? ? ? ?前面我們分享了關于大語言模型的相關技術,包括前向推理、LoRa掛載、MoE模型、模型預訓練等;后續還是會基于MiniMindLM模型繼續分享關于大語言模型的SFT指令微調、LoRa微調、基于人類偏好的強化學習微調以及模型蒸餾相關的技術,請大家持續關注。
一、LLM和VLM推理流程敘述
1.1 LLM
? ? ? ?今天我們基于MiniMind-V項目,分享一些關于多模態大模型的相關技術 ;首先我們回顧一下大語言模型是如何進行推理的:
大語言模型LLM推理流程:
- 首先,大語言模型的輸入只有文本信息,輸入的文本信息會通過分詞器(tokenizer)將文本信息對應詞匯表轉變為tokenID;
- 然后會將轉變出來的tokenID送入到詞嵌入模型(embedding)進行向量化,將每一個tokenID轉變為固定維度的張量,比如512、768維等;
- 轉變完成后將其送入transformer模塊進行自注意力運算和前饋神經變換,同時通過旋轉位置編碼的方式將編碼信息嵌入到Q、K張量上;
- 進過N個transformer模塊,將輸出張量映射到詞匯表的數量維度;
- 選取最后一個token張量進行softmax歸一化運算,將其轉化到概率域;
- 通過Top-p的方式選擇出對應的預測tokenID,通過分詞器將其轉換回文本信息,就完成了一輪的推理運算;
- 然后緩存KVcache,拼接新預測的token再次按照上面的流程進行運算,直到預測token為終止符號或者達到上下文的最大長度則停止運算;
1.2 VLM?
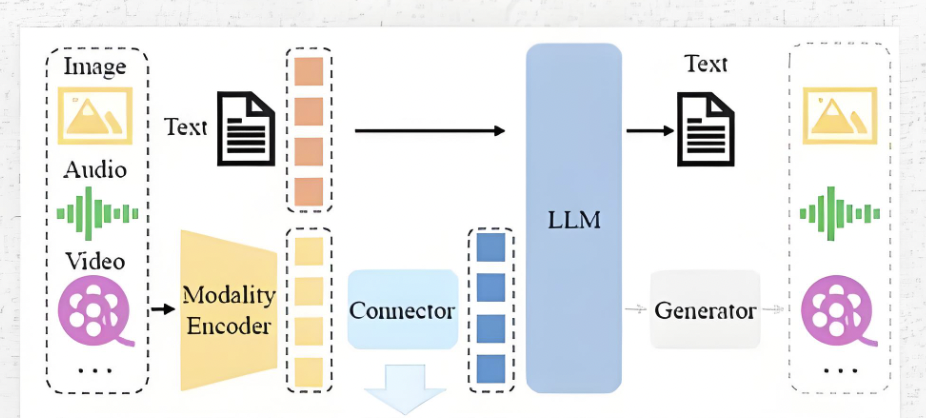
? ? ? ?了解了大語言模型的推理流程,我們就可以有針對性的分析多模態VL模型在推理過程上與大語言模型的異同點;?首先在模型輸入上有很大的不同,多模態VL模型可以接受圖片的輸入,然后就是在輸入transformer模塊之前的分詞方式不同和embedding詞嵌入方式不同;多模態大模型的整體推理流程如下:
多模態VL模型推理流程:
- 首先,多模態模型的輸入是圖片路徑/URL和文本信息;
- 對于文本信息部分的分詞處理大致與大語言模型相同,有一點區別是在送入分詞器之前需要在文本信息中添加圖片信息的占位符,就是圖片的tokenID所對應的文本符號;
- 將添加圖片占位符的文本信息進行分詞處理,生成tokenID,再送入Embedding詞嵌入模型進行向量化;
- 對于圖片信息,需要先通過給定的圖片路徑/URL加載圖片到內存;
- 引入CLIP模型,或者其他優化的CLIP結構模型對圖片進行分塊和特征提取,生成相應數量的token序列,需要注意的是文本信息中的圖片占位符的數量需要與圖片生成的token序列數量一致;
- 通過一個全鏈接層將圖片的token維度與文本信息的token維度對齊,比如生成的文本token的維度是(N,512),生成圖片token的維度是(N,768),需要將圖片的token序列進過一個【768,512】維度的一個全鏈接層,將圖片的token維度變為(N,512);
- 通過文本信息的tokenID鎖定在文本token張量中圖片占位符的起止位置,然后將對齊維度的圖片token序列插入到對應的文本token張量中,替換掉原來圖片占位符tokenID所生成的張量,這樣就將文本張量和圖片張量融合為一個張量矩陣;
- 后面的操作就和大語言模型沒有什么區別了,送入N個transformer模塊進行自注意力計算、旋轉位置編碼、前饋神經網絡運算,預測下一個token,循環往復,直到預測終止符或者達到最大上下文長度停止推理;?
