🌟【技術大咖愚公搬代碼:全棧專家的成長之路,你關注的寶藏博主在這里!】🌟
📣開發者圈持續輸出高質量干貨的"愚公精神"踐行者——全網百萬開發者都在追更的頂級技術博主!
👉 江湖人稱"愚公搬代碼",用七年如一日的精神深耕技術領域,以"挖山不止"的毅力為開發者們搬開知識道路上的重重阻礙!
💎【行業認證·權威頭銜】
? 華為云天團核心成員:特約編輯/云享專家/開發者專家/產品云測專家
? 開發者社區全滿貫:CSDN博客&商業化雙料專家/阿里云簽約作者/騰訊云內容共創官/掘金&亞馬遜&51CTO頂級博主
? 技術生態共建先鋒:橫跨鴻蒙、云計算、AI等前沿領域的技術布道者
🏆【榮譽殿堂】
🎖 連續三年蟬聯"華為云十佳博主"(2022-2024)
🎖 雙冠加冕CSDN"年度博客之星TOP2"(2022&2023)
🎖 十余個技術社區年度杰出貢獻獎得主
📚【知識寶庫】
覆蓋全棧技術矩陣:
? 編程語言:.NET/Java/Python/Go/Node…
? 移動生態:HarmonyOS/iOS/Android/小程序
? 前沿領域:物聯網/網絡安全/大數據/AI/元宇宙
? 游戲開發:Unity3D引擎深度解析
每日更新硬核教程+實戰案例,助你打通技術任督二脈!
💌【特別邀請】
正在構建技術人脈圈的你:
👍 如果這篇推文讓你收獲滿滿,點擊"在看"傳遞技術火炬
💬 在評論區留下你最想學習的技術方向
? 點擊"收藏"建立你的私人知識庫
🔔 關注公眾號獲取獨家技術內參
?與其仰望大神,不如成為大神!關注"愚公搬代碼",讓堅持的力量帶你穿越技術迷霧,見證從量變到質變的奇跡!? |
文章目錄
- 🚀前言
- 🚀一、Scrapy 文件下載
- 🔎1.下載京東外設商品圖片
- 🦋1.1 創建 Scrapy 項目
- 🦋1.2 編寫爬蟲
- 🦋1.3 配置 Pipeline
- 🦋1.4 在 settings.py 中激活 Pipeline
- 🦋1.5 啟動爬蟲
🚀前言
在前面的章節中,我們已經系統地學習了 Scrapy 框架的基礎應用和一些進階技巧,本篇文章將重點講解如何使用 Scrapy 實現 文件下載,讓你能夠抓取網頁中的各類文件,如圖片、PDF、音視頻等。
在爬蟲開發中,文件下載是一個非常常見的需求,尤其是在進行圖片爬取、資料抓取等項目時,我們需要考慮如何高效地下載和存儲文件。Scrapy 提供了非常強大的文件下載支持,能夠幫助我們輕松應對這些任務。
在本篇文章中,我們將探討:
- Scrapy 文件下載的基本原理:了解 Scrapy 如何處理文件下載,掌握文件下載的基本流程。
- 如何配置文件下載功能:通過配置
FILES_STORE等參數,實現文件的下載和存儲。 - 下載不同類型的文件:不僅是圖片,還可以是各種類型的文件,如PDF、音頻、視頻等,如何處理不同格式的文件。
- 文件下載的優化與擴展:如何通過 Scrapy 中的中間件和其他組件對文件下載進行優化,以提升下載效率和穩定性。
通過本篇文章的學習,你將能夠熟練掌握 Scrapy 文件下載的實現方式,為你的爬蟲項目增添更多實用功能。如果你正在處理文件抓取任務,或者希望了解如何更高效地下載和存儲文件,那么本篇教程將為你提供全面的解決方案。
🚀一、Scrapy 文件下載
Scrapy 提供了專門處理文件下載的 Pipeline(項目管道),包括 Files Pipeline(文件管道)和 Images Pipeline(圖像管道)。兩者的使用方式相同,區別在于 Images Pipeline 還支持將所有下載的圖片格式轉換為 JPEG/RGB 格式,并且可以設置縮略圖。
