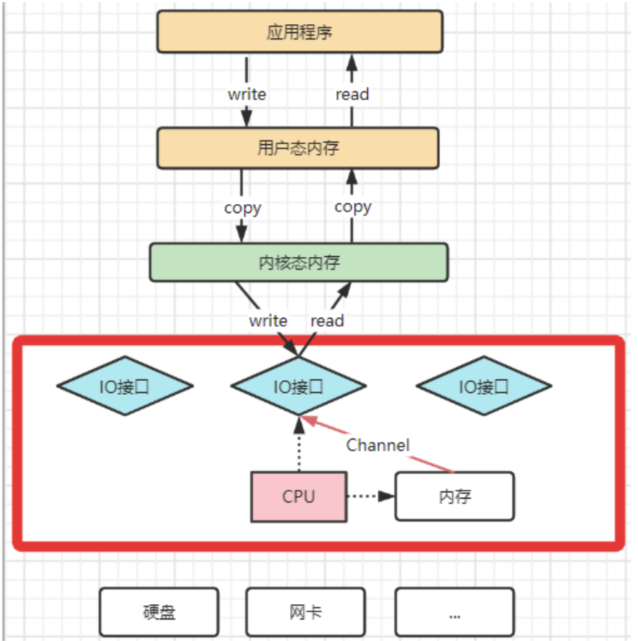
? 這也解釋了,為什么Java應用層與零拷貝相關的操作都是通過Channel的子類實現的。這其實是借鑒了操作系統中的概念。
? 而所謂的零拷貝技術,其實并不是不拷貝,而是要盡量減少CPU拷貝。
2:再來理解下mmap文件映射機制是怎么回事。
? mmap機制的具體實現參見配套示例代碼。主要是通過java.nio.channels.FileChannel的map方法完成映射。
? 以一次文件的讀寫操作為例,應用程序對磁盤文件的讀與寫,都需要經過內核態與用戶態之間的狀態切換,每次狀態切換的過程中,就需要有大量的數據復制。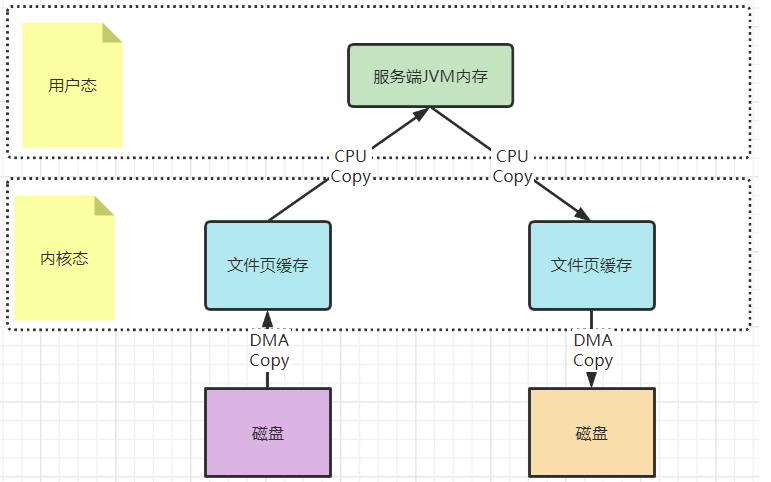
? 在這個過程中,總共需要進行四次數據拷貝。而磁盤與內核態之間的數據拷貝,在操作系統層面已經由CPU拷貝優化成了DMA拷貝。而內核態與用戶態之間的拷貝依然是CPU拷貝。所以,在這個場景下,零拷貝技術優化的重點,就是內核態與用戶態之間的這兩次拷貝。
? 而mmap文件映射的方式,就是在用戶態不再保存文件的內容,而只保存文件的映射,包括文件的內存起始地址,文件大小等。真實的數據,也不需要在用戶態留存,可以直接通過操作映射,在內核態完成數據復制。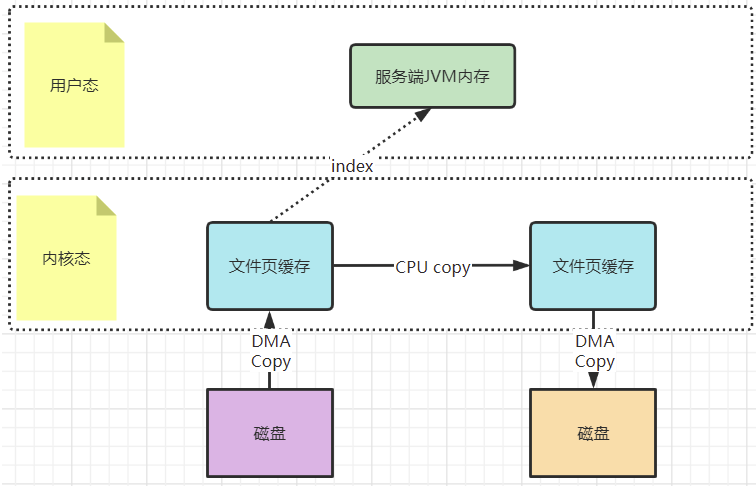
? 這個拷貝過程都是在操作系統的系統調用層面完成的,在Java應用層,其實是無法直接觀測到的,但是我們可以去JDK源碼當中進行間接驗證。在JDK的NIO包中,java.nio.HeapByteBuffer映射的就是JVM的一塊堆內內存,在HeapByteBuffer中,會由一個byte數組來緩存數據內容,所有的讀寫操作也是先操作這個byte數組。這其實就是沒有使用零拷貝的普通文件讀寫機制。
--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
