在科技飛速發展的當下,類人機器人逐漸走進我們的視野,它們有著和人類相似的外形,看起來能像人類一樣在各種環境里完成復雜任務,潛力巨大。但實際上,讓類人機器人真正發揮出實力,還面臨著重重挑戰。
這篇文章,將給大家帶來一個Benchmark的工作:HumanoidBench。
它是一個新的模擬基準平臺。工作鏈接:https://arxiv.org/pdf/2403.10506
如下圖所示:
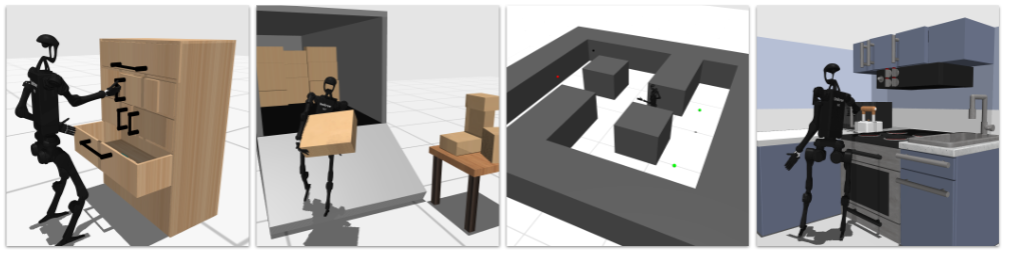
1、研究背景:類人機器人發展的困境
一直以來,類人機器人都被寄予厚望,大家期待它們能在日常生活中無縫協助人類。像波士頓動力的 Atlas、特斯拉的 Optimus、宇樹的 H1 等,這些類人機器人在硬件方面取得了很大進展。可它們的控制器大多是針對特定任務專門設計的,每次遇到新任務或新環境,都得花費大量精力重新設計,而且整體的全身控制能力也很有限。
近年來,機器人學習在操作和移動方面都有了一定進展。但要把這些學習算法應用到類人機器人上,卻困難重重。主要原因是在現實世界中對類人機器人進行實驗,成本太高,還存在安全風險。比如,類人機器人的硬件設備價格昂貴,一旦在實驗中損壞,維修成本很高;而且如果機器人在實驗過程中失控,還可能對周圍環境和人員造成傷害。
為了推動類人機器人研究的快速發展,就需要一個合適的測試平臺。以往的模擬環境和基準測試,要么只關注簡單的操作任務,像抓取和放置;要么只側重于移動,忽略了全身控制和復雜任務的挑戰。就算有些引入了復雜任務,但在任務多樣性、模型準確性等方面還是有所欠缺。所以,開發一個全面的、能涵蓋各種復雜任務的類人機器人基準測試平臺就顯得尤為重要,這就是 HumanoidBench 誕生的背景。
2、方法——打造類人機器人的試煉場
2.1 模擬環境搭建
HumanoidBench 的模擬環境基于 MuJoCo 物理引擎構建,這個引擎以運行速度快、物理模擬準確著稱,為類人機器人的模擬提供了可靠的基礎。在這個環境中,主要使用宇樹 H1 類人機器人,它相對成本較低,并且有精確的模擬模型。H1 機器人配備了兩只靈巧的 Shadow Hands,這讓機器人具備了很強的操作能力。同時,環境中還提供了其他機器人模型,像宇樹 G1、敏捷機器人 Digit,以及不同的末端執行器,比如 Robotiq 2F - 85 平行夾爪和宇樹的 13 自由度手,滿足不同研究的需求。
如下圖:
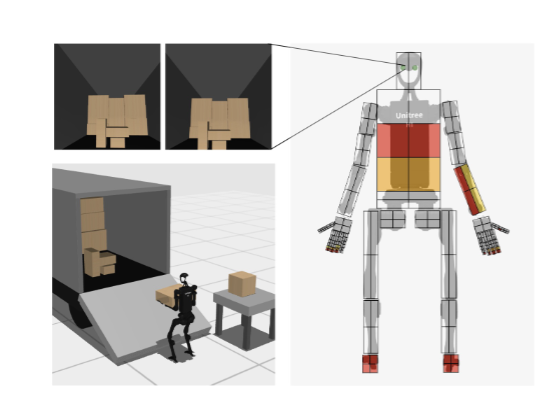
從機器人的身體和手部設置來看,研究人員對不同機器人模型進行了細致的調整。比如,為了讓模擬機器人更接近人類形態,去掉了 Shadow Hands 原本笨重的前臂,使機器人的手部更符合未來類人機器人的發展趨勢。在觀察和動作空間方面,也有明確的設定。觀察空間包含機器人的本體感受狀態(關節角度和速度)、任務相關的環境觀察(物體的姿態和速度),還有從機器人頭部兩個攝像頭獲取的視覺觀察以及全身的觸覺感知。動作空間則通過位置控制來實現,控制頻率為 50Hz,這樣的設置能讓機器人在模擬環境中做出各種動作。
2.2 任務設計
HumanoidBench 包含了豐富多樣的任務,總共 27 個,分為 12 個移動任務和 15 個全身操作任務。這些任務從簡單到復雜,涵蓋了各種不同的場景和技能要求。
如下圖:

移動任務像是走路、站立、跑步等,看似簡單,但對于類人機器人來說卻并不輕松。以走路任務為例,機器人要保持向前的速度接近 1m/s,同時還不能摔倒,這就需要它精確控制身體的平衡和各個關節的運動。跑步任務則要求機器人以 5m/s 的速度前進,對其運動能力和協調性提出了更高的要求。還有像跨越障礙、在迷宮中導航這樣的任務,不僅考驗機器人的移動能力,還需要它具備一定的感知和決策能力。
全身操作任務就更復雜了,涉及到與物體的各種交互。比如,從卡車卸貨這個任務,機器人要先走到卡車旁,然后拿起貨物,再搬運到指定位置,這一過程需要它協調手部的抓取動作和身體的移動,還要根據貨物的重量和形狀調整力度。再比如打開不同類型的櫥柜門,像鉸鏈門、滑動門和抽屜,每種門的打開方式都不同,機器人需要學習不同的操作技巧。還有像打籃球這樣的任務,機器人要先接住從不同方向飛來的球,然后再投籃,這對它的反應速度、空間感知能力和手部操作能力都是極大的挑戰。
2.3 分層強化學習策略
針對類人機器人學習的復雜性,研究人員引入了分層強化學習(HRL)策略。在傳統的端到端強化學習中,算法很難處理高維度的動作空間和復雜的長期規劃任務,而 HRL 則將學習問題分層,把低層次的技能策略和高層次的規劃策略分開。
具體來說,在執行操作任務時,會先預訓練一個低層次的到達策略。比如在推箱子任務中,低層次策略就是讓機器人的手能夠準確地到達指定的 3D 點。這個策略就像是搭建高樓的基石,需要非常穩健。為了訓練出這樣的策略,研究人員利用了 MuJoCo MJX 提供的硬件加速功能,在大量并行環境中進行訓練。訓練完成后,低層次策略就被固定下來,高層次策略則利用這個預訓練的低層次策略,根據不同的任務需求,指揮低層次策略執行相應的動作,從而實現整個任務的完成。
3、實驗——檢驗 HumanoidBench 的有效性
3.1 實驗設置

在實驗中,研究人員選擇了四種強化學習算法作為基線進行測試,分別是 DreamerV3、TD - MPC2、SAC 和 PPO。這些算法在機器人學習領域都有一定的代表性,但在面對類人機器人的復雜任務時,表現卻各有不同。
為了確保實驗的準確性和可靠性,研究人員對每個算法都進行了約 48 小時的訓練,不同算法的訓練步數有所差異,比如 TD - MPC2 訓練 200 萬步,DreamerV3 訓練 1000 萬步。在訓練過程中,每個環境都設置了密集獎勵和稀疏子任務完成獎勵,通過這些獎勵機制來引導機器人學習正確的行為。同時,還對每個任務設置了成功的定性指標,方便評估算法的性能。
3.2 實驗結果
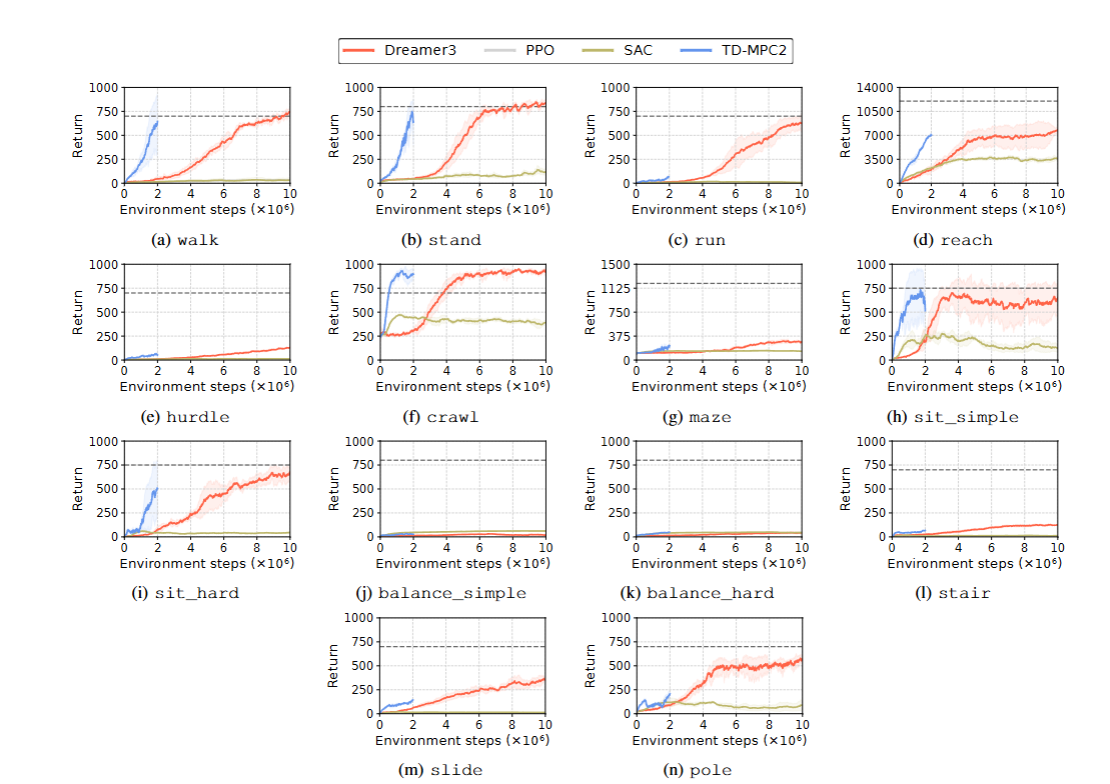
從實驗結果來看,這些基線算法在大多數任務上的表現都不太理想。在移動任務中,即使是像走路這樣看似簡單的任務,算法也需要大量的訓練步數才能學會,而且成功率也不高。這主要是因為類人機器人的狀態和動作空間維度很高,即使在移動任務中手部動作使用較少,但算法還是難以忽略手部的信息,導致策略學習變得困難。
點擊探索 HumanoidBench:類人機器人學習的新平臺查看全文









Java/python/JavaScript/C++/C語言/GO六種最佳實現)





生成隨機數并顯示波形)
)


非阻塞賦值真的并行嗎?)