『Kubernetes(K8S) 入門進階實戰』實戰入門 - Pod 詳解
Pod 結構
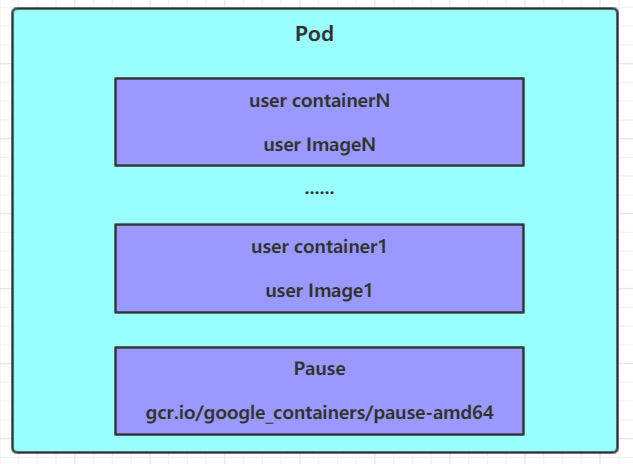
- 每個 Pod 中都可以包含一個或者多個容器,這些容器可以分為兩類
- 用戶程序所在的容器,數量可多可少
- Pause 容器,這是每個 Pod 都會有的一個根容器,它的作用有兩個
- 可以以它為依據,評估整個 Pod 的健康狀態
- 可以在根容器上設置 IP 地址,其它容器都此 IP(Pod IP),以實現 Pod 內部的網路通信
Pod 定義
- Pod 的資源清單
apiVersion: v1 #必選,版本號,例如v1
kind: Pod #必選,資源類型,例如 Pod
metadata: #必選,元數據name: string #必選,Pod名稱namespace: string #Pod所屬的命名空間,默認為"default"labels: #自定義標簽列表- name: string
spec: #必選,Pod中容器的詳細定義containers: #必選,Pod中容器列表- name: string #必選,容器名稱image: string #必選,容器的鏡像名稱imagePullPolicy: [ Always|Never|IfNotPresent ] #獲取鏡像的策略 command: [string] #容器的啟動命令列表,如不指定,使用打包時使用的啟動命令args: [string] #容器的啟動命令參數列表workingDir: string #容器的工作目錄volumeMounts: #掛載到容器內部的存儲卷配置- name: string #引用pod定義的共享存儲卷的名稱,需用volumes[]部分定義的的卷名mountPath: string #存儲卷在容器內mount的絕對路徑,應少于512字符readOnly: boolean #是否為只讀模式ports: #需要暴露的端口庫號列表- name: string #端口的名稱containerPort: int #容器需要監聽的端口號hostPort: int #容器所在主機需要監聽的端口號,默認與Container相同protocol: string #端口協議,支持TCP和UDP,默認TCPenv: #容器運行前需設置的環境變量列表- name: string #環境變量名稱value: string #環境變量的值resources: #資源限制和請求的設置limits: #資源限制的設置cpu: string #Cpu的限制,單位為core數,將用于docker run --cpu-shares參數memory: string #內存限制,單位可以為Mib/Gib,將用于docker run --memory參數requests: #資源請求的設置cpu: string #Cpu請求,容器啟動的初始可用數量memory: string #內存請求,容器啟動的初始可用數量lifecycle: #生命周期鉤子postStart: #容器啟動后立即執行此鉤子,如果執行失敗,會根據重啟策略進行重啟preStop: #容器終止前執行此鉤子,無論結果如何,容器都會終止livenessProbe: #對Pod內各容器健康檢查的設置,當探測無響應幾次后將自動重啟該容器exec: #對Pod容器內檢查方式設置為exec方式command: [string] #exec方式需要制定的命令或腳本httpGet: #對Pod內個容器健康檢查方法設置為HttpGet,需要制定Path、portpath: stringport: numberhost: stringscheme: stringHttpHeaders:- name: stringvalue: stringtcpSocket: #對Pod內個容器健康檢查方式設置為tcpSocket方式port: numberinitialDelaySeconds: 0 #容器啟動完成后首次探測的時間,單位為秒timeoutSeconds: 0 #對容器健康檢查探測等待響應的超時時間,單位秒,默認1秒periodSeconds: 0 #對容器監控檢查的定期探測時間設置,單位秒,默認10秒一次successThreshold: 0failureThreshold: 0securityContext:privileged: falserestartPolicy: [Always | Never | OnFailure] #Pod的重啟策略nodeName: <string> #設置NodeName表示將該Pod調度到指定到名稱的node節點上nodeSelector: obeject #設置NodeSelector表示將該Pod調度到包含這個label的node上imagePullSecrets: #Pull鏡像時使用的secret名稱,以key:secretkey格式指定- name: stringhostNetwork: false #是否使用主機網絡模式,默認為false,如果設置為true,表示使用宿主機網絡volumes: #在該pod上定義共享存儲卷列表- name: string #共享存儲卷名稱 (volumes類型有很多種)emptyDir: {} #類型為emtyDir的存儲卷,與Pod同生命周期的一個臨時目錄。為空值hostPath: string #類型為hostPath的存儲卷,表示掛載Pod所在宿主機的目錄path: string #Pod所在宿主機的目錄,將被用于同期中mount的目錄secret: #類型為secret的存儲卷,掛載集群與定義的secret對象到容器內部scretname: string items: - key: stringpath: stringconfigMap: #類型為configMap的存儲卷,掛載預定義的configMap對象到容器內部name: stringitems:- key: stringpath: string
- 在這里,可通過一個命令來查看每種資源的可配置項,反而不需要去記
# kubectl explain 資源類型 查看某種資源可以配置的一級屬性
# kubectl explain 資源類型.屬性 查看屬性的子屬性
[root@k8s-master01 ~]# kubectl explain pod
KIND: Pod
VERSION: v1
FIELDS:apiVersion <string>kind <string>metadata <Object>spec <Object>status <Object># 查看下一個層級
[root@k8s-master01 ~]# kubectl explain pod.metadata
KIND: Pod
VERSION: v1
RESOURCE: metadata <Object>
FIELDS:annotations <map[string]string>clusterName <string>creationTimestamp <string>deletionGracePeriodSeconds <integer>deletionTimestamp <string>finalizers <[]string>generateName <string>generation <integer>labels <map[string]string>managedFields <[]Object>name <string>namespace <string>ownerReferences <[]Object>resourceVersion <string>selfLink <string>uid <string>
- 在 kubernetes 中基本所有資源的一級屬性都是一樣的,主要包含 5 部分
- apiVersion 版本:由 kubernetes 內部定義,版本號必須可以用
kubectl api-versions查詢到 - kind 類型:由 kubernetes 內部定義,版本號必須可以用
kubectl api-resources查詢到 - metadata 元數據:主要是資源標識和說明,常用的有 name、namespace、labels 等
- spec 描述:這是配置中最重要的一部分,里面是對各種資源配置的詳細描述
- status 狀態信息:里面的內容不需要定義,由 kubernetes 自動生成
- 在上面的屬性中,spec 是接下來研究的重點,繼續看下它的常見子屬性:
- containers <[]Object> 容器列表:用于定義容器的詳細信息
- nodeName:根據 nodeName 的值將 pod 調度到指定的 Node 節點上
- nodeSelector <map[]> :根據 NodeSelector 中定義的信息選擇將該 Pod 調度到包含這些 label 的 Node 上
- hostNetwork:是否使用主機網絡模式,默認為 false,如果設置為 true,表示使用宿主機網絡
- volumes <[]Object> 存儲卷:用于定義 Pod 上面掛在的存儲信息
- restartPolicy 重啟策略:表示 Pod 在遇到故障的時候的處理策略
Pod 配置
pod.spec.containers屬性,是 pod 配置中最為關鍵的一項配置
[root@k8s-master01 ~]# kubectl explain pod.spec.containers
KIND: Pod
VERSION: v1
RESOURCE: containers <[]Object> # 數組,代表可以有多個容器
FIELDS:name <string> # 容器名稱image <string> # 容器需要的鏡像地址imagePullPolicy <string> # 鏡像拉取策略 command <[]string> # 容器的啟動命令列表,如不指定,使用打包時使用的啟動命令args <[]string> # 容器的啟動命令需要的參數列表env <[]Object> # 容器環境變量的配置ports <[]Object> # 容器需要暴露的端口號列表resources <Object> # 資源限制和資源請求的設置
- 創建 pod-base.yaml 文件,內容如下
apiVersion: v1
kind: Pod
metadata:name: pod-basenamespace: devlabels:user: heima
spec:containers:- name: nginximage: nginx:1.17.1- name: busyboximage: busybox:1.30
- 上面定義了一個比較簡單 Pod 的配置,里面有兩個容器
- nginx:用 1.17.1 版本的 nginx 鏡像創建,(nginx 是一個輕量級 web 容器)
- busybox:用 1.30 版本的 busybox 鏡像創建,(busybox 是一個小巧的 linux 命令集合)
# 創建Pod
[root@k8s-master01 pod]# kubectl apply -f pod-base.yaml
pod/pod-base created# 查看 Pod 狀況