HeapByteBuffer(int cap, int lim) { // package-privatesuper(-1, 0, lim, cap, new byte[cap], 0);/*hb = new byte[cap];offset = 0;*/}? 而NIO把包中的另一個實現類java.nio.DirectByteBuffer則映射的是一塊堆外內存。在DirectByteBuffer中,并沒有一個數據結構來保存數據內容,只保存了一個內存地址。所有對數據的讀寫操作,都通過unsafe魔法類直接交由內核完成,這其實就是mmap的讀寫機制。
? mmap文件映射機制,其實并不神秘,我們啟動任何一個Java程序時,其實都大量用到了mmap文件映射。例如,我們可以在Linux機器上,運行一下下面這個最簡單不過的應用程序:
--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
import java.util.Scanner;
public class BlockDemo {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);final String s = scanner.nextLine();System.out.println(s);}
}? 通過Java指令運行起來后,可以用jps查看到運行的進程ID。然后,就可以使用lsof -p {PID}的方式查看文件的映射情況。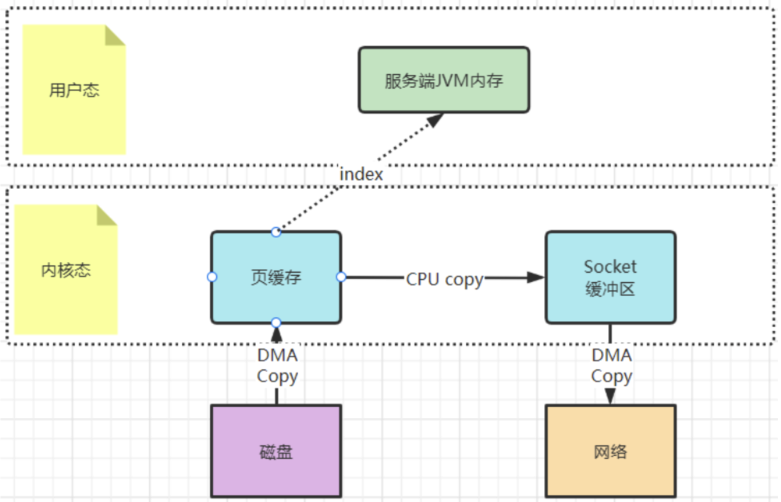
這里面看到的mem類型的FD其實就是文件映射。
cwd 表示程序的工作目錄。rtd 表示用戶的根目錄。 txt表示運行程序的指令。下面的1u表示Java應用的標準輸出,2u表示Java應用的標準錯誤輸出,默認的/dev/pts/1是linux當中的偽終端。通常服務器上會寫 java xxx 1>text.txt 2>&1 這樣的腳本,就是指定這里的1u,2u。