二、VLM推理流程源碼?
? ? ? ?項目基于minimind-v,大家自行下載源碼和對應模型權重,這里不做過多贅述,下載好后在項目中的一級目錄下創建一個jujupyterNotebook文件;項目的推理代碼是minimind-v/eval_vlm.py,以下是該腳本的全部代碼,我們通過jujupyterNotebook將其拆解;
# minimind-v/eval_vlm.pyimport argparse
import os
import random
import numpy as np
import torch
import warnings
from PIL import Image
from transformers import AutoTokenizer, AutoModelForCausalLM
from model.model_vlm import MiniMindVLM
from model.VLMConfig import VLMConfig
from transformers import logging as hf_logginghf_logging.set_verbosity_error()warnings.filterwarnings('ignore')def count_parameters(model):return sum(p.numel() for p in model.parameters() if p.requires_grad)def init_model(lm_config, device):tokenizer = AutoTokenizer.from_pretrained('./model/minimind_tokenizer')if args.load == 0:moe_path = '_moe' if args.use_moe else ''modes = {0: 'pretrain_vlm', 1: 'sft_vlm', 2: 'sft_vlm_multi'}ckp = f'./{args.out_dir}/{modes[args.model_mode]}_{args.dim}{moe_path}.pth'model = MiniMindVLM(lm_config)state_dict = torch.load(ckp, map_location=device)model.load_state_dict({k: v for k, v in state_dict.items() if 'mask' not in k}, strict=False)else:transformers_model_path = 'MiniMind2-V'tokenizer = AutoTokenizer.from_pretrained(transformers_model_path)model = AutoModelForCausalLM.from_pretrained(transformers_model_path, trust_remote_code=True)print(f'VLM參數量:{sum(p.numel() for p in model.parameters() if p.requires_grad) / 1e6:.3f} 百萬')vision_model, preprocess = MiniMindVLM.get_vision_model()return model.eval().to(device), tokenizer, vision_model.eval().to(device), preprocessdef setup_seed(seed):random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falseif __name__ == "__main__":parser = argparse.ArgumentParser(description="Chat with MiniMind")parser.add_argument('--lora_name', default='None', type=str)parser.add_argument('--out_dir', default='out', type=str)parser.add_argument('--temperature', default=0.65, type=float)parser.add_argument('--top_p', default=0.85, type=float)parser.add_argument('--device', default='cuda' if torch.cuda.is_available() else 'cpu', type=str)# MiniMind2-Small (26M):(dim=512, n_layers=8)# MiniMind2 (104M):(dim=768, n_layers=16)parser.add_argument('--dim', default=512, type=int)parser.add_argument('--n_layers', default=8, type=int)parser.add_argument('--max_seq_len', default=8192, type=int)parser.add_argument('--use_moe', default=False, type=bool)# 默認單圖推理,設置為2為多圖推理parser.add_argument('--use_multi', default=1, type=int)parser.add_argument('--stream', default=True, type=bool)parser.add_argument('--load', default=0, type=int, help="0: 原生torch權重,1: transformers加載")parser.add_argument('--model_mode', default=1, type=int,help="0: Pretrain模型,1: SFT模型,2: SFT-多圖模型 (beta拓展)")args = parser.parse_args()lm_config = VLMConfig(dim=args.dim, n_layers=args.n_layers, max_seq_len=args.max_seq_len, use_moe=args.use_moe)model, tokenizer, vision_model, preprocess = init_model(lm_config, args.device)def chat_with_vlm(prompt, pixel_tensors, image_names):messages = [{"role": "user", "content": prompt}]new_prompt = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)[-args.max_seq_len + 1:]print(f'[Image]: {image_names}')with torch.no_grad():x = torch.tensor(tokenizer(new_prompt)['input_ids'], device=args.device).unsqueeze(0)outputs = model.generate(x,eos_token_id=tokenizer.eos_token_id,max_new_tokens=args.max_seq_len,temperature=args.temperature,top_p=args.top_p,stream=True,pad_token_id=tokenizer.pad_token_id,pixel_tensors=pixel_tensors)print('🤖?: ', end='')try:if not args.stream:print(tokenizer.decode(outputs.squeeze()[x.shape[1]:].tolist(), skip_special_tokens=True), end='')else:history_idx = 0for y in outputs:answer = tokenizer.decode(y[0].tolist(), skip_special_tokens=True)if (answer and answer[-1] == '�') or not answer:continueprint(answer[history_idx:], end='', flush=True)history_idx = len(answer)except StopIteration:print("No answer")print('\n')# 單圖推理:每1個圖像單獨推理if args.use_multi == 1:image_dir = './dataset/eval_images/'prompt = f"{model.params.image_special_token}\n描述一下這個圖像的內容。"for image_file in os.listdir(image_dir):image = Image.open(os.path.join(image_dir, image_file)).convert('RGB')pixel_tensors = MiniMindVLM.image2tensor(image, preprocess).to(args.device).unsqueeze(0)chat_with_vlm(prompt, pixel_tensors, image_file)# 2圖推理:目錄下的兩個圖像編碼,一次性推理(power by )if args.use_multi == 2:args.model_mode = 2image_dir = './dataset/eval_multi_images/bird/'prompt = (f"{lm_config.image_special_token}\n"f"{lm_config.image_special_token}\n"f"比較一下兩張圖像的異同點。")pixel_tensors_multi = []for image_file in os.listdir(image_dir):image = Image.open(os.path.join(image_dir, image_file)).convert('RGB')pixel_tensors_multi.append(MiniMindVLM.image2tensor(image, preprocess))pixel_tensors = torch.cat(pixel_tensors_multi, dim=0).to(args.device).unsqueeze(0)# 同樣內容重復10次for _ in range(10):chat_with_vlm(prompt, pixel_tensors, (', '.join(os.listdir(image_dir))))
2.1 導包
代碼:
import argparse
import os
import random
import numpy as np
import torch
import warnings
from PIL import Image
from transformers import AutoTokenizer, AutoModelForCausalLM
from model.model_vlm import MiniMindVLM
from model.VLMConfig import VLMConfig
from transformers import logging as hf_logginghf_logging.set_verbosity_error()warnings.filterwarnings('ignore')
2.2 定義超參類
代碼:
class Args():def __init__(self):self.lora_name = Noneself.out_dir = 'out'self.temperature = 0.65self.top_p = 0.85self.device = 'cpu'self.dim = 512self.n_layers = 8self.max_seq_len = 8192self.use_moe = Falseself.use_multi = 1self.stream = Trueself.load = 0self.model_mode = 1args = Args()2.3 定義模型加載配置參數
