目錄
2.大模型開發
2.1 模型部署
2.1.1 云服務-開放大模型API
2.1.2 本地部署
搜索模型
運行大模型
2.2 調用大模型
接口說明
提示詞角色
?編輯
會話記憶問題
2.3 大模型應用開發架構
2.3.1 技術架構
純Prompt模式
FunctionCalling
RAG檢索增強
Fine-tuning
2.3.2 技術選型
2.大模型開發
2.1 模型部署
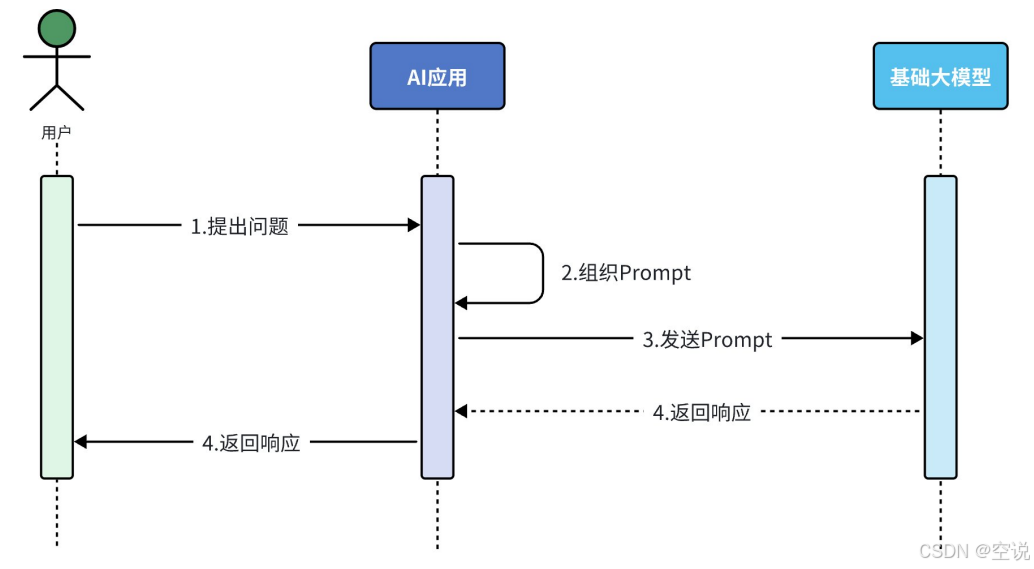
首先大模型應用開發并不是在瀏覽器中跟AI聊天。而是通過訪問模型對外暴露的API接口,實現與大模型的交互;
因此,需要有一個可訪問的大模型,通常有三種選擇:
2.1.1 云服務-開放大模型API
部署在云服務器上,部署維護簡單,部署方案簡單,全球訪問 ,缺點:數據隱私,網絡依賴,長期成本問題
通常發布大模型的官方、大多數的云平臺都會提供開放的、公共的大模型服務。以下是一些國內提供大模型服務的云平臺
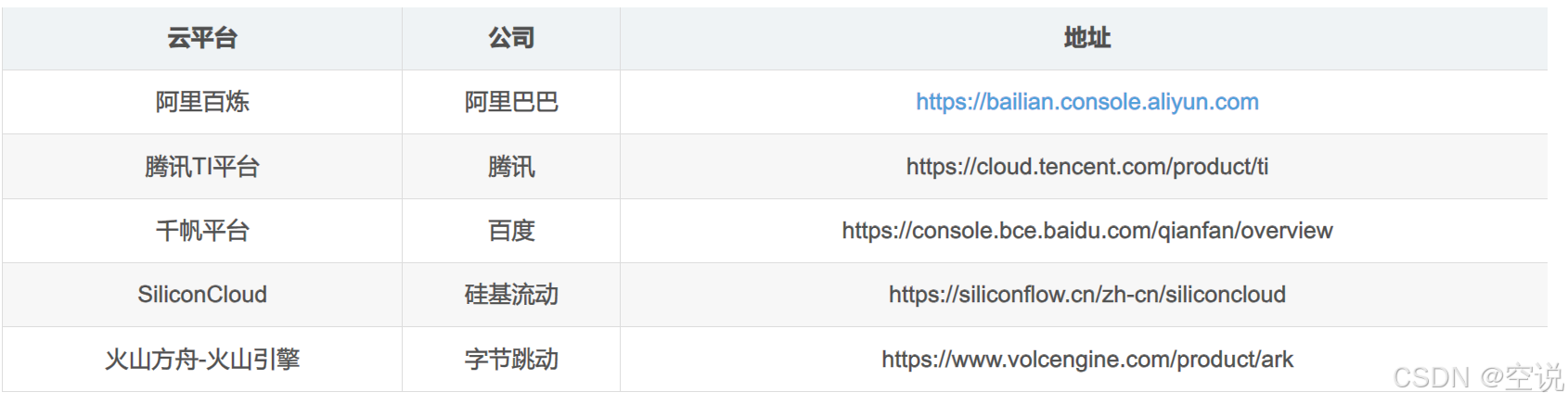
這些開放平臺并不是免費,而是按照調用時消耗的token來付費,每百萬token通常在幾毛~幾元錢,而且平臺通常都會贈送新用戶百萬token的免費使用權;
以百煉大模型為例 大模型服務平臺百煉_企業級大模型開發平臺_百煉AI應用構建-阿里云
注冊一個阿里云賬號==>然后訪問百煉平臺,開通服務(首次開通應該會贈送百萬token的使用權,包括DeepSeek-R1模型、qwen模型。)
==>申請API_KEY(百煉平臺右上角個人中心)==>創建APIKEY==>進入模型廣場
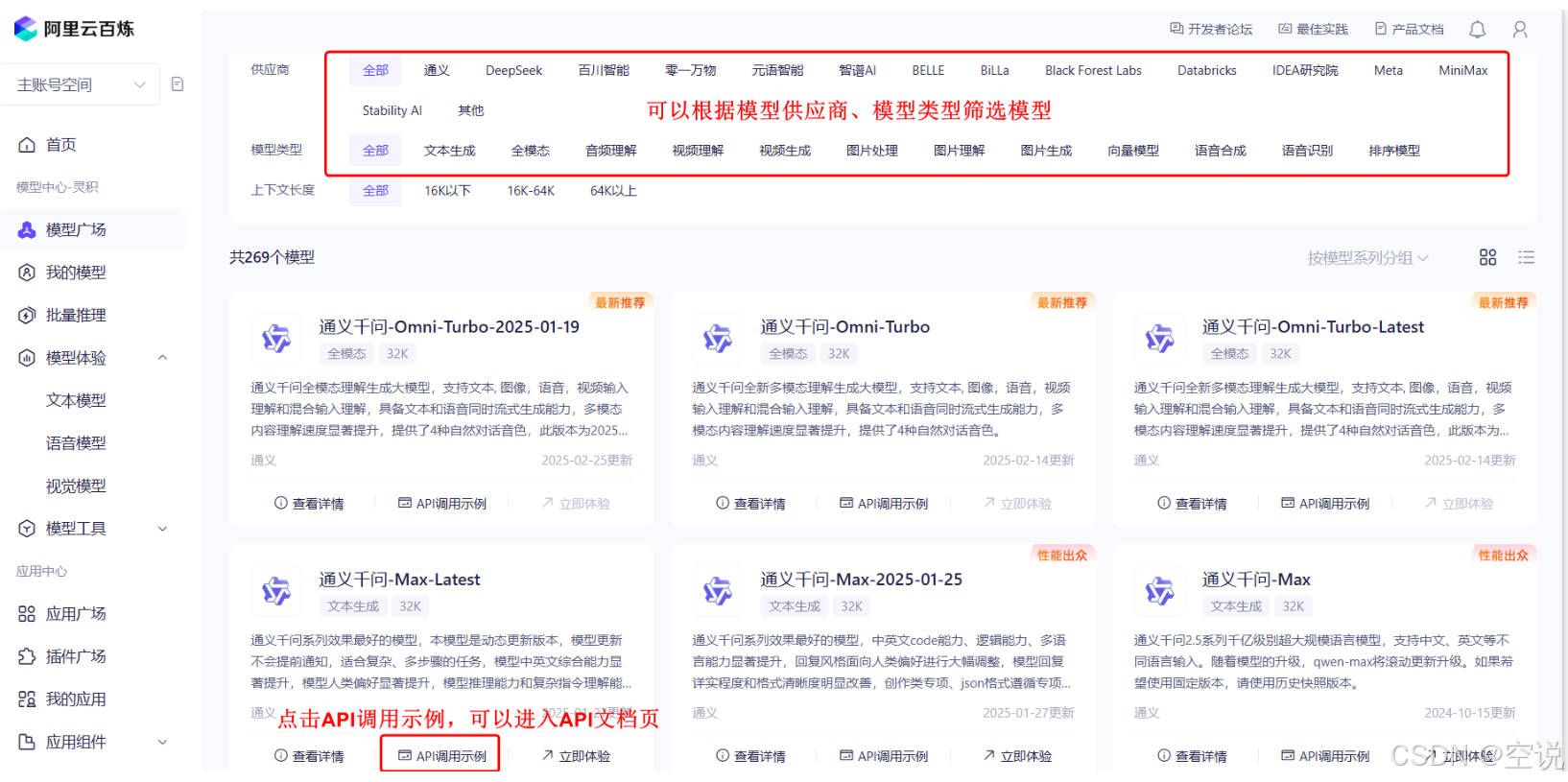