? 最后,這種mmap的映射機制由于還是需要用戶態保存文件的映射信息,數據復制的過程也需要用戶態的參與,這其中的變數還是非常多的。所以,mmap機制適合操作小文件,如果文件太大,映射信息也會過大,容易造成很多問題。通常mmap機制建議的映射文件大小不要超過2G 。而RocketMQ做大的CommitLog文件保持在1G固定大小,也是為了方便文件映射。
3:梳理下sendFile機制是怎么運行的。
? sendFile機制的具體實現參見配套示例代碼。主要是通過java.nio.channels.FileChannel的transferTo方法完成。
--javascripttypescriptshellbashsqljsonhtmlcssccppjavarubypythongorustmarkdown
sourceReadChannel.transferTo(0,sourceFile.length(),targetWriteChannel);? 還記得Kafka當中是如何使用零拷貝的嗎?你應該看到過這樣的例子,就是Kafka將文件從磁盤復制到網卡時,就大量的使用了零拷貝。百度去搜索一下零拷貝,鋪天蓋地的也都是拿這個場景在舉例。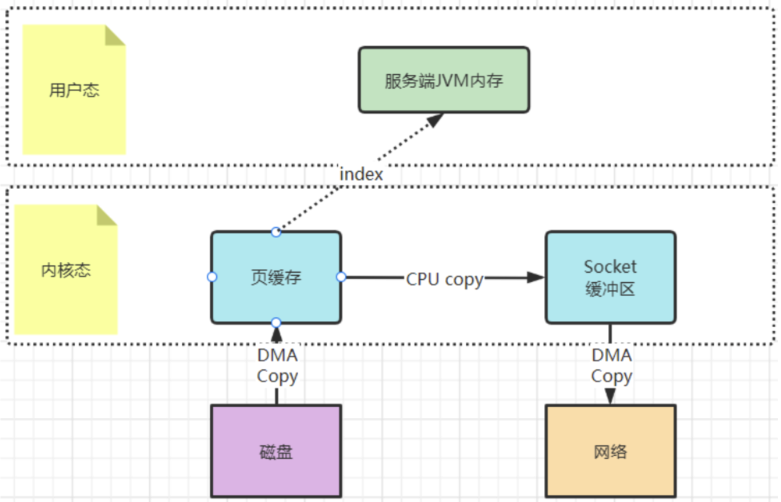
? 早期的sendfile實現機制其實還是依靠CPU進行頁緩存與socket緩存區之間的數據拷貝。但是,在后期的不斷改進過程中,sendfile優化了實現機制,在拷貝過程中,并不直接拷貝文件的內容,而是只拷貝一個帶有文件位置和長度等信息的文件描述符FD,這樣就大大減少了需要傳遞的數據。而真實的數據內容,會交由DMA控制器,從頁緩存中打包異步發送到socket中。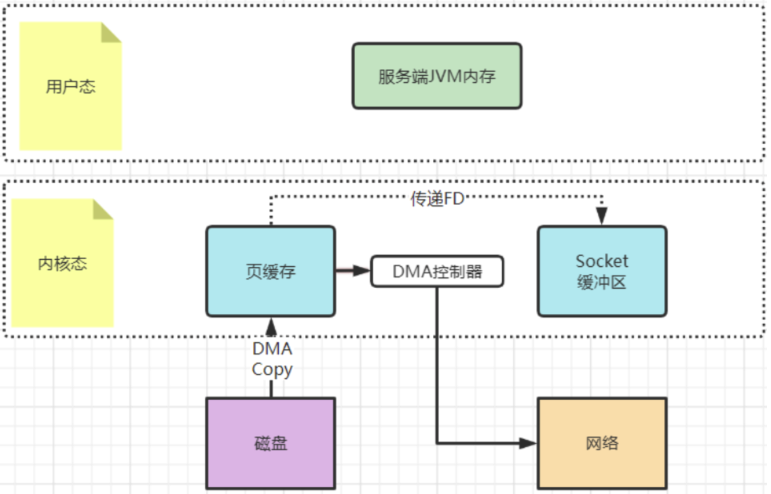