? ? ? ?這里選擇sft_vlm_512.pth權重文件;
代碼:
lm_config = VLMConfig(dim=args.dim, n_layers=args.n_layers, max_seq_len=args.max_seq_len, use_moe=args.use_moe)2.4 加載VLM模型和分詞器
? ? ? ?通過代碼2的輸出結果,我們可以看到VLM模型里面有CLIP模型結構;
代碼1:
tokenizer = AutoTokenizer.from_pretrained('./model/minimind_tokenizer')moe_path = '_moe' if args.use_moe else ''
modes = {0: 'pretrain_vlm', 1: 'sft_vlm', 2: 'sft_vlm_multi'}
ckp = f'./{args.out_dir}/MiniMind2-V-PyTorch/{modes[args.model_mode]}_{args.dim}{moe_path}.pth'
model = MiniMindVLM(lm_config)
state_dict = torch.load(ckp, map_location=device)
model.load_state_dict({k: v for k, v in state_dict.items() if 'mask' not in k}, strict=False)代碼2:
for name, tensor in model.state_dict().items():print(name)輸出結果2:
tok_embeddings.weight
layers.0.attention.wq.weight
layers.0.attention.wk.weight
layers.0.attention.wv.weight
layers.0.attention.wo.weight
layers.0.attention_norm.weight
layers.0.ffn_norm.weight
layers.0.feed_forward.w1.weight
layers.0.feed_forward.w2.weight
layers.0.feed_forward.w3.weight
layers.1.attention.wq.weight
layers.1.attention.wk.weight
layers.1.attention.wv.weight
layers.1.attention.wo.weight
layers.1.attention_norm.weight
layers.1.ffn_norm.weight
layers.1.feed_forward.w1.weight
layers.1.feed_forward.w2.weight
layers.1.feed_forward.w3.weight
layers.2.attention.wq.weight
layers.2.attention.wk.weight
layers.2.attention.wv.weight
layers.2.attention.wo.weight
layers.2.attention_norm.weight
layers.2.ffn_norm.weight
layers.2.feed_forward.w1.weight
layers.2.feed_forward.w2.weight
layers.2.feed_forward.w3.weight
layers.3.attention.wq.weight
layers.3.attention.wk.weight
layers.3.attention.wv.weight
layers.3.attention.wo.weight
layers.3.attention_norm.weight
layers.3.ffn_norm.weight
layers.3.feed_forward.w1.weight
layers.3.feed_forward.w2.weight
layers.3.feed_forward.w3.weight
layers.4.attention.wq.weight
layers.4.attention.wk.weight
layers.4.attention.wv.weight
layers.4.attention.wo.weight
layers.4.attention_norm.weight
layers.4.ffn_norm.weight
layers.4.feed_forward.w1.weight
layers.4.feed_forward.w2.weight
layers.4.feed_forward.w3.weight
layers.5.attention.wq.weight
layers.5.attention.wk.weight
layers.5.attention.wv.weight
layers.5.attention.wo.weight
layers.5.attention_norm.weight
layers.5.ffn_norm.weight
layers.5.feed_forward.w1.weight
layers.5.feed_forward.w2.weight
layers.5.feed_forward.w3.weight
layers.6.attention.wq.weight
layers.6.attention.wk.weight
layers.6.attention.wv.weight
layers.6.attention.wo.weight
layers.6.attention_norm.weight
layers.6.ffn_norm.weight
layers.6.feed_forward.w1.weight
layers.6.feed_forward.w2.weight
layers.6.feed_forward.w3.weight
layers.7.attention.wq.weight
layers.7.attention.wk.weight
layers.7.attention.wv.weight
layers.7.attention.wo.weight
layers.7.attention_norm.weight
layers.7.ffn_norm.weight
layers.7.feed_forward.w1.weight
layers.7.feed_forward.w2.weight
layers.7.feed_forward.w3.weight
norm.weight
output.weight
vision_encoder.logit_scale
vision_encoder.text_model.embeddings.token_embedding.weight
vision_encoder.text_model.embeddings.position_embedding.weight
vision_encoder.text_model.encoder.layers.0.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.0.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.0.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.0.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.0.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.0.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.0.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.0.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.0.layer_norm1.weight
vision_encoder.text_model.encoder.layers.0.layer_norm1.bias
vision_encoder.text_model.encoder.layers.0.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.0.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.0.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.0.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.0.layer_norm2.weight
vision_encoder.text_model.encoder.layers.0.layer_norm2.bias
vision_encoder.text_model.encoder.layers.1.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.1.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.1.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.1.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.1.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.1.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.1.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.1.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.1.layer_norm1.weight
vision_encoder.text_model.encoder.layers.1.layer_norm1.bias
vision_encoder.text_model.encoder.layers.1.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.1.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.1.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.1.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.1.layer_norm2.weight
vision_encoder.text_model.encoder.layers.1.layer_norm2.bias
vision_encoder.text_model.encoder.layers.2.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.2.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.2.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.2.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.2.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.2.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.2.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.2.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.2.layer_norm1.weight