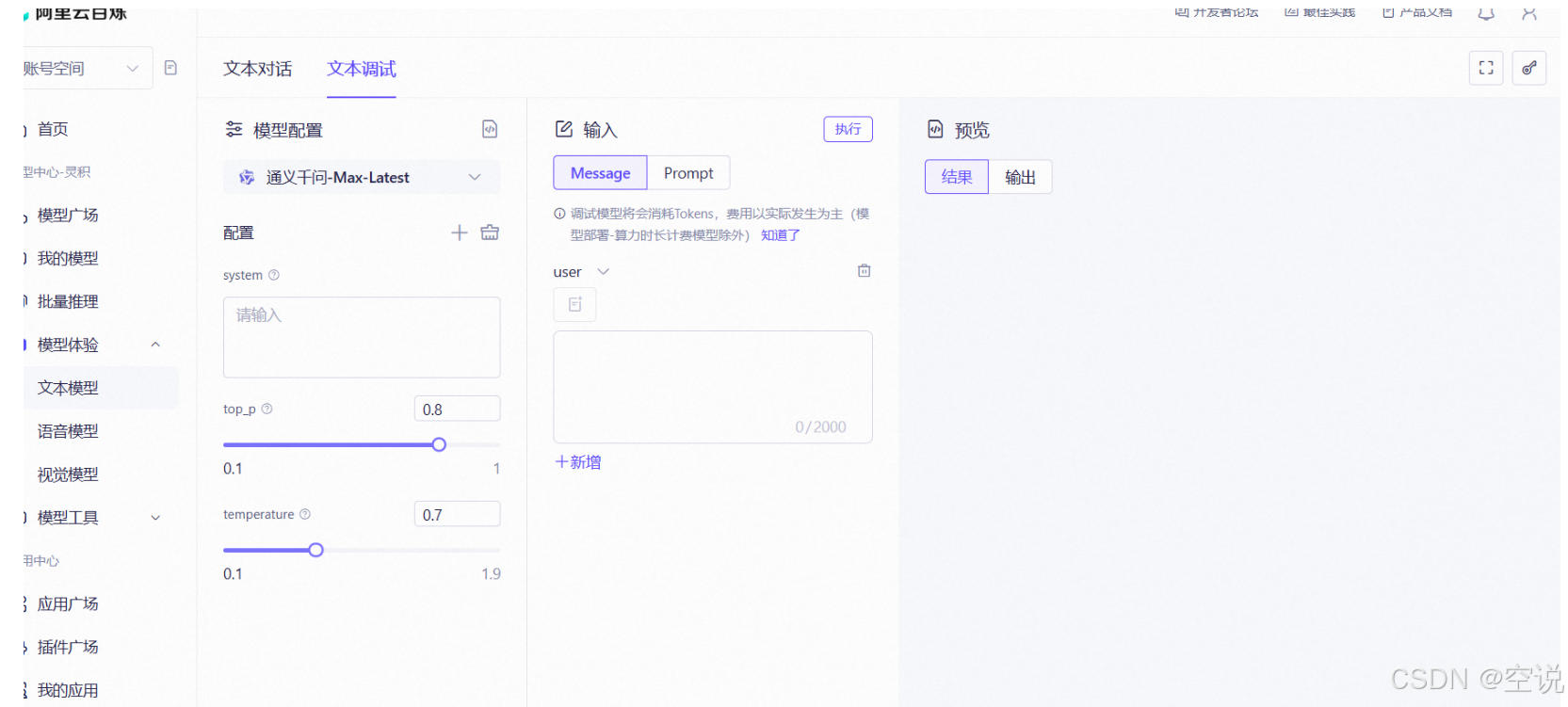
選擇一個自己喜歡的模型,然后點擊API調用示例,即可進入API文檔頁===>立即體驗==>進入API調用大模型的試驗臺==>模擬調用大模型接口
2.1.2 本地部署
數據安全,不依賴網絡,成本低,缺點:初期成本高,部署麻煩周期長
最簡單的方案是使用ollama Download Ollama on macOS,當然這種方式不推薦,閹割版
訪問官網下載查看對應模型的本地調用即可
在OllamaSetup.exe所在目錄打開cmd命令行,然后輸入命令如下:
OllamaSetup.exe /DIR=你要安裝的目錄位置
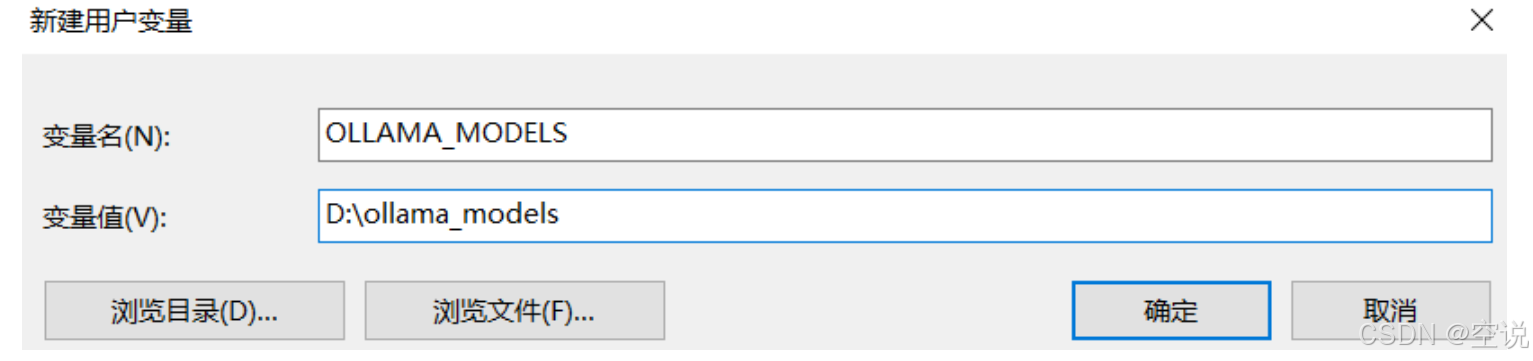
安裝完成后,還需要配置一個環境變量,更改Ollama下載和部署模型的位置。配置完成如圖:
搜索模型
-
Ollama是一個模型管理工具和平臺,它提供了很多國內外常見的模型,可以在其官網上搜索自己需要的模型:Ollama Search;
-
搜索DeepSeek-R1后,進入DeepSeek-R1頁面,會發現DeepSeek-R1也有很多版本:
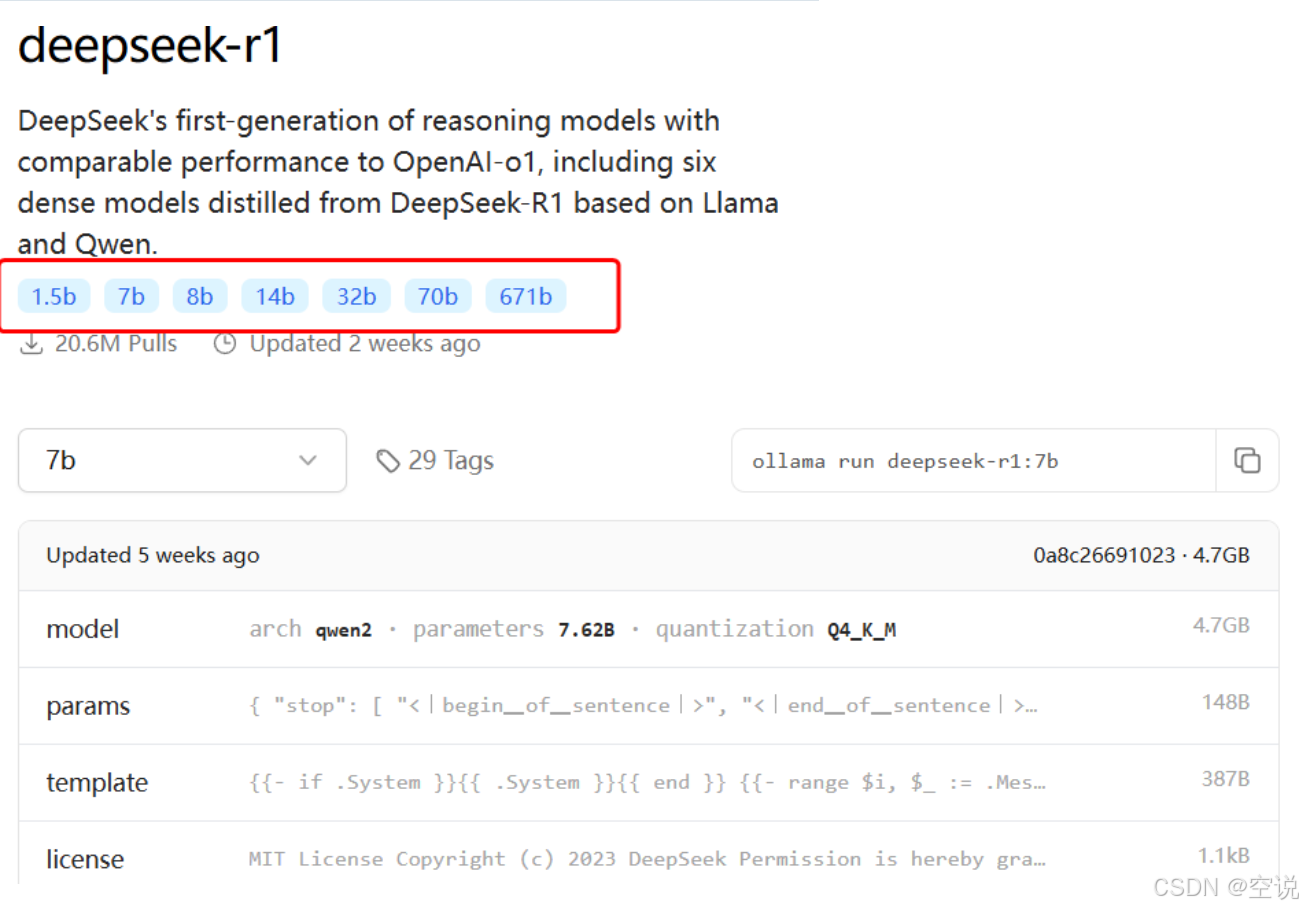
運行大模型
選擇自己電腦合適的模型后,Ollama會給出運行模型的命令: 打開cmd運行即可
ollama run deepseek-r1:7b #運行大模型
/bye #退出當前大模型
ollama ps #查看運行的大模型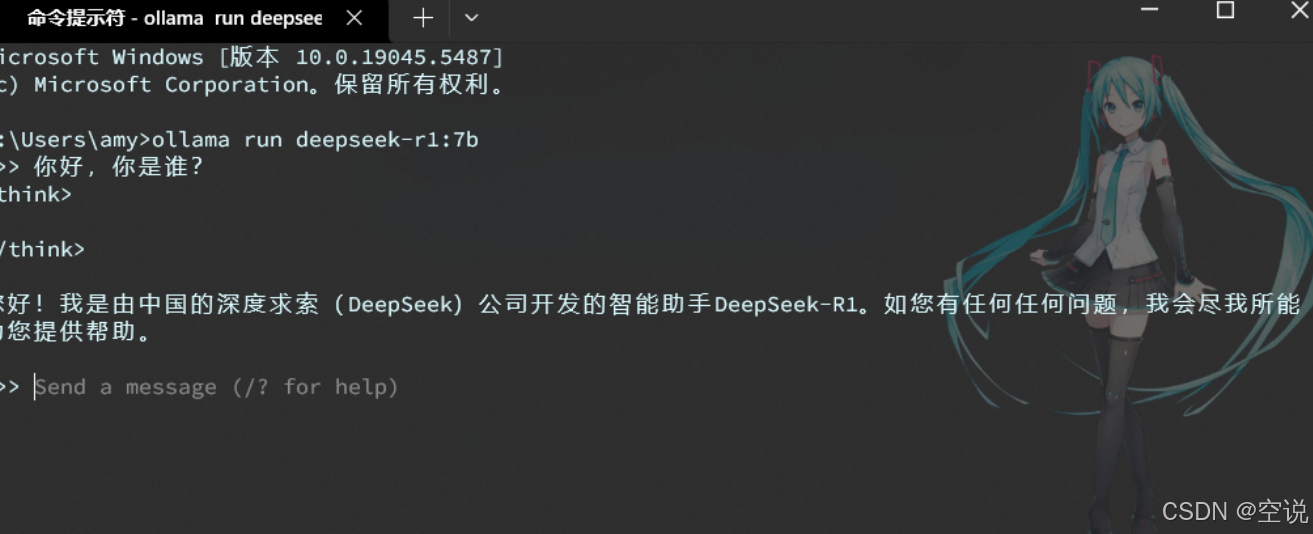 Ollama是一個模型管理工具,有點像Docker,而且命令也很像,常見命令如下:
Ollama是一個模型管理工具,有點像Docker,而且命令也很像,常見命令如下:
ollama serve # Start ollama
ollama create # Create a model from a Modelfile
ollama show # Show information for a model
ollama run # Run a model
ollama stop # Stop a running model
ollama pull # Pull a model from a registry
ollama push # Push a model to a registry
ollama list # List models
ollama ps # List running models
ollama cp # Copy a model
ollama rm # Remove a model
ollama help # Help about any command2.2 調用大模型
調用大模型并不是在瀏覽器中跟AI聊天,而是通過訪問模型對外暴露的API接口,實現與大模型的交互;所以要學習大模型應用開發,就必須掌握模型的API接口規范;
目前大多數大模型都遵循OpenAI的接口規范,是基于Http協議的接口。因此請求路徑、參數、返回值信息都是類似的,可能會有一些小的差別。具體需要查看大模型的官方API文檔。
以DeepSeek官方給出的文檔為例:
# Please install OpenAI SDK first: `pip3 install openai`from openai import OpenAI# 1.初始化OpenAI客戶端,要指定兩個參數:api_key、base_url
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")# 2.發送http請求到大模型,參數比較多
response = client.chat.completions.create(# 2.1.選擇要訪問的模型model="deepseek-chat",# 2.2.發送給大模型的消息messages=[{"role": "system", "content": "You are a helpful assistant"},{"role": "user", "content": "Hello"},],# 2.3.是否以流式返回結果stream=False
)
print(response.choices[0].message.content)接口說明
-
請求方式:通常是POST,因為要傳遞JSON風格的參數;
-
請求路徑:與平臺有關
-
DeepSeek官方平臺:https://api.deepseek.com;
-
阿里云百煉平臺:https://dashscope.aliyuncs.com/compatible-mode/v1;
-
本地ollama部署的模型:http://localhost:11434;
-
-
安全校驗:開放平臺都需要提供API_KEY來校驗權限,本地Ollama則不需要;
-
請求參數:參數很多,比較常見的有:
-
model:要訪問的模型名稱;
-
messages:發送給大模型的消息,是一個數組;
-
stream:-