? 為什么大家都喜歡用這個場景來舉例呢?其實我們去看下Linux操作系統的man幫助手冊就能看到一部分答案。使用指令man 2 sendfile就能看到Linux操作系統對于sendfile這個系統調用的手冊。 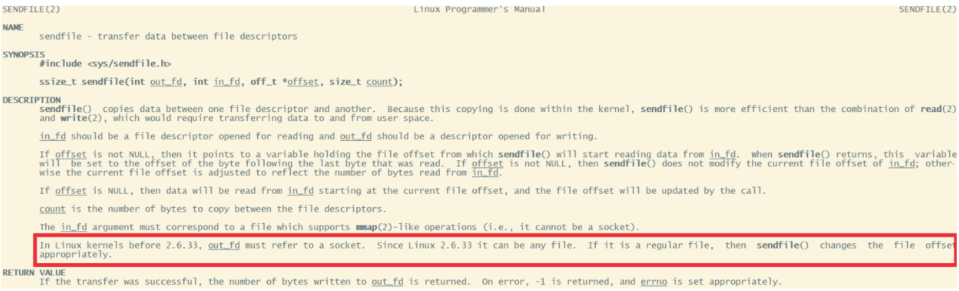
? 2.6.33版本以前的Linux內核中,out_fd只能是一個socket,所以網上鋪天蓋地的老資料都是拿網卡來舉例。但是現在版本已經沒有了這個限制。
? 最后,sendfile機制在內核態直接完成了數據的復制,不需要用戶態的參與,所以這種機制的傳輸效率是非常穩定的。sendfile機制非常適合大數據的復制轉移。
5.3 順序寫加速文件寫入磁盤
? 通常應用程序往磁盤寫文件時,由于磁盤空間不是連續的,會有很多碎片。所以我們去寫一個文件時,也就無法把一個文件寫在一塊連續的磁盤空間中,而需要在磁盤多個扇區之間進行大量的隨機寫。這個過程中有大量的尋址操作,會嚴重影響寫數據的性能。而順序寫機制是在磁盤中提前申請一塊連續的磁盤空間,每次寫數據時,就可以避免這些尋址操作,直接在之前寫入的地址后面接著寫就行。
? Kafka官方詳細分析過順序寫的性能提升問題。Kafka官方曾說明,順序寫的性能基本能夠達到內存級別。而如果配備固態硬盤,順序寫的性能甚至有可能超過寫內存。而RocketMQ很大程度上借鑒了Kafka的這種思想。
? 例如可以看下org.apache.rocketmq.store.CommitLog#DefaultAppendMessageCallback中的doAppend方法。在這個方法中,會以追加的方式將消息先寫入到一個堆外內存byteBuffer中,然后再通過fileChannel寫入到磁盤。
)
實現指南)








)





![【分享】變聲器大師[特殊字符]喬碧蘿同款變聲[特殊字符]游戲變聲[特殊字符]](http://pic.xiahunao.cn/【分享】變聲器大師[特殊字符]喬碧蘿同款變聲[特殊字符]游戲變聲[特殊字符])