vision_encoder.text_model.encoder.layers.2.layer_norm1.bias
vision_encoder.text_model.encoder.layers.2.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.2.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.2.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.2.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.2.layer_norm2.weight
vision_encoder.text_model.encoder.layers.2.layer_norm2.bias
vision_encoder.text_model.encoder.layers.3.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.3.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.3.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.3.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.3.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.3.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.3.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.3.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.3.layer_norm1.weight
vision_encoder.text_model.encoder.layers.3.layer_norm1.bias
vision_encoder.text_model.encoder.layers.3.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.3.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.3.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.3.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.3.layer_norm2.weight
vision_encoder.text_model.encoder.layers.3.layer_norm2.bias
vision_encoder.text_model.encoder.layers.4.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.4.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.4.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.4.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.4.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.4.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.4.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.4.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.4.layer_norm1.weight
vision_encoder.text_model.encoder.layers.4.layer_norm1.bias
vision_encoder.text_model.encoder.layers.4.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.4.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.4.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.4.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.4.layer_norm2.weight
vision_encoder.text_model.encoder.layers.4.layer_norm2.bias
vision_encoder.text_model.encoder.layers.5.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.5.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.5.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.5.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.5.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.5.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.5.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.5.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.5.layer_norm1.weight
vision_encoder.text_model.encoder.layers.5.layer_norm1.bias
vision_encoder.text_model.encoder.layers.5.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.5.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.5.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.5.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.5.layer_norm2.weight
vision_encoder.text_model.encoder.layers.5.layer_norm2.bias
vision_encoder.text_model.encoder.layers.6.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.6.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.6.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.6.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.6.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.6.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.6.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.6.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.6.layer_norm1.weight
vision_encoder.text_model.encoder.layers.6.layer_norm1.bias
vision_encoder.text_model.encoder.layers.6.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.6.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.6.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.6.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.6.layer_norm2.weight
vision_encoder.text_model.encoder.layers.6.layer_norm2.bias
vision_encoder.text_model.encoder.layers.7.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.7.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.7.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.7.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.7.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.7.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.7.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.7.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.7.layer_norm1.weight
vision_encoder.text_model.encoder.layers.7.layer_norm1.bias
vision_encoder.text_model.encoder.layers.7.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.7.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.7.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.7.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.7.layer_norm2.weight
vision_encoder.text_model.encoder.layers.7.layer_norm2.bias
vision_encoder.text_model.encoder.layers.8.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.8.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.8.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.8.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.8.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.8.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.8.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.8.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.8.layer_norm1.weight