true,代表響應結果流式返回;
-
false,代表響應結果一次性返回,但需要等待;
-
-
temperature:取值范圍[0:2),代表大模型生成結果的隨機性,越小隨機性越低。DeepSeek-R1不支持;
-
-
注意,這里請求參數中的messages是一個消息數組,而且其中的消息要包含兩個屬性:
-
role:消息對應的角色;
-
content:消息內容;也被稱為提示詞(Prompt),也就是發送給大模型的指令。
-
提示詞角色
常用的消息的角色有三種:

其中System類型的消息非常重要!影響了后續AI會話的行為模式;
-
比如,當我們詢問AI對話產品(文心一言、DeepSeek等)“你是誰” 這個問題的時候,每一個AI的回答都不一樣,這是怎么回事呢?
-
這其實是因為AI對話產品并不是直接把用戶的提問發送給LLM,通常都會在user提問的前面通過System消息給模型設定好背景
-
所以,當你問問題時,AI就會遵循System的設定來回答了。因此,不同的大模型由于System設定不同,回答的答案也不一樣;
## Role
System: 你是鄧超
## Example
User: 你是誰
Assisant: 到!gogogo,黑咖啡品味有多濃!我只要汽水的輕松,大熱天做個白日夢,夢見我變成了彩虹
我是鄧超啊!哈哈,你沒看錯,就是那個又帥又幽默的鄧超!怎么樣,是不是被我的魅力驚到了?😎 會話記憶問題
為什么要把歷史消息都放入Messages中,形成一個數組呢?
這是因為大模型是沒有記憶的,因此在調用API接口與大模型對話時,每一次對話信息都不會保留,但是可以發現AI對話產品卻能夠記住每一輪對話信息,根據這些信息進一步回答,這是怎么回事呢?