# READY 1/2:表示當前 Pod 中有 2 個容器,其中 1 個準備就緒,1 個未就緒
# RESTARTS:重啟次數,因為有 1 個容器故障了,Pod 一直在重啟試圖恢復它
[root@k8s-master01 pod]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
pod-base 1/2 Running 4 95s# 可以通過describe查看內部的詳情
# 此時已經運行起來了一個基本的 Pod,雖然它暫時有問題
[root@k8s-master01 pod]# kubectl describe pod pod-base -n dev
Pod 鏡像拉取(imagePullPolicy)
- 創建 pod-imagepullpolicy.yaml 文件,內容如下
apiVersion: v1
kind: Pod
metadata:name: pod-imagepullpolicynamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1imagePullPolicy: Never # 用于設置鏡像拉取策略- name: busyboximage: busybox:1.30
imagePullPolicy:用于設置鏡像拉取策略,kubernetes 支持配置三種拉取策略
- Always:總是從遠程倉庫拉取鏡像(一直遠程下載)
- IfNotPresent:本地有則使用本地鏡像,本地沒有則從遠程倉庫拉取鏡像(本地有就本地 本地沒遠程下載)
- Never:只使用本地鏡像,從不去遠程倉庫拉取,本地沒有就報錯 (一直使用本地)
- 默認值說明:
- 如果鏡像 tag 為具體版本號, 默認策略是:IfNotPresent
- 如果鏡像 tag 為:latest(最終版本) ,默認策略是 always
# 創建Pod
[root@k8s-master01 pod]# kubectl create -f pod-imagepullpolicy.yaml
pod/pod-imagepullpolicy created# 查看Pod詳情
# 此時明顯可以看到nginx鏡像有一步Pulling image "nginx:1.17.1"的過程
[root@k8s-master01 pod]# kubectl describe pod pod-imagepullpolicy -n dev
......
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Scheduled <unknown> default-scheduler Successfully assigned dev/pod-imagePullPolicy to node1Normal Pulling 32s kubelet, node1 Pulling image "nginx:1.17.1"Normal Pulled 26s kubelet, node1 Successfully pulled image "nginx:1.17.1"Normal Created 26s kubelet, node1 Created container nginxNormal Started 25s kubelet, node1 Started container nginxNormal Pulled 7s (x3 over 25s) kubelet, node1 Container image "busybox:1.30" already present on machineNormal Created 7s (x3 over 25s) kubelet, node1 Created container busyboxNormal Started 7s (x3 over 25s) kubelet, node1 Started container busybox
啟動命令(command)
- 在前面的案例中,一直有一個問題沒有解決,就是的 busybox 容器一直沒有成功運行
- 原來 busybox 并不是一個程序,而是類似于一個工具類的集合,kubernetes 集群啟動管理后,它會自動關閉。解決方法就是讓其一直在運行,這就用到了 command 配置
- 創建 pod-command.yaml 文件,內容如下
apiVersion: v1
kind: Pod
metadata:name: pod-commandnamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1- name: busyboximage: busybox:1.30command: ["/bin/sh","-c","touch /tmp/hello.txt;while true;do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done;"]
- command:用于在 pod 中的容器初始化完畢之后運行一個命令
# 稍微解釋下上面命令的意思"/bin/sh","-c", # 使用sh執行命令touch /tmp/hello.txt; # 創建一個/tmp/hello.txt 文件while true;do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done; # 每隔3秒向文件中寫入當前時間
- 查看容器內的執行
# 創建Pod
[root@k8s-master01 pod]# kubectl create -f pod-command.yaml
pod/pod-command created# 查看Pod狀態
# 此時發現兩個pod都正常運行了
[root@k8s-master01 pod]# kubectl get pods pod-command -n dev
NAME READY STATUS RESTARTS AGE
pod-command 2/2 Runing 0 2s# 進入 pod 中的busybox容器,查看文件內容
# 補充一個命令: kubectl exec pod名稱 -n 命名空間 -it -c 容器名稱 /bin/sh 在容器內部執行命令
# 使用這個命令就可以進入某個容器的內部,然后進行相關操作了
# 比如,可以查看txt文件的內容
[root@k8s-master01 pod]# kubectl exec pod-command -n dev -it -c busybox /bin/sh
/ # tail -f /tmp/hello.txt
14:44:19
14:44:22
14:44:25
- 特別說明(command+args>command>args=ENTRYPOINT>Dockerfile配置)
- 通過上面發現 command 已經可以完成啟動命令和傳遞參數的功能,為什么這里還要提供一個 args 選項,用于傳遞參數呢?這其實跟 docker 有點關系,kubernetes 中的command、args 兩項其實是實現覆蓋 Dockerfile 中 ENTRYPOINT 的功能
- 如果 command 和 args 均沒有寫,那么用 Dockerfile 的配置
- 如果 command 寫了,但 args 沒有寫,那么 Dockerfile 默認的配置會被忽略,執行輸入的 command
- 如果 command 沒寫,但 args 寫了,那么 Dockerfile 中配置的 ENTRYPOINT 的命令會被執行,使用當前 args 的參數
- 如果 command 和 args 都寫了,那么 Dockerfile 的配置被忽略,執行 command 并追加上 args 參數
- 所謂的 args 在這里
環境變量
- 創建 pod-env.yaml 文件,內容如下
apiVersion: v1
kind: Pod
metadata:name: pod-envnamespace: dev
spec:containers:- name: busyboximage: busybox:1.30command: ["/bin/sh","-c","while true;do /bin/echo $(date +%T);sleep 60; done;"]env: # 設置環境變量列表- name: "username"value: "admin"- name: "password"value: "123456"
env:環境變量,用于在 pod 中的容器設置環境變量
# 創建Pod
[root@k8s-master01 ~]# kubectl create -f pod-env.yaml
pod/pod-env created# 進入容器,輸出環境變量
[root@k8s-master01 ~]# kubectl exec pod-env -n dev -c busybox -it /bin/sh
/ # echo $username
admin
/ # echo $password
123456
端口設置
- 容器的端口設置,也就是 containers 的 ports 選項。首先看下 ports 支持的子選項
[root@k8s-master01 ~]# kubectl explain pod.spec.containers.ports
KIND: Pod
VERSION: v1
RESOURCE: ports <[]Object>
FIELDS:name <string> # 端口名稱,如果指定,必須保證name在pod中是唯一的 containerPort<integer> # 容器要監聽的端口(0<x<65536)hostPort <integer> # 容器要在主機上公開的端口,如果設置,主機上只能運行容器的一個副本(一般省略) hostIP <string> # 要將外部端口綁定到的主機IP(一般省略)protocol <string> # 端口協議。必須是UDP、TCP或SCTP。默認為“TCP”。
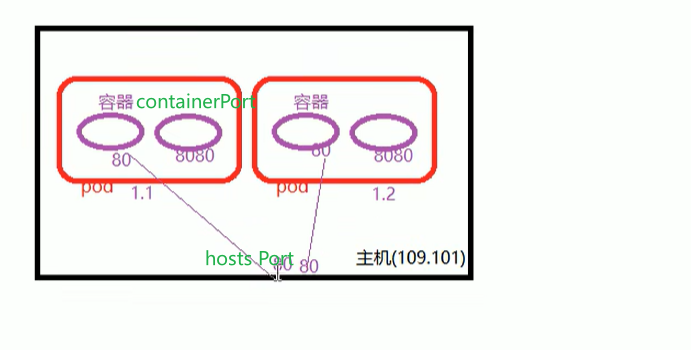
- containerPort 與 hostPort 的區別
- 創建 pod-ports.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-portsnamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1ports: # 設置容器暴露的端口列表- name: nginx-portcontainerPort: 80protocol: TCP
- 執行腳本
- 訪問容器中的程序需要使用的是 Podip:containerPort
# 創建Pod
[root@k8s-master01 ~]# kubectl create -f pod-ports.yaml
pod/pod-ports created# 查看pod
# 在下面可以明顯看到配置信息
[root@k8s-master01 ~]# kubectl get pod pod-ports -n dev -o yaml
......
