文章目錄
- 一、深度學習
- 1.什么是深度學習?
- 2.特點
- 3.神經網絡構造
- 1).單層神經元
- 2)多層神經網絡
- 3)小結
- 4.感知器
- 5.多層感知器
- 6.多層感知器(偏置節點)
- 7.神經網絡構造
一、深度學習
1.什么是深度學習?
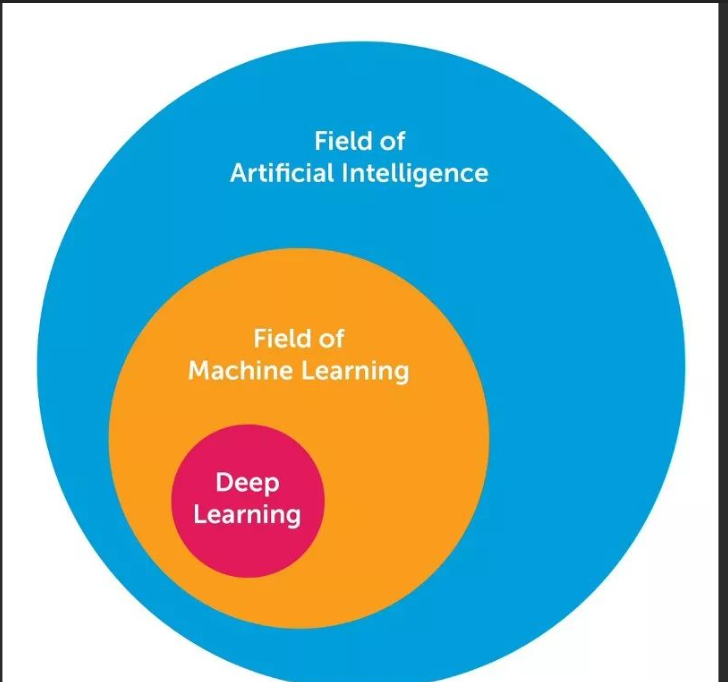
深度學習是人工智能的一個子領域,屬于機器學習的一部分,它基于人工神經網絡的概念和結構,通過模擬人腦的工作方式來進行機器學習。
2.特點
深度學習的主要特點是使用多層次的神經網絡來提取和學習數據中的特征,并通過反向傳播算法來優化參數,從而實現對復雜數據的建模與分類。深度學習在圖像識別、語音識別、自然語言處理等領域取得了顯著的成果,并被廣泛應用于各種領域。
3.神經網絡構造
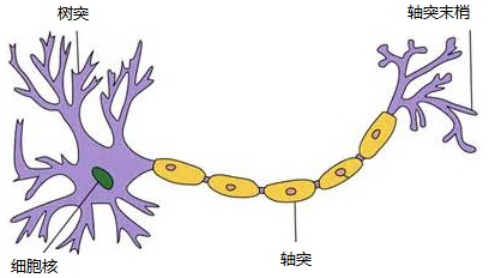
神經網絡是一種由多個神經元(或稱為節點)組成的計算模型,它模擬了生物神經系統中神經元之間的連接方式。神經網絡有輸入層、隱藏層和輸出層組成,其中輸入層用于接收外界的輸入信號,輸出層用于輸出預測結果,隱藏層則用于處理輸入信號并產生中間結果。
1).單層神經元
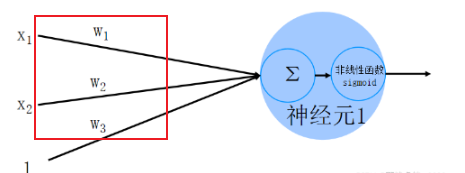
如下圖所示:
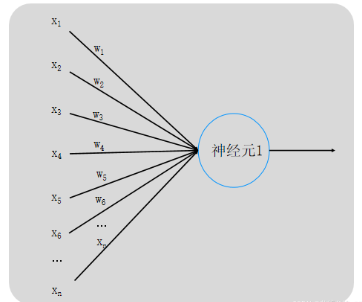
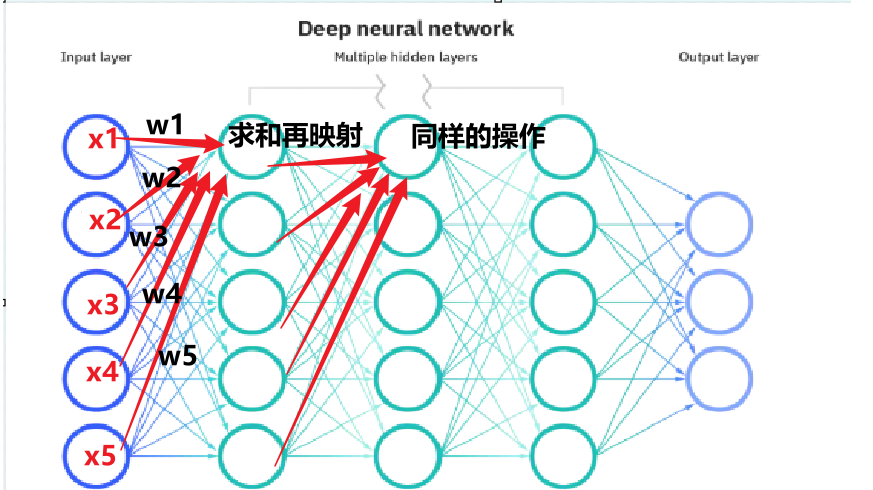
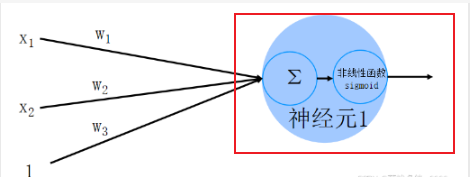
神經元1為輸入層,而外部傳入的x1、x2、x3、x4、x5、……全部都是外界即將傳入神經元的電信號,這些電信號在傳入途中可能會有所損耗,而損耗完剩下的才會傳入神經元,這些傳入的實際信號就用w1x1、w2x2、w3x3、w4x4、w5x5、……來表示,w叫做權重。
-
推導
有下列一堆數據,存在一條直線將他們分開成兩類,而這條線叫線的表達式可以表示為y=kx+b