答案就是Messages數組;
只需要每一次發送請求時,都把歷史對話中每一輪的User消息、Assistant消息都封裝到Messages數組中,一起發送給大模型,這樣大模型就會根據這些歷史對話信息進一步回答,就像是擁有了記憶一樣;
2.3 大模型應用開發架構
2.3.1 技術架構
目前,大模型應用開發的技術架構主要有四種
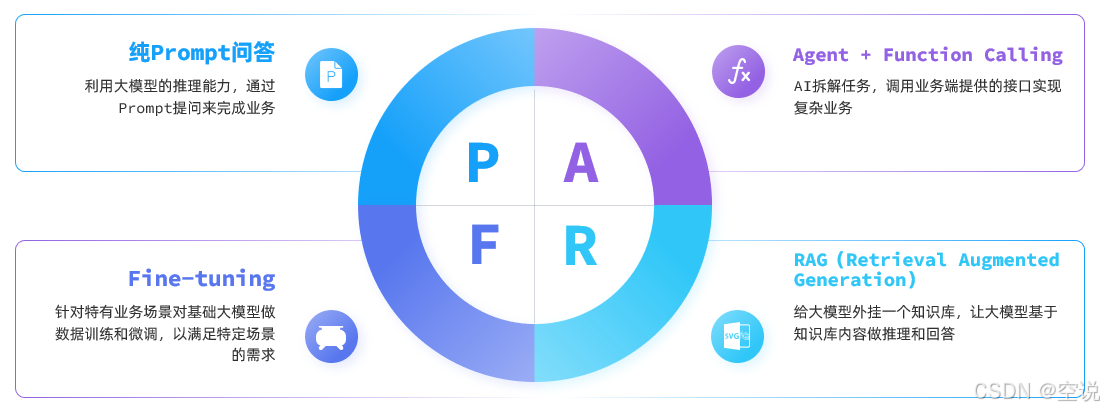
純Prompt模式
不同的提示詞能夠讓大模型給出差異巨大的答案;
不斷雕琢提示詞,使大模型能給出最理想的答案,這個過程就叫做提示詞工程(Prompt Engineering);
很多簡單的AI應用,僅僅靠一段足夠好的提示詞就能實現了,這就是純Prompt模式;流程如圖:
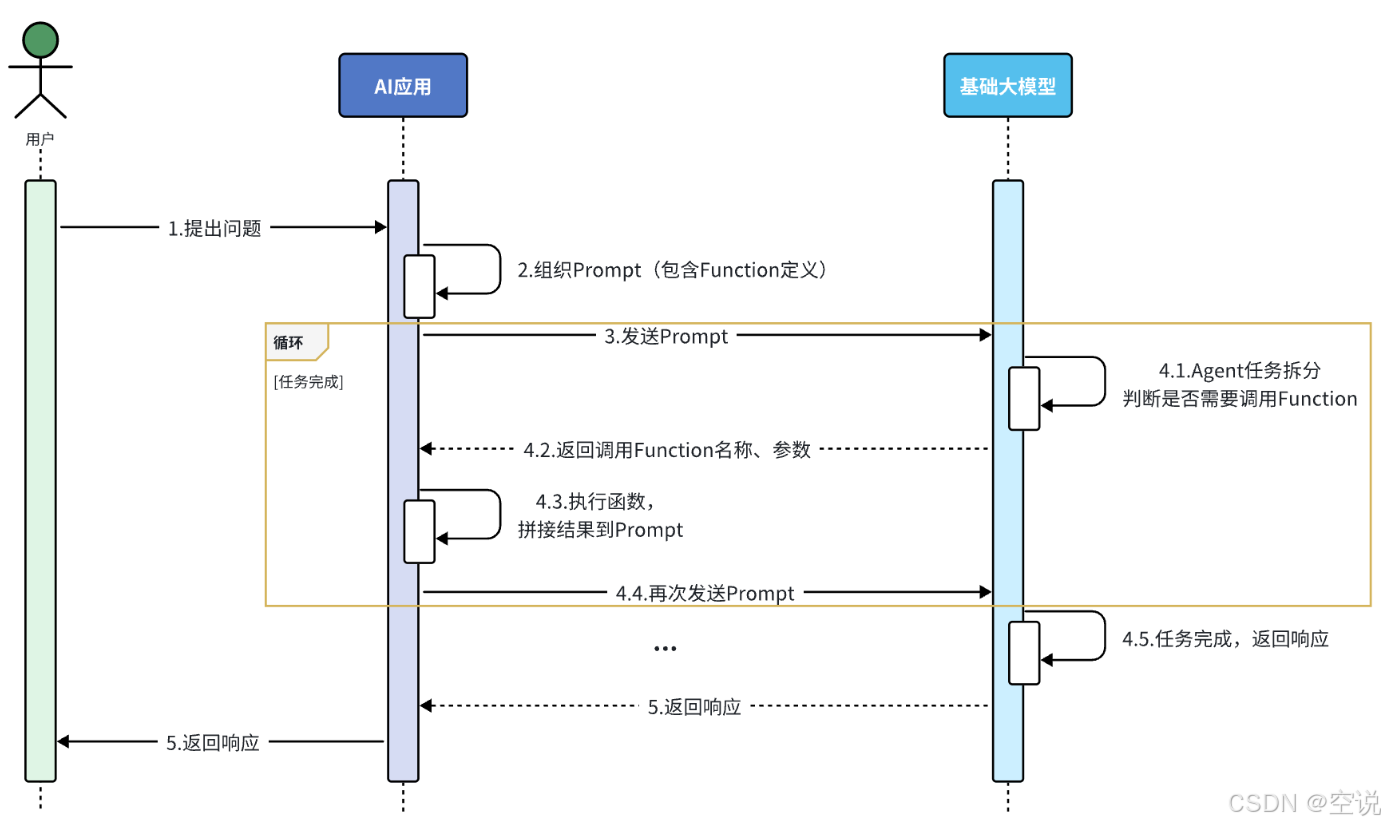
FunctionCalling
大模型雖然可以理解自然語言,更清晰地弄懂用戶意圖,但是確無法直接操作數據庫、執行嚴格的業務規則。這個時候就可以整合傳統應用與大模型的能力了;
-
把傳統應用中的部分功能封裝成一個個函數(Function);
-
在提示詞中描述用戶的需求,并且描述清楚每個函數的作用,要求AI理解用戶意圖,判斷什么時候需要調用哪個函數,并且將任務拆解為多個步驟(Agent);
-
當AI執行到某一步,需要調用某個函數時,會返回要調用的函數名稱、函數需要的參數信息;
-
傳統應用接收到這些數據以后,就可以調用本地函數。再把函數執行結果封裝為提示詞,再次發送給AI;
-
以此類推,逐步執行,直到達成最終結果。
RAG檢索增強
檢索增強生成(Retrieval-Augmented Generation,簡稱RAG)已成為構建智能問答系統的關鍵技術。
模型從知識角度存在很多限制:
-
時效性差:大模型訓練比較耗時,其訓練數據都是舊數據,無法實時更新;
-
缺少專業領域知識:大模型訓練數據都是采集的通用數據,缺少專業數據;
把最新的數據或者專業文檔都拼接到提示詞,一起發給大模型,不就可以了?