spec:containers:- image: nginx:1.17.1imagePullPolicy: IfNotPresentname: nginxports:- containerPort: 80name: nginx-portprotocol: TCP
......
資源配額
- 容器中的程序要運行,肯定是要占用一定資源的,比如 cpu 和內存等,如果不對某個容器的資源做限制,那么它就可能吃掉大量資源,導致其它容器無法運行。針對這種情況, kubernetes 提供了對內存和 cpu 的資源進行配額的機制,這種機制主要通過 resources 選項實現,他有兩個子選項
limits:用于限制運行時容器的最大占用資源,當容器占用資源超過 limits 時會被終止,并進行重啟requests:用于設置容器需要的最小資源,如果環境資源不夠,容器將無法啟動
- 創建 pod-resources.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-resourcesnamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1resources: # 資源配額limits: # 限制資源(上限)cpu: "2" # CPU限制,單位是core數memory: "10Gi" # 內存限制requests: # 請求資源(下限)cpu: "1" # CPU限制,單位是core數memory: "10Mi" # 內存限制
- 在這對 cpu 和 memory 的單位做一個說明
- cpu:core數,可以為整數或小數
- memory:內存大小,可以使用 Gi、Mi、G、M 等形式
# 運行Pod
[root@k8s-master01 ~]# kubectl create -f pod-resources.yaml
pod/pod-resources created# 查看發現pod運行正常
[root@k8s-master01 ~]# kubectl get pod pod-resources -n dev
NAME READY STATUS RESTARTS AGE
pod-resources 1/1 Running 0 39s # 接下來,停止Pod
[root@k8s-master01 ~]# kubectl delete -f pod-resources.yaml
pod "pod-resources" deleted# 編輯pod,修改resources.requests.memory的值為10Gi
[root@k8s-master01 ~]# vim pod-resources.yaml# 再次啟動pod
[root@k8s-master01 ~]# kubectl create -f pod-resources.yaml
pod/pod-resources created# 查看Pod狀態,發現Pod啟動失敗
[root@k8s-master01 ~]# kubectl get pod pod-resources -n dev -o wide
NAME READY STATUS RESTARTS AGE
pod-resources 0/1 Pending 0 20s # 查看pod詳情會發現,如下提示
[root@k8s-master01 ~]# kubectl describe pod pod-resources -n dev
......
Warning FailedScheduling 35s default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 Insufficient memory.(內存不足)
Pod 生命周期
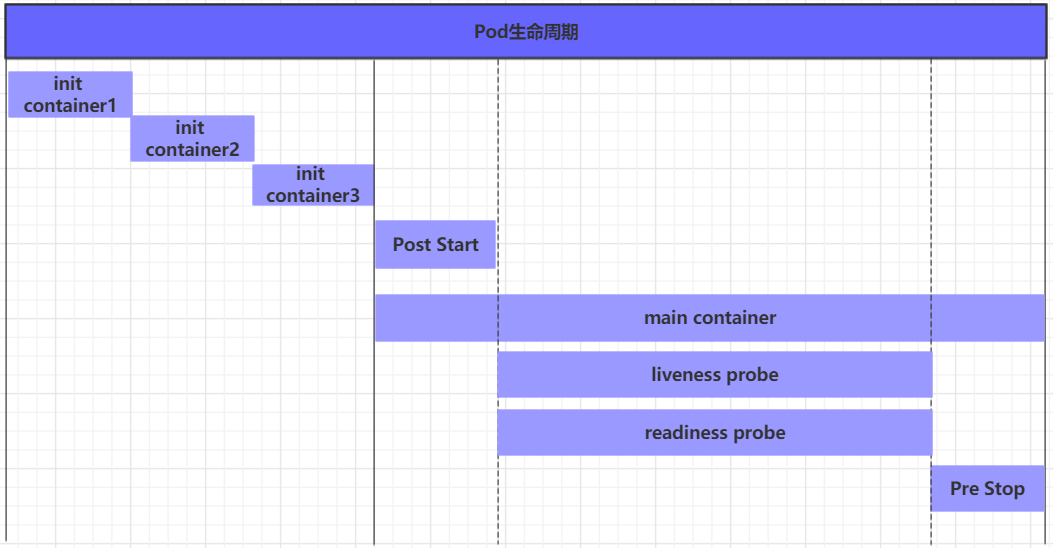
- 一般將 pod 對象從創建至終的這段時間范圍稱為 pod 的生命周期,它主要包含下面的過程
- pod 創建過程
- 運行初始化容器(init container)過程
- 運行主容器(main container)
- 容器啟動后鉤子(post start)、容器終止前鉤子(pre stop)
- 容器的存活性探測(liveness probe)、就緒性探測(readiness probe)
- 在整個生命周期中,Pod 會出現 5 種狀態(相位)
- 掛起(Pending):apiserver 已經創建了 pod 資源對象,但它尚未被調度完成或者仍處于下載鏡像的過程中
- 運行中(Running):pod 已經被調度至某節點,并且所有容器都已經被 kubelet 創建完成
- 成功(Succeeded):pod 中的所有容器都已經成功終止并且不會被重啟
- 失敗(Failed):所有容器都已經終止,但至少有一個容器終止失敗,即容器返回了非 0 值的退出狀態
- 未知(Unknown):apiserver 無法正常獲取到 pod 對象的狀態信息,通常由網絡通信失敗所導致
創建和終止
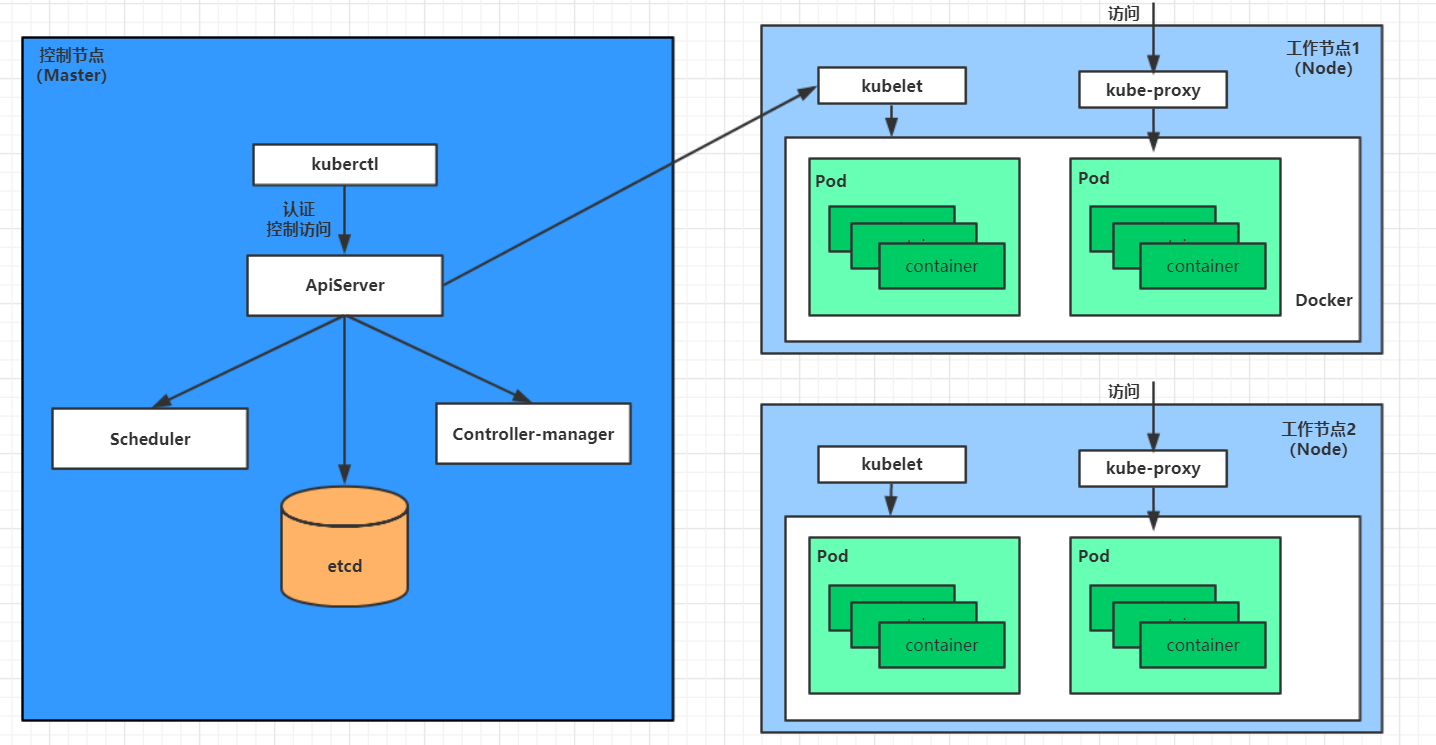
- pod 的創建過程
- 用戶通過 kubectl 或其他 api 客戶端提交需要創建的 pod 信息給 apiServer
- apiServer 開始生成 pod 對象的信息,并將信息存入 etcd,然后返回確認信息至客戶端
- apiServer 開始反映 etcd 中的 pod 對象的變化,其它組件使用 watch 機制來跟蹤檢查 apiServer 上的變動
- scheduler 發現有新的 pod 對象要創建,開始為 Pod 分配主機并將結果信息更新至 apiServer
- node 節點上的 kubelet 發現有 pod 調度過來,嘗試調用 docker 啟動容器,并將結果回送至 apiServer
- apiServer 將接收到的 pod 狀態信息存入 etcd 中
- pod 的終止過程
- 用戶向 apiServer 發送刪除 pod 對象的命令
- apiServcer 中的 pod 對象信息會隨著時間的推移而更新,在寬限期內(默認30s),pod 被視為 dead
- 將 pod 標記為 terminating 狀態
- kubelet 在監控到 pod 對象轉為 terminating 狀態的同時啟動 pod 關閉過程
- 端點控制器監控到 pod 對象的關閉行為時將其從所有匹配到此端點的 service 資源的端點列表中移除
- 如果當前 pod 對象定義了 preStop 鉤子處理器,則在其標記為 terminating 后即會以同步的方式啟動執行
- pod 對象中的容器進程收到停止信號
- 寬限期結束后,若 pod 中還存在仍在運行的進程,那么 pod 對象會收到立即終止的信號
- kubelet 請求 apiServer 將此 pod 資源的寬限期設置為 0 從而完成刪除操作,此時 pod 對于用戶已不可見
初始化容器
- 初始化容器是在 pod 的主容器啟動之前要運行的容器,主要是做一些主容器的前置工作,它具有兩大特征