將這個線性回歸模型的表達式數學轉換成神經網絡模型的計算表達式
y=kx+b —> 0=kx+b-y —> k1x+k2y+b=0 —> w1x1+w2x2+b=0 —> w1x1+w2x2+1*w0=0
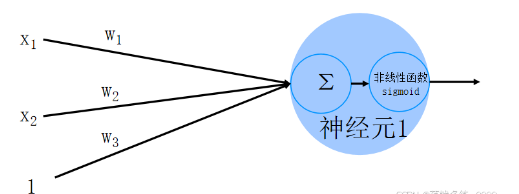
這里的1為偏置項
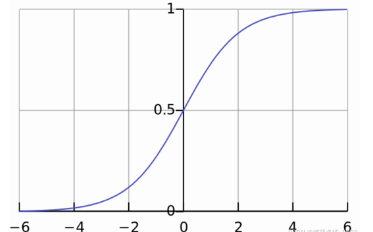
如圖傳入信號為x1,x2,x3,他們分別通過權重w改變以后得到w1x1+w2x2+w3x3,然后再將這個結果映射到非線性函數上,這個非線性函數大多數用的都是sigmoid函數,從而得到最終結果,用sigmoid函數的原因是為了完成邏輯回歸,因為 上圖的模型為線性模型,他不能進行邏輯回歸,所以只能將其映射到sigmoid函數中使其轉變為邏輯回歸。sigmoid函數圖像:
2)多層神經網絡
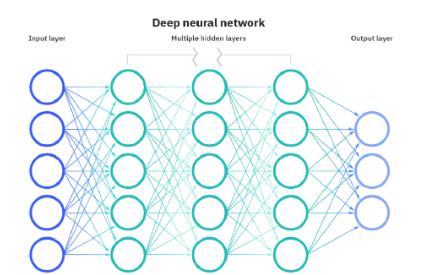
如圖所示,第一列叫輸入層,最后一列叫輸出層,神經元則在中間三列,每一個神經元的運行方式和上述單層網絡一樣,如下圖所示,上圖的5個信號乘以權重的結果求和,然后再對求和的值映射到sigmoid函數,然后第一個神經元接收到這樣的信息,然后第一列的每一個神經元都需要得到所有信號的處理,最后再將這通過映射得到的五個值當做信號x再次計算權重求和映射傳給下一個神經元,傳送到最后到輸出層得到結果。(這里的為初期的神經網絡構架)
3)小結
神經網絡是由大量神經元相互之間鏈接構成,
每個神經元節點代表一種特定的輸出函數,稱為激活函數。
如圖所示:
每兩個節點間的鏈接都代表一種對于通過該連接信號的加權值,稱之為權重。
如圖所示:
4.感知器
在“感知器”中,有兩個層次。分別是輸入層和輸出層。輸入層里的“輸入單元”只負責傳輸數據,不做計算。輸出層里的“輸出單元”則需要對前面一層的輸入進行計算。
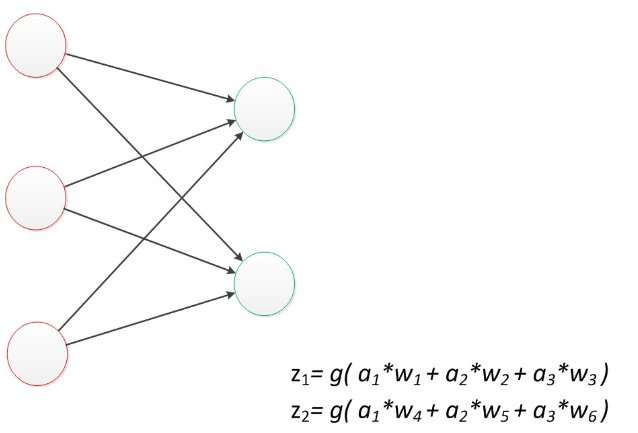
因為上述公式是線性代數方程組,因此可以用矩陣乘法表達這兩個公式,輸出公式為:
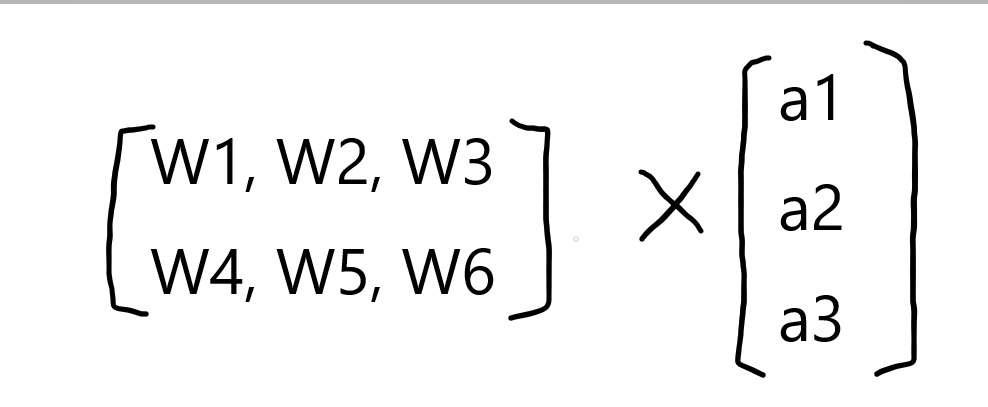
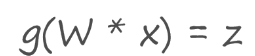
神經網絡的本質
通過參數與激活函數來擬合特征與目標之間的真實函數關系。但在一個神經網絡的程序中,不需要神經元和線,本質上是矩陣的運算,實現一個神經網絡最需要的是線性代數庫。
5.多層感知器
相對于上述感知器,多層感知器則增加了一個中間層,即隱含層,神經網絡可以做非線性分類的關鍵–隱含層。