現在的大模型都是基于Transformer神經網絡,Transformer的強項就是所謂的注意力機制。它可以根據上下文來分析文本含義
但是,上下文的大小是有限制的,GPT3剛剛出來的時候,僅支持2000個token的上下文。所以海量知識庫數據是無法直接寫入提示詞的;
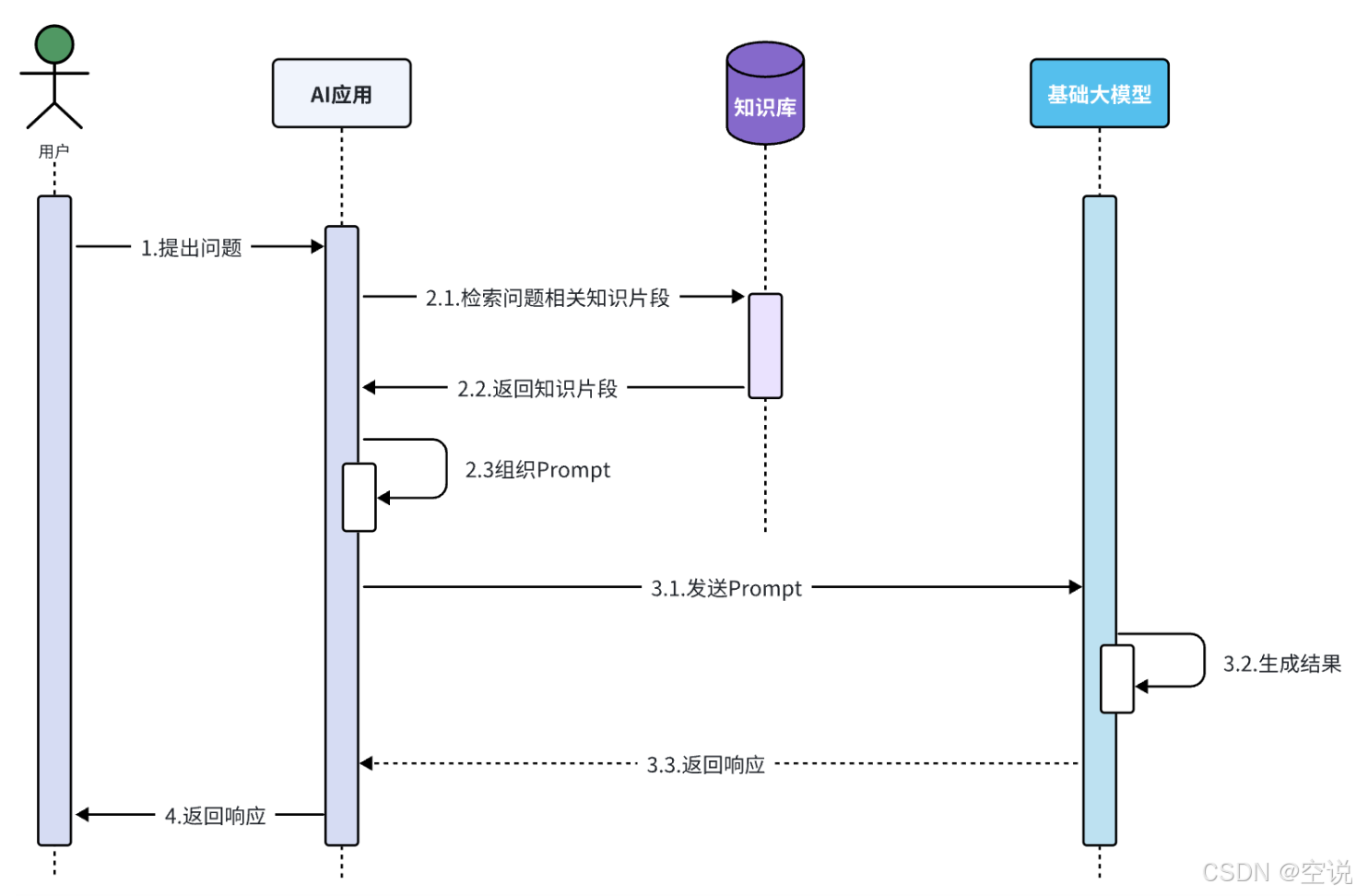
RAG原理
RAG 的核心原理是將檢索技術與生成模型相結合,結合外部知識庫或私有數據源來檢索相關信息來指導和增強生成模型的輸出,有效解決了傳統大語言模型的知識更新滯后和"幻覺"問題。
其核心工作流程分為三個階段:
-
接收請求: 首先,系統接收到用戶的請求(例如提出一個問題)
-
信息檢索(R): 系統從一個大型文檔庫中檢索出與查詢最相關的文檔片段。這一步的目標是找到那些可能包含答案或相關信息的文檔。這里不一定是從向量數據庫中檢索,但是向量數據庫能反應相似度最高的幾個文檔(比如說法不同,意思相同),而不是精確查找
-
文本拆分:將文本按照某種規則拆分為很多片段;
-
文本嵌入(Embedding):根據文本片段內容,將文本片段歸類存儲;
-
文本檢索:根據用戶提問的問題,找出最相關的文本片段;
-
-
生成增強(A): 將檢索到的文檔片段與原始查詢一起輸入到大模型(如chatGPT)中,注意使用合適的提示詞,比如原始的問題是XXX,檢索到的信息是YY,給大模型的輸入應該類似于: 請基于YYY回答XXXX。
-
輸出生成(G): 大模型LLM 基于輸入的查詢和檢索到的文檔片段生成最終的文本答案,并返回給用戶