vision_encoder.text_model.encoder.layers.8.layer_norm1.bias
vision_encoder.text_model.encoder.layers.8.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.8.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.8.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.8.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.8.layer_norm2.weight
vision_encoder.text_model.encoder.layers.8.layer_norm2.bias
vision_encoder.text_model.encoder.layers.9.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.9.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.9.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.9.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.9.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.9.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.9.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.9.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.9.layer_norm1.weight
vision_encoder.text_model.encoder.layers.9.layer_norm1.bias
vision_encoder.text_model.encoder.layers.9.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.9.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.9.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.9.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.9.layer_norm2.weight
vision_encoder.text_model.encoder.layers.9.layer_norm2.bias
vision_encoder.text_model.encoder.layers.10.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.10.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.10.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.10.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.10.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.10.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.10.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.10.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.10.layer_norm1.weight
vision_encoder.text_model.encoder.layers.10.layer_norm1.bias
vision_encoder.text_model.encoder.layers.10.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.10.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.10.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.10.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.10.layer_norm2.weight
vision_encoder.text_model.encoder.layers.10.layer_norm2.bias
vision_encoder.text_model.encoder.layers.11.self_attn.k_proj.weight
vision_encoder.text_model.encoder.layers.11.self_attn.k_proj.bias
vision_encoder.text_model.encoder.layers.11.self_attn.v_proj.weight
vision_encoder.text_model.encoder.layers.11.self_attn.v_proj.bias
vision_encoder.text_model.encoder.layers.11.self_attn.q_proj.weight
vision_encoder.text_model.encoder.layers.11.self_attn.q_proj.bias
vision_encoder.text_model.encoder.layers.11.self_attn.out_proj.weight
vision_encoder.text_model.encoder.layers.11.self_attn.out_proj.bias
vision_encoder.text_model.encoder.layers.11.layer_norm1.weight
vision_encoder.text_model.encoder.layers.11.layer_norm1.bias
vision_encoder.text_model.encoder.layers.11.mlp.fc1.weight
vision_encoder.text_model.encoder.layers.11.mlp.fc1.bias
vision_encoder.text_model.encoder.layers.11.mlp.fc2.weight
vision_encoder.text_model.encoder.layers.11.mlp.fc2.bias
vision_encoder.text_model.encoder.layers.11.layer_norm2.weight
vision_encoder.text_model.encoder.layers.11.layer_norm2.bias
vision_encoder.text_model.final_layer_norm.weight
vision_encoder.text_model.final_layer_norm.bias
vision_encoder.vision_model.embeddings.class_embedding
vision_encoder.vision_model.embeddings.patch_embedding.weight
vision_encoder.vision_model.embeddings.position_embedding.weight
vision_encoder.vision_model.pre_layrnorm.weight
vision_encoder.vision_model.pre_layrnorm.bias
vision_encoder.vision_model.encoder.layers.0.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.0.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.0.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.0.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.0.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.0.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.0.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.0.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.0.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.0.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.0.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.0.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.0.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.0.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.0.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.0.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.1.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.1.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.1.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.1.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.1.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.1.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.1.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.1.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.1.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.1.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.1.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.1.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.1.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.1.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.1.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.1.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.2.