- 初始化容器必須運行完成直至結束,若某初始化容器運行失敗,那么 kubernetes 需要重啟它直到成功完成
- 初始化容器必須按照定義的順序執行,當且僅當前一個成功之后,后面的一個才能運行
- 初始化容器有很多的應用場景,下面列出的是最常見的幾個
- 提供主容器鏡像中不具備的工具程序或自定義代碼
- 初始化容器要先于應用容器串行啟動并運行完成,因此可用于延后應用容器的啟動直至其依賴的條件得到滿足
- 測試案例,創建 pod-initcontainer.yaml
- 假設要以主容器來運行 nginx,但是要求在運行 nginx 之前先要能夠連接上 mysql 和 redis 所在服務器
apiVersion: v1
kind: Pod
metadata:name: pod-initcontainernamespace: dev
spec:containers:- name: main-containerimage: nginx:1.17.1ports: - name: nginx-portcontainerPort: 80initContainers:- name: test-mysqlimage: busybox:1.30command: ['sh', '-c', 'until ping 192.168.124.87 -c 1 ; do echo waiting for mysql...; sleep 2; done;']- name: test-redisimage: busybox:1.30command: ['sh', '-c', 'until ping 192.168.124.88 -c 1 ; do echo waiting for reids...; sleep 2; done;']
# 創建pod
[root@k8s-master01 ~]# kubectl create -f pod-initcontainer.yaml
pod/pod-initcontainer created# 查看pod狀態
# 發現pod卡在啟動第一個初始化容器過程中,后面的容器不會運行
root@k8s-master01 ~]# kubectl describe pod pod-initcontainer -n dev
........
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Scheduled 49s default-scheduler Successfully assigned dev/pod-initcontainer to node1Normal Pulled 48s kubelet, node1 Container image "busybox:1.30" already present on machineNormal Created 48s kubelet, node1 Created container test-mysqlNormal Started 48s kubelet, node1 Started container test-mysql# 動態查看pod
[root@k8s-master01 ~]# kubectl get pods pod-initcontainer -n dev -w
NAME READY STATUS RESTARTS AGE
pod-initcontainer 0/1 Init:0/2 0 15s
pod-initcontainer 0/1 Init:1/2 0 52s
pod-initcontainer 0/1 Init:1/2 0 53s
pod-initcontainer 0/1 PodInitializing 0 89s
pod-initcontainer 1/1 Running 0 90s# 接下來新開一個shell,為當前服務器新增兩個ip,觀察pod的變化
[root@k8s-master01 ~]# ifconfig ens33:1 192.168.90.14 netmask 255.255.255.0 up
[root@k8s-master01 ~]# ifconfig ens33:2 192.168.90.15 netmask 255.255.255.0 up
鉤子函數
- 鉤子函數能夠感知自身生命周期中的事件,并在相應的時刻到來時運行用戶指定的程序代碼
- kubernetes 在主容器的啟動之后和停止之前提供了兩個鉤子函數
- post start:容器創建之后執行,如果失敗了會重啟容器
- pre stop:容器終止之前執行,執行完成之后容器將成功終止,在其完成之前會阻塞刪除容器的操作
- 鉤子處理器支持使用下面三種方式定義動作
- Exec:在容器內執行一次命令
……lifecycle:postStart: exec:command:- cat- /tmp/healthy
……
- TCPSocket:在當前容器嘗試訪問指定的 socket
…… lifecycle:postStart:tcpSocket:port: 8080
……
- HTTPGet:在當前容器中向某 url 發起 http 請求
……lifecycle:postStart:httpGet:path: / #URI地址port: 80 #端口號host: 192.168.5.3 #主機地址scheme: HTTP #支持的協議,http或者https
……
- 以 exec 方式為例,演示下鉤子函數的使用,創建 pod-hook-exec.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-hook-execnamespace: dev
spec:containers:- name: main-containerimage: nginx:1.17.1ports:- name: nginx-portcontainerPort: 80lifecycle:postStart: exec: # 在容器啟動的時候執行一個命令,修改掉nginx的默認首頁內容command: ["/bin/sh", "-c", "echo postStart... > /usr/share/nginx/html/index.html"]preStop:exec: # 在容器停止之前停止nginx服務command: ["/usr/sbin/nginx","-s","quit"]
# 創建pod
[root@k8s-master01 ~]# kubectl create -f pod-hook-exec.yaml
pod/pod-hook-exec created# 查看pod
[root@k8s-master01 ~]# kubectl get pods pod-hook-exec -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-hook-exec 1/1 Running 0 29s 10.244.2.48 node2 # 訪問pod
[root@k8s-master01 ~]# curl 10.244.2.48
postStart...