由于每次都是從向量庫中找出與用戶問題相關的數據,而不是整個知識庫,所以上下文就不會超過大模型的限制,同時又保證了大模型回答問題是基于知識庫中的內容;
Fine-tuning
模型微調,就是在預訓練大模型(比如DeepSeek、Qwen)的基礎上,通過企業自己的數據做進一步的訓練,使大模型的回答更符合自己企業的業務需求。這個過程通常需要在模型的參數上進行細微的修改,以達到最佳的性能表現;
在進行微調時,通常會保留模型的大部分結構和參數,只對其中的一小部分進行調整。減少了訓練時間和計算資源的消耗。
微調的過程包括以下幾個關鍵步驟:
-
選擇合適的預訓練模型:根據任務的需求,選擇一個已經在大量數據上進行過預訓練的模型,如Qwen-2.5;
-
準備特定領域的數據集:收集和準備與任務相關的數據集,這些數據將用于微調模型;
-
設置超參數:調整學習率、批次大小、訓練輪次等超參數,以確保模型能夠有效學習新任務的特征;
-
訓練和優化:使用特定任務的數據對模型進行訓練,通過前向傳播、損失計算、反向傳播和權重更新等步驟,不斷優化模型的性能;
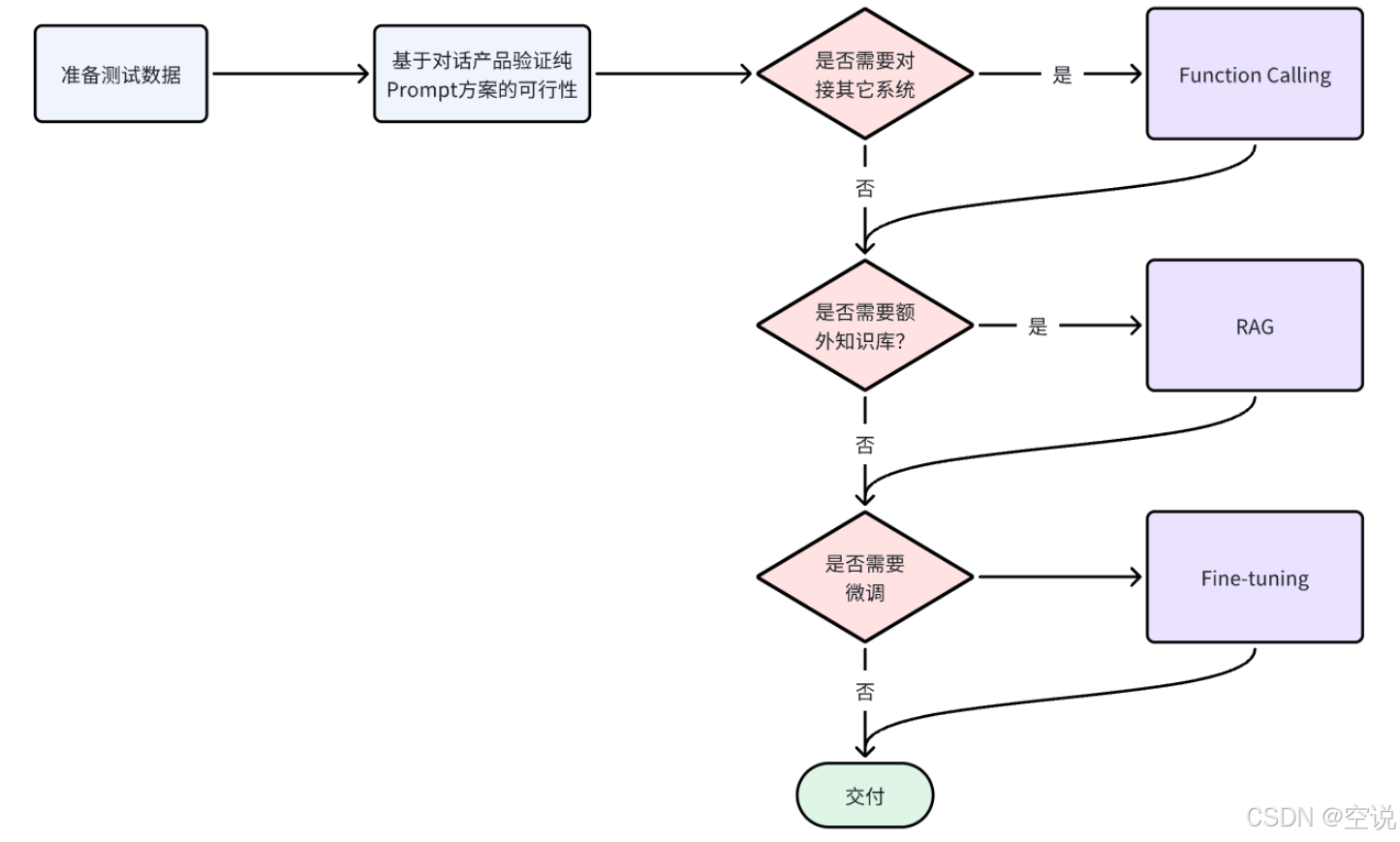
2.3.2 技術選型
-
從開發成本由低到高來看,四種方案的排序:
Prompt < Function Calling < RAG < Fine-tuning -
所以在選擇技術時通常也應該遵循"在達成目標效果的前提下,盡量降低開發成本"這一首要原則。然后可以參考以下流程來思考:

生成隨機數并顯示波形)
)


非阻塞賦值真的并行嗎?)


——Triton源碼接結構)


 - 優化知識庫pdf文檔的識別)