現在,我們將權值矩陣增加到了兩個,用上標來區分不同層次之間的變量。
例如ax(y)代表第y層的第x個節點。
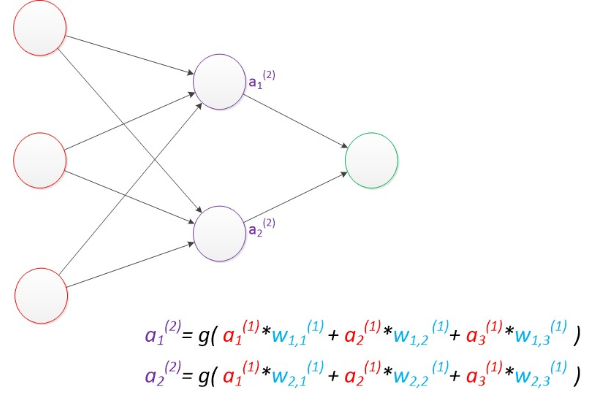
6.多層感知器(偏置節點)
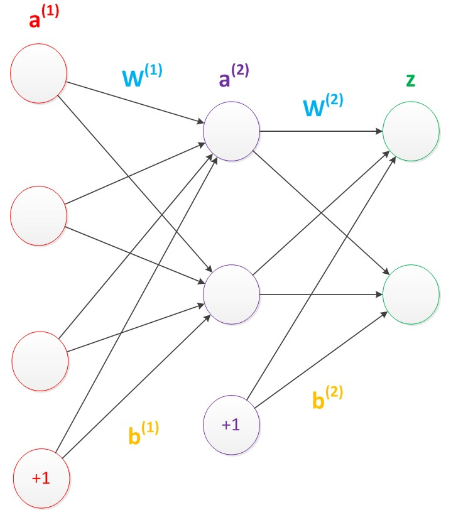
偏置節點:這些節點是默認存在的。它本質上是一個只含有存儲功能,且存儲值永遠為1的單元。在神經網絡的每個層次中,除了輸出層以外,都會含有這樣一個偏置單元。
偏置節點與后一層的所有節點都有連接:
7.神經網絡構造
- 重點
1.設計一個神經網絡時,輸入層與輸出層的節點數往往是固定的,中間層則可以自由指定;
2.神經網絡結構圖中的箭頭代表著預測過程時數據的流向,跟訓練時的數據流有一定的區別;
3.結構圖里的關鍵不是圓圈(代表“神經元”),而是連接線(代表“神經元”之間的連接)。每個連接線對應一個不同的權重(其值稱為權值),這是需要訓練得到的。
- 如何構造中間層
1.輸入層的節點數:與特征的維度匹配
2.輸出層的節點數:與目標的維度匹配。
3.中間層的節點數:目前業界沒有完善的理論來指導這個決策。一般是根據經驗來設置。較好的方法就是預先設定幾個可選值,通過切換這幾個值來看整個模型的預測效果,選擇效果最好的值作為最終選擇。







機器人仿真器存在的問題)
)

--網絡編程習題)



:6G技術加速落地 衛星通信網絡迎來組網高潮)