容器探測
- 容器探測用于檢測容器中的應用實例是否正常工作,是保障業務可用性的一種傳統機制。如果經過探測,實例的狀態不符合預期,那么kubernetes就會把該問題實例" 摘除 ",不承擔業務流量。kubernetes 提供了兩種探針來實現容器探測,分別是:
- liveness probes:存活性探針,用于檢測應用實例當前是否處于正常運行狀態,如果不是, k8s 會重啟容器
- readiness probes:就緒性探針,用于檢測應用實例當前是否可以接收請求,如果不能,k8s 不會轉發流量
- 總結:livenessProbe 決定是否重啟容器,readinessProbe 決定是否將請求轉發給容器
- 上面兩種探針目前均支持三種探測方式
- Exec:在容器內執行一次命令,如果命令執行的退出碼為 0,則認為程序正常,否則不正常
……lifecycle:postStart: exec:command:- cat- /tmp/healthy
……
- TCPSocket:將會嘗試訪問一個用戶容器的端口,如果能夠建立這條連接,則認為程序正常,否則不正常
…… lifecycle:postStart:tcpSocket:port: 8080
……
- HTTPGet:調用容器內 Web 應用的 URL,如果返回的狀態碼在 200 和 399 之間,則認為程序正常,否則不正常
……lifecycle:postStart:httpGet:path: / #URI地址port: 80 #端口號host: 192.168.5.3 #主機地址scheme: HTTP #支持的協議,http或者https
……
- 測試 Exec 探測
- 創建 pod-liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-liveness-execnamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1ports: - name: nginx-portcontainerPort: 80livenessProbe:exec:command: ["/bin/cat","/tmp/hello.txt"] # 執行一個查看文件的命令
- 創建 pod,觀察效果
# 創建Pod
[root@k8s-master01 ~]# kubectl create -f pod-liveness-exec.yaml
pod/pod-liveness-exec created# 查看Pod詳情
[root@k8s-master01 ~]# kubectl describe pods pod-liveness-exec -n dev
......Normal Created 20s (x2 over 50s) kubelet, node1 Created container nginxNormal Started 20s (x2 over 50s) kubelet, node1 Started container nginxNormal Killing 20s kubelet, node1 Container nginx failed liveness probe, will be restartedWarning Unhealthy 0s (x5 over 40s) kubelet, node1 Liveness probe failed: cat: can't open '/tmp/hello11.txt': No such file or directory# 觀察上面的信息就會發現nginx容器啟動之后就進行了健康檢查
# 檢查失敗之后,容器被kill掉,然后嘗試進行重啟(這是重啟策略的作用,后面講解)
# 稍等一會之后,再觀察pod信息,就可以看到RESTARTS不再是0,而是一直增長
[root@k8s-master01 ~]# kubectl get pods pod-liveness-exec -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-exec 0/1 CrashLoopBackOff 2 3m19s# 當然接下來,可以修改成一個存在的文件,比如/tmp/hello.txt,再試,結果就正常了......
- 測試 TCPSocket 探測
- 創建 pod-liveness-tcpsocket.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-liveness-tcpsocketnamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1ports: - name: nginx-portcontainerPort: 80livenessProbe:tcpSocket:port: 8080 # 嘗試訪問8080端口
- 創建 pod,觀察效果
# 創建Pod
[root@k8s-master01 ~]# kubectl create -f pod-liveness-tcpsocket.yaml
pod/pod-liveness-tcpsocket created# 查看Pod詳情
[root@k8s-master01 ~]# kubectl describe pods pod-liveness-tcpsocket -n dev
......Normal Scheduled 31s default-scheduler Successfully assigned dev/pod-liveness-tcpsocket to node2Normal Pulled <invalid> kubelet, node2 Container image "nginx:1.17.1" already present on machineNormal Created <invalid> kubelet, node2 Created container nginxNormal Started <invalid> kubelet, node2 Started container nginxWarning Unhealthy <invalid> (x2 over <invalid>) kubelet, node2 Liveness probe failed: dial tcp 10.244.2.44:8080: connect: connection refused# 觀察上面的信息,發現嘗試訪問8080端口,但是失敗了
# 稍等一會之后,再觀察pod信息,就可以看到RESTARTS不再是0,而是一直增長
[root@k8s-master01 ~]# kubectl get pods pod-liveness-tcpsocket -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-tcpsocket 0/1 CrashLoopBackOff 2 3m19s# 當然接下來,可以修改成一個可以訪問的端口,比如80,再試,結果就正常了......
- 測試 HTTPGet 探測
- 創建 pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-liveness-httpgetnamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1ports:- name: nginx-portcontainerPort: 80livenessProbe:httpGet: # 其實就是訪問http://127.0.0.1:80/hello scheme: HTTP #支持的協議,http或者httpsport: 80 #端口號path: /hello #URI地址
- 創建 pod,觀察效果
# 創建Pod
[root@k8s-master01 ~]# kubectl create -f pod-liveness-httpget.yaml
pod/pod-liveness-httpget created# 查看Pod詳情
[root@k8s-master01 ~]# kubectl describe pod pod-liveness-httpget -n dev
.......Normal Pulled 6s (x3 over 64s) kubelet, node1 Container image "nginx:1.17.1" already present on machineNormal Created 6s (x3 over 64s) kubelet, node1 Created container nginxNormal Started 6s (x3 over 63s) kubelet, node1 Started container nginxWarning Unhealthy 6s (x6 over 56s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404Normal Killing 6s (x2 over 36s) kubelet, node1 Container nginx failed liveness probe, will be restarted# 觀察上面信息,嘗試訪問路徑,但是未找到,出現404錯誤
# 稍等一會之后,再觀察pod信息,就可以看到RESTARTS不再是0,而是一直增長
[root@k8s-master01 ~]# kubectl get pod pod-liveness-httpget -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-httpget 1/1 Running 5 3m17s# 當然接下來,可以修改成一個可以訪問的路徑path,比如/,再試,結果就正常了......