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.2.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.2.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.2.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.2.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.2.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.2.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.2.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.2.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.2.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.2.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.2.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.2.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.2.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.2.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.2.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.3.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.3.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.3.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.3.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.3.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.3.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.3.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.3.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.3.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.3.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.3.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.3.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.3.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.3.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.3.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.3.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.4.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.4.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.4.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.4.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.4.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.4.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.4.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.4.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.4.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.4.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.4.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.4.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.4.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.4.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.4.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.4.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.5.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.5.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.5.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.5.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.5.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.5.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.5.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.5.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.5.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.5.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.5.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.5.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.5.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.5.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.5.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.5.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.6.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.6.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.6.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.6.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.6.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.6.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.6.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.6.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.6.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.6.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.6.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.6.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.6.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.6.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.6.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.6.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.7.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.7.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.7.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.7.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.7.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.7.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.7.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.7.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.7.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.7.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.7.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.7.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.7.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.7.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.7.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.7.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.8.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.8.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.8.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.8.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.8.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.8.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.8.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.8.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.8.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.8.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.8.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.8.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.8.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.8.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.8.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.8.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.9.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.9.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.9.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.9.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.9.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.9.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.9.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.9.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.9.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.9.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.9.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.9.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.9.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.9.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.9.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.9.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.10.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.10.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.10.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.10.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.10.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.10.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.10.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.10.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.10.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.10.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.10.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.10.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.10.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.10.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.10.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.10.layer_norm2.bias
vision_encoder.vision_model.encoder.layers.11.self_attn.k_proj.weight
vision_encoder.vision_model.encoder.layers.11.self_attn.k_proj.bias
vision_encoder.vision_model.encoder.layers.11.self_attn.v_proj.weight
vision_encoder.vision_model.encoder.layers.11.self_attn.v_proj.bias
vision_encoder.vision_model.encoder.layers.11.self_attn.q_proj.weight
vision_encoder.vision_model.encoder.layers.11.self_attn.q_proj.bias
vision_encoder.vision_model.encoder.layers.11.self_attn.out_proj.weight
vision_encoder.vision_model.encoder.layers.11.self_attn.out_proj.bias
vision_encoder.vision_model.encoder.layers.11.layer_norm1.weight
vision_encoder.vision_model.encoder.layers.11.layer_norm1.bias
vision_encoder.vision_model.encoder.layers.11.mlp.fc1.weight
vision_encoder.vision_model.encoder.layers.11.mlp.fc1.bias
vision_encoder.vision_model.encoder.layers.11.mlp.fc2.weight
vision_encoder.vision_model.encoder.layers.11.mlp.fc2.bias
vision_encoder.vision_model.encoder.layers.11.layer_norm2.weight
vision_encoder.vision_model.encoder.layers.11.layer_norm2.bias
vision_encoder.vision_model.post_layernorm.weight
vision_encoder.vision_model.post_layernorm.bias
vision_encoder.visual_projection.weight
vision_encoder.text_projection.weight
vision_proj.vision_proj.0.weight2.5 加載CLIP模型
代碼:
from transformers import CLIPProcessor, CLIPModelvision_model = CLIPModel.from_pretrained('./model/vision_model/clip-vit-base-patch16')
vision_processor = CLIPProcessor.from_pretrained('./model/vision_model/clip-vit-base-patch16')2.6? 加載圖片及提示詞
? ? ? ?輸出結果中的“@”就是圖片的占位符,一共有196個,對應之后圖片編碼后的196個token序列;
代碼:
image_dir = './dataset/eval_images/彩虹瀑布-Rainbow-Falls.jpg'
image = Image.open(os.path.join(image_dir, image_file)).convert('RGB')prompt = f"{model.params.image_special_token}\n描述一下這個圖像的內容。"
print(prompt)輸出結果:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
描述一下這個圖像的內容。2.7 圖片轉tensor
? ? ? ?通過vision_processor將圖片進行了resize操作、維度轉換操作和歸一化操作,這是常見的圖片進行深度學習模型推理前的預處理操作;
代碼1:
def image2tensor(image, processor):if image.mode in ['RGBA', 'LA']: image = image.convert('RGB')inputs = processor(images=image, return_tensors="pt")['pixel_values']return inputs代碼2:
inputs = image2tensor(image, vision_processor)
print(inputs.shape)pixel_tensors = inputs.to('cpu').unsqueeze(0)
print(pixel_tensors.shape)bs, num, c, im_h, im_w = pixel_tensors.shape輸出結果2:
torch.Size([1, 3, 224, 224])
torch.Size([1, 1, 3, 224, 224])2.8 圖片Embedding
? ? ? ?上面我們將圖片預處理后的長和寬為224,然后使用的是patch=16的CLIP模型,那么就會得到(224/16)^2=196個序列;
代碼1:
import torchdef get_image_embeddings(image_tensors, vision_model):with torch.no_grad():outputs = vision_model.vision_model(pixel_values=image_tensors)img_embedding = outputs.last_hidden_state[:, 1:, :].squeeze()return img_embedding代碼2:
b = get_image_embeddings(a, vision_model)
print(b.shape)vision_tensors = torch.stack([b], dim=stack_dim)
print(vision_tensors.shape)輸出結果2:
torch.Size([196, 768])
torch.Size([1, 196, 768])2.9 整體forward推理?