以下以繼承 ImagesPipeline 類為例,重寫三個方法:
-
file_path():該方法用于返回文件下載的路徑,
request參數是當前下載對應的 request 對象。 -
get_media_requests():該方法的第一個參數是
item對象,可以通過 item 獲取 URL,并將 URL 加入請求隊列進行下載。 -
item_completed():當單個 item 下載完成后調用,用于處理下載失敗的圖片。
results參數包含該 item 對應的下載結果,包括成功或失敗的信息。
🔎1.下載京東外設商品圖片
🦋1.1 創建 Scrapy 項目
在命令行窗口中,通過以下命令創建一個名為 imagesDemo 的 Scrapy 項目:
scrapy startproject imagesDemo
接著,在該項目的 spiders 文件夾內創建 imagesSpider.py 爬蟲文件,并在 items.py 文件中定義存儲商品名稱和圖片地址的 Field() 對象:
import scrapyclass ImagesDemoItem(scrapy.Item):wareName = scrapy.Field() # 存儲商品名稱imgPath = scrapy.Field() # 存儲商品圖片地址
🦋1.2 編寫爬蟲
在 imagesSpider.py 文件中,首先導入 json 模塊,并重寫 start_requests() 方法來獲取 JSON 數據。然后在 parse() 方法中提取商品名稱和圖片地址。
# -*- coding: utf-8 -*-
import scrapy # 導入scrapy模塊
import json # 導入json模塊
# 導入ImagesdemoItem類
from imagesDemo.items import ImagesdemoItem
class ImgesspiderSpider(scrapy.Spider):name = 'imgesSpider' # 爬蟲名稱allowed_domains = ['ch.jd.com'] # 域名列表start_urls = ['http://ch.jd.com/'] # 網絡請求初始列表def start_requests(self):url = 'http://ch.jd.com/hotsale2?cateid=686' # 獲取json信息的請求地址yield scrapy.Request(url, self.parse) # 發送網絡請求def parse(self, response):data = json.loads(response.text) # 將返回的json信息轉換為字典products = data['products'] # 獲取所有數據信息for image in products: # 循環遍歷信息item = ImagesdemoItem() # 創建item對象item['wareName'] = image.get('wareName').replace('/','') # 存儲商品名稱# 存儲商品對應的圖片地址item['imgPath'] = 'http://img12.360buyimg.com/n1/s320x320_' + image.get('imgPath')yield item# 導入CrawlerProcess類
