文章目錄
- MambaVision
- 一、研究背景
- (一)Transformer vs Mamba?
- (二)Mamba in CV?
- 二、相關工作?
- (一)Transformer 在計算機視覺領域的進展?
- (二)Mamba 在計算機視覺領域的探索?
- 三、MambaVision 設計?
- (一)宏觀架構?
- (二)微觀架構?
- 四、實驗設置?
- 五、實驗結果?
- 六、結論?
MambaVision
?論文閱讀?
論文鏈接:MambaVision: A Hybrid Mamba-Transformer Vision Backbone
本文提出了 MambaVision 這一專為視覺應用設計的混合骨干網絡,通過重新設計 Mamba 結構和研究混合模式,在多項視覺任務中展現出優于同類模型的性能,為新型視覺模型的發展奠定了基礎。?

一、研究背景
(一)Transformer vs Mamba?
- Transformer憑借注意力機制在多領域廣泛應用,具備通用性和靈活性,適用于多模態學習。然而,其注意力機制的二次復雜度使得訓練和部署成本高昂。?
- Mamba作為一種新型狀態空間模型(SSM),時間復雜度為線性,在語言建模任務中表現優異,甚至超越Transformer,其核心創新在于引入選擇機制,可高效處理長序列數據。?
(二)Mamba in CV?
受 Mamba 啟發,部分基于 Mamba 的骨干網絡被應用于視覺任務,但 Mamba 的自回歸特性在視覺領域存在局限:
- 圖像像素的空間關系具有局部且并行的特點,沒有順序依賴關系,與 Mamba順序處理的序列數據不同。
- 像Mamba這樣的自回歸模型逐步處理數據的方式難以在一次前向傳播中捕捉全局上下文,而視覺任務往往需要全局信息來準確判斷局部。?
二、相關工作?
(一)Transformer 在計算機視覺領域的進展?
1. ViT:利用自注意力層擴大感受野,但缺乏 CNN 的歸納偏差和位移不變性,需大規模數據集訓練。?
2. DeiT:引入知識蒸餾訓練策略,能在小數據集上顯著提升分類準確率。?
3. LeViT:融合重新設計的多層感知機和自注意力模塊,優化推理速度,提升效率和性能。?
4. XCiT:引入轉置自注意力機制,增強對特征通道交互的建模能力。?
5. PVT:金字塔視覺,引入特征金字塔,可以生成多尺度的特征圖用于密集預測任務,采用分層結構,降低空間維度,提高計算效率。
6. Swin Transformer:通過局部窗口自注意力平衡局部和全局上下文。?
7. Twins Transformer:其空間可分離自注意力機制提升了效率。?
8. Focal Transformer:利用焦點自注意力捕捉長距離空間交互細節。?
(二)Mamba 在計算機視覺領域的探索?
1.Vim:提出雙向 SSM,試圖提升全局上下文捕捉能力,但雙向編碼增加計算量,導致訓練和推理變慢,且難以有效融合多方向信息。?
2.EfficientVMamba:采用空洞卷積和跳躍采樣提取全局空間依賴關系,使用分層架構,在不同分辨率下分別利用 SSM 和 CNN 的優勢。?
相比之下,MambaVision 在高分辨率下利用 CNN 更快提取特征,低分辨率下結合 SSM和自注意力捕捉更細粒度細節,在準確率和吞吐量上更具優勢。?
3.VMamba:引入跨掃描模塊 CSM 實現一維選擇掃描,擴大全局感受野,但感受野受跨掃描路徑限制。?
相比之下,MambaVision 的混合器設計更簡單,能捕捉短程和長程依賴,且使用 CNN 層快速提取特征,在性能和吞吐量上更優。?
三、MambaVision 設計?
(一)宏觀架構?
MambaVision 采用分層架構,包含 4 個不同階段。?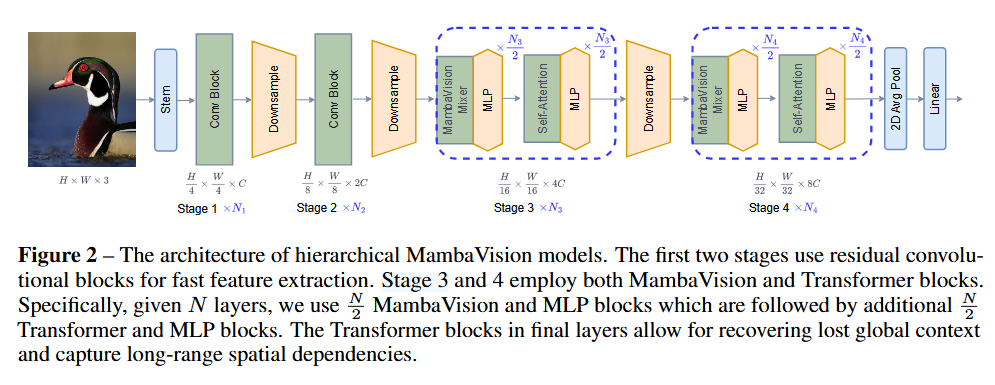
- 前兩個階段使用殘差卷積塊,用于在較高輸入分辨率下快速提取特征。?
- 后兩個階段融合了 MambaVision 和Transformer 塊。?
具體而言,給定N層,使用N個MambaVision 和MLP塊,隨后是另外N 個Transfomer 和 MLP 塊。最終層中的Transformer 塊能夠恢復丟失的全局上下文,并捕捉長距離的空間依賴關系。
?
(二)微觀架構?