代碼:
def forward(self,input_ids: Optional[torch.Tensor] = None,past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,use_cache: bool = False,**args):start_pos = args.get('start_pos', 0)# 0pixel_tensors = args.get('pixel_tensors', None)# 1h = self.tok_embeddings(input_ids)# 2if pixel_tensors is not None and start_pos == 0:if len(pixel_tensors.shape) == 6:pixel_tensors = pixel_tensors.squeeze(2)bs, num, c, im_h, im_w = pixel_tensors.shapestack_dim = 1 if bs > 1 else 0# 2.1vision_tensors = torch.stack([MiniMindVLM.get_image_embeddings(pixel_tensors[:, i, :, :, :], self.vision_encoder)for i in range(num)], dim=stack_dim)# 2.2h = self.count_vision_proj(tokens=input_ids, h=h, vision_tensors=vision_tensors, seqlen=input_ids.shape[1])# 3pos_cis = self.pos_cis[start_pos:start_pos + input_ids.shape[1]]past_kvs = []for l, layer in enumerate(self.layers):h, past_kv = layer(h, pos_cis,past_key_value=past_key_values[l] if past_key_values else None,use_cache=use_cache)past_kvs.append(past_kv)logits = self.output(self.norm(h))aux_loss = sum(l.feed_forward.aux_loss for l in self.layers if isinstance(l.feed_forward, MOEFeedForward))self.OUT.__setitem__('logits', logits)self.OUT.__setitem__('aux_loss', aux_loss)self.OUT.__setitem__('past_key_values', past_kvs)return self.OUT
- 0——?pixel_tensors是上面通過對圖片預處理獲得的歸一化后的張量;
- 1——h是通過模型的Embedding層轉化后的token張量;
- 2——判斷有圖片信息,并且是第一輪推理時,嵌入圖片token張量到h里;
- 2.1——vision_tensors就是上面講到的通過CLIP模型將圖片進行patch分割后通過VIT進行特征提取后的特征圖;
- 2.2——count_vision_proj()函數就是將圖片的token序列添加到h中的具體實現,返回的h就是已經嵌入了圖片token序列的文本圖片融合的token序列;下面我們具體看一下count_vision_proj函數;
- 3——再往下的操作,包括進行旋轉位置編碼,進行自注意力機制的運算就和LLM完全相同了,這里就不再贅述,可以查看之前關于LLM模型推理的博客;
2.9.1 圖像token與文本token融合——count_vision_proj?
代碼:
def count_vision_proj(self, tokens, h, vision_tensors=None, seqlen=512):# 1def find_indices(tokens, image_ids):image_ids_tensor = torch.tensor(image_ids).to(tokens.device)len_image_ids = len(image_ids)if len_image_ids > tokens.size(1):return Nonetokens_view = tokens.unfold(1, len_image_ids, 1)matches = (tokens_view == image_ids_tensor).all(dim=2)return {batch_idx: [(idx.item(), idx.item() + len_image_ids - 1) for idx inmatches[batch_idx].nonzero(as_tuple=True)[0]]for batch_idx in range(tokens.size(0)) if matches[batch_idx].any()} or None# 2image_indices = find_indices(tokens, self.params.image_ids)# 3if vision_tensors is not None and image_indices:# 3.1vision_proj = self.vision_proj(vision_tensors)if len(vision_proj.shape) == 3:vision_proj = vision_proj.unsqueeze(0)new_h = []# 3.2for i in range(h.size(0)):if i in image_indices:h_i = h[i]img_idx = 0for start_idx, end_idx in image_indices[i]:if img_idx < vision_proj.size(1):h_i = torch.cat((h_i[:start_idx], vision_proj[i][img_idx], h_i[end_idx + 1:]), dim=0)[:seqlen]img_idx += 1new_h.append(h_i)else:new_h.append(h[i])return torch.stack(new_h, dim=0)return h
- 1——find_indices函數用于在文本tokenID中尋找圖片占位tokenID的起止位置的索引,返回是一個字典,每個key對應一個圖片占位,value對應該圖片占位的起止索引;
- 2——輸入文本tokenID和圖片占位tokenID尋找對應索引;
- 3——vision_tensors是clip輸出的圖片的特征圖,如果圖片特征存在并且在文本tokenID中找到對應位置,則進行圖片token序列嵌入;
- 3.1——vision_proj層是一個全鏈接層,目的是將圖片token張量的維度與文本token維度對齊,在這里文本的維度是512,但是通過clip輸出的圖片的token維度是768維,所以需要通過一個【768,512】的全鏈接層矩陣進行維度轉換;
- 3.2——下面的for循環就是根據找到的具體位置索引,將對應的圖片的token序列按照對應位置替換掉文本token序列中的圖片占位符張量,全部替換后返回新的h,這時的token序列就包含了文本和圖片的融合信息;
三、總結?
? ? ? ?通過該博客,分享了LLM和VLM在模型前處理階段等一些方面的區別;相較于LLM模型,VLM只是在輸入信息轉換為token序列時有所不同,目的就是將圖片的特征與文本的特征可以結合在一起,形成統一的token序列,在位置編碼上、模型的自注意力運算、模型預測token轉化后處理的流程上其實都是一致的。




 | GmaGIS V0.0.1a3 更新日志)