- 至此,已經使用 liveness Probe 演示了三種探測方式,但是查看 livenessProbe 的子屬性,會發現除了這三種方式,還有一些其他的配置,在這里一并解釋下:
[root@k8s-master01 ~]# kubectl explain pod.spec.containers.livenessProbe
FIELDS:exec <Object> tcpSocket <Object>httpGet <Object>initialDelaySeconds <integer> # 容器啟動后等待多少秒執行第一次探測timeoutSeconds <integer> # 探測超時時間。默認1秒,最小1秒periodSeconds <integer> # 執行探測的頻率。默認是10秒,最小1秒failureThreshold <integer> # 連續探測失敗多少次才被認定為失敗。默認是3。最小值是1successThreshold <integer> # 連續探測成功多少次才被認定為成功。默認是1
- 可以增加配置 2 個進行測試
apiVersion: v1
kind: Pod
metadata:name: pod-liveness-httpgetnamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1ports:- name: nginx-portcontainerPort: 80livenessProbe:httpGet:scheme: HTTPport: 80 path: /initialDelaySeconds: 30 # 容器啟動后30s開始探測timeoutSeconds: 5 # 探測超時時間為5s
重啟策略
- 一旦容器探測出現了問題,kubernetes 就會對容器所在的 Pod 進行重啟,其實這是由 pod 的重啟策略決定的,pod 的重啟策略有 3 種:
- Always:容器失效時,自動重啟該容器,這也是默認值
- OnFailure: 容器終止運行且退出碼不為 0 時重啟
- Never: 不論狀態為何,都不重啟該容器
- 重啟策略適用于 pod 對象中的所有容器,首次需要重啟的容器,將在其需要時立即進行重啟,隨后再次需要重啟的操作將由 kubelet 延遲一段時間后進行,且反復的重啟操作的延遲時長以此為 10s、20s、40s、80s、160s 和 300s,300s 是最大延遲時長
- 創建 pod-restartpolicy.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-restartpolicynamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1ports:- name: nginx-portcontainerPort: 80livenessProbe:httpGet:scheme: HTTPport: 80path: /hellorestartPolicy: Never # 設置重啟策略為 Never
- 運行 Pod 測試
# 創建Pod
[root@k8s-master01 ~]# kubectl create -f pod-restartpolicy.yaml
pod/pod-restartpolicy created# 查看Pod詳情,發現nginx容器失敗
[root@k8s-master01 ~]# kubectl describe pods pod-restartpolicy -n dev
......Warning Unhealthy 15s (x3 over 35s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404Normal Killing 15s kubelet, node1 Container nginx failed liveness probe# 多等一會,再觀察pod的重啟次數,發現一直是0,并未重啟。會發現狀態是 Completed
[root@k8s-master01 ~]# kubectl get pods pod-restartpolicy -n dev
NAME READY STATUS RESTARTS AGE
pod-restartpolicy 0/1 Completed 0 35s
Pod 調度
- 在默認情況下,一個 Pod 在哪個 Node 節點上運行,是由 Scheduler 組件采用相應的算法計算出來的,這個過程是不受人工控制的。但是在實際使用中,這并不滿足的需求,因為很多情況下,我們想控制某些 Pod 到達某些節點上。因此 kubernetes 提供了四大類調度方式:
- 自動調度:運行在哪個節點上完全由 Scheduler 經過一系列的算法計算得出
- 定向調度:NodeName、NodeSelector
- 親和性調度:NodeAffinity、PodAffinity、PodAntiAffinity
- 污點(容忍)調度:Taints、Toleration
定向調度
- 定向調度,指的是利用在 pod 上聲明 nodeName 或者 nodeSelector,以此將 Pod 調度到期望的 node 節點上。注意,這里的調度是強制的,這就意味著即使要調度的目標 Node 不存在,也會向上面進行調度,只不過 pod 運行失敗而已
NodeName
- NodeName 用于強制約束將 Pod 調度到指定的 Name 的 Node 節點上。這種方式,其實是直接跳過 Scheduler 的調度邏輯,直接將 Pod 調度到指定名稱的節點
- 創建 pod-nodename.yaml
# 其中,節點的名稱可通過這個命令來查詢:kubectl get nodesapiVersion: v1
kind: Pod
metadata:name: pod-nodenamenamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1nodeName: k8s-node1 # 指定調度到node1節點上
#創建Pod
[root@k8s-master01 ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created#查看Pod調度到NODE屬性,確實是調度到了node1節點上
[root@k8s-master01 ~]# kubectl get pods pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-nodename 1/1 Running 0 55s 10.244.36.72 k8s-node1 <none> <none> # 接下來,刪除pod,修改nodeName的值為node3(并沒有node3節點)
[root@k8s-master01 ~]# kubectl delete -f pod-nodename.yaml
pod "pod-nodename" deleted
[root@k8s-master01 ~]# vim pod-nodename.yaml
[root@k8s-master01 ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created#再次查看,發現已經向Node3節點調度,但是由于不存在node3節點,所以pod無法正常運行
[root@k8s-master01 ~]# kubectl get pods pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-nodename 0/1 Pending 0 7s <none> k8s-node3 <none> <none>
NodeSelector
- NodeSelector 用于將 pod 調度到添加了指定標簽的 node 節點上。它是通過 kubernetes 的 label-selector 機制實現的,也就是說,在 pod 創建之前,會由 scheduler 使用 MatchNodeSelector 調度策略進行 label 匹配,找出目標 node,然后將 pod 調度到目標節點,該匹配規則是強制約束
- 首先分別為 node 節點添加標簽
# 其中,節點的名稱可通過這個命令來查詢:kubectl get nodes
kubectl label nodes k8s-node1 nodeenv=pro
kubectl label nodes k8s-node2 nodeenv=test
- 創建一個 pod-nodeselector.yaml 文件,并使用它創建 Pod
apiVersion: v1
kind: Pod
metadata:name: pod-nodeselectornamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1nodeSelector:nodeenv: pro # 指定調度到具有nodeenv=pro標簽的節點上
#創建Pod
[root@k8s-master01 ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created#查看Pod調度到NODE屬性,確實是調度到了node1節點上
[root@k8s-master01 ~]# kubectl get pods pod-nodeselector -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-nodeselector 1/1 Running 0 5s 10.244.36.73 k8s-node1 <none> <none># 接下來,刪除pod,修改nodeSelector的值為nodeenv: xxxx(不存在打有此標簽的節點)
[root@k8s-master01 ~]# kubectl delete -f pod-nodeselector.yaml
pod "pod-nodeselector" deleted
[root@k8s-master01 ~]# vim pod-nodeselector.yaml
[root@k8s-master01 ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created#再次查看,發現pod無法正常運行,Node的值為none
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-nodeselector 0/1 Pending 0 2m20s <none> <none># 查看詳情,發現node selector匹配失敗的提示
[root@k8s-master01 ~]# kubectl describe pods pod-nodeselector -n dev
.......