from scrapy.crawler import CrawlerProcess
# 導入獲取項目設置信息
from scrapy.utils.project import get_project_settings# 程序入口
if __name__ == '__main__':# 創建CrawlerProcess類對象并傳入項目設置信息參數process = CrawlerProcess(get_project_settings())# 設置需要啟動的爬蟲名稱process.crawl('imgesSpider')# 啟動爬蟲process.start()
🦋1.3 配置 Pipeline
在 pipelines.py 文件中,導入 ImagesPipeline 類,繼承該類并重寫 file_path() 和 get_media_requests() 方法。
from scrapy.pipelines.images import ImagesPipeline # 導入ImagesPipeline類
import scrapy # 導入scrapy
class ImagesdemoPipeline(ImagesPipeline): # 繼承ImagesPipeline類# 設置文件保存的名稱def file_path(self, request, response=None, info=None):file_name = request.meta['name']+'.jpg' # 將商品名稱設置為圖片名稱return file_name # 返回文件名稱# 發送獲取圖片的網絡請求def get_media_requests(self, item, info):# 發送網絡請求并傳遞商品名稱yield scrapy.Request(item['imgPath'],meta={'name':item['wareName']})# def process_item(self, item, spider):# return item
🦋1.4 在 settings.py 中激活 Pipeline
在 settings.py 文件中激活 ITEM_PIPELINES 配置,并指定圖片下載后的保存路徑。
ITEM_PIPELINES = {'imagesDemo.pipelines.ImagesDemoPipeline': 300,
}IMAGES_STORE = './images' # 圖片保存的文件夾路徑
🦋1.5 啟動爬蟲
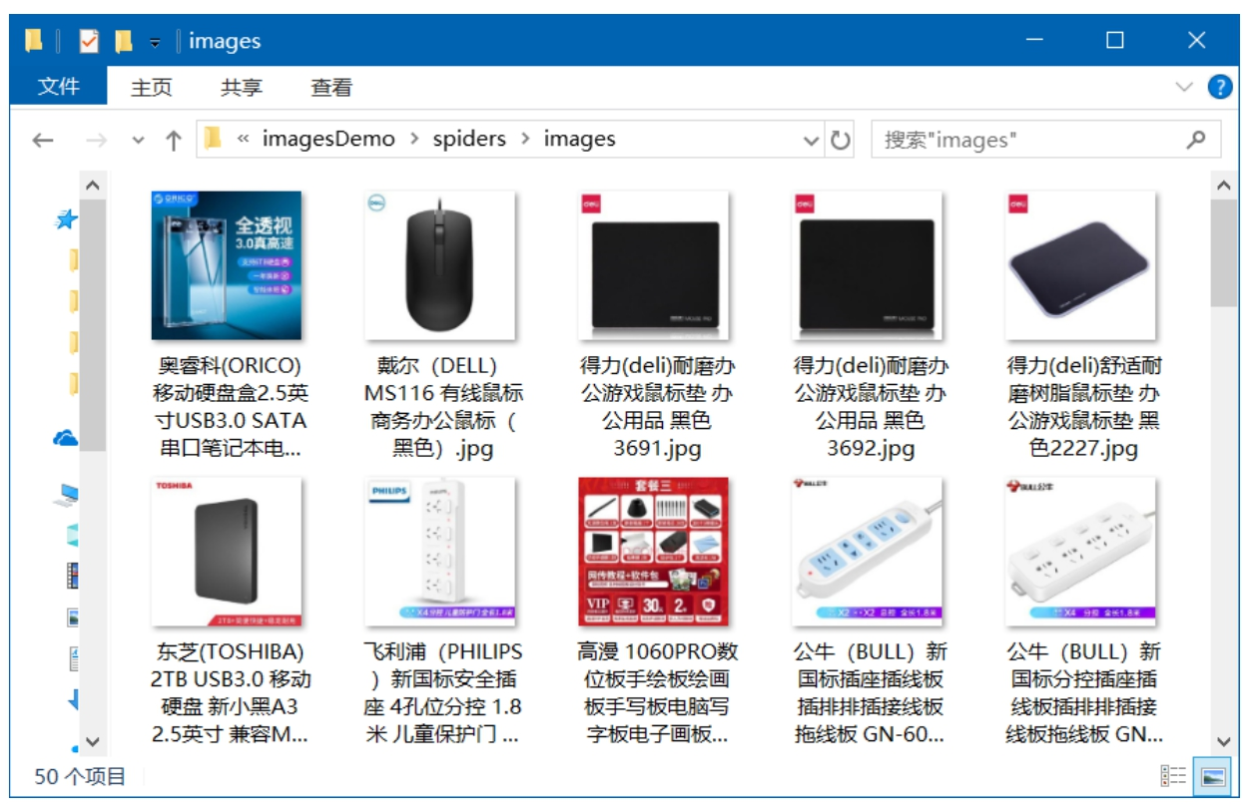
啟動 imagesSpider 爬蟲,下載完成后,打開項目結構中的 images 文件夾,可以查看下載的商品圖片。
工具能力評估,懸鏡安全靈脈AI通過評估!)
項目)

)
)


 - 定時器DMA循環模式修改ARR值、定時器中斷方式修改ARR值 - STM32CubeMX)
)
完整講解與實戰應用)




![[數據可視化] Datagear使用心得:從數據整備到可視化聯動實踐](http://pic.xiahunao.cn/[數據可視化] Datagear使用心得:從數據整備到可視化聯動實踐)


)
----輪詢獲取陀螺儀數據)