Mamba 是結構化狀態空間序列模型(S4)的擴展,能將 1D 連續輸入轉換為輸出。?
其連續參數經離散化處理后,可通過全局卷積計算輸出。?
?
為使 Mamba 更適用于視覺任務,重新設計了 Mamba 混合器:?
- 用常規卷積替換因果卷積,因為因果卷積限制了信息傳播方向,對視覺任務不利;?
- 添加無 SSM 的對稱分支,由額外卷積和 SiLU 激活函數組成,補償因 SSM 順序約束丟失的信息;?
- 將兩個分支輸出拼接并通過線性層投影,使最終特征表示融合順序和空間信息。? 此外,采用通用多頭自注意力機制,其計算方式與以往研究類似。?
四、實驗設置?
1.圖像分類?
- 在 ImageNet-1K 數據集上進行圖像分類實驗,遵循標準訓練方法,所有模型均訓練300個epoch,采用余弦衰減調度器,其中分別使用了20個epoch進行預熱和冷卻階段。使用LAMB 優化器,設置全局批量大小4096、初始學習率0.005和權重衰減0.05,利用 32 個 A100 GPU 加速訓練。?
2.目標檢測和實例分割?
- 以預訓練模型為骨干網絡,在 MS COCO 數據集上進行目標檢測和實例分割任務,使用 Mask-RCNN 頭,超參數設置初始學習率0.0001、批量大小16、權重衰減為0.05的X3學習率調度,使用 8 個 A100 GPU 進行訓練。?
3.語義分割?
- 在 ADE20K 數據集上進行語義分割任務,使用 UperNet 頭和 Adam-W 優化器,初始學習率6e-5,全局批量大小16,使用 8 個 A100 GPU 進行訓練。?
五、實驗結果?
1.圖像分類?
-
MambaVision 在 ImageNet-1K 分類任務中表現卓越,在 Top-1
準確率和圖像吞吐量方面大幅超越CNN、Transformer、Conv - Transformer 和 Mamba 的不同模型系列。? -
與流行模型如 ConvNeXt 和 Swin Transformer 相比,MambaVision-B 的 Top-1準確率更高,圖像吞吐量也更優。
-
與基于 Mamba 的模型相比同樣展現出優勢,且 MambaVision模型變體的計算量(FLOPs)低于同等規模的其他模型。?
?
2.目標檢測與分割?
-
在 MS COCO 數據集的目標檢測和實例分割實驗中,使用簡單 Mask-RCNN 檢測頭,預訓練的 MambaVision-T
骨干網絡在 AP box和AP mask上超越 ConvNeXt-T 和 Swin-T 模型。? -
使用 Cascade Mask-RCNN 網絡時,MambaVision-T、MambaVision-S 和 MambaVision-B
表現更優,在 AP box和 AP mask上相對于對比模型有明顯提升。?
?
-
在 ADE20K 數據集的語義分割任務中,MambaVision 不同變體在 mIoU 指標上優于相近規模的競爭模型,驗證了其作為視覺骨干網絡在不同任務中的有效性,尤其在高分辨率設置下表現出色。?

?
3.消融實驗?
- 對 MambaVision 混合器進行消融實驗,結果表明用常規卷積替換因果卷積、添加對稱分支(即SMM和非SMM)并拼接輸出,能顯著提升模型在分類、目標檢測、實例分割和語義分割任務中的性能,驗證了設計的有效性。?

- 研究不同混合集成模式對模型的影響發現,在每個階段最后幾層使用自注意力塊的設計能有效提升性能,且當自注意力塊數量增加到每個階段最后 N/2 層時,模型達到最佳性能。?
?
六、結論?
- 首次提出 MambaVision 這一專為視覺應用設計的 Mamba-Transformer 混合骨干網絡。?
- 重新設計 Mamba公式增強了全局上下文表示學習能力,全面研究混合設計集成模式。?
- MambaVision 在 Top-1準確率和圖像吞吐量上達到新的最優前沿,大幅超越基于 Transformer 和 Mamba 的模型,為新一代混合視覺模型發展提供了基礎。
?



Java/python/JavaScript/C++/C語言/GO六種最佳實現)





生成隨機數并顯示波形)
)


非阻塞賦值真的并行嗎?)


——Triton源碼接結構)


 - 優化知識庫pdf文檔的識別)