Events:Type Reason Age From Message---- ------ ---- ---- -------Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
親和性調度
- 上面兩種定向調度的方式,使用起來非常方便,但是也有一定的問題,那就是如果沒有滿足條件的 Node,那么 Pod 將不會被運行,即使在集群中還有可用 Node 列表也不行,這就限制了它的使用場景
- 基于上面的問題,kubernetes 還提供了一種親和性調度(Affinity)。它在 NodeSelector 的基礎之上的進行了擴展,可以通過配置的形式,實現優先選擇滿足條件的 Node 進行調度,如果沒有,也可以調度到不滿足條件的節點上,使調度更加靈活
- Affinity 主要分為三類:
- nodeAffinity(node 親和性): 以 node 為目標,解決 pod 可以調度到哪些 node 的問題
- podAffinity(pod 親和性):以 pod 為目標,解決 pod 可以和哪些已存在的 pod 部署在同一個拓撲域中的問題
- podAntiAffinity(pod 反親和性):以 pod 為目標,解決 pod 不能和哪些已存在 pod 部署在同一個拓撲域中的問題
關于親和性(反親和性)使用場景的說明:
親和性:如果兩個應用頻繁交互,那就有必要利用親和性讓兩個應用的盡可能的靠近,這樣可以減少因網絡通信而帶來的性能損耗
反親和性:當應用的采用多副本部署時,有必要采用反親和性讓各個應用實例打散分布在各個 node 上,這樣可以提高服務的高可用性
NodeAffinity
- 首先來看一下 NodeAffinity 的可配置項
pod.spec.affinity.nodeAffinityrequiredDuringSchedulingIgnoredDuringExecution # Node 節點必須滿足指定的所有規則才可以,相當于硬限制nodeSelectorTerms # 節點選擇列表matchFields # 按節點字段列出的節點選擇器要求列表matchExpressions # 按節點標簽列出的節點選擇器要求列表(推薦)key # 鍵values # 值operator # 關系符,支持Exists, DoesNotExist, In, NotIn, Gt, LtpreferredDuringSchedulingIgnoredDuringExecution 優先調度到滿足指定的規則的Node,相當于軟限制 (傾向)preference 一個節點選擇器項,與相應的權重相關聯matchFields 按節點字段列出的節點選擇器要求列表matchExpressions 按節點標簽列出的節點選擇器要求列表(推薦)key 鍵values 值operator 關系符 支持In, NotIn, Exists, DoesNotExist, Gt, Ltweight 傾向權重,在范圍1-100。
- 關系符的使用說明
- matchExpressions:- key: nodeenv # 匹配存在標簽的key為nodeenv的節點operator: Exists- key: nodeenv # 匹配標簽的key為nodeenv,且value是"xxx"或"yyy"的節點operator: Invalues: ["xxx","yyy"]- key: nodeenv # 匹配標簽的key為nodeenv,且value大于"xxx"的節點operator: Gtvalues: "xxx"
- 創建 pod-nodeaffinity-required.yaml,測試 requiredDuringSchedulingIgnoredDuringExecution
apiVersion: v1
kind: Pod
metadata:name: pod-nodeaffinity-requirednamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1affinity: #親和性設置nodeAffinity: #設置node親和性requiredDuringSchedulingIgnoredDuringExecution: # 硬限制nodeSelectorTerms:- matchExpressions: # 匹配env的值在["xxx","yyy"]中的標簽- key: nodeenvoperator: Invalues: ["xxx","yyy"]
# 創建pod
[root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created# 查看pod狀態 (運行失敗)
[root@k8s-master01 ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 0/1 Pending 0 16s <none> <none> ......# 查看Pod的詳情
# 發現調度失敗,提示node選擇失敗
[root@k8s-master01 ~]# kubectl describe pod pod-nodeaffinity-required -n dev
......Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.#接下來,停止pod
[root@k8s-master01 ~]# kubectl delete -f pod-nodeaffinity-required.yaml
pod "pod-nodeaffinity-required" deleted# 修改文件,將values: ["xxx","yyy"]------> ["pro","yyy"]
[root@k8s-master01 ~]# vim pod-nodeaffinity-required.yaml# 再次啟動
[root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created# 此時查看,發現調度成功,已經將pod調度到了node1上
[root@k8s-master01 ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 1/1 Running 0 8s 10.244.36.74 k8s-node1 ......
- 創建 pod-nodeaffinity-preferred.yaml,測試 requiredDuringSchedulingIgnoredDuringExecution
apiVersion: v1
kind: Pod
metadata:name: pod-nodeaffinity-preferrednamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1affinity: #親和性設置nodeAffinity: #設置node親和性preferredDuringSchedulingIgnoredDuringExecution: # 軟限制- weight: 1preference:matchExpressions: # 匹配env的值在["xxx","yyy"]中的標簽(當前環境沒有)- key: nodeenvoperator: Invalues: ["xxx","yyy"]
# 創建pod
[root@k8s-master01 ~]# kubectl create -f pod-nodeaffinity-preferred.yaml
pod/pod-nodeaffinity-preferred created# 查看pod狀態 (運行成功)
[root@k8s-master01 ~]# kubectl get pod pod-nodeaffinity-preferred -n dev
NAME READY STATUS RESTARTS AGE
pod-nodeaffinity-preferred 1/1 Running 0 40s
- NodeAffinity 規則設置的注意事項
- 如果同時定義了 nodeSelector 和 nodeAffinity,那么必須兩個條件都得到滿足,Pod 才能運行在指定的 Node 上
- 如果 nodeAffinity 指定了多個 nodeSelectorTerms,那么只需要其中一個能夠匹配成功即可
- 如果一個 nodeSelectorTerms 中有多個 matchExpressions ,則一個節點必須滿足所有的才能匹配成功
- 如果一個 pod 所在的 Node 在 Pod 運行期間其標簽發生了改變,不再符合該 Pod 的節點親和性需求,則系統將忽略此變化
PodAffinity
- PodAffinity 主要實現以運行的 Pod 為參照,實現讓新創建的 Pod 跟參照 pod 在一個區域的功能。PodAffinity 的可配置項
pod.spec.affinity.podAffinityrequiredDuringSchedulingIgnoredDuringExecution #硬限制namespaces # 指定參照pod的namespacetopologyKey # 指定調度作用域labelSelector # 標簽選擇器matchExpressions # 按節點標簽列出的節點選擇器要求列表(推薦)key # 鍵values # 值operator # 關系符 支持In, NotIn, Exists, DoesNotExist.matchLabels # 指多個matchExpressions映射的內容preferredDuringSchedulingIgnoredDuringExecution # 軟限制podAffinityTerm # 選項namespaces topologyKeylabelSelectormatchExpressions key # 鍵values # 值operatormatchLabels weight # 傾向權重,在范圍1-100
- topologyKey 用于指定調度時作用域,例如
kubernetes.io/hostname # 那就是以Node節點為區分范圍。簡單來說,就是要調度到對應的節點
beta.kubernetes.io/os # 則以 Node節點的操作系統類型來區分。簡單來說,就是調度到和對應 pod 所在的操作系統,同系統的節點上
- 創建 pod-podaffinity-target.yaml,設置參照 pod
apiVersion: v1
kind: Pod
metadata:name: pod-podaffinity-targetnamespace: devlabels:podenv: pro #設置標簽
spec:containers:- name: nginximage: nginx:1.17.1nodeName: k8s-node1 # 將目標pod名確指定到node1上
# 啟動目標pod
[root@k8s-master01 ~]# kubectl create -f pod-podaffinity-target.yaml
pod/pod-podaffinity-target created# 查看pod狀況
[root@k8s-master01 ~]# kubectl get pods pod-podaffinity-target -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-target 1/1 Running 0 4s
- 創建 pod-podaffinity-required.yaml
# 配置表達的意思是:新 Pod 必須要與擁有標簽 nodeenv=xxx 或者 nodeenv=yyy 的 pod 在同一 Node 上,顯然現在沒有這樣 pod
apiVersion: v1
kind: Pod
metadata:name: pod-podaffinity-requirednamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1affinity: #親和性設置podAffinity: #設置pod親和性requiredDuringSchedulingIgnoredDuringExecution: # 硬限制- labelSelector:matchExpressions: # 匹配env的值在["xxx","yyy"]中的標簽- key: podenvoperator: Invalues: ["xxx","yyy"]topologyKey: kubernetes.io/hostname
# 啟動pod
[root@k8s-master01 ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created# 查看pod狀態,發現未運行
[root@k8s-master01 ~]# kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-required 0/1 Pending 0 9s# 查看詳細信息
[root@k8s-master01 ~]# kubectl describe pods pod-podaffinity-required -n dev
......
Events:Type Reason Age From Message---- ------ ---- ---- -------Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 2 node(s) didn't match pod affinity rules, 1 node(s) had taints that the pod didn't tolerate.# 接下來修改 values: ["xxx","yyy"]----->values:["pro","yyy"]
# 意思是:新Pod必須要與擁有標簽nodeenv=xxx或者nodeenv=yyy的pod在同一Node上
[root@k8s-master01 ~]# vim pod-podaffinity-required.yaml# 然后重新創建pod,查看效果
[root@k8s-master01 ~]# kubectl delete -f pod-podaffinity-required.yaml
pod "pod-podaffinity-required" de leted
[root@k8s-master01 ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created# 發現此時Pod運行正常
[root@k8s-master01 ~]# kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE LABELS
pod-podaffinity-required 1/1 Running 0 6s <none>
- 關于 PodAffinity 的 preferredDuringSchedulingIgnoredDuringExecution,這里不再演示
PodAntiAffinity
- PodAntiAffinity 主要實現以運行的 Pod 為參照,讓新創建的 Pod 跟參照 pod 不在一個區域中的功能。它的配置方式和選項跟 PodAffinty 是一樣的,這里不再做詳細解釋,直接做一個測試案例
- 繼續使用上個案例中目標 pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE LABELS
pod-podaffinity-required 1/1 Running 0 3m29s 10.244.1.38 node1 <none>
pod-podaffinity-target 1/1 Running 0 9m25s 10.244.1.37 node1 podenv=pro
- 創建 pod-podantiaffinity-required.yaml
# 配置表達的意思是:新 Pod 必須要與擁有標簽 nodeenv=pro 的 pod 不在同一 Node 上
apiVersion: v1
kind: Pod
metadata:name: pod-podantiaffinity-requirednamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1affinity: #親和性設置podAntiAffinity: #設置pod親和性requiredDuringSchedulingIgnoredDuringExecution: # 硬限制- labelSelector:matchExpressions: # 匹配podenv的值在["pro"]中的標簽- key: podenvoperator: Invalues: ["pro"]topologyKey: kubernetes.io/hostname
# 創建pod
[root@k8s-master01 ~]# kubectl create -f pod-podantiaffinity-required.yaml
pod/pod-podantiaffinity-required created# 查看pod
# 發現調度到了node2上
[root@k8s-master01 ~]# kubectl get pods pod-podantiaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ..
pod-podantiaffinity-required 1/1 Running 0 30s 10.244.1.96 node2 ..
污點和容忍
污點(Taints)
- 前面的調度方式都是站在 Pod 的角度上,通過在 Pod 上添加屬性,來確定 Pod 是否要調度到指定的 Node 上,其實我們也可以站在 Node 的角度上,通過在 Node 上添加污點屬性,來決定是否允許 Pod 調度過來
- Node 被設置上污點之后就和 Pod 之間存在了一種相斥的關系,進而拒絕 Pod 調度進來,甚至可以將已經存在的 Pod 驅逐出去
- 污點的格式為:
key=value:effect,key 和 value 是污點的標簽,effect 描述污點的作用,支持如下三個選項:
- PreferNoSchedule:kubernetes 將盡量避免把 Pod 調度到具有該污點的 Node 上,除非沒有其他節點可調度
- NoSchedule:kubernetes 將不會把 Pod 調度到具有該污點的 Node 上,但不會影響當前 Node 上已存在的 Pod
- NoExecute:kubernetes 將不會把 Pod 調度到具有該污點的 Node 上,同時也會將 Node 上已存在的 Pod 驅離

- 使用 kubectl 設置和去除污點的命令示例如下:
# 設置污點
kubectl taint nodes node1 key=value:effect# 去除污點
kubectl taint nodes node1 key:effect-# 去除所有污點
kubectl taint nodes node1 key-
- 演示下污點的效果
- 準備節點 node1(為了演示效果更加明顯,暫時停止 node2 節點)
# shutdown 某個節點后,可以看看是否對應節點 NotReady 了
kubectl get nodes
- 為 node1 節點設置一個污點
tag=heima:PreferNoSchedule,然后創建 pod1(pod1 可以) - 修改為 node1 節點設置一個污點
tag=heima:NoSchedule,然后創建 pod2(pod1 正常 pod2 失敗) - 修改為 node1 節點設置一個污點
tag=heima:NoExecute然后創建 pod3 (3個pod都失敗)
# 為node1設置污點(PreferNoSchedule)
[root@k8s-master01 ~]# kubectl taint nodes k8s-node1 tag=heima:PreferNoSchedule# 創建pod1
[root@k8s-master01 ~]# kubectl run taint1 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1-766c47bf55-w7plx 1/1 Running 0 97s 10.244.36.76 k8s-node1 # 為node1設置污點(取消PreferNoSchedule,設置NoSchedule)
[root@k8s-master01 ~]# kubectl taint nodes k8s-node1 tag:PreferNoSchedule-
[root@k8s-master01 ~]# kubectl taint nodes k8s-node1 tag=heima:NoSchedule# 創建pod2
[root@k8s-master01 ~]# kubectl run taint2 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1-766c47bf55-w7plx 1/1 Running 0 97s 10.244.36.76 k8s-node1
taint2-84946958cf-q4wl8 0/1 Pending 0 32s <none> <none> # 為node1設置污點(取消NoSchedule,設置NoExecute)
[root@k8s-master01 ~]# kubectl taint nodes k8s-node1 tag:NoSchedule-
[root@k8s-master01 ~]# kubectl taint nodes k8s-node1 tag=heima:NoExecute# 創建pod3
[root@k8s-master01 ~]# kubectl run taint3 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
taint1-766c47bf55-shhns 0/1 Pending 0 12s <none> <none>
taint2-84946958cf-dt7bn 0/1 Pending 0 12s <none> <none>
taint3-57d45f9d4c-b2n4q 0/1 Pending 0 5s <none> <none>
- 小提示:使用 kubeadm 搭建的集群,默認就會給 master 節點添加一個污點標記,所以 pod 就不會調度到 master 節點上
容忍(Toleration)
- 污點的作用,我們可以在 node 上添加污點用于拒絕 pod 調度上來,但是如果就是想將一個 pod 調度到一個有污點的 node 上去,這時候應該怎么做呢?這就要使用到 容忍
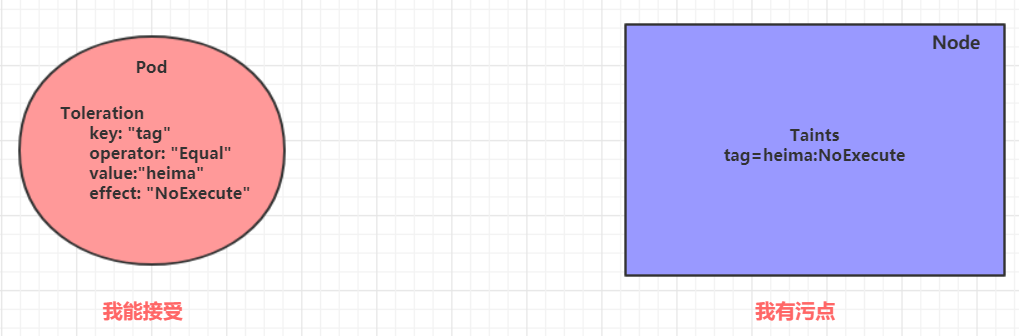
污點就是拒絕,容忍就是忽略,Node 通過污點拒絕 pod 調度上去,Pod 通過容忍忽略拒絕
- 案例效果
- 上一小節,已經在 k8s-node1 節點上打上了
NoExecute的污點,此時 pod 是調度不上去的 - 本小節,可以通過給 pod 添加容忍,然后將其調度上去
- 創建 pod-toleration.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-tolerationnamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1tolerations: # 添加容忍- key: "tag" # 要容忍的污點的keyoperator: "Equal" # 操作符value: "heima" # 容忍的污點的valueeffect: "NoExecute" # 添加容忍的規則,這里必須和標記的污點規則相同
# 創建
[root@k8s-master ~]# kubectl create -f pod-toleration.yaml
pod/pod-toleration created# 添加容忍之前的pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
pod-toleration 0/1 Pending 0 3s <none> <none> <none> # 添加容忍之后的pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
pod-toleration 1/1 Running 0 6s 10.244.36.81 k8s-node1 <none> <none>
- 容忍的詳細配置
[root@k8s-master01 ~]# kubectl explain pod.spec.tolerations
......
FIELDS:key # 對應著要容忍的污點的鍵,空意味著匹配所有的鍵value # 對應著要容忍的污點的值operator # key-value 的運算符,支持 Equal(默認)和 Existseffect # 對應污點的 effect,空意味著匹配所有影響tolerationSeconds # 容忍時間, 當 effect 為 NoExecute 時生效,表示 pod 在 Node 上的停留時間
)





)

)










